C++—stack/queue/deque:stack和queue的使用及模拟实现
目录
一. stack和queue的使用
1.1 stack的使用
1.1.1 接口说明
1.1.2 相关题目及解析
1.2 queue的使用
1.2.1 接口说明
1.2.2 相关题目解析
二. stack和queue的模拟实现
2.1 容器适配器的相关知识
2.2 stack的模拟实现
2.3 queue的模拟实现
三. deque(双端队列)的使用及底层剖析
3.1 deque的使用
3.2 deque的底层剖析
3.2.1 deque 的核心特点
3.2.2 deque 的底层数据结构
3.3 deque特性总结
3.4 为什么选择deque作为stack和queue的底层默认容器
3.5 比较deque与vector的下标访问效率
3.5.1 直接使用sort函数比较
3.5.3 将deque中的数据拷贝到vector中,排序后再拷贝回deque,与直接排vector中的数据比较
四. vector/list/deque 比较
4.1 各容器的优缺点
1. std::vector
底层结构:
优点:
缺点:
2. std::list
底层结构:
优点:
缺点:
3. std::deque
底层结构:
优点:
缺点:
对比表格
4.2 各容器适用场景总结
结语
一. stack和queue的使用
1.1 stack的使用
1.1.1 接口说明
| 函数说明 | 接口说明 |
| stack() | 构造空的栈 |
| empty() | 检测stack是否为空 |
| size() | 返回stack中元素的个数 |
| top() | 返回栈顶元素的引用 |
| push() | 将元素val压入stack中 |
| pop() | 将stack中尾部的元素弹出 |
1.1.2 相关题目及解析
1、最小栈
思路:
1. 建立两个栈 st 和 minst,st 是用来存储所有数据,minst 是用来存储最小值的栈
2. 入栈时,数据直接push到st;如果minst栈为空,则也直接入栈,如果不为空,则将该数据与minst栈顶数据比较,如过比栈顶数据小就将这个数据push到minst栈中,反之则不push到minst
3. 出栈时,先判断minst和st栈是否为空,不为空,则将minst栈顶数据与st栈顶数据比较,如果相等,则两个栈都pop数据;不相等则只pop st中的数据
class MinStack {
public:MinStack() {}void push(int val) {st.push(val);if(minst.empty() || val <= minst.top()){minst.push(val);}}void pop() {if(!minst.empty() && !st.empty() && st.top() == minst.top()){minst.pop();} if(!st.empty()){st.pop();}}int top() {return st.top();}int getMin() {return minst.top();}private:stack<int> st;stack<int> minst;
};2、栈的压入弹出序列
思路:
1. 入栈序列入栈
2. 栈顶数据与出栈序列比较
2.1 相等储蓄出栈顶,知道不相等或栈为空
2.2 不相等,继续入栈
结束条件:入栈序列走完了
class Solution {
