行人跌倒智能检测系统:YOLOv8/V5/V6/V7 多模型 + PySide6 界面 深度学习 多场景适配 大数据 (建议收藏)✅
博主介绍:✌全网粉丝10W+,前互联网大厂软件研发、集结硕博英豪成立软件开发工作室,专注于计算机相关专业项目实战6年之久,累计开发项目作品上万套。凭借丰富的经验与专业实力,已帮助成千上万的学生顺利毕业,选择我们,就是选择放心、选择安心毕业✌
> 🍅想要获取完整文章或者源码,或者代做,拉到文章底部即可与我联系了。🍅点击查看作者主页,了解更多项目!
🍅感兴趣的可以先收藏起来,点赞、关注不迷路,大家在毕设选题,项目以及论文编写等相关问题都可以给我留言咨询,希望帮助同学们顺利毕业 。🍅
1、毕业设计:2026年计算机专业毕业设计选题汇总(建议收藏)✅
2、最全计算机专业毕业设计选题大全(建议收藏)✅
1、项目介绍
技术栈:
python语言、YoloV8V5模型、PySide6界面、注册登录、训练集测试集
摘要:开发行人跌倒检测系统在确保老年人安全方面扮演着至关重要的角色。本篇文章详尽地阐述了如何利用深度学习技术构建一个行人跌倒检测系统,并附上了完整的代码实现。