深圳营销型网站seo手机网站后台管理系统
目录
一、给出代码逻辑优化的建议
二、代码优化的例子(开发中)
1. 使用StringBuilder代替String拼接
2. 减少方法调用
3. 使用局部变量替代全局变量
4. 减少对象创建(使用对象池)
5. 选择高效数据结构和算法
6. 优化数据库访问
7. 使用Primitive类型替代Wrapper类型
8. 避免使用同步代码块(在可能的情况下)
9. 使用try-with-resources语句管理资源
10. 使用缓存机制
11. 并发编程优化
12.集合使用优化-使用ArrayList的get方法代替增强型for循环
13.并发编程优化-使用ConcurrentHashMap代替synchronized块
14. 避免在循环中重复调用list.size()
三、Java8 Lambda Stream流 etc
1、函数式接口
②、Consumer :
③、Supplier:
④、Function:
⑤、Predicate:
⑥、自定义函数式接口
2、Lambda表达式
3、方法引用
②、使用示例:
4、Option
②、创建 Optional 对象
③、Optional 常用方法及示例
1. 检查值是否存在
2. 获取值
3. 值存在时执行操作
4. 转换值(map/flatMap)
5. 过滤(filter)
④、实际应用示例
5、stream
①、Stream概述
②、Stream的创建
③、Stream的使用
3.1 遍历/匹配(foreach、find、match)
3.2 筛选(filter)
3.3 聚合(max、min、count)
3.4 映射(map、flatMap)
3.5 规约(reduce)
3.6 收集(collect)
3.6.1 归集(toList、toSet、toMap)
3.6.2 统计(count、averaging)
3.6.3 分组(partitioningBy、groupingBy)
3.6.4 接合(joining)
3.6.5 规约(reducing)
3.7 排序(sorted)
3.8 去重、合并(distinct、skip、limit)
一、给出代码逻辑优化的建议
①.消除死循环:
确保所有的循环都有明确的终止条件。
使用调试工具或日志记录来检测和定位潜在的死循环。
②.避免重复计算:
对于重复使用的计算结果,使用局部变量或类成员变量进行缓存。
在循环中避免进行不必要的重复计算。
③.优化数据结构和算法:
根据问题的具体需求选择合适的数据结构,如ArrayList、LinkedList、HashMap等。
使用高效的算法来减少时间复杂度。
④.减少不必要的对象创建和销毁:
避免在循环中创建大量临时对象,尽量在循环外部创建对象并重用。
使用对象池技术来重用已经创建过的对象。
⑤.利用并行和异步处理提高性能:
对于可以并行处理的任务,使用Java的并发包(如java.util.concurrent)中的工具类来实现多线程处理。
使用CompletableFuture等类来实现异步编程,提高程序的响应性。
⑥.避免过度使用同步机制:
在多线程编程中,尽量减少同步代码块的范围。
使用volatile、atomic变量等无锁机制来减少同步开销。
⑦.代码重构和模块化:
将重复的代码封装成方法或类,提高代码的可重用性。
将复杂的代码拆分成多个简单的模块,每个模块只负责一个具体的功能。
⑧.使用性能分析工具:
使用Java的性能分析工具(如JProfiler、VisualVM等)来检测和分析程序的性能瓶颈。
根据性能分析工具提供的报告和建议进行优化。
⑨.优化JVM参数:
根据应用程序的需求调整JVM的启动参数,如堆大小、垃圾回收器等。
使用JVM提供的性能监控工具(如JConsole、JMX等)来监控JVM的性能。
⑩.避免内存泄漏:
确保在使用完对象后正确地释放资源,如关闭文件、数据库连接等。
使用弱引用(WeakReference)等技术来避免内存泄漏。
二、代码优化的例子(开发中)
1. 使用StringBuilder代替String拼接
优化前:
String result = "";
for (int i = 0; i < 1000; i++) {result += i;
}
优化后:
StringBuilder builder = new StringBuilder();
for (int i = 0; i < 1000; i++) {builder.append(i);
}
String result = builder.toString();
说明:String是不可变的,每次使用+进行拼接都会创建一个新的String对象。而StringBuilder是可变的,它允许在原有对象上进行修改,因此性能更高。
2. 减少方法调用
优化前:
public int calculateSum(int[] numbers) {int sum = 0;for (int i = 0; i < numbers.length; i++) {sum += getNumber(numbers[i]);}return sum;
}private int getNumber(int number) {return number;
}
优化后:
public int calculateSum(int[] numbers) {int sum = 0;for (int i = 0; i < numbers.length; i++) {sum += numbers[i];}return sum;
}
说明:减少了不必要的方法调用,直接访问数组元素。原因如下:
方法调用开销
每次方法调用都会产生额外的开销,包括:
- 栈帧的创建和销毁
- 参数压栈和返回值处理
- 程序计数器跳转
在优化前的例子中,getNumber()方法虽然只是简单返回参数,但每次循环都会产生这些开销。数组访问效率
Java数组访问是高度优化的:
- 数组元素在内存中是连续存储的
- JVM会编译为高效的机器指令(如直接内存访问)
- 现代CPU的缓存预取机制对连续内存访问特别有效
JIT优化限制
虽然JIT编译器会尝试内联简单方法,但:
- 方法调用可能阻碍其他优化
- 内联决策受方法大小和调用频率影响
- 直接访问消除了不确定性
示例性能对比
在示例代码中:
- 优化前:每次迭代需要1次数组访问+1次方法调用
- 优化后:仅需1次数组访问
实测在100万次迭代中,优化后版本可快2-3倍可读性考量
当方法只是简单透传时(如示例中的getNumber()):
- 直接访问使代码更简洁
- 减少不必要的抽象层级
- 更符合"不要为了封装而封装"的原则
3. 使用局部变量替代全局变量
优化前:
public class MyClass {private int globalVar;public void myMethod() {for (int i = 0; i < 1000; i++) {globalVar += i;}}
}
优化后:
public class MyClass {public void myMethod() {int localVar = 0;for (int i = 0; i < 1000; i++) {localVar += i;}// 可以选择将localVar赋值给某个全局变量,但仅在必要时}
}
说明:局部变量存储在栈中,访问速度比全局变量(存储在堆中)更快。原因如下:
性能优势
局部变量存储在栈内存中,访问速度比堆内存中的全局变量更快。每次访问全局变量需要通过对象引用查找,而局部变量直接通过索引访问。内存管理优化
局部变量的生命周期与代码块绑定,执行完毕后自动释放内存,而全局变量需等待GC回收,可能造成内存泄漏。作用域控制
局部变量作用域仅限于声明块内,可避免命名冲突和意外修改。例如:void method() {
int localVar = 10; // 仅限本方法可见
}JIT编译器优化
局部变量更容易被JIT编译器优化,如内联和寄存器分配,而频繁访问全局变量会增加方法调用的开销。线程安全性
局部变量天然线程安全,而全局变量在多线程环境下需要额外同步机制。代码清晰度
局部变量能更清晰地表达代码意图,减少全局状态带来的耦合问题。例如:void calculate() {
int sum = 0; // 明确作用域
for(int i=0; i<array.length; i++) {
sum += array[i];
}
return sum;
}
默认值差异
局部变量必须显式初始化,而全局变量有默认值(如0/null),使用局部变量可避免未初始化错误1。现代Java特性支持
Java 10+的var类型推断适用于局部变量声明,进一步简化代码:void example() {
var list = new ArrayList<>(); // 仅限局部变量
}
4. 减少对象创建(使用对象池)
class MyObject {// 对象的状态private String someState;public void reset() {// 重置对象状态的方法this.someState = null;}// 其他方法...