public:bool IsPopOrder(vector<int>& pushV, vector<int>& popV) {// write code herestack<int> st;size_t pushi=0,popi=0;while(pushi<pushV.size()){st.push(pushV[pushi]);while(!st.empty() && st.top() == popV[popi]){st.pop();++popi;}++pushi;}return st.empty();}};3、逆波兰表达式求值
思路:
1、运算数,入栈
2、运算符,取栈顶的两个数据运算,运算结果继续入栈
class Solution {
public:// 后缀序列// 运算数顺序不变,运算符优先级已经排好了int evalRPN(vector<string>& tokens) {stack<int> st;for(auto& str : tokens){if(str == "+" || str == "-" || str == "*" || str == "/"){// 运算符int right = st.top();st.pop();int left = st.top();st.pop();switch(str[0]) // 这里必须是整形{case '+':st.push(left + right);break;case '-':st.push(left +- right); break; case '*':st.push(left * right);break;case '/':st.push(left / right);break;}}else{// 要把字符串转换为整型st.push(stoi(str));}}return st.top();}
};1.2 queue的使用
1.2.1 接口说明
| 函数声明 | 接口说明 |
| queue() | 构造空的链表 |
| empty() | 判断队列是否为空,是返回true,否则返回false |
| push() | 在队尾将元素val入队列 |
| pop() | 将队头元素出队列 |
| front() | 返回队头元素的引用 |
| back() | 返回队尾元素的引用 |
| size() | 返回队列中有效元素的个数 |
1.2.2 相关题目解析
二叉树的层序遍历
思路:
1、创建一个队列来放置节点,创建一个变量levelSize来记录每一层的节点个数
2、先将根节点入队列,并将levelSize置为1
3、队列不为空时,创建vector<int>容器 v 用来存储每一层的数据,将队头节点数据存储后再将其弹出,如果该节点有左右子树节点就将其左右子树节点入队列
3、更新levelSize为队列中节点个数
4、创建vector<vector>容器 vv 将 v 中的数据插入到里面,最后返回
class Solution {
public:vector<vector<int>> levelOrder(TreeNode* root) {queue<TreeNode*> q;int levelSize = 0;if (root) {q.push(root);levelSize = 1;}vector<vector<int>> vv;while (!q.empty()) {//一层一层出完vector<int> v;while (levelSize--) {TreeNode* front = q.front();q.pop();v.push_back(front->val);if (front->left) {q.push(front->left);}if (front->right) {q.push(front->right);}}levelSize = q.size();vv.push_back(v);}return vv;}