该系统采用了先进的YOLOv8算法,并对YOLOv7、YOLOv6、YOLOv5等先前版本进行了性能对比,包括mAP、F1 Score等关键性能指标。文章深入讲解了YOLOv8的工作原理,并提供了相关的Python实现代码、训练用的数据集,以及一个基于PySide6的图形用户界面。
该系统能够准确地识别行人跌倒事件,并支持通过图片、图片文件夹、视频文件以及实时摄像头输入进行检测。它还包括了诸如热力图分析、检测框标签、类别统计、可调整的置信度和IOU阈值、以及结果可视化等功能。此外,系统还设计了一个基于SQLite的用户管理界面,允许用户切换模型和自定义界面。
2、项目界面
(1)跌倒智能检测识别
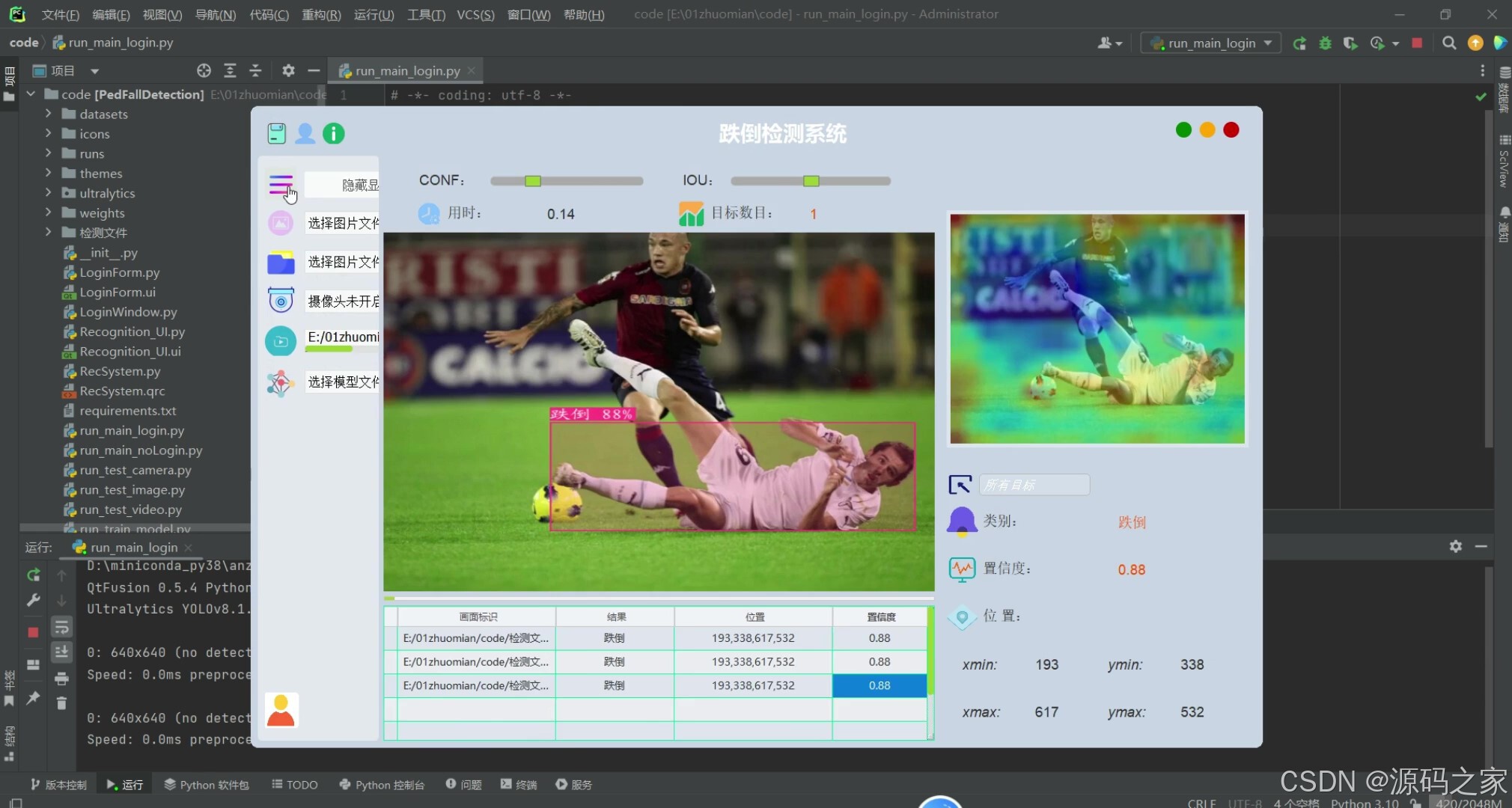
(2)跌倒智能检测识别
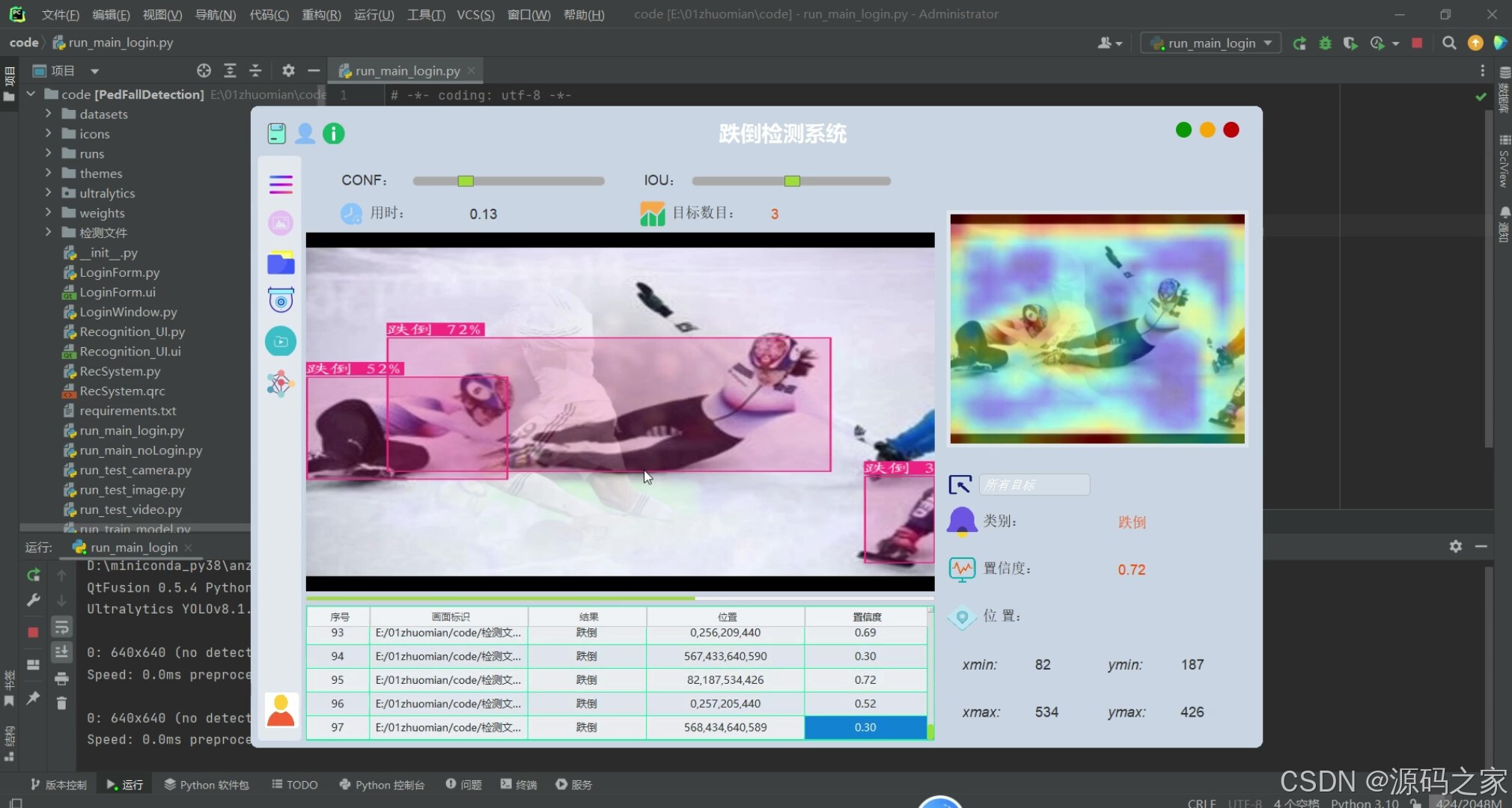
(3)跌倒智能检测识别
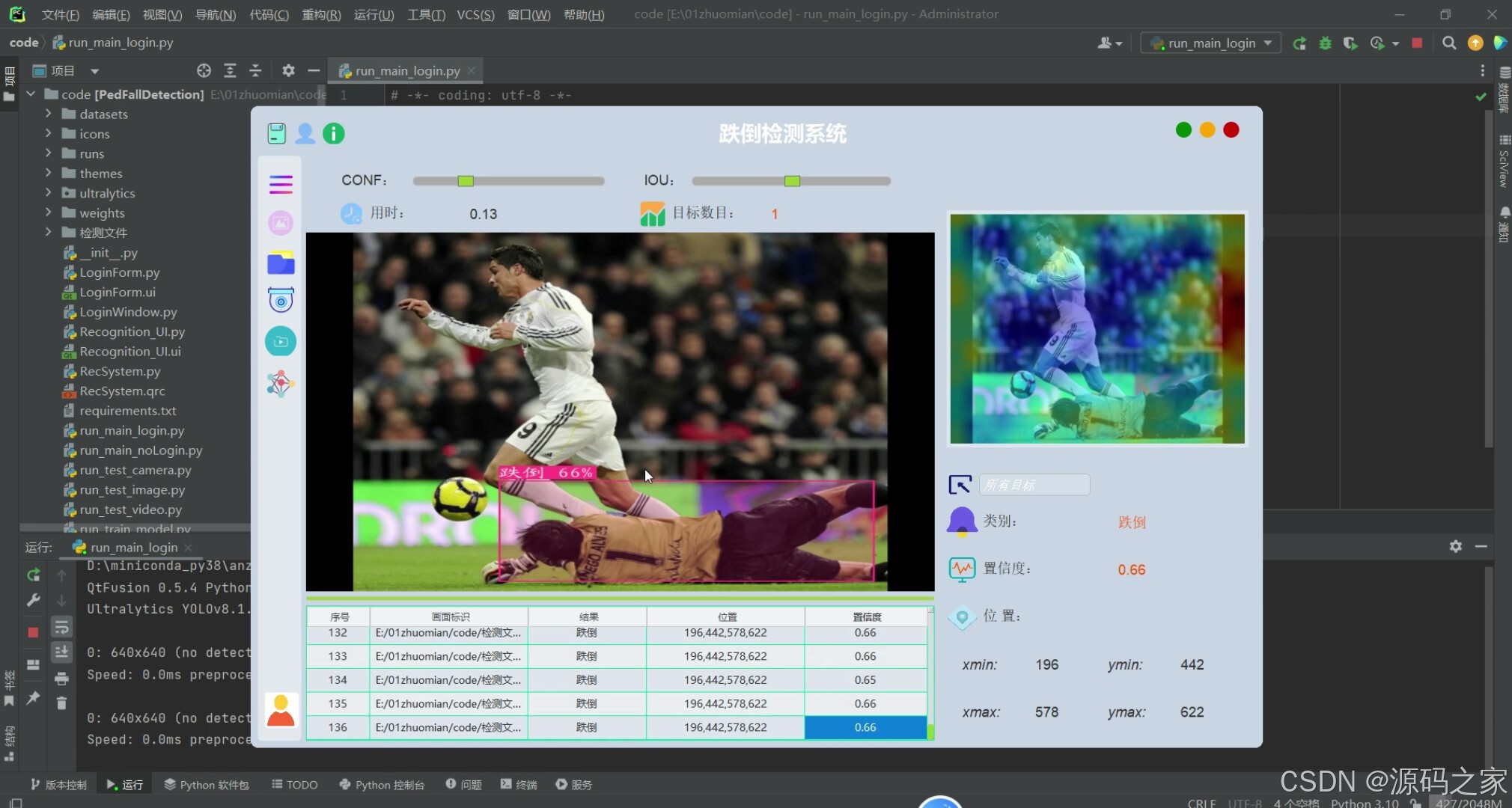
(4)跌倒智能检测识别
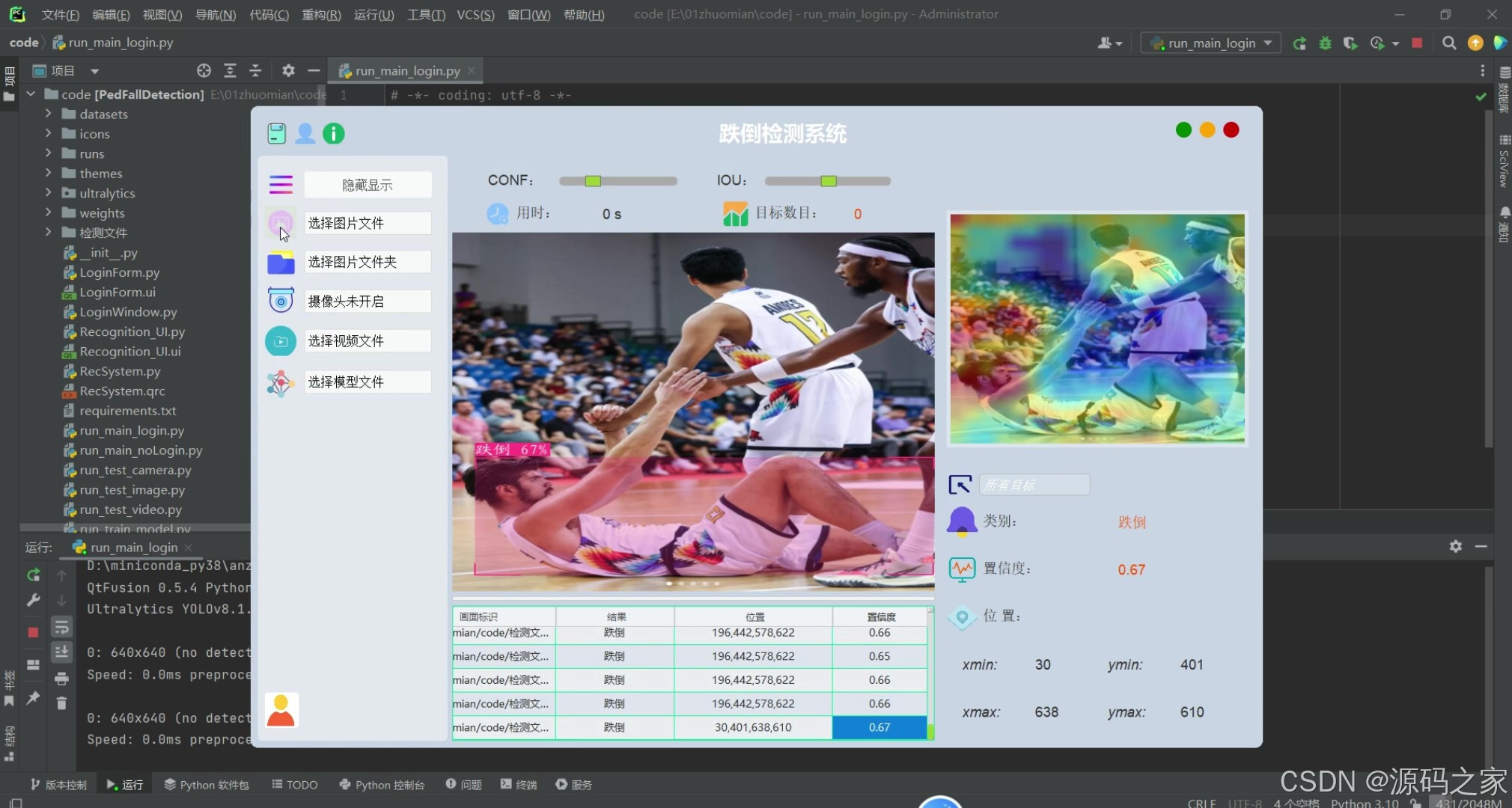
(5)跌倒智能检测识别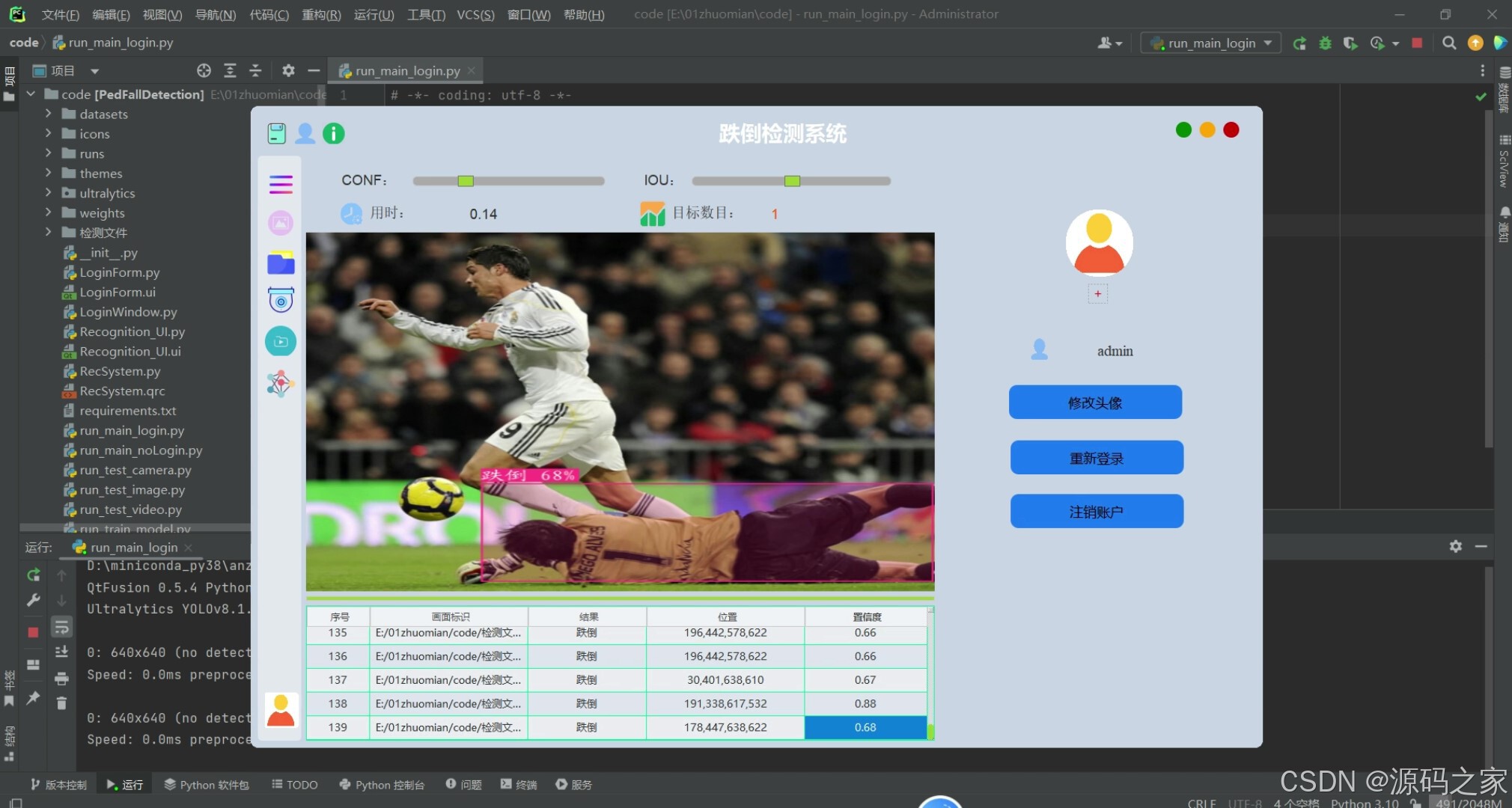
(6)界面设计
