微软PIKE-RAG:多层次多粒度体系化智能化的知识库构建方案
微软PIKE-RAG:多层次多粒度体系化智能化知识库构建方案
笔者注:PIKE-RAG是微软亚洲研究院的一个知识库设计和构建工作,高度体系化,里面拆解问题、单点能力设计、整体流程设计等各方面都有比较大的借鉴价值,因而写这篇文章记录一下
作者认为传统的RAG大致有3个方面的问题:
- 多样化的数据源(Knowledge source diversity):因而也需要知识库具备存储多样化数据(即多模态)和推理的能力
- 特定领域泛化缺陷(Domain specialization deficit):知识库对问题的关键部分会给出不准确或者不完整的知识,导致最终回复效果违反基本原理
- 架构同质化(One-size-fits-all):通过同一套技术框架解决不同类型问题,但RAG的真实场景下需要多样化的能力,特别是提取、理解、组织领域知识和基本原理的能力
笔者注:原文中的rationale本意指的是“基本原理”、“根本原因”的意思,论文的上下文中,知识库可以提供召回的原因其实意味着它在通过推理选出要找回的内容,推理过程文本构成了rationale。
故而研究团队提出了specialized Knowledge and Rationale Augmented Generation (PIKE-RAG),名字略显复杂,意思是知识进行特殊处理且增强了基本原理的生成模式。
问题分类定义
作者梳理了影响RAG任务的关键因素(笔者表示完全赞同):
- 知识的相关性和完整性(Relevance and Completeness of Knowledge)
- 知识提取的复杂度(Complexity of Knowledge Extraction)