};二. stack和queue的模拟实现
2.1 容器适配器的相关知识
stack和queue是容器适配器,也是容器的一种,在模拟实现前我们先学习一下容器适配器。
在 C++ 中,容器适配器(Container Adapters) 是一种特殊的容器类型,它通过封装底层的基础容器(如 vector、deque、list),并提供一组特定的接口,来模拟某种经典的数据结构(如栈、队列、优先队列)的行为。
适配器本身不直接存储数据,而是依赖底层容器来存储元素,它只提供了一个新的 “接口视图”,限制了对底层容器的访问方式,以符合特定数据结构的语义。
核心特性:
- 依赖底层容器:适配器没有自己的存储结构,必须绑定一个基础容器(如
deque、vector、list)来实现存储。 - 接口受限:适配器只暴露特定数据结构所需的接口(如栈的
push/pop/top,队列的push/pop/front),隐藏了底层容器的其他接口(如随机访问、迭代器遍历),避免违反数据结构的语义。 - 不支持迭代器:由于适配器的核心是 “限制访问方式”,因此它通常不提供迭代器(
priority_queue完全不支持,stack和queue也仅在 C++20 后支持有限的迭代器),防止用户通过迭代器破坏其封装的逻辑。
容器适配器的优缺点:
优点:
- 语义清晰:直接模拟栈、队列等经典数据结构,代码可读性高(如用
stack表示递归调用栈,用priority_queue表示任务调度优先级)。 - 封装性强:隐藏底层容器的无关接口,避免误操作(如栈不能直接访问中间元素,队列不能从中间删除元素)。
-
复用底层容器:无需重新实现存储逻辑,直接复用
vector、deque等高效容器的性能优化(如内存分配、缓存友好性)。
缺点:
- 灵活性不足:不支持迭代器,无法遍历元素(如不能遍历
stack的所有元素,需弹出后记录,破坏栈结构)。 - 接口有限:仅提供特定数据结构的核心接口,无法进行底层容器的高级操作(如
vector的reserve预分配内存,list的splice合并链表)。 - 底层依赖:性能受底层容器影响(如
stack用vector时,扩容会有拷贝开销;用list时,缓存命中率低)。
2.2 stack的模拟实现
namespace Stack
{// 这样从头开始写太麻烦了,我们可以直接用容器来操作//template<class T>//class stack//{// // ...//private:// T* _a;// size_t _top;// size_t capacity;//};// 容器适配器,适配是一种转换,用容器适配转换实现栈// 适配封装实现// 给数组、顺序表、链表都可以template<class T, class Container = deque<T>> class stack{ public:// 不用写构造、拷贝、析构等,默认生成的就够用void push(const T& x){_con.push_back(x);// 如果容器不支持push_back接口就报错,说明那个容器不能适配stack// 必须支持这个接口,才能用那个容器来适配stack}void pop(){_con.pop_back();}const T& top(){return _con.back();// vector和list都有front和back接口,其实是为这里准备的,平时很少用}size_t size(){return _con.size();}bool empty(){return _con.empty();}// 纯粹就是封装private:Container _con;};2.3 queue的模拟实现