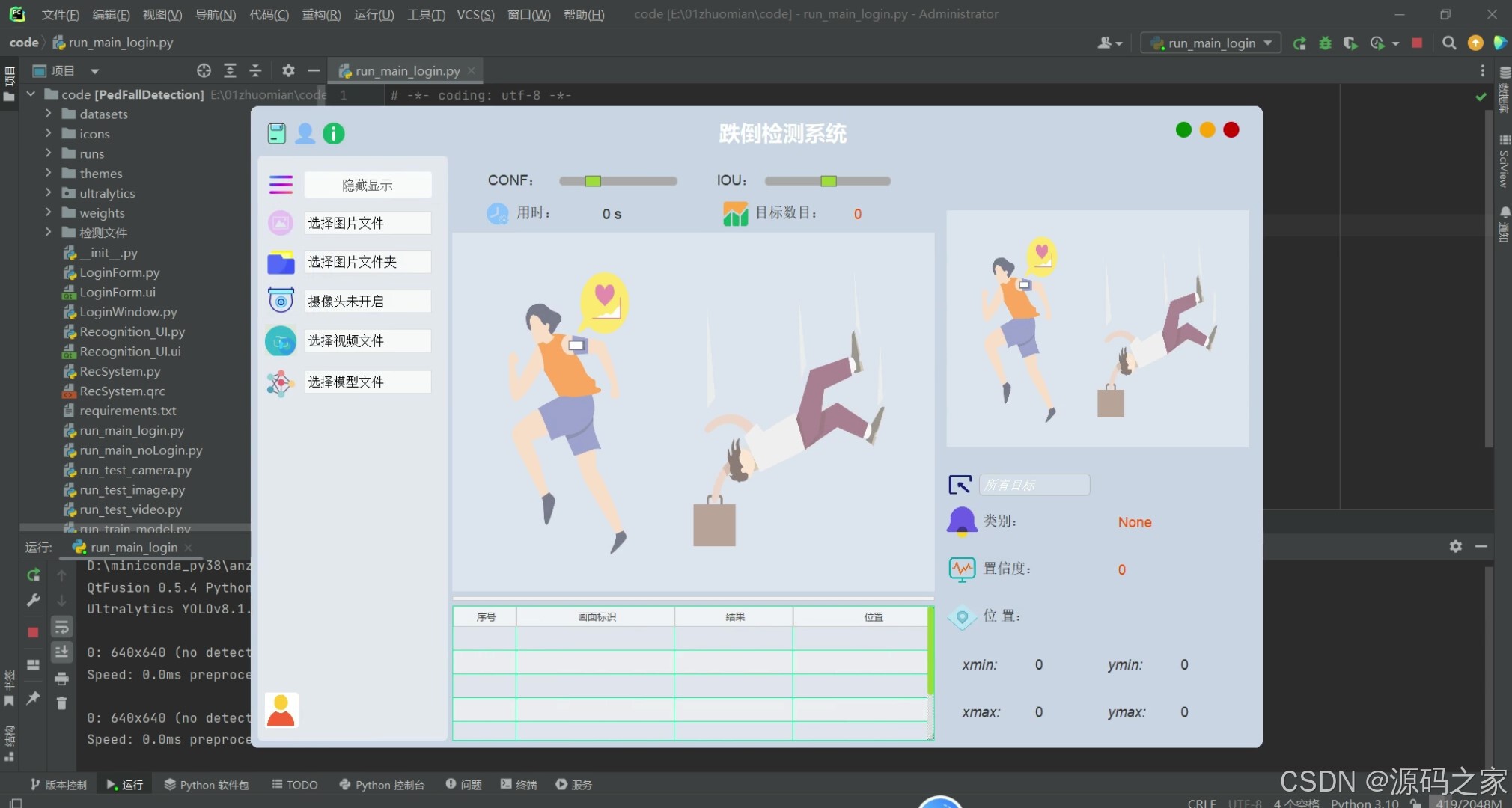
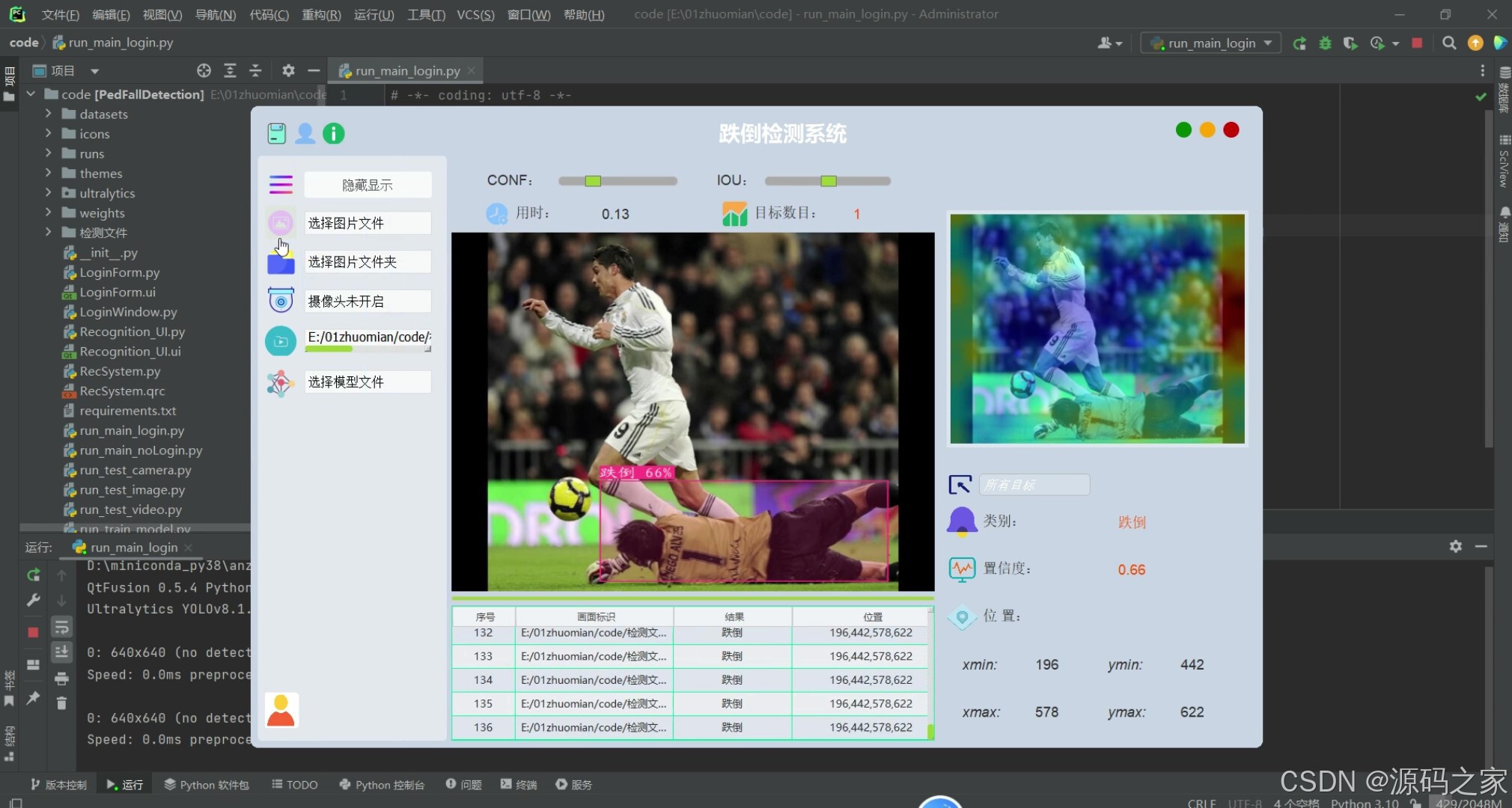
(7)视频检测识别
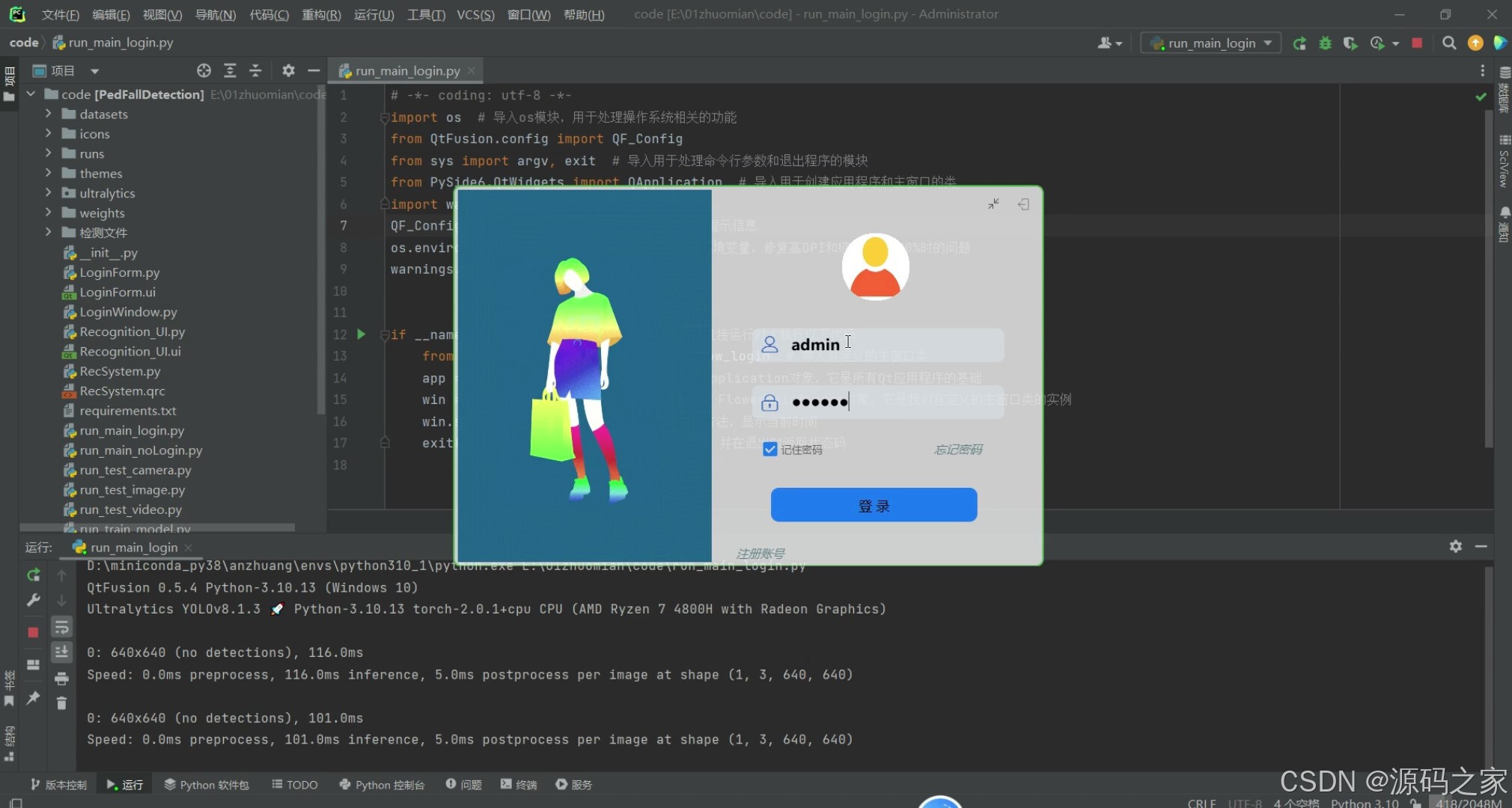
(8)注册登录
3、项目说明
1、数据集介绍
在本次研究中,我们深入分析并构建了一个行人跌倒检测数据集,该数据集的设计与预处理方法对于确保我们的行人跌倒检测系统能够有效识别并处理各种跌倒情景至关重要。本数据集包括了总共1770张经过细致筛选的图片,其中1110张用于训练模型,以保证模型能学习到丰富的特征;330张图片用于验证,以调整模型参数,防止过拟合;另外330张用于最终的测试,以评估模型的实际表现。
在数据预处理阶段,我们采取了多项措施以保证模型训练的质量和效率。首先,所有图像均经过自动方向校正,并去除了EXIF方向信息,确保所有的训练数据都以统一的方向呈现。这一步骤是必要的,因为不同的图像捕获设备和拍摄角度可能导致图像的方向不一致,这对于模型的训练可能产生负面影响。
