学习周报二十二
文章目录
- 摘要
- abstract
- 一、深度学习
- 1.2 无监督学习
- 1.1 聚类算法——K-Means
- 1.2.1 梯度下降、成本函数
- 1.2.2 初始化K-Means
- 1.2.3 选择聚类个数K
- 二、CNN
- 2.1 CIFAR-10运行结果
- 2.2 根据任务训练
- 总结
摘要
本周继续学习深度学习,并实践。学习了深度学习的无监督学习定义,聚类算法中的K-Means;在CNN学习实践中,根据一些任务要求训练模型。
abstract
This week, I continued studying deep learning and putting it into practice. I learned about the definition of unsupervised learning in deep learning and the K-Means clustering algorithm. In the CNN practice, I trained models according to the requirements of certain tasks.
一、深度学习
1.2 无监督学习
无监督学习与监督学习的对比在于,监督学习会同时给出未知x,和标签y,在一定量的数据集合上,找出x与y的相关函数,以便训练预测出新的x出现时,y的值;无监督学习只会给出x,一大堆数据,然后根据函数(算法)找出某一些数据共同具有的特征,将他们划分到一起称为一种模式或者说结构。
包含两种任务:聚类和降维。
聚类:将数据集中的样本划分为若干个通常不相交的子集(称为“簇”),每个簇内部的样本在某种意义上是彼此相似的。
降维:在保留数据集中大部分重要信息(如结构、方差)的同时,将高维空间中的数据映射到低维空间。目的是为了数据可视化、去除噪声或为后续任务压缩数据。
同时,关联规则学习(如购物篮分析)和生成模型(如GANs,通过学习无标签数据的分布来生成新数据)属于无监督学习的范畴。
1.1 聚类算法——K-Means
假设选择两个聚簇点,随即放置,在数据上找出分别距离着两个聚簇点位置较近的数据点,将数据分成两类,然后计算数据的平均最短距离点,将两个聚簇点移动到那个位置,然后重新划分数据到两个聚簇点的分类(根据新的位置距离),重复下去。
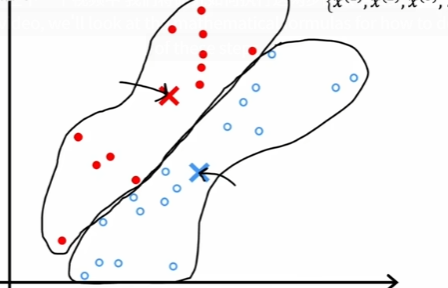
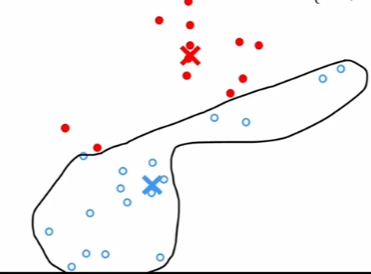
对数据进行聚簇点选择时,首先聚簇点的维度需要与数据相同,比如说数据时二维包含横纵坐标,那么聚簇点同样是二维的,三维数据对应三维聚簇点。其次,随机选择 K 个点作为初始的聚类中心,K 值的选择通常很困难,在训练中,如果训练的过程中出现某些聚簇点没有距离近的数据点,则删掉。在计算中,各个数据点的横坐标相加平均,纵坐标相加平均(二维数据,三维同理),就得到更新的聚簇点位置坐标。
1.2.1 梯度下降、成本函数
xix^{i}xi代表是数据中第i个数据。
c(i)c^{(i)}c(i)代表第i个数据的索引,c10c^{10}c10得出的结果表示的是第10个数据对应的聚簇点位置=μc(i)\mu_{c^{(i)}}μc(i)。
μk\mu_kμk表示第k个聚簇点的位置。
成本函数//失真函数:
J(c1,c2,..,cm,μ1,μ2,...,μk)=1m∑i=1m∣∣x(i)−μc(i)∣∣2J(c^{1},c^{2},..,c^{m},\mu_1,\mu_2,...,\mu_k)=\frac{1}{m}\sum_{i=1}^m||x^{(i)}-\mu_{c^{(i)}}||^2J(c1,c2,..,cm,μ1,μ2,...,μk)=m1∑i=1m∣∣x(i)−μc(i)∣∣2,代表所有数据,第i个数据x(i)x^{(i)}x(i)到对应聚簇点μc(i)\mu_{c^{(i)}}μc(i)的距离的平方和的平均。
梯度下降:
就是每次更新聚簇点位置后,重新计算每个数据到聚簇点的距离,根据距离最近聚簇点重新分类数据,为了使得成本函数最小,使得分类后数据找到中心点更新聚簇点。
这样成本函数永不会上升,保证收敛。
1.2.2 初始化K-Means
选择 K 个初始中心点。将每个点分配给最近的中心点,形成簇。重新计算每个簇的中心点(均值)。重复 2-3 步,直到中心点不再变化。优化过程本质上是一个贪心算法,它只会朝着局部最优的方向改进。如果初始中心点选得不好,有两个中心点一开始就落在了同一个真实的簇里,那么算法就很难正确地发现其他簇的自然结构。
方式:
1)从数据集中随机选择 K 个点作为初始中心点。
优点:快,简单。
缺点:结果不稳定:每次运行可能得到截然不同的结果和聚类效果。可能效果很差:很容易选中一些离群点或密集区域中的点,导致局部最优。
解决:解决随机初始化的不稳定性,采用一种叫做“随机重跑”的策略:运行 K-Means 多次(例如 10 次),每次都用不同的随机种子初始化。从这多次运行的结果中,选择簇内平方和最小 的那个作为最终模型。计算成本高。
2)K-Means++:让初始的聚类中心彼此之间尽可能远离,从而为全局解提供一个更好的起点。
第一个中心点:从数据点中随机均匀地选择一个点作为第一个聚类中心。
计算距离:对于数据集中的每一个点计算它到已选定的所有聚类中心的最短距离。
概率选择下一个中心点:一个点被选为下一个聚类中心的概率与其距离平方成正比。离已选中心越远的点,被选中的概率越大。
重复运行选择K个聚簇点。
优点:显著提升效果:通常能找到一个更优、更一致的聚类结果。加速收敛:因为起点更好,所以需要的迭代次数更少。理论保证:有数学证明表明 K-Means++ 能找到接近最优的解。
缺点:比随机初始化计算量稍大,因为需要计算距离和概率。
1.2.3 选择聚类个数K
肘部法则:绘制不同 K 值对应的簇内平方和曲线。簇内平方和衡量的是每个样本点到其所属簇中心点的距离总和。随着 K 值的增大,这个值会逐渐减小(因为每个簇变得更小、更紧凑)。
缺点:“拐点”有时不明显,主观性强,不同的人可能会选择不同的点。
轮廓系数:衡量一个样本点与其所属簇的相似度(内聚性)和其他簇的相似度(分离性)的对比。
a(i):样本 i 到同簇内所有其他点的平均距离。(内聚性,越小越好);
b(i):样本 i 到其他某个簇中所有点的平均距离的最小值。(分离性,越大越好);
样本 i 的轮廓系数 s(i) 定义为:s(i)=b(i)−a(i)max[a(i),b(i)]s(i)=\frac{b(i)-a(i)}{max[a(i),b(i)]}s(i)=max[a(i),b(i)]b(i)−a(i).
流程:计算 K 从 2 到某个最大值对应的平均轮廓系数(所有样本 s(i) 的平均值)。绘制 K 值与平均轮廓系数的关系图。选择平均轮廓系数最大的 K 值。
s(i) 接近 1:说明样本 i 的聚类是合理的。
s(i) 接近 0:说明样本 i 处在两个簇的边界上。
总结:
1)我们可以根据实际需求来选择聚类个数,注重业务需求。
2)对于选定的几个候选 K 值,将聚类结果可视化,观察这些簇在图上是否有清晰的界限,是否符合你的直觉,查看每个簇的大小。如果一个 K 值导致某个簇只有极少数点,可能不合适。
选择 K 是一个权衡的过程,需要将业务目标与技术指标结合起来,做出最合理的决策。
二、CNN
2.1 CIFAR-10运行结果
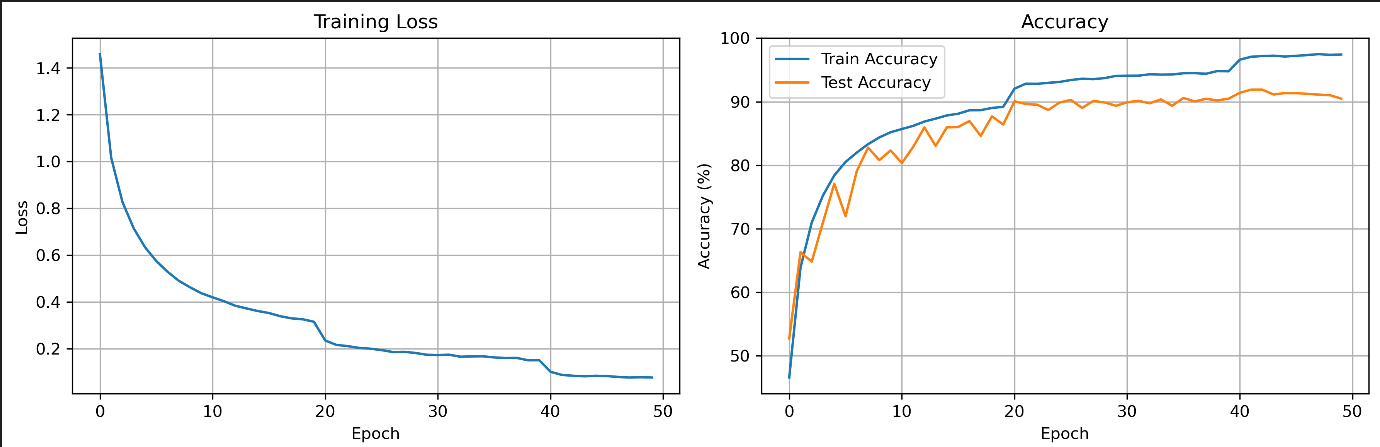
可视化,代码跑完了,准确率还行。
2.2 根据任务训练




对于数据清洗想过三种方式,按名字定义来,副本和以正确命名作为规则删选;以图片的hash对比作为判断比较删除;以两种方式结合的形式。
最后采用,副本和以正确命名作为规则删选
数据清洗:
import os
import json
import shutil
from pathlib import Path
import redef classify_images_by_naming_rules():"""根据命名规则分类图片并生成JSON文件"""# 定义路径train_image_dir = r"Problem B\AgriculturalDisease_trainingset\images"validation_image_dir = r"Problem B\AgriculturalDisease_validationset\images"base_output_dir = "classified_images1"# 创建输出目录images3_dir = os.path.join(base_output_dir, "images3") # 训练集分类后images4_dir = os.path.join(base_output_dir, "images4") # 验证集分类后os.makedirs(images3_dir, exist_ok=True)os.makedirs(images4_dir, exist_ok=True)# 支持的图片格式image_extensions = {'.jpg', '.jpeg', '.png', '.bmp', '.gif', '.JPG', '.JPEG', '.PNG', '.BMP', '.GIF'}# 命名规则正则表达式:标签ID_图片号.扩展名naming_pattern = re.compile(r'^(\d{1,2})_(\d+)\.(jpg|jpeg|png|bmp|gif)$', re.IGNORECASE)print("开始根据命名规则分类图片...")# 处理训练集图片print("\n=== 处理训练集图片 ===")train_results = process_image_set(train_image_dir, images3_dir, naming_pattern, image_extensions, "训练集")# 处理验证集图片print("\n=== 处理验证集图片 ===")validation_results = process_image_set(validation_image_dir, images4_dir, naming_pattern, image_extensions, "验证集")# 生成JSON文件generate_json_files(base_output_dir, train_results, validation_results)print(f"\n处理完成!")print(f"训练集: {train_results['valid_count']} 张有效图片, {train_results['invalid_count']} 张无效图片")print(f"验证集: {validation_results['valid_count']} 张有效图片, {validation_results['invalid_count']} 张无效图片")print(f"分类结果保存在: {base_output_dir}")def process_image_set(source_dir, target_dir, naming_pattern, image_extensions, set_name):"""处理单个图片集,根据命名规则分类图片"""results = {'valid_count': 0,'invalid_count': 0,'valid_files': [],'invalid_files': [],'category_stats': {}}if not os.path.exists(source_dir):print(f"警告: {set_name}目录不存在: {source_dir}")return results# 获取所有图片文件all_files = [f for f in os.listdir(source_dir)if os.path.isfile(os.path.join(source_dir, f)) andPath(f).suffix.lower() in image_extensions]print(f"{set_name}找到 {len(all_files)} 个图片文件")# 处理每个图片文件for filename in all_files:file_path = os.path.join(source_dir, filename)# 检查文件名是否符合命名规则match = naming_pattern.match(filename)if match:label_id = match.group(1)image_id = match.group(2)# 验证标签ID是否在有效范围内(0-60)if is_valid_label_id(label_id):# 复制文件到目标目录target_path = os.path.join(target_dir, filename)shutil.copy2(file_path, target_path)# 添加到结果results['valid_count'] += 1results['valid_files'].append({"disease_class": int(label_id),"image_id": filename})# 更新类别统计if label_id not in results['category_stats']:results['category_stats'][label_id] = 0results['category_stats'][label_id] += 1else:# 标签ID超出范围results['invalid_count'] += 1results['invalid_files'].append(filename)print(f"标签ID超出范围(0-60): {filename}")else:# 不符合命名规则results['invalid_count'] += 1results['invalid_files'].append(filename)print(f"不符合命名规则: {filename}")print(f"{set_name}处理完成:")print(f" 有效图片: {results['valid_count']}")print(f" 无效图片: {results['invalid_count']}")return resultsdef is_valid_label_id(label_id):"""验证标签ID是否在有效范围内(0-60)"""try:id_num = int(label_id)return 0 <= id_num <= 60except ValueError:return Falsedef generate_json_files(output_dir, train_results, validation_results):"""生成JSON文件"""# 生成训练集JSON文件train_json_path = os.path.join(output_dir, "training_images.json")with open(train_json_path, 'w', encoding='utf-8') as f:json.dump(train_results['valid_files'], f, indent=4, ensure_ascii=False)# 生成验证集JSON文件validation_json_path = os.path.join(output_dir, "validation_images.json")with open(validation_json_path, 'w', encoding='utf-8') as f:json.dump(validation_results['valid_files'], f, indent=4, ensure_ascii=False)# 生成处理报告generate_processing_report(output_dir, train_results, validation_results)print(f"JSON文件已生成:")print(f" 训练集: {train_json_path}")print(f" 验证集: {validation_json_path}")def generate_processing_report(output_dir, train_results, validation_results):"""生成处理报告"""report = {"metadata": {"processing_method": "naming_rule_classification","naming_rule": "标签ID_图片号.扩展名 (标签ID为1-2位数字,范围0-60,图片号为若干位数字)","total_valid_images": train_results['valid_count'] + validation_results['valid_count'],"total_invalid_images": train_results['invalid_count'] + validation_results['invalid_count'],"processing_date": "2023-01-01" # 这里可以替换为实际处理日期},"training_set": {"summary": {"valid_count": train_results['valid_count'],"invalid_count": train_results['invalid_count']},"category_statistics": train_results['category_stats'],"valid_files_sample": train_results['valid_files'][:5] if train_results['valid_files'] else [],"invalid_files_sample": train_results['invalid_files'][:5] if train_results['invalid_files'] else []},"validation_set": {"summary": {"valid_count": validation_results['valid_count'],"invalid_count": validation_results['invalid_count']},"category_statistics": validation_results['category_stats'],"valid_files_sample": validation_results['valid_files'][:5] if validation_results['valid_files'] else [],"invalid_files_sample": validation_results['invalid_files'][:5] if validation_results['invalid_files'] else []},"directory_structure": {"base_output": output_dir,"training_images": os.path.join(output_dir, "images3"),"validation_images": os.path.join(output_dir, "images4")}}# 写入JSON文件report_path = os.path.join(output_dir, "processing_report.json")with open(report_path, 'w', encoding='utf-8') as f:json.dump(report, f, ensure_ascii=False, indent=4)print(f"处理报告已生成: {report_path}")# 显示统计信息print("\n=== 分类统计 ===")print(f"训练集:")print(f" 有效图片: {train_results['valid_count']}")print(f" 无效图片: {train_results['invalid_count']}")print(f" 类别分布:")for label_id, count in sorted(train_results['category_stats'].items()):print(f" 类别 {label_id}: {count} 张图片")print(f"验证集:")print(f" 有效图片: {validation_results['valid_count']}")print(f" 无效图片: {validation_results['invalid_count']}")print(f" 类别分布:")for label_id, count in sorted(validation_results['category_stats'].items()):print(f" 类别 {label_id}: {count} 张图片")if __name__ == "__main__":classify_images_by_naming_rules()
任务一训练:
import os
import time
import json
import numpy as np
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
from torchvision import models, transforms
from torchvision.models import EfficientNet_B3_Weights
from PIL import Image
from tqdm import tqdm
from sklearn.metrics import precision_score, recall_score, f1_score, mean_squared_error, mean_absolute_error, r2_score# -------------------------- 数据集类定义 --------------------------