namespace Queue
{// 链式队列,队列只能用list、deque来适配// 用容器转换,封装适配出队列template<class T, class Container = deque<T>>class queue{public:// 不用写构造、拷贝、析构等,默认生成的就够用void push(const T& x){_con.push_back(x);// 如果容器不支持push_back接口就报错,说明那个容器不能适配stack// 必须支持这个接口,才能用那个容器来适配stack}void pop(){_con.pop_front();//_con.erase(); // 可以用这个让vector容器也能是实例化,但是效率很低}const T& front(){return _con.front();// vector和list都有front和back接口,其实是为这里准备的,平时很少用}const T& back(){return _con.back();// vector和list都有front和back接口,其实是为这里准备的,平时很少用}size_t size(){return _con.size();}bool empty(){return _con.empty();}// 纯粹就是封装private:Container _con;};三. deque(双端队列)的使用及底层剖析
3.1 deque的使用
deque的使用可以理解为vector和list的结合,既支持头部和我尾部的插入删除,也支持随机访问
int main()
{deque<int> dq;dq.push_back(1);dq.push_back(2);dq.push_front(0);dq.push_front(-1);dq.pop_back();dq.pop_front();dq[0] += 10;for (auto e : dq){cout << e << " ";}cout << endl;
}3.2 deque的底层剖析
deque(双端队列):是一种双开口的"连续"空间的数据结构,双开口的含义是:可以在头尾两端进行插入和删除操作,且时间复杂度为O(1),与vector比较,头插效率高,不需要搬移元素;与 list比较,空间利用率比较高。
3.2.1 deque 的核心特点
在深入底层之前,我们先回顾一下 std::deque 的主要特性,这有助于我们理解其设计动机:
- 双端高效操作:在队列的前端(
push_front,pop_front)和后端(push_back,pop_back)进行插入和删除操作的时间复杂度通常是 O(1)。 - 随机访问:可以像数组一样通过索引直接访问元素,时间复杂度为 O(1)。
- 动态大小:可以根据需要动态增长和收缩,无需手动管理内存。
- 非连续存储:这是
deque与vector最核心的区别。vector的元素存储在一块连续的内存区域,而deque的元素则分散在多个不连续的内存块中。