进一步地,为了适应深度学习模型的需求,我们将所有图像的分辨率统一调整到640x640像素。选择这一分辨率是为了在图像清晰度和计算资源之间找到一个平衡点。同时,为了提升模型对数据的泛化能力,并增加训练过程的多样性,我们对数据集中的图像实施了随机水平翻转,每张图像有50%的概率在训练时被翻转。这种数据增强方法能有效地模仿行人跌倒时可能出现的各种方向变化,从而提高模型识别跌倒行为的能力。
在数据标注方面,我们精心地对每一个跌倒事件进行了框定,确保标签的准确性和一致性。标注过程中,我们特别注意到跌倒行为的多样性,以确保系统能够在不同的场合和环境中保持高识别率。通过对数据集分布的分析,我们观察到了一系列有趣的特征。跌倒的实例在图像中广泛分布,覆盖了各种不同的场景,这确保了模型能够适应多种环境。此外,我们发现标注框的宽度和高度集中在一定的范围内,这表明我们的数据集中存在不同尺度的跌倒行为,从而为检测系统提供了广泛的样本来学习,以适应不同距离和角度下的跌倒检测。
通过以上的数据集设计和预处理步骤,我们确信所构建的数据集能够有效地支持行人跌倒检测系统的开发和评估。这些精心设计的方法不仅有助于提升模型性能,还为进一步的优化和研究奠定了坚实的基础。
4、核心代码
import random # 导入random模块,用于生成随机数
import sys # 导入sys模块,用于访问与Python解释器相关的变量和函数