class DiseaseDataset(torch.utils.data.Dataset):def __init__(self, image_dir, annot_path, is_train=True):self.image_dir = image_dirself.is_train = is_trainwith open(annot_path, "r", encoding="utf-8") as f:self.annotations = json.load(f)self.transform = self._get_transforms()def _get_transforms(self):if self.is_train:return transforms.Compose([transforms.RandomResizedCrop((300, 300), scale=(0.8, 1.0), ratio=(0.9, 1.1)),transforms.RandomHorizontalFlip(p=0.5),transforms.RandomVerticalFlip(p=0.3),transforms.ColorJitter(brightness=0.2, contrast=0.2, saturation=0.2),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])else:return transforms.Compose([transforms.Resize((300, 300)),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])def __len__(self):return len(self.annotations)def __getitem__(self, idx):item = self.annotations[idx]image_id = item["image_id"]label = item["disease_class"]image = Image.open(os.path.join(self.image_dir, image_id)).convert("RGB")image = self.transform(image)return image, torch.tensor(label, dtype=torch.long)# -------------------------- 模型定义 --------------------------
class EfficientNetB3(nn.Module):def __init__(self, num_classes):super().__init__()self.backbone = models.efficientnet_b3(weights=EfficientNet_B3_Weights.DEFAULT)for param in list(self.backbone.parameters())[:-150]:param.requires_grad = Falsein_features = self.backbone.classifier[1].in_featuresself.backbone.classifier = nn.Sequential(nn.Dropout(p=0.5, inplace=True),nn.Linear(in_features, num_classes))def forward(self, x):return self.backbone(x)# -------------------------- 训练与验证函数 --------------------------
def train_one_epoch(model, loader, criterion, optimizer, device, num_classes):model.train()total_loss = 0.0total_correct = 0total_samples = 0all_preds = []all_labels = []for images, labels in tqdm(loader, desc="训练"):images, labels = images.to(device), labels.to(device)optimizer.zero_grad()outputs = model(images)loss = criterion(outputs, labels)loss.backward()optimizer.step()total_loss += loss.item() * images.size(0)_, predicted = torch.max(outputs.data, 1)total_correct += (predicted == labels).sum().item()total_samples += labels.size(0)# 收集预测和标签用于计算其他指标all_preds.extend(predicted.cpu().numpy())all_labels.extend(labels.cpu().numpy())avg_loss = total_loss / total_samplesaccuracy = total_correct / total_samples# 计算分类指标precision = precision_score(all_labels, all_preds, average='macro', zero_division=0)recall = recall_score(all_labels, all_preds, average='macro', zero_division=0)f1 = f1_score(all_labels, all_preds, average='macro', zero_division=0)# 计算回归指标(注意:这些指标通常不用于分类任务,但按要求实现)mse = mean_squared_error(all_labels, all_preds)mae = mean_absolute_error(all_labels, all_preds)rmse = np.sqrt(mse)r2 = r2_score(all_labels, all_preds)return avg_loss, accuracy, precision, recall, f1, mse, mae, rmse, r2def validate(model, loader, criterion, device, num_classes):model.eval()total_loss = 0.0total_correct = 0total_samples = 0all_preds = []all_labels = []with torch.no_grad():for images, labels in tqdm(loader, desc="验证"):images, labels = images.to(device), labels.to(device)outputs = model(images)loss = criterion(outputs, labels)total_loss += loss.item() * images.size(0)_, predicted = torch.max(outputs.data, 1)total_correct += (predicted == labels).sum().item()total_samples += labels.size(0)# 收集预测和标签用于计算其他指标all_preds.extend(predicted.cpu().numpy())all_labels.extend(labels.cpu().numpy())avg_loss = total_loss / total_samplesaccuracy = total_correct / total_samples# 计算分类指标precision = precision_score(all_labels, all_preds, average='macro', zero_division=0)recall = recall_score(all_labels, all_preds, average='macro', zero_division=0)f1 = f1_score(all_labels, all_preds, average='macro', zero_division=0)# 计算回归指标mse = mean_squared_error(all_labels, all_preds)mae = mean_absolute_error(all_labels, all_preds)rmse = np.sqrt(mse)r2 = r2_score(all_labels, all_preds)return avg_loss, accuracy, precision, recall, f1, mse, mae, rmse, r2# -------------------------- 训练指标可视化函数 --------------------------
def plot_single_metric(history, metric_name, save_dir="./result/"):"""绘制单个指标的训练和验证曲线"""plt.figure(figsize=(10, 6))plt.plot(history[f"train_{metric_name}"], label="Training")plt.plot(history[f"val_{metric_name}"], label="Validation")plt.title(f"{metric_name.capitalize()} vs. Epoch")plt.xlabel("Epoch")plt.ylabel(metric_name.capitalize())plt.legend()# 创建保存目录os.makedirs(save_dir, exist_ok=True)save_path = os.path.join(save_dir, f"{metric_name}_curve.png")plt.savefig(save_path, dpi=300)print(f"{metric_name} 可视化已保存至 {save_path}")plt.close()# -------------------------- 主执行逻辑 --------------------------
if __name__ == '__main__':# 配置参数TRAIN_IMAGE_DIR = "./dataset/AgriculturalDisease_trainingset/images"TRAIN_ANNOT_PATH = "./dataset/AgriculturalDisease_trainingset/clean_annotations.json"VAL_IMAGE_DIR = "./dataset/AgriculturalDisease_validationset/images"VAL_ANNOT_PATH = "./dataset/AgriculturalDisease_validationset/clean_annotations.json"MODEL_SAVE_PATH = "./model_task1/efficientnet_b3_best.pth"RESULT_DIR = "./result/" # 指标可视化结果保存目录NUM_CLASSES = 61BATCH_SIZE = 32EPOCHS = 100LEARNING_RATE = 5e-5DEVICE = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 加载数据集train_dataset = DiseaseDataset(image_dir=TRAIN_IMAGE_DIR,annot_path=TRAIN_ANNOT_PATH,is_train=True)val_dataset = DiseaseDataset(image_dir=VAL_IMAGE_DIR,annot_path=VAL_ANNOT_PATH,is_train=False)# 创建数据加载器# 打印数据集信息print(f"训练集样本数:{len(train_dataset)},验证集样本数:{len(val_dataset)}")print(f"使用设备:{DEVICE}")# 初始化模型、损失函数、优化器model = EfficientNetB3(num_classes=NUM_CLASSES).to(DEVICE)criterion = nn.CrossEntropyLoss()optimizer = optim.Adam(model.parameters(), lr=LEARNING_RATE,weight_decay=1e-5)scheduler = optim.lr_scheduler.ReduceLROnPlateau(optimizer, mode='min', factor=0.7, patience=5,min_lr=1e-6)# 训练循环(含计时)history = {"train_loss": [], "train_acc": [], "train_precision": [], "train_recall": [],"train_f1": [], "train_mse": [], "train_mae": [], "train_rmse": [], "train_r2": [],"val_loss": [], "val_acc": [], "val_precision": [], "val_recall": [],"val_f1": [], "val_mse": [], "val_mae": [], "val_rmse": [], "val_r2": []}best_val_acc = 0.0start_time = time.time()for epoch in range(EPOCHS):print(f"\n===== Epoch {epoch + 1}/{EPOCHS} =====")# 训练train_metrics = train_one_epoch(model, train_loader, criterion, optimizer, DEVICE, NUM_CLASSES)train_loss, train_acc, train_precision, train_recall, train_f1, train_mse, train_mae, train_rmse, train_r2 = train_metrics# 验证val_metrics = validate(model, val_loader, criterion, DEVICE, NUM_CLASSES)val_loss, val_acc, val_precision, val_recall, val_f1, val_mse, val_mae, val_rmse, val_r2 = val_metrics# 学习率调整scheduler.step(val_loss)# 记录指标history["train_loss"].append(train_loss)history["train_acc"].append(train_acc)history["train_precision"].append(train_precision)history["train_recall"].append(train_recall)history["train_f1"].append(train_f1)history["train_mse"].append(train_mse)history["train_mae"].append(train_mae)history["train_rmse"].append(train_rmse)history["train_r2"].append(train_r2)history["val_loss"].append(val_loss)history["val_acc"].append(val_acc)history["val_precision"].append(val_precision)history["val_recall"].append(val_recall)history["val_f1"].append(val_f1)history["val_mse"].append(val_mse)history["val_mae"].append(val_mae)history["val_rmse"].append(val_rmse)history["val_r2"].append(val_r2)# 打印本轮结果print(f"训练损失:{train_loss:.4f},训练准确率:{train_acc:.4f}")print(f"训练精确率:{train_precision:.4f},训练召回率:{train_recall:.4f},训练F1:{train_f1:.4f}")print(f"训练MSE:{train_mse:.4f},MAE:{train_mae:.4f},RMSE:{train_rmse:.4f},R2:{train_r2:.4f}")print(f"验证损失:{val_loss:.4f},验证准确率:{val_acc:.4f}")print(f"验证精确率:{val_precision:.4f},验证召回率:{val_recall:.4f},验证F1:{val_f1:.4f}")print(f"验证MSE:{val_mse:.4f},MAE:{val_mae:.4f},RMSE:{val_rmse:.4f},R2:{val_r2:.4f}")print(f"当前学习率:{optimizer.param_groups[0]['lr']:.6f}")# 保存最佳模型if val_acc > best_val_acc:best_val_acc = val_accos.makedirs(os.path.dirname(MODEL_SAVE_PATH), exist_ok=True)torch.save(model.state_dict(), MODEL_SAVE_PATH)print(f"最佳模型已保存(验证准确率:{best_val_acc:.4f})")# 计算总训练时长end_time = time.time()total_time = end_time - start_timehours, remainder = divmod(total_time, 3600)minutes, seconds = divmod(remainder, 60)print(f"\n训练完成!总时长:{int(hours)}小时{int(minutes)}分钟{int(seconds)}秒")print(f"最佳验证准确率:{best_val_acc:.4f}")# 可视化所有指标,每个指标单独保存为一张图片metrics = ["loss", "acc", "precision", "recall", "f1", "mse", "mae", "rmse", "r2"]for metric in metrics:plot_single_metric(history, metric, RESULT_DIR)
对于小样本来说,计划两者中方式,一使用任务一训练完的参数进行训练,这样参数对数据拟合的更好;二完全训练一个新的模型和参数。
先采用第二种方式。
任务二训练:
import os
import time
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
from torch.utils.data import DataLoader
from torch.cuda.amp import GradScaler, autocast
from torchvision import transforms
from tqdm import tqdm
from sklearn.metrics import accuracy_score, f1_score
import numpy as np
import matplotlib.pyplot as plt
import glob
from PIL import Image
import json# 设置matplotlib中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False# 使用绝对路径
BASE_DIR = r"D:\game\1"class Config:# 根据图片中的目录结构设置路径train_data_dir = os.path.join(BASE_DIR, "images", "images3") # 训练集图片路径val_data_dir = os.path.join(BASE_DIR, "images", "images4") # 验证集图片路径train_json_path = os.path.join(BASE_DIR, "training_images.json") # 训练集JSON文件val_json_path = os.path.join(BASE_DIR, "validation_images.json") # 验证集JSON文件# 图片要求的核心参数shots_per_class = 10 # 每个类别10张训练图像num_classes = 61 # 61类农业病害max_parameters = 2000000 # 降低到200万参数以下(原2000万)# 训练参数 - 调整为更稳定的设置batch_size = 8 # 减小batch_sizeepochs = 100learning_rate = 5e-5 # 降低学习率weight_decay = 1e-3 # 增加权重衰减label_smoothing = 0.3 # 增加标签平滑# 模型参数dropout_rate = 0.5 # 增加dropout防止过拟合# 早停patience = 10 # 减少早停耐心值# 梯度裁剪max_grad_norm = 1.0device = torch.device("cuda" if torch.cuda.is_available() else "cpu")save_path = os.path.join(BASE_DIR, "best_cnn_fewshot_2M.pth")fig_save_path = os.path.join(BASE_DIR, "fewshot_training_metrics_2M.png")def ensure_directories(self):"""确保所有必要的目录存在"""directories = [os.path.dirname(self.save_path), # 模型保存目录os.path.dirname(self.fig_save_path), # 图表保存目录self.train_data_dir, # 训练数据目录self.val_data_dir # 验证数据目录]for dir_path in directories:if dir_path and not os.path.exists(dir_path):try:os.makedirs(dir_path, exist_ok=True)print(f"✓ 创建目录: {dir_path}")except Exception as e:print(f"✗ 创建目录失败 {dir_path}: {e}")config = Config()# 简化的数据增强变换 - 避免数值不稳定
