论文研读|基于扩散过程的图像篡改定位
前言:本篇博客首先简要介绍AI图像编辑主流方法,然后介绍近期关于基于扩散过程的图像篡改定位研究工作。
推荐🌟:基于扩散模型的图像编辑综述:Diffusion model-based image editing: A survey. TIFS, 2025.
以上综述介绍了多种AI图像的编辑方式,其中一种编辑流程是:首先根据mask定位出编辑区域,然后采用提示文本,对mask区域进行编辑。代表性开源数据集:AutoSplicing(一个基于DALL-E2进行图像编辑的数据集)。图像篡改定位目的就是定位出用于编辑的mask区域。

下面介绍几篇近期关于基于扩散过程的图像篡改定位研究工作。
-
Diff-IFL: Towards General Image Forgery Localization using Diffusion Probabilistic Model. ICME, 2024.
核心思想:提出一种基于扩散模型的通用图像伪造定位方法,将图像伪造定位任务重新定义为“条件性真实掩码重建”问题,并采用扩散概率模型从噪声中逐步恢复出伪造区域的精确掩码。模型采用由粗到精的两阶段结构:- 粗定位模块(Coarse Localization Module, CLM):使用 Swin Transformer + FPN 提取多尺度伪造特征。通过一个辅助的全卷积网络(FCN)解码器生成一个粗掩码,初步定位伪造区域。
- 掩码扩散模块(Mask Diffusion Module, MDM):将真实掩码(GT Mask) 逐步加噪,再通过扩散解码器逐步去噪,恢复出清晰的掩码。在去噪过程中,将CLM提取的伪造特征作为条件先验,引导模型更准确地重建掩码。此外,使用轻量化的扩散解码器(6层Transformer),而非传统U-Net,提升效率。

-
DiffusionFF: Face Forgery Detection via Diffusion-based Artifact Localization. arXiv, 20250803.
核心思想:传统方法(如直接回归)生成的结构差异性(DSSIM)图往往模糊、细节丢失严重。DiffusionFF 使用去噪扩散模型 从噪声逐步生成高保真、细粒度的DSSIM图,能更精确地捕捉伪造痕迹。使用预训练的伪造检测器(如ConvNeXt)提取多尺度特征,作为扩散模型的条件输入。生成的DSSIM图与检测器的高级语义特征通过门控机制融合,提升分类性能。

-
UGD-IML: A Unified Generative Diffusion-based Framework for Constrained and Unconstrained Image Manipulation Localization arXiv, 20250808
核心思想:提出一种基于扩散模型的统一生成式框架,用于同时处理无约束图像篡改定位和有约束图像篡改定位两个任务。UGD-IML 首次将这两个任务整合到同一个模型中,只需通过控制输入图像(是否包含原始图像)即可切换任务模式,无需修改模型结构或重新训练。与以往基于判别式模型的方法不同,UGD-IML 使用扩散模型来学习数据的潜在分布,从而减少对大规模标注数据的依赖。通过逐步去噪的过程生成预测结果,具有更强的鲁棒性、不确定性估计能力和更好的泛化性能。使用目标检测网络DETR作为Decoder,使用DDIM确定性采样,逐步输出预测的篡改区域。

-
SDiFL: Stable Diffusion-Driven Framework forImage Forgery Localization. arXiv, 20250827.