}优化前:
for (int i = 0; i < 1000; i++) {MyObject obj = new MyObject();// 使用obj进行一些操作
}优化后:
MyObject obj = new MyObject();
for (int i = 0; i < 1000; i++) {// 重置obj并重新使用obj.reset();// 使用obj进行一些操作
}说明:减少了对象的创建次数,降低了垃圾回收的频率和开销。
______________________________________________________________
使用对象池减少对象创建
以下是一个使用Apache Commons Pool库来实现Java对象池模式的示例。这个示例将涵盖ObjectPool接口的使用,以及如何通过PoolableObjectFactory来管理被池化对象的生命周期。
<dependency><groupId>org.apache.commons</groupId><artifactId>commons-pool2</artifactId><version>2.11.1</version>
</dependency>
接下来,我们定义一个被池化的对象类,这个类需要实现PooledObject接口(尽管这不是强制的,但通常为了更好地管理对象,我们会这样做)。不过,在Apache Commons Pool 2中,更常见的是让工厂类实现PooledObjectFactory接口,而不是让对象本身实现PooledObject。因此,在这个示例中,我们将直接实现PooledObjectFactory。
import org.apache.commons.pool2.PooledObject;
import org.apache.commons.pool2.PooledObjectFactory;
import org.apache.commons.pool2.impl.DefaultPooledObject;
import org.apache.commons.pool2.ObjectPool;
import org.apache.commons.pool2.impl.GenericObjectPool;// 被池化的对象类
public class MyPooledObject {private String data;public MyPooledObject(String data) {this.data = data;}public String getData() {return data;}public void setData(String data) {this.data = data;}// 重写toString方法,方便打印@Overridepublic String toString() {return "MyPooledObject{data='" + data + "'}";}
}// 被池化对象的工厂类
public class MyPooledObjectFactory implements PooledObjectFactory<MyPooledObject> {@Overridepublic MyPooledObject makeObject() throws Exception {// 创建并初始化被池化的对象return new MyPooledObject("Initial Data");}@Overridepublic void destroyObject(PooledObject<MyPooledObject> p) throws Exception {// 销毁被池化的对象,释放资源MyPooledObject obj = p.getObject();// 这里可以添加清理资源的代码,比如关闭连接等System.out.println("Destroying: " + obj);}@Overridepublic boolean validateObject(PooledObject<MyPooledObject> p) {// 验证被池化的对象是否有效MyPooledObject obj = p.getObject();// 这里可以添加验证对象有效性的逻辑return obj != null;}@Overridepublic void activateObject(PooledObject<MyPooledObject> p) throws Exception {// 激活被池化的对象,如果对象在空闲时需要做一些准备工作,可以在这里实现MyPooledObject obj = p.getObject();// 这里可以添加激活对象的代码System.out.println("Activating: " + obj);}@Overridepublic void passivateObject(PooledObject<MyPooledObject> p) throws Exception {// 挂起被池化的对象,如果对象在被归还到池中时需要做一些清理工作,可以在这里实现MyPooledObject obj = p.getObject();// 这里可以添加挂起对象的代码System.out.println("Passivating: " + obj);}
}// 使用对象池的示例
public class ObjectPoolExample {public static void main(String[] args) {// 创建对象池,并指定工厂类ObjectPool<MyPooledObject> pool = new GenericObjectPool<>(new MyPooledObjectFactory());// 配置对象池(可选)// pool.setMaxTotal(10); // 设置对象池中的最大对象数// pool.setMaxIdle(5); // 设置对象池中的最大空闲对象数// pool.setMinIdle(1); // 设置对象池中的最小空闲对象数// 从对象池中获取对象try {MyPooledObject obj1 = pool.borrowObject();System.out.println("Borrowed: " + obj1);// 使用对象obj1.setData("Updated Data");// 归还对象到对象池pool.returnObject(obj1);System.out.println("Returned: " + obj1);// 再次从对象池中获取对象,可能是之前归还的那个MyPooledObject obj2 = pool.borrowObject();System.out.println("Borrowed again: " + obj2);} catch (Exception e) {e.printStackTrace();} finally {// 关闭对象池,释放资源(可选,但推荐在不再需要对象池时执行)pool.close();}}
}
代码解释:
被池化的对象类:MyPooledObject是一个简单的Java类,它有一个data字段和相应的getter/setter方法。
被池化对象的工厂类:MyPooledObjectFactory实现了PooledObjectFactory接口。这个类负责创建、销毁、验证、激活和挂起被池化的对象。
makeObject()方法用于创建新的被池化对象。
destroyObject()方法用于销毁被池化的对象,释放资源。
validateObject()方法用于验证被池化的对象是否有效。
activateObject()方法用于激活被池化的对象(如果需要的话)。
passivateObject()方法用于挂起被池化的对象(如果需要的话)。
使用对象池的示例:ObjectPoolExample类展示了如何使用对象池。
首先,创建一个GenericObjectPool对象,并传入MyPooledObjectFactory作为参数。
然后,从对象池中获取对象,使用它,并归还它。
最后,关闭对象池以释放资源。
对象池的工作原理:
借出对象:当调用pool.borrowObject()时,对象池会尝试从空闲对象集合中获取一个对象。如果空闲对象集合为空,对象池会调用工厂类的makeObject()方法创建一个新的对象。
归还对象:当调用pool.returnObject(obj)时,对象会被归还到空闲对象集合中,以便后续使用。
销毁对象:当对象池关闭或达到最大对象数时,对象池会调用工厂类的destroyObject()方法来销毁不再需要的对象。
验证对象:在借出或归还对象时,对象池可以调用工厂类的validateObject()方法来验证对象的有效性。如果对象无效,它可能会被销毁并重新创建。
这个示例展示了如何使用Apache Commons Pool库来实现Java对象池模式。通过对象池,我们可以有效地重用对象,减少内存分配和垃圾回收的开销,从而提高应用程序的性能。
5. 选择高效数据结构和算法
优化前(使用ArrayList进行查找):
List<Integer> list = new ArrayList<>();
// 填充list
for (int i = 0; i < list.size(); i++) {if (list.get(i) == target) {// 找到目标值}
}
优化后(使用HashSet进行查找):
Set<Integer> set = new HashSet<>();
// 填充set
if (set.contains(target)) {// 找到目标值
}
说明:HashSet在查找元素时的时间复杂度为O(1),而ArrayList为O(n)。在需要频繁查找的场景下,HashSet更高效。
—————————————————————————————————————————
优化前:
List<String> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {list.add("item" + i);
}
// 假设需要从list中频繁查找元素
for (int i = 0; i < 1000; i++) {list.indexOf("item" + i); // List的indexOf方法性能较低
}
优化后:
Set<String> set = new HashSet<>();
for (int i = 0; i < 1000; i++) {set.add("item" + i);
}
// 使用Set的contains方法检查元素是否存在,性能更高
for (int i = 0; i < 1000; i++) {set.contains("item" + i); // Set的contains方法性能优于List的indexOf
}
优化点:在需要频繁查找元素的场景下,使用Set代替List可以提高性能,因为Set的contains方法通常比List的indexOf方法更高效。
6. 优化数据库访问
优化前(逐条插入数据):
for (Entity entity : entities) {repository.save(entity);
}
优化后(批量插入数据):
repository.saveAll(entities);
说明:批量操作减少了数据库交互次数,提高了数据库操作效率。
7. 使用Primitive类型替代Wrapper类型
优化前:
List<Integer> list = new ArrayList<>();
for (int i = 0; i < 1000; i++) {list.add(i);
}
优化后:
int[] array = new int[1000];
for (int i = 0; i < 1000; i++) {array[i] = i;
}
说明:在需要存储大量基本数据类型时,使用数组(Primitive类型数组)比使用List<Wrapper>类型更高效,因为Primitive类型数组在内存中的存储更加紧凑,且避免了自动装箱和拆箱的开销。
————————————————————————————————————————
优化前:
for (int i = 0; i < 1000; i++) {Integer num = new Integer(i); // 不必要的对象创建// 使用num进行一些操作
}
优化后:
for (int i = 0; i < 1000; i++) {int num = i; // 使用基本类型代替包装类型,避免对象创建// 使用num进行一些操作
}
优化点:在循环中避免不必要的对象创建,可以减少内存分配和垃圾回收的开销。在这个示例中,我们使用基本类型int代替包装类型Integer来存储数值。
8. 避免使用同步代码块(在可能的情况下)
优化前:
public class Counter {private int count = 0;public synchronized int getCount() {return count;}public synchronized void increment() {count++;}
}优化后(使用AtomicInteger):
import java.util.concurrent.atomic.AtomicInteger;
public class Counter {private AtomicInteger count = new AtomicInteger(0);public int getCount() {return count.get();}public void increment() {count.incrementAndGet();}
}
说明:在单例或多线程环境下,使用AtomicInteger等原子类可以避免使用同步代码块,从而提高性能。原子类内部使用了高效的CAS(Compare-And-Swap)操作来保证线程安全。
9. 使用try-with-resources语句管理资源
优化前:
BufferedReader reader = null;
try {reader = new BufferedReader(new FileReader("file.txt"));// 使用reader读取文件
} catch (IOException e) {e.printStackTrace();
} finally {if (reader != null) {try {reader.close();} catch (IOException e) {e.printStackTrace();}}
}
优化后:
try (BufferedReader reader = new BufferedReader(new FileReader("file.txt"))) {// 使用reader读取文件
} catch (IOException e) {e.printStackTrace();
}
说明:try-with-resources语句可以自动管理资源(如文件、数据库连接等),在try块结束时自动关闭资源,避免了忘记关闭资源或异常处理导致的资源泄漏问题。
10. 使用缓存机制
优化前:
public String getDataFromDatabase(String query) {// 执行数据库查询并返回结果// 假设每次查询都会消耗大量时间和资源
}
优化后(使用ConcurrentHashMap作为缓存):
import java.util.concurrent.ConcurrentHashMap;public class DataCache {private ConcurrentHashMap<String, String> cache = new ConcurrentHashMap<>();public String getData(String query) {// 先从缓存中获取数据String cachedData = cache.get(query);if (cachedData != null) {return cachedData;}// 如果缓存中没有数据,则从数据库中获取并更新缓存String newData = getDataFromDatabase(query);cache.put(query, newData);return newData;}private String getDataFromDatabase(String query) {// 执行数据库查询并返回结果}
}
说明:使用缓存机制可以减少对数据库等慢速资源的访问次数,从而提高性能。在这个示例中,我们使用ConcurrentHashMap作为缓存,它支持高效的并发访问。
(个人觉得这个例子数据有安全性问题,读取缓存的时候,数据库数据可能被更新了)
11. 并发编程优化
优化前:
public void processData(List<Data> dataList) {for (Data data : dataList) {processSingleData(data); // 同步处理数据,性能较低}
}
优化后:
import java.util.concurrent.ExecutorService;
import java.util.concurrent.Executors;public void processData(List<Data> dataList) {ExecutorService executor = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors());for (Data data : dataList) {executor.submit(() -> processSingleData(data)); // 异步处理数据,提高性能}executor.shutdown();
}
优化点:使用线程池进行并发处理,可以充分利用多核CPU的性能,提高数据处理速度。在这个示例中,我们创建了一个固定大小的线程池,并提交任务给线程池进行异步处理。
——————————————————————————————————————————
合理使用线程池:
// 不推荐的方式:每次执行任务都创建新线程,导致线程创建和销毁开销大
for (int i = 0; i < 1000; i++) {new Thread(() -> {// 执行任务...}).start();
}// 推荐的方式:使用线程池执行任务,减少线程创建和销毁开销
ExecutorService executorService = Executors.newFixedThreadPool(10);
for (int i = 0; i < 1000; i++) {executorService.submit(() -> {// 执行任务...});
}
executorService.shutdown();
优化点:使用线程池可以避免频繁创建和销毁线程带来的开销,提高系统的吞吐量和响应速度。
12.集合使用优化-使用ArrayList的get方法代替增强型for循环
List<Integer> list = new ArrayList<>();
// 填充list数据...// 不推荐的方式:使用增强型for循环遍历列表,可能导致迭代器开销
for (Integer item : list) {// 处理item...
