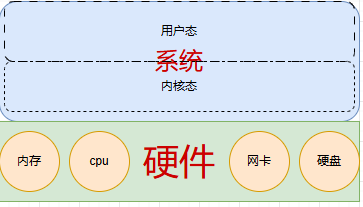
单机并发简介
一、简介
高性能我们首先需要从哪里了解了,当然是从单机开始了解,我们需要大概了解单机的性能,才能知道一个上百万乃至上千万的并发连接需要平摊到多少单机。
单机高性能不是单纯的堆积硬件,而是系统架构、硬件能力、内核机制、应用模型协同演进的结果。
二、单机性能瓶颈
在 2000 年代初,Web 服务开始兴起,但传统 Unix 网络编程模型(如每个连接一个线程/进程)无法支撑上万并发连接,所有有人提出了C10K,就是单机如何做到1w连接,包含如下选择。
1、进程线程调度
- 每个线程/进程占用大量内存(默认栈空间 2MB)
- 上下文切换开销巨大
- 文件描述符数量受限(默认 1024)
- 内核态与用户态频繁切换:每次 read/write 都要陷入内核
- I/O 多路复用效率低:select/poll 是 O(n) 扫描所有 fd,且每次调用都要复制整个 fd 集合到内核
- 连接管理开销大:每个 TCP 连接占用内核资源(socket buffer、TCP 控制块等)
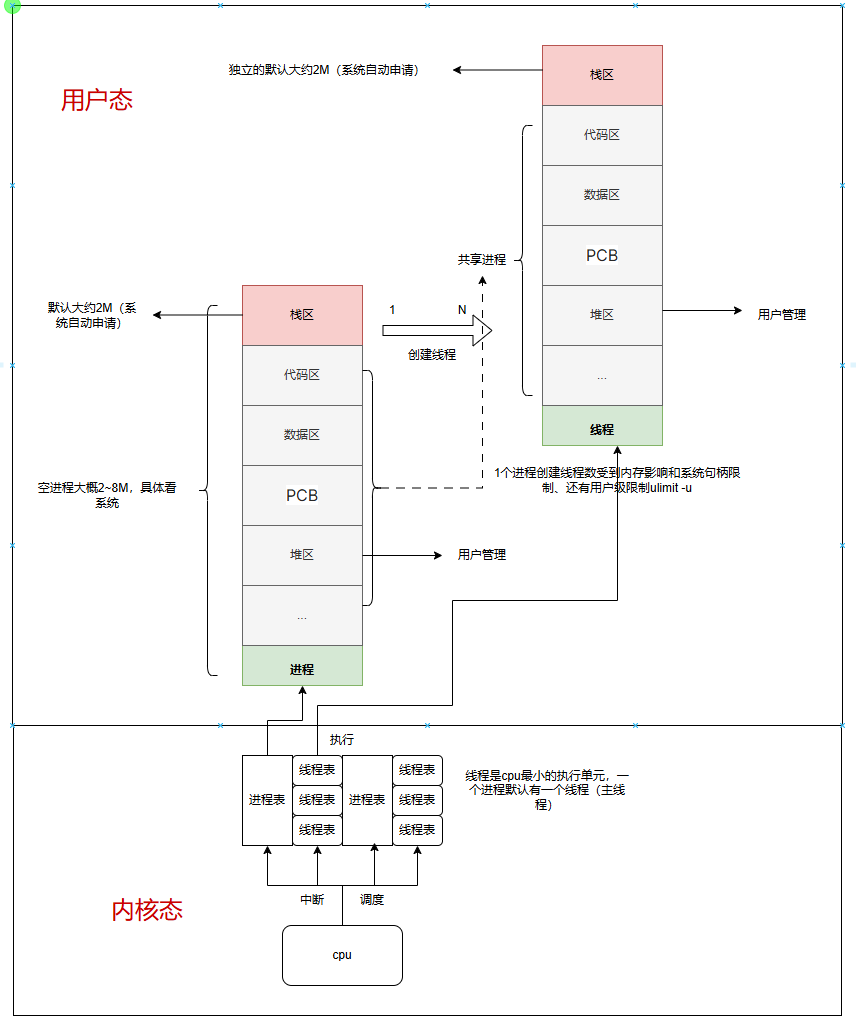
线程调度图,每个线程都是cpu最小的一个执行单位,现在多核cpu可以同时执行多个线程。
但是线程过多cpu每次调度都需要中断来请求,而且很多寄存器的的数据需要存储切换,那么这里就带来了时间成本(硬件和软件调度时间、中断时间)。
- I/O 密集型:少量线程 + 异步 I/O(如 Node.js、Nginx)
- CPU 密集型:线程数 ≈ CPU 核数(避免过多上下文切换)
2、内存
每一个进程开一个线程默认的堆栈就需要申请大约2M,不考虑申请的内容和其他代码区,有些系统可以达到8M虚拟内存,那么如果一台内存32G的电脑最多只能开16,384个线程(理论值,当然还有系统及应用还占了大部分内存)。当然系统可以把栈设为64kb或者128kb,那么理论上线程可以翻倍,但是同样数量一多那么cpu调度时间也翻倍(这里不考虑),如果64kb大概可以有524,288个线程(理论值内存都给他)。
3、文件描述符
