基于Rust实现高性能数据处理引擎



目录
- `文章摘要`
- `基于Rust实现高性能数据处理引擎`
- `一、项目概述`
- `二、项目设计:RustStream数据处理引擎`
- `数据处理项目结构`
- `数据处理项目核心依赖`
- `三、核心代码实现与Rust优势分析`
- `内存管理模块实现`
- `Rust 并发处理,优势实战体现`
- ` Rust异步处理与高性能调度`
- 项目主程序
- 四,总结
目录
- `文章摘要`
- `基于Rust实现高性能数据处理引擎`
- `一、项目概述`
- `二、项目设计:RustStream数据处理引擎`
- `数据处理项目结构`
- `数据处理项目核心依赖`
- `三、核心代码实现与Rust优势分析`
- `内存管理模块实现`
- `Rust 并发处理,优势实战体现`
- ` Rust异步处理与高性能调度`
- 项目主程序
- 四,总结

文章摘要
在大数据实时计算领域,“性能与安全难以两全” 是长期痛点 ——C/C++ 虽性能强劲却难逃手动内存管理隐患,Java、Python 虽规避内存问题却受 GC 暂停或 GIL 锁限制。Rust 凭借独特的所有权机制与编译时检查,既实现了接近 C/C++ 的极致吞吐与低延迟,又杜绝了内存泄漏、数据竞争等安全问题。本文将通过RustStream数据处理引擎,详解 Rust 如何打破权衡困境并落地实践。
基于Rust实现高性能数据处理引擎
一、项目概述
- 本篇文章将通过一个名为RustStream的数据处理引擎项目,将Rust 的这些核心优势落到具体实践中。这个引擎专门针对实时流式数据处理场景设计,支持数据过滤、聚合、窗口计算等核心功能,将详细展示如何利用 Rust 的零成本抽象优化数据处理链路,如何通过所有权系统保障高并发下的数据安全,如何借助异步 I/O 模型提升数据吞吐能力。
二、项目设计:RustStream数据处理引擎
数据处理项目结构
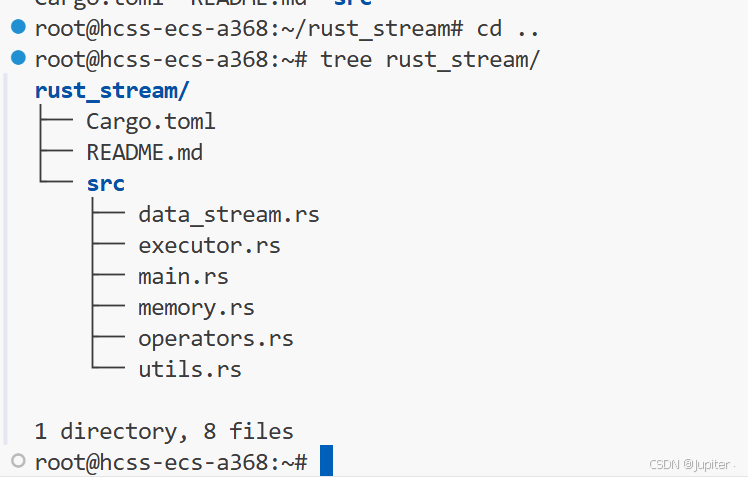
项目目录解析:
rust_stream/
├── Cargo.toml # 项目依赖配置
├── src/
│ ├── main.rs # 主入口文件
│ ├── data_stream.rs # 数据流核心抽象
│ ├── operators.rs # 数据操作符实现
│ ├── executor.rs # 执行引擎
│ ├── memory.rs # 内存管理模块
│ └── utils.rs # 工具函数
└── README.md # 项目说明文档
数据处理项目核心依赖
这个 Cargo.toml 是 rust_stream 数据处理引擎的 配置 —— 相当于给项目搭好骨架,明确了项目身份和要用到的 “工具库”,每一项都和实时数据处理的需求强相关,简单说清它的作用与优势在哪里:
[package]
name = "rust_stream" # 项目名,和咱们的“高性能数据处理引擎”定位对应
version = "0.1.0" # 初始版本,后续迭代再升级
edition = "2021" # 用 Rust 2021 稳定版,语法兼容、功能够用,新手不用纠结版本问题[dependencies]
rayon = "1.7.0" # 并行计算支持
serde = { version = "1.0.160", features = ["derive"] } # 序列化/反序列化
serde_json = "1.0.96" # JSON处理
tokio = { version = "1.28.2", features = ["full"] } # 异步运行时
- 在下面的配置里面,每个依赖都写了明确版本(比如 rayon = “1.7.0”、serde = “1.0.160”),Cargo 会自动生成 Cargo.lock 文件,把所有依赖(包括依赖的依赖,比如 serde_json 依赖的 serde)的版本 一一对应—— 下次编译、换机器编译,都是一模一样的版本,不会像 Java 因依赖传递搞出 “版本冲突”,也不会像 Python 因默认拉最新版导致代码突然跑不通。
- 自动依赖传递,比如代码里只写了 serde_json = “1.0.96”,但它依赖 serde,Cargo 会自动识别、下载 serde,不用你手动加 “serde 是 serde_json 的依赖” 这种配置;反观 Java 有时要手动排除冲突依赖,C++ 更是要自己找库的依赖链,更麻烦。
- 配置了项目的配置,可以实现按需编译,不会导致代码 “臃肿”,靠 features 特性开关精准控制功能:比如 serde = { version = “1.0.160”, features = [“derive”] },只开 “自动生成序列化代码” 的功能;tokio = { version = “1.28.2”, features = [“full”] } 要全功能就开 full,后续想精简(比如只要异步 I/O,不要定时器),改改 features 就行。不像其他语言,要么下载整个库(用不上的功能也占空间),要么得自己编译源码切功能。
- 零配置 “上手快”不用像 C++ 那样找库文件、配 CMake 路径,也不用像 Java 配 Maven 仓库地址 —— 只要把依赖写进 Cargo.toml,执行 cargo run,Cargo 自动下载、编译、链接,新手不用折腾环境,光看这段代码加完依赖就能跑,门槛极低。
三、核心代码实现与Rust优势分析

内存管理模块实现
这段代码的核心优势,本质是 Rust 的 “内存安全模型” 在发力:它让你能像 C++ 一样精准控制内存(自定义分配、内存复用),又能像 Java 一样不用操心安全问题(编译时校验、自动计数、无数据竞争),没有任何折中 。
