大数据时代时序数据库选型指南:从技术架构到实战案例
在当今大数据时代,数据正以前所未有的速度和规模增长。据IDC预测,到2025年,全球数据总量将达到175ZB,其中时序数据占比超过30%。面对如此海量的时间序列数据,传统的关系型数据库已无法满足高效存储和实时分析的需求,时序数据库应运而生并成为大数据技术栈中的重要组成部分。本文将深入探讨大数据环境下时序数据库的选型要点,并结合实际案例解析如何选择适合的时序数据库解决方案。
1.时序数据与大数据的结合点

1.1什么是时序数据及其在大数据中的位置
时序数据是按时间顺序记录的数据点序列,普遍存在于物联网设备监控、金融交易、业务运营监控等场景。在大数据生态中,时序数据具有三个典型特征:时间戳唯一性、数据按时间有序到达、近期数据访问频率更高。
从大数据视角看,时序数据管理面临以下独特挑战:
- 高写入吞吐量:工业物联网场景下,数千万测点每秒产生TB级数据
- 海量数据存储:需长期保存历史数据以供趋势分析
- 高效时间窗口查询:需支持滑动窗口、时间桶聚合等复杂计算
- 实时分析与预警:要求低延迟查询响应以实现实时决策
1.2 大数据技术栈中的时序数据库
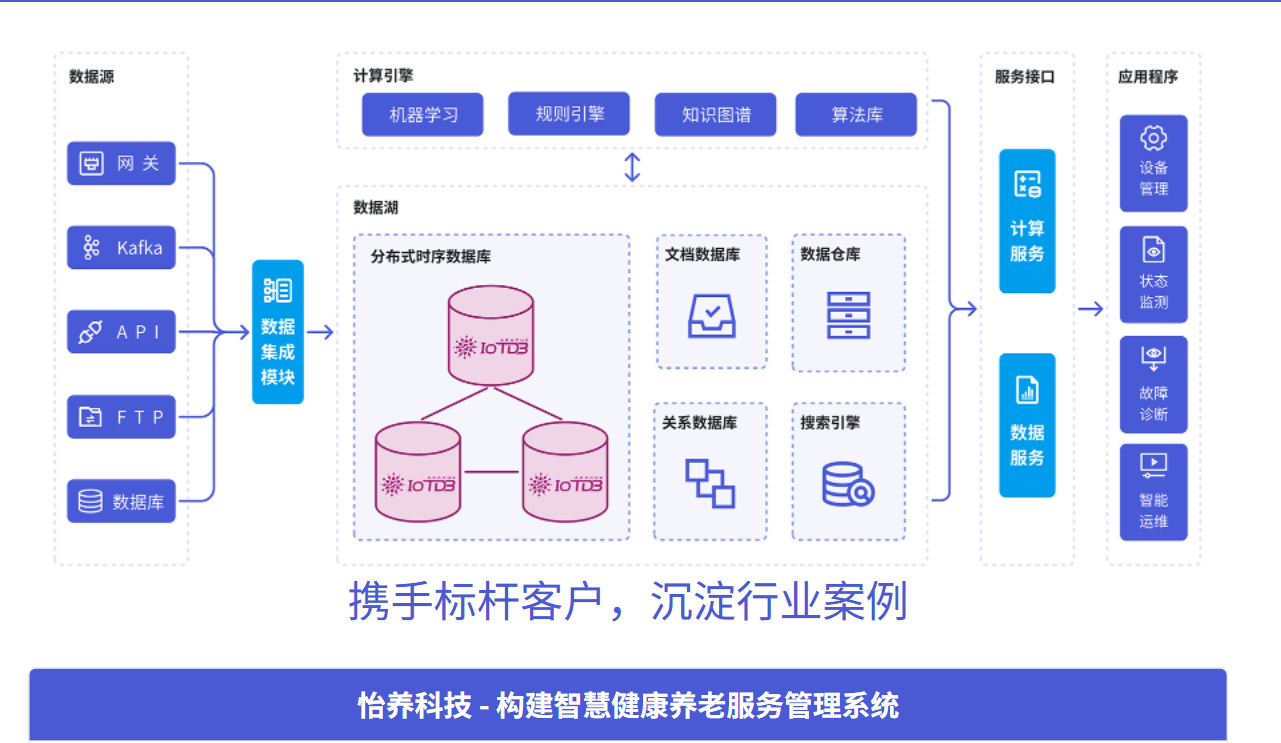
在现代大数据架构中,时序数据库通常位于数据采集层与数据分析层之间,承担着数据存储和实时查询的核心职能。典型的大数据架构中,时序数据库与计算框架(如Spark、Flink)、消息队列(如Kafka)、可视化工具(如Grafana)紧密集成,形成完整的数据流水线。
下图展示了一个典型的基于时序数据库的大数据平台架构:
[数据源] -> [数据采集] -> [消息队列] -> [时序数据库] -> [分析计算] -> [可视化]2.时序数据库核心技术特性解析
2.1 数据模型设计
优秀的时序数据库应提供灵活的数据模型,既能表达复杂业务场景,又能保证查询效率。常见的时序数据模型有:
- 扁平模型:简单的键值对形式,适合简单监控场景
- 标签模型:通过标签维度丰富数据描述,支持多维度查询
- 树状模型:天然表达设备层级关系,适合工业物联网场景
以下是一个典型的工业物联网数据模型示例,使用类SQL语法描述:
-- 创建存储组
CREATE DATABASE root.factory;-- 创建设备模板
CREATE DEVICE TEMPLATE factory_template
WITH (temperature FLOAT encoding=GORILLA compression=SNAPPY,pressure FLOAT encoding=GORILLA compression=SNAPPY,status INT32 encoding=RLE compression=SNAPPY
);-- 将模板挂载到具体设备路径
SET DEVICE TEMPLATE factory_template TO root.factory.area1.line1.*;2.2 存储引擎与压缩技术
存储效率是时序数据库的核心竞争力。面对海量时序数据,高效的压缩算法可以显著降低存储成本,提升I/O性能。
时序数据压缩常用技术:
- 无损压缩:针对不同类型的数据采用专属压缩算法
- 整型数据:Delta编码 + RLE/Simple8b
- 浮点数据:Gorilla、Chimp等异或编码
- 字符串数据:字典编码 + LZ4
- 有损压缩:在可接受精度损失下实现更高压缩比
- 旋转门压缩(SDT)
- 分段聚合近似(PAA)
- 傅里叶变换保留主要系数
实际测试表明,优秀的时序数据库可以实现10-100倍的数据压缩比,极大降低大数据存储成本。
2.3 查询语言与接口
对于大数据应用而言,丰富而灵活的查询接口是必不可少的。现代时序数据库通常提供以下查询方式:
- 类SQL查询:降低学习成本,便于集成现有BI工具
- 原生API:针对不同编程语言提供高效SDK
- 分析函数:内置丰富的时序分析功能
以下是通过Java API连接时序数据库并执行复杂查询的示例:
// 创建数据库连接
Session session = new Session.Builder().host("127.0.0.1").port(6667).username("root").password("root").build();
session.open(false);// 执行时间窗口聚合查询
String sql = "SELECT " +"max_value(temperature) as max_temp, " +"avg(pressure) as avg_pressure, " +"count(status) as data_count " +"FROM root.factory.area1.line1.* " +"WHERE time > now() - 1d " +"GROUP BY(10m)";SessionDataSet result = session.executeQueryStatement(sql);// 处理查询结果