def get_simpler_transforms(is_train=True):"""简化的数据增强,避免过度增强导致数值不稳定"""if is_train:return transforms.Compose([transforms.Resize(256),transforms.RandomCrop(224), # 替换RandomResizedCroptransforms.RandomHorizontalFlip(p=0.3), # 降低翻转概率# 移除可能引入噪声的增强:ColorJitter, GaussianBlur等transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])else:return transforms.Compose([transforms.Resize(256),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])# 针对新的JSON格式修改数据集类
class FewShotCropDiseaseDataset(torch.utils.data.Dataset):def __init__(self, data_dir, json_path, transform=None, shots_per_class=10, mode='train'):self.data_dir = data_dirself.json_path = json_pathself.transform = transformself.shots_per_class = shots_per_classself.mode = modeprint(f"初始化{mode}数据集:")print(f" 数据目录: {data_dir}")print(f" JSON路径: {json_path}")# 从JSON文件加载图像路径和标签映射self.samples = self._load_samples_from_json()self.num_classes = len(set([label for _, label in self.samples])) if self.samples else 0# 应用小样本选择策略if mode == 'train' and self.samples:self.samples = self._apply_few_shot_selection()print(f"{mode}数据集: {len(self.samples)}样本, {self.num_classes}类")def _load_samples_from_json(self):"""从JSON文件加载图像路径和标签"""samples = []try:with open(self.json_path, 'r', encoding='utf-8') as f:json_data = json.load(f)print(f"JSON文件加载成功,包含 {len(json_data)} 个条目")# 处理JSON格式: [{"disease_class": 0, "image_id": "0_27417.jpg"}, ...]for item in json_data:if isinstance(item, dict) and 'disease_class' in item and 'image_id' in item:image_id = item['image_id']disease_class = item['disease_class']# 构建图像路径image_path = os.path.join(self.data_dir, image_id)samples.append((image_path, disease_class))else:print(f"警告: 跳过无效的JSON项: {item}")except Exception as e:print(f"加载JSON文件失败: {e}")return []# 过滤不存在的图像文件valid_samples = []for img_path, label in samples:if os.path.exists(img_path):valid_samples.append((img_path, label))else:print(f"警告: 图像文件不存在: {img_path}")print(f"从JSON加载了 {len(valid_samples)} 个有效样本")return valid_samplesdef _apply_few_shot_selection(self):"""应用小样本选择策略"""if self.mode != 'train' or not self.shots_per_class:return self.samples# 按标签分组label_to_images = {}for img_path, label in self.samples:if label not in label_to_images:label_to_images[label] = []label_to_images[label].append((img_path, label))# 对每个类别选择指定数量的样本selected_samples = []for label, images in label_to_images.items():if len(images) > self.shots_per_class:selected_indices = np.random.choice(len(images), self.shots_per_class, replace=False)for idx in selected_indices:selected_samples.append(images[idx])print(f" 类别 {label}: 选择 {self.shots_per_class}/{len(images)} 张图像")else:selected_samples.extend(images)print(f" 类别 {label}: 使用所有 {len(images)} 张图像")return selected_samplesdef __len__(self):return len(self.samples)def __getitem__(self, idx):img_path, label = self.samples[idx]try:image = Image.open(img_path).convert('RGB')except Exception as e:print(f"加载图像失败 {img_path}: {e}")# 返回黑色图像作为占位符image = Image.new('RGB', (224, 224), color='black')if self.transform:image = self.transform(image)return image, label# 极简化的CNN模型(参数量大幅减少)
class UltraLightweightCNN(nn.Module):def __init__(self, num_classes=61, dropout_rate=0.5):super().__init__()# 极简特征提取器 - 参数减少90%self.features = nn.Sequential(# 第一层 - 大幅减少通道数nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1), # 112x112nn.BatchNorm2d(32),nn.ReLU(inplace=True),nn.Dropout2d(0.1),# 第二层nn.Conv2d(32, 64, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(64),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2), # 56x56nn.Dropout2d(0.2),# 第三层nn.Conv2d(64, 128, kernel_size=3, stride=1, padding=1),nn.BatchNorm2d(128),nn.ReLU(inplace=True),nn.MaxPool2d(kernel_size=2, stride=2), # 28x28nn.Dropout2d(0.3),# 全局平均池化nn.AdaptiveAvgPool2d((1, 1)))# 简化分类器self.classifier = nn.Sequential(nn.Dropout(dropout_rate),nn.Linear(128, num_classes) # 直接输出,减少一层)def forward(self, x):x = self.features(x)x = x.view(x.size(0), -1)x = self.classifier(x)return x# 参数计算函数
def count_parameters(model):"""计算模型参数数量"""total_params = sum(p.numel() for p in model.parameters())trainable_params = sum(p.numel() for p in model.parameters() if p.requires_grad)return total_params, trainable_params# 增强稳定性的训练函数
def train_one_epoch_stable(model, train_loader, criterion, optimizer, scaler, device, max_grad_norm=1.0):"""增强稳定性的训练函数,包含梯度裁剪和NaN检查"""model.train()total_loss = 0.0all_preds = []all_labels = []processed_samples = 0for imgs, labels in tqdm(train_loader, desc="Training"):imgs, labels = imgs.to(device), labels.to(device)optimizer.zero_grad()try:with autocast():outputs = model(imgs)loss = criterion(outputs, labels)# 检查损失是否为NaNif torch.isnan(loss):print("警告: 检测到NaN损失,跳过该batch")continuescaler.scale(loss).backward()# 梯度裁剪 - 防止梯度爆炸scaler.unscale_(optimizer)torch.nn.utils.clip_grad_norm_(model.parameters(), max_grad_norm)scaler.step(optimizer)scaler.update()total_loss += loss.item() * imgs.size(0)processed_samples += imgs.size(0)preds = torch.argmax(outputs, dim=1).cpu().numpy()all_preds.extend(preds)all_labels.extend(labels.cpu().numpy())except Exception as e:print(f"训练过程中出现异常: {e}")continueif processed_samples == 0:print("警告: 本epoch没有成功处理的样本")return float('nan'), 0.0, 0.0epoch_loss = total_loss / processed_samplesepoch_acc = accuracy_score(all_labels, all_preds) if len(all_labels) > 0 else 0.0epoch_f1 = f1_score(all_labels, all_preds, average="macro") if len(all_labels) > 0 else 0.0return epoch_loss, epoch_acc, epoch_f1def validate_stable(model, val_loader, criterion, device):"""增强稳定性的验证函数"""model.eval()total_loss = 0.0all_preds = []all_labels = []processed_samples = 0with torch.no_grad():for imgs, labels in tqdm(val_loader, desc="Validating"):imgs, labels = imgs.to(device), labels.to(device)try:with autocast():outputs = model(imgs)loss = criterion(outputs, labels)# 检查损失是否为NaNif torch.isnan(loss):print("警告: 验证中检测到NaN损失,跳过该batch")continuetotal_loss += loss.item() * imgs.size(0)processed_samples += imgs.size(0)preds = torch.argmax(outputs, dim=1).cpu().numpy()all_preds.extend(preds)all_labels.extend(labels.cpu().numpy())except Exception as e:print(f"验证过程中出现异常: {e}")continueif processed_samples == 0:print("警告: 验证阶段没有成功处理的样本")return float('nan'), 0.0, 0.0val_loss = total_loss / processed_samplesval_acc = accuracy_score(all_labels, all_preds) if len(all_labels) > 0 else 0.0val_f1 = f1_score(all_labels, all_preds, average="macro") if len(all_labels) > 0 else 0.0return val_loss, val_acc, val_f1# 模型输出检查函数
def check_model_outputs(model, data_loader, device):"""检查模型输出是否正常"""model.eval()with torch.no_grad():for i, (imgs, labels) in enumerate(data_loader):if i >= 3: # 只检查前3个batchbreakimgs, labels = imgs.to(device), labels.to(device)outputs = model(imgs)# 检查输出if torch.isnan(outputs).any():print("错误: 模型输出包含NaN")return Falseif torch.isinf(outputs).any():print("错误: 模型输出包含Inf")return False# 检查概率分布probs = torch.softmax(outputs, dim=1)if torch.isnan(probs).any():print("错误: 概率分布包含NaN")return Falseprob_sums = probs.sum(dim=1)if (prob_sums - 1.0).abs().max() > 1e-3:print(f"警告: 概率和不为1,最大偏差: {(prob_sums - 1.0).abs().max():.6f}")print("✓ 模型输出检查通过")return True# 可视化函数
def plot_training_metrics(epochs, train_losses, val_losses, train_accs, val_accs, train_f1s, val_f1s, save_path):# 确保图表保存目录存在save_dir = os.path.dirname(save_path)if save_dir and not os.path.exists(save_dir):os.makedirs(save_dir, exist_ok=True)print(f"✓ 创建图表保存目录: {save_dir}")fig, axes = plt.subplots(1, 3, figsize=(18, 5))# 过滤NaN值epochs_range = range(1, epochs + 1)train_losses_clean = [loss if not np.isnan(loss) else None for loss in train_losses]val_losses_clean = [loss if not np.isnan(loss) else None for loss in val_losses]axes[0].plot(epochs_range, train_losses_clean, label="训练损失", color="blue", linestyle="-", marker='o',markersize=2)axes[0].plot(epochs_range, val_losses_clean, label="验证损失", color="red", linestyle="--", marker='s',markersize=2)axes[0].set_title("损失随训练轮次变化")axes[0].set_xlabel("轮次(Epoch)")axes[0].set_ylabel("损失值")axes[0].legend()axes[0].grid(alpha=0.3)axes[1].plot(epochs_range, train_accs, label="训练准确率", color="blue", linestyle="-", marker='o', markersize=2)axes[1].plot(epochs_range, val_accs, label="验证准确率", color="red", linestyle="--", marker='s', markersize=2)axes[1].set_title("准确率随训练轮次变化")axes[1].set_xlabel("轮次(Epoch)")axes[1].set_ylabel("准确率")axes[1].set_ylim(0, 1.0)axes[1].legend()axes[1].grid(alpha=0.3)axes[2].plot(epochs_range, train_f1s, label="训练F1", color="blue", linestyle="-", marker='o', markersize=2)axes[2].plot(epochs_range, val_f1s, label="验证F1", color="red", linestyle="--", marker='s', markersize=2)axes[2].set_title("F1分数随训练轮次变化")axes[2].set_xlabel("轮次(Epoch)")axes[2].set_ylabel("F1分数")axes[2].set_ylim(0, 1.0)axes[2].legend()axes[2].grid(alpha=0.3)plt.tight_layout()plt.savefig(save_path, dpi=300)print(f"训练指标可视化图表已保存至:{save_path}")plt.show()# 主训练函数