import time # 导入time模块,用于处理时间
from QtFusion.config import QF_Config
import cv2 # 导入OpenCV库,用于处理图像
from QtFusion.widgets import QMainWindow # 从QtFusion库中导入FBaseWindow类,用于创建窗口
from QtFusion.utils import cv_imread, drawRectBox # 从QtFusion库中导入cv_imread和drawRectBox函数,用于读取图像和绘制矩形框
from PySide6 import QtWidgets, QtCore # 导入PySide6库中的QtWidgets和QtCore模块,用于创建GUI
from QtFusion.path import abs_path
from YOLOv8Model import YOLOv8Detector # 从YOLOv8Model模块中导入YOLOv8Detector类,用于加载YOLOv8模型并进行目标检测
from datasets.PedFall.label_name import Label_listQF_Config.set_verbose(False)class MainWindow(QMainWindow): # 定义MainWindow类,继承自FBaseWindow类def __init__(self): # 定义构造函数super().__init__() # 调用父类的构造函数self.resize(640, 640) # 设置窗口的大小self.label = QtWidgets.QLabel(self) # 创建一个QLabel对象self.label.setGeometry(0, 0, 640, 640) # 设置QLabel的位置和大小def keyPressEvent(self, event): # 定义keyPressEvent函数,用于处理键盘事件if event.key() == QtCore.Qt.Key.Key_Q: # 如果按下的是Q键self.close() # 关闭窗口
app = QtWidgets.QApplication(sys.argv) # 创建QApplication对象
window = MainWindow() # 创建MainWindow对象img_path = abs_path("test_media/fall_262.jpg")