- 理解和推理的深度(Depth of Understanding and Reasoning)
- 知识蒸馏的有效性(Effectiveness of Knowledge Utilization)
笔者注:如果知识蒸馏让比较难理解的话,可以等价替换为知识总结,意思大致相同。
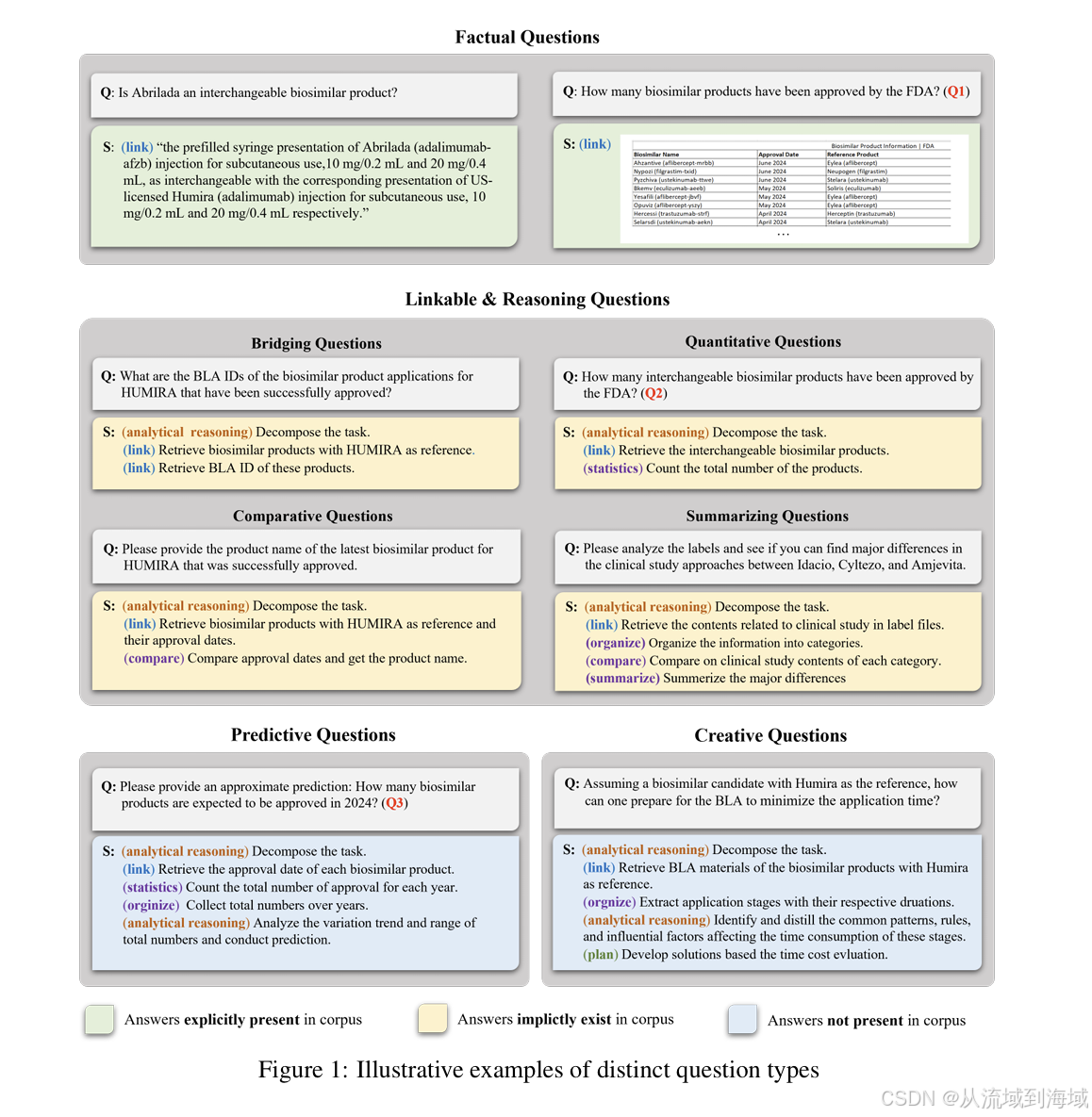
如上图,研究团队首先将RAG预期要解决的问题分为以下4类,其中联系与推理问题还可以继续向下细分:
- 事实问题(Factual Questions)
- 联系与推理问题(Linkable-Reasoning Questions)
- 关联性问题(Bridging Questions)
- 定量问题(Quantitative Questions)
- 比较问题 (Comparative Questions)
- 总结问题(Summarizing Questions)
- 预测性问题(Predictive Questions)
- 创造性问题(Creative Questions)
四类问题中,事实问题在知识库语料显式存在答案;联系与推理问题在语料库中隐式存在答案,需要将检索到的显式知识关联一下才能得出答案;预测性问题和创造性问题则在语料库中不存在答案,其中预测性问题的求解需要将检索内容收集、组织成结构化知识然后进一步分析得出答案,而创造性问题的求解需要知识库提供的事实性信息足够可用,且模型能够理解其中潜在的基本原理和规则,才能具备必须创造性思维。
由此可见,四类问题的难度是逐步上升的,难度每上升一个等级,需要的知识库的能力同时也需要随之跃上一个等级。
知识库成熟度分级
因而作者将知识库的能力(或者叫完备性成熟度都可以)分为了L1~L4四个等级,知识库的等级越高,能在解决低等级问题的同时,解决更加复杂的问题,如下图:

- L1级别:L1知识库需要具备提供准确且可靠的用于回答事实问题的知识,作为知识检索能力的坚实基础。
- L2级别:L2知识库需要同时能对事实问题和关联与推理问题两个难度的问题提供准确且可靠的信息,以支持更复杂的多跳查询和推理任务。
- L3级别:L3级别知识库需要进一步增强提供推理性预测能力的知识以解决预测性问题,同时具备L1和L2知识库的能力。
- L4级别:L4级别知识库需要能够提供推理性良好的规划和求解思路的能力以解决创造性问题,同时具备L1~L3知识库的能力。
接下来,我们将按照成熟度由低到高逐级进行介绍。
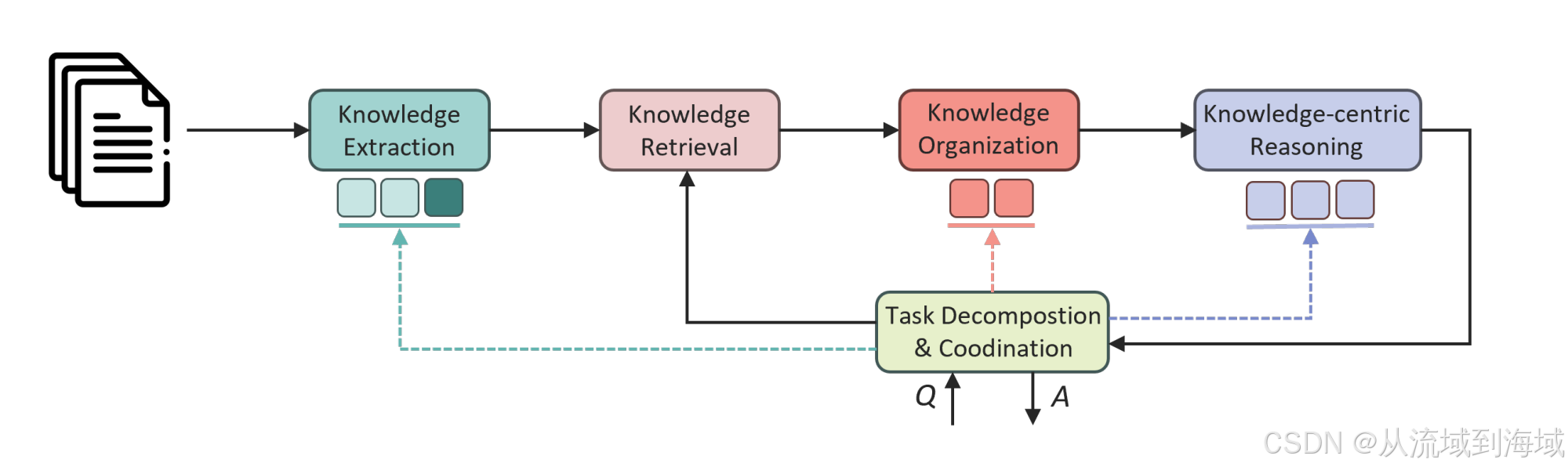
PIKE核心架构总览
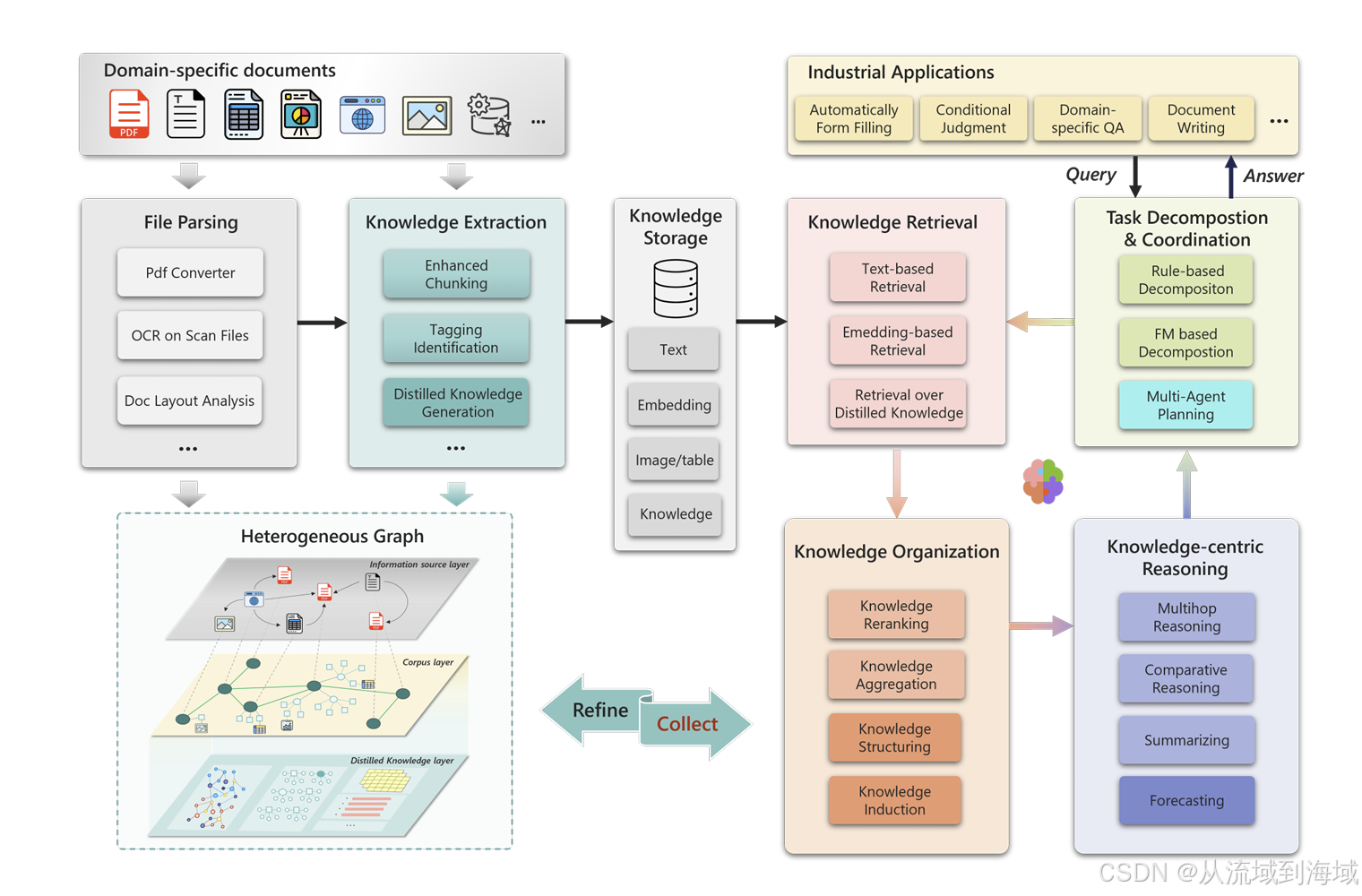
如图,PIKE是一个具备知识检索、知识组织、任务拆分和协调、知识中心推理等多重能力的高度体系化的知识库。该知识库的核心组件包括:文件解析、知识提取、知识检索、知识组织、知识推理等组件,以这些组件为基础,进一步引入LLM设计了任务拆分和协调组件和多agent规划组件。
L1~L4级别知识面临的挑战和需要的组件如下图,不再一一赘述,有疑问的读者可以在评论区留言:

下面逐级介绍不同成熟度的知识库。
L0:知识库构建(Level-0: Knowledge Base Construction)
文件解析
文件解析组件是一个具备读取不同类型文件能力的file reader,支持从多种知识来源中提取不同类型的信息(文本、图标、图片),并且无缝整合在一起,工程能力具体可以参考源码。
知识组织
文中多次提到知识组织,每次组织的形式有所不同,读者可能需要多点时间去理解区分