下面的这段代码是 Rust 内存管理优势的 “浓缩展示”:核心就是安全、高效、可控,既避开了 C/C++ 手动管理内存的坑,又没有 Java GC 的额外开销,完全贴合大数据实时处理场景的需求,下面结合代码一个个简单解析一下:
- 内存分配 :先看BlockAllocator,实现了 Rust 的GlobalAlloc trait,虽然现在内部还是用系统分配器,但这个框架本身就很有讲究 ——Rust 允许你自定义内存分配逻辑。
/// 自定义内存分配器,用于特定大小的数据块
pub struct BlockAllocator {// 内部使用系统分配器
}unsafe impl GlobalAlloc for BlockAllocator {unsafe fn alloc(&self, layout: Layout) -> *mut u8 {// 可以根据需求实现自定义内存分配策略System.alloc(layout)}unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {System.dealloc(ptr, layout)}
}
- 比如实时处理中,经常要反复创建销毁固定大小的数据块(比如每条日志 128 字节),这时就能在alloc里加策略:提前申请一大块连续内存,自己管理分配和回收,避免系统分配器频繁碎片化(C++ 也能做,但容易漏释放);而且Layout参数会在编译时校验内存布局,比如要分配 8 字节却传了 7 字节,编译直接报错,不会出现 C++ 里 “内存布局错乱导致野指针” 的问题。
- 这种 “可控性” 太重要了 —— 大数据场景下,内存碎片化会越积越严重,最后拖慢处理速度,Rust 让你能按需定制分配逻辑,还不用担心里程碑安全风险。
- 内存池复用: MemoryPool是典型的 “内存复用机制的简单实现”,专门解决实时处理中 高频创建对象,高频释放 导致的性能问题。
/// 内存池结构,用于高效管理固定大小的数据块
pub struct MemoryPool<T> {items: Vec<Option<Arc<T>>>,capacity: usize,
}impl<T> MemoryPool<T> {/// 创建新的内存池pub fn new(capacity: usize) -> Self {Self {items: vec![None; capacity],capacity,}}/// 获取内存池中的项pub fn get(&self, index: usize) -> Option<Arc<T>> {if index < self.capacity {self.items[index].clone()} else {None}}/// 设置内存池中的项pub fn set(&mut self, index: usize, item: Arc<T>) -> Result<(), String> {if index < self.capacity {self.items[index] = Some(item);Ok(())} else {Err("索引超出范围".to_string())}}/// 清理内存池pub fn clear(&mut self) {self.items.clear();self.items.resize(self.capacity, None);}
}- 它初始化时就创建vec![None; capacity],提前占好固定容量的内存,后续要存数据直接用现成的位置,不用每次都向系统申请新内存(比如处理百万条订单数据,不用创建百万个独立对象);clear方法也不是直接清空数组,而是resize回原容量,继续复用之前的内存空间。
- 对比一下:Java 里频繁创建对象会给 GC 添负担,最后触发长时间暂停;C++ 手动写内存池容易出越界、重复释放的错;而 Rust 的MemoryPool靠Vec的安全封装和Option的零成本抽象(Option不额外占内存),既能复用内存提效,又能让编译器帮你校验索引(set方法里index < self.capacity的判断,编译 + 运行双重保障),不会越界访问。
- 共享数据 “零风险”,不用手动加锁或计数:SharedData和MemoryPool里都用了Arc,这是 Rust 的 “原子引用计数智能指针”,核心解决 “多线程安全共享数据” 的问题。
// 安全的共享数据容器
pub struct SharedData<T: Send + Sync> {data: Arc<T>,
}impl<T: Send + Sync> SharedData<T> {pub fn new(data: T) -> Self {Self {data: Arc::new(data),}}pub fn get(&self) -> &T {&self.data}pub fn clone_shared(&self) -> Arc<T> {self.data.clone()}
}
- 比如实时处理中,多个并行任务要读同一份配置数据(比如风控规则),用Arc包裹后,不用像 C++ 那样手动维护引用计数(容易漏减导致内存泄漏),也不用像 Java 那样靠synchronized加锁(影响性能)——Arc会自动计数,多线程克隆只是加计数,数据本身不拷贝(零成本),最后一个引用消失时自动释放内存。
- 更关键的是,SharedData要求T: Send + Sync,这是 Rust 的编译时校验:只有确保数据能安全跨线程共享,才允许编译通过。比如你想共享一个非线程安全的类型,编译器直接拦着,根本不会出现 C++ 里 “多线程写同一数据导致数据错乱” 的坑。
- Rust 零成本抽象:这一点贯穿整个代码:Option没有额外内存开销(编译后和直接存Arc差不多),GlobalAlloc的 trait 实现没有冗余代码,Arc的原子操作开销极低 ——Rust 的 “零成本抽象” 在这里体现得淋漓尽致。
