基于中国深圳无桩共享单车数据的出行目的推断与时空活动模式挖掘
基于中国深圳无桩共享单车数据的出行目的推断与时空活动模式挖掘
本文聚焦中国深圳无桩共享单车出行数据,通过构建多因素融合的推断框架,解决了“个体骑行目的识别”这一核心问题,并基于结果揭示了骑行时空模式,为城市交通规划与单车管理提供科学依据。以下按章节展开详细解读:
参考原文:Inferring the trip purposes and uncovering spatio-temporal activity patterns from dockless shared bike dataset in Shenzhen, China
1. 引言(Introduction)
本章通过梳理共享单车研究背景、现有缺口,明确研究目标与意义,为全文构建逻辑起点。
1.1 共享单车的价值与发展现状
- 共享单车的定位:被定义为“低成本、低排放、便捷”的交通方式,核心价值包括:替代短途机动车出行、衔接公共交通(如解决“最后一公里”)、减少噪音与空气污染,同时能增加居民体力活动、支持休闲出行,带来健康效益。
- 两类共享单车模式对比:
- 传统有桩模式:1965年阿姆斯特丹首次推出,需在固定站点租还,灵活性低。
- 无桩模式:2016年中国率先推出,依托互联网技术实现“授权区域内自由停放”,凭借高可达性、便捷停车与支付优势,快速取代有桩模式,成为全球主流。
- 深圳的典型性:作为中国高度城市化的 metropolis,2018年已有8条地铁线路、854条公交线路,无桩共享单车日均使用量达65万次,其骑行行为能反映城市交通特征,是理想研究区域。
1.2 现有研究的核心缺口
文章指出,当前无桩共享单车研究存在三大关键局限:
- 数据依赖问题:早期研究多依赖“出行调查数据”,存在成本高、样本量有限、数据质量差(如记忆偏差)、仅记录单日出行等缺陷,难以反映出行行为的时间动态性。
- GPS数据的语义缺失:虽有研究用GPS轨迹数据(如手机、智能卡、出租车轨迹)分析骑行特征,但GPS数据仅记录“位置-时间”,缺乏“出行目的”这类语义信息,无法区分“通勤”“购物”“就医”等行为。
- 推断模型的因素遗漏:少数尝试推断骑行目的的研究(如Xie and Wang, 2018;Li et al., 2020a)存在不足:前者仅将目的分为“休闲”和“实用(通勤为主)”,无法细分;后者虽用POI(兴趣点)数据,但忽略POI吸引力(如与落点距离);Xing et al. (2020) 用聚类方法,但未考虑POI服务容量、时间因素,且无法识别“教育”“医疗”等重要目的。
1.3 本文研究目标与创新
- 核心目标:提出一个基于“重力模型+贝叶斯规则”的框架,实现无桩共享单车个体骑行目的的精准推断,并揭示其时空活动模式。
- 关键创新:
- 整合“距离、时间、环境、POI类型占比、POI服务容量”五大因素,其中后两者是现有研究普遍遗漏的;
- 引入AOI(兴趣面)和TUD(腾讯用户密度)数据,量化POI服务容量,反映不同POI的规模差异(如地铁 station vs 公交站);
- 对比三类模型(基础+改进),验证因素添加对推断效果的提升作用。
2. 案例研究数据(Case Study Data)
本章明确研究区域范围,详细介绍四类核心数据集的来源、处理方法与用途,为后续模型构建提供数据支撑。
2.1 研究区域(Case Study Region)
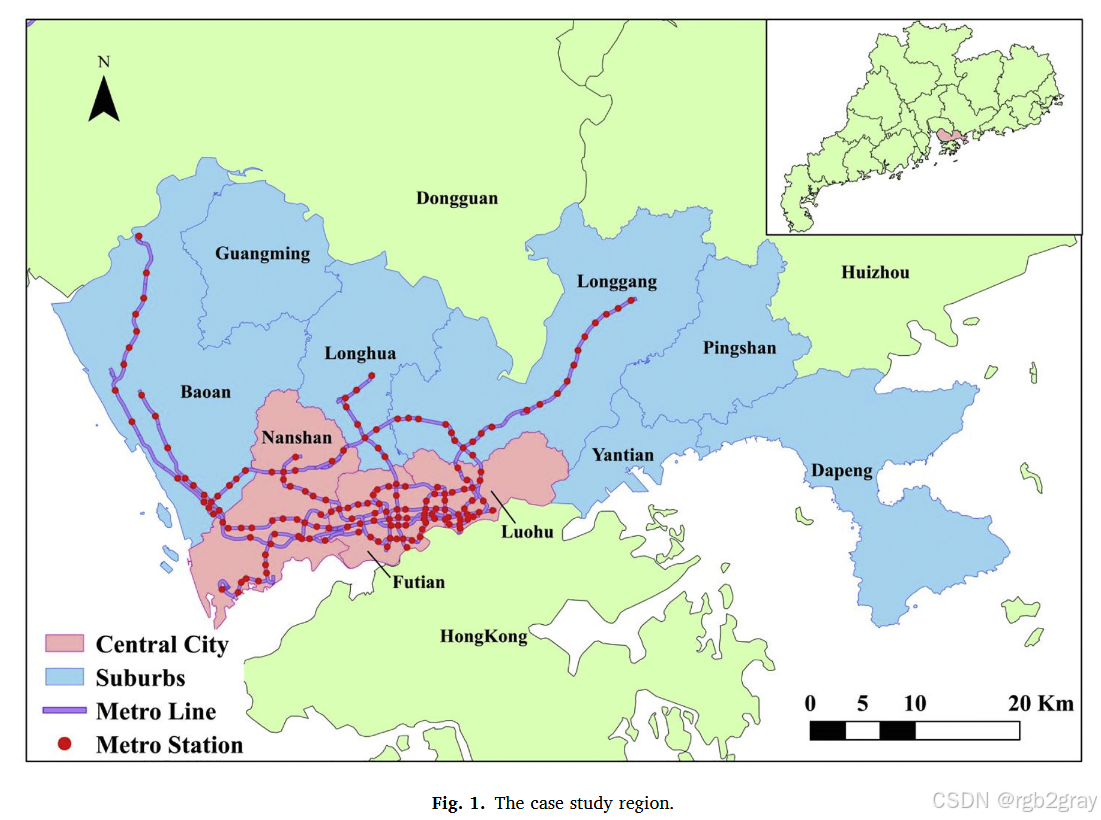
- 空间范围:中国广东省深圳市(图1),进一步划分为“中心城区”和“郊区”:
- 中心城区:南山、福田、罗湖,以商业和住宅用地为主,公共交通密集;
- 郊区:宝安、龙华、龙岗等其他行政区,以工业和住宅用地为主,2018年地铁系统逐步扩展至该区域。
- 选择理由:深圳是无桩共享单车首批试点城市,骑行需求旺盛,且土地利用类型多样(商业、工业、住宅),能反映不同场景下的骑行行为,研究结果具有代表性。
2.2 数据集详情(Datasets)
本文共使用四类数据,均经过严格筛选与处理,具体如下:
2.2.1 无桩共享单车数据
- 来源:深圳多家运营商(摩拜、ofo、Bluegogo、Ubike、小明单车),其中ofo(51.5%)和摩拜(43.2%)占比最高,数据代表性强。
- 时间范围:2018年10月8日-14日(5个工作日+2个周末),覆盖一周完整周期,便于分析时间差异。
- 数据内容:每条记录包含“车辆唯一ID、骑行起点GPS坐标、终点GPS坐标(落点)、骑行开始时间、结束时间”,并按小时分类存储。
- 数据清洗:剔除非真实骑行数据,依据:
- 最短距离:<100米的 trips 视为运营商调运,非用户实际出行;
- 最长距离:97.28%的 trips <3000米,故剔除>3000米的异常数据。
2.2.2 POI(兴趣点)数据
- 来源:互联网数字地图,共374,053个POI。
- 数据属性:每个POI包含“ID、名称、经度、纬度、类别”(如“餐厅”“学校”“地铁站”)。
- 关键处理:基于无桩共享单车“短途出行”特征,将POI按“骑行目的”划分为9类,建立“目的-POI类别”映射关系(表1),例如:
- “家庭”对应“住宅区”POI;
- “工作”对应“写字楼、金融机构、工业园区”等POI;