核心思想:传统方法通常将伪造定位视为像素级分类问题(判断每个像素是否被篡改),而本文首次将生成式模型(Stable Diffusion) 引入图像取证领域,将伪造定位视为条件生成问题。借鉴Stable Diffusion V3(SD3)的多模态架构,将高频残差信息(通过SRM滤波器提取)作为显式模态,与图像潜在表示融合,增强模型对篡改痕迹的感知能力。
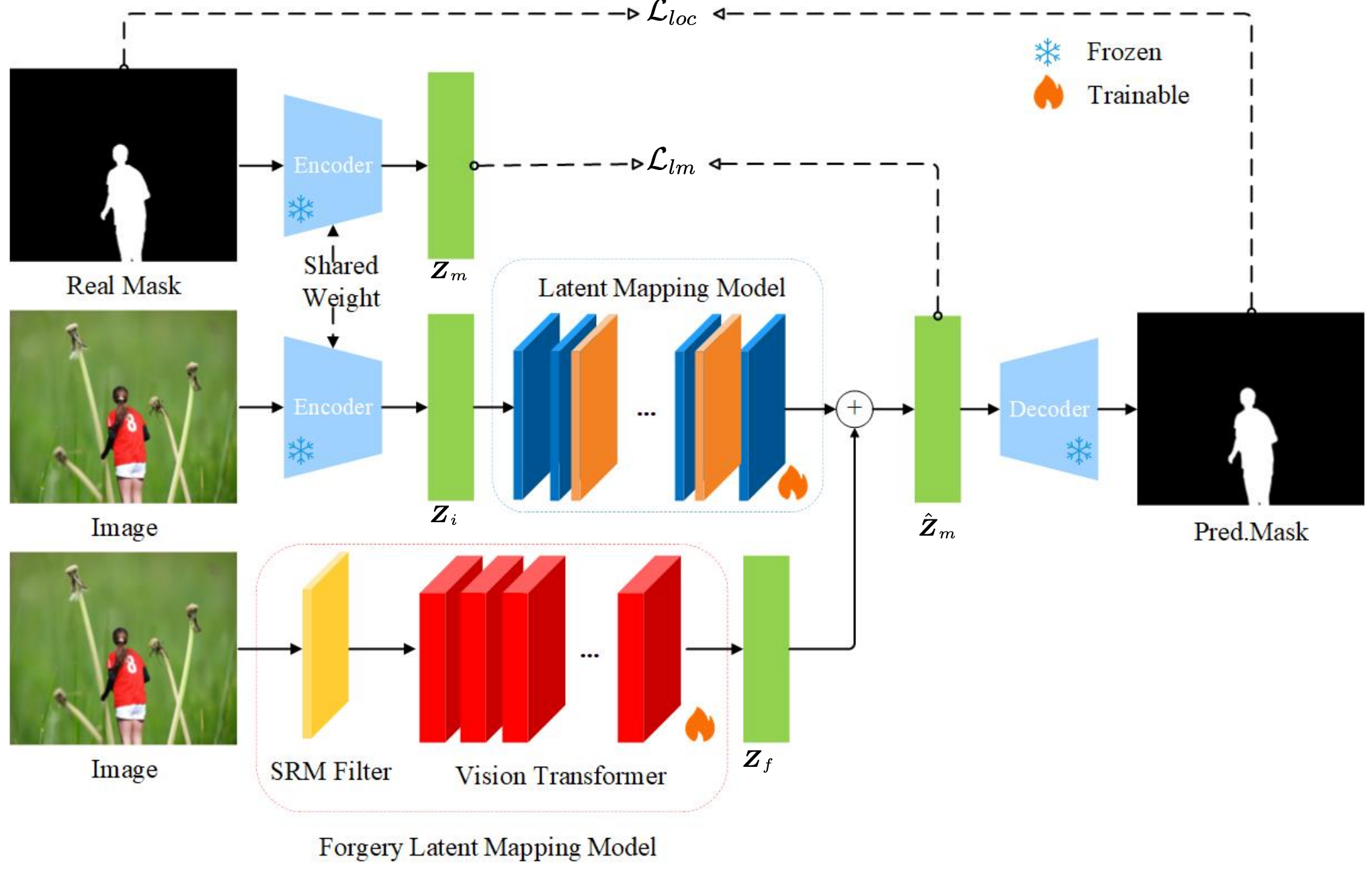
数据层面:采用传统的篡改数据集,tampCoco [8], IMD2020 [32], andCASIA2 [33] datasets. In total, these datasets contain approximately 830,000 manipulated and pristine images with varied forgery patterns. The image resolutions typically range from 384×256 to 1920×1080. These datasets were selected due to their diversity in manipulation types (such as splicing, copymove, and inpainting), the realism of the editing artifacts, andtheir widespread
以下研究工作一篇是关注高分辨率图像的篡改定位,另一篇是关注针对图像的操作链取证。
-
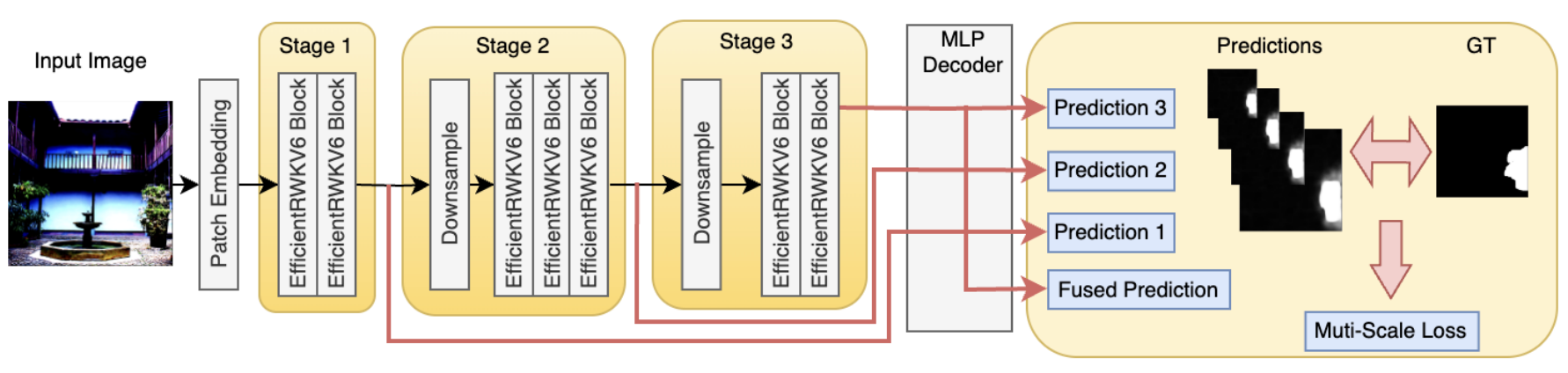