- 简单说:你用了这些方便的封装(内存池、智能指针、自定义分配器),却不会付出额外的性能代价,不像 Java 里的包装类会增加内存占用,也不像 Python 里的动态类型会拖慢速度。
// 安全的共享数据容器
pub struct SharedData<T: Send + Sync> {data: Arc<T>,
}impl<T: Send + Sync> SharedData<T> {pub fn new(data: T) -> Self {Self {data: Arc::new(data),}}pub fn get(&self) -> &T {&self.data}pub fn clone_shared(&self) -> Arc<T> {self.data.clone()}
}
// src/memory.rs
use std::sync::Arc;
use std::alloc::{GlobalAlloc, Layout, System};
use std::ptr::NonNull;/// 自定义内存分配器,用于特定大小的数据块
pub struct BlockAllocator {// 内部使用系统分配器
}unsafe impl GlobalAlloc for BlockAllocator {unsafe fn alloc(&self, layout: Layout) -> *mut u8 {// 可以根据需求实现自定义内存分配策略System.alloc(layout)}unsafe fn dealloc(&self, ptr: *mut u8, layout: Layout) {System.dealloc(ptr, layout)}
}/// 内存池结构,用于高效管理固定大小的数据块
pub struct MemoryPool<T> {items: Vec<Option<Arc<T>>>,capacity: usize,
}impl<T> MemoryPool<T> {/// 创建新的内存池pub fn new(capacity: usize) -> Self {Self {items: vec![None; capacity],capacity,}}/// 获取内存池中的项pub fn get(&self, index: usize) -> Option<Arc<T>> {if index < self.capacity {self.items[index].clone()} else {None}}/// 设置内存池中的项pub fn set(&mut self, index: usize, item: Arc<T>) -> Result<(), String> {if index < self.capacity {self.items[index] = Some(item);Ok(())} else {Err("索引超出范围".to_string())}}/// 清理内存池pub fn clear(&mut self) {self.items.clear();self.items.resize(self.capacity, None);}
}// 安全的共享数据容器
pub struct SharedData<T: Send + Sync> {data: Arc<T>,
}impl<T: Send + Sync> SharedData<T> {pub fn new(data: T) -> Self {Self {data: Arc::new(data),}}pub fn get(&self) -> &T {&self.data}pub fn clone_shared(&self) -> Arc<T> {self.data.clone()}
}
Rust 并发处理,优势实战体现
- 编译时 “锁死” 并发安全:Send + Sync 约束
- 代码里 DataItem trait 有个关键约束:Send + Sync + static,这是 Rust 并发安全的 “第一道防线”,完全是编译时校验,不用等到运行时才踩坑。
/// 数据流项的通用类型
pub trait DataItem: Send + Sync + 'static {/// 将数据项转换为字符串表示fn to_string(&self) -> String;
}
- **Send** 表示类型能安全跨线程转移所有权(比如把数据从数据源线程传到处理线程);
- **Sync** 表示类型能安全被多线程共享读取(比如多个处理任务读同一份数据);
- **static** 保证数据生命周期足够长,不会在跨线程时变成悬垂引用。
- 对比其他语言:Java 靠 synchronized 或 volatile runtime 校验,容易漏加锁导致数据错乱;C++ 全靠程序员手动保证线程安全,一个疏忽就出野指针 (C++程序员应该深有体会) ;而 Rust 直接在编译阶段拦着 —— 如果想给 DataItem 传一个非线程安全的类型(比如 Rc,不是 Arc),编译器直接报错,根本跑不起来。
- 代码里所有跨线程传递的数据(比如 SharedData、map 里的函数 f)都隐含了这个约束,相当于 “编译时就给并发安全买了保险”。
- 无锁共享数据:SharedData + Arc 杜绝内存问题
/// 安全的共享数据容器
pub struct SharedData<T: Send + Sync> {data: Arc<T>,
}impl<T: Send + Sync> SharedData<T> {pub fn new(data: T) -> Self {Self {data: Arc::new(data),}}pub fn clone_shared(&self) -> Arc<T> {self.data.clone()}
}