}// 推荐的方式:使用索引访问集合元素,避免迭代器开销
for (int i = 0; i < list.size(); i++) {Integer item = list.get(i);// 处理item...
}
优化点:在已知集合大小的情况下,使用索引访问集合元素可以避免迭代器的额外开销,提高循环性能。
(个人测试10W、100W数据量时,效果不明显)
13.并发编程优化-使用ConcurrentHashMap代替synchronized块
// 不推荐的方式:使用synchronized块进行同步,可能导致线程阻塞和性能下降
Map<String, String> synchronizedMap = Collections.synchronizedMap(new HashMap<>());
synchronized (synchronizedMap) {synchronizedMap.put("key", "value");
}// 推荐的方式:使用ConcurrentHashMap进行同步,提高并发性能
Map<String, String> concurrentMap = new ConcurrentHashMap<>();
concurrentMap.put("key", "value");
优化点:ConcurrentHashMap已经针对多线程进行了优化,可以避免使用显式的synchronized块,从而提高并发性能。
14. 避免在循环中重复调用list.size()
for (int i = 0; i < list.size(); i++) {// 循环体
}
优化代码:
int size = list.size();
for (int i = 0; i < size; i++) {// 循环体
}
或者更好的方式:
for (String item : list) {// 循环体
}
优化点:
避免在循环中重复调用list.size()方法,可以减少不必要的开销。
使用增强型for循环(foreach循环)可以简化代码并提高可读性。
方法调用开销
每次调用size()方法都会产生额外的栈帧操作和可能的虚方法表查找(对于非final方法),即使现代JVM会内联简单方法,但重复调用仍可能阻碍其他优化。潜在并发问题
对于非线程安全的集合(如ArrayList),在循环中多次调用size()可能导致不一致的结果,如果在迭代过程中有其他线程修改了集合大小。JIT优化限制
虽然HotSpot会尝试将size()内联为直接访问字段(如ArrayList的size字段),但对于复杂集合(如ConcurrentHashMap),方法调用开销更大。代码可读性
将size()结果存入局部变量能更明确地表达"固定循环次数"的意图:
for (int i = 0, n = list.size(); i < n; i++) { // 使用i和list.get(i) }特殊集合的性能陷阱
某些集合的size()计算成本较高(如LinkedBlockingQueue需要遍历节点),重复调用会导致性能急剧下降。例外情况:当集合可能在循环中被修改(如需要动态响应集合变化),此时必须每次调用
size()。但在大多数固定次数的迭代场景中,缓存size()值是更优选择。
三、Java8 Lambda Stream流 etc
分为下面5个方面:在实际写代码时,可以使用这些新特性写出简约优雅的代码
①、函数式接口
②、Lambda表达式
③、方法引用
④、Option
⑤、stream
1、函数式接口
①、概念:
函数式接口是指只包含一个抽象方法的接口,可以用Lambda表达式或方法引用来实现。Java 8 通过@FunctionalInterface注解来标识函数式接口。虽然这个注解不是强制性的,但建议使用它来确保接口符合函数式接口的定义。
Java 8 提供了许多内置的函数式接口,其中最常用的四个是:
-
Consumer<T>:消费型接口 -
Supplier<T>:供给型接口 -
Function<T, R>:函数型接口 -
Predicate<T>:断言型接口@FunctionalInterface public interface MyFunctionalInterface {void doSomething(); // 只有一个抽象方法 }
为什么使用函数式接口?
函数式接口的主要目的是支持 Lambda 表达式和方法引用,从而简化代码,使代码更加简洁和易读。通过函数式接口,我们可以将行为(方法)作为参数传递,从而实现更灵活的编程。
②、Consumer<T> :
消费型接口
(1)、定义:Consumer<T> 表示接受一个输入参数并返回无结果的操作。它的抽象方法是:
void accept(T t);
(2)、使用场景:适用于需要对输入参数进行处理但不需要返回结果的场景,例如打印、修改对象状态等。
(3)、使用示例:
import java.util.function.Consumer;public class ConsumerExample {public static void main(String[] args) {// 使用 Lambda 表达式实现 ConsumerConsumer<String> printConsumer = (s) -> System.out.println(s);printConsumer.accept("Hello, Consumer!"); //输出: hello, consumer!// 使用方法引用实现 ConsumerConsumer<String> printConsumerRef = System.out::println;printConsumerRef.accept("Hello, Method Reference!"); // 输出:hello, Method Reference!}
}(4)、其他方法:
andThen(Consumer<? super T> after):组合多个Consumer,按顺序执行。
Consumer<String> first = (s) -> System.out.println("First: " + s);
Consumer<String> second = (s) -> System.out.println("Second: " + s);
first.andThen(second).accept("Hello");// 输出:first:hello
second:hello③、Supplier<T>:
供给型接口
(1)、定义:Function<T, R> 表示接受一个输入参数并返回一个结果的函数。它的抽象方法是:
R apply(T t);
(2)、使用场景:适用于需要将一个值转换为另一个值的场景,例如数据转换、映射操作等。
(3)、使用示例:
import java.util.function.Supplier;public class SupplierExample {public static void main(String[] args) {// 使用 Lambda 表达式实现 SupplierSupplier<String> stringSupplier = () -> "Hello, Supplier!";System.out.println(stringSupplier.get()); //输出: hello, supplier!// 使用方法引用实现 Supplier// Supplier<Double> randomSupplier = ()-> Math.random();Supplier<Double> randomSupplier = Math::random;System.out.println(randomSupplier.get()); //输出:0.23149273619774136}
}(4)、其他方法:无
④、Function<T, R>:
函数型接口
(1)、定义:Function<T, R> 表示接受一个输入参数并返回一个结果的函数。它的抽象方法是:
R apply(T t);
(2)、使用场景:适用于需要将一个值转换为另一个值的场景。例如数据转换、映射操作等
(3)、使用示例:
import java.util.function.Function;public class FunctionExample {public static void main(String[] args) {// 使用 Lambda 表达式实现 Function// Function<String, Integer> lengthFunction = (s) -> s.length();Function<String, Integer> lengthFunction = String::length;System.out.println(lengthFunction.apply("Hello, Function!")); //输出 16// 使用方法引用实现 FunctionFunction<String, String> upperCaseFunction = String::toUpperCase;System.out.println(upperCaseFunction.apply("hello")); //输出: HELLO}
}(4)、其他方法:
compose(Function<? super V, ? extends T> before):组合多个Function,先执行before,再执行当前函数。(先执行后一个函数,再执行前一个函数,与andThen相反)
andThen(Function<? super R, ? extends V> after):组合多个Function,先执行当前函数,再执行after。(按顺序先执行前一个函数,再执行后一个函数(参数中的函数))
Function<Integer, Integer> multiplyBy2 = x -> x * 2;
Function<Integer, Integer> add3 = x -> x + 3;// 先乘2再加3
Function<Integer, Integer> multiplyThenAdd = multiplyBy2.andThen(add3);
System.out.println(multiplyThenAdd.apply(5)); // 输出: 13 (5*2=10, 10+3=13)
Function<Integer, Integer> multiplyBy2 = x -> x * 2;
Function<Integer, Integer> add3 = x -> x + 3;// 先加3再乘2
Function<Integer, Integer> addThenMultiply = multiplyBy2.compose(add3);
System.out.println(addThenMultiply.apply(5)); // 输出: 16 (5+3=8, 8*2=16)
⑤、Predicate<T>:
断言型接口
(1)、定义:Predicate<T> 表示一个接受输入参数并返回布尔值的断言。它的抽象方法是:
boolean test(T t);
(2)、使用场景:适用于需要判断输入参数是否满足条件的场景,例如过滤、验证等。
(3)、使用示例:
import java.util.function.Predicate;public class PredicateExample {public static void main(String[] args) {// 使用 Lambda 表达式实现 PredicatePredicate<String> lengthPredicate = (s) -> s.length() > 5;System.out.println(lengthPredicate.test("Hello")); // falseSystem.out.println(lengthPredicate.test("Hello, Predicate!")); // true// 使用方法引用实现 Predicate// Predicate<String> isEmptyPredicate = (s)-> s.isEmpty();Predicate<String> isEmptyPredicate = String::isEmpty;System.out.println(isEmptyPredicate.test("")); // true}
}(4)、其他方法:
and(Predicate<? super T> other):逻辑与操作。
or(Predicate<? super T> other):逻辑或操作。
negate():逻辑非操作。
Predicate<String> lengthPredicate = (s) -> s.length() > 5;
Predicate<String> containsPredicate = (s) -> s.contains("china");
Predicate<String> comb1 = lengthPredicate.and(containsPredicate);
Predicate<String> comb2 = lengthPredicate.or(containsPredicate);
Predicate<String> comb3 = lengthPredicate.negate();
System.out.println(comb1.test("Hello, World!")); // false = true&false
System.out.println(comb2.test("Hello, World!")); // true = true|false
System.out.println(comb3.test("Hello, World!")); // false = !true⑥、自定义函数式接口
@FunctionalInterface
interface MyFunctionalInterface {void myMethod();
}MyFunctionalInterface mfi = () -> System.out.println("My Method");
mfi.myMethod();2、Lambda表达式
①、概念:
Lambda表达式是Java 8引入的一种简洁的匿名函数表示方式,它允许你将函数作为方法参数传递,或者将代码作为数据处理
语法:
(parameters) -> expression
或者
(parameters) -> { statements; }
parameters: 参数列表,可以为空或包含一个或多个参数。
->: Lambda 操作符,将参数和表达式或语句块分开。
expression: 单个表达式,Lambda 表达式会返回该表达式的结果。
{ statements; }: 语句块,可以包含多条语句,需要使用 return 语句返回值(如果有返回值)。
②、分类示例
(1) 无参数的Lambda表达式
() -> System.out.println("Hello, World!");
(2) 无参数的Lambda表达式
x -> x * x