- “换乘”对应“地铁站、公交站、火车站”等POI;
- 同时为每类POI赋予“服务容量指数”(如地铁站2.00、高校1.00),用于后续模型计算。
2.2.3 AOI(兴趣面)数据
- 定义:与POI(点要素)不同,AOI是“面要素”,能反映地理实体的轮廓和面积(如一个公园的范围、一所大学的占地)。
- 来源:互联网数字地图,分类与POI一致,但补充了POI在“空间范围”上的信息(如POI仅记录地铁站入口,AOI记录整个地铁站区域)。
- 特殊处理:对于地铁、公交站等未被AOI覆盖的交通类POI,以其为中心建立50米半径的缓冲区,作为“等效AOI”,确保数据完整性。
2.2.4 TUD(腾讯用户密度)数据
- 来源:腾讯社交平台(中国最大社交平台),记录用户实时位置。
- 优势:深圳等大城市的腾讯用户覆盖率超93%,能精准反映“人口动态分布”和“区域活力”,是量化POI服务容量的关键数据。
- 用途:通过计算AOI范围内的平均TUD值,衡量POI的“被访问频率”——TUD值越高,说明该POI的服务容量(吸引力)越强(如市中心商场的TUD远高于郊区小超市)。
3. 研究方法(Method)
本章是全文核心,详细阐述“骑行目的推断框架”的流程、关键步骤与三类模型的构建逻辑,解决“如何从数据到目的”的技术问题。
3.1 推断框架概述(Overview of the Inference Framework)
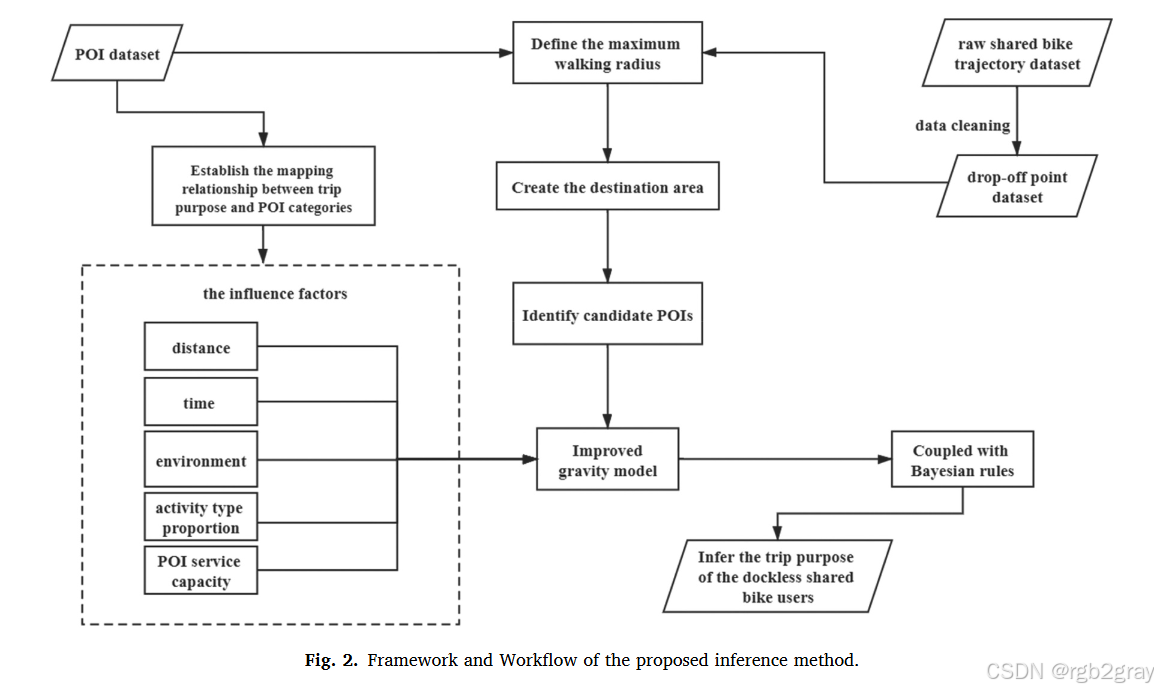
框架流程如图2所示,分为四步,形成闭环:
- 建立映射关系:基于表1,将9类骑行目的(家庭、工作、换乘等)与对应的POI类别关联,明确“目的-POI”对应规则;
- 划定目的地范围:以骑行落点为中心,定义“最大步行半径”,范围内的POI作为“候选POI”(即用户可能前往的目的地);
- 计算POI吸引力:用重力模型(基础/改进),结合距离、时间、环境等因素,计算每个候选POI对用户的吸引力;
- 推断骑行目的:用贝叶斯规则,基于POI吸引力计算用户访问各候选POI的概率,概率最高的POI对应的目的即为“推断结果”。
3.2 目的地范围界定(Destination Areas)
- 核心问题:无桩共享单车的落点并非用户“最终目的地”(如用户在商场附近停车,步行至商场),需确定“落点到目的地的最大步行距离”。
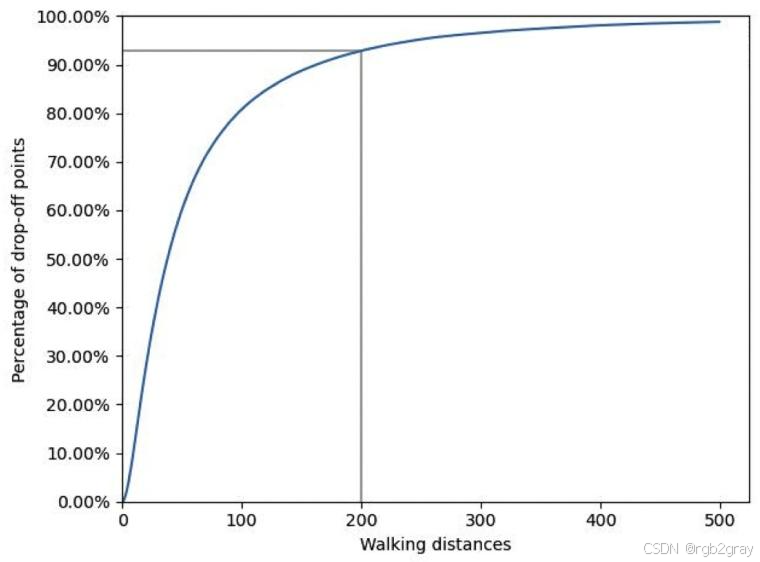
- 确定方法:统计不同步行半径内“存在候选POI的落点占比”(图3),发现:
- 步行半径200米时,92.38%的落点能找到至少1个候选POI,覆盖绝大多数用户的步行习惯;
- 半径超过200米后,占比提升缓慢,故最终将“200米”设为最大步行半径。
- 候选POI识别:如图4所示(示意图),以落点为中心,200米范围内的POI(如中餐厅1、超市、住宅区)均为候选POI,且需按表1映射到对应目的(如住宅区→家庭,中餐厅→餐饮)。
3.3 骑行目的推断模型(Models for Inferring the Trip Purpose)
本文构建三类模型,逐步添加关键因素,对比其推断效果,核心是“重力模型”(计算吸引力)与“贝叶斯规则”(计算概率)的结合。
3.3.1 重力模型(Gravity Models)
重力模型源于“牛顿万有引力定律”,在交通地理中用于衡量“两个地点间的相互作用”,本文调整为“落点(D)与候选POI(P)间的吸引力”,基本逻辑是:POI吸引力与“自身规模(如服务容量)”正相关,与“落点-POI距离”负相关。
模型I(基础模型):考虑距离、时间、环境
- 核心因素:
- 距离:用落点与POI的欧氏距离平方(d(D,P)²)表示“交通阻抗”,距离越远,吸引力越弱;
- 时间:加入“时间权重(W(t))”,基于生活常识和设施营业时间(如医院24小时营业,银行仅白天营业),调整不同时段的POI吸引力(如深夜“工作”类POI的时间权重接近0);
- 环境:用“目的地范围内同类别POI数量”表示(如200米内有3个中餐厅,则餐饮类POI的环境因素为3),数量越多,该类目的吸引力越强。
- 公式:
G(D,P,t)=number(POI.category=P.category)d(D,P)2∗W(tP.category)G(D, P, t)=\frac{number(POI.category = P.category)}{d(D, P)^{2}} * W(t_{P.category}) G(D,P,t)=d(D,P)2number(POI.category=P.category)∗W(tP.category)
其中,G(D,P,t)为t时刻POI(P)对落点(D)的吸引力,number(…)为同类别POI数量,W(…)为时间权重。
模型II(改进模型1):加入POI类型占比
- 改进原因:模型I的“环境因素”仅考虑“目的地范围内的POI数量”,忽略“整个研究区域内POI类别的分布差异”(如深圳“工作”类POI占比45.33%,“家庭”类仅4.87%,模型I会过度倾向“工作”目的)。
- 新增因素:POI类型占比(C(activity_i)):
- 先计算“某类目的的POI数量密度(ρ(activity_i))”:区域内该类POI数量/研究区该类POI总数;