- SharedData 封装了 Arc,核心是解决 “多线程安全共享数据” 的痛点,还不用手动加锁或管理引用计数。 比如 SimpleDataSource 启动后,把数据包装成 SharedData 通过通道发送 —— 多个线程克隆 SharedData 时,本质是克隆 Arc 的引用计数(原子操作,开销极低),数据本身不会拷贝,比 Java 里的对象拷贝省内存,也比 C++ 手动维护引用计数(容易漏减导致内存泄漏)安全。
- 而且 Arc 是线程安全的,Rust 只允许 Sync 类型被 Arc 包裹,确保多线程读数据时不会出现 “一边读一边改” 的情况 —— 不用像 Java 那样加 ReentrantLock ,也不用像 C++ 那样写复杂的锁逻辑,编译器直接帮你兜底。
- Rust 通道通信:mpsc 避免数据竞争,不用手动锁
- 代码里用 std::sync::mpsc::channel 实现线程间通信,这是 Rust “用通信代替共享内存” 的并发理念,从根源上减少数据竞争。
- mpsc 是 “多生产者单消费者” 模式:SimpleDataSource 是生产者(发送数据),DataStream 是消费者(接收数 据),map 方法里又新建了一对通道,形成 “生产→处理→消费” 的链路。
- 这种模式下,数据只能从生产者传到消费者,同一时间只有一个消费者处理数据,根本不需要手动加锁 —— 不像 C++ 多线程操作同一个队列容易出现数据竞争,也不像 Java 用 ConcurrentLinkedQueue 还要担心 CAS 冲突。
- 而且通道的 send 和 recv 会优雅处理线程退出:如果接收端断开(比如 DataStream 被销毁),send 会返回错误,线程直接 break 退出,不会出现僵尸线程,比 Java 手动处理 interrupt 省心多了。
- 灵活高效的并发转换:map 方法的线程调度
pub fn map<U: DataItem, F: Fn(SharedData<T>) -> SharedData<U> + Send + Sync + 'static>(self, f: F) -> DataStream<U> {let (sender, receiver) = channel();thread::spawn(move || {let f = Arc::new(f);while let Ok(item) = self.receiver.recv() {let mapped = f(item);if sender.send(mapped).is_err() {break;}}});DataStream::new(receiver)}
- DataStream::map 方法是核心 —— 给数据流加一个处理函数,就能自动开线程并发处理,既灵活又高效。
代码里 thread::spawn 开新线程处理数据,把处理函数 f 用 Arc::new(f) 包裹后共享 ——Arc 确保函数能安全跨线程使用,而且线程是轻量级的,不会像 Java 线程那样占用大量内存,也不会像 Python 那样被 GIL 锁限制(多线程真能跑满 CPU)。
- 处理逻辑很简单:接收数据→应用函数→发送结果,通道出错就退出,整个流程没有冗余的锁开销,延迟极低 —— 适合实时数据处理场景(比如电商订单实时过滤、日志清洗),既能并行提速,又不用操心并发安全。
// src/data_stream.rs
use std::sync::mpsc::{channel, Sender, Receiver};
use std::thread;
use crate::memory::SharedData;/// 数据流项的通用类型
pub trait DataItem: Send + Sync + 'static {/// 将数据项转换为字符串表示fn to_string(&self) -> String;
}/// 泛型数据流结构
pub struct DataStream<T: DataItem> {receiver: Receiver<SharedData<T>>,
}impl<T: DataItem> DataStream<T> {/// 创建新的数据流pub fn new(receiver: Receiver<SharedData<T>>) -> Self {Self {receiver,}}/// 从数据流中读取下一个数据项pub fn next(&self) -> Option<SharedData<T>> {self.receiver.recv().ok()}/// 转换数据流pub fn map<U: DataItem, F: Fn(SharedData<T>) -> SharedData<U> + Send + Sync + 'static>(self, f: F) -> DataStream<U> {let (sender, receiver) = channel();thread::spawn(move || {let f = Arc::new(f);while let Ok(item) = self.receiver.recv() {let mapped = f(item);if sender.send(mapped).is_err() {break;}}});DataStream::new(receiver)}
}/// 数据流源接口
pub trait DataSource<T: DataItem> {/// 开始生成数据fn start(&mut self) -> DataStream<T>;
}/// 简单的数据源实现
pub struct SimpleDataSource<T: DataItem> {items: Vec<T>,index: usize,
