SemanticVLA:面向高效机器人操作的语义对齐剪枝与增强方法
一、研究背景视觉-语言-动作模型在机器人操作领域取得显著进展,通过预训练视觉语言模型实现从语言到动作的端到端映射,推动智能机器人的实际应用。但现有模型在动态、杂乱环境中部署时仍受两大瓶颈制约:视觉感知冗余:通用视觉编码器对所有像素均匀处理,不分任务相关性,导致背景干扰、环境噪声被无差别编码,既增加计算成本,又稀释对任务关键线索的注意力。指令-视觉语义对齐表层化:依赖通用跨模态对齐机制,难以捕捉机器人操作中复杂的语义关系和细粒度视觉组合性,无法有效识别全局动作线索、局部语义锚点及结构化的指令-空间依赖。这些问题导致模型计算效率低下、任务接地能力弱,限制了在实际机器人操作场景中的落地。二、核心创新点提出语义引导双视觉剪枝器,通过指令感知的token过滤和几何感知的聚合,针对性解决视觉冗余问题,同时保留语义对齐。设计语义互补分层融合器,跨编码器整合密集补丁特征与稀疏语义token,强化指令语义与空间结构的对齐。构建语义条件动作耦合器,重构视觉到动作的映射路径,将7自由度动作重构为语义连贯的动作类型表示,提升动作解码的效率与可解释性。实现性能与效率的帕累托最优,在降低训练成本和推理延迟的同时,显著提升任务成功率,突破现有模型的权衡困境。三、主要工作3.1 整体框架设计输入包含实时视觉观测、机器人本体感受状态(如关节角度、末端执行器姿态)和自然语言指令,目标是预测未来K个动作序列。框架通过两条并行路径处理视觉输入:SigLIP基视觉编码器:经指令驱动剪枝器进行语义稀疏化DINOv2基空间编码器:经空间聚合剪枝器提取密集几何特征两条路径的输出通过语义互补分层融合器生成任务相关表示,与指令、本体感受状态及可学习的动作占位符拼接后,输入双向解码器并行生成所有动作,形成“稀疏化-融合-动作映射”的端到端 pipeline(figure2)。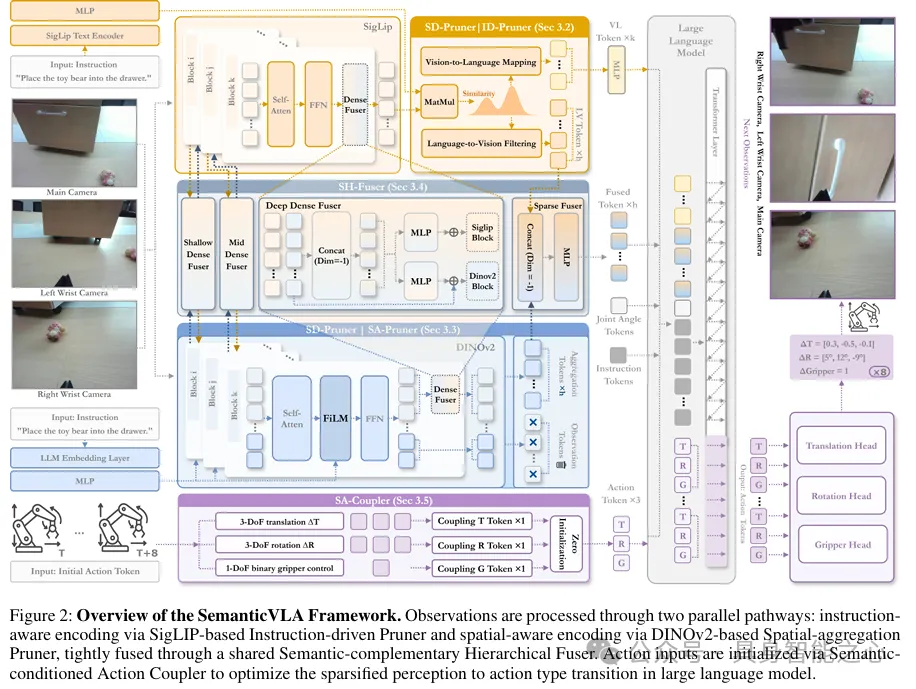
3.2 语义引导双视觉剪枝器(SD-Pruner)针对SigLIP和DINOv2的编码器特性,设计两个专项剪枝模块,实现语义对齐的视觉稀疏化:指令驱动剪枝器(ID-Pruner)—— 面向SigLIP基于指令与视觉token的跨模态相似度,通过双路径实现稀疏化:构建余弦相似度矩阵:将指令token投影到视觉空间,计算与每个视觉token的余弦相似度视觉到语言映射:聚合视觉token相似度得分,筛选Top-k关键指令token,形成全局动作线索特征,解决“知目标而不知步骤”问题语言到视觉过滤:聚合指令token相似度得分,筛选Top-h关键视觉token,保留局部语义锚点,缓解“看不见则做不到”问题输出为两类token的并集,在压缩视觉输入的同时保留核心语义-视觉对齐信息(figure3左)空间聚合剪枝器(SA-Pruner)—— 面向DINOv2引入零初始化聚合token,将DINOv2的密集特征聚合为紧凑的几何token通过FiLM层注入指令语义,生成尺度和偏移参数,动态调整空间特征以匹配任务上下文输出与ID-Pruner结构对齐,为跨模态融合奠定基础3.3 