DSAC-T算法实现控制倒立摆
DSAC-T算法实现控制倒立摆
DSAC-T文献地址
DSAC-TGithub源码地址
DSAC算法是基于SAC算法改进得到的,对于如何使用SAC算法实现摆锤任务,可以参考笔者这篇帖子SAC算法实现摆锤
笔者计划使用DSAC-T算法,实现基于Gymnasium库的InvertedPendulum-v5倒立摆任务。
整体代码在文章结尾。
DSAC-T算法的改进点
DSAC-T算法对DSAC算法进行了如下改进:
- 将价值分布的梯度,分为均值相关梯度(随机收益的一阶导);方差相关梯度(随机收益二阶导)。使用目标回报的期望值替换来稳定均值的更新;
- 训练两个独立的值分布模型,采用Q值最低的分布来计算值分布和策略函数的梯度。(减少潜在的高估问题,引入轻微的低估,增强学习的稳定性);
- 防止对任务的奖励尺度过于敏感,实施基于方差的评价网络梯度调整技术,涉及用基于方差的值替换固定边界,用基于方差的梯度缩放权重调节更新。增强不同奖励量级的学习鲁棒性。
主要是对CriticCriticCritic更新进行改进。
Critic更新
DSAC-T相对于SAC算法,将动作状态价值函数从只输出单一值,修改为输出高斯分布的均值和方差。
将值的点估计,改进为分布估计。
但在更新值分布均值时,使用高斯分布随机采样作为目标回报,会导致梯度方差大,训练不稳定,因此在此基础上再改进,引入期望值替代:
- 更新Q值均值时,使用目标Q值的期望替代随机采样值。
- 仅在使用方差计算裁剪边界时保留随机采样。
Critic更新的目标函数是,最小化当前值分布和目标分布之间的KL散度。
JZ(θ)=E[DKL(TπϕZθ~(⋅∣s,a)∣∣Zθ(⋅∣s,a))]J_{\mathcal{Z}}(\theta) = E[D_{KL}(T^{\pi_\phi }\mathcal{Z}_{\tilde{\theta}}(\cdot|s,a)||\mathcal{Z}_\theta(\cdot|s,a))]JZ(θ)=E[DKL(TπϕZθ~(⋅∣s,a)∣∣Zθ(⋅∣s,a))]
- Zθ(⋅∣s,a)\mathcal{Z}_\theta(\cdot|s,a)Zθ(⋅∣s,a)是当前Critic网络拟合的值分布;
- TπϕZθ~(⋅∣s,a)T^{\pi_\phi }\mathcal{Z}_{\tilde{\theta}}(\cdot|s,a)TπϕZθ~(⋅∣s,a)是目标分布(通过目标网络和策略网络计算得到)
- (s,a)(s,a)(s,a)是经验回放中的样本分布。
该目标函数梯度计算:
∇θJZ(θ)=ωE[−(yqmin−Qθ(s,a))σθ(s,a)2∇θQθ(s,a)−(C(yzmin;b)−Qθ(s,a))2−σθ(s,a)2σθ(s,a)3∇θσθ(s,a)]\nabla_\theta J_\mathcal{Z}(\theta) = \omega E[-\dfrac{(y^{min}_q-Q_\theta(s,a))}{\sigma_\theta(s,a)^2}\nabla_\theta Q_\theta(s,a)-\dfrac{(C(y^{min}_z;b)-Q_\theta(s,a))^2-\sigma_\theta(s,a)^2}{\sigma_\theta(s,a)^3}\nabla_\theta \sigma_\theta(s,a)]∇θJZ(θ)=ωE[−σθ(s,a)2(yqmin−Qθ(s,a))∇θQθ(s,a)−σθ(s,a)3(C(yzmin;b)−Qθ(s,a))2−σθ(s,a)2∇θσθ(s,a)]
- 第一项是均值相关梯度:
- yqmin=r+γ(Qθiˉ(s′,a′)−αlogπϕˉ(a′∣s′))y^{min}_q = r + \gamma (Q_{\bar{\theta_i}}(s',a')-\alpha \log\pi_{\bar{\phi}}(a'|s'))yqmin=r+γ(Qθiˉ(s′,a′)−αlogπϕˉ(a′∣s′))——TD目标均值
- yqmin−Qθ(s,a)y^{min}_q-Q_\theta(s,a)yqmin−Qθ(s,a)——目标CriticCriticCritic均值−-−当前CriticCriticCritic均值,即传统意义上的TD误差。
- yqminy^{min}_qyqmin中的Qθiˉ(s′,a′)Q_{\bar{\theta_i}}(s',a')Qθiˉ(s′,a′)是下一状态动作的价值,使用当前Critic1Critic1Critic1和Critic2Critic2Critic2输出较小的均值,即Qθiˉ(s′,a′)=min(Qθ1,μ(s′,a′),Qθ2,μ(s′,a′))Q_{\bar{\theta_i}}(s',a')=\min(Q_{\theta_1,\mu}(s',a'),Q_{\theta_2,\mu}(s',a'))Qθiˉ(s′,a′)=min(Qθ1,μ(s′,a′),Qθ2,μ(s′,a′))
- 对于Critic1Critic1Critic1和Critic2Critic2Critic2都有各自的LossLossLoss,即梯度中的∇θQθ(s,a)\nabla_\theta Q_\theta(s,a)∇θQθ(s,a)分别是∇θ1Qθ1,μ(s,a)\nabla_{\theta_1} Q_{\theta_1,\mu}(s,a)∇θ1Qθ1,μ(s,a)和∇θ2Qθ2,μ(s,a)\nabla_{\theta_2} Q_{\theta_2,\mu}(s,a)∇θ2Qθ2,μ(s,a),也都是对均值求梯度。
- 第二项是方差相关梯度:
- yzmin=r+γ(Z(s′,a′)−αlogπϕˉ(a′∣s′))y^{min}_z=r+\gamma(Z(s',a')-\alpha\log\pi_{\bar{\phi}}(a'|s'))yzmin=r+γ(Z(s′,a′)−αlogπϕˉ(a′∣s′))——TD目标采样,得到的N(Qθ,μ,Qθ,σ)\mathcal{N}(Q_{\theta,\mu},Q_{\theta,\sigma})N(Qθ,μ,Qθ,σ),通过值分布得到的均值和方差进行采样,yzi=Qθi,μ+N(0,I)∗Qθi,σy_{z_i}=Q_{\theta_i,\mu} + \mathcal{N}(0,I)*Q_{\theta_i,\sigma}yzi=Qθi,μ+N(0,I)∗Qθi,σ,即μi+normal(0,1)∗σi\mu_i + normal(0,1) * \sigma_iμi+normal(0,1)∗σi,这样能够进行方向传播计算梯度。
- yzmin=min(yz1,yz2)y^{min}_z=\min(y_{z_1},y_{z_2})yzmin=min(yz1,yz2)——取两个CriticCriticCritic网络采样后,较小的采样值。