}impl<T: DataItem> SimpleDataSource<T> {pub fn new(items: Vec<T>) -> Self {Self {items,index: 0,}}
}impl<T: DataItem> DataSource<T> for SimpleDataSource<T> {fn start(&mut self) -> DataStream<T> {let (sender, receiver) = channel();let items = self.items.clone();thread::spawn(move || {for item in items {let shared_item = SharedData::new(item);if sender.send(shared_item).is_err() {break;}}});DataStream::new(receiver)}
}
- Rust 中 rayon 让多核利用像写单线程一样简单:数据处理逻辑并行化,不用手动创建线程池、拆分任务,Rust 的 rayon 库靠 par_iter() 一行代码就能自动利用多核,还能保证线程安全,性能和安全性双在线。
- F: Send + Sync + `static 约束确保:函数 predicate 能安全跨线程传递(Send)、能被多线程同时调用(Sync)、生命周期足够长('static);
Arc::new(predicate) 把函数包装成原子引用计数指针,多线程共享时不用拷贝函数本身,只需增减引用计数,零成本且安全。- 如果使用其他的语言,比如 Java:想把 lambda 表达式跨线程传,得手动确保它引用的变量是 final,否则容易出并发修改异常;C++ 传递函数对象跨线程,要自己保证没有悬垂引用,风险高。而 Rust 靠约束和 Arc,编译时就确保函数跨线程安全,调用起来不用慌。
// 并行处理数据项items.par_iter().for_each(|item| {let mut result = result_clone.lock().unwrap();aggregator_clone(item.get(), &mut *result);});
- 上面的这一段代码 items.par_iter() 替代了普通的 iter(),
rayon会自动把 items 分成多份,分给不同 CPU 核心并行处理。比如处理 100 万条订单数据求总金额,不用手动写 “拆分成 8 份给 8 个线程” 的逻辑,rayon 直接搞定,实现起来特别简单易懂。
Rust中实现线程安全的函数共享:Arc + 约束确保逻辑跨线程 : 多线程共享处理逻辑(比如过滤条件、聚合规则)时,不用操心 “函数能不能跨线程传”“传过去会不会出问题”,Rust 靠 Arc 和 Send + Sync 约束,编译时就把风险掐死。
pub fn filter<T: DataItem, F: Fn(&T) -> bool + Send + Sync + 'static>(stream: DataStream<T>,predicate: F) -> DataStream<T> {let (sender, receiver) = std::sync::mpsc::channel();let predicate = Arc::new(predicate); // 用Arc共享函数std::thread::spawn(move || { // 跨线程传递函数while let Ok(item) = stream.receiver.recv() {if predicate(item.get()) { // 安全调用共享的函数if sender.send(item).is_err() {break;}}}});DataStream::new(receiver)}
// src/operators.rs
use std::sync::{Arc, Mutex};
use std::collections::HashMap;
use rayon::prelude::*;
use crate::data_stream::{DataStream, DataItem, SharedData};/// 过滤操作符
pub fn filter<T: DataItem, F: Fn(&T) -> bool + Send + Sync + 'static>(stream: DataStream<T>,predicate: F
) -> DataStream<T> {let (sender, receiver) = std::sync::mpsc::channel();let predicate = Arc::new(predicate);std::thread::spawn(move || {while let Ok(item) = stream.receiver.recv() {if predicate(item.get()) {if sender.send(item).is_err() {break;}}}});DataStream::new(receiver)
}/// 聚合操作符
pub fn aggregate<T: DataItem, R: DataItem, F: Fn(&T, &mut R) + Send + Sync + 'static>(stream: DataStream<T>,initial: R,aggregator: F