- 再归一化得到“类型占比”:C(activity_i) = ρ(activity_i) / 所有目的的ρ之和,反映该类目的在区域内的相对重要性。
- 公式:
G(D,P,t)=C(activityi=P.activity)d(D,P)2∗W(tP.category)G(D, P, t)=\frac{C(activity_i = P.activity)}{d(D, P)^{2}} * W(t_{P.category}) G(D,P,t)=d(D,P)2C(activityi=P.activity)∗W(tP.category)
用“类型占比(C)”替代模型I的“同类别POI数量”,修正区域POI分布差异的影响。
模型III(改进模型2):加入POI服务容量
- 改进原因:模型II仍未考虑“同类别POI的规模差异”(如“大学”和“幼儿园”均属“教育”类POI,但大学服务容量远大于幼儿园,吸引力更强)。
- 新增因素:POI服务容量(SC(P.type)):
- 计算步骤:① 用AOI范围内的平均TUD值表示POI的“原始服务容量”;② 归一化(公式7):(原始值-最小值)/(最大值-最小值),得到0-1间的服务容量指数;③ 特殊调整:地铁地下区域TUD数据缺失,结合深圳地铁日均客流量,将地铁站服务容量指数设为2.00(最高),高校设为1.00(表1)。
- 公式:
G(D,P,t)=SC(P.type)∗C(activityi=P.activity)d(D,P)2∗W(tP.category)G(D, P, t)=\frac{SC(P.type) * C(activity_i = P.activity)}{d(D, P)^{2}} * W(t_{P.category}) G(D,P,t)=d(D,P)2SC(P.type)∗C(activityi=P.activity)∗W(tP.category)
在模型II基础上,乘以“服务容量指数(SC)”,体现POI规模对吸引力的影响。
3.3.2 贝叶斯规则(Bayesian Rules)
- 核心作用:将“POI吸引力(G)”转化为“用户访问该POI的概率(Pr)”,实现“吸引力→目的”的推断。
- 逻辑推导:
- 假设“用户在t时刻于D点停车,前往P点”的概率,与“P点对D点的吸引力(G)”正相关;
- 对所有候选POI的吸引力进行归一化,得到每个POI的访问概率:
Pr(Pi∣D,t)=G(D,Pi,t)∑j=1nG(D,Pj,t)Pr(P_i | D, t)=\frac{G(D, P_i, t)}{\sum_{j=1}^{n} G(D, P_j, t)} Pr(Pi∣D,t)=∑j=1nG(D,Pj,t)G(D,Pi,t)
其中,n为候选POI数量,Pr最高的POI对应的目的,即为该次骑行的推断目的。
4. 结果与讨论(Results and Discussions)
本章通过“模型对比、模型验证、时空模式分析”三部分,验证推断框架的有效性,并挖掘深圳无桩共享单车骑行的核心规律。
4.1 三类模型的推断结果对比
通过表2(三类模型的活动占比)和图5(四类高服务容量活动的推断量对比),揭示因素添加对结果的影响:
4.1.1 模型I的局限性
- 结果特征:推断的“工作”类占比46.40%,“家庭”类仅8.42%,两者差异极大,与“通勤往返”的实际规律不符;“换乘”“购物”类占比极低(分别为4.22%、0.25%),因这类POI在研究区占比低,模型I受其影响显著。
- 结论:仅考虑距离、时间、环境时,结果受POI整体分布偏差大,合理性差。
4.1.2 模型II的改进效果
- 结果变化:加入POI类型占比后,“家庭”(15.54%)、“换乘”(12.67%)、“购物”(2.50%)等低POI占比类别的推断占比显著提升,“工作”类降至22.88%,“家庭-工作”占比更接近实际通勤规律。
- 结论:POI类型占比的加入,修正了区域POI分布偏差,结果合理性提升。
4.1.3 模型III的最优性
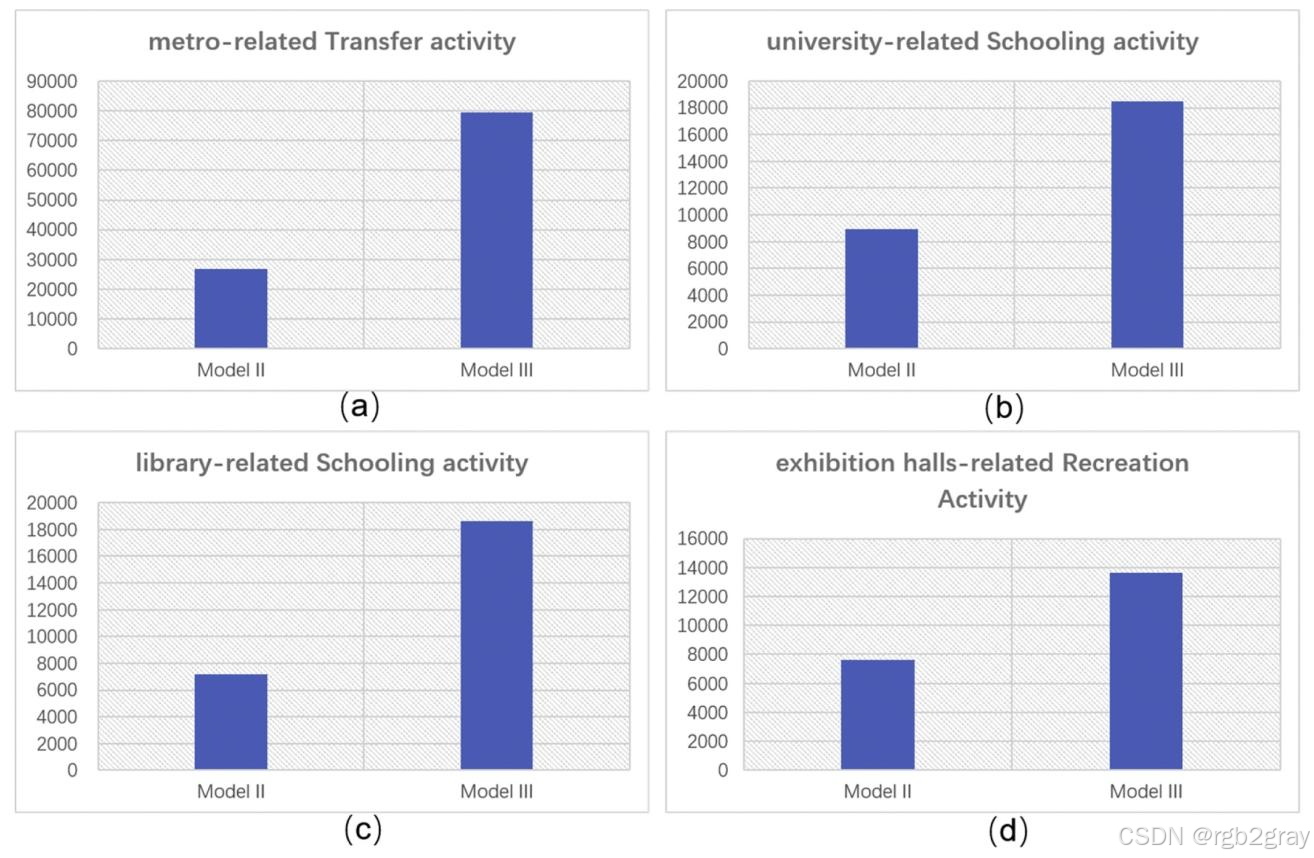
- 结果变化:加入POI服务容量后,高服务容量POI对应的活动量大幅增加(图5):
- 地铁换乘活动:模型III的推断量是模型II的2.95倍(图5a),因地铁站服务容量最高;
- 高校教育活动:模型III是模型II的2倍(图5b),与深圳高校10万学生的实际骑行需求匹配;
- 图书馆教育、展览馆休闲活动:模型III的推断量也显著高于模型II(图5c、d)。
- 结论:POI服务容量的加入,能识别“低POI占比但高吸引力”的活动(如地铁换乘),结果最精准。
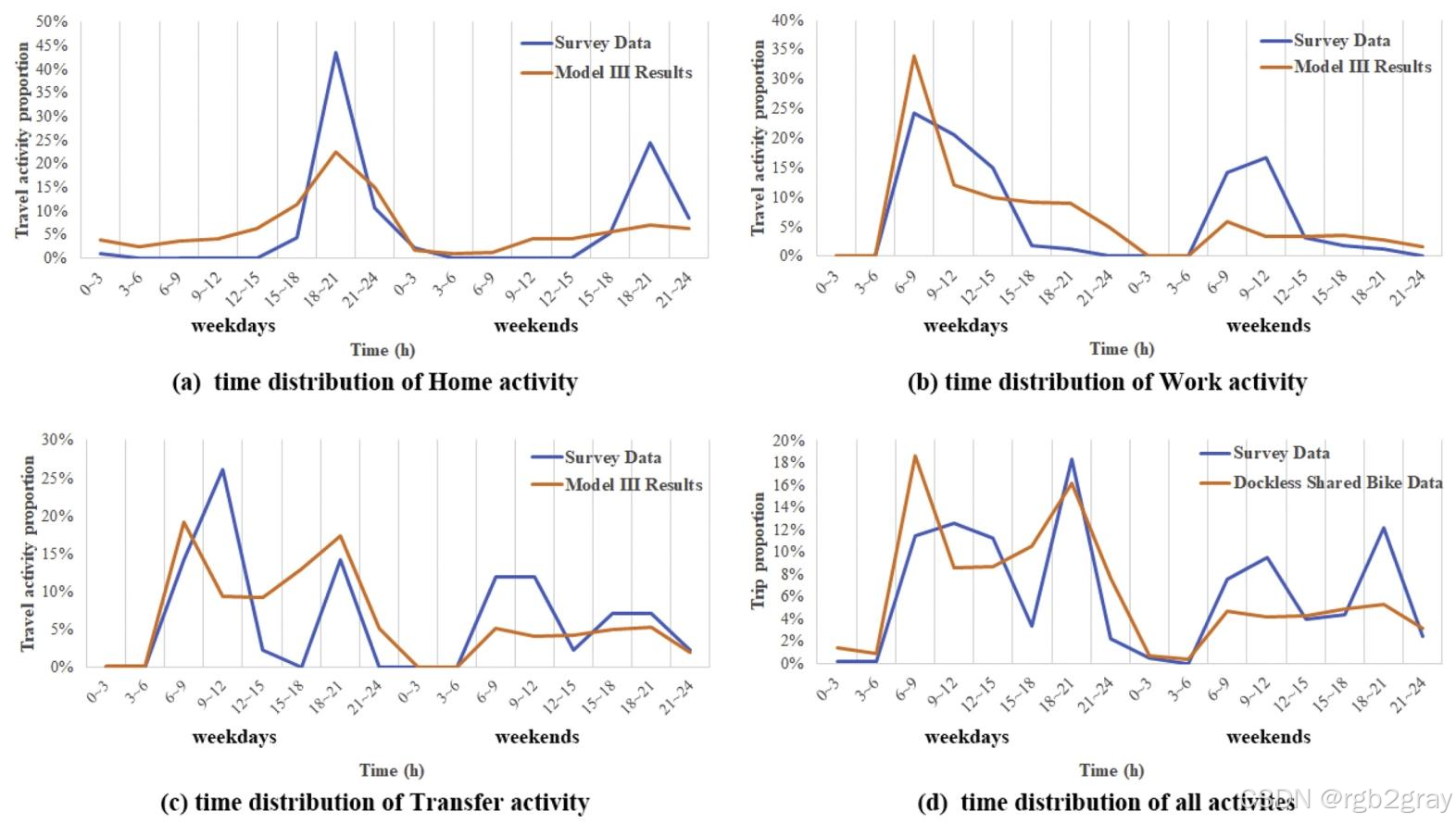
4.2 模型验证(Model Validation)
用“2019年12月深圳出行调查数据”(453条无桩共享单车骑行活动链)验证模型有效性,从“活动占比”和“时间分布”两方面对比:
4.2.1 活动占比验证(表3)
- 对比维度:因调查数据未记录“休闲、生活服务、医疗”三类活动,仅对比“家庭、工作+教育、换乘、餐饮、购物”五类;
- 核心结论:模型III的结果与调查数据最接近:
- 换乘活动:模型I(4.22%)远低于调查(9.27%),模型II(12.67%)高于调查,模型III(11.03%)接近调查;
- 家庭活动:模型III(17.28%)虽低于调查(20.75%),但差距小于模型I(8.42%)和模型II(15.54%);