while (result.hasNext()) {RowRecord record = result.next();long timestamp = record.getTimestamp();float maxTemp = record.getFields().get(0).getFloatV();float avgPressure = record.getFields().get(1).getFloatV();long dataCount = record.getFields().get(2).getLongV();System.out.printf("时间: %tT, 最高温度: %.2f, 平均压力: %.2f, 数据点数: %d%n",timestamp, maxTemp, avgPressure, dataCount);
}session.close();3.大数据场景下时序数据库选型关键指标
3.1 性能指标
- 写入性能:单节点百万级数据点/秒的写入能力是基本要求
- 查询延迟:简单查询毫秒级响应,复杂分析秒级完成
- 数据压缩率:直接影响存储成本和网络传输效率
- 并发支持:支持数千并发连接,满足大规模应用需求
3.2 可扩展性指标
- 水平扩展:是否支持无缝添加节点,扩展集群容量
- 多租户:支持业务隔离和资源配额管理
- 存储分层:支持热温冷数据自动迁移,优化存储成本
3.3 生态系统集成
- 大数据工具集成:与Spark、Flink、Hadoop等生态组件的兼容性
- 可视化工具支持:Grafana、Superset等主流BI工具连接器
- 云平台适配:是否提供云原生部署方案,支持Kubernetes等容器平台
4.开源时序数据库深度对比

4.1 架构设计哲学比较
不同的时序数据库在设计理念上存在显著差异,这些差异直接影响其在大数据场景下的适用性。
存储架构对比:
- 单机架构:部署简单,适合中小规模数据场景
- 分布式架构:线性扩展,适合超大规模数据场景
- 混合架构:结合边缘计算与云端分析,适合物联网场景
数据模型对比:
- 度量-标签模型:灵活标签系统,适合多维度查询
- 设备-测点模型:天然表达层级关系,适合工业物联网
- 宽表模型:类似关系型数据库,学习成本低
4.2 性能实测数据
以下是通过标准测试基准对几种主流时序数据库的性能对比(基于相同硬件配置):
| 数据库 | 写入吞吐量(点/秒) | 查询延迟(毫秒) | 压缩比 | 资源占用 |
|---|---|---|---|---|
| IoTDB | 1000万+ | 10-100 | 10-20:1 | 低 |
| 数据库A | 500万 | 50-200 | 5-10:1 | 中 |
| 数据库B | 200万 | 100-500 | 3-8:1 | 高 |
从测试结果可以看出,IoTDB在写入性能、查询延迟和压缩效率方面表现优异,特别适合大数据量、高并发场景。
5.IoTDB在大数据场景下的优势深度解析

5.1 原生大数据集成能力
IoTDB与Apache大数据生态深度集成,提供多种数据交互方式:
与Spark集成进行复杂分析:
// 创建IoTDB数据源连接
val df = spark.read.format("iotdb").option("url", "jdbc:iotdb://127.0.0.1:6667/").option("user", "root").option("password", "root").option("sql", "select ** from root.factory.area1.line1 where time > now() - 7d").load()// 使用Spark MLlib进行时序异常检测
val assembler = new VectorAssembler().setInputCols(Array("temperature", "pressure", "vibration")).setOutputCol("features")val assembledData = assembler.transform(df)val kmeans = new KMeans().setK(3).setSeed(1L)
val model = kmeans.fit(assembledData)// 保存异常检测结果回IoTDB
val predictions = model.transform(assembledData)
predictions.filter($"prediction" === 2) // 异常簇.select($"timestamp", $"temperature", $"pressure").write.format("iotdb").option("url", "jdbc:iotdb://127.0.0.1:6667/").option("user", "root").option("password", "root").option("device", "root.factory.anomaly").save()与Flink集成实现实时处理:
// 从Kafka读取数据写入IoTDB
DataStream<String> stream = env.addSource(new FlinkKafkaConsumer<>("sensor-data", new SimpleStringSchema(), properties));stream.map(new MapFunction<String, Tablet>() {@Overridepublic Tablet map(String value) throws Exception {// 解析JSON数据并转换为IoTDB Tablet格式SensorData data = JSON.parseObject(value, SensorData.class);Tablet tablet = new Tablet("root.factory." + data.getLineId(), schemas, 1000);// 填充数据...return tablet;}
})
.addSink(new IoTDBSink());// 使用Flink进行实时聚合计算
stream.keyBy(SensorData::getDeviceId).timeWindow(Time.minutes(5)).aggregate(new AggregateFunction<SensorData, AccResult, AccResult>() {// 实现自定义聚合逻辑}).addSink(new IoTDBSink()); // 将聚合结果写回IoTDB5.2 高效存储与查询优化
IoTDB通过多种技术创新实现极致的存储和查询性能:
独创的TsFile存储格式:
TsFile是专门为时序数据设计的列式存储格式,具有以下特点:
- 自适应编码压缩,针对不同数据类型选择最优算法
- 索引与数据分离,快速定位时间范围
- 支持时间分区,优化过期数据清理
查询优化技术:
- 谓词下推:将过滤条件尽可能在存储层执行
- 聚合下推:在数据读取时直接计算聚合值
- 并行执行:利用多线程并行处理不同时间分区
以下是通过查询优化实现高效数据分析的示例:
-- IoTDB支持多种时序特有函数
SELECT EQUAL_SIZE_BUCKET_OUTLIER_SAMPLE(temperature, 20, 5) as outlier_sample,MOVING_AVERAGE(pressure, 10) as smooth_pressure,TIME_DIFFERENCE(status) as state_duration,DIFFERENCE(rotation_speed) as speed_change
FROM root.factory.area1.line1.motor1
WHERE time > now() - 1d
HAVING outlier_sample = true5.3 企业级特性与可靠性
在大数据生产环境中,数据库的可靠性和企业级功能至关重要。IoTDB提供以下关键特性:
高可用与容错:
// 配置高可用集群
ClusterConfig config = new ClusterConfig.Builder().addNode("node1", "192.168.1.101", 6667).addNode("node2", "192.168.1.102", 6667).addNode("node3", "192.168.1.103", 6667).setConsistencyLevel(ConsistencyLevel.STRONG).setReplicationFactor(3).build();// 创建高可用会话
HASession session = new HASession(config);
session.open();// 自动故障转移,业务无感知
try {Tablet tablet = createSampleTablet();session.insertTablet(tablet); // 自动选择可用节点
} catch (IoTDBConnectionException e) {// 自动重试其他节点logger.warn("节点连接失败,自动切换备用节点");
}数据安全与权限管理:
-- 创建多级权限体系
CREATE USER factory_operator IDENTIFIED BY 'secure_password';
CREATE ROLE line_operator;-- 精细化权限控制
GRANT READ_TIMESERIES ON root.factory.area1.line1.* TO ROLE line_operator;