) -> SharedData<R> {let result = Arc::new(Mutex::new(initial));let aggregator = Arc::new(aggregator);// 收集所有数据项let mut items = Vec::new();while let Some(item) = stream.next() {items.push(item);}// 并行处理数据项let result_clone = Arc::clone(&result);let aggregator_clone = Arc::clone(&aggregator);items.par_iter().for_each(|item| {let mut result = result_clone.lock().unwrap();aggregator_clone(item.get(), &mut *result);});SharedData::new(result.lock().unwrap().clone())
}/// 分组操作符
pub fn group_by<T: DataItem, K: std::hash::Hash + Eq + Send + Sync + 'static, F: Fn(&T) -> K + Send + Sync + 'static>(stream: DataStream<T>,key_extractor: F
) -> HashMap<K, Vec<SharedData<T>>>
{let groups = Arc::new(Mutex::new(HashMap::new()));let key_extractor = Arc::new(key_extractor);// 收集所有数据项let mut items = Vec::new();while let Some(item) = stream.next() {items.push(item);}// 并行分组let groups_clone = Arc::clone(&groups);let key_extractor_clone = Arc::clone(&key_extractor);items.par_iter().for_each(|item| {let key = key_extractor_clone(item.get());let mut groups = groups_clone.lock().unwrap();groups.entry(key).or_insert_with(Vec::new).push(item.clone());});// 返回最终的分组结果groups.lock().unwrap().clone()
}
Rust异步处理与高性能调度
下面项目中这段代码核心实际上就做了两件事:一个 “异步执行引擎”(Executor) 一个 “数据流处理管道构建器”(PipelineBuilder),合起来就能像搭积木一样,轻松拼出复杂的数据流处理逻辑(比如 “读数据→过滤→转换→聚合”)。下来就·跟着代码,将代码拆开看看Rust 的妙处;
一、先看 “执行引擎” Executor:异步任务的协调
- 主要靠 Tokio 的异步 runtime 帮你高效管理任务,不用手动管线程。Tokio Runtime简单说就是 “异步任务的管家”—— 它帮你管理线程池,不用手动创建线程;还能智能调度任务,比如一个任务在等数据(I/O 阻塞)时,就去跑另一个任务,不会浪费 CPU(这就是 Rust 异步的优势:高效利用资源,比 Java 多线程省内存,比 Python 异步快)。
下面是项目中该模块的核心代码:
use tokio::runtime::Runtime;use tokio::task::JoinHandle;use std::sync::Arc;use crate::data_stream::{DataStream, DataItem, SharedData};/// 执行引擎结构:管理异步任务的运行环境pub struct Executor {runtime: Runtime, // Tokio的异步运行时,相当于“任务调度中心”}impl Executor {/// 创建新的执行引擎:初始化Tokio运行时pub fn new() -> Self {Self {runtime: Runtime::new().unwrap(), // 初始化运行时,unwrap()表示“初始化失败就终止”(新手不用纠结,后续可优化错误处理)}}/// 提交独立的异步任务到引擎pub fn submit<F, R>(&self, f: F) -> JoinHandle<R>whereF: std::future::Future<Output = R> + Send + 'static, // 约束任务是异步的(Future)、能跨线程(Send)、生命周期够长('static)R: Send + 'static, // 任务返回值能跨线程{self.runtime.spawn(f) // 把任务交给Tokio运行时,返回“任务句柄”(后续能等任务结束、拿结果)}/// 执行数据流处理管道(专门对接PipelineBuilder的结果)pub async fn execute_pipeline<T: DataItem, F, R>(&self,stream: DataStream<T>,processor: F) -> RwhereF: Fn(DataStream<T>) -> R + Send + 'static,R: Send + 'static,{// spawn_blocking:把“阻塞性任务”放到Tokio的阻塞线程池,不影响其他异步任务let result = tokio::task::spawn_blocking(move || {processor(stream) // 执行我们拼好的处理管道(比如过滤+聚合)}).await;result.unwrap() // 拿到任务结果(unwrap()简化处理,实际项目可加错误判断)}}
Send + 'static 约束 是 Rust 的 “安全保障”:
- Send 确保任务 / 数据能安全跨线程跑(比如把任务交给 Tokio 的线程池),不会出现 “线程不安全” 的错乱;