linux的一切对象都是文件,那么每一个线程一个连接都是文件,之前的linux限制1024,现在的linux文件描述符可以直接更改到1048576之下,这个值受nr_open限制(单个进程能设置的最大 FD 数(无论软 / 硬限制))可以打开上百万的文件已经够用了。
高并发针对线程和进程及文件描述符的限制就是上面这些,这些都可以通过增加内存、扩大描述符解决,但是还有一个就是之前都是select/poll这种模式,如果数量一盘大那么搜索效率极低。
4、网络请求
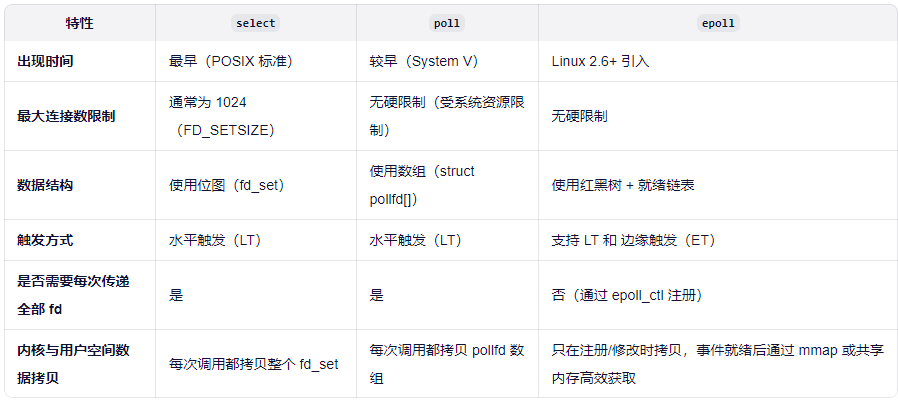
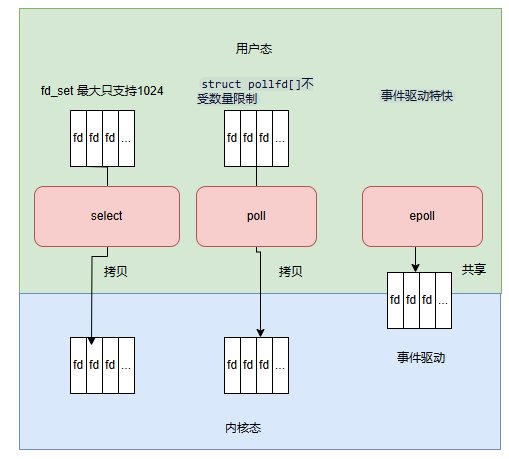
- select:每次获取接收信息都得通过内核态拷贝到用户态,然后再循环找到所有的文件描述符看是哪个,时间复杂度这里就是O(n)了,越大时间越慢,而且还受文件描述符的限制默认只有1024个。极端情况并发那么每个查询那么就得nxn。
- poll:可以传入一个FD数组到内核,没有文件描述符限制了,但是有事件过来还是得一个一个文件描述符来遍历,所以时间复杂度还是O(n),只是不需要没有文件描述符1024的限制了。
- epoll:采用了事件驱动模式,FD文件描述符直接内核态和用户态共享,减少了内核用户传递的拷贝,而且基于事件驱动就是没来一个事件只有这个FD返回回调,那么用户可以直接拿这个FD进行使用不需要遍历数组,所以时间复杂度为O(1),这样解决了这个内核应用切换拷贝问题和描述符轮询问题。
具体如下:
5、磁盘io
硬盘 I/O 对单机并发性能有显著影响,尤其是在高并发服务(如 Web 服务器、数据库、消息队列等)中。虽然网络 I/O 和 CPU 常被首先关注,但磁盘 I/O 往往成为系统瓶颈的“隐形杀手”。
- 在同步 I/O 模型中(如传统阻塞 read/write),一个线程发起磁盘读写后会阻塞等待完成。
- 如果有大量并发请求需要读写磁盘(如日志写入、静态文件服务、数据库查询),线程池可能被耗尽,新请求无法处理。
- 机械硬盘(HDD):随机访问延迟约 5–15 ms(受限于磁头寻道 + 旋转延迟)。