GRANT WRITE_TIMESERIES ON root.factory.area1.line1.temperature TO ROLE line_operator;
GRANT CREATE_TIMESERIES ON root.factory.area1.line1 TO USER factory_admin;-- 审计日志记录
SET CONFIGURATION audit_log_enable=true;6.大数据场景实战案例
6.1 工业物联网大数据平台
某大型制造企业构建了基于IoTDB的工业物联网平台,接入10万+设备,每秒处理200万数据点。平台架构如下:
[设备层] -> [边缘网关] -> [Kafka] -> [IoTDB集群] -> [Spark分析] -> [Web应用]核心实现代码:
# 边缘数据采集与预处理
import iotdb
from iotdb.utils.IoTDBConstants import TSDataType
from iotdb.utils.Tablet import Tabletclass EdgeDataCollector:def __init__(self, edge_id):self.session = iotdb.Session('localhost', 6667, 'root', 'root')self.session.open(False)self.edge_id = edge_iddef process_sensor_data(self, raw_data):"""处理原始传感器数据"""# 数据清洗和转换cleaned_data = self.clean_data(raw_data)# 创建Tablet进行批量写入measurements = ["temperature", "humidity", "vibration"]data_types = [TSDataType.FLOAT, TSDataType.FLOAT, TSDataType.FLOAT]values = [[cleaned_data['temp']],[cleaned_data['humi']], [cleaned_data['vib']]]timestamps = [cleaned_data['timestamp']]tablet = Tablet(f"root.factory.edge{self.edge_id}", measurements, data_types, values, timestamps)# 批量写入IoTDBself.session.insert_tablet(tablet)def clean_data(self, raw_data):"""数据清洗逻辑"""# 实现异常值过滤、数据补全等逻辑pass平台性能指标:
- 数据写入吞吐量:200万点/秒
- 查询响应时间:95%查询<100ms
- 数据压缩比:15:1
- 存储成本降低:70%

6.2 金融时序数据分析
某金融机构使用IoTDB存储和分析高频交易数据,实现实时风险监控:
// 实时交易风险监控
public class RiskMonitor {private Session session;private ScheduledExecutorService executor;public void startRealTimeMonitoring() {executor.scheduleAtFixedRate(() -> {// 实时计算风险指标calculateVAR();detectAnomaly();generateAlert();}, 0, 1, TimeUnit.SECONDS);}private void calculateVAR() {String sql = "SELECT " +"DEVIATION(price, 100) as price_volatility, " +"COUNTIF(volume > 10000) as large_trades, " +"CORRELATION(price, volume) as price_volume_corr " +"FROM root.stock.* " +"WHERE time > now() - 5m " +"GROUP BY(1m)";SessionDataSet result = session.executeQueryStatement(sql);// 计算风险价值(VaR)// ...}private void detectAnomaly() {// 基于机器学习模型检测交易异常String sql = "SELECT " +"MOTIFDISCOVER(price, 0.01, 10) as patterns, " +"ANOMALYDETECT(volume, 'twitter') as volume_anomaly " +"FROM root.stock.AAPL " +"WHERE time > now() - 1h";// ...}