EfficientIML: Efficient High-Resolution Image Manipulation Localization. arXiv, 20250910.
核心思想:提出一个高效的高分辨率图像篡改定位方法,以应对当前图像篡改检测领域在处理高分辨率图像和新兴扩散模型生成篡改时所面临的挑战。
数据层面:首先构建高分辨率图像SIF数据集,包含1200+张分辨率高达1800×1200的图像。对于每张图像,首先使用Universal Image Segmentation[17] (HIPPIE)分割物体定位出mask区域, 然后使用Qwen-VL Plus得到修复提示词,将三者送入SD2进行修复,得到修复图像,未公开
-
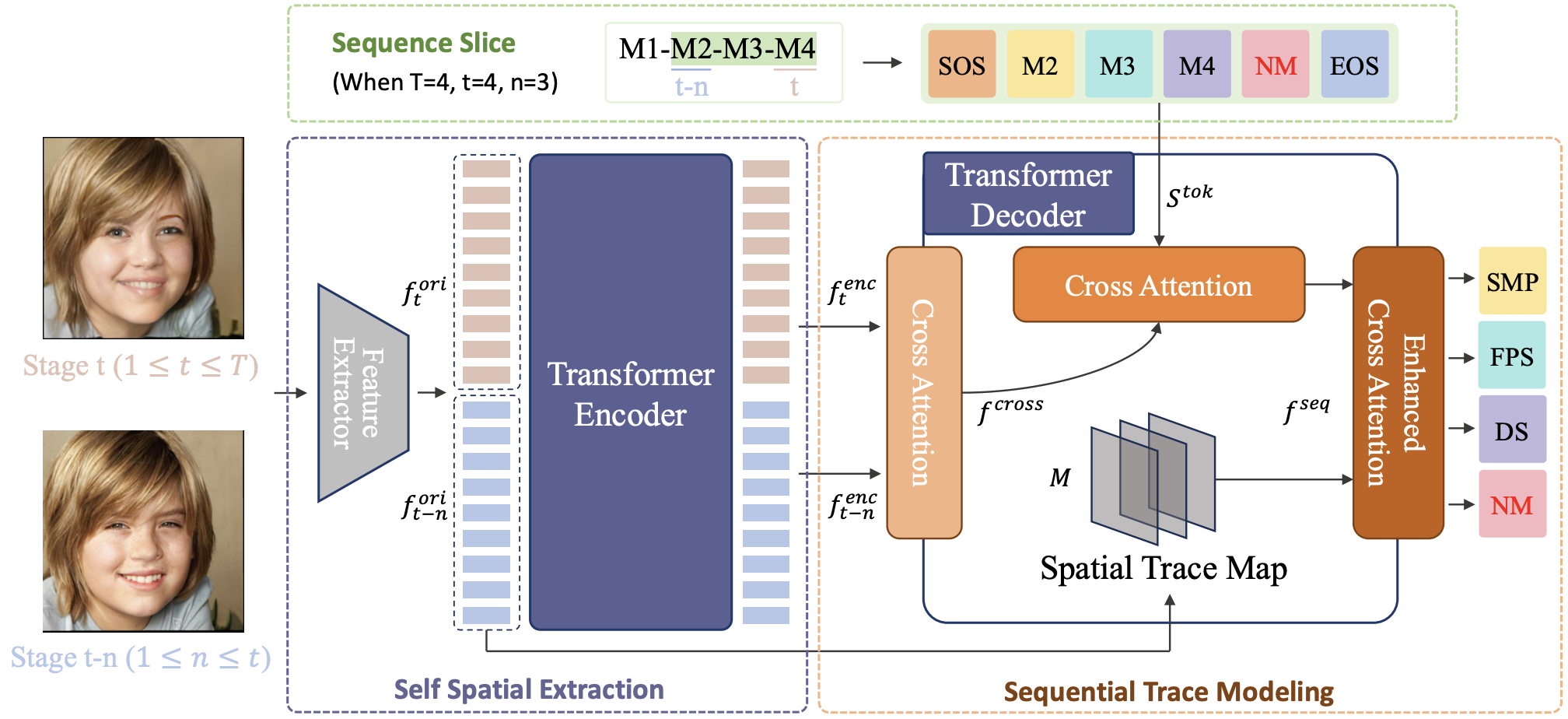
Modelship Attribution: Tracing Multi-Stage Manipulations Across Generative Models. arXiv, 20250603.
核心思想:提出并解决一个全新的任务“模型身份溯源”(Modelship Attribution),旨在追踪图像在多阶段、多模型编辑过程中的完整演化历史。传统的模型溯源方法通常只识别图像是由哪一个生成模型生成的,适用于单阶段生成或篡改的场景。然而,在真实世界中,一张图像可能被多个用户使用不同的生成工具(如 GAN、扩散模型、3D重建模型)多次编辑,导致早期模型的“指纹”被后续操作覆盖,使得传统方法失效。