- 固态硬盘(SSD):延迟低至 0.1 ms 以下,但仍有上限。
- 相比之下,内存访问是纳秒级(~100 ns),CPU 处理更是极快。
- 即使是 NVMe SSD,顺序读写带宽通常在 1–7 GB/s。
- 若并发请求大量读写大文件(如视频、备份),可能打满磁盘带宽,导致其他 I/O 请求排队。
6、网络协议:
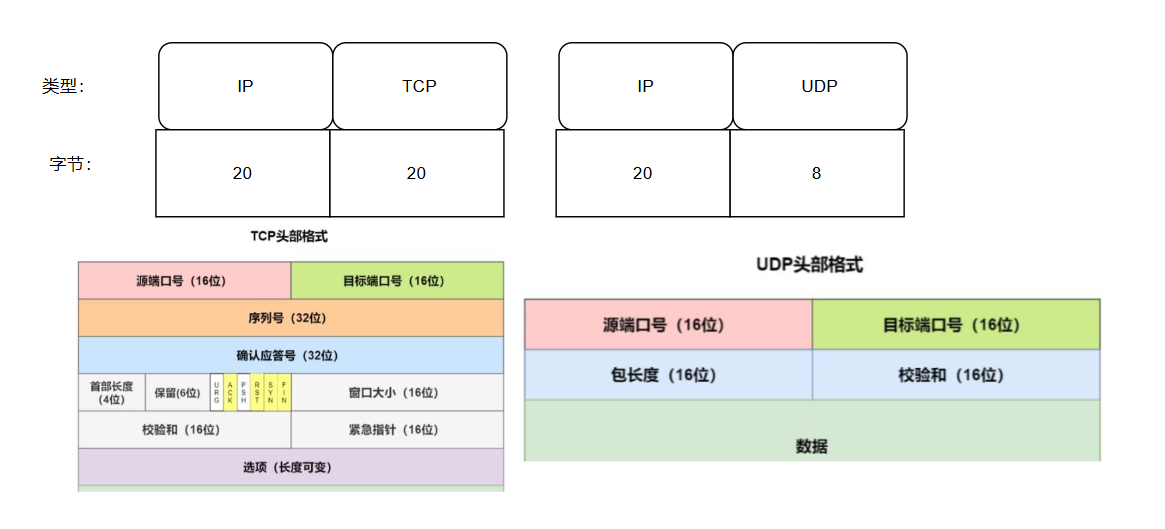
网络传输过来也需要内存:tcp固定是40字节、udp是28个字节,所以这个就看带宽了。
从上面分析我们就知道需要让单机发挥性能,需要从网络、cpu调度、内存、文件描述符、网络请求这些方面。
三、优化整理:
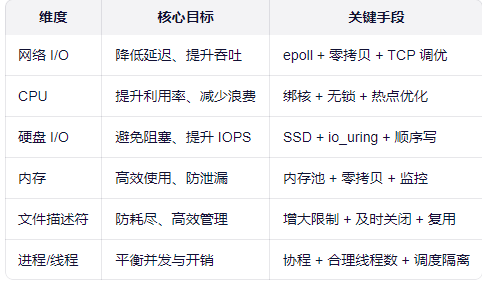
让 CPU 忙于计算,而非等待 I/O;让资源用在刀刃上,而非浪费在切换与拷贝。
根据预估并发值(当然抛开业务架构、带宽、网卡这些来谈并发,完全是耍流氓,只是让人知道有哪些会影响并发的)
| 配置 | 内存限制(连接数) | CPU 限制(QPS) | 典型并发连接数(长连接) | 典型 QPS(短连接/API) | 适用场景 |
|---|---|---|---|---|---|
| 4核8GB | ≈ 50万~80万 (每个连接约 10–16KB 内存) | ≈ 5k–15k QPS (轻量请求) | 30万 ~ 60万 | 8k ~ 20k | 中小 Web 服务、API 网关 |
| 4核16GB | ≈ 100万~150万 | ≈ 5k–15k QPS (CPU 成瓶颈) | 80万 ~ 120万 | 8k ~ 20k | 高连接数 IM、推送服务 |
| 8核16GB | ≈ 100万~150万 | ≈ 15k–40k QPS (CPU 翻倍) | 80万 ~ 130万 | 20k ~ 50k | 高吞吐 API、游戏服务器 |
| 4核32GB | ≈ 200万~250万 | ≈ 5k–15k QPS (CPU 仍是瓶颈) | 150万 ~ 200万 | 8k ~ 20k | 超高连接数(如 IoT 设备接入) |