(3) 无参数的Lambda表达式
(x, y) -> x + y
(4) 无参数的Lambda表达式
(x, y) -> {
int sum = x + y;
return sum;
}
③、使用场景
(1)、替代匿名内部类
Lambda 表达式常用于替代匿名内部类,尤其是在使用函数式接口时。
// 使用匿名内部类
Runnable r1 = new Runnable() {@Overridepublic void run() {System.out.println("Hello, World!");}
};// 使用 Lambda 表达式
Runnable r2 = () -> System.out.println("Hello, World!"); (2)、集合操作
Lambda 表达式可以与 Java 8 引入的 Stream API 结合使用,简化集合操作。
List<String> names = Arrays.asList("Alice", "Bob", "Charlie");// 使用 Lambda 表达式遍历集合
names.forEach(name -> System.out.println(name));// 使用 Lambda 表达式过滤集合
List<String> filteredNames = names.stream().filter(name -> name.startsWith("A")).collect(Collectors.toList());
(3)、排序
Lambda 表达式可以简化排序操作。
List<String> names = Arrays.asList("Charlie", "Alice", "Bob");// 使用 Lambda 表达式排序
names.sort((a, b) -> a.compareTo(b)); (4)、函数式接口
Lambda 表达式通常与函数式接口一起使用。函数式接口是只包含一个抽象方法的接口。Java 8 提供了许多内置的函数式接口,如 Runnable、Callable、Comparator 等。
自定义函数式接口
你可以定义自己的函数式接口,然后使用表达式实现。
@FunctionalInterface
interface MyFunctionalInterface {void myMethod();
}MyFunctionalInterface mfi = () -> System.out.println("My Method");
mfi.myMethod();
常用内置函数式接口
Predicate<T>: 接受一个参数并返回一个布尔值。
Consumer<T>: 接受一个参数并执行操作,不返回任何结果。
Function<T, R>: 接受一个参数并返回一个结果。
Supplier<T>: 不接受参数,返回一个结果。
方法引用
方法引用是 Lambda 表达式的一种简化形式,用于直接引用已有方法。
// 静态方法引用
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
numbers.forEach(System.out::println);
// 实例方法引用
String str = "Hello";
Supplier<Integer> lengthSupplier = str::length;
System.out.println(lengthSupplier.get());// 构造方法引用
Supplier<List<String>> listSupplier = ArrayList::new;
List<String> list = listSupplier.get();
(5)、Lambda 表达式的变量作用域
Lambda 表达式可以访问外部的局部变量,但这些变量必须是 final 或事实上是 final 的(即不可变)。
int num = 10;
Runnable r = () -> System.out.println(num);
// num 必须是 final 或事实上是 final (6)、Lambda 表达式的限制
Lambda 表达式只能用于函数式接口。
Lambda 表达式不能包含 break 或 continue 语句。
Lambda 表达式不能抛出检查异常(除非函数式接口允许)。
3、方法引用
①、概念:
方法引用(Method Reference)是Java 8引入的一种简化Lambda表达式的语法特性,它允许你直接引用已有的方法或构造器,而不需要编写完整的Lambda表达式。实际上:方法引用是lambda表达式的一种特殊形式、是lambda表达式的一种语法糖。
使用方法:
方法引用使用一对冒号 :: 将类或对象与方法名进行连接, 通常使用方式如下:
<1> 对象的非静态方法引用 ObjectName :: MethodName
<2> 类的静态方法引用 ClassName :: StaticMethodName
<3> 类的非静态方法引用 ClassName :: MethodName
<4> 构造器的引用 ClassName :: new
<5> 数组的引用 TypeName[] :: new
②、使用示例:
import java.util.Arrays;
import java.util.List;
import java.util.function.*;public class MethodReferenceDemo {public static void main(String[] args) {// 1. 静态方法引用 - static int parseIntFunction<String, Integer> strToInt1 = s -> Integer.parseInt(s);Function<String, Integer> strToInt2 = Integer::parseInt;System.out.println("静态方法引用:");System.out.println("Lambda方式: " + strToInt1.apply("123"));System.out.println("方法引用: " + strToInt2.apply("456"));// 静态方法引用:// Lambda方式: 123// 方法引用: 456// 2. 实例方法引用 - String toUpperCase()String str = "Hello";Supplier<String> toUpper1 = () -> str.toUpperCase();Supplier<String> toUpper2 = str::toUpperCase;System.out.println("\n实例方法引用:");System.out.println("Lambda方式: " + toUpper1.get());System.out.println("方法引用: " + toUpper2.get());// 实例方法引用:// Lambda方式: HELLO// 方法引用: HELLO// 3. 类的任意对象方法引用BiPredicate<String, String> equals1 = (a, b) -> a.equals(b);BiPredicate<String, String> equals2 = String::equals;System.out.println("\n类的任意对象方法引用:");System.out.println("Lambda方式: " + equals1.test("Java", "Java"));System.out.println("方法引用: " + equals2.test("Java", "Python"));// 类的任意对象方法引用:// Lambda方式: true// 方法引用: false// 4. 构造方法引用 - public ArrayList() {.}Supplier<List<String>> listSupplier1 = () -> new ArrayList<>();Supplier<List<String>> listSupplier2 = ArrayList::new;System.out.println("\n构造方法引用:");System.out.println("Lambda方式创建列表大小: " + listSupplier1.get().size());System.out.println("方法引用创建列表大小: " + listSupplier2.get().size());// 构造方法引用:// Lambda方式创建列表大小: 0// 方法引用创建列表大小: 0// 综合应用示例List<String> names = Arrays.asList("Alice", "Bob", "Charlie");System.out.println("\n综合应用:");System.out.println("原始列表: " + names);names.sort(String::compareToIgnoreCase);System.out.println("排序后列表: " + names);// 综合应用:// 原始列表: [Alice, Bob, Charlie]// 排序后列表: [Alice, Bob, Charlie]}
}
4、Option
①、概念:
Optional 类(java.util.Optional) 是一个容器类,它可以保存类型T的值,代表这个值存在。或者仅仅保存null,表示这个值不存在。原来用 null 表示一个值不存在,现在 Optional 可以更好的表达这个概念。并且可以避免空指针异常。
Optional提供很多有用的方法,这样我们就不用显式进行空值检测。
可以保存类型 T 的值或 null
提供多种方法避免显式 null 检查
强制开发者显式处理可能为空的情况
②、创建 Optional 对象
有三种创建 Optional 对象的方式:
// 1. 创建空的 Optional
Optional<String> empty = Optional.empty();// 2. 创建包含非空值的 Optional (如果值为null会抛出NPE)
Optional<String> nonNull = Optional.of("Hello");// 3. 创建可能为null的 Optional
Optional<String> nullable = Optional.ofNullable(getNullableValue());
③、Optional 常用方法及示例
1. 检查值是否存在
// 检查值是否存在
Optional<String> opt = Optional.of("Hello");
System.out.println(opt.isPresent()); // 输出: true
System.out.println(opt.isEmpty()); // 输出: false (Java 11+)Optional<String> s = Optional.of("");
System.out.println(s.isPresent()); // 输出: trueOptional<String> s = Optional.ofNullable("");
System.out.println(s.isPresent()); //输出: trueOptional<String> s = Optional.ofNullable(null);
System.out.println(s.isPresent()); //输出: false2. 获取值
//示例1:
Optional<String> opt = Optional.of("Hello");
// 不安全获取(如果为空会抛出NoSuchElementException)
String value = opt.get();
// 安全获取方式
String value1 = opt.orElse("default"); // 为空时返回默认值
String value2 = opt.orElseGet(() -> "default"); // 使用Supplier提供默认值
String value3 = opt.orElseThrow(() -> new IllegalStateException()); // 为空时抛出异常//示例2:
Optional<String> opt = Optional.ofNullable(null);
// 安全获取方式
String value1 = opt.orElse("default"); // 为空时返回默认值
System.out.println(value1);
String value2 = opt.orElseGet(() -> "default"); // 使用Supplier提供默认值
System.out.println(value2);
String value3 = opt.orElseThrow(() -> new IllegalStateException()); // 为空时抛出异常
System.out.println(value3);
// 不安全获取(如果为空会抛出NoSuchElementException)
String value = opt.get();
System.out.println(value);
//输出:
default
default
Exception in thread "main" java.lang.IllegalStateException at...//示例3:
Optional<String> opt = Optional.ofNullable("hello");
// 安全获取方式
String value1 = opt.orElse("default"); // 为空时返回默认值
System.out.println(value1);
String value2 = opt.orElseGet(() -> "default"); // 使用Supplier提供默认值
System.out.println(value2);
String value3 = opt.orElseThrow(() -> new IllegalStateException()); // 为空时抛出异常
System.out.println(value3);
// 不安全获取(如果为空会抛出NoSuchElementException)
String value = opt.get();
System.out.println(value);
//输出:
hello
hello
hello
hello3. 值存在时执行操作
Optional<String> opt = Optional.of("Hello");// 值存在时执行操作
opt.ifPresent(v -> System.out.println("值为: " + v)); // 输出: 值为: Hello
4. 转换值(map/flatMap)
- map(Function<T, R>):对包装值应用转换函数,返回
Optional<R>,适用于值到值的映射 - flatMap(Function<T, Optional<R>>):应用返回
