Agentic RL 如何让语⾔ 模型成为⾃主智能体
简介
Agentic RL 是强化学习的一种扩展,旨在通过与外部世界(如搜索引擎、代码解释器、数据库等)的闭环交互,使大语言模型(LLM)具备自主规划、决策、工具使用和环境交互能力。通过多轮强化学习,Agentic RL 能减少对提示的依赖,并增强模型在复杂任务中的自适应与探索能力。
与传统强化学习方法不同,Agentic RL 强调智能体的自主决策和内在目标驱动,能主动优化学习路径,提升在复杂动态环境中的表现。它在多个领域(如自动驾驶、智能制造、金融交易)具有广泛应用,尤其适用于需要快速适应变化的场景。
其核心价值主要体现在两方面:
- 减少提示依赖: 让模型摆脱对 prompt 的过度依赖,具备自适应问题求解能力;
- 强化自主探索: 借助多轮强化学习,提升探索与推理能力,从而弥补静态数据分布稀疏或重复带来的不足。

Agentic RL 优缺点 🛠️
🌟 Agentic RL 优点
- 通过 tool 交互获取外部知识,进一步提升模型准确率。
- PPO 系列是一个 online-rl 方法,需要的数据量小很多,而传统 DPO 需要大量数据进行训练。
- 每次通过 sampling 生成样本,然后进行训练提升。
⚠️ Agentic RL 缺点
- 真正复杂任务可能需要 30-100 个 step 才能完成,目前 RL 框架集中解决 10 个 step 左右就能完成的任务,距离真正解决复杂问题仍有一段距离。
- 受限于 LLM 处理长序列效果下降、计算效率低等原因。
GRPO rule-based 方法虽已简化流程,仍需要标注数据、精心设计 reward、调参及数据,才能得到好效果。 - RL 依赖环境训练,一般速度较慢(仿真环境),如何跟上 GPU 计算 RL 训练,仍是一个问题。
- Agentic RL 研究单一工具居多(code, web-search),而多工具混合、多轮调用研究较少。
Agentic RL 与 LLM-RL
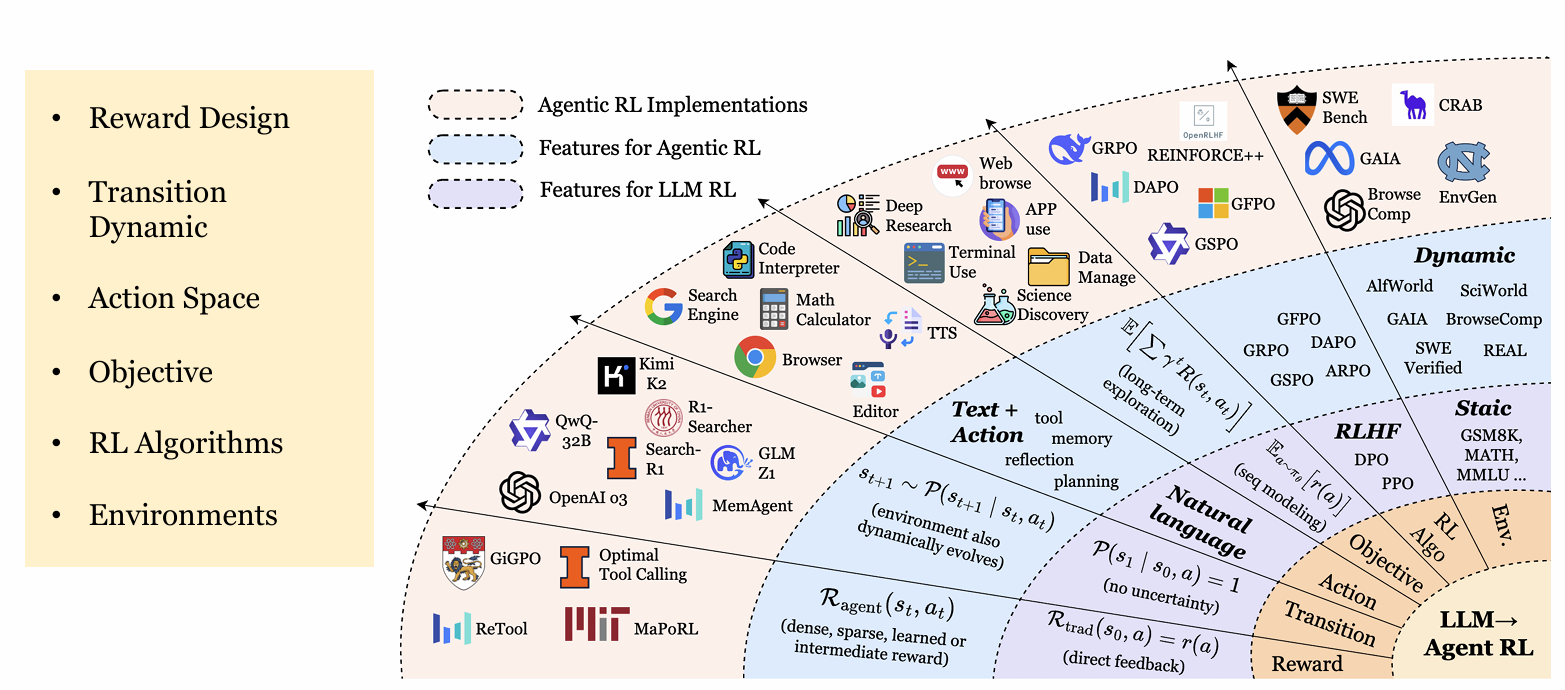
传统的 LLM-RL,特别是基于人类偏好的强化微调(Preference-Based Reinforcement Finetuning, PBRFT),核心目标是对齐(Alignment),即使模型的单次输出更符合人类的价值观或偏好。
与之不同,Agentic RL 的核心目标是决策(Decision-making)。它致力于优化 LLM 在一系列连续交互中执行复杂任务的能力。以 RLHF 为代表的对齐式 LLM-RL 通常被近似为单步(序列级)决策的马尔可夫决策过程(MDP);而 Agentic RL 则在部分可观测环境中进行多步、长时程的决策,更适合用部分可观测马尔可夫决策过程(POMDP)来刻画。