deque并不是真正连续的空间,而是由一段段连续的小空间拼接而成的,实际deque类似于一个 动态的二维数组,其底层结构如下图所示:
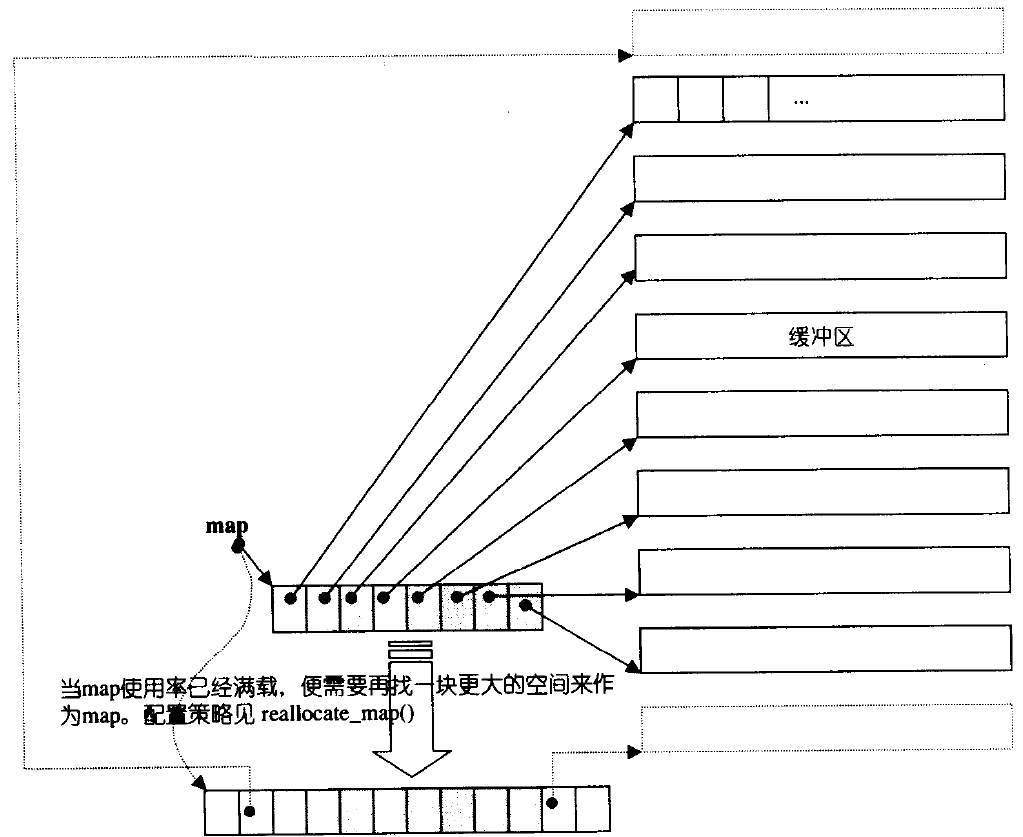
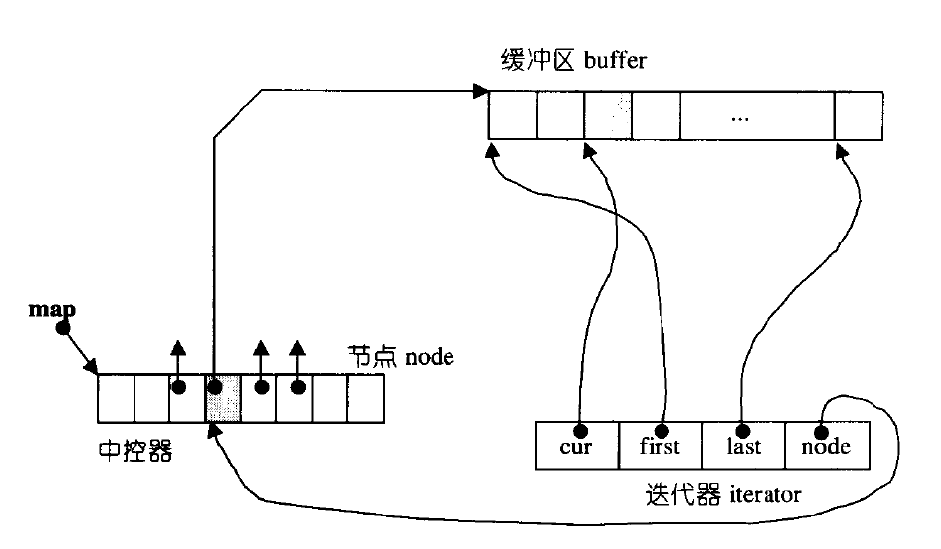
双端队列底层是一段假象的连续空间,实际是分段连续的,为了维护其“整体连续”以及随机访问 的假象,落在了deque的迭代器身上,因此deque的迭代器设计就比较复杂,如下图所示:
3.2.2 deque 的底层数据结构
std::deque 的底层实现通常是一个 ** 中央控制器(Central Controller)加上多个缓冲区(Buffer)** 的组合结构。
可以把它想象成一个 “分段的数组”,由一个 “管理层” 来维护这些分段。
-
缓冲区(Buffer)
- 这是实际存储元素的地方,是一段连续的内存。
- 每个缓冲区的大小是固定的,通常由实现决定(例如,GCC 的 STL 中,每个缓冲区默认可以存储 512 字节的数据,如果元素是
int(4 字节),那么一个缓冲区就可以存 128 个int)。 - 当一个缓冲区被填满后,
deque会分配一个新的缓冲区。
-
中央控制器
- 这是
deque的 “大脑”,它负责管理所有的缓冲区。 - 它通常是一个指针数组(或者一个动态增长的数组),我们称之为 “地图”(map)。这个数组中的每个元素都是一个指针,指向一个缓冲区。
- 这是
-
迭代器(Iterator)
deque的迭代器是一个复杂的对象,它需要能够跨越不同的缓冲区。- 一个典型的
deque迭代器内部会包含:一个指向当前所在缓冲区的指针(cur);一个指向当前缓冲区起始位置的指针(first);一个指向当前缓冲区末尾位置的指针(last);一个指向中央控制器中对应指针的指针(node)。
根据下面图象我们能够更加清晰的观察到deque的底层实现
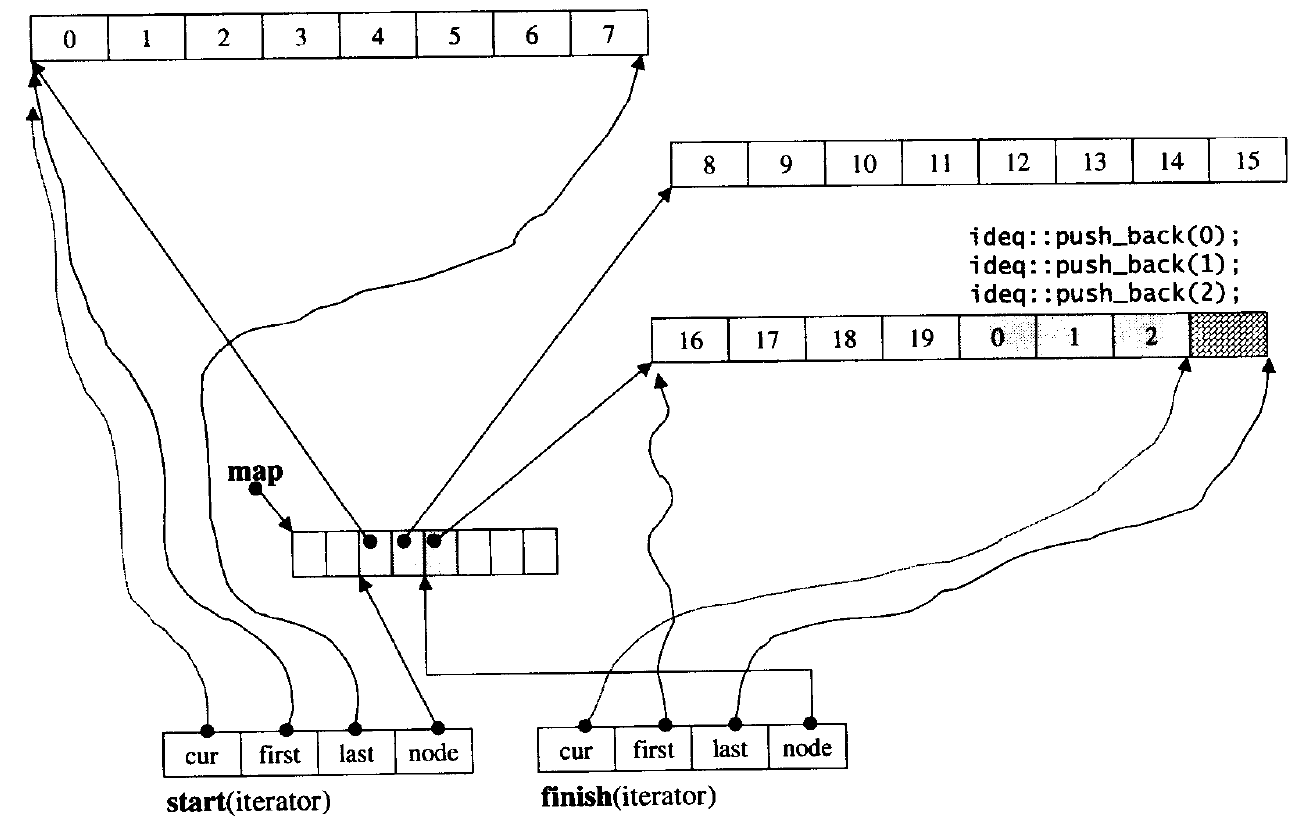
3.3 deque特性总结
deque设计的初衷是希望能够结合vector和list的优点,但是很显然,它并没有完全实现,如果我们想要在这中间位置实现插入删除时,依然需要挪动数据,时间复杂度为O(N)
deque的优点:
- 它通过分段连续存储和中央控制器的机制,实现了在两端的 O (1) 时间复杂度插入和删除。
- 它通过计算缓冲区索引和偏移量的方式,实现了O (1) 时间复杂度的随机访问。
- 与vector比较,deque的优势是:头部插入和删除时,不需要搬移元素,效率特别高,而且在扩容时,也不需要搬移大量的元素,因此其效率是必vector高的。
- 与list比较,其底层是连续空间,空间利用率比较高,不需要存储额外字段。
deque的缺陷:
- 迭代器实现复杂:
deque的迭代器比vector和list的迭代器都要复杂,这会带来一些性能开销。 - 随机访问效率略低:虽然是 O (1),但
deque的随机访问需要进行缓冲区计算和指针跳转,因此通常比vector慢。而序列式场景中,可能需要经常遍历,因此需要线性结构时,大多数情况下优先考虑vector和list, - 内存开销稍大:除了存储元素本身,
deque还需要维护中央控制器和每个缓冲区的管理信息。
3.4 为什么选择deque作为stack和queue的底层默认容器
deque的应用并不多,而目前能看到的一个应用就是,STL用其作为stack和queue的底层数据结构,那为什么选择deque呢?
