在unsloth框架下的基于医疗deepseek模型微调
目录
框架介绍:
微调 vs 强化学习 vs 模型蒸馏
微调(Fine-tuning):
强化学习(Reinforcement Learning):
模型蒸馏(Model Distillation):
大模型微调:
全量微调与高效微调
全量微调(Full Fine-Tuning):
高效微调(Efficient Fine-Tuning):
高效微调与LoRA、 QLoRA:
高效微调的应用场景:
环境安装:
模型下载:
医疗数据下载:
训练代码:
参数解析:
参考链接:
框架介绍:
unsloth 是一个专门为模型微调而设计的框架,旨在解决模型微调过程中训练速度慢、显存占用高等问题。以下是其相关介绍:
主要优势
快速的训练速度:在对主流模型(如 llama-3、qwen2、mistral 等)进行微调时,unsloth 的速度相比其他传统微调方法可提高 2 至 5 倍,能让开发者更快地完成模型训练过程,缩短开发周期。
低显存占用:它最大能够减少约 70% 的显存使用量,使得在显存有限的硬件上,如中低端的 GPU 设备,也能顺利进行模型微调训练。
技术特点
强大的兼容性:unsloth 支持多种硬件设置,涵盖了从 NVIDIA Tesla T4 到 H100 等不同型号的 GPU,还扩展到了 AMD 和英特尔 GPU 的兼容性,为使用不同硬件的开发者提供了便利。
优化的内存使用:采用智能权重上投等开创性技术,在 QLoRA 过程中减少了权重上投的必要性,有效优化内存使用。同时,能迅速利用 bfloat16,提高 16 位训练的稳定性,进一步加快 QLoRA 的微调过程。
使用体验
安装简单:可以通过pip install "unsloth(cu121 - torch230)@git + https://github.com/unslothai/unsloth.git"命令进行安装。
免费且易用的笔记本:提供免费的 Jupyter 笔记本,用户只需添加数据集并点击 “运行全部”,即可获得微调后的模型,支持导出为 GGUF、Ollama、vLLM 等多种格式,还可上传至 Hugging Face。
其他特性
动态量化与长上下文支持:支持动态 4 - bit 量化,精度损失几乎为零,显存占用仅增加不到 10%。同时,支持 Llama 3.3 模型的 89K 上下文窗口,处理长文本更高效。
视觉模型支持:除语言模型外,还支持 Llama 3.2 Vision、Qwen 2.5 VL 等视觉模型,满足多模态任务需求。
微调 vs 强化学习 vs 模型蒸馏
伴随着DeepSeek的兴起,关于强化学习训练、模型蒸馏等概念也逐渐被人熟知,这里简单总结下这三者的异同。微调、强化学习训练和模型蒸馏都是常用的技术方法,尽管这些方法在某些方面存在交集,但它们的核心原理和任务目标却有显著差异。
微调(Fine-tuning):
微调是指在已经训练好的大型预训练模型的基础上,进一步训练该模型以适应特定任务或特定领域的数据。相比从零开始训练一个模型,微调所需的数据和计算资源显著减少;可以在特定任务上取得更好的性能,因为模型在微调过程中会重点学习与任务相关的特性;可以在多种领域(如情感分析、问答系统等)上进行微调,从而快速适应不同应用场景。
举个🌰:想象一下,你有一只机器人狗,它已经在基本的狗行为上进行了初步训练,比如行走和听从简单的命令。微调就像是对这只机器狗进行进一步的训练以适应特定的任务环境。比如说,你希望这只机器狗能够在公园里捡回特定种类的球。通过微调,你可以在原有的训练基础上,用一组特定的数据集(比如各种颜色和大小的球)来调整其行为,使其在新环境中表现得更好。
目标:通过少量的标注数据对预训练模型进行优化,适应具体任务。
特点:微调的计算量相对较小,能够在有限的数据和计算资源下提升模型在特定任务上的性能。
应用:常用于下游任务如情感分析、机器翻译、推荐系统等。
强化学习(Reinforcement Learning):
强化学习是一种机器学习方法,它通过让智能体在环境中执行动作,以获得反馈或奖励信号,从而学习最优策略。通过不断地试错和调整策略,智能体逐渐找到能够最大化长期回报的行为路径。这种学习方法常用于需要决策和动态环境交互的任务,如游戏、机器人导航和自动化控制系统。
举个🌰:强化学习训练则有点像是教这只机器狗通过尝试和错误来学习新技能。在这种情况下,你没有直接告诉它应该怎么做,而是为它设定一个目标,比如尽可能快地找到并捡起一只球。机器狗每完成一次任务都会获得奖励,然后它将通过调整自己的行为来最大化获得的奖励。例如,如果机器狗发现跑直线能更快地找到球,它可能会在未来的尝试中更倾向于这样做。
目标:通过与环境的交互,学习最优的行为策略,最大化累积奖励。
特点:强化学习强调动态决策,它通常不依赖于预定义的数据集,而是依赖于与环境的持续交互。
应用:强化学习在游戏AI(如AlphaGo)、机器人控制、自动驾驶等任务中有广泛应用。
模型蒸馏(Model Distillation):
模型蒸馏是一种模型压缩技术,通过将一个复杂的大型模型(通常称为“教师模型”)中的知识迁移到一个更小的模型(称为“学生模型”)。在这个过程中,教师模型首先对训练数据进行预测,生成软标签即概率分布。这些软标签包含了有关任务的重要信息。学生模型则使用这些软标签进行训练,以接近教师模型的性能。模型蒸馏能够在保持高精度的同时,显著减少模型的大小和计算消耗,适用于在资源受限的环境下部署机器学习模型。
举个🌰:你有一只非常昂贵和精密的机器人狗,它可以完美执行任务。为了降低成本,你希望制造一个更简单的机器狗,同样能有效完成任务。通过模型蒸馏,你会使用大狗的行为数据来训练小狗,让后者理解和模仿前者的精妙动作,同时保持高效性。
目标:通过教师模型的“知识转移” ,帮助学生模型提升性能,特别是计算能力有限的设备上。
特点:蒸馏的核心在于知识的迁移,尤其是在模型压缩和部署方面的优势。学生模型通常在性能上能接近教师模型,但参数量更小,计算更高效。
