知识增强篇:RAG技术
目录
一、RAG 的必要性
二、核心机制解析
1、主要流程
(1)建立索引阶段
(2)检索生成阶段
(3)典型输出流程
2、关键技术
(1) 数据预处理与知识结构化
(2) 向量化与索引构建
(3) 检索优化策略
三、相关优化方案
1、延迟优化
(0)技术挑战
(1)向量索引优化
(2)混合缓存策略
(3)硬件加速
(4)行业案例
2、幻觉抑制
(0)技术挑战
(1)检索阶段过滤
(2)生成过程控制
(3)后处理验证
(4)行业应用
3、知识新鲜度
(0)技术挑战
(1)流式处理架构
(2)增量索引技术
(3)变更检测算法
(4)行业实践
4、RAG 应用优化
一、RAG 的必要性
LLM 大模型虽然展现了强大的通用对话能力,但在实际产业应用中暴露明显缺陷:
- 知识时效性:GPT-4的训练数据截止2023年4月,无法回答时效性强的查询(如实时股价、突发事件);
- 领域专业性:在医疗、法律等垂直领域,LLM的幻觉率(Hallucination Rate)高达37%(Stanford研究数据);
- 长尾覆盖:对低频专业术语(如"非小细胞肺癌ALK基因突变")的响应准确性不足50%;
LLM 大模型的三大根本性限制:
- 参数化知识固化:1750 亿参数的 GPT-3 存储知识量仅相当于 9 TB 文本的 0.0003% 压缩率
- 训练成本约束:每更新 1% 知识需耗费200万美元(OpenAI内部数据估算)
- 隐性知识缺失:无法捕捉行业内部非结构化经验(如企业内部的故障处理手册)
典型缺陷案例:
- 时间敏感错误:询问"COVID-19 XBB.1.5变种特性",GPT-4 主要依赖2022年训练数据
- 专业术语混淆:将金融领域的"CDS"(信用违约互换)误解释为"光盘存储"