- 为了防止(yzimin−Qθi(s,a),μ)2=δ2(y^{min}_{z_i} - Q_{\theta_i(s,a),\mu})^2=\delta^2(yzimin−Qθi(s,a),μ)2=δ2时,导致梯度爆炸,因此对yziminy^{min}_{z_i}yzimin进行裁剪C(yzimin;b)=clip(yzi,Qθi(s,a),μ(s,a)−b,Qθi(s,a),μ+b)C(y^{min}_{z_i};b)=clip(y_{z_i},Q_{\theta_i(s,a),\mu}(s,a)-b,Q_{\theta_i(s,a),\mu}+b)C(yzimin;b)=clip(yzi,Qθi(s,a),μ(s,a)−b,Qθi(s,a),μ+b)。其中Qθi(s,a),μ(s,a)Q_{\theta_i(s,a),\mu}(s,a)Qθi(s,a),μ(s,a)为CriticiCritic_iCritici的均值。
- 为了防止学习时对奖励的尺度过于敏感,因为更新大小由方差调节,即分母中的方差。因此,为了解决该奖励敏感问题,引入梯度缩放权重ω\omegaω
- ω\omegaω是使用两个CriticCriticCritic网络输出的分布标准差计算得到,并引入了标准差的长期滑动平均值,作为稳定跟踪整体不确定性水平。
- ωi=clip(σmean2σθi2+ϵ,0.1,10.0)\omega_i = clip(\dfrac{\sigma_{mean}^2}{\sigma_{\theta_i}^2+\epsilon},0.1,10.0)ωi=clip(σθi2+ϵσmean2,0.1,10.0),其中ϵ\epsilonϵ是小正常数,用于防止分母过小引起的梯度爆炸,通过裁剪,控制梯度调整的幅度大小。
- σmean=(1−τ)σold,mean+τσnew,meanσnew,mean=mean(Qθi,std)\sigma_{mean} = (1 - \tau)\sigma_{old,mean} + \tau \sigma_{new,mean}\qquad \sigma_{new,mean} = mean(Q_{\theta_i,std})σmean=(1−τ)σold,mean+τσnew,meanσnew,mean=mean(Qθi,std),τ\tauτ为更新常数,一般取0.010.010.01。
- 不同的CriticLossCriticLossCriticLoss有不同的ω\omegaω参数。
Critic结构
由于从点估计改进为分布估计,所以需要对CriticCriticCritic结构进行修改:
class Critic(nn.Module):def __init__(self, state_dim, action_dim, hidden_dim=256):super().__init__()self.state_dim = state_dimself.action_dim = action_dimself.net = nn.Sequential(nn.Linear(state_dim+action_dim, hidden_dim),nn.GELU(),nn.Linear(hidden_dim, hidden_dim),nn.GELU(),)self.mu = nn.Linear(hidden_dim, 1)self.std = nn.Linear(hidden_dim, 1)def forward(self, s, a):x = torch.cat([s, a], dim=-1)mu = self.mu(self.net(x)) std = F.softplus(self.std(self.net(x))) # 确保标准差大于0normal = Normal(torch.zeros_like(mu), torch.ones_like(std))z = normal.sample()z = torch.clamp(z, -3.0, 3.0) # 对单位高斯分布采样值进行截断,使用3σ范围q_value = mu + torch.mul(z, std) # 动作状态价值采样值return mu.squeeze(-1), std.squeeze(-1), q_value.squeeze(-1)
Critic更新流程
- 通过两个CriticCriticCritic网络计算当前动作状态的均值和标准差;
- 更新标准差的长期滑动平均值σmean\sigma_{mean}σmean;
- 通过两个CriticCriticCritic网络计算下一动作状态的均值和采样值,用于计算TD目标。选择均值较小的均值和采样值。
- 使用均值较小的均值和采样值,计算得到截断TD目标动作状态价值,截断边界选择3σ。
- 计算梯度缩放权重ω\omegaω,得到两个CriticCriticCritic网络的损失,并反向传播更新权重。
def update(self, state, action, reward, next_state, done):state = torch.tensor(state, dtype=torch.float32).to(self.device)action = torch.tensor(action, dtype=torch.float32).to(self.device)reward = torch.tensor(reward, dtype=torch.float32).to(self.device)next_state = torch.tensor(next_state, dtype=torch.float32).to(self.device)done = torch.tensor(done, dtype=torch.int64).to(self.device)# 计算 CriticLoss1 和 CriticLoss2,更新 Critic1 和 Critic2next_action, log_next_action_prob = self.actor(next_state)q1_mu, q1_std, _ = self.critic1(state, action)q2_mu, q2_std, _ = self.critic2(state, action)# 用于计算后续裁剪TD_Error的边界,使用3σ范围进行裁剪,因此需要先更新长期滑动标准差的平均值,从而达到动态裁剪TD误差的作用# 初始值设置为-1.0,表示未开始更新if self.mean_std1 == -1.0: self.mean_std1 = torch.mean(q1_std.detach())else:self.mean_std1 = (1-self.tau_b) * self.mean_std1 + \self.tau_b * torch.mean(q1_std.detach())if self.mean_std2 == -1.0:self.mean_std2 = torch.mean(q2_std.detach())else:self.mean_std2 = (1-self.tau_b) * self.mean_std2 + \self.tau_b * torch.mean(q2_std.detach())next_q1_mu, _, next_q1_sample = self.critic1(next_state, next_action)next_q2_mu, _, next_q2_sample = self.critic2(next_state, next_action)# 取均值较小的价值采样值,作为下一个状态动作的价值next_q_sample = torch.where(next_q1_mu < next_q2_mu, next_q1_sample, next_q2_sample)next_q_mu = torch.min(next_q1_mu, next_q2_mu)# critic1_loss 和 crtic2_loss 分别使用各自的 q_mu 来计算TD_errortarget_q1_mu = reward + (1 - done) * self.gamma * \(next_q_mu - self.alpha * log_next_action_prob)target_q1_sample = reward + \(1 - done) * self.gamma * \(next_q_sample - self.alpha * log_next_action_prob)target_q1_bound = 3 * self.mean_std1TD1_Error = torch.clamp(target_q1_sample - q1_mu, -target_q1_bound, target_q1_bound)clamp_TD1_target = TD1_Error + q1_mutarget_q2_mu = reward + (1 - done) * self.gamma * \(next_q_mu - self.alpha * log_next_action_prob)target_q2_sample = reward + \(1 - done) * self.gamma * \(next_q_sample - self.alpha * log_next_action_prob)target_q2_bound = 3 * self.mean_std2TD2_Error = torch.clamp(target_q2_sample - q2_mu, -target_q2_bound, target_q2_bound)clamp_TD2_target = TD2_Error + q2_mu# eps小常数,防止分母为0# 计算梯度缩放权重# 虽然文献中的梯度存在方差分母缩放项,但可以视为整合进学习率中,故可以省略σ^2。eps = 0.1ratio1 = (torch.pow(self.mean_std1, 2) /(torch.pow(q1_std.detach(), 2)+eps)).clamp(min=0.1, max=10)ratio2 = (torch.pow(self.mean_std2, 2) /(torch.pow(q2_std.detach(), 2)+eps)).clamp(min=0.1, max=10)critic_loss1 = torch.mean(ratio1 * (F.huber_loss(q1_mu, target_q1_mu.detach(), delta=50, reduction='none')+ q1_std * (torch.pow(q1_std.detach(), 2) - F.huber_loss(q1_mu.detach(), clamp_TD1_target.detach(), delta=50, reduction='none'))/(q1_std.detach()+eps)))critic_loss2 = torch.mean(ratio2 * (F.huber_loss(q2_mu, target_q2_mu.detach(), delta=50, reduction='none')+ q2_std * (torch.pow(q2_std.detach(), 2) - F.huber_loss(q2_mu.detach(), clamp_TD2_target.detach(), delta=50, reduction='none'))/(q2_std.detach()+eps)))self.optimizer_critic1.zero_grad()self.optimizer_critic2.zero_grad()critic_loss1.backward()critic_loss2.backward()self.optimizer_critic1.step()self.optimizer_critic2.step()
Actor更新
DSAC-T的Actor更新与SAC算法中的Actor更新相同
# 计算ActorLoss,更新Actornew_action, log_prob = self.actor(state)q1_mu, q1_std, _ = self.critic1(state, new_action)q2_mu, q2_std, _ = self.critic2(state, new_action)actor_loss = - \torch.mean(torch.min(q1_mu, q2_mu) -self.alpha.detach() * log_prob)self.optimizer_actor.zero_grad()actor_loss.backward()self.optimizer_actor.step()
温度系数α更新
α更新与SAC算法中相同
# 更新alphaalpha_loss = torch.mean(self.alpha * (- log_prob - self.target_entropy).detach())self.optimizer_alpha.zero_grad()alpha_loss.backward()self.optimizer_alpha.step()
对目标网络软更新
def soft_update(self, net: nn.Module, target_net: nn.Module):for param_target, param in zip(target_net.parameters(), net.parameters()):param_target.data.copy_(param.data * self.tau + param_target.data * (1.0 - self.tau))self.soft_update(self.critic1, self.target_critic1)self.soft_update(self.critic2, self.target_critic2)