作者将知识库设计为多层次带连接关系的网络结构,相当于是一个分层次的知识图谱:
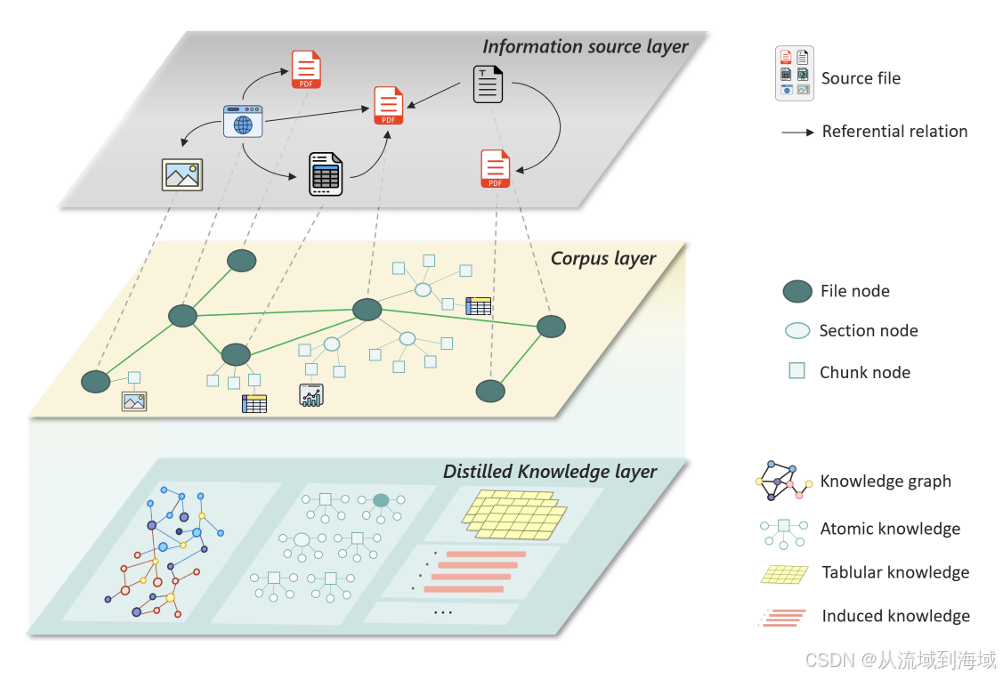
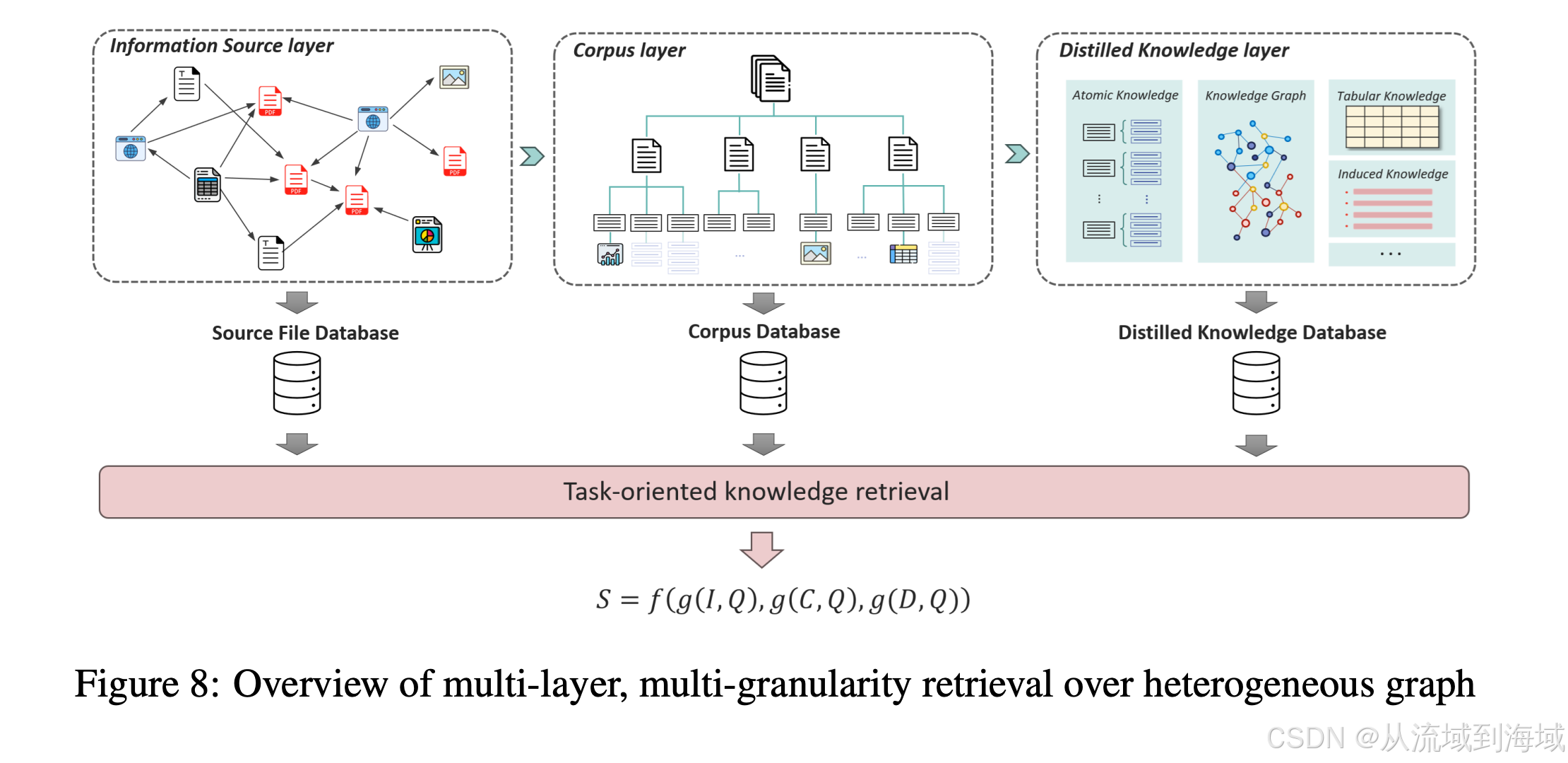
- 信息源层(Information Resource Layer)
信息源层将不同类型的信息源组织成节点,通过连接它们的边来刻画彼此之间的参照关系,这种结构可以支持参照引用,并且将知识上下文划,以建立在多种信源上进行推理的基础。 - 语料层(Corpus Layer)
语料层以章节或者块的形式组织解析好的信息同时保持原有的层次结构,诸如表格和图片之类的多模态内容会由大语言模型进行总结,并作为整合到文本块中以支持多模态信息检索。本层能够支持对知识进行不同粒度的提取,并提供在不同类型的内容之间进行准确的语义分块和检索的能力。 - 蒸馏知识层(Distilled Knowledge Layer)
蒸馏知识层进一步将知识结构化,包括知识图谱,原子知识和表格知识:- 知识图谱(Knowledge graph):基于LLM从语料文本中抽取实体和彼此之间的关系,建立知识图谱。
- 原子知识(Atomic knowledge):将语料文本划分为原子语句(atomic statements),可以认为原子语句是知识的基本单位,将原子语句和语料节点的关联关系组合起来,构建了原子知识(图谱)。
- 表格知识(Tabular knowledge):从语料文本里面提取存在特殊类型和关系的实体对构建表格知识。这些实体对也被看作是知识单位,并且组合起来构成了表格知识(图谱)
L1:聚焦事实问题的RAG系统(Level-1: Factual Question focused RAG System)

