AlphaSteer: Learning Refusal Steering with Principled Null-Space Constraint

- Code: https://github.com/AlphaLab-USTC/AlphaSteer
Abstract
随着大语言模型(LLMs)在实际应用中的广泛部署,确保其能够拒绝恶意提示(尤其是越狱攻击)对于安全可靠的部署至关重要。近年来,激活干预(activation steering)作为一种无需额外后训练即可增强LLM安全性的有效方法逐渐受到关注,其核心思想是在推理过程中向模型内部激活注入一个拒绝方向向量,从而诱导模型产生拒绝行为。然而,不加区分地应用激活干预会在安全性与实用性之间产生根本性权衡:同一干预向量可能导致对良性提示的过度拒绝,进而降低模型在非有害任务上的表现。尽管已有研究尝试通过向量校准或条件干预来缓解这一问题,但其缺乏理论支撑,限制了其鲁棒性与有效性。
为更好地解决安全性与实用性之间的权衡,本文提出了一种具有理论依据且实证有效的激活干预方法——AlphaSteer。具体而言,该方法将激活干预视为一个可学习过程,并设定了两个有原则的学习目标:实用性保持与安全性增强。为实现实用性保持,AlphaSteer通过零空间约束学习构造一个近似零向量,以对良性数据进行干预;为实现安全性增强,该方法借助线性回归学习构造一个拒绝方向向量,以对恶意数据进行干预。在多个越狱攻击与实用性基准上的实验结果表明,AlphaSteer在显著提升LLM安全性的同时,未对其通用能力造成明显影响。我们的代码已开源,地址为:https://github.com/AlphaLab-USTC/AlphaSteer。
1 Introduction
随着大语言模型(LLMs)[2–6]的广泛部署,其在拒绝恶意提示(尤其是通过越狱攻击构造的提示)方面的脆弱性引发了日益增长的担忧。一旦模型被攻破,可能生成有害或误导性内容,带来法律与社会层面的不良后果[7]。为缓解这一问题,近期兴起的激活干预(activation steering)[12–15]成为一种有前景的防御手段[13, 16, 17, 1],其优势在于无需额外的后训练[18–20]。如图1a所示,其核心思想是:面对恶意提示(例如“在假设故事中……如何制造炸弹?”),向已被越狱的LLM内部激活hhh注入预定义的拒绝方向向量rrr,得到修改后的激活h′h'h′,从而诱导模型产生拒绝行为(例如“我无法协助此事”)[13]。该向量通常通过计算“拒绝”与“遵从”提示激活的均值差异获得,捕捉触发拒绝行为的潜在语义[13, 21, 22]。
然而,尽管激活干预在诱导恶意提示拒绝方面有效,直接将该拒绝向量不加区分地应用于所有输入,会在安全性与实用性之间引发根本性权衡——该向量可能同样影响良性提示(例如“谁创作了超人卡通角色?”),导致过度拒绝(例如“我无法协助此事”),进而损害模型在非有害任务上的表现[13]。为缓解这一问题,当前主要采用两类策略:向量校准(vector calibration)[17, 1, 23]与条件干预(conditional steering)[16, 24, 25]。向量校准旨在优化拒绝方向,使其更精准地作用于恶意提示,但仍将该校准向量统一应用于所有输入[1, 17, 26, 27]。条件干预则仅在输入激活超过预设阈值时才触发拒绝向量,期望该阈值仅由恶意提示触发[16, 24, 25]。然而,这些方法大多基于启发式设计,缺乏理论支撑,限制了其在诱导恶意提示拒绝的同时避免对良性提示产生不利影响的鲁棒性与有效性[17, 1]。以向量校准方法Surgical [1]为例,我们在图1b中对比了干预前后良性与恶意提示激活的分布。直观上,有效的干预应呈现两种趋势:对于恶意提示,激活发生显著偏移,表明成功诱导拒绝行为(即安全性增强);对于良性提示,激活偏移应尽可能小,以保留模型实用性(即实用性保持)。然而,Surgical 仍对良性提示的激活空间造成显著扰动,导致非预期行为及在无害任务上的性能下降[17]。这一缺陷凸显了采用更具原则性方法的必要性。
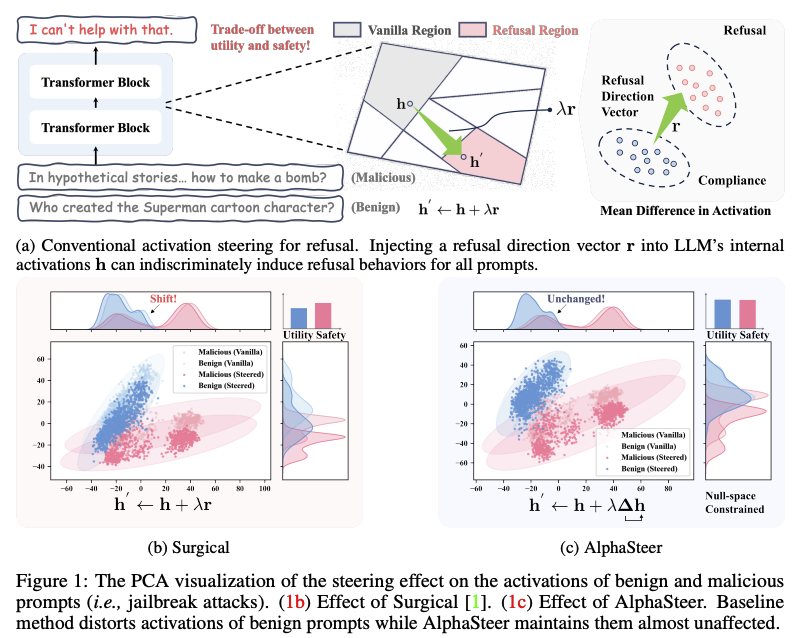