应用:常见于模型压缩、边缘计算、低功耗设备的部署中,用于提升部署效率并降低计算需求。
大模型微调:
与RAG(Retrieval-Augmented Generation)或Agent技术依靠构建复杂的工作流以优化模型性能不同,微调通过直接调整模型的参数来提升模型的能力。这种方法让模型通过在特定任务的数据上进行再训练,从而'永久'掌握该任务所需的技能。微调不仅可以显著提高模型在特定领域或任务上的表现,还能使其适应于各种具体应用场景的需求。这种能力的增强是通过更精细地调整模型内部的权重和偏差,使其在理解和生成信息时更加精准,因此被广泛用于需要高精度和领域适应性的任务中。
全量微调与高效微调
从广义上讲,微调可以分为两种主要方式:全量微调和高效微调。全量微调是指利用所有可用数据来重新训练模型,以全面优化其参数。尽管这种方法对计算资源的需求较高,但它能够在最大程度上提升模型对特定任务的适应能力。相反,高效微调则采用更精简的策略,只使用部分数据进行调整,并主要修改模型的部分参数。这种方法以相对较低的计算开销,实现对模型性能的显著提升,类似于“以小博大”,非常适合在资源有限的情况下快速调整和增强模型的性能。
全量微调(Full Fine-Tuning):
举个🌰:想象一下你在一家公司管理一个团队,这个团队的所有成员已经接受了基础培训,知道如何处理一般的工作任务。现在,公司引入了一个全新的复杂项目,要求团队具备更多的专业技能和知识。
优点:全面掌握所有相关技能,使模型对新任务有更高的适应性。
缺点:耗时更长,资源消耗大。
高效微调(Efficient Fine-Tuning):
高效微调的方法更有针对性,它不需要花费大量的时间和资源。举个🌰:比如,如果机器人狗的任务只是要学会在一种新环境中识别特别的障碍物,你可以在已有的模型基础上,仅仅微调那些与识别相关的参数,而无需重新训练整个模型。
优点:节省时间和资源,快速提升特定技能。
缺点:可能不如全面培训那样细致和彻底,但能够在特定任务中高效达标。
现在绝大多数开源模型,在开源的时候都会公布两个版本的模型,其一是Base模型,该模型只经过了预训练,没有经过指令微调;其二则是Chat模型(或者就是不带尾缀的模型),则是在预训练模型基础上进一步进行全量指令微调之后的对话模型。
高效微调与LoRA、 QLoRA:
尽管全量微调可以对模型的能力进行深度改造,但要带入模型全部参数进行训练,需要消耗大量的算力,且有一定的技术门槛。相比之下,在绝大多数场景中,如果我们只想提升模型某个具体领域的能力,那高效微调会更加合适。尽管在2020年前后,深度学习领域诞生了很多高效微调的方法,但现在适用于大模型的最主流的高效微调方法只有一种——LoRA。
LoRA(Low-Rank Adaptation)微调是一种参数高效的微调方法,旨在通过引入低秩矩阵来减少微调时需要调整的参数数量,从而显著降低显存和计算资源的消耗。具体来说,LoRA 微调并不直接调整原始模型的所有参数,而是通过在某些层中插入低秩的适配器(Adapter)层来进行训练。
LoRA的原理:
在标准微调中,会修改模型的所有权重,而在 LoRA 中,只有某些低秩矩阵(适配器)被训练和调整。这意味着原始模型的参数保持不变,只是通过少量的新参数来调整模型的输出。
低秩矩阵的引入可以在显存和计算能力有限的情况下,依然有效地对大型预训练模型进行微调,从而让 LoRA 成为显存较小的设备上的理想选择。
举个🌰:想象你想教学生们怎样进行快速心算而不去完全打破他们原有的学习方法。你决定只引入一个简化版本的心算技巧,让他们在现有知识的基础上进行少量调整。这就像是把原有的学习方式轻量化处理,只增加所需的少量新知识,而不是重新教授整个数学课程。
LoRA的优势:
1.显存优化: 只需要调整少量的参数(适配器),显著减少了显存需求,适合显存有限的GPU。
2.计算效率: 微调过程中的计算负担也更轻,因为减少了需要调整的参数量。
3.灵活性: 可以与现有的预训练模型轻松结合使用,适用于多种任务,如文本生成、分类、问答等。
而QLoRA(Quantized Low-Rank Adaptation)则是 LoRA 的一个扩展版本,它结合了 LoRA 的低秩适配器和量化技术。QLoRA 进一步优化了计算效率和存储需求,特别是在极端显存受限的环境下。与 LoRA 不同的是, QLoRA 会将插入的低秩适配器层的部分权重进行量化(通常是量化为INT4或INT8),在保持性能的同时显著降低模型的存储和计算需求。
举个🌰:针对学生中一些学习资源(如时间或精力)更加有限的情况,你进一步优化教学方法,不仅简化了学习内容(类似LoRA),同时还用了一些有助于记忆的技巧(比如使用图像或口诀),从而更有效地传授知识。这样,每个学生能在有限时间内学会心算法。在技术上,QLoRA涉及量化(quantization)技术,将模型的一部分权重参数存储在较低精度的数值格式中,以此减少内存使用和计算量,同时结合LoRA的低秩调整,让适应过程更加高效。
QLoRA的优势:
1.在显存非常有限的情况下仍能进行微调。2.可以处理更大规模的模型。
3.适合用于边缘设备和需要低延迟推理的场景。
高效微调的应用场景:
在实际大模型应用场景中,高效微调主要用于以下四个方面:
1.对话风格微调:高效微调可以用于根据特定需求调整模型的对话风格。例如,针对客服系统、虚拟助理等场景,模型可以通过微调来适应不同的语气、礼貌程度或回答方式,从而在与用户互动时提供更符合要求的对话体验。通过微调少量的参数(例如对话生成的策略、情感表达等),可以使模型表现出更具针对性和个性化的风格。
2.知识灌注:知识灌注是指将外部知识或领域特定的信息快速集成到已有的预训练模型中。通过高效微调,模型可以更好地学习新领域的专有知识,而无需重新从头开始训练。例如,对于法律、医疗等专业领域,可以使用少量的标注数据对预训练模型进行微调,帮助模型理解特定行业的术语、规则和知识,进而提升专业领域的问答能力。