基于L0的基础之上,L1知识库引入了知识提取和知识组织来实现检索和生成能力。大量专业术语和黑话(alias)和不能进行推理的的文本块对文本块的检索产生了很大影响,它们扰乱了语义关联性并引入了噪音干扰。
L1知识库的架构如上图,该架构可以通过扩展添加任务分解、协调、(初始阶段)知识组织等组件,确保它可以高效应对更复杂的查询(queries)。
增强型文本块
研究团队设计了一个循环式的文本分割算法将大文本内容分割为更小的可管理的文本块,同时保留块的上下文并高效生成文本块摘要。在上图的处理流程中,文本块主要用于实现2个目标:
- 文本块作为知识的单位,可被向量化之后存在库内用于检索
- 作为进一步提取和摘要的知识源
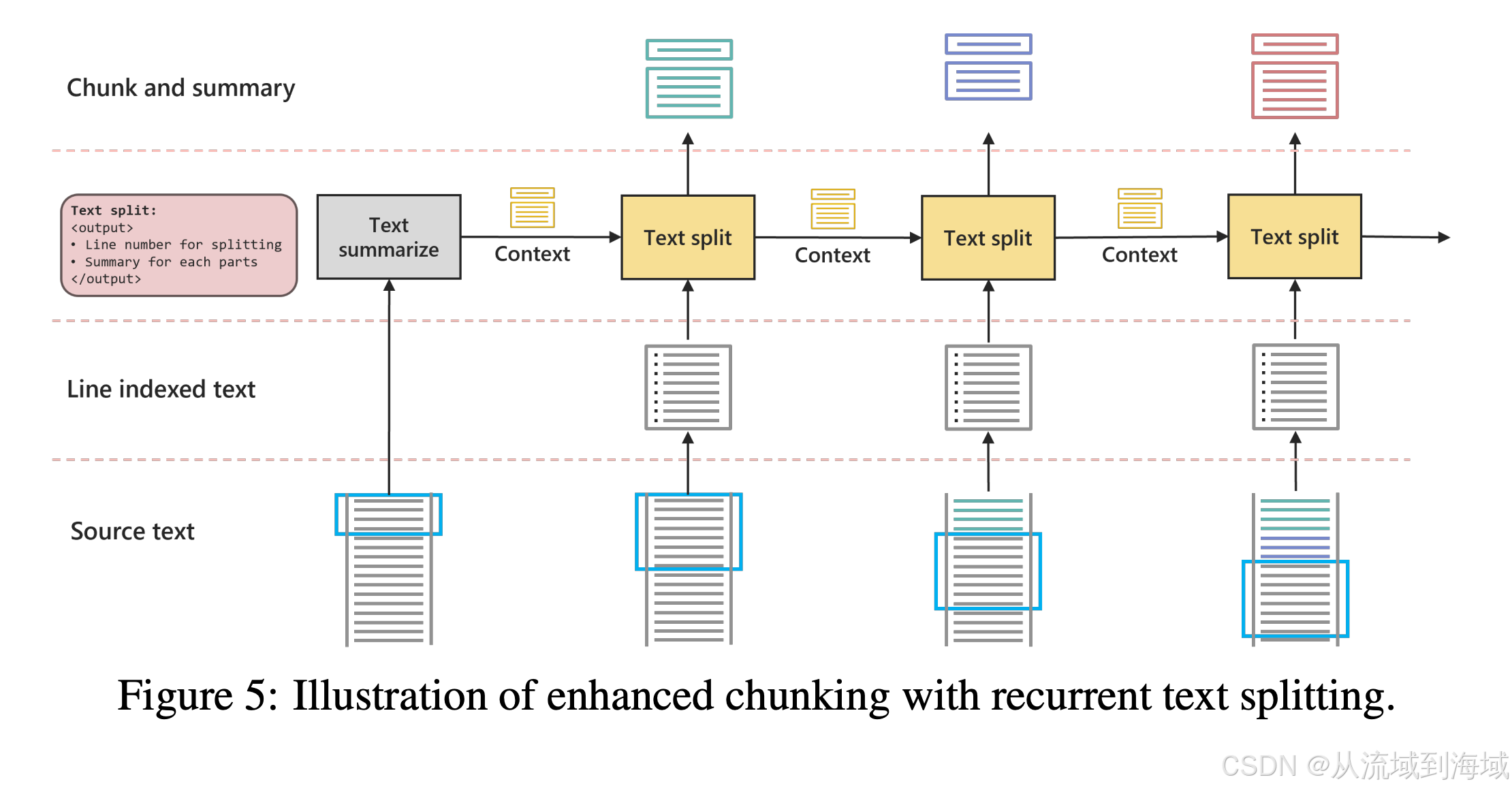
算法处理流程见上图,简述如下:
(查阅源码得知,每个文本块,chunk_size=4000字,overlap=200字,所以是先按这样的大小切分,再执行下面的算法)
首次迭代生成原始块,包括分割标记用的的行号和每个被分割部分的摘要,并结果文本作为上下文继续传递下去,按输出行号对文本进行分割,每个被分割的块使用初始块的上下文和自己的全部文本内容作为输入继续生成上下文,如此循环下次直至所有的文本块都不再可以划分。
笔者注:按4000字切分文档没有并考虑语义关系,但循环文本分割算法因为有上一次切分的上下文所以在一定程度考虑语义关系,且正如原文所述,可以依据文本内容和结果使用动态窗口切分块。除此之外,不断传递的山下文也维持了块与块之间的内在叙事关联性。
自动打标
为解决领域差距问题(domain gap issue),作者提出了基于LLM的自动打标模块来减小查询文本和原文档之间的差距,产生的标签有两种类型:
- 基于语料文本提取后语义标签得到的语料标签集
- 查询本身和查询召回内容均提取语音标签后,通过匹配组合成对(pair)的标签对集
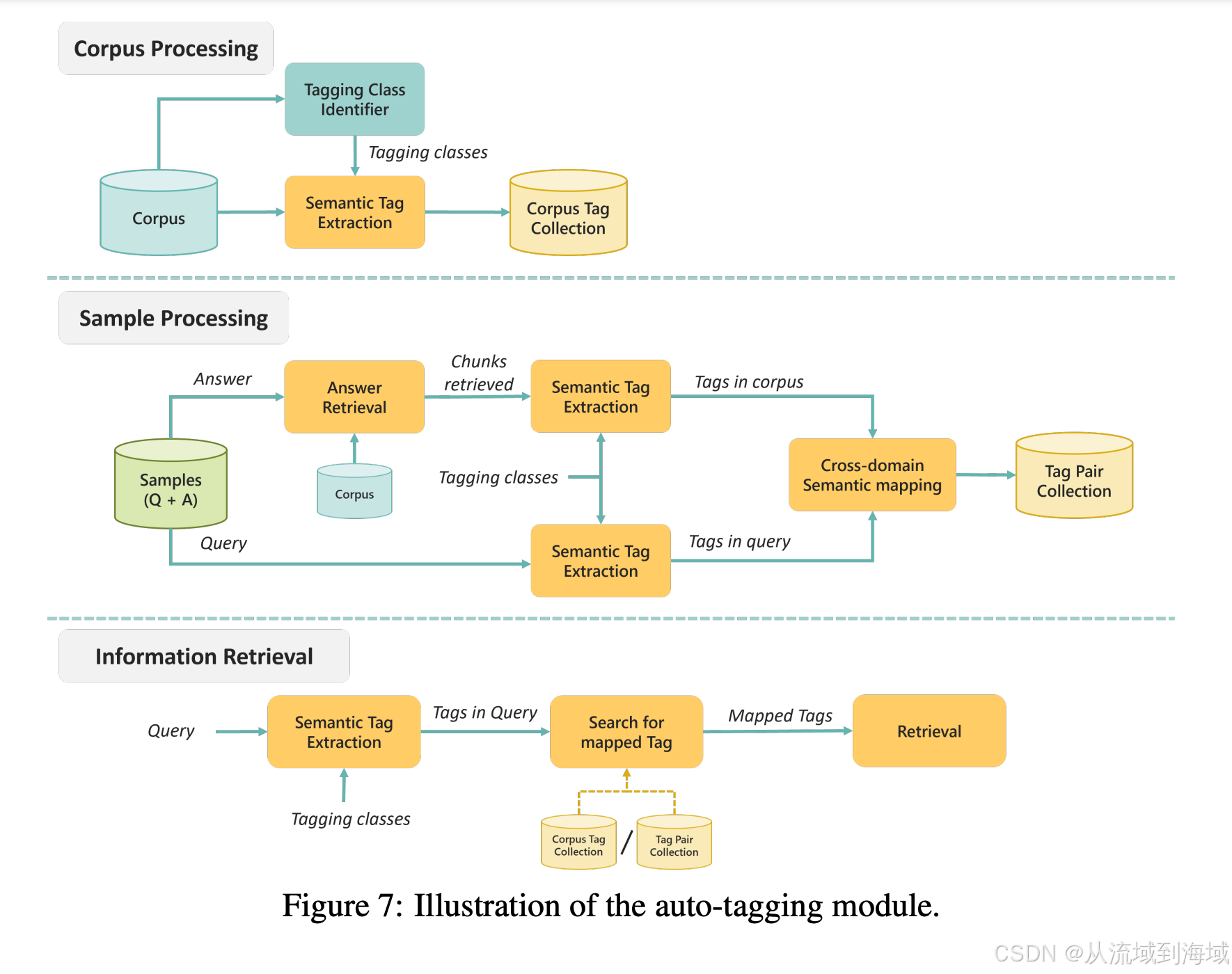
语义标签是经由LLM识别语料块的核心特征生成的,总结这些特征之后产生了分类名称,将分类名称作为标签使用,为此专门设计了提示词。
自动打标模块产生了复杂的领域特定标签集,QA之间成员的标签对建立了标签之间的映射关系,这些都可以在处理查询时召回,进一部分通过语料标签或者标签对中的语料标签来完成检索。
多粒度检索
L1知识库可以实现多粒度检索,从不同层的知识库召回内容后计算相似度,在聚合3层知识库的相似度结果计算一个最终的相似度。
L2:聚焦关联与推理问题的RAG系统(Level-2: Linkable and Reasoning Question focused RAG System)
L2知识库在L1的基础上,进一步引入了以知识为中心的推理和任务分解&协调组件,如下图:
知识原子化
作者认为解决一个特定的任务只需要全部知识的一个子集,为了对齐查询和知识之间的粒度,提出了知识原子化模块。该模块的主要作用是给定一个文本块,尽可能生成关于该文本块的问题,作为原子问题,进而将原子问题作为文本块的标签使用。
(笔者注:通过预先生产可能的问题,以提升真实查询和知识的匹配程度)
知识感知任务分解
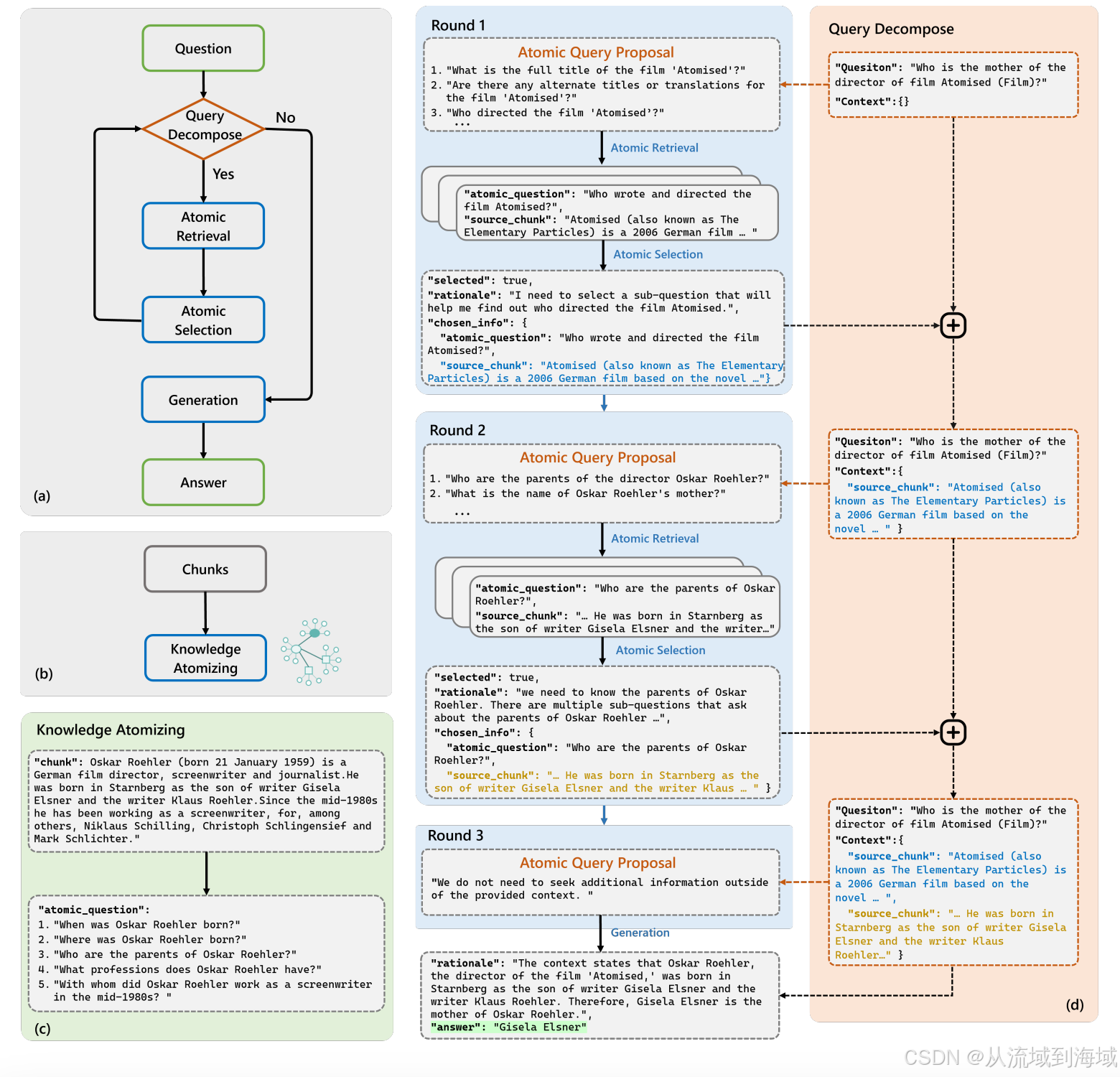
将查询内容分解为多个原子查询,每个原子查询在知识库中做召回构成原子提案(候选集),然后在原子提案中选取完成任务需要的原子查询继续召回,如此迭代多轮,直到所有需要的知识都被查询得到,生成最终回归结果。