RAG通过动态检索外部知识库,将相关文档片段注入生成上下文。将 LLM 看作人类大脑的"长期记忆",RAG相当于外接的"工作记忆"模块,实现动态知识存取。可实现如下:
- 知识实时更新:无需重新训练即可整合最新数据
- 领域定制化:微软 Azure Cognitive Search 案例显示,医疗问答准确率提升62%
- 可解释性增强:每个回答附带来源文档引用(如法律条款第X章第Y条)
二、核心机制解析
通俗的说: RAG = 给 AI 配了个随时可更新知识的移动硬盘(索引库) + 一个严格按资料答题的学霸(LLM 生成模型)。
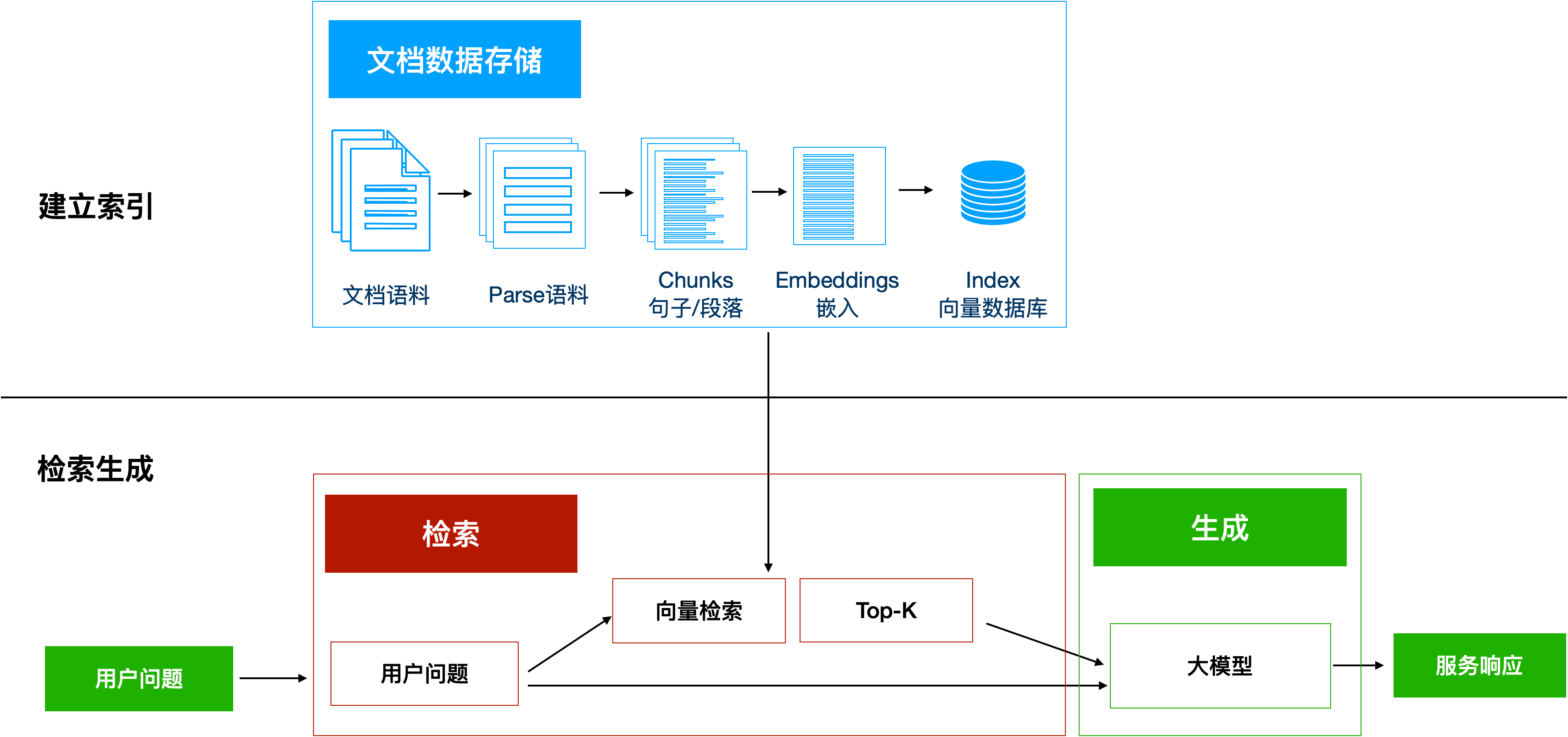
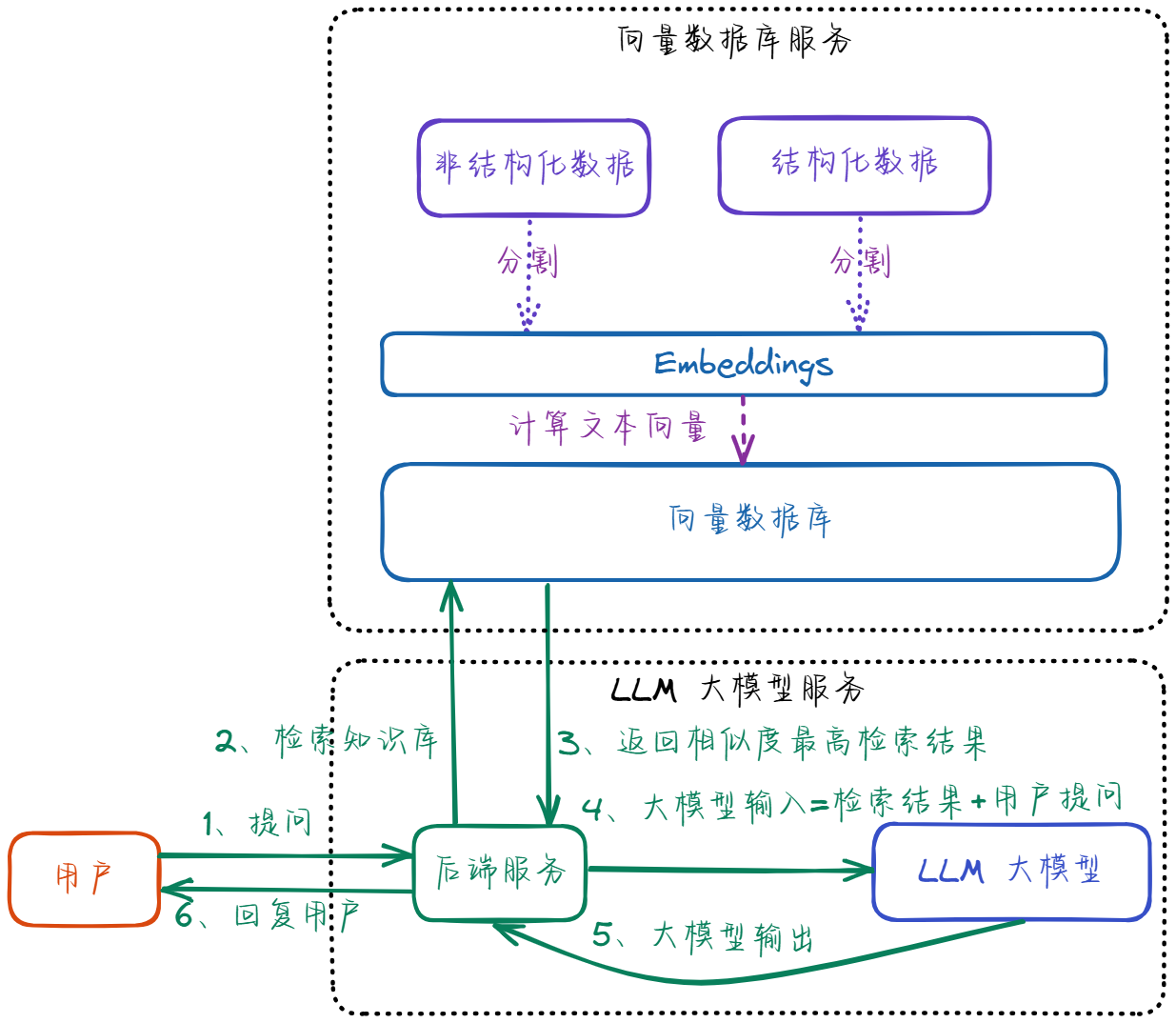
1、主要流程
(1)建立索引阶段
目标:将知识库转化为可高效检索的向量数据库
- 文档预处理:加载PDF/文本等数据,按语义切分(如500字/块)
from langchain.document_loaders import TextLoader
from langchain.text_splitter import RecursiveCharacterTextSplitter
loader = TextLoader("技术文档.pdf")
docs = loader.load()
text_splitter = RecursiveCharacterTextSplitter(chunk_size=500)
chunks = text_splitter.split_documents(docs)- 向量编码:使用嵌入模型(如BERT、GPT)将文本转为向量
from langchain.embeddings import HuggingFaceEmbeddings
embedder = HuggingFaceEmbeddings(model_name="sentence-transformers/all-mpnet-base-v2")
vectors = embedder.embed_documents([chunk.page_content for chunk in chunks])- 构建索引:将向量存入数据库(如FAISS、Pinecone)
from langchain.vectorstores import FAISS
vector_db = FAISS.from_documents(chunks, embedder)
vector_db.save_local("tech_index")(2)检索生成阶段
目标:实时检索相关文档并生成精准答案
- 问题向量化:将用户query转换为向量
query = "如何设计高并发系统?"
query_vector = embedder.embed_query(query)- 语义检索:从数据库查找Top-K相似文档(余弦相似度)
retrieved_docs = vector_db.similarity_search(query, k=3)- 上下文增强生成:将检索结果注入大模型prompt
from langchain.chains import RetrievalQA
from langchain.chat_models import ChatOpenAI
qa = RetrievalQA.from_chain_type(
llm=ChatOpenAI(model="gpt-3.5-turbo"),
chain_type="stuff",
retriever=vector_db.as_retriever()
)
answer = qa.invoke(query)["result"](3)典型输出流程
用户提问:“微服务通信如何保证安全性?”