3.推理能力提升:高效微调还可以用于提升大模型的推理能力,尤其是在处理更复杂推理任务时。通过微调,模型能够更加高效地理解长文本、推理隐含信息,或者从数据中提取逻辑关系,进而在多轮推理任务中提供更准确的答案。这种微调方式可以帮助模型在解答复杂问题时,提高推理准确性并减少错误。
4.Agent能力(Function calling & MCP能力)提升:在多任务协作或功能调用场景中,高效微调能够显著提升模型Agent能力,使得模型能够有效地与其他系统进行交互、调用外部API或执行特定MCP任务。通过针对性微调,模型可以学会更精准的功能调用策略、参数解析和操作指令,从而在自动化服务、智能助手或机器人控制等领域表现得更加高效和智能。
环境安装:
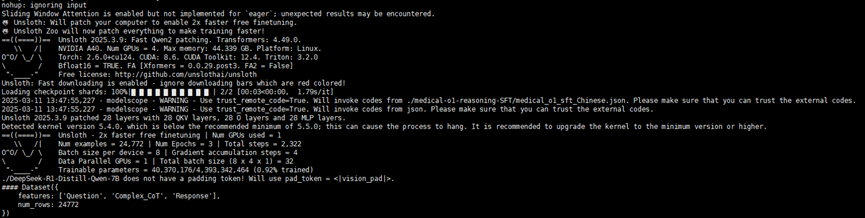
pip install unsloth模型下载:
模型选择DeepSeek-R1-Distill-Qwen-7B,魔塔链接魔搭社区。
医疗数据下载:
医疗数据采用带有CoT的数据集medical-o1-reasoning-SFT。该数据集用于微调华佗 GPT-o1,这是一款专为高级医学推理而设计的医疗领域大语言模型。该数据集是使用 GPT-4o 构建的,GPT-4o 会搜索可验证的医学问题的解决方案,并通过医学验证器对这些方案进行验证。
魔塔链接魔搭社区。

训练代码:
from unsloth import FastLanguageModel
import torch
from trl import SFTTrainer, SFTConfig
from datasets import load_dataset
from modelscope.msdatasets import MsDataset
from unsloth import is_bfloat16_supported
#这决定了模型的上下文长度。例如,Gemini 的上下文长度超过 100 万,而 Llama-3 的上下文长度为 8192。允许选择任意数字 - 但出于测试目的,建议将其设置为 2048。Unsloth 还支持非常长的上下文微调,表明可以提供比最佳长 4 倍的上下文长度。
max_seq_length = 2048
#将其保持为 None,但可以为较新的 GPU 选择 torch.float16 或 torch.bfloat16。
dtype = None
#采用 4 位量化进行微调。这样可将内存使用量减少 4 倍,从而在空闲的 16GB 内存 GPU 中实际进行微调。4 位量化本质上将权重转换为一组有限的数字以减少内存使用量。这样做的缺点是准确度会下降 1-2%。如果想要获得如此微小的额外准确度,请在 H100 等较大的 GPU 上将其设置为 False
load_in_4bit = False #True
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "./DeepSeek-R1-Distill-Qwen-7B",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
EOS_TOKEN = tokenizer.eos_token # Must add EOS_TOKEN
print("ori model:\n", model)
"""
model:
Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(152064, 3584, padding_idx=151654)
(layers): ModuleList(
(0-27): 28 x Qwen2DecoderLayer(
(self_attn): Qwen2Attention(
(q_proj): Linear(in_features=3584, out_features=3584, bias=True)
(k_proj): Linear(in_features=3584, out_features=512, bias=True)
(v_proj): Linear(in_features=3584, out_features=512, bias=True)
(o_proj): Linear(in_features=3584, out_features=3584, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=3584, out_features=18944, bias=False)
(up_proj): Linear(in_features=3584, out_features=18944, bias=False)
(down_proj): Linear(in_features=18944, out_features=3584, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((3584,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=3584, out_features=152064, bias=False)
)
"""
train_prompt_style = """Below is an instruction that describes a task, paired with an input that provides further context. Write a response that appropriately completes the request. Before answering, think carefully about the question and create a step-by-step chain of thoughts to ensure a logical and accurate response.