- 整体而言,模型III的推断误差最小。
4.2.2 时间分布验证(图6)
- 选择“家庭、工作、换乘”三类样本量较大的活动,对比模型III推断结果与调查数据的时间分布:
- 家庭活动(图6a):工作日18点、21点双高峰,周末两高峰更接近,与调查数据趋势一致;
- 工作活动(图6b):工作日8点早高峰显著,周末8点高峰仍存在(反映加班),与调查数据匹配;
- 换乘活动(图6c):工作日8点、18点双高峰(通勤换乘),周末高峰平缓,与调查数据规律一致;
- 偏差原因(图6d):部分时段的偏差源于“共享单车总数据”与“调查样本”的时间分布差异(如调查样本中早高峰骑行占比略高),但整体趋势无显著差异。
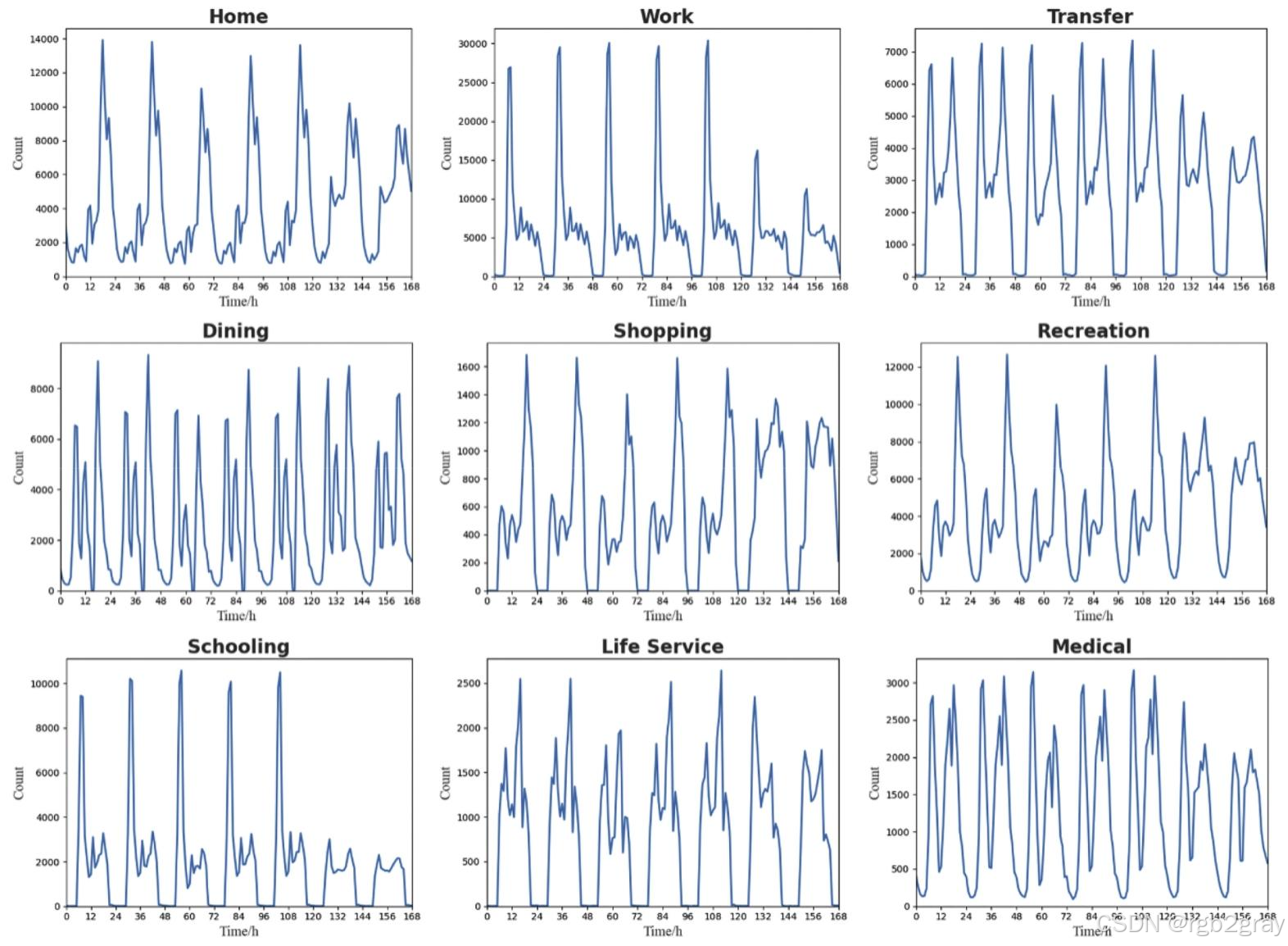
4.3 骑行活动的时空模式(Spatio-Temporal Patterns)
基于模型III的推断结果,结合核密度估计(KDE,搜索半径1500米)、时间序列分析,揭示深圳无桩共享单车骑行的时空规律。
4.3.1 时间模式(图7)
所有活动呈现显著的“周期性”和“时段差异”,与居民生活作息高度匹配:
- 家庭活动:工作日18点(下班回家)、21点(外出后返回)双高峰,18点高峰远高于21点;周末两高峰强度接近,因居民外出时间更灵活;
- 工作活动:工作日8点(上班)高峰显著,18点(下班)次高峰;周末8点仍有高峰(加班),但强度仅为工作日的1/3;
- 换乘活动:工作日8点、18点双高峰(通勤衔接地铁),周末高峰平缓,强度低于工作日;
- 餐饮活动:早8点(早餐)、午12点(午餐)、晚18点(晚餐)三高峰,早高峰最强,反映“骑行买早餐”的高频需求;
- 购物/休闲活动:工作日19点(下班后)单高峰;周末多高峰(10点、15点、19点),因居民有更多自由时间;
- 教育活动:工作日8点(上学)主高峰,13点(下午上课)、18点(课后活动)次高峰;周末8点、18点小高峰(培训);
- 生活服务活动:工作日16点(下班后办事)主高峰,9点(上班前)次高峰;周末9点高峰略高于16点;
- 医疗活动:工作日多高峰(8点、10点、14点),周末高峰少且强度低,因居民更倾向工作日就医。
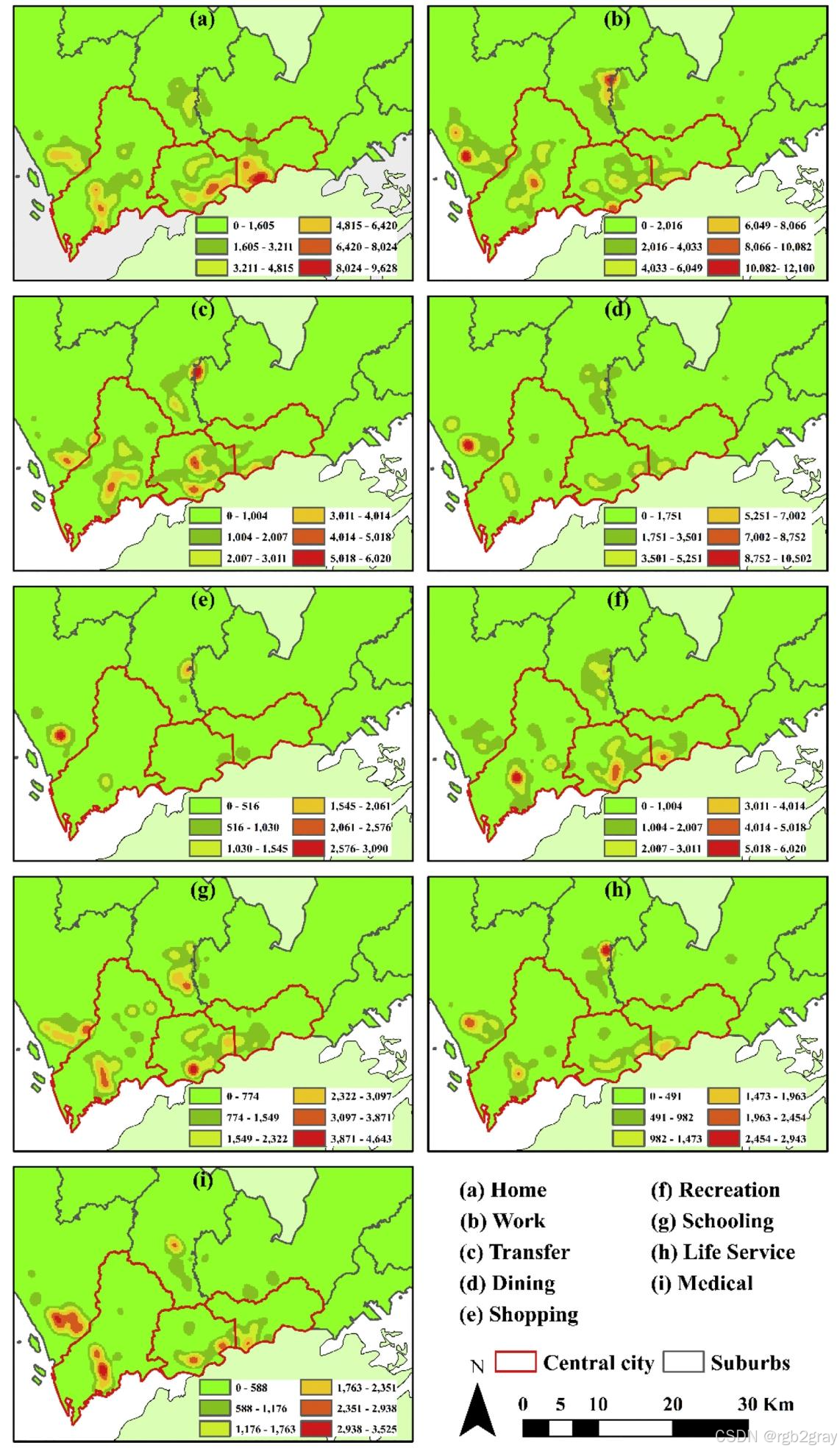
4.3.2 空间模式(图8)
用KDE热力图展示9类活动的空间聚集特征,与深圳土地利用、设施分布高度相关:
- 家庭活动(图8a):中心城区(南山、福田)和郊区(宝安、龙华)均有密集区,郊区密集区多位于“工业-住宅混合区”(如龙华工业园区周边),因郊区居民通勤距离短,直接骑行回家;
- 工作活动(图8b):空间分布与家庭活动高度重叠,中心城区密集区对应商业办公区(如福田CBD),郊区对应工业园区(如龙岗工业园),验证“郊区短通勤”特征;
- 换乘活动(图8c):热点集中在“地铁站周边”,且中心城区(如福田站、罗湖站)密度远高于郊区(如龙华站),因中心城区地铁客流量大,“单车+地铁”衔接需求强;
- 餐饮活动(图8d):热点分布在“郊区工业园区”(如宝安沙井)和“中心城区商业街区”(如南山科技园),前者因园区内餐饮设施集中,后者因商业活动密集;
- 购物活动(图8e):总量少,空间分散,中心城区热点对应大型商场(如福田COCO Park),郊区热点对应园区配套超市,反映“就近购物”习惯;
- 休闲活动(图8f):中心城区热点集中(如深圳湾公园、福田市民中心),郊区热点少且分散,因中心城区休闲设施更完善;
- 教育活动(图8g):热点集中在“高校密集区”(南山大学城)和“中小学密集区”(福田、罗湖),与教育设施分布完全匹配;
- 生活服务活动(图8h):空间模式与餐饮活动相似,热点在郊区园区和中心城区社区,因这类活动(如洗衣、快递)需“就近便捷”;
- 医疗活动(图8i):热点严格围绕“大型医院”分布(如南山医院、福田人民医院),空间聚集性最强,因医疗设施的“辐射效应”显著。
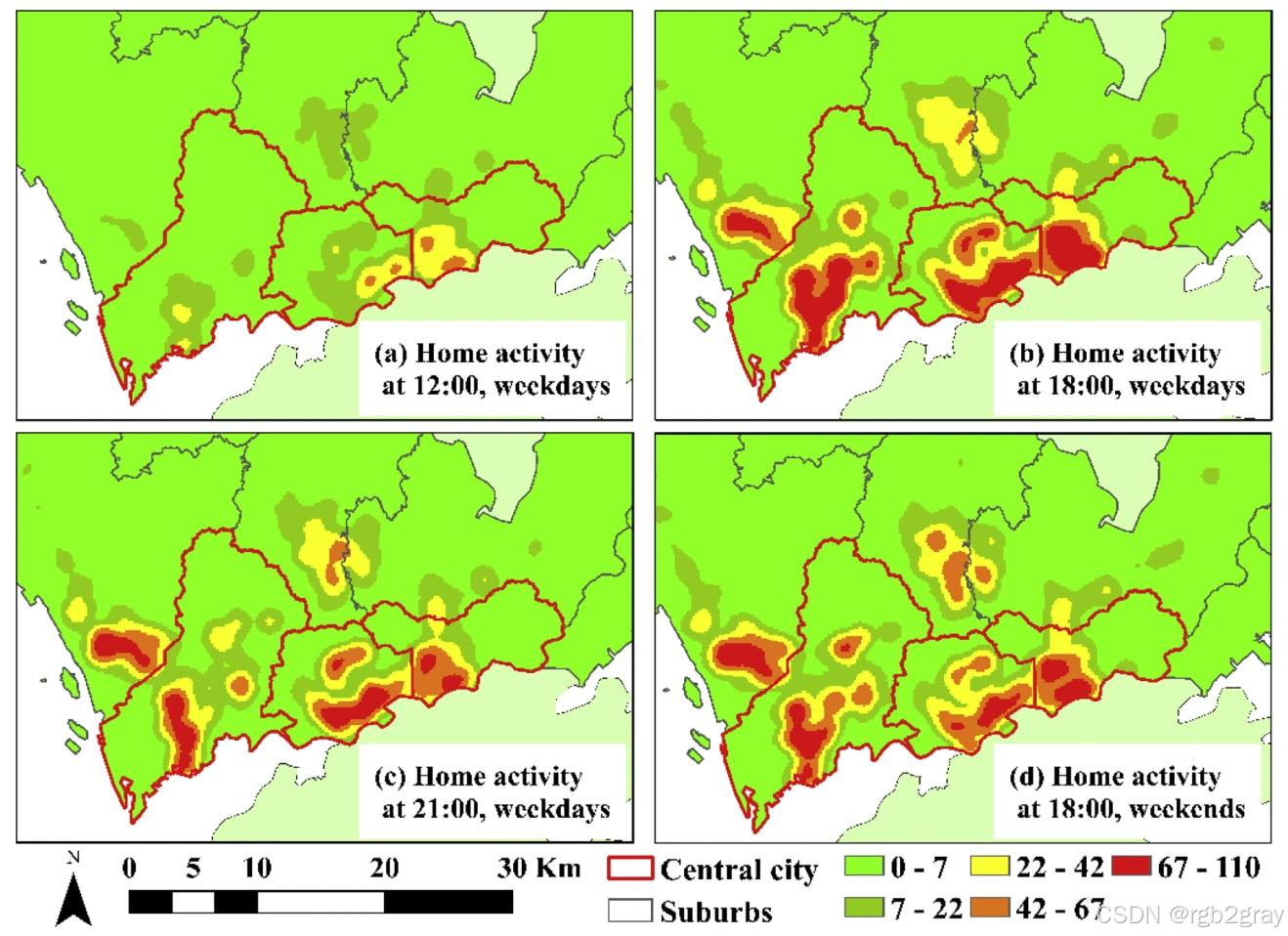
4.3.3 时空耦合模式(图9-12)
选择“家庭、工作、换乘、餐饮”四类核心活动,分析其“时间变化对空间分布的影响”:
家庭活动(图9)
- 工作日12点(图9a):热点集中在中心城区(如福田CBD周边住宅),因郊区居民多在园区工作,中午不回家,中心城区部分居民回家午休;
- 工作日18点(图9b):中心城区和郊区均出现大范围热点,郊区热点强度高于中午,因郊区居民下班骑行回家;
- 工作日21点(图9c):热点范围缩小,集中在“中心城区高档住宅”和“郊区园区周边住宅”,因居民夜间外出后返回;
- 周末18点(图9d):热点分布更均匀,郊区热点强度与中心城区接近,因周末居民外出活动更分散。
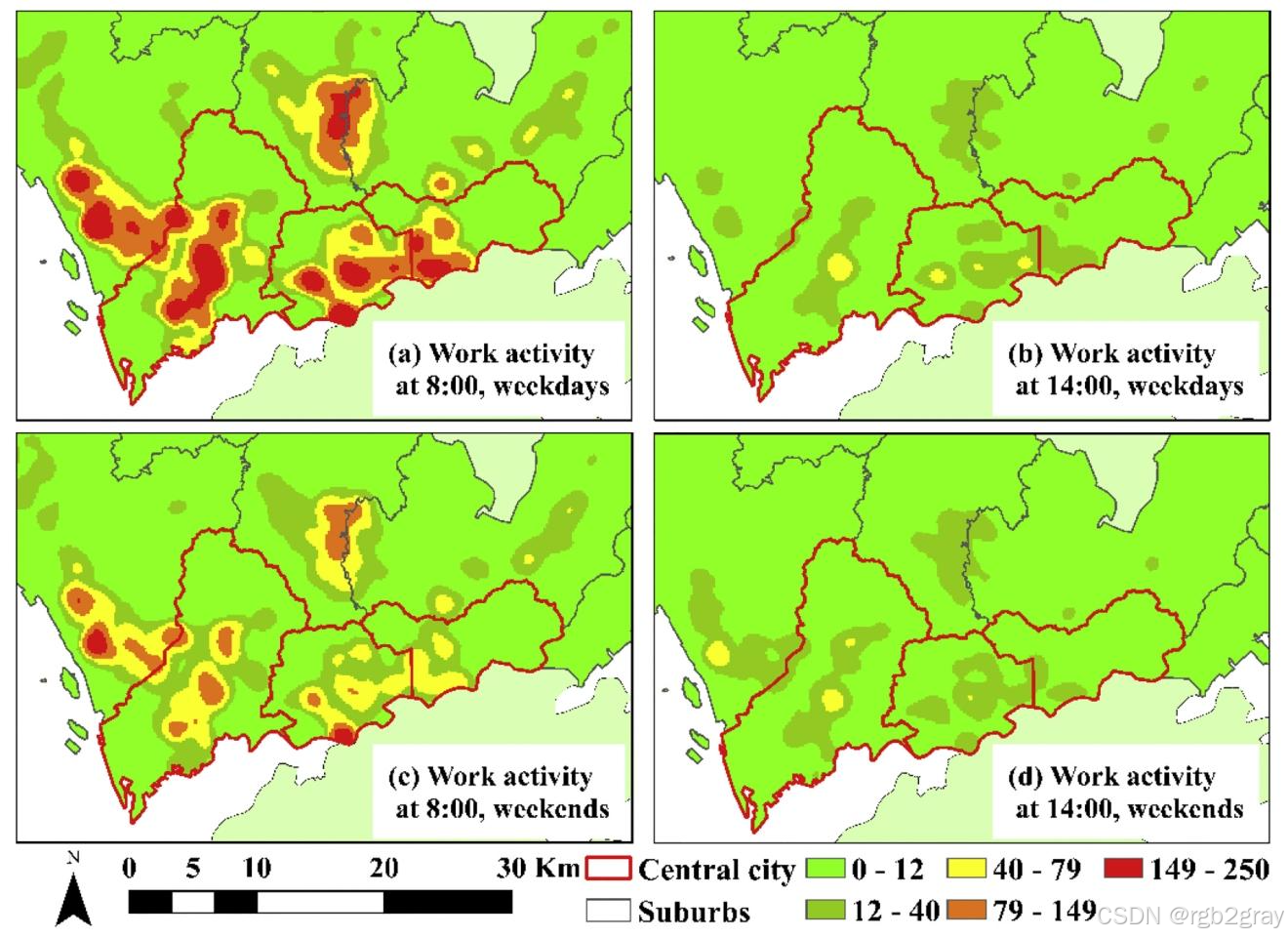
工作活动(图10)
- 工作日8点(图10a):热点广泛分布于中心城区办公区和郊区工业园区,强度高且范围大,是早高峰通勤核心时段;
- 工作日14点(图10b):热点范围缩小,强度降低,仅保留“核心办公区”(如福田CBD)和“园区核心区”(如龙岗华为基地),因工作时段骑行需求减少;
- 周末8点(图10c):热点集中在“高科技企业密集区”(南山科技园)和“工业园区”(宝安福永),范围小但强度较高,反映加班需求;
- 周末14点(图10d):热点几乎消失,仅零星分布,因周末工作活动极少。
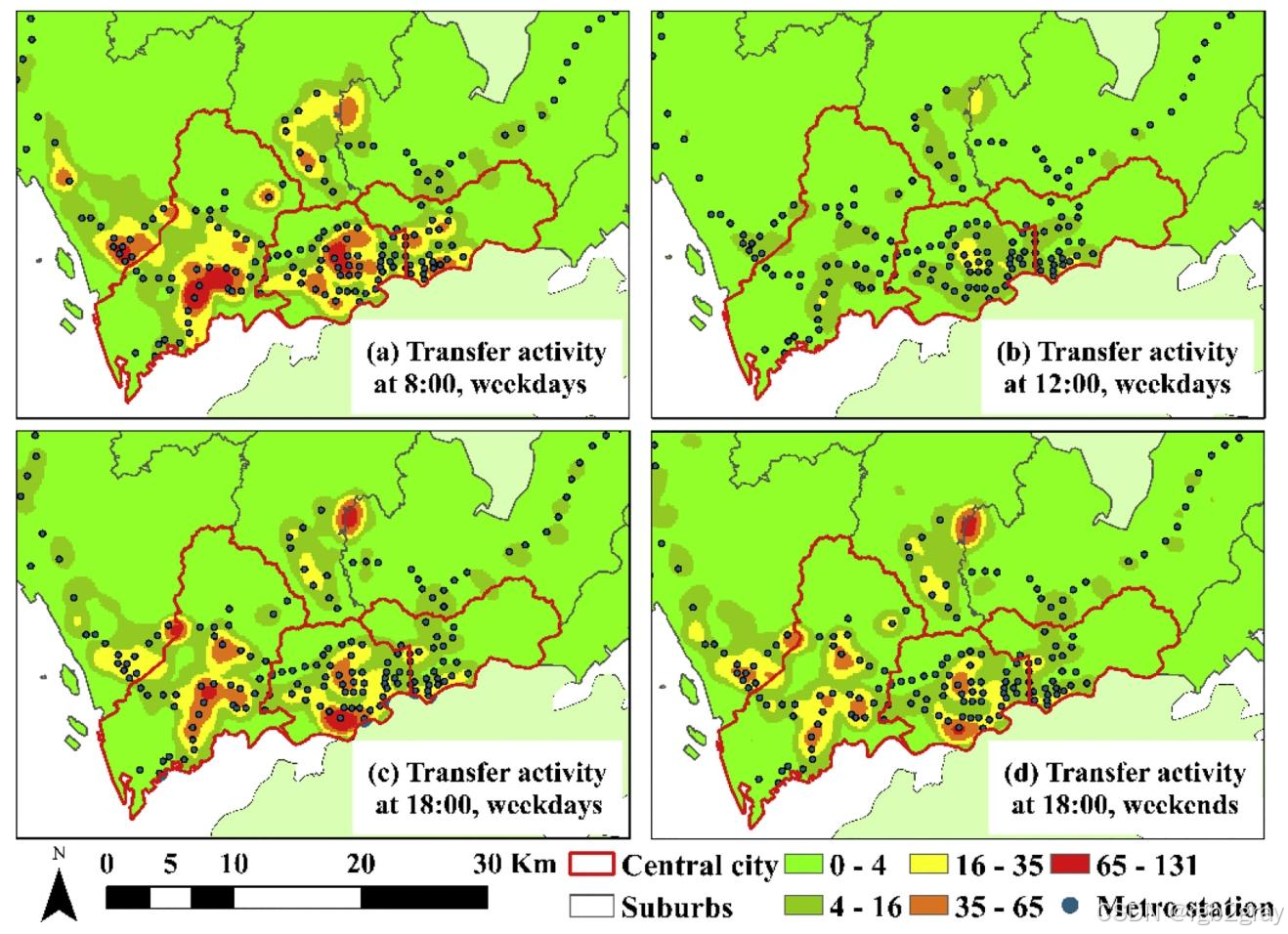
换乘活动(图11)
- 工作日8点(图11a):热点沿“中心城区地铁线路”分布(如1号线、3号线),地铁站周边形成高密度区,是早高峰换乘高峰;
- 工作日12点(图11b):热点范围大幅缩小,强度低,仅少数地铁站(如福田站)有弱热点,因非通勤时段换乘需求少;
- 工作日18点(图11c):热点再次沿中心城区地铁线分布,强度与早高峰接近,是晚高峰换乘高峰;
- 周末18点(图11d):热点范围小,集中在“旅游/商业区地铁站”(如深圳北站、世界之窗站),因周末居民出行以休闲为主,换乘需求集中在热门区域。
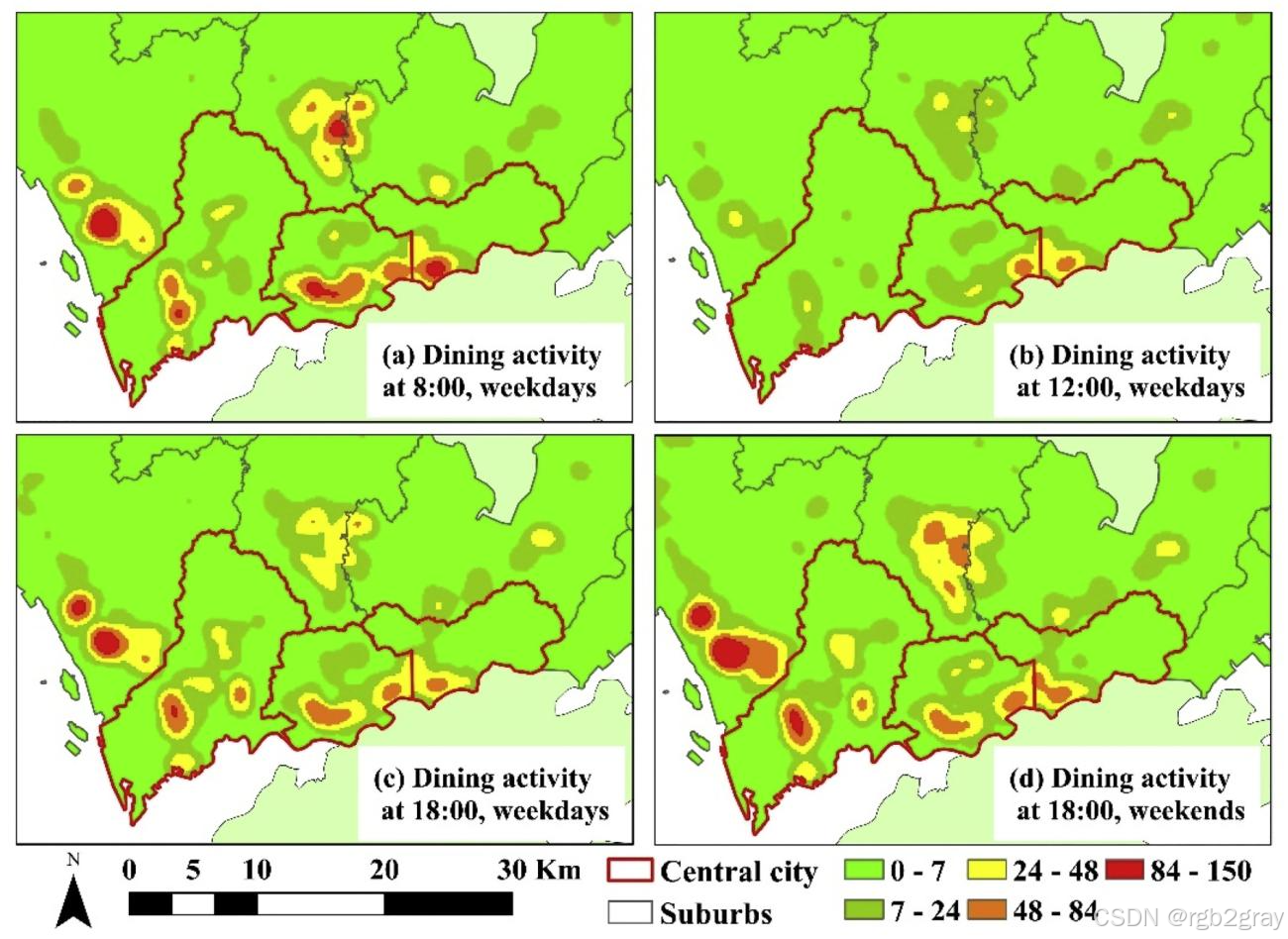
餐饮活动(图12)
- 工作日8点(图12a):热点广泛分布于“郊区园区入口”和“中心城区社区”,因居民骑行买早餐;
- 工作日12点(图12b):热点范围缩小,集中在“园区食堂周边”和“办公区餐厅周边”,强度低于早高峰;
- 工作日18点(图12c):热点范围扩大,中心城区商业街区和郊区园区周边均有高强度热点,因居民下班后外出就餐;
- 周末18点(图12d):热点分布更分散,中心城区热点强度高于郊区,因周末居民更倾向去中心城区聚餐。
5. 结论(Conclusions)
本章总结研究核心发现、理论贡献与实践价值,并指出未来研究方向。
5.1 核心结论
- 模型有效性:融合“距离、时间、环境、POI类型占比、POI服务容量”的模型III,能最精准推断无桩共享单车骑行目的,其活动占比和时间分布与调查数据高度匹配,解决了现有研究“因素遗漏”“结果偏差”的问题。
- 深圳骑行时空规律:
- 时间上:所有活动呈现“工作日高峰集中、周末高峰分散”的特征,与居民通勤、生活作息强相关;
- 空间上:郊区以“短通勤(家庭-工作直接骑行)”为主,中心城区以“单车+地铁换乘”和“休闲/商业骑行”为主;
- 时空耦合上:活动的空间分布随时段动态变化,如早高峰换乘集中在中心城区地铁线,晚高峰餐饮集中在商业/园区周边。
5.2 理论与实践贡献
- 理论贡献:
- 提出“多因素融合的骑行目的推断框架”,首次将“POI类型占比”“POI服务容量”纳入模型,填补现有研究空白;
- 验证了AOI、TUD数据在“量化POI服务容量”中的有效性,为交通行为研究提供新的数据与方法参考。
- 实践价值:
- 对单车运营商:郊区需加强“工业-住宅区间”的单车调度(匹配短通勤需求),中心城区需在“地铁早晚高峰”前增加地铁站周边单车供给(匹配换乘需求),周末需在“高科技园区”和“中心城区商业街区”增加单车;
- 对城市规划:郊区需优化“工业-住宅混合区”的自行车道,中心城区需完善“地铁站-商业/办公区”的自行车接驳设施,同时在郊区园区配套更多餐饮、生活服务设施,减少不必要的骑行需求;
- 对交通管理:可基于骑行时空模式,在“早高峰餐饮热点区”“晚高峰换乘热点区”设置临时单车停放点,缓解拥堵。
5.3 未来研究方向
- 模型优化:本文未用调查数据进行模型参数校准(如时间权重、距离衰减系数),未来可扩大调查样本量,通过机器学习方法优化参数,进一步提升推断精度;
- 跨城市对比:POI服务容量指数(表1)基于深圳数据,未来可在其他城市(如北京、上海)验证该指数的适用性,建立“城市类型-服务容量指数”的通用模型;
- 多模式融合:未来可结合“共享单车+公交+地铁”的多源数据,分析“多模式出行链”的目的与模式,更全面揭示城市出行特征。
附录
import pandas as pd
import numpy as np
import geopandas as gpd
from shapely.geometry import Point, Polygon
import matplotlib.pyplot as plt
from scipy.stats import gaussian_kde
import warnings
warnings.filterwarnings('ignore')# -------------------------- 1. 数据加载与预处理(匹配文章数据集格式) --------------------------
def load_and_preprocess_data():"""加载并预处理文章提及的四类核心数据:- 共享单车数据:筛选有效骑行(100m<距离<3000m),提取起终点GPS与时间- POI数据:关联9类出行目的(表1映射关系),添加服务容量指数- AOI数据:生成交通类POI的50m缓冲区(弥补AOI数据缺失)- TUD数据:计算AOI范围内平均用户密度,用于后续服务容量验证"""# 1.1 共享单车数据(格式:bike_id, start_time, end_time, start_lon, start_lat, end_lon, end_lat)bike_data = pd.read_csv("shenzhen_dockless_bike_201810.csv", parse_dates=["start_time", "end_time"])# 