stack是一种后进先出的特殊线性数据结构,因此只要具有push_back()和pop_back()操作的线性结构,都可以作为stack的底层容器,比如vector和list都可以;queue是先进先出的特殊线性数据结构,只要具有push_back()和pop_front()操作的线性结构,都可以作为queue的底层容器,比如 list。但是STL中对stack和queue默认选择deque作为其底层容器,主要是因为:
- stack和queue不需要遍历(因此stack和queue没有迭代器),只需要在固定的一端或者两端进行操作。
- 在stack中元素增长时,deque比vector的效率高(扩容时不需要搬移大量数据);queue中的 元素增长时,deque不仅效率高,而且内存使用率高。
结合了deque的优点,而完美的避开了其缺陷。
3.5 比较deque与vector的下标访问效率
通过sort排序的速度,来比较下标访问的速率,因为排序算法主要是通过下标来访问数据进行排序
3.5.1 直接使用sort函数比较
void test_op1()
{srand(time(0));const int N = 1000000;deque<int> dq;vector<int> v;for (int i = 0; i < N; ++i){auto e = rand() + i;v.push_back(e);dq.push_back(e);}int begin1 = clock();sort(v.begin(), v.end());int end1 = clock();int begin2 = clock();sort(dq.begin(), dq.end());int end2 = clock();printf("vector:%d\n", end1 - begin1); // 更快printf("deque:%d\n", end2 - begin2);
}3.5.3 将deque中的数据拷贝到vector中,排序后再拷贝回deque,与直接排vector中的数据比较
void test_op2()
{srand(time(0));const int N = 1000000;deque<int> dq1;deque<int> dq2;for (int i = 0; i < N; ++i){auto e = rand() + i;dq1.push_back(e);dq2.push_back(e);}int begin1 = clock();sort(dq1.begin(), dq1.end());int end1 = clock();int begin2 = clock();// 拷贝到vectorvector<int> v(dq2.begin(), dq2.end());sort(v.begin(), v.end());dq2.assign(v.begin(), v.end());int end2 = clock();printf("deque sort:%d\n", end1 - begin1);printf("deque copy vector sort, copy back deque:%d\n", end2 - begin2); // 把deque中的数据拷贝到vector,排完之后再拷贝回deque都比直接将deque排序快
}
总结:通过上面的测试我们可以得知,涉及到下标随机访问最好用vector
四. vector/list/deque 比较
C++ 标准库中的 std::vector、std::list 和 std::deque 这三种常用序列容器。
它们的核心差异源于底层数据结构的不同,这直接决定了它们在不同操作场景下的性能表现。
4.1 各容器的优缺点
1. std::vector
底层结构:
- 动态数组,内存连续分配。
- 当容量不足时,会重新分配一块更大的内存(通常是原来的 1.5 或 2 倍),并将所有元素拷贝过去。
优点:
- 随机访问效率极高:
O(1),直接通过索引访问元素。 - 尾插 / 尾删效率高:
O(1)( amortized,平均时间),除非需要扩容。 - 内存局部性好:连续的内存布局使得 CPU 缓存命中率高。
- 空间利用率较高:相比
list,没有额外的指针开销。
缺点:
- 中间插入 / 删除效率低:
O(n),需要移动插入 / 删除点后的所有元素。 - 扩容开销:重新分配内存和拷贝元素会导致性能波动。
- 不适合频繁在头部操作:头插 / 头删也是
O(n)时间。
2. std::list
底层结构:
- 双向链表,每个节点包含数据、前驱指针和后继指针。
- 内存不连续,节点分散在堆上。
优点:
- 任意位置插入 / 删除效率高:
O(1),只需修改指针指向,无需移动元素。 - 不需要扩容:节点按需分配,没有内存浪费。
- 迭代器稳定性:插入 / 删除元素时,其他元素的迭代器不会失效(仅被删除节点的迭代器失效)。
缺点:
- 随机访问效率低:
O(n),必须从头或尾遍历到目标位置,不支持下标随机访问。 - 内存开销大:每个节点需要额外存储两个指针。
- 内存局部性差:节点分散,CPU 缓存命中率低。
3. std::deque
底层结构:
- 双端队列,结合了
vector和list的特点。 - 底层是分段连续的内存块,通过一个中央索引数组管理这些块。
优点:
- 头尾操作效率高:
O(1),两端都可以快速插入和删除。 - 随机访问效率较高:
O(1),但比vector稍慢(需要两次指针解引用)。 - 无扩容开销:分段分配内存,不需要整体拷贝。
- 内存局部性较好:CPU高速缓存命中率不错
缺点:
- 中间插入 / 删除效率低:
O(n),需要移动元素。 - 内存开销较大:中央索引数组和每个块的额外管理成本。
- 迭代器复杂度高:迭代器需要处理跨块的情况,实现较复杂。
对比表格
| 特性 | std::vector | std::list | std::deque |
|---|---|---|---|
| 随机访问 | O(1) | O(n) | O(1) |
| 头部插入 / 删除 | O(n) | O(1) | O(1) |
| 尾部插入 / 删除 | O(1) | O(1) | O(1) |
| 中间插入 / 删除 | O(n) | O(1) | O(n) |
| 扩容机制 | 重新分配拷贝 | 无扩容 | 分段扩容 |
| 内存连续性 | 连续 | 不连续 | 分段连续 |
| 内存开销 | 低 | 高 | 中 |
| 迭代器稳定性 | 插入 / 删除时可能失效 | 稳定(除被删节点) | 插入 / 删除时可能失效 |
| 适用场景 | 频繁随机访问、尾操作 | 频繁插入删除、任意位置操作 | 频繁头尾操作、需要随机访问 |
4.2 各容器适用场景总结
4.2.1 优先用 std::vector 的情况:
- 需要频繁通过索引访问元素。
- 主要在末尾添加或删除元素。
- 对内存占用和缓存性能敏感。
4.2.2 优先用 std::list 的情况:
- 需要在任意位置频繁插入或删除元素。
- 不需要随机访问,只需顺序遍历。
- 对迭代器稳定性要求高。
4.2.3 优先用 std::deque 的情况:
- 需要在两端频繁插入或删除元素,(比如作stack很热queue的默认适配容器)。
- 需要随机访问,但对访问速度要求不是极致。
- 不希望有
vector那样的扩容开销。
总结:deque能用来替代vector和list吗? 不能
vector的核心优势是连续内存 + 高效随机访问,这是deque和list无法比拟的(deque随机访问慢,list根本不适合)。list的核心优势是任意位置 O (1) 插入 / 删除,这是vector和deque做不到的(两者中间操作都是 O (n))。deque的核心优势是双端 O (1) 操作 + 无扩容拷贝,但它在随机访问和中间插入 / 删除上都不如前两者极致,只能作为 “中间选项”。三者的关系不是 “替代”,而是 “互补”—— 实际开发中需根据具体操作场景选择
结语
如有不足或改进之处,欢迎大家在评论区积极讨论,后续我也会持续更新C++相关的知识。文章制作不易,如果文章对你有帮助,就点赞收藏关注支持一下作者吧,让我们一起努力,共同进步!