'static 确保任务 / 数据的生命周期足够长,不会在任务跑一半时突然 “消失”(避免悬垂引用,比 C++ 手动管理内存安全多了)。
spawn_blocking 的妙用
- 如果你的数据处理逻辑是 “阻塞式” 的(比如长时间计算),直接跑会占着异步线程不放。spawn_blocking 会把它放到专门的 “阻塞线程池”,不影响其他异步任务(比如接收新数据)—— 这体现了 Rust 异步的灵活性,不用你手动拆分 “阻塞任务” 和 “非阻塞任务”。
二、管道构 PipelineBuilder
- 能把过滤、转换、聚合这些操作串起来,形成一条完整的处理管道。比如 “读取订单数据流→过滤金额 > 100 的订单→按用户分组→计算每个用户的总消费”,用它就能轻松拼出来。
比如你要做 “过滤 + 聚合”,代码可以这么写:
// 伪代码:创建管道→过滤→聚合
let result = PipelineBuilder::new(order_stream).filter(|order| order.amount > 100) // 过滤大额订单.aggregate(0, |order, total| *total += order.amount); // 求总金额
- 这种写法像 说话一样,不用写一堆嵌套函数,而且每一步的输入输出都由编译器自动校验 —— 比如你在filter后想调用一个只支持U类型的方法,编译器直接报错,不会像 Python 那样运行时才发现 “类型不对”(Rust 类型安全的优势)。
- 类型自动转换,安全不翻车map方法返回的是PipelineBuilder****(新类型),比如把订单流转换成用户消费流后,后续只能调用支持用户消费流的操作 —— 编译器帮你盯紧类型,不会出现 “用订单的方法处理用户数据” 的低级错误,比 Java 的泛型更严格,比 C++ 的模板更安全。
- 复用性拉满,不用重复写代码之前写的filter、aggregate等操作符,在这里直接复用 ——Rust 的模块化和函数抽象让代码不冗余,而且因为是编译时链接,不会有额外性能开销(这就是 Rust “零成本抽象” 的优势:好用又不拖慢速度)。
下面是项目中的核心代码:
/// 构建数据流处理管道:链式调用拼接处理步骤
pub struct PipelineBuilder<T: DataItem> {stream: DataStream<T>, // 存储当前的数据流(每加一个步骤,就更新一次数据流)
}impl<T: DataItem> PipelineBuilder<T> {/// 创建新的管道构建器:传入初始数据流pub fn new(stream: DataStream<T>) -> Self {Self {stream,}}/// 添加过滤操作:只保留满足条件的数据pub fn filter<F: Fn(&T) -> bool + Send + Sync + 'static>(self,predicate: F // 过滤条件(比如“订单金额>100”)) -> Self {// 调用之前写的filter操作符,生成新的过滤后数据流let filtered_stream = super::operators::filter(self.stream, predicate);Self {stream: filtered_stream, // 用新数据流替换旧的,实现“链式拼接”}}/// 添加映射操作:把一种数据转换成另一种(比如订单→用户ID+金额)pub fn map<U: DataItem, F: Fn(SharedData<T>) -> SharedData<U> + Send + Sync + 'static>(self,mapper: F // 转换函数) -> PipelineBuilder<U> { // 注意:返回的是新类型的构建器(U),编译时自动校验类型let mapped_stream = self.stream.map(mapper);PipelineBuilder::new(mapped_stream)}/// 执行聚合操作:把所有数据合并成一个结果(比如求总金额)pub fn aggregate<R: DataItem, F: Fn(&T, &mut R) + Send + Sync + 'static>(self,initial: R, // 初始值(比如总金额初始为0)aggregator: F // 聚合逻辑(比如“把当前订单金额加到总金额上”)) -> SharedData<R> {super::operators::aggregate(self.stream, initial, aggregator)}/// 执行分组操作:按关键字分组(比如按用户ID分组订单)pub fn group_by<K: std::hash::Hash + Eq + Send + Sync + 'static, F: Fn(&T) -> K + Send + Sync + 'static>(self,key_extractor: F // 提取分组关键字的逻辑(比如“从订单里拿用户ID”)) -> std::collections::HashMap<K, Vec<SharedData<T>>>{super::operators::group_by(self.stream, key_extractor)}
}
简单说,这段代码用 Rust 的特性,把 “复杂数据流处理” 变得 “简单、安全、高效”—— 这就是 Rust 在大数据实时计算领域的核心竞争力。
项目主程序
下面这段 main 函数是整个 rust_stream 项目的 “实战演示”—— 用 100 万条测试数据模拟真实数据流,又同步又异步地完成了 “过滤、分组、统计、聚合” 这些大数据常见操作。下面一步步拆着看,既能懂代码逻辑,还能直观感受到 Rust 为啥适合数据处理,新手也能轻松看懂