计算骑行距离(欧氏距离,单位:米)bike_data["distance"] = np.sqrt((bike_data["end_lon"] - bike_data["start_lon"]) ** 2 + (bike_data["end_lat"] - bike_data["start_lat"]) ** 2) * 111319 # 经度/纬度差转米(地球半径近似值)# 筛选有效骑行(文章1-43、1-49节设定:100m<距离<3000m)bike_data = bike_data[(bike_data["distance"] > 100) & (bike_data["distance"] < 3000)].reset_index(drop=True)# 提取小时段(用于时间权重计算)bike_data["hour"] = bike_data["end_time"].dt.hourbike_data["is_weekday"] = bike_data["end_time"].dt.weekday < 5 # 区分工作日/周末# 1.2 POI数据(格式:poi_id, name, lon, lat, category, service_capacity)# 依据文章表1建立POI类别与出行目的、服务容量的映射poi_purpose_map = {"Residence": ("Home", 0.60),"Office": ("Work", 0.46),"Financial": ("Work", 0.59),"IndustrialPark": ("Work", 0.43),"MetroStation": ("Transfer", 2.00),"BusStation": ("Transfer", 0.30),"Restaurant": ("Dining", 0.43),"Cafe": ("Dining", 0.18),"Mall": ("Shopping", 0.77),"Supermarket": ("Shopping", 0.30),"Park": ("Recreation", 0.82),"ExhibitionHall": ("Recreation", 0.92),"University": ("Schooling", 1.00),"PrimarySchool": ("Schooling", 0.43),"Hospital": ("Medical", 0.65),"Clinic": ("Medical", 0.31),"LifeService": ("LifeService", 0.23)}poi_data = pd.read_csv("shenzhen_poi.csv")# 关联出行目的与服务容量(文章表1核心参数)poi_data[["trip_purpose", "service_capacity"]] = pd.DataFrame(poi_data["category"].map(poi_purpose_map).tolist(), index=poi_data.index)# 转换为GeoDataFrame(便于空间计算)poi_gdf = gpd.GeoDataFrame(poi_data, geometry=[Point(xy) for xy in zip(poi_data["lon"], poi_data["lat"])],crs="EPSG:4326")# 1.3 AOI数据(格式:aoi_id, name, category, geometry)+ 交通类POI缓冲区aoi_gdf = gpd.read_file("shenzhen_aoi.shp")# 为地铁/公交站POI生成50m缓冲区(文章1-79节处理方法)transport_poi = poi_gdf[poi_gdf["category"].isin(["MetroStation", "BusStation"])]transport_aoi = transport_poi.copy()transport_aoi["geometry"] = transport_aoi.geometry.buffer(50 / 111319) # 50米缓冲区(经纬度单位转换)transport_aoi["aoi_type"] = transport_aoi["category"]# 合并原始AOI与交通类POI缓冲区aoi_gdf = pd.concat([aoi_gdf, transport_aoi[["name", "geometry", "aoi_type"]]], ignore_index=True)# 1.4 TUD数据(格式:time, lon, lat, user_density)- 用于验证POI服务容量tud_data = pd.read_csv("shenzhen_tud_201810.csv", parse_dates=["time"])tud_gdf = gpd.GeoDataFrame(tud_data, geometry=[Point(xy) for xy in zip(tud_data["lon"], tud_data["lat"])],crs="EPSG:4326")return bike_data, poi_gdf, aoi_gdf, tud_gdf# -------------------------- 2. 候选POI识别(文章3.2节:200米目的地范围) --------------------------