检索到的内容(来自知识库):
《分布式系统安全指南》第4.2节:
“服务间通信必须启用双向TLS认证,确保服务身份合法性”
“建议使用私有CA为每个微服务签发唯一数字证书”
《API网关配置规范》第5章:
“在Envoy代理层实现mTLS,配置示例包含证书路径与CA验证逻辑”
“流量加密需使用TLS 1.3协议,禁用弱加密套件”
《服务认证白皮书》第3.1节:
“JWT令牌应包含服务ID、有效期和数字签名,推荐ES256算法”
“令牌需通过Opaque令牌机制与API网关集成”发送给大模型的Prompt:
下面中的 {检索内容 n} 替换为知识库中检索到的。
[角色] 你是一名云安全架构师,需基于以下上下文回答问题:
[上下文]
1. {检索内容1}
2. {检索内容2}
3. {检索内容3}
[任务]
回答用户问题:“微服务通信如何保证安全性?”
[要求]
- 分步骤说明技术方案
- 包含TLS配置、身份认证、令牌管理三部分
- 避免理论描述,聚焦实施方案
- 禁止添加非上下文外的信息 LLM 模型生成的最终答案:
- 答案严格限定在检索到的3个文档内容范围内
- 技术细节(如ES256算法、Envoy配置)均源自知识库
- 结构化输出符合Prompt中“分步骤实施”的要求
1. 双向TLS认证
为每个微服务部署由私有CA签发的X.509证书
在Envoy代理层强制启用mTLS,验证服务证书合法性
2. 身份认证增强
服务间调用时在HTTP头部嵌入JWT令牌
令牌需包含服务ID、时间戳,使用ES256算法签名
3. 动态令牌管理
通过API网关验证令牌签名和有效期
每小时轮换一次令牌密钥,历史密钥保存于密钥保险库
4. 审计监控
记录所有服务通信的TLS协议版本和加密套件
对未通过mTLS认证的请求触发实时告警2、关键技术
(1) 数据预处理与知识结构化
1)多源异构数据整合
- 数据加载与格式转换:支持PDF、HTML、数据库、API等来源,通过OCR(如Tesseract)提取扫描文档,利用PyPDF2、Unstructured等库解析结构。
- 数据清洗与标准化:去除噪声(如HTML标签、重复段落)、统一编码格式(UTF-8)、修复缺失字符,并提取元数据(文件来源、时间戳、作者等)。
- 敏感信息脱敏:通过正则表达式或NLP模型识别身份证号、电话等隐私数据,进行掩码或替换处理。
2)文本分块策略
- 固定窗口分块:按固定Token数(如512)分割,简单但可能破坏语义连贯性。
- 语义分块:使用NLP模型(如BERT)检测语义边界,结合标点、段落结构分割。
- 递归分割(RAPTOR) :先粗粒度分块,再对复杂段落二次分割,平衡粒度与上下文完整性。
- 动态分块:根据检索效果反馈调整分块大小,例如对法律条文采用小分块,对研究报告采用大分块。
3)元数据增强
- 结构化字段附加:为每个分块添加标题、章节、关键词、实体标签(如Spacy提取)等元数据,支持混合检索。