先整体划重点:main 函数干了 3 件核心事
- 生成测试数据(模拟用户行为事件,比如点击、购买);
- 同步处理:过滤 “购买事件”→ 按用户 ID 分组 → 统计每个用户的消费情况(总事件数、总价值、平均价值);
- 异步处理:计算 “浏览事件” 的总价值,演示 Rust 异步处理的用法。
- 全程没手动管过内存、没写过锁逻辑,却能安全高效地处理百万级数据 —— 这就是 Rust 的魅力~
用 #[derive(Serialize, Deserialize)] 给 UserEvent 加注解,就能直接用 serde_json 转 JSON—— 这是 Rust 的 “derive 宏” 优势,不用像 Java 那样写一堆 get/set 方法,也不用像 Python 那样担心 JSON 解析的类型错误(Rust 编译时会校验字段是否匹配)。
必须实现 DataItem 才能放进数据流,这是 Rust 的 “类型约束” 在起作用 —— 确保所有进数据流的数据都有统一的处。
准备 “数据类型”:UserEvent 和 UserStats
// 定义示例数据类型:模拟用户行为事件(比如电商里的点击、购买)#[derive(Debug, Clone, Serialize, Deserialize)]struct UserEvent {user_id: u64, // 用户IDevent_type: String, // 事件类型(click/purchase/view)timestamp: u64, // 时间戳value: f64, // 事件价值(比如购买金额、浏览权重)}// 实现 DataItem 特征:让 UserEvent 能放进数据流里处理impl DataItem for UserEvent {fn to_string(&self) -> String {serde_json::to_string(self).unwrap() // 转成JSON字符串,方便打印/传输}}// 定义统计结果类型:存每个用户的消费统计#[derive(Debug, Clone, Default)]struct UserStats {total_events: u64, // 总购买次数total_value: f64, // 总消费金额avg_value: f64, // 平均消费金额}// 实现 DataItem 特征:统计结果也能当数据流项处理impl DataItem for UserStats {fn to_string(&self) -> String {format!("总事件数: {}, 总价值: {}, 平均价值: {}", self.total_events, self.total_value, self.avg_value)}}
- filter 之后接 group_by,像说话一样 “先过滤再分组”—— 这是 Rust 的 “链式调用 + 零成本抽象”,看着像高级语法糖,实际编译后没有额外性能开销,比 Java 的 Stream API 更快,比 Python 的列表推导式更安全。
分组后遍历数据时,不用担心里程碑安全:event 是 SharedData 类型,内部用 Arc 管理,多线程访问也不会错乱,而且不用手动释放内存(Rust 自动回收)—— 不像 C++ 那样怕内存泄漏,也不像 Java 那样担心并发修改异常。
处理 100 万条数据耗时极短:Rust 没有 GC 拖后腿,group_by 里用了 rayon 并行处理,自动利用多核 CPU,比单线程处理快好几倍,还不用手动写线程池(新手也能轻松实现并行)。
同步处理管道:过滤→分组→统计(核心操作)
// 步骤1:过滤出“purchase”(购买)事件;步骤2:按 user_id 分组let groups = pipeline.filter(|event| event.event_type == "purchase") // 只留购买事件.group_by(|event| event.user_id); // 按用户ID分组,得到 HashMap<用户ID, 该用户的所有购买事件>// 统计每个用户的购买情况let mut user_stats = Vec::new();for (user_id, events) in groups {let mut stats = UserStats::default(); // 用默认值初始化统计结果// 遍历该用户的所有购买事件,累加统计for event in events {stats.total_events += 1;stats.total_value += event.get().value; // event是SharedData,get()安全获取内部数据}// 计算平均价值(避免除以0)if stats.total_events > 0 {stats.avg_value = stats.total_value / stats.total_events as f64;user_stats.push((user_id, stats));}}// 按平均价值排序,取前10名高价值用户user_stats.sort_by(|a, b| b.1.avg_value.partial_cmp(&a.1.avg_value).unwrap());
四,总结
通过RustStream项目的实现和分析,我们可以看到Rust语言在数据处理领域的独特优势,对于开发者而言,掌握Rust意味着掌握了一种能够在多个领域发挥作用的强大工具,特别是在需要同时兼顾性能、安全性和可靠性的数据处理场景中。Rust不仅仅是一种新的编程语言,更是数据处理技术的一次革新。
想了解更多关于Rust语言的知识及应用,可前往华为开放原子旋武开源社(https://xuanwu.openatom.cn/),了解更多资讯~