def main():print("=== 修复后的小样本农作物病害分类训练开始 ===")# 确保所有必要目录存在config.ensure_directories()print(f"任务要求: 每个类别{config.shots_per_class}张训练图像, {config.num_classes}个类别")print(f"模型参数限制: {config.max_parameters}参数以下")print(f"设备: {config.device}")print(f"基础目录: {BASE_DIR}")# 检查路径是否存在paths_to_check = {"训练数据目录": config.train_data_dir,"验证数据目录": config.val_data_dir,"训练JSON文件": config.train_json_path,"验证JSON文件": config.val_json_path}for name, path in paths_to_check.items():exists = os.path.exists(path)status = "存在" if exists else "不存在"print(f"{name}: {path} -> {status}")if not all(os.path.exists(path) for path in [config.train_data_dir, config.val_data_dir]):print("错误: 数据目录不存在")return# 创建小样本数据集train_transform = get_simpler_transforms(is_train=True)val_transform = get_simpler_transforms(is_train=False)# 训练集train_dataset = FewShotCropDiseaseDataset(data_dir=config.train_data_dir,json_path=config.train_json_path,transform=train_transform,shots_per_class=config.shots_per_class,mode='train')# 验证集val_dataset = FewShotCropDiseaseDataset(data_dir=config.val_data_dir,json_path=config.val_json_path,transform=val_transform,shots_per_class=None, # 验证集使用所有样本mode='val')# 检查数据集是否为空if len(train_dataset) == 0:print("错误: 训练集为空,无法创建DataLoader")returnif len(val_dataset) == 0:print("错误: 验证集为空,无法创建DataLoader")returntrain_loader = DataLoader(# 初始化极轻量级模型model = UltraLightweightCNN(num_classes=config.num_classes,dropout_rate=config.dropout_rate).to(config.device)# 计算参数数量total_params, trainable_params = count_parameters(model)print(f"模型参数统计:")print(f"总参数: {total_params:,} ({total_params / 1e6:.2f}M)")print(f"可训练参数: {trainable_params:,} ({trainable_params / 1e6:.2f}M)")if total_params > config.max_parameters:print(f"警告: 模型参数({total_params:,})超过限制({config.max_parameters:,})!")else:print(f"✓ 模型参数符合要求(≤{config.max_parameters:,})")# 优化器和损失函数optimizer = optim.AdamW(model.parameters(),lr=config.learning_rate,weight_decay=config.weight_decay)scheduler = CosineAnnealingLR(optimizer, T_max=config.epochs, eta_min=1e-6)criterion = nn.CrossEntropyLoss(label_smoothing=config.label_smoothing).to(config.device)scaler = GradScaler()# 在训练前检查模型输出print("进行模型输出检查...")if not check_model_outputs(model, val_loader, config.device):print("模型初始化异常,请检查数据预处理!")return# 训练记录train_losses, val_losses = [], []train_accs, val_accs = [], []train_f1s, val_f1s = [], []start_time = time.time()best_val_f1 = 0.0early_stop_counter = 0print(f"\n开始训练,共{config.epochs}轮")for epoch in range(config.epochs):print(f"\n--- Epoch {epoch + 1}/{config.epochs} ---")# 训练与验证train_loss, train_acc, train_f1 = train_one_epoch_stable(model, train_loader, criterion, optimizer, scaler, config.device, config.max_grad_norm)val_loss, val_acc, val_f1 = validate_stable(model, val_loader, criterion, config.device)# 学习率调度scheduler.step()# 记录指标train_losses.append(train_loss)val_losses.append(val_loss)train_accs.append(train_acc)val_accs.append(val_acc)train_f1s.append(train_f1)val_f1s.append(val_f1)# 打印日志train_loss_str = f"{train_loss:.4f}" if not np.isnan(train_loss) else "nan"val_loss_str = f"{val_loss:.4f}" if not np.isnan(val_loss) else "nan"print(f"Epoch {epoch + 1}/{config.epochs} | "f"Train Loss: {train_loss_str}, Acc: {train_acc:.4f}, F1: {train_f1:.4f} | "f"Val Loss: {val_loss_str}, Acc: {val_acc:.4f}, F1: {val_f1:.4f} | "f"LR: {optimizer.param_groups[0]['lr']:.6f}")# 早停与模型保存if not np.isnan(val_f1) and val_f1 > best_val_f1:best_val_f1 = val_f1# 确保模型保存目录存在save_dir = os.path.dirname(config.save_path)if save_dir and not os.path.exists(save_dir):os.makedirs(save_dir, exist_ok=True)print(f"✓ 创建模型保存目录: {save_dir}")torch.save(model.state_dict(), config.save_path)print(f"保存最佳模型(Val F1: {best_val_f1:.4f})")early_stop_counter = 0else:early_stop_counter += 1if early_stop_counter >= config.patience:print(f"早停触发(连续{config.patience}轮无提升)")break# 训练结束end_time = time.time()elapsed_time = end_time - start_timehours = int(elapsed_time // 3600)minutes = int((elapsed_time % 3600) // 60)seconds = int(elapsed_time % 60)print(f"\n训练结束!总用时:{hours}小时{minutes}分钟{seconds}秒")print(f"最佳验证集F1: {best_val_f1:.4f}")# 可视化训练指标actual_epochs = len(train_losses)plot_training_metrics(actual_epochs,train_losses, val_losses,train_accs, val_accs,train_f1s, val_f1s,config.fig_save_path)if __name__ == "__main__":main()
任务三:一个等级分类任务
import os
import time
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
from torch.utils.data import DataLoader
from torch.cuda.amp import GradScaler, autocast
from torchvision import transforms, models
from torchvision.models import ResNet18_Weights
from tqdm import tqdm
from sklearn.metrics import accuracy_score, f1_score, classification_report, confusion_matrix
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import json
import gc
import seaborn as sns
from datetime import datetime# 设置matplotlib中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False# 使用绝对路径
BASE_DIR = r"D:\game\1"class Config:# 路径配置train_data_dir = os.path.join(BASE_DIR, "images", "images3")val_data_dir = os.path.join(BASE_DIR, "images", "images4")train_json_path = os.path.join(BASE_DIR, "training_images.json")val_json_path = os.path.join(BASE_DIR, "validation_images.json")# 任务参数 - 三分类病害严重程度num_classes = 3class_names = ['健康', '一般疾病', '严重疾病']# 训练参数 - 关键修复:更安全的参数设置batch_size = 16 # 调整为更小的batch size epochs = 50learning_rate = 1e-5 # 调整学习率weight_decay = 1e-4label_smoothing = 0.0 # 暂时禁用标签平滑# 模型参数dropout_rate = 0.2patience = 10# 数据加载参数num_workers = 0pin_memory = Falsedevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")save_path = os.path.join(BASE_DIR, "best_disease_severity_model.pth")# 新增可视化文件路径fig_save_path = os.path.join(BASE_DIR, "training_metrics.png")confusion_matrix_path = os.path.join(BASE_DIR, "confusion_matrix.png")metrics_report_path = os.path.join(BASE_DIR, "metrics_report.txt")def ensure_directories(self):"""确保所有必要的目录存在"""directories = [os.path.dirname(self.save_path),os.path.dirname(self.fig_save_path),self.train_data_dir,self.val_data_dir]for dir_path in directories:if dir_path and not os.path.exists(dir_path):try:os.makedirs(dir_path, exist_ok=True)print(f"✓ 创建目录: {dir_path}")except Exception as e:print(f"✗ 创建目录失败 {dir_path}: {e}")config = Config()# 完整的标签名称列表(61个类别)
label_names = ["苹果 - 健康", "苹果 - 黑星病(轻度)", "苹果 - 黑星病(重度)", "苹果 - 蛙眼斑病","苹果 - 锈病(轻度)", "苹果 - 锈病(重度)", "樱桃 - 健康", "樱桃 - 白粉病(轻度)","樱桃 - 白粉病(重度)", "玉米 - 健康", "玉米 - 灰斑病(轻度)", "玉米 - 灰斑病(重度)","玉米 - 多堆柄锈菌病(轻度)", "玉米 - 多堆柄锈菌病(重度)", "玉米 - 弯孢霉叶斑病(真菌性,轻度)","玉米 - 弯孢霉叶斑病(真菌性,重度)", "玉米 - 矮花叶病毒病", "葡萄 - 健康","葡萄 - 黑腐病(真菌性,轻度)", "葡萄 - 黑腐病(真菌性,重度)", "葡萄 - 黑痘病(真菌性,轻度)","葡萄 - 黑痘病(真菌性,重度)", "葡萄 - 叶枯病(真菌性,轻度)", "葡萄 - 叶枯病(真菌性,重度)","柑橘 - 健康", "柑橘 - 黄龙病(轻度)", "柑橘 - 黄龙病(重度)", "桃子 - 健康","桃子 - 细菌性斑点病(轻度)", "桃子 - 细菌性斑点病(重度)", "辣椒 - 健康","辣椒 - 疮痂病(轻度)", "辣椒 - 疮痂病(重度)", "马铃薯 - 健康","马铃薯 - 早疫病(真菌性,轻度)", "马铃薯 - 早疫病(真菌性,重度)","马铃薯 - 晚疫病(真菌性,轻度)", "马铃薯 - 晚疫病(真菌性,重度)", "草莓 - 健康","草莓 - 焦枯病(轻度)", "草莓 - 焦枯病(重度)", "番茄 - 健康", "番茄 - 白粉病(轻度)","番茄 - 白粉病(重度)", "番茄 - 细菌性斑点病(细菌性,轻度)", "番茄 - 细菌性斑点病(细菌性,重度)","番茄 - 早疫病(真菌性,轻度)", "番茄 - 早疫病(真菌性,重度)", "番茄 - 晚疫病(卵菌性,轻度)","番茄 - 晚疫病(卵菌性,重度)", "番茄 - 叶霉病(真菌性,轻度)", "番茄 - 叶霉病(真菌性,重度)","番茄 - 靶斑病(细菌性,轻度)", "番茄 - 靶斑病(细菌性,重度)", "番茄 - 早疫叶斑病(真菌性,轻度)","番茄 - 早疫叶斑病(真菌性,重度)", "番茄 - 叶螨危害(轻度)", "番茄 - 叶螨危害(重度)","番茄 - 黄化曲叶病毒病(轻度)", "番茄 - 黄化曲叶病毒病(重度)", "番茄 - 花叶病毒病"
]def map_disease_to_severity_3class(disease_label):"""将病害标签映射到严重程度等级(三分类)"""if not isinstance(disease_label, str):print(f"错误: disease_label 不是字符串: {type(disease_label)}")return 1 # 默认为一般疾病if '健康' in disease_label:return 0 # 健康elif '重度' in disease_label:return 2 # 严重疾病else:return 1 # 一般疾病# 为所有61个类别创建映射
print("开始创建标签映射...")
label_id_to_severity = {}
for label_id, label_name in enumerate(label_names):severity_level = map_disease_to_severity_3class(label_name)label_id_to_severity[label_id] = severity_levelif label_id < 10: # 只显示前10个标签的映射print(f"原始标签 {label_id}: '{label_name}' -> 严重程度: {severity_level}")print(f"标签映射完成,共映射 {len(label_id_to_severity)} 个标签")# 关键修复:安全的数据预处理
def get_safe_transforms(is_train=True):"""安全的数据增强,使用更保守的参数"""if is_train:return transforms.Compose([transforms.Resize((256, 256)),transforms.RandomCrop(224),transforms.RandomHorizontalFlip(p=0.2),transforms.ToTensor(),# 使用更安全的归一化参数transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])else:return transforms.Compose([transforms.Resize((256, 256)),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])def simple_collate_fn(batch):"""简化的collate函数"""batch = [item for item in batch if item[0] is not None and item[1] is not None]if len(batch) == 0:return torch.tensor([]), torch.tensor([])try:images, labels = zip(*batch)images = torch.stack(images, 0)labels = torch.tensor(labels)return images, labelsexcept Exception as e:print(f"堆叠张量失败: {e}")return torch.tensor([]), torch.tensor([])class SafeDiseaseDataset(torch.utils.data.Dataset):def __init__(self, data_dir, json_path, transform=None, mode='train'):self.data_dir = data_dirself.json_path = json_pathself.transform = transformself.mode = modeself.samples = []print(f"初始化{mode}数据集...")self._load_samples()def _load_samples(self):"""加载样本"""try:with open(self.json_path, 'r', encoding='utf-8') as f:json_data = json.load(f)valid_count = 0for i, item in enumerate(json_data):if isinstance(item, dict) and 'disease_class' in item and 'image_id' in item:image_id = item['image_id']original_label_id = item['disease_class']# 验证标签IDif not isinstance(original_label_id, int) or original_label_id < 0 or original_label_id >= len(label_names):continue# 映射到严重程度severity_level = label_id_to_severity.get(original_label_id, 1)# 构建图像路径image_path = os.path.join(self.data_dir, image_id)# 检查文件是否存在if not os.path.exists(image_path):base_name = os.path.splitext(image_path)[0]for ext in ['.jpg', '.JPG', '.jpeg', '.JPEG', '.png', '.PNG']:alt_path = base_name + extif os.path.exists(alt_path):image_path = alt_pathbreakif os.path.exists(image_path):self.samples.append((image_path, severity_level))valid_count += 1print(f"从JSON加载了 {valid_count} 个有效样本")except Exception as e:print(f"加载JSON文件失败: {e}")def __len__(self):return len(self.samples)def __getitem__(self, idx):try:img_path, severity_val = self.samples[idx]image = Image.open(img_path).convert('RGB')if self.transform:image = self.transform(image)# 检查数据范围if torch.isnan(image).any() or torch.isinf(image).any():return None, Nonereturn image, severity_valexcept Exception as e:return None, None# 关键修复:更安全的模型架构
class VerySafeModel(nn.Module):def __init__(self, num_classes=3):super().__init__()# 使用预训练模型self.backbone = models.resnet18(weights=ResNet18_Weights.IMAGENET1K_V1)# 冻结大部分层for param in list(self.backbone.parameters())[:-30]:param.requires_grad = Falsein_features = self.backbone.fc.in_features# 更简单的分类头self.backbone.fc = nn.Sequential(nn.Dropout(0.2),nn.Linear(in_features, 512),nn.BatchNorm1d(512),nn.ReLU(inplace=True),nn.Dropout(0.2),nn.Linear(512, num_classes))# 安全的权重初始化self._initialize_weights()def _initialize_weights(self):"""安全的权重初始化"""for m in self.backbone.fc.modules():if isinstance(m, nn.Linear):nn.init.kaiming_normal_(m.weight)nn.init.constant_(m.bias, 0)def forward(self, x):return self.backbone(x)# 新增:完整的训练函数,包含指标计算