- 层级关系标记:记录分块间的父子关系(如“段落-子条款”),支持父文档检索时重建完整上下文。
(2) 向量化与索引构建
1)嵌入模型选择与优化
- 通用模型:如text-embedding-3-small、BAAI/bge-base,适用于通用领域语义编码。
- 领域微调:在垂直领域数据(如医学文献)上继续训练嵌入模型,提升专业术语的向量表征能力。
- 多向量嵌入:对同一文本生成多个视角的嵌入(如关键词、摘要、实体),增强检索鲁棒性。
2)索引结构与优化算法
- HNSW(Hierarchical Navigable Small World) :基于图结构的近似最近邻算法,支持亿级向量毫秒级检索,适合高召回场景。
- IVF-PQ(Inverted File with Product Quantization) :通过聚类和量化压缩向量,牺牲少量精度换取内存占用降低10倍。
- 混合索引:对元数据字段构建倒排索引,与向量索引联动,实现“向量+关键词”联合检索。
3)分布式存储架构
- 水平分片:按数据特征(如时间、主题)分片存储,结合一致性哈希实现负载均衡。
- 冷热分离:高频访问数据驻留内存,低频数据存入磁盘,通过LRU策略动态调整。
(3) 检索优化策略
1)查询重构技术
- HyDE(Hypothetical Document Embedding) :先用LLM生成假设性答案,将其作为查询向量,提升语义对齐度。
- 子查询分解:将复杂问题拆解为多个子问题(如“新冠症状与治疗”拆为症状、药物、疗程),并行检索后合并。
- 多语言查询扩展:对非英语查询生成同义词、翻译版本,扩大检索覆盖面。
2)混合检索与重排序
- BM25+向量融合:BM25捕获关键词匹配,向量模型捕捉语义相似度,加权得分(如0.4BM25 + 0.6向量)。
- 交叉编码器重排序:使用MiniLM、Cohere Reranker等模型对Top-K结果重新打分,综合上下文相关性。
- 多样性控制:通过MMR(最大边际相关性)算法避免结果冗余,确保返回不同视角的信息。
3)上下文压缩与摘要
- 抽取式压缩:用BERT模型识别检索结果中的关键句子,减少输入长度。
- 生成式摘要:调用LLM生成检索内容的浓缩版,保留核心信息,节省Token消耗。
三、相关优化方案
| 挑战 | 推荐工具链 | 关键指标目标 |
| 延迟优化 | Faiss-GPU + Redis + Triton推理服务器 | P99延迟<100ms |
| 数据新鲜度 | Kafka + Delta Lake + DVC | 更新延迟<5分钟 |
| 幻觉抑制 | SelfCheckGPT + UMLS + Beam Search | 幻觉率<5% |
1、延迟优化
(0)技术挑战
- 向量检索延迟:10亿级向量库查询耗时可达200ms以上