| 8核32GB | ≈ 200万~250万 | ≈ 30k–80k QPS (CPU+内存均衡) | 150万 ~ 220万 | 40k ~ 100k+ | 高并发网关、实时通信平台 |
1. 内存 vs 并发连接数
- 每个空闲 TCP 连接在内核中约占用 3–8KB(
struct sock+ 缓冲区) - 应用层若保存连接上下文(如 session),通常再占 5–10KB
- 保守估计:每个连接 ≈ 10–16KB
- 8GB 可用内存 ≈ 6GB 用户态 → 支持 ~60万连接
- 16GB → ~120万连接
- 32GB → ~200万+ 连接
2. CPU vs QPS(请求处理能力)
- 轻量 API(JSON 解析 + 简单逻辑):
- 每请求 CPU 消耗 ≈ 0.1 ~ 0.5 ms
- 4核 ≈ 4000 ms/s ÷ 0.3 ms ≈ 13k QPS
- 8核 ≈ 25k~50k QPS
- 若含加密(TLS)、数据库访问、日志写入,QPS 下降 30%~70%
3. 瓶颈分析(统计正常还得看cpu的主频也跟速率有关)
| 配置 | 主要瓶颈 |
|---|---|
| 4核8G | 内存 & CPU 均受限 |
| 4核16G / 4核32G | CPU 是瓶颈(连接数高但处理不过来) |
| 8核16G | 内存可能限制连接数,CPU 支撑高 QPS |
| 8核32G | 最均衡,适合高连接 + 高吞吐 |
单机高性能并非单纯依赖硬件堆砌,而是网络模型、CPU调度、内存管理、文件描述符限制、磁盘I/O与协议栈协同优化的系统工程。从C10K到C10M的演进,核心在于用事件驱动(如epoll)替代线程/进程模型,以异步非阻塞I/O减少资源浪费,并通过合理配置突破内核与硬件的天然瓶颈。在典型优化场景下,一台8核32GB的现代服务器已可稳定支撑百万级长连接与十万级QPS,成为构建高并发分布式系统的坚实基石。因此,理解并驾驭单机性能边界,是设计可扩展、高可用架构的第一步。
根据上述来说,其实单机性能已经可以支持足够的连接数,但是qps那得根据具体的应用比如(nginx、tomcat、redis、日志、mq、数据库等),撇开业务谈并发量那是空谈。