为此,本文由传统的“单模型识别”转向“多阶段操作序列重建”,即不仅要识别出图像是由哪些模型编辑的,还要还原出这些模型的操作顺序,即“谁在什么时候做了什么”。数据层面:构建新数据集 Modelship Deepfake Dataset,使用三种不同架构的人脸替换模型(StyleMapGAN、DiffSwap、FacePartsSwap)对同一张图像进行四阶段编辑(鼻子、眼睛、嘴、眉毛)。包含 83,700 张图像,涵盖 19 种操作序列组合,模拟真实世界中的复杂篡改流程。
方法层面:Modelship Attribution Transformer。其中,Sequence Slice 将多阶段编辑过程切片,分析阶段间的变化;Self Spatial Extraction 使用 CNN + FPN + Transformer 提取图像细微特征;Modelship Trace Modeling 通过交叉注意力机制建模图像差异与操作序列的关系,并引入空间轨迹图突出编辑区域。
总结:当前基于扩散模型的图像篡改区域定位方法能够比较精确地定位出篡改区域(包括使用扩散模型进行篡改的图像),更进一步,如果我们使用扩散模型对图像进行篡改,那么是否能够利用扩散模型的可逆特性,在篡改图像的基础上反推篡改轨迹,恢复出原始图像呢?
本人尝试过使用DDIM inversion和DDIM sampling对测试图像进行加噪,之后采用篡改提示词去噪得到篡改图像。在已知篡改图像、篡改提示词和模型参数的情况下,得到的恢复图像仅能够保留原始测试图像的风格,而无法完全恢复出原始图像的语义和图像结构。
此外,当前针对AI生成图像检测与篡改定位的相关研究工作仍然停留于定位出篡改区域,如何进一步恢复出原始图像也是值得探索的研究问题。