- 上下文融合开销:多文档拼接导致prompt长度增长(如从512 tokens到2048 tokens)
- 生成模型计算量:每增加1个检索文档,生成时间线性增长约15%
(1)向量索引优化
- HNSW算法:构建分层图结构,复杂度从O(n)降到O(log n)
# 使用Faiss实现HNSW
index = faiss.IndexHNSWFlat(dim, 32)
index.hnsw.efSearch = 128 # 平衡精度与速度- IVF-PQ量化:将768维向量压缩至64字节,内存占用减少12倍
- 乘积量化(Product Quantization)将向量切分为8个子空间,每个子空间用256个质心表示
(2)混合缓存策略
- 预计算缓存:对高频query进行离线向量预存(LRU缓存淘汰策略)
- 结果缓存:使用Redis存储<query_hash, top3_docs>映射,命中率可达85%+
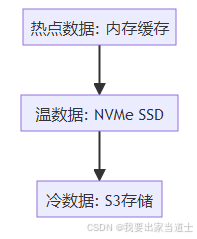
- 分层存储:
(3)硬件加速
- GPU加速检索:Nvidia GPU加速的Faiss-GPU库比CPU版本快50倍
- 模型蒸馏:将BERT-large蒸馏为TinyBERT,嵌入质量损失<3%但速度提升8倍
(4)行业案例
Salesforce Einstein客服系统:
- 采用HNSW+IVF_PQ组合索引,10亿文档查询延迟从320ms降至47ms
- 使用GPU集群并行处理,QPS(每秒查询数)从120提升至2100
2、幻觉抑制
LLM 大模型的一个很严重的缺点就是无法确保内容可靠性。
(0)技术挑战
- 检索失效:Top-K文档未包含正确答案(负样本占比>40%时风险激增)
- 过度泛化:模型强行填补知识缺口(如编造不存在的法律条款)
- 上下文污染:低相关性文档干扰生成过程
(1)检索阶段过滤
- 置信度阈值:仅保留相似度>0.85的文档
- 元数据过滤:
# 按时间/权威性过滤
filter = {"publish_date": ">2023-01-01", "source": ["CDC", "WHO"]}
results = vector_db.search(query, filter=filter)(2)生成过程控制
- 受控解码:
# 使用Constrained Beam Search
from transformers import AutoTokenizer, AutoModelForCausalLM
model = AutoModelForCausalLM.from_pretrained("gpt-3.5-turbo")
constraints = ["COVID-19", "vaccine"] # 强制包含关键词