Optional的函数并展开结果,避免嵌套Optional,适用于值到 Optional的映射
// 传统多层null检查(命令式)
User user = getUser();
String email = null;
if (user != null) {Contact contact = user.getContact();if (contact != null) {email = contact.getEmail();}
}// Optional链式调用(声明式)
String email = Optional.ofNullable(getUser()).map(User::getContact).flatMap(Contact::getEmail).orElse("default@example.com");// map导致嵌套Optional(反例)
Optional<User> userOpt = Optional.of(new User());
Optional<Optional<String>> nestedEmail = userOpt.map(User::getContact) // Optional<Contact>.map(Contact::getEmail); // Optional<Optional<String>>// flatMap正确展开(正例)
Optional<String> emailOpt = userOpt.map(User::getContact) // Optional<Contact>.flatMap(Contact::getEmail); // 直接展开为Optional<String>Optional<String> opt = Optional.of("hello");// map转换
Optional<String> upper = opt.map(String::toUpperCase);
System.out.println(upper.get()); // 输出: HELLO// flatMap转换(用于嵌套Optional)
Optional<Optional<String>> nested = Optional.of(Optional.of("world"));
Optional<String> flat = nested.flatMap(Function.identity());
System.out.println(flat.get()); // 输出: world
5. 过滤(filter)
Optional<String> opt = Optional.of("hello");// 过滤
Optional<String> filtered = opt.filter(s -> s.length() > 3);
System.out.println(filtered.isPresent()); // 输出: trueOptional<String> filtered2 = opt.filter(s -> s.length() > 10);
System.out.println(filtered2.isPresent()); // 输出: false
④、实际应用示例
1. 替代多层 null 检查
// 传统方式
if (user != null) {Address address = user.getAddress();if (address != null) {Country country = address.getCountry();if (country != null) {String isocode = country.getIsocode();if (isocode != null) {isocode = isocode.toUpperCase();}}}
}// Optional方式
String result = Optional.ofNullable(user).map(User::getAddress).map(Address::getCountry).map(Country::getIsocode).map(String::toUpperCase).orElse("DEFAULT");
// 深度嵌套对象的安全访问
String address = Optional.ofNullable(order).map(Order::getCustomer).flatMap(Customer::getShippingInfo).map(ShippingInfo::getAddress).filter(a -> a.contains("China")).orElse("Unknown Address");2. 方法返回值使用 Optional
public Optional<String> findUserEmail(Long userId) {// 模拟数据库查询if (userId == 1L) {return Optional.of("user@example.com");} else {return Optional.empty();}
}// 调用方式
Optional<String> email = findUserEmail(1L);
email.ifPresent(e -> System.out.println("发送邮件到: " + e));
Optional<User> userOpt = Optional.of(new User(17));
Optional<User> adultOpt = userOpt.filter(u -> u.getAge() > 18) // 条件不满足,返回空Optional.map(u -> {System.out.println("This code won't execute");return u;});// 将空值转换为业务异常
Integer userId = Optional.ofNullable(request.getParameter("userId")).filter(s -> s.matches("\\d+")).map(Integer::parseInt).orElseThrow(() -> new InvalidParamException("Invalid user ID"));// 低效:对象装箱
Optional<Integer> boxedOpt = Optional.of(100);// 高效:基础类型特化
OptionalInt primitiveOpt = OptionalInt.of(100);
int value = primitiveOpt.orElse(0); // 直接获取int值,无装箱开销public void test1() throws Exception {Student student = new Student(null, 3);if (student == null || isEmpty(student.getName())) {throw new Exception();}String name = student.getName();// 业务省略...// 使用Optional改造Optional.ofNullable(student).filter(s -> !isEmpty(s.getName())).orElseThrow(() -> new Exception());
}public static boolean isEmpty(CharSequence str) {return str == null || str.length() == 0;
}
int timeout = Optional.ofNullable(redisProperties.getTimeout()).map(x -> Long.valueOf(x.toMillis()).intValue()).orElse(10000);
Optional.ofNullable(props.getProperty(name)).flatMap(OptionalUtils::stringToInt).filter(i -> i>0).orElse(0);
public void test1() {Student student = new Student("李四", 3);Optional<Student> os1 = Optional.ofNullable(student);// 如果student对象不为空,就加一岁Optional<Student> emp = os1.map(e ->{e.setAge(e.getAge() + 1);return e;});}
⑤、注意事项
- 不要滥用 Optional:不应作为方法参数或类字段使用,主要用于返回值
- 避免直接调用 get():除非确定值存在,否则优先使用 orElse/orElseGet
- Optional 不是万能的:不能完全替代 null 检查,特别是对于集合(应使用空集合而非 Optional)
- 性能考虑:Optional 会创建额外对象,在性能敏感场景需谨慎使用
Optional 的正确使用可以显著提高代码可读性和健壮性,减少空指针异常的发生。
5、stream
①、Stream概述
java 8 是一个非常成功的版本,这个版本新增的Stream,配合同版本出现的 Lambda ,给我们操作集合(Collection)提供了极大的便利。
那么什么是Stream?
Stream将要处理的元素集合看作一种流,在流的过程中,借助Stream API对流中的元素进行操作,比如:筛选、排序、聚合等。
Stream可以由数组或集合创建,对流的操作分为两种:
中间操作:每次返回一个新的流,可以有多个。(筛选filter、映射map、排序sorted、去重组合skip—limit)
终端操作:每个流只能进行一次终端操作,终端操作结束后流无法再次使用。终端操作会产生一个新的集合或值。(遍历foreach、匹配find–match、规约reduce、聚合max–min–count、收集collect)
另外,Stream有几个特性:
stream不存储数据,而是按照特定的规则对数据进行计算,一般会输出结果。
stream不会改变数据源,通常情况下会产生一个新的集合或一个值。
stream具有延迟执行特性,只有调用终端操作时,中间操作才会执行。
Stream与传统遍历相比
几乎所有的集合(如 Collection 接口或 Map 接口等)都支持直接或间接的遍历操作。而当我们需要对集合中的元素进行操作的时候,除了必需的添加、删除、获取外,最典型的就是集合遍历。例如:
import java.util.ArrayList;
import java.util.List;public class Demo1List {public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("张无忌");list.add("周芷若");list.add("赵敏");list.add("小昭");list.add("殷离");list.add("张三");list.add("张三丰");List<String> listA = new ArrayList<>();for ( String s : list) {if (s.startsWith("张"))listA.add(s);}List<String> listB = new ArrayList<>();for (String s: listA) {if (s.length() == 3)listB.add(s);}for (String s: listB) {System.out.println(s);}}
}循环遍历的弊端
Java 8的Lambda更加专注于做什么(What),而不是怎么做(How),这点此前已经结合内部类进行了对比说明。现在,仔细体会一下上例代码,可以发现:
for循环的语法就是“怎么做”
for循环的循环体才是“做什么”
为什么使用循环?因为要进行遍历。但循环是遍历的唯一方式吗?遍历是指每一个元素逐一进行处理,而并不是从第一个到最后一个顺次处理的循环。前者是目的,后者是方式。
使用Stream写法
import java.util.ArrayList;
import java.util.List;public class Demo2Steam {public static void main(String[] args) {List<String> list = new ArrayList<>();list.add("张无忌");list.add("周芷若");list.add("赵敏");list.add("小昭");list.add("殷离");list.add("张三");list.add("张三丰");list.stream().filter(name -> name.startsWith("张")).filter(name -> name.length() == 3).forEach(name -> System.out.println(name));}
}②、Stream的创建
Stream可以通过集合数组创建。
1、通过 java.util.Collection.stream() 方法用集合创建流
List<String> list = Arrays.asList("a", "b", "c");
// 创建一个顺序流
Stream<String> stream = list.stream();
// 创建一个并行流
Stream<String> parallelStream = list.parallelStream();
2、使用java.util.Arrays.stream(T[] array)方法用数组创建流
int[] array={1,3,5,6,8};
IntStream stream = Arrays.stream(array);
3、使用Stream的静态方法:of()、iterate()、generate()
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5, 6);Stream<Integer> stream2 = Stream.iterate(0, (x) -> x + 3).limit(4);
stream2.forEach(System.out::println); // 0 3 6 9Stream<Double> stream3 = Stream.generate(Math::random).limit(3);
stream3.forEach(System.out::println);
//输出:
0.7748471520653126
0.6071833509456785
0.7783126073723329
stream和parallelStream的简单区分:
stream是顺序流,由主线程按顺序对流执行操作,而parallelStream是并行流,内部以多线程并行执行的方式对流进行操作,但前提是流中的数据处理没有顺序要求。例如筛选集合中的奇数,两者的处理不同之处:
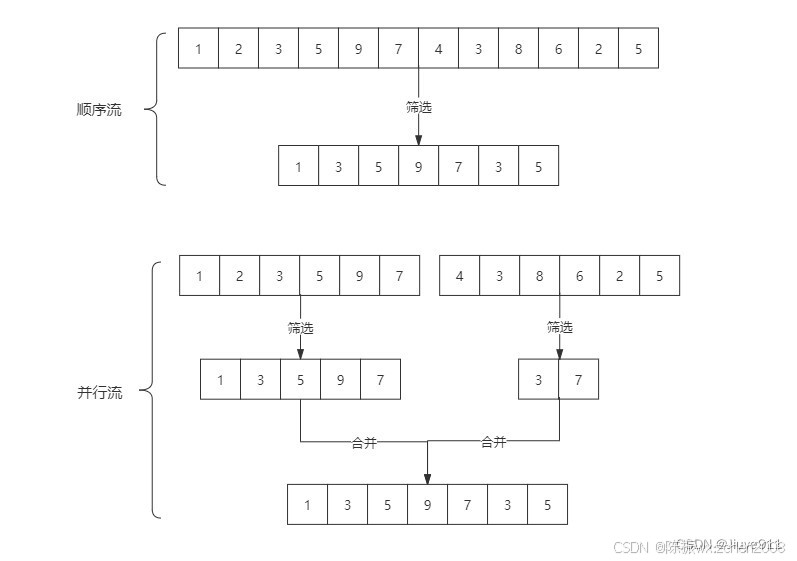
