MYSQL索引的底层数据结构
MYSQL索引
啥是索引,为什么要用索引,怎么用,为什么要用
索引:就好像查字典一样,通过偏旁部首,声母韵母这种方式去查某个字,会让你的效率更高更快。
在mysql中,索引是一种数据结构,他的功能和查字典没啥两样,主要就是让数据检索的效率更快。
Mysql索引的数据结构的选择:
- 不是说hash查找的时间复杂度是o(1),为什么不使用哈希查找?
因为一般来说我们存储的数据都是范围的存储,数据的左右多少都是有点关系的,但是哈希查找不是这样的,他说通过计算哈希值,把每个数据放到某个位置去,他不支持范围查找数据的关联系比较弱。
- 为什么不使用二叉搜索数
因为最坏的情况下,二叉搜索树可能会退化成一个单分支的数,这个时候的二叉搜索树其实和单链表没啥区别了时间复杂度都是o(n),并且数据库的数据是保存在磁盘上的,也就是相当于每次访问一个数据都要发生一次磁盘oi(开关)。

- 为什么不使用N叉数(B树)
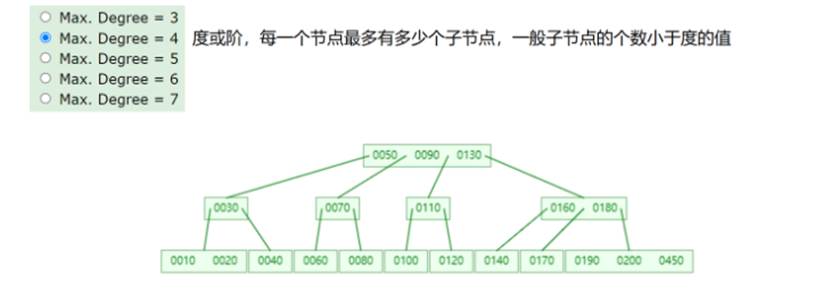
时间复杂度o(logn)
树的高度被有效控制,查询数据的次数变少了,数据库的效率也提升了,为什么不使用呢,是因为有更好的B+树
4为什么索引选择了使用B+树(面试题)

B+树,时间复杂度是o(logn);
仔细观察这个B+树和B树
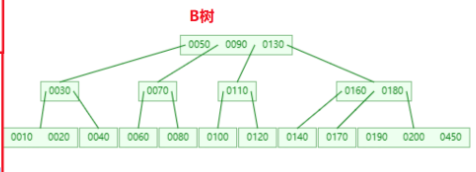
这两棵树有什么区别吗?
- B+树的所有叶子节点之间相当于一个双向循环列表,通过其中的任意一个元素都能找到他的兄弟节点。
- 非叶子节点保存的只是对子节点的引用,所有的真实数据都保存在叶子节点中。
- B+树和B树,在树高都一样的情况下,查找任一元素都时间复杂度都一样,性能更加均衡。