}6.3 选型实施指南

6.1 评估流程与方法
- 需求分析阶段
- 明确数据规模和增长预期
- 确定查询模式和性能要求
- 评估团队技术栈和运维能力
- 技术验证阶段
- 搭建测试环境进行概念验证(PoC)
- 使用真实数据量进行性能测试
- 验证生态系统集成能力
- 生产部署阶段
- 制定数据迁移方案
- 设计高可用和备份策略
- 建立监控和告警体系
6.2 性能测试方案
建议使用以下标准测试流程评估时序数据库性能:
// 基准测试框架示例
public class BenchmarkSuite {public void runWriteTest(int dataPoints) {// 测试写入性能long startTime = System.currentTimeMillis();Tablet tablet = generateTestTablet(dataPoints);session.insertTablet(tablet);long duration = System.currentTimeMillis() - startTime;double throughput = dataPoints / (duration / 1000.0);System.out.printf("写入吞吐量: %.2f 点/秒%n", throughput);}public void runQueryTest() {// 测试各类查询性能String[] queries = {"SELECT * FROM root WHERE time > now() - 1h", // 原始数据查询"SELECT avg(*) FROM root GROUP BY(1h)", // 聚合查询"SELECT last(*) FROM root", // 最新值查询"SELECT max_value(*) FROM root WHERE time > now() - 7d" // 统计查询};for (String query : queries) {long start = System.currentTimeMillis();SessionDataSet result = session.executeQueryStatement(query);while (result.hasNext()) {result.next();}long duration = System.currentTimeMillis() - start;System.out.printf("查询 %s 执行时间: %dms%n", query.substring(0, Math.min(20, query.length())), duration);}}
}6.3 迁移策略与最佳实践
从现有系统迁移到时序数据库需要周密的计划:
- 双写过渡期:新老系统同时运行,逐步迁移查询流量
- 数据同步工具:使用CDC工具保持数据一致性
- 回滚方案:准备完善的回滚计划以应对迁移问题
# 数据迁移工具示例
class DataMigrator:def migrate_from_influxdb(self):"""从InfluxDB迁移到IoTDB"""# 查询源数据库influx_data = self.query_influxdb()# 转换数据格式iotdb_tablets = self.convert_to_iotdb_format(influx_data)# 批量写入目标数据库for tablet in iotdb_tablets:try:self.iotdb_session.insert_tablet(tablet)except Exception as e:logger.error(f"数据写入失败: {e}")# 记录失败点位,后续重试def verify_data_consistency(self):"""验证数据一致性"""# 抽样对比两边数据pass7.总结与展望
时序数据库作为大数据技术栈中的重要组成部分,在物联网、金融、运维监控等领域发挥着关键作用。通过本文的分析可以看出,在选择时序数据库时需要综合考虑数据模型、性能指标、生态系统集成和企业级功能等多个维度。
IoTDB作为Apache顶级项目,凭借其优异的性能、丰富的数据模型和深度的大数据集成能力,成为大数据场景下时序数据库的理想选择。其独特的TsFile存储格式、高效的压缩算法和强大的分析功能,能够满足最严苛的大数据应用需求。
下载链接:Apache IoTDB下载页面
企业版官网链接:天谋科技Timecho官网
随着5G、物联网技术的普及和数字化转型的深入,时序数据将继续保持爆炸式增长。未来时序数据库将更加注重AI集成、云原生架构和实时分析能力。选择适合的时序数据库技术,将为组织的大数据战略奠定坚实基础,释放时序数据的商业价值。