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning. Please answer the following medical question.
### Question:
{}
### Response:
<think>
{}
</think>
{}"""
def formatting_prompts_func(examples):
inputs = examples["Question"]
cots = examples["Complex_CoT"]
outputs = examples["Response"]
texts = []
for input, cot, output in zip(inputs, cots, outputs):
text = train_prompt_style.format(input, cot, output) + EOS_TOKEN
texts.append(text)
return {
"text": texts,
}
ds = MsDataset.load('./medical-o1-reasoning-SFT/medical_o1_sft_Chinese.json', split = "train").to_hf_dataset()
dataset = ds.map(formatting_prompts_func, batched = True,)
print(dataset["text"][0])
"""
### Instruction:
You are a medical expert with advanced knowledge in clinical reasoning, diagnostics, and treatment planning. Please answer the following medical question.
### Question:
根据描述,一个1岁的孩子在夏季头皮出现多处小结节,长期不愈合,且现在疮大如梅,溃破流脓,口不收敛,头皮下有空洞,患处皮肤增厚。这种病症在中医中诊断为什么病?
### Response:
<think>
这个小孩子在夏天头皮上长了些小结节,一直都没好,后来变成了脓包,流了好多脓。想想夏天那么热,可能和湿热有关。才一岁的小孩,免疫力本来就不强,夏天的湿热没准就侵袭了身体。
用中医的角度来看,出现小结节、再加上长期不愈合,这些症状让我想到了头疮。小孩子最容易得这些皮肤病,主要因为湿热在体表郁结。
但再看看,头皮下还有空洞,这可能不止是简单的头疮。看起来病情挺严重的,也许是脓肿没治好。这样的情况中医中有时候叫做禿疮或者湿疮,也可能是另一种情况。
等一下,头皮上的空洞和皮肤增厚更像是疾病已经深入到头皮下,这是不是说明有可能是流注或瘰疬?这些名字常描述头部或颈部的严重感染,特别是有化脓不愈合,又形成通道或空洞的情况。
仔细想想,我怎么感觉这些症状更贴近瘰疬的表现?尤其考虑到孩子的年纪和夏天发生的季节性因素,湿热可能是主因,但可能也有火毒或者痰湿造成的滞留。
回到基本的症状描述上看,这种长期不愈合又复杂的状况,如果结合中医更偏重的病名,是不是有可能是涉及更深层次的感染?
再考虑一下,这应该不是单纯的瘰疬,得仔细分析头皮增厚并出现空洞这样的严重症状。中医里头,这样的表现可能更符合‘蚀疮’或‘头疽’。这些病名通常描述头部严重感染后的溃烂和组织坏死。
看看季节和孩子的体质,夏天又湿又热,外邪很容易侵入头部,对孩子这么弱的免疫系统简直就是挑战。头疽这个病名听起来真是切合,因为它描述的感染严重,溃烂到出现空洞。
不过,仔细琢磨后发现,还有个病名似乎更为合适,叫做‘蝼蛄疖’,这病在中医里专指像这种严重感染并伴有深部空洞的情况。它也涵盖了化脓和皮肤增厚这些症状。
哦,该不会是夏季湿热,导致湿毒入侵,孩子的体质不能御,其病情发展成这样的感染?综合分析后我觉得‘蝼蛄疖’这个病名真是相当符合。
</think>
从中医的角度来看,你所描述的症状符合“蝼蛄疖”的病症。这种病症通常发生在头皮,表现为多处结节,溃破流脓,形成空洞,患处皮肤增厚且长期不愈合。湿热较重的夏季更容易导致这种病症的发展,特别是在免疫力较弱的儿童身上。建议结合中医的清热解毒、祛湿消肿的治疗方法进行处理,并配合专业的医疗建议进行详细诊断和治疗。<|end▁of▁sentence|>
"""
# Do model patching and add fast LoRA weights
model = FastLanguageModel.get_peft_model(
model,
r = 16, ## Choose any number > 0 ! Suggested 8, 16, 32, 64, 128
target_modules = ["q_proj", "k_proj", "v_proj", "o_proj",
"gate_proj", "up_proj", "down_proj",],
lora_alpha = 16, #微调的缩放因子。较大的数字将使微调更多地了解您的数据集,但可能会导致过度拟合。建议将其设置为等于等级r,或将其加倍
lora_dropout = 0, # Supports any, but = 0 is optimized
bias = "none", # Supports any, but = "none" is optimized
# [NEW] "unsloth" uses 30% less VRAM, fits 2x larger batch sizes!
use_gradient_checkpointing = "unsloth", # True or "unsloth" for very long context
random_state = 3407, #训练和微调需要随机数,因此设置此数字可使实验可重复
max_seq_length = max_seq_length,
use_rslora = False, # We support rank stabilized LoRA
loftq_config = None, # And LoftQ
)
print("lora model:\n", model)
"""
Unsloth 2025.3.9 patched 28 layers with 28 QKV layers, 28 O layers and 28 MLP layers.