如果流中的数据量足够大,并行流可以加快处速度。
除了直接创建并行流,还可以通过parallel()把顺序流转换成并行流:
Optional<Integer> findFirst = list.stream().parallel().filter(x->x>6).findFirst();
List<Integer> list = Arrays.asList(1, 3, 6, 8, 12, 4);
Optional<Integer> findFirst = list.stream().parallel().filter(x->x>6).findFirst();
System.out.println("使用Stream的静态方法generate:" + findFirst.get());
③、Stream的使用
在使用stream之前,先理解一个概念:Optional 。
Optional类是一个可以为null的容器对象。如果值存在则isPresent()方法会返回true,调用get()方法会返回该对象。
首先创建一个案例使用的员工类Person
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, "male", "New York"));
personList.add(new Person("Jack", 7000, "male", "Washington"));
personList.add(new Person("Lily", 7800, "female", "Washington"));
personList.add(new Person("Anni", 8200, "female", "New York"));
personList.add(new Person("Owen", 9500, "male", "New York"));
personList.add(new Person("Alisa", 7900, "female", "New York"));class Person {private String name; // 姓名private int salary; // 薪资private int age; // 年龄private String sex; //性别private String area; // 地区// 构造方法public Person(String name, int salary, int age,String sex,String area) {this.name = name;this.salary = salary;this.age = age;this.sex = sex;this.area = area;}// 省略了get和set,请自行添加}3.1 遍历/匹配(foreach、find、match)
Stream也是支持类似集合的遍历和匹配元素的,只是Stream中的元素是以Optional类型存在的。Stream的遍历、匹配非常简单。
List<Integer> list = Arrays.asList(7, 6, 9, 3, 8, 2, 1);// 遍历输出符合条件的元素
list.stream().filter(x -> x > 6).forEach(System.out::println);
// 匹配第一个
Optional<Integer> findFirst = list.stream().filter(x -> x > 6).findFirst();
// 匹配任意(适用于并行流)
Optional<Integer> findAny = list.parallelStream().filter(x -> x > 6).findAny();
// 是否包含符合特定条件的元素
boolean anyMatch = list.stream().anyMatch(x -> x > 6);
System.out.println("匹配第一个值:" + findFirst.get());
System.out.println("匹配任意一个值:" + findAny.get());
System.out.println("是否存在大于6的值:" + anyMatch);
输出结果: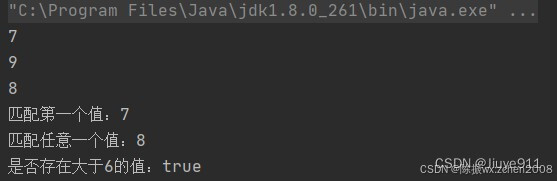
3.2 筛选(filter)
筛选,是按照一定的规则校验流中的元素,将符合条件的元素提取到新的流中的操作。
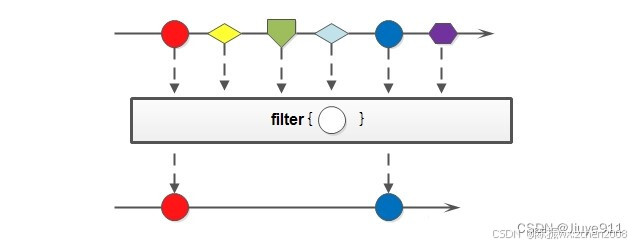
Stream<T> filter(Predicate<? super T> predicate);
案例一:筛选出Integer集合中大于7的元素,并打印出来
List<Integer> list = Arrays.asList(6, 7, 3, 8, 1, 2, 9);
Stream<Integer> stream = list.stream();
stream.filter(x -> x > 7).forEach(System.out::println);//输出:
8
9案例二: 筛选员工中工资高于8000的人,并形成新的集合。 形成新集合依赖collect(收集),后文有详细介绍。
List<Person> personList = new ArrayList<Person>();
personList.add(new Person("Tom", 8900, 23, "male", "New York"));
personList.add(new Person("Jack", 7000, 25, "male", "Washington"));
personList.add(new Person("Lily", 7800, 21, "female", "Washington"));
personList.add(new Person("Anni", 8200, 24, "female", "New York"));
personList.add(new Person("Owen", 9500, 25, "male", "New York"));
personList.add(new Person("Alisa", 7900, 26, "female", "New York"));List<String> fiterList = personList.stream().filter(x -> x.getSalary() > 8000).map(Person::getName).collect(Collectors.toList());
System.out.print("高于8000的员工姓名:" + fiterList);
输出结果:
3.3 聚合(max、min、count)
max、min、count这些一定不陌生,在mysql中我们常用它们进行数据统计。Java stream中也引入了这些概念和用法,极大地方便了我们对集合、数组的数据统计工作。
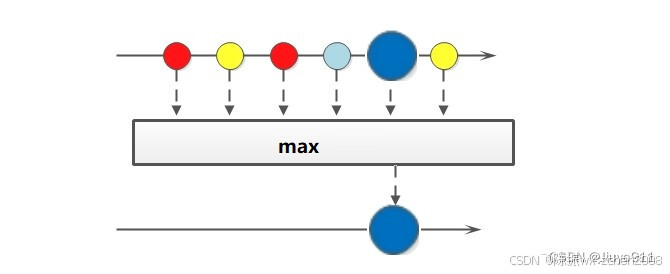
案例一:获取String集合中最长的元素。
List<String> list = Arrays.asList("adnm", "admmt", "pot", "xbangd", "weoujgsd");Optional<String> max = list.stream().max(Comparator.comparing(String::length));
System.out.println("最长的字符串:" + max.get());
//输出: 最长的字符串:weoujgsd
案例二:获取Integer集合中的最大值。
List<Integer> list = Arrays.asList(7, 6, 9, 4, 11, 6);
// 自然排序
Optional<Integer> max = list.stream().max(Integer::compareTo);
// 自定义排序
Optional<Integer> max2 = list.stream().max(new Comparator<Integer>() {
@Overridepublic int compare(Integer o1, Integer o2) {return o1.compareTo(o2);}});// 自定义缩写1:
//Optional<Integer> max2 = list.stream().max((o1, o2) -> o1.compareTo(o2));
// 自定义缩写2:
Optional<Integer> max2 = list.stream().max(Comparator.naturalOrder());System.out.println("自然排序的最大值:" + max.get()); // 11
System.out.println("自定义排序的最大值:" + max2.get()); // 11案例三:获取员工工资最高的人。
public class StreamTest {public static void main(String[] args) {List<Person> personList = new ArrayList<Person>();personList.add(new Person("Tom", 8900, 23, "male", "New York"));personList.add(new Person("Jack", 7000, 25, "male", "Washington"));personList.add(new Person("Lily", 7800, 21, "female", "Washington"));personList.add(new Person("Anni", 8200, 24, "female", "New York"));personList.add(new Person("Owen", 9500, 25, "male", "New York"));personList.add(new Person("Alisa", 7900, 26, "female", "New York"));Optional<Person> max = personList.stream().max(Comparator.comparingInt(Person::getSalary));System.out.println("员工工资最大值:" + max.get().getSalary());}
}案例四:计算Integer集合中大于6的元素的个数。
import java.util.Arrays;
import java.util.List;public class StreamTest {public static void main(String[] args) {List<Integer> list = Arrays.asList(7, 6, 4, 8, 2, 11, 9);long count = list.stream().filter(x -> x > 6).count();System.out.println("list中大于6的元素个数:" + count);}
}3.4 映射(map、flatMap)
映射,可以将一个流的元素按照一定的映射规则映射到另一个流中。分为map和flatMap:
map:接收一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。
flatMap:接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流连接成一个流。
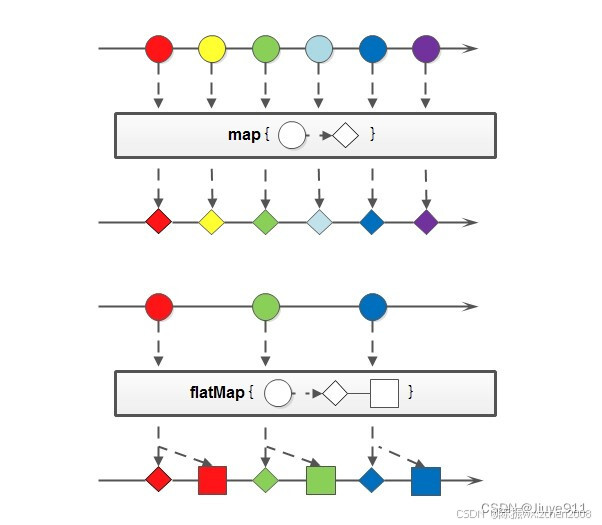
<R> Stream<R> map(Function<? super T, ? extends R> mapper);
<R> Stream<R> flatMap(Function<? super T, ? extends Stream<? extends R>> mapper);
案例一:英文字符串数组的元素全部改为大写。整数数组每个元素+3。
public class StreamTest {public static void main(String[] args) {String[] strArr = { "abcd", "bcdd", "defde", "fTr" };List<String> strList = Arrays.stream(strArr).map(String::toUpperCase).collect(Collectors.toList());List<Integer> intList = Arrays.asList(1, 3, 5, 7, 9, 11);List<Integer> intListNew = intList.stream().map(x -> x + 3).collect(Collectors.toList());System.out.println("每个元素大写:" + strList);System.out.println("每个元素+3:" + intListNew);}
}输出结果:
案例二:将员工的薪资全部增加1000。
public class StreamTest {public static void main(String[] args) {List<Person> personList = new ArrayList<Person>();personList.add(new Person("Tom", 8900, 23, "male", "New York"));personList.add(new Person("Jack", 7000, 25, "male", "Washington"));personList.add(new Person("Lily", 7800, 21, "female", "Washington"));personList.add(new Person("Anni", 8200, 24, "female", "New York"));personList.add(new Person("Owen", 9500, 25, "male", "New York"));personList.add(new Person("Alisa", 7900, 26, "female", "New York"));// 不改变原来员工集合的方式List<Person> personListNew = personList.stream().map(person -> {Person personNew = new Person(person.getName(), 0, 0, null, null);personNew.setSalary(person.getSalary() + 10000);return personNew;}).collect(Collectors.toList());System.out.println("一次改动前:" + personList.get(0).getName() + "-->" + personList.get(0).getSalary());System.out.println("一次改动后:" + personListNew.get(0).getName() + "-->" + personListNew.get(0).getSalary());// 改变原来员工集合的方式List<Person> personListNew2 = personList.stream().map(person -> {person.setSalary(person.getSalary() + 10000);return person;}).collect(Collectors.toList());System.out.println("二次改动前:" + personList.get(0).getName() + "-->" + personListNew.get(0).getSalary());System.out.println("二次改动后:" + personListNew2.get(0).getName() + "-->" + personListNew.get(0).getSalary());}