语义互补分层融合器(SH-Fuser)通过双层融合机制整合两条视觉路径的互补特征,避免简单后期拼接:密集融合器:在SigLIP和DINOv2的浅层、中层、深层Transformer块间插入,交换补丁级信息,使语义线索与空间几何先验在各阶段协同增强稀疏融合器:在最终阶段合并ID-Pruner的局部语义token与SA-Pruner的聚合token,形成紧凑统一的表示该设计将视觉token压缩8-16倍,同时兼顾语义接地性和几何准确性(figure2)。3.4 语义条件动作耦合器(SA-Coupler)重构传统7自由度动作的表示与解码方式:token级语义对齐:将平移、旋转、夹持器控制三个运动原语各表示为单个token,实现动作类型的语义连贯建模头级模块化预测:设计三个专用预测头,分别回归平移、旋转、夹持器控制的连续运动参数结合并行解码,将动作token数量从350减少至150,大幅降低推理开销(figure3右)四、相关工作4.1 轻量模型驱动的机器人操作这类模型擅长确定性实时控制,但过度依赖预定义对象和环境,缺乏开放世界所需的语义泛化能力。4.2 基于VLM的VLA模型两大分支单体架构:保持因果性和语义一致的多步推理,适用于开放式环境,但自回归动作解码导致效率瓶颈分层专家模型:利用扩散或流匹配机制进行高频动作预测,但VLM与动作专家间存在脱节,未充分发挥VLM的推理能力4.3 高效VLA建模方法算法策略:通过离散余弦变换合并动作箱、并行解码等方式加速推理架构创新:采用Mamba backbone、多出口设计、动态层跳过机制减少冗余计算压缩方法:聚焦模型缩小以保留任务性能,但普遍忽视视觉输入与指令语义的对齐五、实验结果5.1 实验设置硬件:8×A800 GPU仿真基准:LIBERO数据集,包含空间推理、对象泛化、目标理解、长视距任务四大套件真实场景:AgileX Cobot Magic平台,涵盖对象放置、抽屉操作、T恤折叠等多类任务基线模型:OpenVLA、Octo、PD-VLA等主流高效VLA模型5.2 核心性能表现仿真性能:在LIBERO基准上达到97.7%的整体成功率,超越OpenVLA 21.1%,位列第一;轻量版本仍保持95.8%的高成功率(table1)效率优势:训练成本降低3.0倍,推理延迟降低2.7倍,视觉token压缩8-16倍,动作token压缩至原来的3/7,吞吐量显著提升(table2)真实场景表现:在长视距任务中成功率达77.8%,超越OpenVLA-OFT 22.2%,展现出强泛化能力(table3)消融实验:SD-Pruner的双剪枝组合使成功率提升2.1%-5.2%;稀疏化比率8×时实现性能与效率的最优平衡(table4、table5)5.3 定性分析通过注意力图谱可视化,ID-Pruner有效捕捉全局动作线索和局部语义锚点,SA-Pruner聚焦几何结构,两者互补增强;在真实场景中,模型能稳定完成多步骤复杂指令,展现出可靠的指令跟随能力(figure4、figure5)。
参考[1]SemanticVLA: Semantic-Aligned Sparsification and Enhancement for Efficient Robotic Manipulation