outputs = model.generate(inputs, constraints=constraints)- 温度调度:初始生成阶段temperature=0.3,后续逐步放宽至0.7
(3)后处理验证
- 自一致性检查:
# 使用SelfCheckGPT检测
from selfcheck import SelfCheck
detector = SelfCheck()
score = detector.check(claim="病毒可通过空气传播", context=retrieved_docs)
if score < 0.6:
return "根据现有资料无法确认该结论"- 知识图谱验证:将生成实体链接到Wikidata/领域KG验证关系正确性
(4)行业应用
梅奥诊所诊断辅助系统:
- 采用BioBERT重排序器,将医学文献相关性评分提升35%
- 集成UMLS医学本体库进行实体校验,幻觉率从22%降至3.7%
- 实时监控FDA药品数据库更新,确保处方建议合规性
3、知识新鲜度
(0)技术挑战
- 更新滞后性:传统ETL流程导致数据更新周期>T+1;
- 版本冲突:新旧知识混合引发信息不一致;
- 变更检测:如何识别文档关键修改(如法律条款修订);
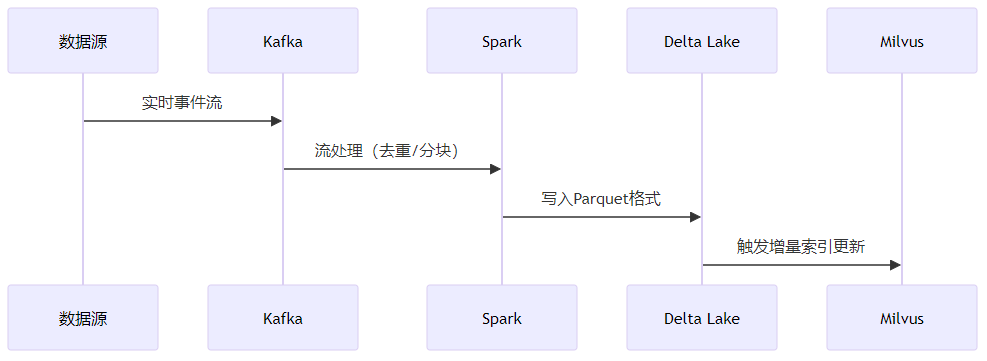
(1)流式处理架构
(2)增量索引技术
- 删除处理:维护倒排列表记录失效文档ID
- 增量编码:仅对新文档进行向量化(节约90%计算资源)
- 版本快照:使用DVC(Data Version Control)管理不同时间点的知识库版本
(3)变更检测算法
- 文本差分:基于最长公共子序列(LCS)识别修改段落
- 语义变化检测:
from sentence_transformers import util
old_embedding = model.encode(old_text)
new_embedding = model.encode(new_text)
if util.cos_sim(old_embedding, new_embedding) < 0.92:
trigger_update()(4)行业实践
彭博金融终端RAG系统:
- 整合100+实时数据源(路透社/财报电话会议)
- 使用Kafka Streams实现从数据更新到索引生效的端到端延迟<2分钟
- 动态调整经济指标权重(如CPI数据发布后自动提升相关文档优先级)
4、RAG 应用优化
主要从下图中黄色对话框内标注的模块进行优化。
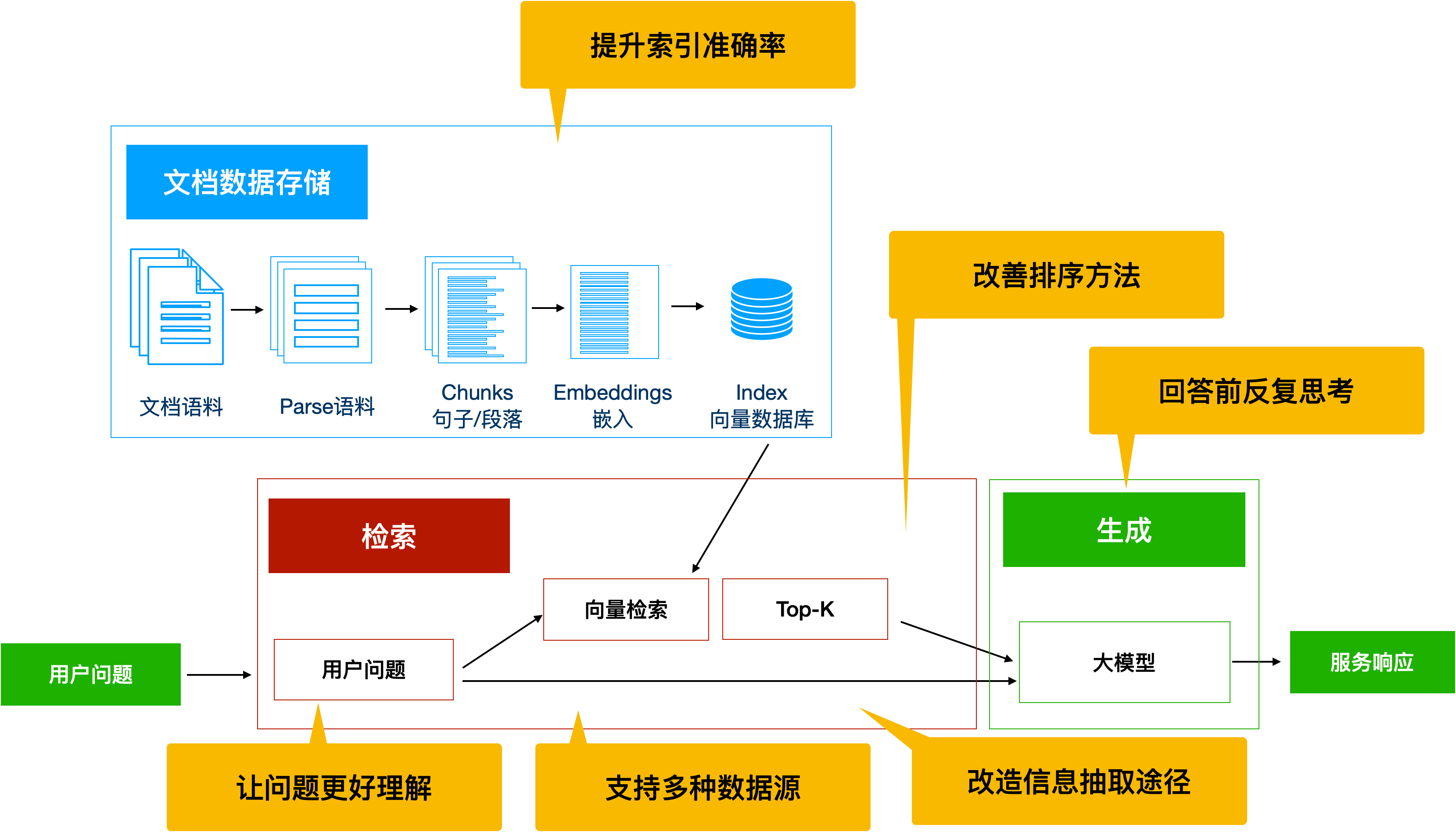
具体可参考阿里云教程:
阿里云大模型工程师ACA认证免费课程![]() https://edu.aliyun.com/course/3126500/lesson/342570338
https://edu.aliyun.com/course/3126500/lesson/342570338