def train_epoch_with_metrics(model, train_loader, criterion, optimizer, device):"""训练函数,包含完整的指标计算"""model.train()total_loss = 0.0all_preds = []all_labels = []total_samples = 0valid_batches = 0progress_bar = tqdm(train_loader, desc="训练")for batch_idx, (imgs, labels) in enumerate(progress_bar):if len(imgs) == 0:continueimgs, labels = imgs.to(device), labels.to(device)# 检查数据if torch.isnan(imgs).any() or torch.isinf(imgs).any():continueif labels.min() < 0 or labels.max() >= config.num_classes:continueoptimizer.zero_grad()try:outputs = model(imgs)if torch.isnan(outputs).any() or torch.isinf(outputs).any():continueloss = criterion(outputs, labels)if torch.isnan(loss) or torch.isinf(loss):continueloss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)optimizer.step()# 计算预测结果preds = torch.argmax(outputs, dim=1).cpu().numpy()all_preds.extend(preds)all_labels.extend(labels.cpu().numpy())total_loss += loss.item() * imgs.size(0)total_samples += imgs.size(0)valid_batches += 1# 更新进度条if len(all_labels) > 0:current_acc = accuracy_score(all_labels, all_preds)progress_bar.set_postfix({'loss': f'{loss.item():.4f}','acc': f'{current_acc:.3f}'})except Exception as e:continueif batch_idx % 50 == 0:torch.cuda.empty_cache() if torch.cuda.is_available() else gc.collect()if valid_batches == 0:return float('nan'), 0.0, 0.0, 0.0, [], []epoch_loss = total_loss / total_samples# 计算各种指标if len(all_labels) > 0:epoch_acc = accuracy_score(all_labels, all_preds)epoch_f1 = f1_score(all_labels, all_preds, average='macro')epoch_f1_weighted = f1_score(all_labels, all_preds, average='weighted')else:epoch_acc, epoch_f1, epoch_f1_weighted = 0.0, 0.0, 0.0return epoch_loss, epoch_acc, epoch_f1, epoch_f1_weighted, all_preds, all_labels# 新增:完整的验证函数,包含详细指标
def validate_with_metrics(model, val_loader, criterion, device):"""验证函数,包含详细的指标计算"""model.eval()total_loss = 0.0all_preds = []all_labels = []total_samples = 0with torch.no_grad():progress_bar = tqdm(val_loader, desc="验证")for batch_idx, (imgs, labels) in enumerate(progress_bar):if len(imgs) == 0:continueimgs, labels = imgs.to(device), labels.to(device)try:outputs = model(imgs)loss = criterion(outputs, labels)if not torch.isnan(loss) and not torch.isinf(loss):preds = torch.argmax(outputs, dim=1).cpu().numpy()all_preds.extend(preds)all_labels.extend(labels.cpu().numpy())total_loss += loss.item() * imgs.size(0)total_samples += imgs.size(0)except Exception as e:continueif total_samples == 0:return float('nan'), 0.0, 0.0, 0.0, {}, [], []val_loss = total_loss / total_samples# 计算详细指标if len(all_labels) > 0:val_acc = accuracy_score(all_labels, all_preds)val_f1_macro = f1_score(all_labels, all_preds, average='macro')val_f1_weighted = f1_score(all_labels, all_preds, average='weighted')# 分类报告class_report = classification_report(all_labels, all_preds,target_names=config.class_names,output_dict=True, zero_division=0)# 计算每个类别的指标class_metrics = {}for i, class_name in enumerate(config.class_names):if str(i) in class_report:class_metrics[class_name] = {'precision': class_report[str(i)]['precision'],'recall': class_report[str(i)]['recall'],'f1-score': class_report[str(i)]['f1-score'],'support': class_report[str(i)]['support']}else:val_acc, val_f1_macro, val_f1_weighted = 0.0, 0.0, 0.0class_report = {}class_metrics = {}return val_loss, val_acc, val_f1_macro, val_f1_weighted, class_metrics, all_preds, all_labels# 新增:可视化函数
def plot_training_metrics(history, save_path):"""绘制训练指标图表"""fig, axes = plt.subplots(2, 2, figsize=(15, 10))epochs = range(1, len(history['train_loss']) + 1)# 损失曲线axes[0, 0].plot(epochs, history['train_loss'], 'b-', label='训练损失', linewidth=2)axes[0, 0].plot(epochs, history['val_loss'], 'r-', label='验证损失', linewidth=2)axes[0, 0].set_title('训练和验证损失')axes[0, 0].set_xlabel('Epoch')axes[0, 0].set_ylabel('Loss')axes[0, 0].legend()axes[0, 0].grid(True)# 准确率曲线axes[0, 1].plot(epochs, history['train_acc'], 'b-', label='训练准确率', linewidth=2)axes[0, 1].plot(epochs, history['val_acc'], 'r-', label='验证准确率', linewidth=2)axes[0, 1].set_title('训练和验证准确率')axes[0, 1].set_xlabel('Epoch')axes[0, 1].set_ylabel('Accuracy')axes[0, 1].set_ylim(0, 1)axes[0, 1].legend()axes[0, 1].grid(True)# F1分数曲线axes[1, 0].plot(epochs, history['train_f1_macro'], 'b-', label='训练F1(macro)', linewidth=2)axes[1, 0].plot(epochs, history['val_f1_macro'], 'r-', label='验证F1(macro)', linewidth=2)axes[1, 0].plot(epochs, history['train_f1_weighted'], 'b--', label='训练F1(weighted)', linewidth=2)axes[1, 0].plot(epochs, history['val_f1_weighted'], 'r--', label='验证F1(weighted)', linewidth=2)axes[1, 0].set_title('训练和验证F1分数')axes[1, 0].set_xlabel('Epoch')axes[1, 0].set_ylabel('F1 Score')axes[1, 0].set_ylim(0, 1)axes[1, 0].legend()axes[1, 0].grid(True)# 学习率曲线axes[1, 1].plot(epochs, history['learning_rate'], 'g-', label='学习率', linewidth=2)axes[1, 1].set_title('学习率变化')axes[1, 1].set_xlabel('Epoch')axes[1, 1].set_ylabel('Learning Rate')axes[1, 1].set_yscale('log')axes[1, 1].legend()axes[1, 1].grid(True)plt.tight_layout()plt.savefig(save_path, dpi=300, bbox_inches='tight')plt.show()# 新增:绘制混淆矩阵
def plot_confusion_matrix(true_labels, predictions, class_names, save_path):"""绘制混淆矩阵"""cm = confusion_matrix(true_labels, predictions)plt.figure(figsize=(8, 6))sns.heatmap(cm, annot=True, fmt='d', cmap='Blues',xticklabels=class_names, yticklabels=class_names)plt.title('混淆矩阵')plt.xlabel('预测标签')plt.ylabel('真实标签')plt.tight_layout()plt.savefig(save_path, dpi=300, bbox_inches='tight')plt.show()# 新增:保存指标报告
def save_metrics_report(history, final_metrics, class_metrics, save_path):"""保存详细的指标报告"""with open(save_path, 'w', encoding='utf-8') as f:f.write("=== 病害严重程度分类模型训练报告 ===\n")f.write(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n\n")f.write("最终评估指标:\n")f.write(f"验证准确率: {final_metrics['val_acc']:.4f}\n")f.write(f"宏平均F1分数: {final_metrics['val_f1_macro']:.4f}\n")f.write(f"加权平均F1分数: {final_metrics['val_f1_weighted']:.4f}\n")f.write(f"验证损失: {final_metrics['val_loss']:.4f}\n\n")f.write("各类别详细指标:\n")for class_name, metrics in class_metrics.items():f.write(f"{class_name}:\n")f.write(f" 精确率: {metrics['precision']:.4f}\n")f.write(f" 召回率: {metrics['recall']:.4f}\n")f.write(f" F1分数: {metrics['f1-score']:.4f}\n")f.write(f" 样本数: {metrics['support']}\n\n")f.write("训练过程统计:\n")f.write(f"总训练轮次: {len(history['train_loss'])}\n")f.write(f"最佳验证准确率: {max(history['val_acc']):.4f}\n")f.write(f"最佳验证F1分数: {max(history['val_f1_macro']):.4f}\n")def main():print("=== 病害严重程度分级预测训练开始(增强可视化版)===")config.ensure_directories()print(f"设备: {config.device}")print(f"工作目录: {BASE_DIR}")# 检查路径paths_to_check = {"训练数据目录": config.train_data_dir,"验证数据目录": config.val_data_dir,"训练JSON文件": config.train_json_path,"验证JSON文件": config.val_json_path}for name, path in paths_to_check.items():exists = os.path.exists(path)status = "存在" if exists else "不存在"print(f"{name}: {status}")if not all(os.path.exists(path) for path in[config.train_data_dir, config.val_data_dir, config.train_json_path, config.val_json_path]):print("错误: 必要的文件或目录不存在")return# 创建数据集print("\n创建数据集...")train_dataset = SafeDiseaseDataset(config.train_data_dir, config.train_json_path,get_safe_transforms(is_train=True), 'train')val_dataset = SafeDiseaseDataset(config.val_data_dir, config.val_json_path,get_safe_transforms(is_train=False), 'val')if len(train_dataset) == 0:print("错误: 训练数据集为空")returnprint(f"训练样本: {len(train_dataset)}, 验证样本: {len(val_dataset)}")# 创建DataLoader# 初始化模型model = VerySafeModel(config.num_classes).to(config.device)# 优化器和损失函数optimizer = optim.AdamW(model.parameters(),lr=config.learning_rate,weight_decay=config.weight_decay)scheduler = CosineAnnealingLR(optimizer, T_max=config.epochs)criterion = nn.CrossEntropyLoss()# 训练历史记录history = {'train_loss': [], 'val_loss': [],'train_acc': [], 'val_acc': [],'train_f1_macro': [], 'val_f1_macro': [],'train_f1_weighted': [], 'val_f1_weighted': [],'learning_rate': []}best_val_acc = 0.0early_stop_counter = 0print("\n开始训练...")start_time = time.time()for epoch in range(config.epochs):print(f"\nEpoch {epoch + 1}/{config.epochs}")# 训练train_loss, train_acc, train_f1_macro, train_f1_weighted, _, _ = train_epoch_with_metrics(model, train_loader, criterion, optimizer, config.device)# 验证val_loss, val_acc, val_f1_macro, val_f1_weighted, class_metrics, val_preds, val_labels = validate_with_metrics(model, val_loader, criterion, config.device)# 学习率调整scheduler.step()current_lr = optimizer.param_groups[0]['lr']# 记录历史if not np.isnan(train_loss):history['train_loss'].append(train_loss)history['val_loss'].append(val_loss)history['train_acc'].append(train_acc)history['val_acc'].append(val_acc)history['train_f1_macro'].append(train_f1_macro)history['val_f1_macro'].append(val_f1_macro)history['train_f1_weighted'].append(train_f1_weighted)history['val_f1_weighted'].append(val_f1_weighted)history['learning_rate'].append(current_lr)# 打印指标print(f"训练损失: {train_loss:.4f}, 准确率: {train_acc:.4f}, F1(macro): {train_f1_macro:.4f}")print(f"验证损失: {val_loss:.4f}, 准确率: {val_acc:.4f}, F1(macro): {val_f1_macro:.4f}")print(f"学习率: {current_lr:.2e}")# 保存最佳模型if not np.isnan(val_acc) and val_acc > best_val_acc:best_val_acc = val_accearly_stop_counter = 0torch.save(model.state_dict(), config.save_path)print(f"保存最佳模型(验证准确率: {val_acc:.4f})")# 保存最终预测结果用于可视化final_preds = val_predsfinal_labels = val_labelsfinal_class_metrics = class_metricselse:early_stop_counter += 1# 早停if early_stop_counter >= config.patience:print(f"早停触发(连续{config.patience}轮无提升)")break# 训练完成end_time = time.time()training_time = end_time - start_timeprint(f"\n训练完成!总用时: {training_time:.2f}秒")# 可视化if len(history['train_loss']) > 0:print("\n生成可视化图表...")# 绘制训练指标plot_training_metrics(history, config.fig_save_path)# 绘制混淆矩阵if 'final_preds' in locals() and 'final_labels' in locals():plot_confusion_matrix(final_labels, final_preds, config.class_names, config.confusion_matrix_path)# 保存指标报告final_metrics = {'val_loss': history['val_loss'][-1],'val_acc': history['val_acc'][-1],'val_f1_macro': history['val_f1_macro'][-1],'val_f1_weighted': history['val_f1_weighted'][-1]}save_metrics_report(history, final_metrics, final_class_metrics, config.metrics_report_path)print("可视化完成!")print(f"训练曲线图: {config.fig_save_path}")print(f"混淆矩阵图: {config.confusion_matrix_path}")print(f"指标报告: {config.metrics_report_path}")if __name__ == "__main__":main()
