深圳微信网站制作中国高定十大品牌
我在使用selenium的find_element的方式去获取网页元素,一般通过xpath、css_selector、class_name的方式去获取元素的绝对位置。
但是有时候如果网页多了一些弹窗或者啥之类的,绝对位置会发生变化,使用xpath等方法,需要经常变动。
于是我在想,能不能让selenium也能像Beautifulsoup一样,可以根据html的结构找到需要的部分,并解析出来。
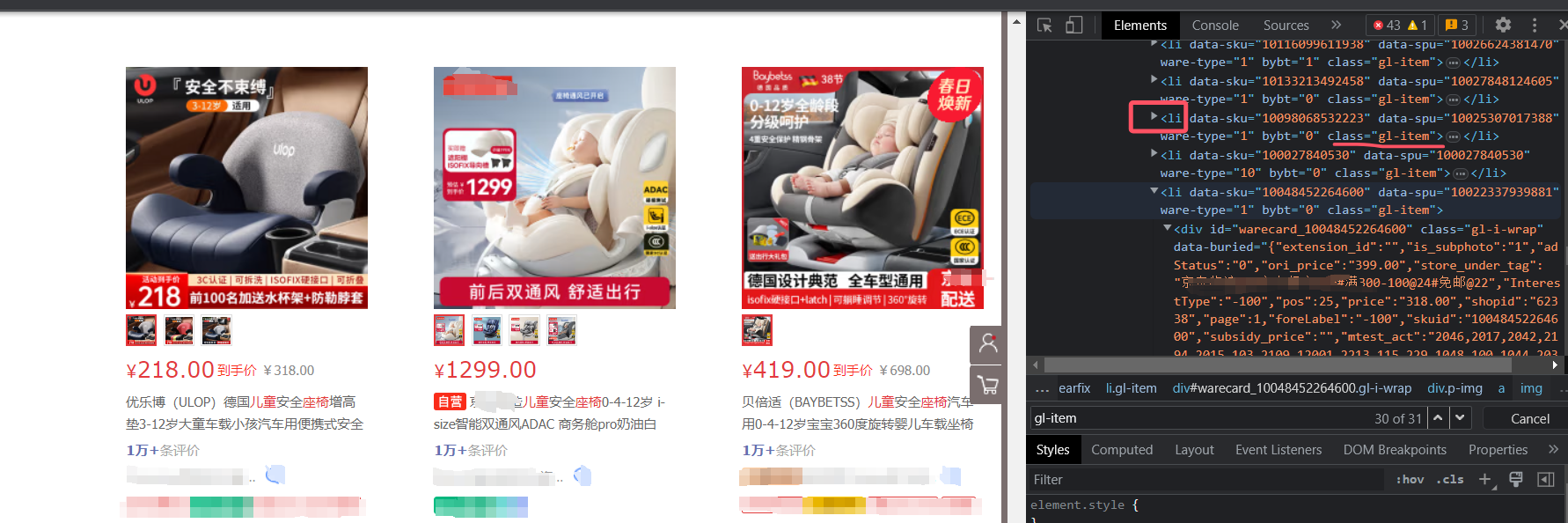
方法:
- 复制那里的css_selector
- 对比css_selector的构建和html上的元素的上下位置
products=page_soup.find('div', {'id': 'List'}).ul.findAll("li") #找到最大的那个位置
for product in products:# 提取商品链接link_element = product.find_element(By.CSS_SELECTOR, "p-name a")product_link = link_element.get_attribute("href")product_title = link_element.get_attribute("title")
写法类似beautifulsoup的写法。
- 如果想要多个条件并列,写法:
tags_elements = product.find_elements(By.CSS_SELECTOR, "div.p-icons img, div.p-icons i")
这个是想同时获得icons 下的img 和i 的节点元素的内容。
- 提取上一级或者下一级的写法:
例如:提取 div 的p-icons的,下一级元素img;
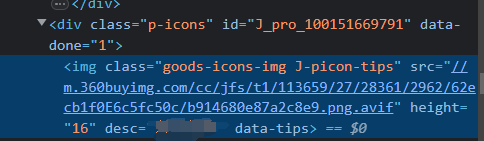
css_selector : #J_pro_100151669791 > img:nth-child(1)
在div class为“p-icons”下的
具体写法:
tags_elements = product.find_elements(By.CSS_SELECTOR, "div.p-icons img:nth-child(1)")
- 提取其中的具体标签值,例如 像上面的desc的:
for tag_element in tags_elements:tag = tag_element.get_attribute("desc") or tag_element.textif "XX超市" in tag or "五星旗舰店" in tag or "自营" in tag:tags.append(tag.strip())
可以批量判断是否为这个标签值
总的写法:
for product in products:print()# 提取商品链接 link_element = product.find_element(By.CSS_SELECTOR, "div.p-name a")#print('提取商品链接:',link_element)#产品链接 产品名称product_link = link_element.get_attribute("href") #产品链接product_title = link_element.text #产品名称print(product_title)print('提取商品链接:',product_link)#价格 product_price_element = product.find_element(By.CSS_SELECTOR, "div.p-price i")product_price = product_price_element.text if product_price_element else "无"print(product_price)#评价数 #warecard_10116099611938 > div.p-commit > strongcomment_count_element = product.find_element(By.CSS_SELECTOR, "div.p-commit a")comment_count = comment_count_element.text if comment_count_element else "无"print(comment_count)# 提取店铺名称shop_name_element = product.find_element(By.CSS_SELECTOR, "div.p-shop a, div.p-shop span") ##warecard_10129282745285 > div.p-shop > spanshop_name = shop_name_element.text if shop_name_element else "无"print(shop_name)#划线价original_price= is_exist_element(product,"div.p-price span.originalPrice")print(original_price)#自营is_self_operated = is_extact_element_element(product,"div.p-name.p-name-type-2 img","alt","自营")print(is_self_operated)#X东超市is_jd_supermarket = is_extact_element_element(product, "div.p-icons img","desc",'XX超市')print(is_jd_supermarket)#5星店铺 is_five_star = is_element(product,"div.p-shop img")print(is_five_star)