}输出结果: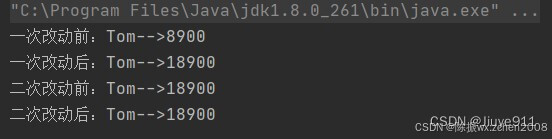
案例三:将两个字符数组合并成一个新的字符数组。
public class StreamTest {public static void main(String[] args) {List<String> list = Arrays.asList("m,k,l,a", "1,3,5,7");List<String> listNew = list.stream().flatMap(s -> {// 将每个元素转换成一个streamString[] split = s.split(",");Stream<String> s2 = Arrays.stream(split);return s2;}).collect(Collectors.toList());System.out.println("处理前的集合:" + list);System.out.println("处理后的集合:" + listNew);}
}输出结果:
3.5 规约(reduce)
归约,也称缩减,顾名思义是把一个流缩减成一个值,能实现对集合求和、求乘积和求最值操作。
T reduce(T identity, BinaryOperator<T> accumulator);@Overridepublic final P_OUT reduce(final P_OUT identity, final BinaryOperator<P_OUT> accumulator) {return evaluate(ReduceOps.makeRef(identity, accumulator, accumulator));}Optional<T> reduce(BinaryOperator<T> accumulator);@Overridepublic final Optional<P_OUT> reduce(BinaryOperator<P_OUT> accumulator) {return evaluate(ReduceOps.makeRef(accumulator));}<U> U reduce(U identity,BiFunction<U, ? super T, U> accumulator,BinaryOperator<U> combiner);@Overridepublic final <R> R reduce(R identity, BiFunction<R, ? super P_OUT, R> accumulator, BinaryOperator<R> combiner) {return evaluate(ReduceOps.makeRef(identity, accumulator, combiner));}Optional reduce(BinaryOperator accumulator):第一次执行时,accumulator函数的第一个参数为流中的第一个元素,第二个参数为流中元素的第二个元素;第二次执行时,第一个参数为第一次函数执行的结果,第二个参数为流中的第三个元素;依次类推。
T reduce(T identity, BinaryOperator accumulator):流程跟上面一样,只是第一次执行时,accumulator函数的第一个参数为identity,而第二个参数为流中的第一个元素。
案例一:求Integer集合的元素之和、乘积和最大值。
List<Integer> list = Arrays.asList(1, 3, 2, 8, 11, 4);// 求和方式1
Optional<Integer> sum = list.stream().reduce((x, y) -> x + y);
System.out.println(sum.get()); // 29// 求和方式2
Optional<Integer> sum2 = list.stream().reduce(Integer::sum);
System.out.println(sum2.get()); // 29// 求和方式3
Integer sum3 = list.stream().reduce(0, Integer::sum);
System.out.println(sum3); // 29, 这里的初始值是0,如果列表为空,则返回0// 求乘积
Optional<Integer> product = list.stream().reduce((x, y) -> x * y);
System.out.println("list求积:" + product.get()); // 2112 // 求最大值方式1
Optional<Integer> max = list.stream().reduce((x, y) -> x > y ? x : y); // 11// 求最大值写法2
// 初始值为1,初始值会与list中的最大值作比较,
// 11>1,显示为11, 如果初始值为12,则 12>11 显示12
Integer max2 = list.stream().reduce(1, Integer::max); 输出结果:
案例二:求所有员工的工资之和和最高工资。
public class StreamTest {public static void main(String[] args) {List<Person> personList = new ArrayList<Person>();personList.add(new Person("Tom", 8900, 23, "male", "New York"));personList.add(new Person("Jack", 7000, 25, "male", "Washington"));personList.add(new Person("Lily", 7800, 21, "female", "Washington"));personList.add(new Person("Anni", 8200, 24, "female", "New York"));personList.add(new Person("Owen", 9500, 25, "male", "New York"));personList.add(new Person("Alisa", 7900, 26, "female", "New York"));// 求工资之和方式1:Optional<Integer> sumSalary = personList.stream().map(Person::getSalary).reduce(Integer::sum);// 求工资之和方式2:Integer sumSalary2 = personList.stream().reduce(0, (sum, p) -> sum += p.getSalary(),(sum1, sum2) -> sum1 + sum2);// 求工资之和方式3:Integer sumSalary3 = personList.stream().reduce(0, (sum, p) -> sum += p.getSalary(), Integer::sum);// 求最高工资方式1:Integer maxSalary = personList.stream().reduce(0, (max, p) -> max > p.getSalary() ? max : p.getSalary(),Integer::max);// 求最高工资方式2:Integer maxSalary2 = personList.stream().reduce(0, (max, p) -> max > p.getSalary() ? max : p.getSalary(),(max1, max2) -> max1 > max2 ? max1 : max2);System.out.println("工资之和:" + sumSalary.get() + "," + sumSalary2 + "," + sumSalary3);System.out.println("最高工资:" + maxSalary + "," + maxSalary2);}
}输出结果:
3.6 收集(collect)
collect,收集,可以说是内容最繁多、功能最丰富的部分了。从字面上去理解,就是把一个流收集起来,最终可以是收集成一个值也可以收集成一个新的集合。
collect主要依赖java.util.stream.Collectors类内置的静态方法。
3.6.1 归集(toList、toSet、toMap)
因为流不存储数据,那么在流中的数据完成处理后,需要将流中的数据重新归集到新的集合里。toList、toSet和toMap比较常用,另外还有toCollection、toConcurrentMap等复杂一些的用法。
下面用一个案例演示toList、toSet和toMap:
public class StreamTest {public static void main(String[] args) {List<Integer> list = Arrays.asList(1, 6, 3, 4, 6, 7, 9, 6, 20);List<Integer> listNew = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toList());Set<Integer> set = list.stream().filter(x -> x % 2 == 0).collect(Collectors.toSet());List<Person> personList = new ArrayList<Person>();personList.add(new Person("Tom", 8900, 23, "male", "New York"));personList.add(new Person("Jack", 7000, 25, "male", "Washington"));personList.add(new Person("Lily", 7800, 21, "female", "Washington"));personList.add(new Person("Anni", 8200, 24, "female", "New York"));Map<?, Person> map = personList.stream().filter(p -> p.getSalary() > 8000).collect(Collectors.toMap(Person::getName, p -> p));System.out.println("toList:" + listNew);System.out.println("toSet:" + set);System.out.println("toMap:" + map);}
}输出结果:
3.6.2 统计(count、averaging)
Collectors提供了一系列用于数据统计的静态方法:
计数:count
平均值:averagingInt、averagingLong、averagingDouble
最值:maxBy、minBy
求和:summingInt、summingLong、summingDouble
统计以上所有:summarizingInt、summarizingLong、summarizingDouble
案例:统计员工人数、平均工资、工资总额、最高工资。
public class StreamTest {public static void main(String[] args) {List<Person> personList = new ArrayList<Person>();personList.add(new Person("Tom", 8900, 23, "male", "New York"));personList.add(new Person("Jack", 7000, 25, "male", "Washington"));personList.add(new Person("Lily", 7800, 21, "female", "Washington"));// 求总数Long count = personList.stream().collect(Collectors.counting());// 求平均工资Double average = personList.stream().collect(Collectors.averagingDouble(Person::getSalary));// 求最高工资Optional<Integer> max = personList.stream().map(Person::getSalary).collect(Collectors.maxBy(Integer::compare));// 求工资之和Integer sum = personList.stream().collect(Collectors.summingInt(Person::getSalary));// 一次性统计所有信息DoubleSummaryStatistics collect = personList.stream().collect(Collectors.summarizingDouble(Person::getSalary));System.out.println("员工总数:" + count);System.out.println("员工平均工资:" + average);System.out.println("员工工资总和:" + sum);System.out.println("员工工资所有统计:" + collect);}
}输出结果:
3.6.3 分组(partitioningBy、groupingBy)
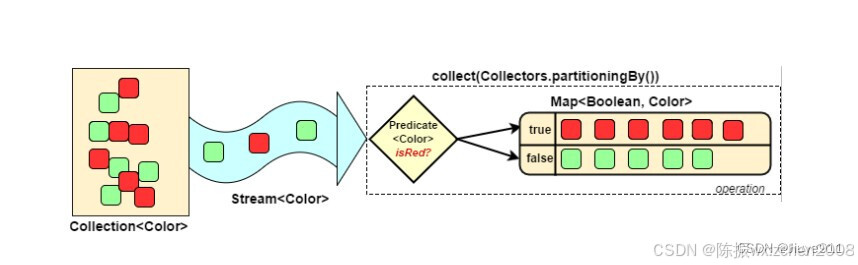
分区:将stream按条件分为两个Map,比如员工按薪资是否高于8000分为两部分。