任务四:
import os
import time
import torch
import torch.nn as nn
import torch.optim as optim
from torch.optim.lr_scheduler import CosineAnnealingLR
from torch.utils.data import DataLoader
from torch.cuda.amp import GradScaler, autocast
from torchvision import transforms, models
from torchvision.models import ResNet18_Weights
from tqdm import tqdm
from sklearn.metrics import accuracy_score, f1_score, classification_report, confusion_matrix
import numpy as np
import matplotlib.pyplot as plt
from PIL import Image
import json
import gc
import seaborn as sns
from datetime import datetime# 设置matplotlib中文字体
plt.rcParams["font.family"] = ["SimHei", "WenQuanYi Micro Hei", "Heiti TC"]
plt.rcParams["axes.unicode_minus"] = False# 使用第一个代码的路径结构
BASE_DIR = r"D:\game\1"class MultiTaskConfig:def __init__(self):# 路径配置 - 使用第一个代码的路径结构self.train_data_dir = os.path.join(BASE_DIR, "images", "images3")self.val_data_dir = os.path.join(BASE_DIR, "images", "images4")self.train_json_path = os.path.join(BASE_DIR, "training_images.json")self.val_json_path = os.path.join(BASE_DIR, "validation_images.json")# 模型保存路径self.model_save_path = os.path.join(BASE_DIR, "multitask_best_model.pth")self.result_dir = os.path.join(BASE_DIR, "multitask_results")# 任务参数self.num_disease_classes = 61 # 病害分类(61个类别)self.num_severity_classes = 3 # 严重程度分级(健康、一般、严重)# 训练参数self.batch_size = 16self.epochs = 50self.learning_rate = 1e-5self.weight_decay = 1e-4self.device = torch.device("cuda" if torch.cuda.is_available() else "cpu")# 病害类别名称(61个类别)self.disease_names = ["苹果-健康", "苹果-黑星病(轻度)", "苹果-黑星病(重度)", "苹果-蛙眼斑病","苹果-锈病(轻度)", "苹果-锈病(重度)", "樱桃-健康", "樱桃-白粉病(轻度)","樱桃-白粉病(重度)", "玉米-健康", "玉米-灰斑病(轻度)", "玉米-灰斑病(重度)","玉米-多堆柄锈菌病(轻度)", "玉米-多堆柄锈菌病(重度)", "玉米-弯孢霉叶斑病(真菌性,轻度)","玉米-弯孢霉叶斑病(真菌性,重度)", "玉米-矮花叶病毒病", "葡萄-健康","葡萄-黑腐病(真菌性,轻度)", "葡萄-黑腐病(真菌性,重度)", "葡萄-黑痘病(真菌性,轻度)","葡萄-黑痘病(真菌性,重度)", "葡萄-叶枯病(真菌性,轻度)", "葡萄-叶枯病(真菌性,重度)","柑橘-健康", "柑橘-黄龙病(轻度)", "柑橘-黄龙病(重度)", "桃子-健康","桃子-细菌性斑点病(轻度)", "桃子-细菌性斑点病(重度)", "辣椒-健康","辣椒-疮痂病(轻度)", "辣椒-疮痂病(重度)", "马铃薯-健康","马铃薯-早疫病(真菌性,轻度)", "马铃薯-早疫病(真菌性,重度)","马铃薯-晚疫病(真菌性,轻度)", "马铃薯-晚疫病(真菌性,重度)", "草莓-健康","草莓-焦枯病(轻度)", "草莓-焦枯病(重度)", "番茄-健康", "番茄-白粉病(轻度)","番茄-白粉病(重度)", "番茄-细菌性斑点病(细菌性,轻度)", "番茄-细菌性斑点病(细菌性,重度)","番茄-早疫病(真菌性,轻度)", "番茄-早疫病(真菌性,重度)", "番茄-晚疫病(卵菌性,轻度)","番茄-晚疫病(卵菌性,重度)", "番茄-叶霉病(真菌性,轻度)", "番茄-叶霉病(真菌性,重度)","番茄-靶斑病(细菌性,轻度)", "番茄-靶斑病(细菌性,重度)", "番茄-早疫叶斑病(真菌性,轻度)","番茄-早疫叶斑病(真菌性,重度)", "番茄-叶螨危害(轻度)", "番茄-叶螨危害(重度)","番茄-黄化曲叶病毒病(轻度)", "番茄-黄化曲叶病毒病(重度)", "番茄-花叶病毒病"]self.severity_names = ['健康', '一般疾病', '严重疾病']# 可视化文件路径self.training_plot_path = os.path.join(self.result_dir, "multitask_training_metrics.png")self.confusion_matrix_path = os.path.join(self.result_dir, "multitask_confusion_matrices.png")self.diagnostic_report_path = os.path.join(self.result_dir, "diagnostic_reports.json")self.synergy_report_path = os.path.join(self.result_dir, "synergy_analysis_report.json")self.metrics_report_path = os.path.join(self.result_dir, "detailed_metrics_report.txt")# 创建必要的目录self._create_directories()def _create_directories(self):"""创建所有必要的目录"""directories = [self.result_dir,os.path.dirname(self.model_save_path),self.train_data_dir,self.val_data_dir]for dir_path in directories:if dir_path and not os.path.exists(dir_path):try:os.makedirs(dir_path, exist_ok=True)print(f"✓ 创建目录: {dir_path}")except Exception as e:print(f"✗ 创建目录失败 {dir_path}: {e}")config = MultiTaskConfig()# -------------------------- 可解释性诊断报告生成器 --------------------------
class DiagnosticReportGenerator:def __init__(self, disease_names, severity_names):self.disease_names = disease_namesself.severity_names = severity_namesdef generate_detailed_report(self, image_id, disease_pred, severity_pred, disease_probs, severity_probs, disease_true=None, severity_true=None):"""生成详细的可解释性诊断报告"""# 基础诊断信息report = {"image_id": image_id,"timestamp": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),"diagnostic_results": {"disease_prediction": {"predicted_class": int(disease_pred),"predicted_class_name": self.disease_names[disease_pred],"confidence_score": float(disease_probs[disease_pred]),"top_3_predictions": self._get_top_predictions(disease_probs, self.disease_names, 3)},"severity_prediction": {"predicted_level": int(severity_pred),"predicted_level_name": self.severity_names[severity_pred],"confidence_score": float(severity_probs[severity_pred]),"all_level_confidences": {self.severity_names[i]: float(severity_probs[i]) for i in range(len(self.severity_names))}}},"interpretation_analysis": self._generate_interpretation(disease_pred, severity_pred, disease_probs[disease_pred]),"treatment_recommendations": self._generate_recommendations(severity_pred)}# 如果提供了真实标签,添加评估信息if disease_true is not None and severity_true is not None:report["evaluation"] = {"ground_truth": {"true_disease_class": int(disease_true),"true_disease_name": self.disease_names[disease_true],"true_severity_level": int(severity_true),"true_severity_name": self.severity_names[severity_true]},"accuracy_assessment": {"disease_correct": bool(disease_pred == disease_true),"severity_correct": bool(severity_pred == severity_true),"overall_correct": bool(disease_pred == disease_true and severity_pred == severity_true)}}return reportdef _get_top_predictions(self, probs, class_names, top_k=3):"""获取Top-K预测结果"""top_indices = np.argsort(probs)[-top_k:][::-1]return [{"class_name": class_names[i],"confidence": float(probs[i]),"rank": rank + 1}for rank, i in enumerate(top_indices)]def _generate_interpretation(self, disease_pred, severity_pred, confidence):"""生成诊断解释分析"""interpretations = []# 置信度分析if confidence > 0.9:confidence_level = "极高置信度"interpretation = "模型对该诊断结果非常有信心,可靠性高"elif confidence > 0.7:confidence_level = "高置信度"interpretation = "模型诊断结果可信度较高"elif confidence > 0.5:confidence_level = "中等置信度"interpretation = "诊断结果具有一定参考价值,建议结合其他信息判断"else:confidence_level = "低置信度"interpretation = "模型诊断不确定性较高,强烈建议人工复核"interpretations.append({"confidence_level": confidence_level,"interpretation": interpretation,"numerical_confidence": float(confidence)})# 严重程度分析severity_analysis = {"level": severity_pred,"level_name": self.severity_names[severity_pred],"implications": self._get_severity_implications(severity_pred)}interpretations.append(severity_analysis)return interpretationsdef _get_severity_implications(self, severity_level):"""根据严重程度生成影响分析"""if severity_level == 0: # 健康return ["植株生长状态良好", "无需特殊处理", "建议定期观察"]elif severity_level == 1: # 一般疾病return ["需要预防性处理", "建议加强监测", "可能影响作物产量"]else: # 严重疾病return ["需要立即治疗", "可能造成严重减产", "建议专业农技人员介入"]def _generate_recommendations(self, severity_level):"""生成治疗建议"""base_recommendations = {"monitoring": "建议持续观察植株变化","record_keeping": "记录诊断结果和处理措施"}if severity_level == 0:base_recommendations.update({"action": "维持当前管理措施","frequency": "每周检查一次","urgency": "低"})elif severity_level == 1:base_recommendations.update({"action": "实施预防性防治措施","frequency": "每3天检查一次","urgency": "中","suggestions": ["使用生物农药", "调整灌溉方案", "增强通风"]})else:base_recommendations.update({"action": "立即采取综合防治措施","frequency": "每日检查","urgency": "高","suggestions": ["使用高效化学农药", "隔离病株", "咨询专业农技人员"]})return base_recommendations# -------------------------- 多任务数据集类 --------------------------
class MultiTaskDiseaseDataset(torch.utils.data.Dataset):def __init__(self, data_dir, json_path, transform=None, mode='train'):self.data_dir = data_dirself.json_path = json_pathself.transform = transformself.mode = modeself.samples = []print(f"初始化{mode}数据集...")self._load_samples()def _load_samples(self):"""加载样本数据"""try:with open(self.json_path, 'r', encoding='utf-8') as f:json_data = json.load(f)valid_count = 0for item in json_data:if isinstance(item, dict) and 'disease_class' in item and 'image_id' in item:image_id = item['image_id']disease_label = item['disease_class']# 验证病害标签if not isinstance(disease_label, int) or disease_label < 0 or disease_label >= len(config.disease_names):continue# 计算严重程度标签disease_name = config.disease_names[disease_label]if '健康' in disease_name:severity_label = 0 # 健康elif '重度' in disease_name:severity_label = 2 # 严重疾病else:severity_label = 1 # 一般疾病# 构建图像路径image_path = os.path.join(self.data_dir, image_id)# 检查文件是否存在(支持多种扩展名)if not os.path.exists(image_path):base_name = os.path.splitext(image_path)[0]for ext in ['.jpg', '.JPG', '.jpeg', '.JPEG', '.png', '.PNG']:alt_path = base_name + extif os.path.exists(alt_path):image_path = alt_pathbreakif os.path.exists(image_path):self.samples.append({'image_path': image_path,'disease_label': disease_label,'severity_label': severity_label})valid_count += 1print(f"从JSON加载了 {valid_count} 个有效样本")except Exception as e:print(f"加载JSON文件失败: {e}")def __len__(self):return len(self.samples)def __getitem__(self, idx):try:sample = self.samples[idx]image_path = sample['image_path']disease_label = sample['disease_label']severity_label = sample['severity_label']# 加载图像image = Image.open(image_path).convert('RGB')if self.transform:image = self.transform(image)# 检查数据有效性if torch.isnan(image).any() or torch.isinf(image).any():return None, None, Nonereturn image, disease_label, severity_labelexcept Exception as e:return None, None, None# -------------------------- 多任务模型架构 --------------------------