model:
PeftModelForCausalLM(
(base_model): LoraModel(
(model): Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(152064, 3584, padding_idx=151654)
(layers): ModuleList(
(0-27): 28 x Qwen2DecoderLayer(
(self_attn): Qwen2Attention(
(q_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=3584, bias=True)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=3584, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(k_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=512, bias=True)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=512, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(v_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=512, bias=True)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=512, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(o_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=3584, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=3584, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=18944, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=18944, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(up_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=3584, out_features=18944, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=3584, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=18944, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(down_proj): lora.Linear4bit(
(base_layer): Linear4bit(in_features=18944, out_features=3584, bias=False)
(lora_dropout): ModuleDict(
(default): Identity()
)
(lora_A): ModuleDict(
(default): Linear(in_features=18944, out_features=16, bias=False)
)
(lora_B): ModuleDict(
(default): Linear(in_features=16, out_features=3584, bias=False)
)
(lora_embedding_A): ParameterDict()
(lora_embedding_B): ParameterDict()
(lora_magnitude_vector): ModuleDict()
)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((3584,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=3584, out_features=152064, bias=False)
)
)
)
"""
FastLanguageModel.for_inference(model)
#普通问答
question = "你是谁?"
inputs = tokenizer([question], return_tensors="pt").to("cuda")
print("inputs:\n", inputs)
"""
inputs:
{'input_ids': tensor([[105043, 100165, 11319]], device='cuda:0'), 'attention_mask': tensor([[1, 1, 1]], device='cuda:0')}
"""
outputs = model.generate(input_ids=inputs.input_ids, max_new_tokens=1200, use_cache=True,)
print("outputs:\n", outputs)
"""
outputs:
tensor([[105043, 100165, 11319, 1248, 151649, 271, 35946, 101909, 15469,
110498, 3837, 67071, 105538, 102217, 30918, 50984, 9909, 33464,
39350, 7552, 73218, 102024, 100013, 3837, 35946, 101222, 100005,
101294, 57218, 103377, 3837, 36993, 101217, 114706, 99878, 33108,
114886, 105421, 100364, 20002, 1773, 151643]], device='cuda:0')
"""
response = tokenizer.batch_decode(outputs)
print("response:\n", response)
"""
response:
["你是谁?'\n</think>\n\n我是一个AI助手,由中国的深度求索(DeepSeek)公司独立开发,我清楚自己的身份与局限,会始终秉持专业和诚实的态度帮助用户。<|end▁of▁sentence|>"]
"""
print("格式化输出:",response[0])
"""
格式化输出: 你是谁?'
</think>
我是一个AI助手,由中国的深度求索(DeepSeek)公司独立开发,我清楚自己的身份与局限,会始终秉持专业和诚实的态度帮助用户。<|end▁of▁sentence|>
"""
#结构化输入方法
prompt_style_chat = """请写出一个恰当的回答来完成当前对话任务。
### Instruction:你是一名助人为乐的助手。
### Question:{}
### Response:<think>{}"""
question = "你好,好久不见!"
print("格式化输入:",[prompt_style_chat.format(question, "")])
"""
格式化输入: ['请写出一个恰当的回答来完成当前对话任务。\n### Instruction:你是一名助人为乐的助手。\n### Question:你好,好久不见!\n### Response:<think>']
"""
inputs = tokenizer([prompt_style_chat.format(question, "")], return_tensors="pt").to("cuda")
outputs = model.generate(input_ids=inputs.input_ids, max_new_tokens=1200, use_cache=True,)
response = tokenizer.batch_decode(outputs)
print("response:\n", response)
"""
response:
['请写出一个恰当的回答来完成当前对话任务。\n### Instruction:你是一名助人为乐的助手。\n### Question:你好,好久不见!\n### Response:<think>\n好,用户发来了“你好,好久不见!”,看起来是在打招呼,可能是在闲聊或者想拉近距离。\n\n我需要回应友好,保持对话的连贯性。回复“你好!久仰大名!最近怎么样?”,这样既表达了关心,又询问了近况,方便用户继续交流。\n\n这样回应既符合助人为乐的宗旨,又保持了自然的语气,让用户感觉亲切。\n</think>\n\n你好!久仰大名!最近怎么样?<|end▁of▁sentence|>']
"""
print("格式化输出:\n", response[0].split("### Response:")[1])
"""
格式化输出:
<think>
好,用户发来了“你好,好久不见!”,看起来是在打招呼,可能是在闲聊或者想拉近距离。
我需要回应友好,保持对话的连贯性。回复“你好!久仰大名!最近怎么样?”,这样既表达了关心,又询问了近况,方便用户继续交流。
这样回应既符合助人为乐的宗旨,又保持了自然的语气,让用户感觉亲切。
</think>
你好!久仰大名!最近怎么样?<|end▁of▁sentence|>
</think>
"""
#问答模版设置
prompt_style = """以下是一个任务说明,配有提供更多背景信息的输入。请写出一个恰当的回答来完成该任务。在回答之前,请仔细思考问题,并按步骤进行推理,确保回答逻辑清晰且准确。
### Instruction:您是一位具有高级临床推理、诊断和治疗规划知识的医学专家。请回答以下医学问题。
### 问题:{}
### 回复:{}
"""
question_1 = "一位61岁的女性,有长期在咳嗽或打喷嚏等活动中发生不自主尿液流失的病史,但夜间没有漏尿。她接受了妇科检查和Q-tip测试。根据这些检查结果,膀胱测量(cystometry)最可能会显示她的残余尿量和逼尿肌收缩情况如何?"
question_2 = "面对一位突发胸痛并放射至颈部和左臂的患者,其既往病史包括高胆固醇血症和冠状动脉疾病,同时伴有升高的肌钙蛋白I水平和心动过速,根据这些临床表现,最可能受累的冠状动脉是哪一条?"