def identify_candidate_pois(bike_dropoff, poi_gdf, max_walk_radius=200):"""基于骑行终点(dropoff)生成200米目的地范围,筛选候选POI:param bike_dropoff: 单条骑行的终点信息(含end_lon, end_lat):param poi_gdf: POI的GeoDataFrame:param max_walk_radius: 最大步行半径(文章1-57、1-58节设定为200米):return: 候选POI列表(含目的、服务容量、与终点距离)"""# 生成终点的200米缓冲区(经纬度单位:1米≈1/111319度)dropoff_point = Point(bike_dropoff["end_lon"], bike_dropoff["end_lat"])dropoff_buffer = dropoff_point.buffer(max_walk_radius / 111319)# 筛选缓冲区内的POI(候选POI)candidate_pois = poi_gdf[poi_gdf.geometry.within(dropoff_buffer)].copy()# 计算候选POI与终点的距离(米)candidate_pois["distance_to_dropoff"] = candidate_pois.geometry.distance(dropoff_point) * 111319return candidate_pois[["poi_id", "trip_purpose", "service_capacity", "distance_to_dropoff"]]# -------------------------- 3. 重力模型实现(文章3.3.1节:三类模型) --------------------------
def calculate_time_weight(hour, is_weekday, trip_purpose):"""计算时间权重(文章1-70节:基于生活常识与设施营业时间):param hour: 骑行结束小时(0-23):param is_weekday: 是否为工作日(bool):param trip_purpose: 出行目的(如Home, Work, Transfer):return: 时间权重(0-1)"""time_weights = {"Home": {"weekday": [0.1, 0.1, 0.1, 0.1, 0.2, 0.4, 0.6, 0.3, 0.2, 0.2, 0.2, 0.3, 0.3, 0.4, 0.5, 0.8, 1.0, 0.9, 0.7, 0.5, 0.4, 0.3, 0.2, 0.1],"weekend": [0.1, 0.1, 0.1, 0.1, 0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.7,0.6, 0.6, 0.7, 0.8, 0.9, 0.8, 0.7, 0.6, 0.5, 0.3, 0.2, 0.1]},"Work": {"weekday": [0.05, 0.05, 0.05, 0.05, 0.1, 0.3, 0.8, 1.0, 0.9, 0.8, 0.7, 0.7,0.7, 0.8, 0.9, 0.8, 0.5, 0.2, 0.1, 0.05, 0.05, 0.05, 0.05, 0.05],"weekend": [0.05, 0.05, 0.05, 0.05, 0.05, 0.1, 0.2, 0.3, 0.4, 0.5, 0.5, 0.5,0.5, 0.4, 0.3, 0.2, 0.1, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05, 0.05]},"Transfer": {"weekday": [0.1, 0.1, 0.1, 0.1, 0.2, 0.5, 0.9, 1.0, 0.8, 0.6, 0.5, 0.5,0.5, 0.6, 0.7, 0.9, 1.0, 0.8, 0.5, 0.2, 0.1, 0.1, 0.1, 0.1],"weekend": [0.1, 0.1, 0.1, 0.1, 0.1, 0.2, 0.3, 0.5, 0.7, 0.8, 0.8, 0.8,0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2, 0.1, 0.1, 0.1, 0.1, 0.1]},# 其他目的(Dining/Shopping等)的时间权重可参考文章逻辑补充,此处简化"default": {"weekday": [0.05, 0.05, 0.05, 0.05, 0.1, 0.2, 0.4, 0.6, 0.8, 0.9, 1.0, 0.9,0.8, 0.9, 1.0, 0.9, 0.8, 0.6, 0.4, 0.2, 0.1, 0.05, 0.05, 0.05],"weekend": [0.05, 0.05, 0.05, 0.05, 0.05, 0.1, 0.3, 0.5, 0.7, 0.9, 