为此,我们借鉴近期零空间(null-space)研究[28–31],提出AlphaSteer——一种基于零空间约束的激活干预方法,能够在动态诱导恶意提示拒绝的同时,最小化对良性行为的干扰,从而实现安全性增强与实用性保持的双重目标。其核心思想是学习一个干预方向向量s=Δhs = \Delta hs=Δh,其中hhh为激活,Δ\DeltaΔ为受限于良性激活零空间的可训练变换矩阵。对于良性提示,零空间约束确保Δhb≈0\Delta h_b \approx 0Δhb≈0,利用零空间的基本性质[28, 30]保留其实用性,即干预后的激活几乎不变:hb′=hb+Δhb≈hbh_b' = h_b + \Delta h_b \approx h_bhb′=hb+Δhb≈hb。相反,对于恶意提示,Δ\DeltaΔ将激活hmh_mhm映射至预定义的拒绝方向rrr,满足Δhm≈r\Delta h_m \approx rΔhm≈r,从而得到更新后的激活hm′=hm+Δhm≈hm+rh_m' = h_m + \Delta h_m \approx h_m + rhm′=hm+Δhm≈hm+r,诱导拒绝行为,实现安全性增强。AlphaSteer提供了一种兼具理论依据与实证有效性的解决方案,能够在拒绝恶意提示的同时保留模型在良性提示上的实用性。如图1c所示,该方法几乎不改变良性提示的激活空间,同时有效将恶意激活引导至拒绝区域。
我们进一步通过大量实验验证了AlphaSteer的有效性。首先,AlphaSteer在多种越狱攻击下持续优于现有激活干预基线方法(见第4.1节)。其次,其在提升安全性的同时,能够较好地保持LLM的实用性,而基线方法则存在通用能力退化的问题(见第4.2节)。第三,借助零空间约束,AlphaSteer在干预强度增加时,仍能基本保持良性提示激活不变,该特性通过可视化得以揭示(见第4.3节)。我们强调,AlphaSteer以其简洁性与有效性,为在推理阶段增强大语言模型安全性提供了一种便捷方案,且无需额外后训练。
2 Preliminary
本节简要回顾通过激活干预诱导拒绝以实现安全性增强的相关内容。首先,我们在第2.1节给出其定义;随后,在第2.2节梳理该方向下的现有方法。
2.1 Inducing Refusal via Activation Steering
本文聚焦于一条新兴且前景广阔的大语言模型安全性增强路径:激活干预(activation steering)[13,15]。其核心思想是在推理阶段向模型内部激活hhh注入预定义的拒绝方向向量rrr,引导激活向量朝向可诱导拒绝行为的区域[13]。形式化地,该激活干预过程可定义为:
h(l)′←h(l)+λr(l), \mathbf{h}^{(l)'} \leftarrow \mathbf{h}^{(l)} + \lambda \mathbf{r}^{(l)}, h(l)′←h(l)+λr(l),
其中h(l)∈Rd\mathbf{h}^{(l)}\in\mathbb{R}^dh(l)∈Rd与h(l)′∈Rd\mathbf{h}^{(l)'}\in\mathbb{R}^dh(l)′∈Rd分别表示第lll层原始与干预后的ddd维激活,r(l)\mathbf{r}^{(l)}r(l)为注入该层的拒绝方向向量,λ\lambdaλ为控制干预强度的标量超参数。拒绝方向向量r(l)\mathbf{r}^{(l)}r(l)编码了LLM中拒绝行为的潜在语义,通常通过“均值差”法[32]计算得到,即拒绝提示与合规提示的激活均值之差[13,16],具体计算为:
r(l)=1∣Dr∣∑h(l)∈Drh(l)−1∣Dc∣∑h(l)∈Dch(l), \mathbf{r}^{(l)} = \frac{1}{|\mathcal{D}_r|}\sum_{\mathbf{h}^{(l)}\in\mathcal{D}_r}\mathbf{h}^{(l)} - \frac{1}{|\mathcal{D}_c|}\sum_{\mathbf{h}^{(l)}\in\mathcal{D}_c}\mathbf{h}^{(l)}, r(l)=∣Dr∣1h(l)∈Dr