#问题1测试
inputs1 = tokenizer([prompt_style.format(question_1, "")], return_tensors="pt").to("cuda")
outputs1 = model.generate(input_ids=inputs1.input_ids, max_new_tokens=1200, use_cache=True,)
response1 = tokenizer.batch_decode(outputs1)
print("问题1回复:\n", response1[0].split("### 回复:")[1])
"""
问题1回复:
嗯,我现在需要解决一个关于膀胱测量的问题。让我仔细看看问题内容。问题描述了一位61岁的女性,有长期在咳嗽或打喷嚏时不自主尿液流失的病史,但夜间没有漏尿。她接受了妇科检查和Q-tip测试,现在想知道膀胱测量(cystometry)的结果,特别是她的残余尿量和逼尿肌收缩情况。
首先,我需要理解她的症状。她描述的是在咳嗽或打喷嚏时,不自主地流失尿液。这可能意味着在活动时,膀胱颈的肌肉没有完全收缩,导致尿液从膀胱漏出。这种情况通常称为“持续性尿失禁”(D乌)或“不自主尿失禁”。持续性尿失禁是由于膀胱颈的肌肉松弛,逼尿肌无法完全抑制膀胱的活动,导致尿液不自主地漏出。
接下来,她提到夜间没有漏尿。这可能是因为夜间活动较少,膀胱颈的肌肉在静息状态下已经收缩,所以夜间症状不明显。但早晨可能在活动时再次出现漏尿,尤其是在排尿困难时。
她接受了妇科检查和Q-tip测试。Q-tip测试是一种常用的测试方法,用于评估尿失禁的情况。通常,Q-tip测试包括让患者侧卧,然后进行三个动作:迅速坐起、迅速下床或迅速站起来。在这些动作下,如果患者出现尿液从尿道滴出,就说明存在持续性尿失禁。如果没有尿液滴出,可能排除了持续性尿失禁,但需要结合其他症状来判断。
现在,问题转向膀胱测量(cystometry)的结果。膀胱测量用于评估膀胱的容量和压力感受器的情况,特别是残余尿量( leftover urine)和逼尿肌的收缩情况。残余尿量是指在膀胱被完全排空后,仍存在于膀胱中的尿量。逼尿肌的收缩情况则与膀胱颈的肌肉有关,收缩良好意味着逼尿肌能够有效抑制尿液漏出。
根据她的症状,膀胱测量可能会显示以下情况:因为她有持续性尿失禁,膀胱颈的肌肉可能没有完全收缩,导致残余尿量较多。残余尿量多可能意味着在膀胱被排空后,仍有较多的尿液留在膀胱中。同时,逼尿肌的收缩情况可能不完全,即逼尿肌无法有效抑制尿液漏出,这也是导致尿失禁的原因。
此外,Q-tip测试的结果可能支持膀胱测量的结论。如果Q-tip测试显示患者在坐起、下床或站起来时有尿液滴出,这进一步证明了膀胱颈肌肉松弛,残余尿量多,逼尿肌收缩不完全。
所以,综合来看,膀胱测量最可能会显示她的残余尿量较多,而逼尿肌的收缩可能不完全,这与她的持续性尿失禁症状一致。
</think>
根据该患者的症状和检查结果,膀胱测量最可能会显示以下情况:
1. **残余尿量较多**:由于患者在咳嗽或打喷嚏时不自主尿液流失,提示膀胱颈肌肉可能未完全收缩,导致膀胱中存在较多的残余尿量。
2. **逼尿肌收缩不完全**:患者的持续性尿失禁症状表明,逼尿肌在膀胱活动时未能有效抑制尿液漏出,这可能是因为膀胱颈肌肉松弛。
**结论**:膀胱测量最可能会显示患者有较多的残余尿量,并伴有逼尿肌收缩不完全的情况。<|end▁of▁sentence|>
"""
#问题2测试
inputs2 = tokenizer([prompt_style.format(question_2, "")], return_tensors="pt").to("cuda")
outputs2 = model.generate(input_ids=inputs2.input_ids, max_new_tokens=1200, use_cache=True,)
response2 = tokenizer.batch_decode(outputs2)
print("问题2回复:\n", response2[0].split("### 回复:")[1])
"""
问题2回复:
首先,我需要分析患者的症状和检查结果。患者的主诉是突发胸痛,伴随颈部和左臂放射性疼痛,这提示可能是冠状动脉病变导致的心绞痛或心肌梗死。同时,患者有高胆固醇血症和冠状动脉疾病的历史,这可能与冠状动脉病变有关。
检查结果方面,肌钙蛋白I水平升高,肌钙蛋白I通常用于评估心肌缺血的程度,升高提示心肌可能受累。另外,心动过速可能是由于冠状动脉供血减少导致的心律失常,如冠心病的典型症状。
接下来,我需要确定患者的冠状动脉病变的具体位置。患者有放射性疼痛,尤其是在颈部和左臂,这可能与特定的冠状动脉有关。通常,放射性疼痛可能与前 descending (前降支)、左 descending (左降支)、 superior lateral ( superior lateral) 或 caudate (钙化) 等冠状动脉有关。
考虑到患者的既往病史包括冠状动脉疾病,我需要进一步分析哪个冠状动脉病变最可能引起上述症状。肌钙蛋白I升高可能提示心肌缺血,而心动过速可能与冠状动脉供血不足有关。
结合这些因素,我推测患者的病变可能位于前 descending 或左 descending 冠状动脉。这些支通常位于心脏的左前方,因此病变可能会影响左臂和颈部的供血,导致放射性疼痛和心律失常。此外,肌钙蛋白I的升高可能进一步支持这些区域的病变。
最后,综合患者的主诉、检查结果和冠状动脉病变的历史,最可能受累的冠状动脉是前 descending 冠状动脉或左 descending 冠状动脉。
</think>
根据患者的主诉、检查结果和既往病史,最可能受累的冠状动脉是前 descending 冠状动脉或左 descending 冠状动脉。这些冠状动脉病变可能导致心绞痛、放射性疼痛、心肌缺血和心动过速等症状。<|end▁of▁sentence|>
"""
#模型训练
trainer = SFTTrainer(
model = model,
train_dataset = dataset,
tokenizer = tokenizer,
args = SFTConfig(
dataset_text_field = "text",
max_seq_length = max_seq_length,