class MultiTaskResNet(nn.Module):def __init__(self, num_disease_classes, num_severity_classes):super().__init__()# 共享的特征提取器(使用ResNet18)self.backbone = models.resnet18(weights=ResNet18_Weights.IMAGENET1K_V1)# 冻结前面的层,只训练最后几层for param in list(self.backbone.parameters())[:-30]:param.requires_grad = False# 获取特征维度in_features = self.backbone.fc.in_features# 共享特征层self.shared_features = nn.Sequential(nn.Dropout(0.3),nn.Linear(in_features, 512),nn.BatchNorm1d(512),nn.ReLU(inplace=True),nn.Dropout(0.2))# 病害分类头self.disease_classifier = nn.Sequential(nn.Linear(512, 256),nn.BatchNorm1d(256),nn.ReLU(inplace=True),nn.Dropout(0.1),nn.Linear(256, num_disease_classes))# 严重程度分类头self.severity_classifier = nn.Sequential(nn.Linear(512, 128),nn.BatchNorm1d(128),nn.ReLU(inplace=True),nn.Dropout(0.1),nn.Linear(128, num_severity_classes))# 移除原始分类器self.backbone.fc = nn.Identity()# 初始化权重self._initialize_weights()def _initialize_weights(self):"""权重初始化"""for module in [self.disease_classifier, self.severity_classifier]:for m in module.modules():if isinstance(m, nn.Linear):nn.init.kaiming_normal_(m.weight)nn.init.constant_(m.bias, 0)def forward(self, x):# 基础特征提取features = self.backbone(x)# 共享特征shared_features = self.shared_features(features)# 多任务输出disease_output = self.disease_classifier(shared_features)severity_output = self.severity_classifier(shared_features)return disease_output, severity_output# -------------------------- 数据预处理 --------------------------
def get_multitask_transforms(is_train=True):"""获取多任务学习的数据预处理"""if is_train:return transforms.Compose([transforms.Resize((256, 256)),transforms.RandomCrop(224),transforms.RandomHorizontalFlip(p=0.3),transforms.RandomRotation(10),transforms.ColorJitter(brightness=0.2, contrast=0.2),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])else:return transforms.Compose([transforms.Resize((256, 256)),transforms.CenterCrop(224),transforms.ToTensor(),transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])])def multitask_collate_fn(batch):"""多任务学习的collate函数"""batch = [item for item in batch if item[0] is not None and item[1] is not None and item[2] is not None]if len(batch) == 0:return torch.tensor([]), torch.tensor([]), torch.tensor([])try:images, disease_labels, severity_labels = zip(*batch)images = torch.stack(images, 0)disease_labels = torch.tensor(disease_labels)severity_labels = torch.tensor(severity_labels)return images, disease_labels, severity_labelsexcept Exception as e:print(f"堆叠张量失败: {e}")return torch.tensor([]), torch.tensor([]), torch.tensor([])# -------------------------- 多任务训练函数 --------------------------
def train_multitask_epoch(model, train_loader, criterion_disease, criterion_severity, optimizer, device, alpha=0.7):"""多任务训练epoch"""model.train()total_disease_loss = 0.0total_severity_loss = 0.0total_loss = 0.0disease_correct = 0severity_correct = 0total_samples = 0all_disease_preds = []all_disease_labels = []all_severity_preds = []all_severity_labels = []progress_bar = tqdm(train_loader, desc="多任务训练")for batch_idx, (images, disease_labels, severity_labels) in enumerate(progress_bar):if len(images) == 0:continueimages = images.to(device)disease_labels = disease_labels.to(device)severity_labels = severity_labels.to(device)# 数据验证if (torch.isnan(images).any() or torch.isinf(images).any() ordisease_labels.min() < 0 or disease_labels.max() >= config.num_disease_classes orseverity_labels.min() < 0 or severity_labels.max() >= config.num_severity_classes):continueoptimizer.zero_grad()try:# 前向传播disease_output, severity_output = model(images)# 计算损失disease_loss = criterion_disease(disease_output, disease_labels)severity_loss = criterion_severity(severity_output, severity_labels)# 加权总损失(可调节的任务权重)total_batch_loss = alpha * disease_loss + (1 - alpha) * severity_loss# 反向传播total_batch_loss.backward()torch.nn.utils.clip_grad_norm_(model.parameters(), max_norm=1.0)optimizer.step()# 统计信息total_disease_loss += disease_loss.item() * images.size(0)total_severity_loss += severity_loss.item() * images.size(0)total_loss += total_batch_loss.item() * images.size(0)# 预测结果_, disease_preds = torch.max(disease_output, 1)_, severity_preds = torch.max(severity_output, 1)disease_correct += (disease_preds == disease_labels).sum().item()severity_correct += (severity_preds == severity_labels).sum().item()total_samples += images.size(0)# 收集预测结果all_disease_preds.extend(disease_preds.cpu().numpy())all_disease_labels.extend(disease_labels.cpu().numpy())all_severity_preds.extend(severity_preds.cpu().numpy())all_severity_labels.extend(severity_labels.cpu().numpy())# 更新进度条if len(all_disease_labels) > 0:current_disease_acc = accuracy_score(all_disease_labels, all_disease_preds)current_severity_acc = accuracy_score(all_severity_labels, all_severity_preds)progress_bar.set_postfix({'disease_acc': f'{current_disease_acc:.3f}','severity_acc': f'{current_severity_acc:.3f}','total_loss': f'{total_batch_loss.item():.4f}'})except Exception as e:continueif batch_idx % 50 == 0:torch.cuda.empty_cache() if torch.cuda.is_available() else gc.collect()if total_samples == 0:return float('nan'), float('nan'), float('nan'), 0.0, 0.0, 0.0, 0.0# 计算平均指标avg_total_loss = total_loss / total_samplesavg_disease_loss = total_disease_loss / total_samplesavg_severity_loss = total_severity_loss / total_samplesdisease_accuracy = disease_correct / total_samplesseverity_accuracy = severity_correct / total_samples# 计算F1分数if len(all_disease_labels) > 0:disease_f1 = f1_score(all_disease_labels, all_disease_preds, average='macro', zero_division=0)severity_f1 = f1_score(all_severity_labels, all_severity_preds, average='macro', zero_division=0)else:disease_f1, severity_f1 = 0.0, 0.0return (avg_total_loss, avg_disease_loss, avg_severity_loss,disease_accuracy, severity_accuracy, disease_f1, severity_f1)# -------------------------- 多任务验证函数 --------------------------
def validate_multitask(model, val_loader, criterion_disease, criterion_severity, device, report_generator):"""多任务验证"""model.eval()total_disease_loss = 0.0total_severity_loss = 0.0total_loss = 0.0disease_correct = 0severity_correct = 0total_samples = 0all_disease_preds = []all_disease_labels = []all_severity_preds = []all_severity_labels = []# 存储诊断报告diagnostic_reports = []with torch.no_grad():progress_bar = tqdm(val_loader, desc="多任务验证")for batch_idx, (images, disease_labels, severity_labels) in enumerate(progress_bar):if len(images) == 0:continueimages = images.to(device)disease_labels = disease_labels.to(device)severity_labels = severity_labels.to(device)try:# 前向传播disease_output, severity_output = model(images)# 计算损失# 概率计算disease_probs = torch.softmax(disease_output, dim=1)severity_probs = torch.softmax(severity_output, dim=1)# 预测结果_, disease_preds = torch.max(disease_output, 1)_, severity_preds = torch.max(severity_output, 1)# 统计信息total_disease_loss += disease_loss.item() * images.size(0)total_severity_loss += severity_loss.item() * images.size(0)total_loss += total_batch_loss.item() * images.size(0)disease_correct += (disease_preds == disease_labels).sum().item()severity_correct += (severity_preds == severity_labels).sum().item()total_samples += images.size(0)# 收集预测结果all_disease_preds.extend(disease_preds.cpu().numpy())all_disease_labels.extend(disease_labels.cpu().numpy())all_severity_preds.extend(severity_preds.cpu().numpy())all_severity_labels.extend(severity_labels.cpu().numpy())# 为每个样本生成诊断报告for i in range(images.size(0)):report = report_generator.generate_detailed_report(image_id=f"batch{batch_idx}_sample{i}",disease_pred=disease_preds[i].item(),severity_pred=severity_preds[i].item(),disease_probs=disease_probs[i].cpu().numpy(),severity_probs=severity_probs[i].cpu().numpy(),disease_true=disease_labels[i].item(),severity_true=severity_labels[i].item())diagnostic_reports.append(report)# 更新进度条if len(all_disease_labels) > 0:current_disease_acc = accuracy_score(all_disease_labels, all_disease_preds)current_severity_acc = accuracy_score(all_severity_labels, all_severity_preds)progress_bar.set_postfix({'disease_acc': f'{current_disease_acc:.3f}','severity_acc': f'{current_severity_acc:.3f}'})except Exception as e:continueif total_samples == 0:return float('nan'), float('nan'), float('nan'), 0.0, 0.0, 0.0, 0.0, {}, [], [], [], [], []# 计算平均指标avg_total_loss = total_loss / total_samplesavg_disease_loss = total_disease_loss / total_samplesavg_severity_loss = total_severity_loss / total_samplesdisease_accuracy = disease_correct / total_samplesseverity_accuracy = severity_correct / total_samples# 计算详细指标if len(all_disease_labels) > 0:disease_f1 = f1_score(all_disease_labels, all_disease_preds, average='macro', zero_division=0)severity_f1 = f1_score(all_severity_labels, all_severity_preds, average='macro', zero_division=0)disease_precision = precision_score(all_disease_labels, all_disease_preds, average='macro', zero_division=0)severity_precision = precision_score(all_severity_labels, all_severity_preds, average='macro', zero_division=0)disease_recall = recall_score(all_disease_labels, all_disease_preds, average='macro', zero_division=0)severity_recall = recall_score(all_severity_labels, all_severity_preds, average='macro', zero_division=0)# 分类报告disease_class_report = classification_report(all_disease_labels, all_disease_preds,target_names=config.disease_names, output_dict=True, zero_division=0)severity_class_report = classification_report(all_severity_labels, all_severity_preds,target_names=config.severity_names, output_dict=True, zero_division=0)else:disease_f1 = severity_f1 = disease_precision = severity_precision = disease_recall = severity_recall = 0.0disease_class_report = severity_class_report = {}return (avg_total_loss, avg_disease_loss, avg_severity_loss,disease_accuracy, severity_accuracy, disease_f1, severity_f1,disease_precision, severity_precision, disease_recall, severity_recall,diagnostic_reports, all_disease_preds, all_disease_labels,all_severity_preds, all_severity_labels)# -------------------------- 协同效应评估 --------------------------