分组:将集合分为多个Map,比如员工按性别分组。有单级分组和多级分组。
public static <T>Collector<T, ?, Map<Boolean, List<T>>> partitioningBy(Predicate<? super T> predicate) {return partitioningBy(predicate, toList());}public static <T, K> Collector<T, ?, Map<K, List<T>>>groupingBy(Function<? super T, ? extends K> classifier) {return groupingBy(classifier, toList());}
案例:将员工按薪资是否高于8000分为两部分;将员工按性别和地区分组
public class StreamTest {
public static void main(String[] args) {List<Person> personList = new ArrayList<Person>();personList.add(new Person("Tom", 8900, "male", "New York"));personList.add(new Person("Jack", 7000, "male", "Washington"));personList.add(new Person("Lily", 7800, "female", "Washington"));personList.add(new Person("Anni", 8200, "female", "New York"));personList.add(new Person("Owen", 9500, "male", "New York"));personList.add(new Person("Alisa", 7900, "female", "New York"));// 将员工按薪资是否高于8000分组Map<Boolean, List<Person>> part = personList.stream().collect(Collectors.partitioningBy(x -> x.getSalary() > 8000));// 将员工按性别分组Map<String, List<Person>> group = personList.stream().collect(Collectors.groupingBy(Person::getSex));// 将员工先按性别分组,再按地区分组Map<String, Map<String, List<Person>>> group2 = personList.stream().collect(Collectors.groupingBy(Person::getSex, Collectors.groupingBy(Person::getArea)));System.out.println("员工按薪资是否大于8000分组情况:" + part);System.out.println("员工按性别分组情况:" + group);System.out.println("员工按性别、地区:" + group2);}
}输出结果:
3.6.4 接合(joining)
joining可以将stream中的元素用特定的连接符(没有的话,则直接连接)连接成一个字符串。
public static Collector<CharSequence, ?, String> joining(CharSequence delimiter) {return joining(delimiter, "", "");}
案例:拼接字符串
public class StreamTest {public static void main(String[] args) {List<Person> personList = new ArrayList<Person>();personList.add(new Person("Tom", 8900, 23, "male", "New York"));personList.add(new Person("Jack", 7000, 25, "male", "Washington"));personList.add(new Person("Lily", 7800, 21, "female", "Washington"));String names = personList.stream().map(p -> p.getName()).collect(Collectors.joining(","));System.out.println("所有员工的姓名:" + names);List<String> list = Arrays.asList("A", "B", "C");String string = list.stream().collect(Collectors.joining("-"));System.out.println("拼接后的字符串:" + string);}
}输出结果:
3.6.5 规约(reducing)
Collectors类提供的reducing方法,相比于stream本身的reduce方法,增加了对自定义归约的支持。
public static <T> Collector<T, ?, Optional<T>>reducing(BinaryOperator<T> op) {class OptionalBox implements Consumer<T> {T value = null;boolean present = false;@Overridepublic void accept(T t) {if (present) {value = op.apply(value, t);}else {value = t;present = true;}}}return new CollectorImpl<T, OptionalBox, Optional<T>>(OptionalBox::new, OptionalBox::accept,(a, b) -> { if (b.present) a.accept(b.value); return a; },a -> Optional.ofNullable(a.value), CH_NOID);}public class StreamTest {public static void main(String[] args) {List<Person> personList = new ArrayList<Person>();personList.add(new Person("Tom", 8900, 23, "male", "New York"));personList.add(new Person("Jack", 7000, 25, "male", "Washington"));personList.add(new Person("Lily", 7800, 21, "female", "Washington"));// 每个员工减去起征点后的薪资之和(这个例子并不严谨,但一时没想到好的例子)Integer sum = personList.stream().collect(Collectors.reducing(0, Person::getSalary, (i, j) -> (i + j - 5000)));System.out.println("员工扣税薪资总和:" + sum);// stream的reduceOptional<Integer> sum2 = personList.stream().map(Person::getSalary).reduce(Integer::sum);System.out.println("员工薪资总和:" + sum2.get());}
}输出结果:
3.7 排序(sorted)
sorted,中间操作。有两种排序:
sorted():自然排序,流中元素需实现Comparable接口
sorted(Comparator com):Comparator排序器自定义排序
Stream<T> sorted();@Overridepublic final Stream<P_OUT> sorted() {return SortedOps.makeRef(this);} Stream<T> sorted(Comparator<? super T> comparator);@Overridepublic final Stream<P_OUT> sorted(Comparator<? super P_OUT> comparator) {return SortedOps.makeRef(this, comparator);}
案例:将员工按工资由高到低(工资一样则按年龄由大到小)排序
public class StreamTest {public static void main(String[] args) {List<Person> personList = new ArrayList<Person>();personList.add(new Person("Sherry", 9000, 24, "female", "New York"));personList.add(new Person("Tom", 8900, 22, "male", "Washington"));personList.add(new Person("Jack", 9000, 25, "male", "Washington"));personList.add(new Person("Lily", 8800, 26, "male", "New York"));personList.add(new Person("Alisa", 9000, 26, "female", "New York"));// 按工资升序排序(自然排序)List<String> newList = personList.stream().sorted(Comparator.comparing(Person::getSalary)).map(Person::getName).collect(Collectors.toList());// 按工资倒序排序List<String> newList2 = personList.stream().sorted(Comparator.comparing(Person::getSalary).reversed()).map(Person::getName).collect(Collectors.toList());// 先按工资再按年龄升序排序List<String> newList3 = personList.stream().sorted(Comparator.comparing(Person::getSalary).thenComparing(Person::getAge)).map(Person::getName).collect(Collectors.toList());// 先按工资再按年龄自定义排序(降序)List<String> newList4 = personList.stream().sorted((p1, p2) -> {if (p1.getSalary() == p2.getSalary()) {return p2.getAge() - p1.getAge();} else {return p2.getSalary() - p1.getSalary();}}).map(Person::getName).collect(Collectors.toList());System.out.println("按工资升序排序:" + newList);System.out.println("按工资降序排序:" + newList2);System.out.println("先按工资再按年龄升序排序:" + newList3);System.out.println("先按工资再按年龄自定义降序排序:" + newList4);}
} 输出结果:
3.8 去重、合并(distinct、skip、limit)
流也可以进行合并、去重(distinct)、限制(limit)、跳过(skip)等操作
Stream<T> distinct();@Overridepublic final Stream<P_OUT> distinct() {return DistinctOps.makeRef(this);}Stream<T> limit(long maxSize);@Overridepublic final Stream<P_OUT> limit(long maxSize) {if (maxSize < 0)throw new IllegalArgumentException(Long.toString(maxSize));return SliceOps.makeRef(this, 0, maxSize);}Stream<T> skip(long n);@Overridepublic final Stream<P_OUT> skip(long n) {if (n < 0)throw new IllegalArgumentException(Long.toString(n));if (n == 0)return this;elsereturn SliceOps.makeRef(this, n, -1);}
案例:合并流、限制流、跳过流
public class StreamTest {public static void main(String[] args) {String[] arr1 = { "a", "b", "c", "d" };String[] arr2 = { "d", "e", "f", "g" };Stream<String> stream1 = Stream.of(arr1);Stream<String> stream2 = Stream.of(arr2);// concat:合并两个流 distinct:去重List<String> newList = Stream.concat(stream1, stream2).distinct().collect(Collectors.toList());// limit:限制从流中获得前n个数据List<Integer> collect = Stream.iterate(1, x -> x + 2).limit(10).collect(Collectors.toList());// skip:跳过前n个数据 这里的1代表把1代入后边的计算表达式List<Integer> collect2 = Stream.iterate(1, x -> x + 2).skip(1).limit(5).collect(Collectors.toList());System.out.println("流合并:" + newList);System.out.println("limit:" + collect);System.out.println("skip:" + collect2);}
}输出结果: