Transformer原理硬核解析:Self-Attention与位置编码
🔍 Transformer 是自然语言处理(NLP)的“革命性”模型,彻底取代了RNN/CNN的序列建模方式。其核心在于Self-Attention机制和位置编码设计。本文用最直观的方式带你彻底搞懂这两大核心原理!
📌 Self-Attention:为什么能“看见全局”?
🌟 核心思想
Self-Attention(自注意力)让每个词都能直接与序列中所有其他词交互,捕捉长距离依赖关系。与RNN的“顺序处理”不同,Self-Attention通过矩阵并行计算实现高效全局建模。
🔥 计算步骤
-
输入向量:将输入词嵌入(Embedding)为向量
 (n为序列长度,d为维度)。
(n为序列长度,d为维度)。 -
生成Q/K/V:通过线性变换得到Query、Key、Value矩阵:
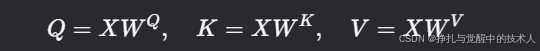
-
计算注意力分数:
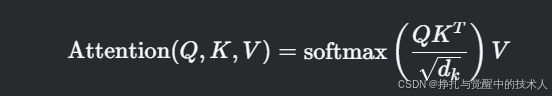
-
缩放因子
 :防止点积结果过大导致梯度消失。
:防止点积结果过大导致梯度消失。
-
-
多头注意力(Multi-Head):
-
将Q/K/V拆分为h个头,并行计算后拼接结果,增强模型对不同语义子空间的捕捉能力。
-
# Self-Attention代码实现(简化版PyTorch)
import torch
import torch.nn as nn
class SelfAttention(nn.Module):
def __init__(self, embed_size, heads):
super(SelfAttention, self).__init__()
self.embed_size = embed_size
self.heads = heads
self.head_dim = embed_size // heads
# 定义Q/K/V的线性变换
self.Wq = nn.Linear(embed_size, embed_size)
self.Wk = nn.Linear(embed_size, embed_size)
self.Wv = nn.Linear(embed_size, embed_size)
self.fc_out = nn.Linear(embed_size, embed_size)
def forward(self, x):
batch_size, seq_len, _ = x.shape
# 生成Q/K/V
Q = self.Wq(x).view(batch_size, seq_len, self.heads, self.head_dim)
K = self.Wk(x).view(batch_size, seq_len, self.heads, self.head_dim)
V = self.Wv(x).view(batch_size, seq_len, self.heads, self.head_dim)
# 计算注意力分数
energy = torch.einsum("bqhd,bkhd->bhqk", [Q, K]) # 多维矩阵乘法
energy = energy / (self.head_dim ** 0.5)
attention = torch.softmax(energy, dim=-1)
# 加权求和
out = torch.einsum("bhqk,bkhd->bqhd", [attention, V])
out = out.reshape(batch_size, seq_len, self.embed_size)
return self.fc_out(out)📊 Self-Attention vs CNN/RNN
| 特性 | Self-Attention | RNN | CNN |
|---|---|---|---|
| 长距离依赖 | ✅ 直接全局交互 | ❌ 逐步传递 | ❌ 局部感受野 |
| 并行计算 | ✅ 矩阵运算 | ❌ 序列依赖 | ✅ 卷积核并行 |
| 计算复杂度 | O(n^2)O(n2) | O(n)O(n) | O(k \cdot n)O(k⋅n) |
📌 位置编码(Positional Encoding):如何表示序列顺序?
🌟 为什么需要位置编码?
Self-Attention本身是位置无关的(词袋模型),需额外注入位置信息以区分序列顺序。
🔥 两种主流位置编码方法
-
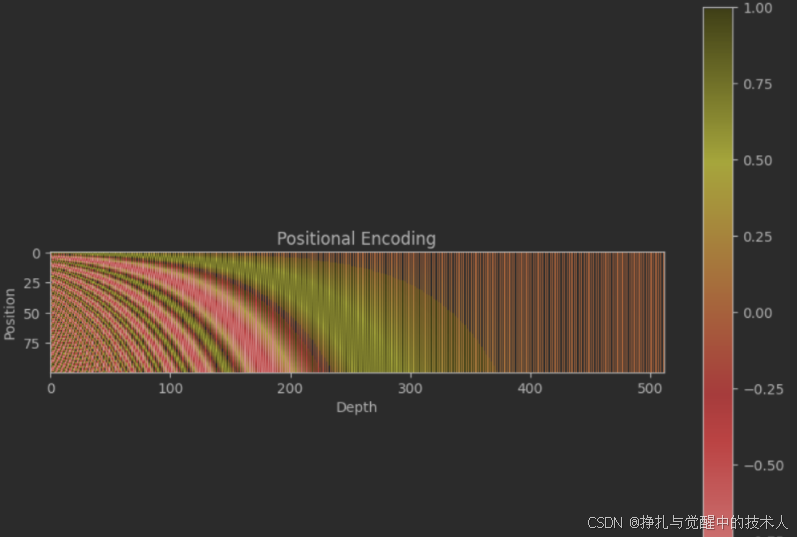
正弦/余弦编码(Sinusoidal PE)
-
公式:
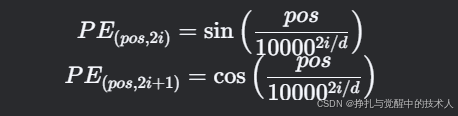
-
特点:
-
无需学习,固定编码。
-
可泛化到任意长度序列。
-
-
-
可学习的位置编码(Learned PE)
-
将位置编码作为可训练参数(如BERT)。
-
优点:灵活适应任务需求;缺点:无法处理超长序列。
-
💻 位置编码代码示例
# 正弦位置编码实现
import torch
def sinusoidal_position_encoding(seq_len, d_model):
position = torch.arange(seq_len).unsqueeze(1)
div_term = torch.exp(torch.arange(0, d_model, 2) * (-math.log(10000.0) / d_model))
pe = torch.zeros(seq_len, d_model)
pe[:, 0::2] = torch.sin(position * div_term)
pe[:, 1::2] = torch.cos(position * div_term)
return pe
# 使用示例
d_model = 512
max_len = 100
pe = sinusoidal_position_encoding(max_len, d_model) # shape: (100, 512)📌 Transformer整体架构回顾
-
编码器(Encoder):
-
由多个Encoder Layer堆叠,每个Layer包含:
-
Multi-Head Self-Attention
-
Feed Forward Network(FFN)
-
残差连接 + LayerNorm
-
-
-
解码器(Decoder):
-
在Encoder基础上增加Cross-Attention层(关注Encoder输出)。
-
使用Masked Self-Attention防止未来信息泄露。
-
⚠️ 关键问题与注意事项
-
计算复杂度高:序列长度n较大时,O(n^2)O(n2)复杂度导致资源消耗激增(需优化如稀疏注意力)。
-
位置编码选择:
-
短序列任务可用可学习编码;长序列推荐正弦编码。
-
-
多头注意力头数:通常设置为8-16头,头数过多可能引发过拟合。
🌟 总结
-
Self-Attention:通过Q/K/V矩阵实现全局交互,是Transformer的“灵魂”。
-
位置编码:弥补Self-Attention的位置感知缺陷,决定模型对序列顺序的敏感性。
-
应用场景:几乎所有NLP任务(如BERT、GPT)、多模态模型(CLIP)、语音识别等。