一个MDP可以由元组(S,A,P,R,γ)定义,其中S是状态空间,A是动作空间,P是状态转移概率,R是奖励函数,γ是折扣因子。
传统PBRFT:一个退化的单步MDP
在PBRFT(如经典的RLHF流程)中,决策过程被急剧简化。其MDP可以表示为:
| MDPtrad = (Strad, Atrad, Ptrad, Rtrad, T=1) |
|---|
其特点如下:
- 状态空间(Strad):通常仅包含一个由用户提示(prompt)构成的初始状态s0
- 动作空间(Atrad):动作是生成一个完整的文本序列
- 转移动态(Ptrad):一旦模型生成回应,交互立即终止。因此,时间跨度T=1。这是一个单步决策问题
- 奖励函数(Rtrad):奖励r(a)是对整个生成序列的一次性标量评估,通常由一个预先训练好的奖励模型给出
- 学习目标(Jtrad):最大化单步期望奖励,Jtrad(θ) = Ea ∼ πθ(·)[r(a)]
PBRFT就像回答一道选择题:给定题干(prompt),模型直接给出完整答案(生成文本),然后获得一个最终分数(reward)。整个过程只有一步。
Agentic RL:一个部分可观测的长时程POMDP
Agentic RL的场景则复杂得多,它被建模为一个部分可观测马尔可夫决策过程(Partially Observable MDP, POMDP):
| POMDP = (Sagent, Aagent, Pagent, Ragent, γ, O) |
|---|
其特点如下:
- 状态空间(Sagent):环境状态s是动态变化的,且智能体无法完全观测,只能接收到一个观测ot = O(st)
- 动作空间(Aagent):动作空间是混合的,包含两部分:(Aagent)=Atext ∪ Aaction
- Atext:生成自然语言文本
- Aaction:执行结构化动作,如调用API、使用工具或与环境交互
- 转移动态(Pagent):环境根据智能体的动作随机转移到下一个状态st+1 ~ P(st+1 | st, at),时间跨度T>1
- 奖励函数(Ragent):奖励可以是稀疏的(仅在任务最终完成时给予),也可以是密集的(在每个中间步骤根据进展给予)
- 学习目标(Jagent):最大化长期折扣累积奖励和 J agent ( θ ) = E τ ∼ π θ [ ∑ t = 0 T − 1 γ t R agent ( s t , a t ) ] J_{\text{agent}}(\theta) = \mathbb{E}_{\tau \sim \pi_{\theta}} \left[ \sum_{t=0}^{T-1} \gamma^{t} R_{\text{agent}}(s_t, a_t) \right] Jagent(θ)=Eτ∼πθ[∑t=0T−1γtRagent(st,at)]
下表总结了两者之间的主要差异:
| 特性 | 传统 LLM-RL (如 RLHF) |
|---|