image = cv_imread(img_path) # 使用cv_imread函数读取图像image = cv2.resize(image, (850, 500)) # 将图像大小调整为850x500
pre_img = model.preprocess(image) # 对图像进行预处理
t1 = time.time() # 获取当前时间(开始时间)
pred = model.predict(pre_img) # 使用模型进行预测
t2 = time.time() # 获取当前时间(结束时间)
use_time = t2 - t1 # 计算预测所用的时间det = pred[0] # 获取预测结果的第一个元素(检测结果)# 如果有检测信息则进入
if det is not None and len(det):det_info = model.postprocess(pred) # 对预测结果进行后处理for info in det_info: # 遍历检测信息# 获取类别名称、边界框、置信度和类别IDname, bbox, conf, cls_id = info['class_name'], info['bbox'], info['score'], info['class_id']label = '%s %.0f%%' % (name, conf * 100) # 创建标签,包含类别名称和置信度# 画出检测到的目标物image = drawRectBox(image, bbox, alpha=0.2, addText=label, color=colors[cls_id]) # 在图像上绘制边界框和标签print("推理时间: %.2f" % use_time) # 打印预测所用的时间
window.dispImage(window.label, image) # 在窗口的label上显示图像
# 显示窗口
window.show()
# 进入 Qt 应用程序的主循环
sys.exit(app.exec())🍅✌感兴趣的可以先收藏起来,点赞关注不迷路,想学习更多项目可以查看主页,大家在毕设选题,项目编程以及论文编写等相关问题都可以给我留言咨询,希望可以帮助同学们顺利毕业!🍅✌
5、源码获取方式
🍅由于篇幅限制,获取完整文章或源码、代做项目的,拉到文章底部即可看到个人联系方式。🍅
点赞、收藏、关注,不迷路,下方查看👇🏻获取联系方式👇🏻