dataset_num_proc=2,
per_device_train_batch_size = 2,
gradient_accumulation_steps = 4,
num_train_epochs = 3,
warmup_steps = 5,
#max_steps = 60,
learning_rate=2e-4,
fp16=not is_bfloat16_supported(),
bf16=is_bfloat16_supported(),
logging_steps=10,
optim="adamw_8bit",
weight_decay=0.01,
lr_scheduler_type="linear",
seed=3407,
output_dir="outputs",
),
)
print("tokenizer:\n", tokenizer)
trainer.train()
#模型保存,权重合并
new_model_local = "DeepSeek-R1-Medical"
model.save_pretrained(new_model_local)
tokenizer.save_pretrained(new_model_local)
model.save_pretrained_merged(new_model_local, tokenizer, save_method = "merged_16bit",)
model, tokenizer = FastLanguageModel.from_pretrained(
model_name = "./DeepSeek-R1-Medical",
max_seq_length = max_seq_length,
dtype = dtype,
load_in_4bit = load_in_4bit,
)
print("merged model:\n", model)
"""
model:
Qwen2ForCausalLM(
(model): Qwen2Model(
(embed_tokens): Embedding(152064, 3584, padding_idx=151654)
(layers): ModuleList(
(0-27): 28 x Qwen2DecoderLayer(
(self_attn): Qwen2Attention(
(q_proj): Linear(in_features=3584, out_features=3584, bias=True)
(k_proj): Linear(in_features=3584, out_features=512, bias=True)
(v_proj): Linear(in_features=3584, out_features=512, bias=True)
(o_proj): Linear(in_features=3584, out_features=3584, bias=False)
(rotary_emb): LlamaRotaryEmbedding()
)
(mlp): Qwen2MLP(
(gate_proj): Linear(in_features=3584, out_features=18944, bias=False)
(up_proj): Linear(in_features=3584, out_features=18944, bias=False)
(down_proj): Linear(in_features=18944, out_features=3584, bias=False)
(act_fn): SiLU()
)
(input_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
(post_attention_layernorm): Qwen2RMSNorm((3584,), eps=1e-06)
)
)
(norm): Qwen2RMSNorm((3584,), eps=1e-06)
(rotary_emb): LlamaRotaryEmbedding()
)
(lm_head): Linear(in_features=3584, out_features=152064, bias=False)
)
"""
FastLanguageModel.for_inference(model)
#问题验证
#问题1测试
inputs1 = tokenizer([prompt_style.format(question_1, "")], return_tensors="pt").to("cuda")
outputs1 = model.generate(input_ids=inputs1.input_ids, max_new_tokens=1200, use_cache=True,)
response1 = tokenizer.batch_decode(outputs1)
print("问题1回复:\n", response1[0].split("### 回复:")[1])
"""
问题1回复:
<think>
这位61岁的女性,她一直有在咳嗽或打喷嚏时不自主地失尿的情况,但夜间好像没有问题。这让我想到,她可能在白天活动时的肌肉紧张导致尿液泄漏。这听起来像是膀胱在正常工作,只是她的逼尿肌可能不够有力,导致尿液漏出。
她已经做过妇科检查和Q-tip测试,这让我想到,这些检查应该能帮助我们了解她的膀胱功能。如果逼尿肌不够活跃,尿液可能在膀胱内积聚,但因为没有夜间漏尿,这说明她膀胱的容量似乎没问题。
那么,如果进行膀胱测量,我们可能会看到她的残余尿量是多少。通常,如果逼尿肌不够活跃,她的残余尿量可能较高,因为她可能在膀胱内积聚了一些尿液。
结合她的病史和这些检查,我觉得她的膀胱容量应该是正常的,只是逼尿肌不够活跃导致尿液泄漏。因此,膀胱测量可能会显示她的残余尿量较高,而逼尿肌收缩可能不完全。
总结一下,我觉得她的膀胱容量正常,但因为逼尿肌不够活跃,她有不自主漏尿的情况。膀胱测量可能显示残余尿量较高,逼尿肌收缩不完全。这似乎解释了她的症状。
</think>
根据这位61岁女性的症状和病史,她可能在白天由于肌肉紧张导致不自主漏尿,但夜间没有漏尿。这提示她的膀胱容量可能正常,但逼尿肌功能不完全,导致尿液在膀胱内积聚,从而引发尿液泄漏。