(笔者注:知识->原子问题,查询->原子查询,原子问题和原子查询处在大致对等的维度,从而提升了能在知识库查询到相关知识的概率)
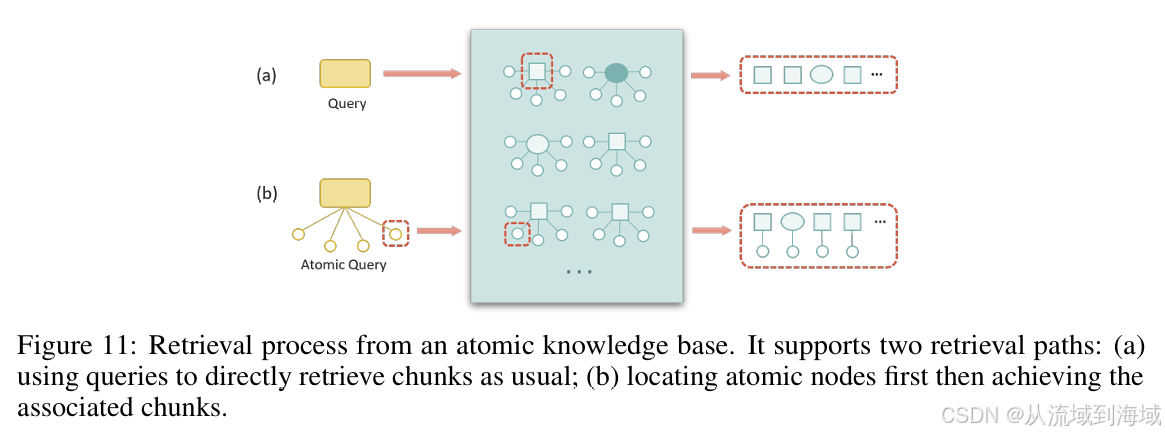
知识原子化之后支持2条查询路径:(1) 原有的直接查询块;(2) 通过原子查询定位到原子问题,再取到相应的块。
下图提供了一个具体的例子:
知识感知任务分解器训练(Knowledge-Aware Task Decomposer Training)
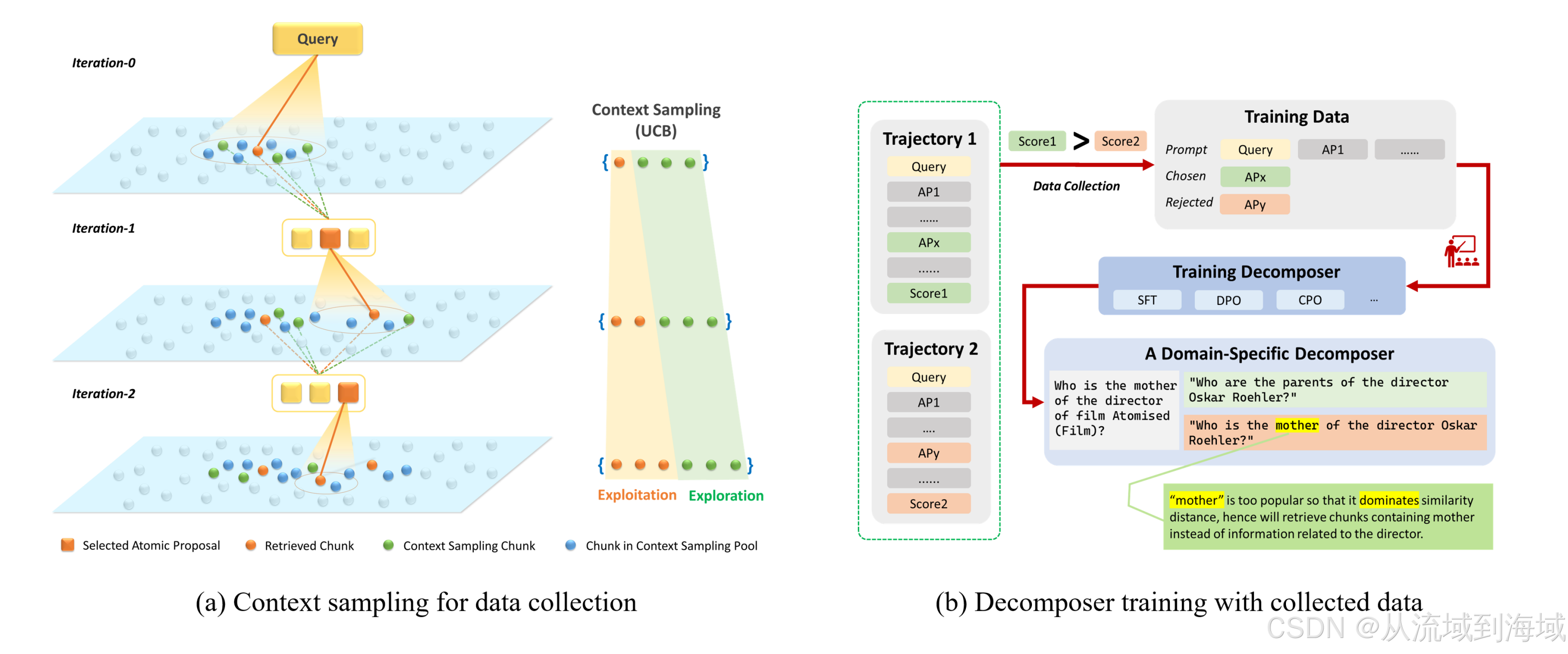
知识感知任务分解要求具备一定的智能,因而研究团队将该组件设计为可训练的组件。通过下图所示的流程收集数据并进行训练,训练的方法包括深度学习的SFT、强化学习的DPO、CPO等。
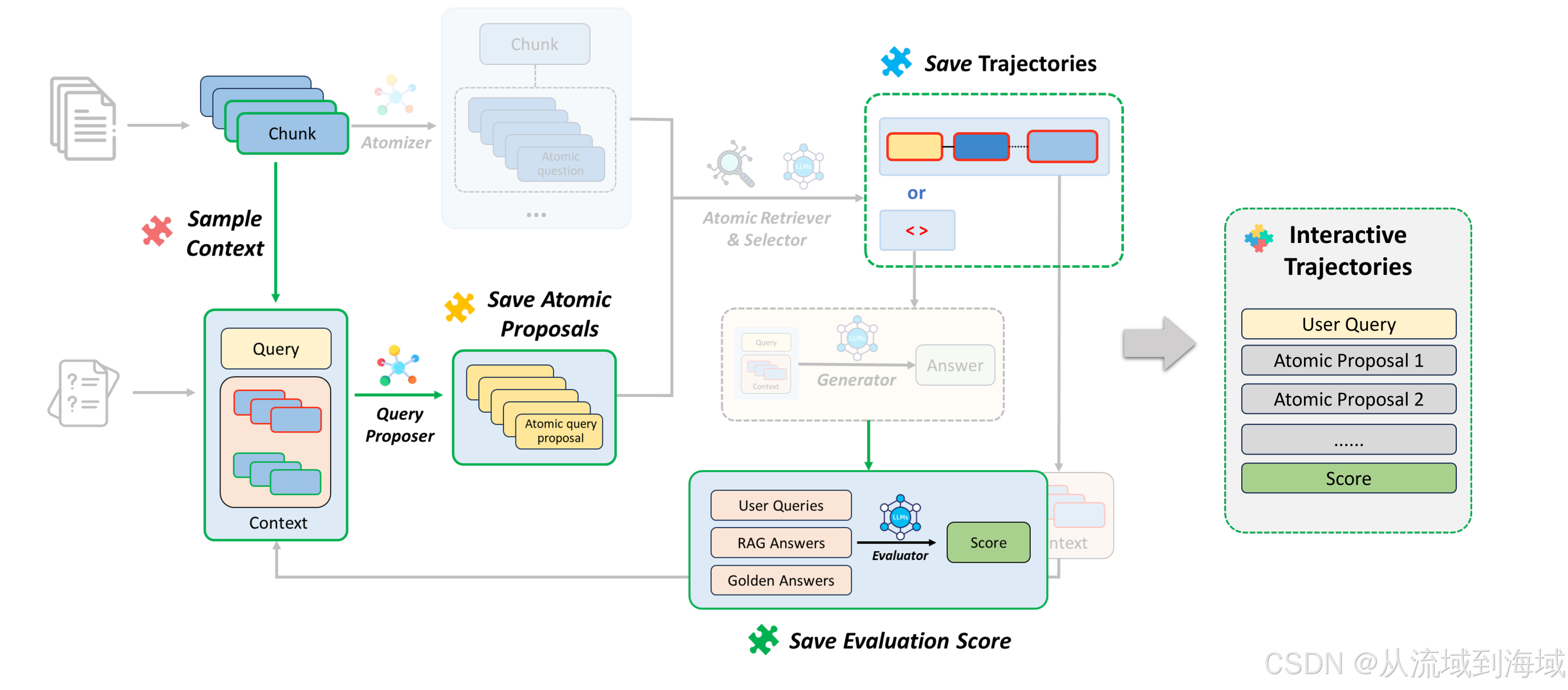
中间有一步是Evaluator根据正确答案和查询结果的原子打分,最终用户查询、原子提案(候选集)、得分三者组成了训练数据。
L3:聚焦预测性问题的RAG系统(Level-3: Predictive Question focused RAG System)
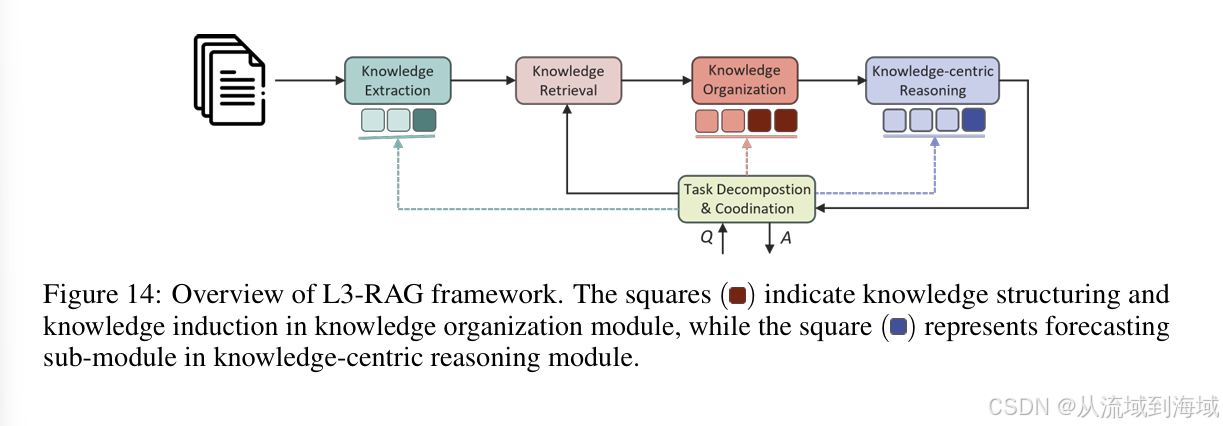
L3知识库相较于L2知识库:
- 知识组织组件中添加了知识归纳子组件
知识结构化组件将遵循任务分解模块组件的指令来收集和组织相关知识,知识归纳子组件进一步将这些知识进行分类,使用分类后的统计数据进行分析和预测。 - 知识中心推理组件中添加预测子组件
预测子组件使得知识库可以基于输入查询和组织好的知识来推断结果,它不仅使得系统可以基于历史知识生成答案,也可以产生映射,,以为复杂的查询提供更健壮更动态的回复。