经验回放
class ReplayBuffer:"""经验回放"""def __init__(self, batch_size=64, max_size=10000):self.data = []self.batch_size = batch_sizeself.max_size = max_sizedef add_data(self, state, action, reward, next_state, done):if self.length() >= self.max_size:tmp = self.data[1:]self.data = tmp.copy()self.data.append((state, action, reward, next_state, done))def sample(self):sample_data = random.sample(self.data, self.batch_size)state, action, reward, next_state, done = zip(*sample_data)return np.array(state), np.array(action), np.array(reward), np.array(next_state), np.array(done)def length(self):return len(self.data)
DSAC-T Agent
class DSAC:def __init__(self, state_dim, action_dim, action_bound, gamma, device, target_entropy, tau, lr):self.actor = Actor(state_dim, action_dim, action_bound).to(device)self.critic1 = Critic(state_dim, action_dim).to(device)self.critic2 = Critic(state_dim, action_dim).to(device)self.target_critic1 = Critic(state_dim, action_dim).to(device)self.target_critic2 = Critic(state_dim, action_dim).to(device)self.target_critic1.load_state_dict(self.critic1.state_dict())self.target_critic2.load_state_dict(self.critic2.state_dict())self.optimizer_actor = torch.optim.AdamW(self.actor.parameters(), lr=lr)self.optimizer_critic1 = torch.optim.AdamW(self.critic1.parameters(), lr=lr)self.optimizer_critic2 = torch.optim.AdamW(self.critic2.parameters(), lr=lr)self.alpha = torch.tensor(3, dtype=torch.float32, requires_grad=True)self.optimizer_alpha = torch.optim.AdamW([self.alpha])self.target_entropy = target_entropyself.device = deviceself.gamma = gammaself.tau = tauself.initialize()self.mean_std1 = -1.0self.mean_std2 = -1.0self.tau_b = 0.01def initialize(self):def init_weights(m):if isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight)nn.init.zeros_(m.bias)self.actor.apply(init_weights)self.critic1.apply(init_weights)self.critic2.apply(init_weights)def soft_update(self, net: nn.Module, target_net: nn.Module):for param_target, param in zip(target_net.parameters(), net.parameters()):param_target.data.copy_(param.data * self.tau + param_target.data * (1.0 - self.tau))def take_action(self, state):state = torch.tensor(state, dtype=torch.float32).to(self.device)action = self.actor(state)[0]return [action.item()] # env.step(action) 中的action需为数组,不能只是一个数def update(self, state, action, reward, next_state, done):state = torch.tensor(state, dtype=torch.float32).to(self.device)action = torch.tensor(action, dtype=torch.float32).to(self.device)reward = torch.tensor(reward, dtype=torch.float32).to(self.device)next_state = torch.tensor(next_state, dtype=torch.float32).to(self.device)done = torch.tensor(done, dtype=torch.int64).to(self.device)# 计算 CriticLoss1 和 CriticLoss2,更新 Critic1 和 Critic2next_action, log_next_action_prob = self.actor(next_state)q1_mu, q1_std, _ = self.critic1(state, action)q2_mu, q2_std, _ = self.critic2(state, action)# 用于计算后续裁剪TD_Error的边界,使用3σ范围进行裁剪,因此需要先更新标准差,从而达到动态裁剪TD误差的作用if self.mean_std1 == -1.0:self.mean_std1 = torch.mean(q1_std.detach())else:self.mean_std1 = (1-self.tau_b) * self.mean_std1 + \self.tau_b * torch.mean(q1_std.detach())if self.mean_std2 == -1.0:self.mean_std2 = torch.mean(q2_std.detach())else:self.mean_std2 = (1-self.tau_b) * self.mean_std2 + \self.tau_b * torch.mean(q2_std.detach())next_q1_mu, _, next_q1_sample = self.critic1(next_state, next_action)next_q2_mu, _, next_q2_sample = self.critic2(next_state, next_action)# 取均值较小的价值采样值,作为下一个状态动作的价值next_q_sample = torch.where(next_q1_mu < next_q2_mu, next_q1_sample, next_q2_sample)next_q_mu = torch.min(next_q1_mu, next_q2_mu)# critic1_loss 和 crtic2_loss 分别使用各自的 q_mu 来计算TD_errortarget_q1_mu = reward + (1 - done) * self.gamma * \(next_q_mu - self.alpha * log_next_action_prob)target_q1_sample = reward + \(1 - done) * self.gamma * \(next_q_sample - self.alpha * log_next_action_prob)target_q1_bound = 3 * self.mean_std1TD1_Error = torch.clamp(target_q1_sample - q1_mu, -target_q1_bound, target_q1_bound)clamp_TD1_target = TD1_Error + q1_mutarget_q2_mu = reward + (1 - done) * self.gamma * \(next_q_mu - self.alpha * log_next_action_prob)target_q2_sample = reward + \(1 - done) * self.gamma * \(next_q_sample - self.alpha * log_next_action_prob)target_q2_bound = 3 * self.mean_std2TD2_Error = torch.clamp(target_q2_sample - q2_mu, -target_q2_bound, target_q2_bound)clamp_TD2_target = TD2_Error + q2_mu# eps小常数,防止分母为0eps = 0.1ratio1 = (torch.pow(self.mean_std1, 2) /(torch.pow(q1_std.detach(), 2)+eps)).clamp(min=0.1, max=10)ratio2 = (torch.pow(self.mean_std2, 2) /(torch.pow(q2_std.detach(), 2)+eps)).clamp(min=0.1, max=10)critic_loss1 = torch.mean(ratio1 * (F.huber_loss(q1_mu, target_q1_mu.detach(), delta=50, reduction='none')+ q1_std * (torch.pow(q1_std.detach(), 2) - F.huber_loss(q1_mu.detach(), clamp_TD1_target.detach(), delta=50, reduction='none'))/(q1_std.detach()+eps)))critic_loss2 = torch.mean(ratio2 * (F.huber_loss(q2_mu, target_q2_mu.detach(), delta=50, reduction='none')+ q2_std * (torch.pow(q2_std.detach(), 2) - F.huber_loss(q2_mu.detach(), clamp_TD2_target.detach(), delta=50, reduction='none'))/(q2_std.detach()+eps)))self.optimizer_critic1.zero_grad()self.optimizer_critic2.zero_grad()critic_loss1.backward()critic_loss2.backward()self.optimizer_critic1.step()self.optimizer_critic2.step()# 计算ActorLoss,更新Actornew_action, log_prob = self.actor(state)q1_mu, q1_std, _ = self.critic1(state, new_action)q2_mu, q2_std, _ = self.critic2(state, new_action)actor_loss = - \torch.mean(torch.min(q1_mu, q2_mu) -self.alpha.detach() * log_prob)self.optimizer_actor.zero_grad()actor_loss.backward()self.optimizer_actor.step()# 更新alphaalpha_loss = torch.mean(self.alpha * (- log_prob - self.target_entropy).detach())self.optimizer_alpha.zero_grad()alpha_loss.backward()self.optimizer_alpha.step()self.soft_update(self.critic1, self.target_critic1)self.soft_update(self.critic2, self.target_critic2)
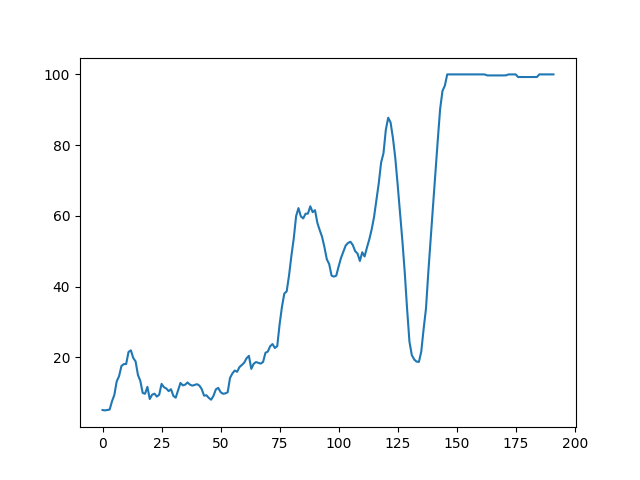
控制倒立摆完整代码
import os
import torch
import torch.nn as nn
import torch.nn.functional as F