在进行膀胱测量时,我们可能会发现她的残余尿量较高,因为尿液在膀胱内没有被完全排出。而逼尿肌收缩可能不完全,这进一步支持了她不自主漏尿的原因。因此,膀胱测量最可能会显示她的残余尿量较高,同时逼尿肌收缩可能不完全。<|end▁of▁sentence|>
"""
#问题2测试
inputs2 = tokenizer([prompt_style.format(question_2, "")], return_tensors="pt").to("cuda")
outputs2 = model.generate(input_ids=inputs2.input_ids, max_new_tokens=1200, use_cache=True,)
response2 = tokenizer.batch_decode(outputs2)
print("问题2回复:\n", response2[0].split("### 回复:")[1])
"""
问题2回复:
<think>
哦,这位患者突然出现胸痛,而且痛感还放射到颈部和左臂,这听起来很严重。胸痛和放射痛通常和心脏有关,尤其是冠状动脉的问题。
嗯,他有高胆固醇血症和冠状动脉疾病史,这说明他的心血管健康不太好。再加上肌钙蛋白I水平升高,这通常提示有心肌损伤或者心肌炎。
心肌炎常常和某种病毒有关,比如麻疹或腮腺炎。这些感染可能会导致心肌细胞损伤,从而引起心绞痛和肌钙蛋白上升。
另外,他的心率也快了。心率加快可能是因为心肌缺血,这和冠心病有关,特别是心肌缺血性病变。
考虑到这些因素,可能是因为心肌炎导致的冠状动脉病变。通常这种情况影响的是冠状动脉的左前降支,因为它与心脏的左心室供血密切相关。
哦,左前降支受累的话,会导致心肌缺血,从而解释心率加快和肌钙蛋白上升。
看来,综合这些信息,最有可能的是左前降支被影响了。嗯,这个结论和症状表现都吻合,应该是对的。
</think>
根据患者的临床表现和既往病史,最可能受累的冠状动脉是左前降支。患者突然出现胸痛,放射到颈部和左臂,提示可能有心肌损伤或心肌炎。肌钙蛋白I水平升高和心动过速也支持这种诊断。心肌炎常与麻疹或腮腺炎等病毒感染有关,这些感染可能引发心肌细胞损伤,并导致冠状动脉左前降支受累,导致心肌缺血和心率加快。因此,综合考虑,左前降支受累是最可能的诊断。<|end▁of▁sentence|>
"""
问题1标准答案:
在这种压力性尿失禁的情况下,膀胱测压检查(cystometry)最可能显示正常的排尿后残余尿量,因为压力性尿失禁通常不会影响膀胱排空功能。此外,由于压力性尿失禁主要与身体用力有关,而不是膀胱过度活动症(OAB),因此在测试过程中不太可能观察到逼尿肌的非自主收缩。
问题2标准答案:
根据患者表现出的突然胸痛并放射至颈部和左臂,结合其有高胆固醇血症和冠状动脉疾病的病史,肌钙蛋白升高和心动过速,临床症状强烈提示左前降支(LAD)动脉受累。该动脉通常是引发此类症状的罪魁祸首,因为它供应了心脏的大部分区域。放射性疼痛和肌钙蛋白升高的组合表明心肌受损,这使得LAD成为最可能的致病动脉。然而,在没有进一步的诊断检查(如心电图)的情况下,最终的确诊仍需等待确认。
从训练前后的模型对同样医学问题的回答可以看出,虽然只训练了3个epoch,但是效果还是不错的。结合标准答案,可以看出训练后的模型回答的都是正确的,而原始模型回答的却是不对的。
参数解析:
SFTTrainer 部分
| 参数 | 作用 |
| trl(Transformer Reinforcement Learning) | Hugging Face 旗下的 trl 库,提供监督微调(SFT) 和强化学习(RLHF)相关的功能 |
| model=model | 指定需要进行微调的 预训练模型 |
| tokenizer=tokenizer | 指定 分词器,用于处理文本数据 |
| train_dataset=dataset | 传入 训练数据集 |
| dataset_text field="text" | 指定数据集中哪一列包含训练文本(在formatting_prompts func里处理) |
| dataset_text_field="text" | 最大序列长度,控制输入文本的最大 Token 数量 |
| dataset_num_proc=2 | 最大序列长度,控制输入文本的最大 Token 数量 |
TrainingArguments 部分
| 参数 | 作用 |
| per_device_train_batch_size=2 | 每个 GPU/设备 的训练批量大小(较小值适合大模型) |
| gradient_accumulation_steps=4 | 梯度累积步数(相当于batch size=2x4=8) |
| warmup_steps=5 | 预热步数(初始阶段学习率较低,然后逐步升高) |
| max_steps=60 | 最大训练步数(控制训练的总步数,此处总共约消耗60*8=480条数据) |
| learning_rate=2e-4 | 学习率(2e-4=0.0002,控制权重更新幅度) |
| fp16=not is_bfloat16_supported() | 如果 GPU不支持bfloat16,则使用fp16(16位浮点数) |
| bf16=is_bfloat16_supported() | 如果 GPU 支持bfloat16,则启用bfloat16(训练更稳定) |
| logging_steps=10 | 每 10 步记录一次训练日志 |
| optim="'adamw_8bit" | 使用adamw 8bit(8-bit AdamW优化器)减少显存占用 |
| weight_decay=0.01 | 权重衰减(L2正则化),防止过拟合 |
| lr_scheduler type="linear" | 权重衰减(L2正则化),防止过拟合 |
| seed=3407 | 随机种子(保证实验结果可复现) |
| output dir="outputs' | 训练结果的输出目录 |
参考链接:
GitHub - unslothai/unsloth: Finetune Llama 3.3, DeepSeek-R1 & Reasoning LLMs 2x faster with 70% less memory! 🦥
从零开始的DeepSeek微调训练实战(SFT)