L4:聚焦创造性问题的RAG系统(Level-4: Creative Question focused RAG System)
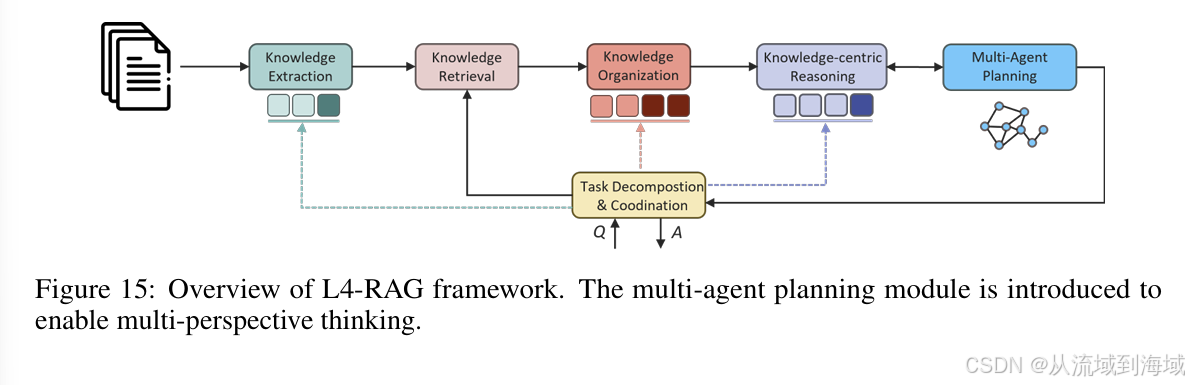
L4知识库相较于L3知识库增加了多agent规划组件,使得整个系统具备多视角思维能力。
作者认为创造性问题的难点在于召回知识后需要从中提取连贯的逻辑原理,才能指导多重因素下的复杂推理流程,同时能够评估产生回复的数量,开放性问题的数量。
多agent的每一个agent都贡献了独特的视角和推理策略,通过这些agent的并行运行,来模拟生成复杂连贯解法的多样性思考过程。这样的多agent架构支持不同推理路径的并行处理和汇总过程,以高效管理复杂问题时的推理。
通过模拟不同视角,L4知识库增强了应对创造性问题的能力,并且能够生成创新想法而不是预设的解法。多agent的协同输出不仅丰富了推理过程,也提供给用户一个更综合的视角,培养创造性思维,产生应对复杂问题的创新解法。
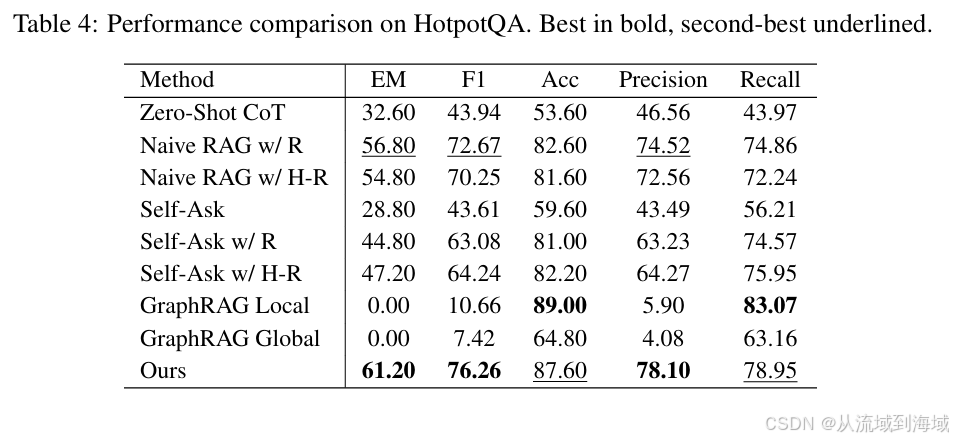
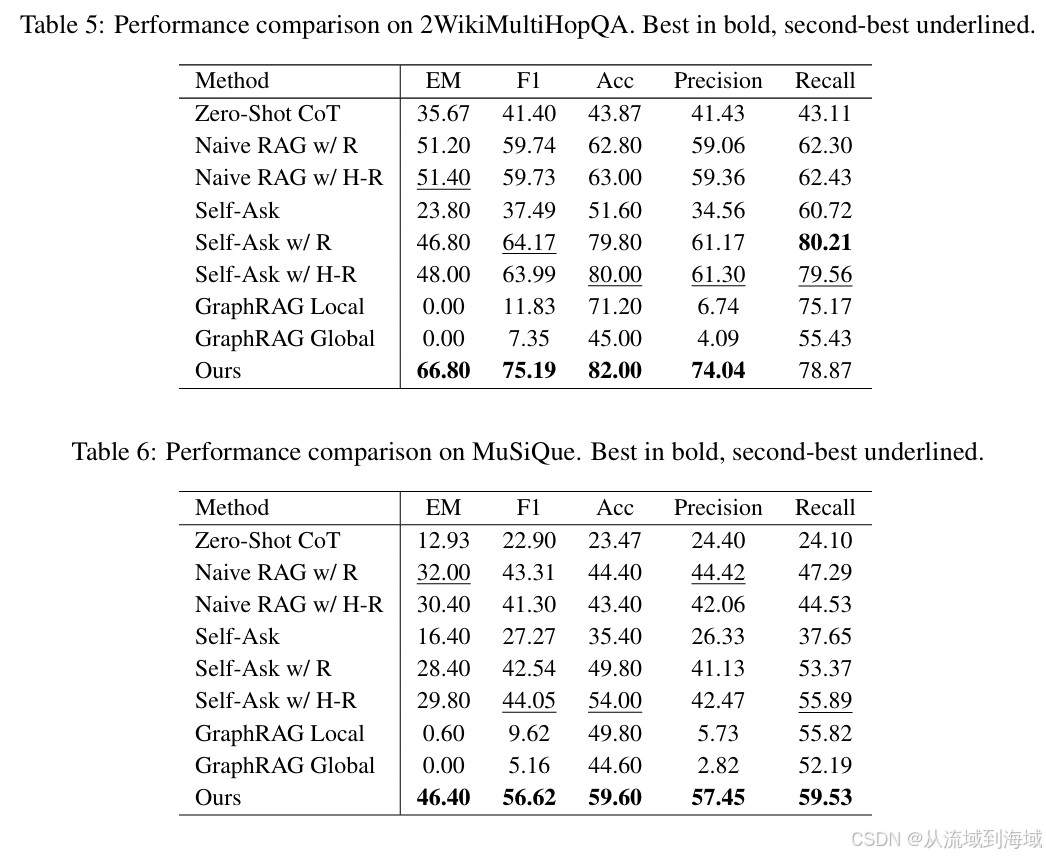
效果实验
研究团队在多个QA数据集上对比了本方案知识库和传统知识库的结果指标,几乎全部都明显领先。这么体系化的方案自然能够产生原有RAG系统更好的效果,贴表如下,不再赘述:
参考文献
- PIKE-RAG: sPecIalized KnowledgE and RationaleAugmented Generation
- 项目地址:https://github.com/microsoft/PIKE-RAG/tree/main/pikerag