def evaluate_multitask_synergy(history, final_metrics, config):"""评估多任务学习的协同效应"""synergy_report = {"evaluation_time": datetime.now().strftime("%Y-%m-%d %H:%M:%S"),"task_performance_comparison": {"disease_classification": {"final_accuracy": final_metrics['disease_accuracy'],"best_accuracy": max(history['val_disease_acc']),"final_f1_score": final_metrics['disease_f1']},"severity_classification": {"final_accuracy": final_metrics['severity_accuracy'],"best_accuracy": max(history['val_severity_acc']),"final_f1_score": final_metrics['severity_f1']}},"synergy_metrics": {},"performance_analysis": {}}# 计算协同效应指标disease_acc = final_metrics['disease_accuracy']severity_acc = final_metrics['severity_accuracy']# 任务相关性评估task_correlation = np.corrcoef(history['val_disease_acc'], history['val_severity_acc'])[0, 1]synergy_report["synergy_metrics"]["task_correlation"] = float(task_correlation)# 协同效应等级评定if disease_acc > 0.75 and severity_acc > 0.85 and task_correlation > 0.3:synergy_level = "强协同效应"analysis = "两个任务相互促进,性能均达到较高水平"elif disease_acc > 0.65 and severity_acc > 0.75 and task_correlation > 0.1:synergy_level = "中等协同效应"analysis = "任务间存在正向影响,有进一步优化空间"else:synergy_level = "弱协同效应"analysis = "建议调整任务权重或网络结构以增强协同效果"synergy_report["performance_analysis"] = {"synergy_level": synergy_level,"analysis": analysis,"recommendations": ["考虑调整任务损失权重","优化共享特征层结构","增加任务特定特征提取能力"]}# 保存协同效应报告with open(config.synergy_report_path, 'w', encoding='utf-8') as f:json.dump(synergy_report, f, ensure_ascii=False, indent=2)return synergy_report# -------------------------- 可视化函数 --------------------------
def plot_multitask_training_metrics(history, config):"""绘制多任务训练指标"""epochs = range(1, len(history['train_total_loss']) + 1)fig, ((ax1, ax2), (ax3, ax4)) = plt.subplots(2, 2, figsize=(15, 12))# 1. 总损失曲线ax1.plot(epochs, history['train_total_loss'], 'b-', label='训练总损失', linewidth=2)ax1.plot(epochs, history['val_total_loss'], 'r-', label='验证总损失', linewidth=2)ax1.set_title('多任务学习总损失曲线')ax1.set_xlabel('训练轮次')ax1.set_ylabel('损失值')ax1.legend()ax1.grid(True)# 2. 病害分类准确率ax2.plot(epochs, history['train_disease_acc'], 'b-', label='训练病害准确率', linewidth=2)ax2.plot(epochs, history['val_disease_acc'], 'r-', label='验证病害准确率', linewidth=2)ax2.set_title('病害分类准确率')ax2.set_xlabel('训练轮次')ax2.set_ylabel('准确率')ax2.set_ylim(0, 1)ax2.legend()ax2.grid(True)# 3. 严重程度分类准确率ax3.plot(epochs, history['train_severity_acc'], 'b-', label='训练严重程度准确率', linewidth=2)ax3.plot(epochs, history['val_severity_acc'], 'r-', label='验证严重程度准确率', linewidth=2)ax3.set_title('严重程度分类准确率')ax3.set_xlabel('训练轮次')ax3.set_ylabel('准确率')ax3.set_ylim(0, 1)ax3.legend()ax3.grid(True)# 4. 任务损失对比ax4.plot(epochs, history['train_disease_loss'], 'g-', label='训练病害损失', linewidth=2)ax4.plot(epochs, history['train_severity_loss'], 'm-', label='训练严重程度损失', linewidth=2)ax4.set_title('任务损失对比')ax4.set_xlabel('训练轮次')ax4.set_ylabel('损失值')ax4.legend()ax4.grid(True)plt.tight_layout()plt.savefig(config.training_plot_path, dpi=300, bbox_inches='tight')plt.show()def plot_multitask_confusion_matrices(disease_true, disease_pred, severity_true, severity_pred, config):"""绘制多任务混淆矩阵"""fig, (ax1, ax2) = plt.subplots(1, 2, figsize=(20, 8))# 病害分类混淆矩阵(显示前10个类别)disease_cm = confusion_matrix(disease_true, disease_pred)# 只显示前10个类别以避免过于拥挤show_classes = min(10, len(config.disease_names))sns.heatmap(disease_cm[:show_classes, :show_classes], annot=True, fmt='d', cmap='Blues', ax=ax1,xticklabels=config.disease_names[:show_classes], yticklabels=config.disease_names[:show_classes])ax1.set_title('病害分类混淆矩阵(前10个类别)')ax1.set_xlabel('预测标签')ax1.set_ylabel('真实标签')# 严重程度分类混淆矩阵severity_cm = confusion_matrix(severity_true, severity_pred)sns.heatmap(severity_cm, annot=True, fmt='d', cmap='Blues', ax=ax2,xticklabels=config.severity_names, yticklabels=config.severity_names)ax2.set_title('严重程度分类混淆矩阵')ax2.set_xlabel('预测标签')ax2.set_ylabel('真实标签')plt.tight_layout()plt.savefig(config.confusion_matrix_path, dpi=300, bbox_inches='tight')plt.show()def save_detailed_metrics_report(history, final_metrics, synergy_report, config):"""保存详细指标报告"""with open(config.metrics_report_path, 'w', encoding='utf-8') as f:f.write("=== 多任务联合学习与可解释性诊断系统评估报告 ===\n")f.write(f"生成时间: {datetime.now().strftime('%Y-%m-%d %H:%M:%S')}\n\n")f.write("最终性能指标:\n")f.write(f"病害分类准确率: {final_metrics['disease_accuracy']:.4f}\n")f.write(f"病害分类F1分数: {final_metrics['disease_f1']:.4f}\n")f.write(f"严重程度分类准确率: {final_metrics['severity_accuracy']:.4f}\n")f.write(f"严重程度分类F1分数: {final_metrics['severity_f1']:.4f}\n\n")f.write("训练过程统计:\n")f.write(f"总训练轮次: {len(history['train_total_loss'])}\n")f.write(f"最佳病害准确率: {max(history['val_disease_acc']):.4f}\n")f.write(f"最佳严重程度准确率: {max(history['val_severity_acc']):.4f}\n\n")f.write("多任务协同效应分析:\n")f.write(f"协同等级: {synergy_report['performance_analysis']['synergy_level']}\n")f.write(f"分析结果: {synergy_report['performance_analysis']['analysis']}\n")f.write(f"任务相关性: {synergy_report['synergy_metrics']['task_correlation']:.4f}\n")# -------------------------- 主函数 --------------------------
def main():print("=== 多任务联合学习与可解释性诊断系统 ===")print("基于第一个代码路径结构的完整实现")# 检查路径for name, path in paths_to_check.items():exists = os.path.exists(path)status = "✓ 存在" if exists else "✗ 不存在"print(f"{name}: {status}")if not all(os.path.exists(path) for path in [config.train_data_dir, config.val_data_dir, config.train_json_path, config.val_json_path]):print("错误: 必要的文件或目录不存在,请检查路径配置")return# 创建数据集print("\n创建多任务数据集...")train_dataset = MultiTaskDiseaseDataset(config.train_data_dir, config.train_json_path,get_multitask_transforms(is_train=True), 'train')val_dataset = MultiTaskDiseaseDataset(config.val_data_dir, config.val_json_path,get_multitask_transforms(is_train=False), 'val')if len(train_dataset) == 0 or len(val_dataset) == 0:print("错误: 数据集为空,请检查数据路径和JSON文件")returnprint(f"训练样本: {len(train_dataset)}, 验证样本: {len(val_dataset)}")# 创建数据加载器train_loader = DataLoader(train_dataset, batch_size=config.batch_size, shuffle=True,collate_fn=multitask_collate_fn, num_workers=2)val_loader = DataLoader(val_dataset, batch_size=config.batch_size, shuffle=False,collate_fn=multitask_collate_fn, num_workers=2)# 初始化模型model = MultiTaskResNet(config.num_disease_classes, config.num_severity_classes).to(config.device)# 损失函数和优化器criterion_disease = nn.CrossEntropyLoss()criterion_severity = nn.CrossEntropyLoss()optimizer = optim.AdamW(model.parameters(),lr=config.learning_rate,weight_decay=config.weight_decay)scheduler = CosineAnnealingLR(optimizer, T_max=config.epochs)# 初始化诊断报告生成器report_generator = DiagnosticReportGenerator(config.disease_names, config.severity_names)# 训练历史记录history = {'train_total_loss': [], 'val_total_loss': [],'train_disease_loss': [], 'val_disease_loss': [],'train_severity_loss': [], 'val_severity_loss': [],'train_disease_acc': [], 'val_disease_acc': [],'train_severity_acc': [], 'val_severity_acc': [],'train_disease_f1': [], 'val_disease_f1': [],'train_severity_f1': [], 'val_severity_f1': []}best_disease_acc = 0.0early_stop_counter = 0patience = 10print("\n开始多任务训练...")start_time = time.time()for epoch in range(config.epochs):print(f"\nEpoch {epoch + 1}/{config.epochs}")# 训练# 验证# 学习率调整scheduler.step()current_lr = optimizer.param_groups[0]['lr']# 记录历史if not np.isnan(train_metrics[0]):history['train_total_loss'].append(train_metrics[0])history['train_disease_loss'].append(train_metrics[1])history['train_severity_loss'].append(train_metrics[2])history['train_disease_acc'].append(train_metrics[3])history['train_severity_acc'].append(train_metrics[4])history['train_disease_f1'].append(train_metrics[5])history['train_severity_f1'].append(train_metrics[6])history['val_total_loss'].append(val_metrics[0])history['val_disease_loss'].append(val_metrics[1])history['val_severity_loss'].append(val_metrics[2])history['val_disease_acc'].append(val_metrics[3])history['val_severity_acc'].append(val_metrics[4])history['val_disease_f1'].append(val_metrics[5])history['val_severity_f1'].append(val_metrics[6])# 打印指标print(f"训练 - 病害准确率: {train_metrics[3]:.4f}, 严重程度准确率: {train_metrics[4]:.4f}")print(f"验证 - 病害准确率: {val_metrics[3]:.4f}, 严重程度准确率: {val_metrics[4]:.4f}")print(f"学习率: {current_lr:.2e}")# 保存最佳模型if not np.isnan(val_metrics[3]) and val_metrics[3] > best_disease_acc:best_disease_acc = val_metrics[3]early_stop_counter = 0torch.save(model.state_dict(), config.model_save_path)print(f"✓ 保存最佳模型(验证病害准确率: {val_metrics[3]:.4f})")# 保存最终结果用于分析final_reports = val_metrics[12]final_disease_preds = val_metrics[13]final_disease_labels = val_metrics[14]final_severity_preds = val_metrics[15]final_severity_labels = val_metrics[16]final_metrics = {'disease_accuracy': val_metrics[3],'severity_accuracy': val_metrics[4],'disease_f1': val_metrics[5],'severity_f1': val_metrics[6]}else:early_stop_counter += 1# 早停# 训练完成end_time = time.time()training_time = end_time - start_timeprint(f"\n训练完成!总用时: {training_time:.2f}秒")# 生成可视化结果if len(history['train_total_loss']) > 0:print("\n生成可视化结果和分析报告...")# 绘制训练曲线plot_multitask_training_metrics(history, config)# 绘制混淆矩阵if 'final_disease_preds' in locals():plot_multitask_confusion_matrices(final_disease_labels, final_disease_preds,final_severity_labels, final_severity_preds, config)# 保存诊断报告with open(config.diagnostic_report_path, 'w', encoding='utf-8') as f:json.dump(final_reports, f, ensure_ascii=False, indent=2)# 评估协同效应synergy_report = evaluate_multitask_synergy(history, final_metrics, config)# 保存详细指标报告save_detailed_metrics_report(history, final_metrics, synergy_report, config)print("\n=== 任务完成总结 ===")print(f"✓ 训练曲线图: {config.training_plot_path}")print(f"✓ 混淆矩阵图: {config.confusion_matrix_path}")print(f"✓ 诊断报告: {config.diagnostic_report_path}")print(f"✓ 协同效应分析: {config.synergy_report_path}")print(f"✓ 详细指标报告: {config.metrics_report_path}")print(f"✓ 最佳模型: {config.model_save_path}")print(f"✓ 多任务协同等级: {synergy_report['performance_analysis']['synergy_level']}")if __name__ == "__main__":main()
结果:
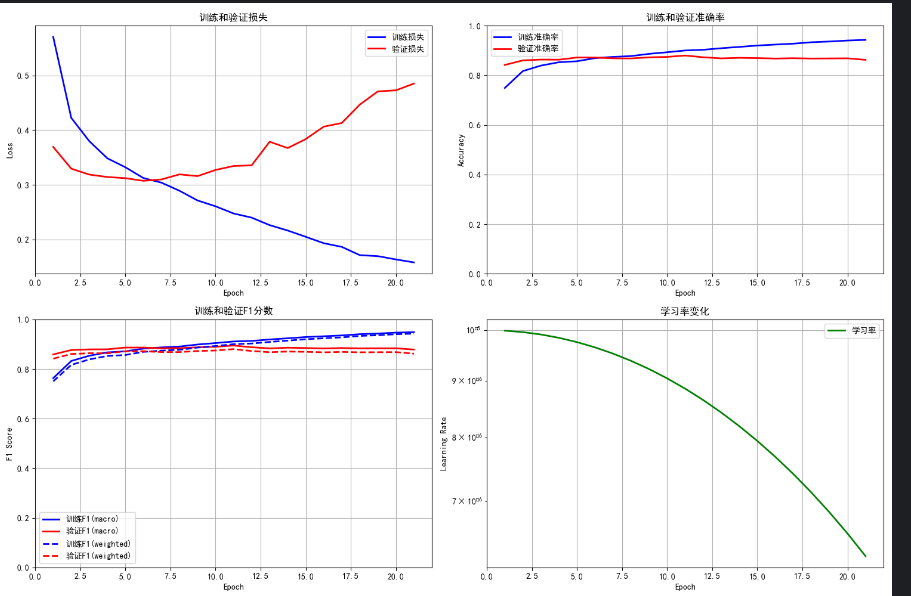
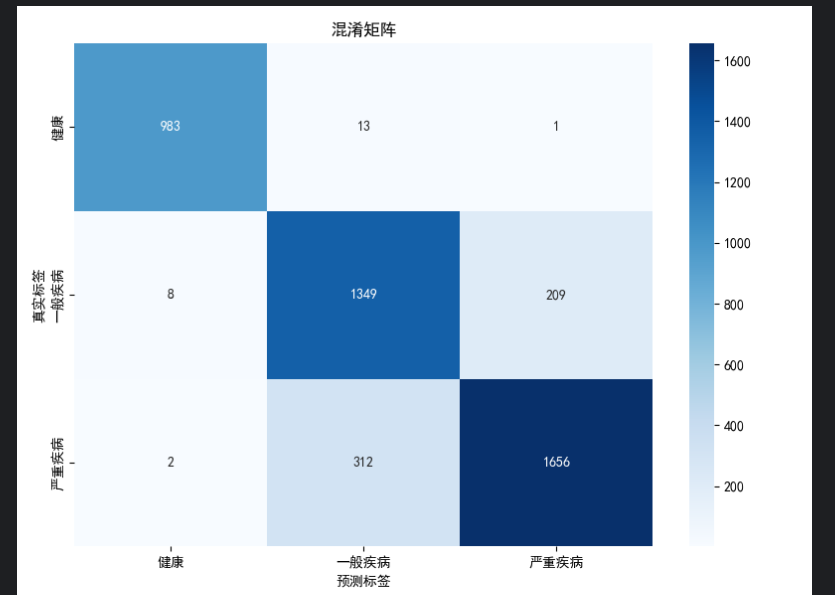
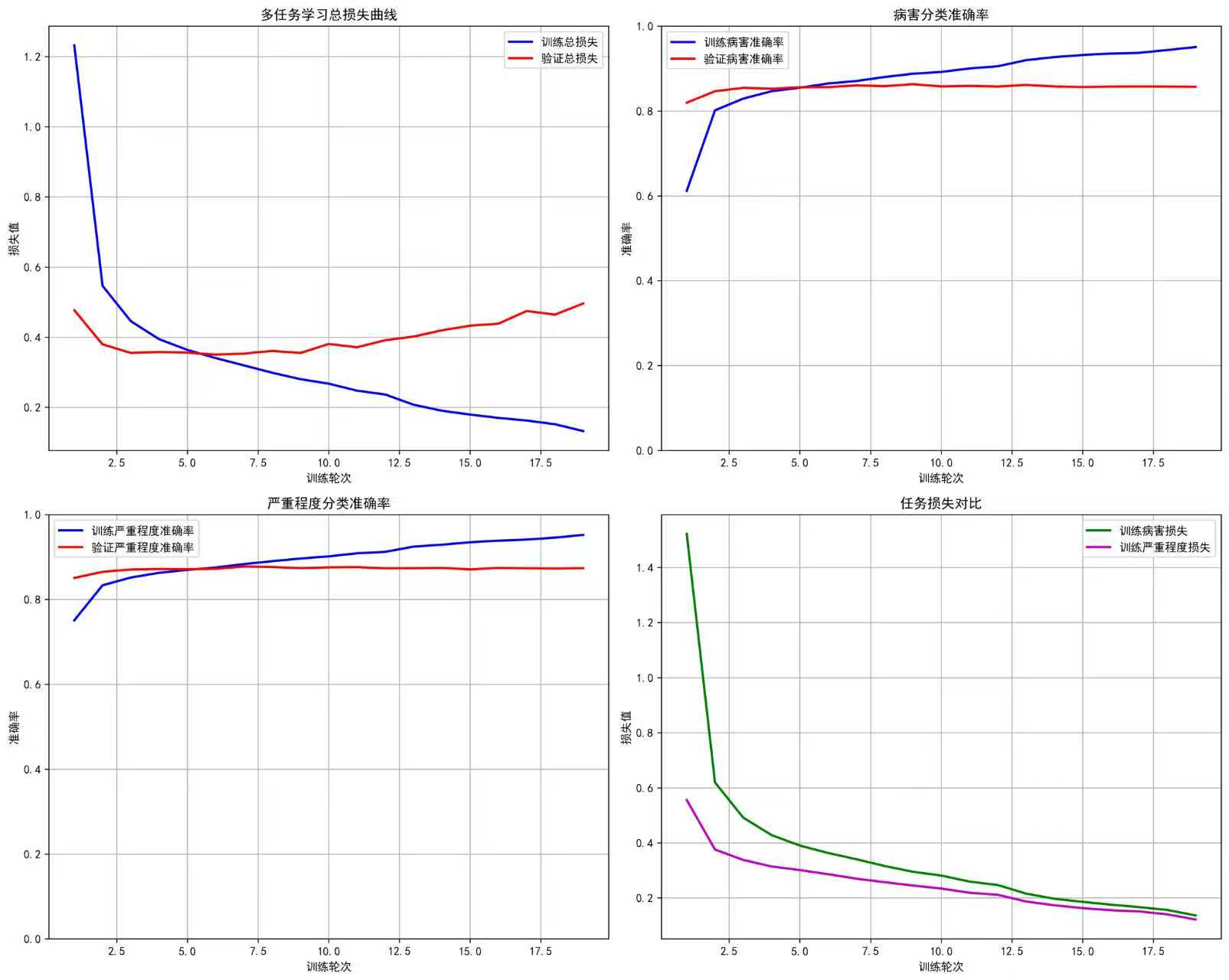
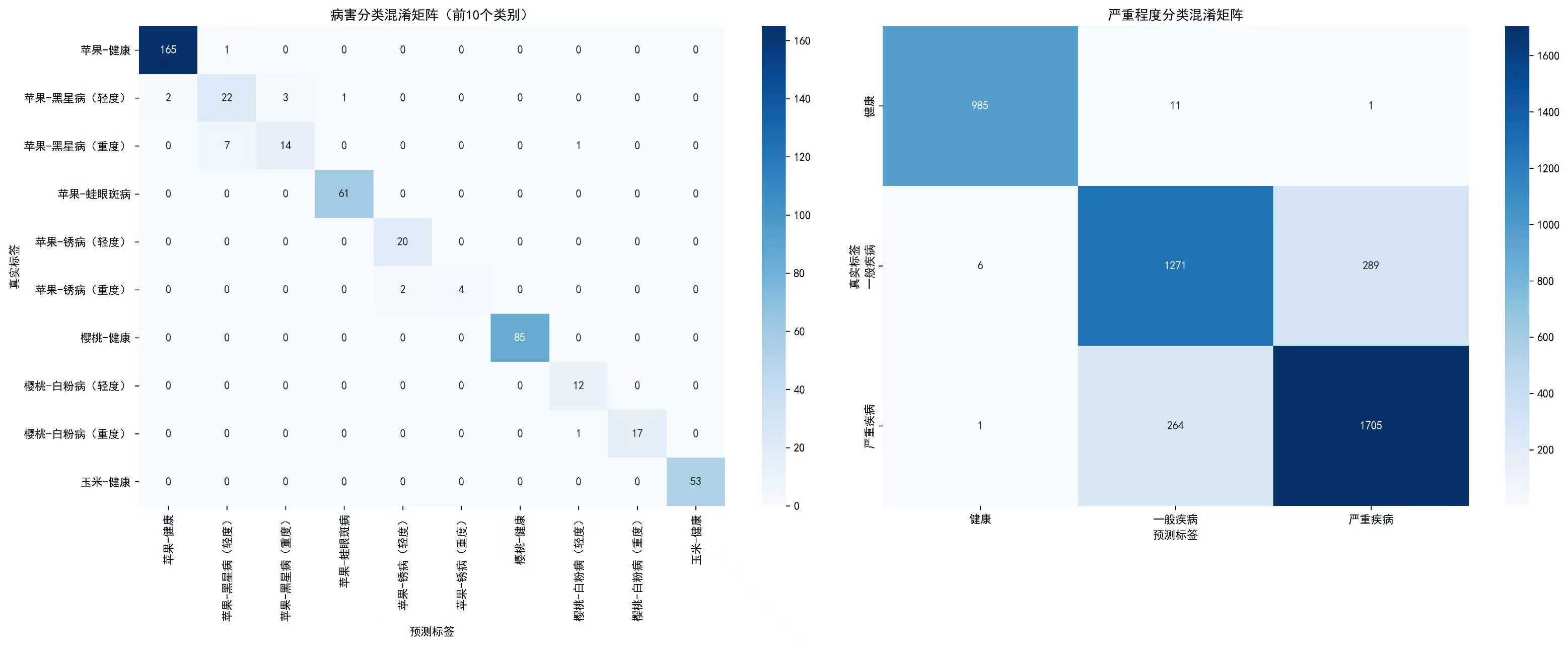
对于代码,我删掉了部分数据加载器。
总结
深度学习内容计划进行无监督部分基础,神经网络方面结合代码学习算法并实践。CNN继续内容实践相结合学习。学了一点matlab软件内容。