import numpy as np
import gymnasium as gym
import random
from torch.distributions import Normal
import matplotlib.pyplot as pltclass Actor(nn.Module):def __init__(self, state_dim, action_dim, action_bound, hidden_dim=256):super().__init__()self.net = nn.Sequential(nn.Linear(state_dim, hidden_dim), nn.GELU(),nn.Linear(hidden_dim, hidden_dim), nn.GELU(),)self.mu = nn.Linear(hidden_dim, action_dim)self.std = nn.Linear(hidden_dim, action_dim)self.action_bound = action_bounddef forward(self, x):mu = self.mu(self.net(x))std = F.softplus(self.std(self.net(x))) # 确保标准差 > 0normal = torch.distributions.Normal(mu, std)normal_sample = normal.rsample() # 重参数化采样action = torch.tanh(normal_sample) # 计算得到动作,范围在[-1,1]# 重参数化采样得到的动作对应的对数概率,ln(p(a_{raw}|s))log_sample_prob = normal.log_prob(normal_sample)log_tanh_prob = log_sample_prob - \torch.log(1 - action.pow(2) + 1e-6) # 得到tanh缩放后的动作的对数概率,ln(π(a|s))action = action * self.action_boundreturn action, log_tanh_prob.squeeze(-1)class Critic(nn.Module):def __init__(self, state_dim, action_dim, hidden_dim=256):super().__init__()self.state_dim = state_dimself.action_dim = action_dimself.net = nn.Sequential(nn.Linear(state_dim+action_dim, hidden_dim),nn.GELU(),nn.Linear(hidden_dim, hidden_dim),nn.GELU(),)self.mu = nn.Linear(hidden_dim, 1)self.std = nn.Linear(hidden_dim, 1)def forward(self, s, a):x = torch.cat([s, a], dim=-1)mu = self.mu(self.net(x))std = F.softplus(self.std(self.net(x)))normal = Normal(torch.zeros_like(mu), torch.ones_like(std))z = normal.sample()z = torch.clamp(z, -3.0, 3.0)q_value = mu + torch.mul(z, std)return mu.squeeze(-1), std.squeeze(-1), q_value.squeeze(-1)class ReplayBuffer:"""经验回放"""def __init__(self, batch_size=64, max_size=10000):self.data = []self.batch_size = batch_sizeself.max_size = max_sizedef add_data(self, state, action, reward, next_state, done):if self.length() >= self.max_size:tmp = self.data[1:]self.data = tmp.copy()self.data.append((state, action, reward, next_state, done))def sample(self):sample_data = random.sample(self.data, self.batch_size)state, action, reward, next_state, done = zip(*sample_data)return np.array(state), np.array(action), np.array(reward), np.array(next_state), np.array(done)def length(self):return len(self.data)class DSAC:def __init__(self, state_dim, action_dim, action_bound, gamma, device, target_entropy, tau, lr):self.actor = Actor(state_dim, action_dim, action_bound).to(device)self.critic1 = Critic(state_dim, action_dim).to(device)self.critic2 = Critic(state_dim, action_dim).to(device)self.target_critic1 = Critic(state_dim, action_dim).to(device)self.target_critic2 = Critic(state_dim, action_dim).to(device)self.target_critic1.load_state_dict(self.critic1.state_dict())self.target_critic2.load_state_dict(self.critic2.state_dict())self.optimizer_actor = torch.optim.AdamW(self.actor.parameters(), lr=lr)self.optimizer_critic1 = torch.optim.AdamW(self.critic1.parameters(), lr=lr)self.optimizer_critic2 = torch.optim.AdamW(self.critic2.parameters(), lr=lr)self.alpha = torch.tensor(3, dtype=torch.float32, requires_grad=True)self.optimizer_alpha = torch.optim.AdamW([self.alpha])self.target_entropy = target_entropyself.device = deviceself.gamma = gammaself.tau = tauself.initialize()self.mean_std1 = -1.0self.mean_std2 = -1.0self.tau_b = 0.01def initialize(self):def init_weights(m):if isinstance(m, nn.Linear):nn.init.xavier_uniform_(m.weight)nn.init.zeros_(m.bias)self.actor.apply(init_weights)self.critic1.apply(init_weights)self.critic2.apply(init_weights)def soft_update(self, net: nn.Module, target_net: nn.Module):for param_target, param in zip(target_net.parameters(), net.parameters()):param_target.data.copy_(param.data * self.tau + param_target.data * (1.0 - self.tau))def take_action(self, state):state = torch.tensor(state, dtype=torch.float32).to(self.device)action = self.actor(state)[0]return [action.item()] # env.step(action) 中的action需为数组,不能只是一个数def update(self, state, action, reward, next_state, done):state = torch.tensor(state, dtype=torch.float32).to(self.device)action = torch.tensor(action, dtype=torch.float32).to(self.device)reward = torch.tensor(reward, dtype=torch.float32).to(self.device)next_state = torch.tensor(next_state, dtype=torch.float32).to(self.device)done = torch.tensor(done, dtype=torch.int64).to(self.device)# 计算 CriticLoss1 和 CriticLoss2,更新 Critic1 和 Critic2next_action, log_next_action_prob = self.actor(next_state)q1_mu, q1_std, _ = self.critic1(state, action)q2_mu, q2_std, _ = self.critic2(state, action)# 用于计算后续裁剪TD_Error的边界,使用3σ范围进行裁剪,因此需要先更新标准差,从而达到动态裁剪TD误差的作用if self.mean_std1 == -1.0:self.mean_std1 = torch.mean(q1_std.detach())else:self.mean_std1 = (1-self.tau_b) * self.mean_std1 + \self.tau_b * torch.mean(q1_std.detach())if self.mean_std2 == -1.0:self.mean_std2 = torch.mean(q2_std.detach())else:self.mean_std2 = (1-self.tau_b) * self.mean_std2 + \self.tau_b * torch.mean(q2_std.detach())next_q1_mu, _, next_q1_sample = self.critic1(next_state, next_action)next_q2_mu, _, next_q2_sample = self.critic2(next_state, next_action)# 取均值较小的价值采样值,作为下一个状态动作的价值next_q_sample = torch.where(next_q1_mu < next_q2_mu, next_q1_sample, next_q2_sample)next_q_mu = torch.min(next_q1_mu, next_q2_mu)# critic1_loss 和 crtic2_loss 分别使用各自的 q_mu 来计算TD_errortarget_q1_mu = reward + (1 - done) * self.gamma * \(next_q_mu - self.alpha * log_next_action_prob)target_q1_sample = reward + \(1 - done) * self.gamma * \(next_q_sample - self.alpha * log_next_action_prob)target_q1_bound = 3 * self.mean_std1TD1_Error = torch.clamp(target_q1_sample - q1_mu, -target_q1_bound, target_q1_bound)clamp_TD1_target = TD1_Error + q1_mutarget_q2_mu = reward + (1 - done) * self.gamma * \(next_q_mu - self.alpha * log_next_action_prob)target_q2_sample = reward + \(1 - done) * self.gamma * \(next_q_sample - self.alpha * log_next_action_prob)target_q2_bound = 3 * self.mean_std2TD2_Error = torch.clamp(target_q2_sample - q2_mu, -target_q2_bound, target_q2_bound)clamp_TD2_target = TD2_Error + q2_mu# eps小常数,防止分母为0eps = 0.1ratio1 = (torch.pow(self.mean_std1, 2) /(torch.pow(q1_std.detach(), 2)+eps)).clamp(min=0.1, max=10)ratio2 = (torch.pow(self.mean_std2, 2) /(torch.pow(q2_std.detach(), 2)+eps)).clamp(min=0.1, max=10)critic_loss1 = torch.mean(ratio1 * (F.huber_loss(q1_mu, target_q1_mu.detach(), delta=50, reduction='none')+ q1_std * (torch.pow(q1_std.detach(), 2) - F.huber_loss(q1_mu.detach(), clamp_TD1_target.detach(), delta=50, reduction='none'))/(q1_std.detach()+eps)))critic_loss2 = torch.mean(ratio2 * (F.huber_loss(q2_mu, target_q2_mu.detach(), delta=50, reduction='none')+ q2_std * (torch.pow(q2_std.detach(), 2) - F.huber_loss(q2_mu.detach(), clamp_TD2_target.detach(), delta=50, reduction='none'))/(q2_std.detach()+eps)))self.optimizer_critic1.zero_grad()self.optimizer_critic2.zero_grad()critic_loss1.backward()critic_loss2.backward()self.optimizer_critic1.step()self.optimizer_critic2.step()# 计算ActorLoss,更新Actornew_action, log_prob = self.actor(state)q1_mu, q1_std, _ = self.critic1(state, new_action)q2_mu, q2_std, _ = self.critic2(state, new_action)actor_loss = - \torch.mean(torch.min(q1_mu, q2_mu) -self.alpha.detach() * log_prob)self.optimizer_actor.zero_grad()actor_loss.backward()self.optimizer_actor.step()# 更新alphaalpha_loss = torch.mean(self.alpha * (- log_prob - self.target_entropy).detach())self.optimizer_alpha.zero_grad()alpha_loss.backward()self.optimizer_alpha.step()self.soft_update(self.critic1, self.target_critic1)self.soft_update(self.critic2, self.target_critic2)if __name__ == "__main__":os.system('cls')env = gym.make('InvertedPendulum-v5', render_mode='human')# env = gym.make('InvertedPendulum-v5')buffersize = 10000minimal_size = 1024batch_size = 256# 智能体参数gamma = 0.99device = torch.device('cuda') if torch.cuda.is_available() else torch.device('cpu')episode = 300target_entropy = - env.action_space.shape[0] # 设置为负动作维度tau = 0.005lr = 3e-5# print(gym.envs.registry.keys())state_dim = env.observation_space.shape[0]action_dim = env.action_space.shape[0]action_bound = env.action_space.high[0]agent = DSAC(state_dim, action_dim, action_bound,gamma, device, target_entropy, tau, lr)replay_buffer = ReplayBuffer(batch_size, buffersize)episode_return_list = []for num in range(episode):episode_reward = []state, info = env.reset()done = Falsemax_iteration = 1024i = 0while i < max_iteration:action = agent.take_action(state)next_state, reward, done, _, __ = env.step(action)replay_buffer.add_data(state, action, reward, next_state, done)episode_reward.append(reward)state = next_statei += 1if replay_buffer.length() > minimal_size:b_s, b_a, b_r, b_ns, b_d = replay_buffer.sample()agent.update(b_s, b_a, b_r, b_ns, b_d)res = 0for i in range(len(episode_reward)-1, -1, -1):res = gamma * res + episode_reward[i]print(f'{num}轮回报:{res}')episode_return_list.append(res)average = [np.mean(episode_return_list[i:i+9])for i in range(0, len(episode_return_list)-8)]epi = [x for x in range(len(average))]plt.plot(epi, average)plt.show()env.close()运行episode=200和300的回报结果图