1.0, 1.0,0.9, 0.9, 1.0, 0.9, 0.7, 0.5, 0.3, 0.1, 0.05, 0.05, 0.05, 0.05]}}key = "weekday" if is_weekday else "weekend"return time_weights.get(trip_purpose, time_weights["default"])[key][hour]def gravity_model(candidate_pois, bike_info, model_type="basic"):"""实现文章三类重力模型,计算候选POI的吸引力:param candidate_pois: 候选POI列表(含目的、服务容量、距离):param bike_info: 单条骑行信息(含hour, is_weekday):param model_type: 模型类型(basic=模型I, activity_prop=模型II, service_cap=模型III):return: 含POI吸引力的候选POI列表"""if len(candidate_pois) == 0:return pd.DataFrame() # 无候选POI时返回空# 基础参数hour = bike_info["hour"]is_weekday = bike_info["is_weekday"]candidate_pois = candidate_pois.copy()# 1. 计算时间权重(所有模型均需)candidate_pois["time_weight"] = candidate_pois["trip_purpose"].apply(lambda x: calculate_time_weight(hour, is_weekday, x))# 2. 模型I(基础模型:距离+时间+环境,文章1-69、1-71节)# 环境因素:候选POI中同目的POI数量purpose_count = candidate_pois["trip_purpose"].value_counts()candidate_pois["env_factor"] = candidate_pois["trip_purpose"].map(purpose_count)# 吸引力计算(距离用平方衰减,文章1-70节公式3)candidate_pois["attraction_basic"] = (candidate_pois["env_factor"] / (candidate_pois["distance_to_dropoff"] ** 2) ) * candidate_pois["time_weight"]# 3. 模型II(改进模型:加入活动类型占比,文章1-76、1-77节)# 计算POI类型占比(C(activity_i):候选POI中某目的占比/全量POI中该目的占比)global_poi_purpose_ratio = poi_gdf["trip_purpose"].value_counts(normalize=True) # 全量POI目的占比candidate_purpose_ratio = candidate_pois["trip_purpose"].value_counts(normalize=True) # 候选POI目的占比# 填充缺失目的的占比(避免除零)for purpose in global_poi_purpose_ratio.index:if purpose not in candidate_purpose_ratio.index:candidate_purpose_ratio[purpose] = 1e-6# 计算类型占比C(activity_i)candidate_pois["activity_prop"] = candidate_pois["trip_purpose"].map(lambda x: candidate_purpose_ratio[x] / global_poi_purpose_ratio[x])# 吸引力计算(文章1-77节公式6)candidate_pois["attraction_activity"] = (candidate_pois["activity_prop"] / (candidate_pois["distance_to_dropoff"] ** 2) ) * candidate_pois["time_weight"]# 4. 模型III(改进模型:加入POI服务容量,文章1-79、1-82节)# 吸引力计算(文章1-82节公式)candidate_pois["attraction_service"] = (candidate_pois["service_capacity"] * candidate_pois["activity_prop"] / (candidate_pois["distance_to_dropoff"] ** 2) ) * candidate_pois["time_weight"]# 返回指定模型的吸引力if model_type == "basic":candidate_pois["attraction"] = candidate_pois["attraction_basic"]elif model_type == "activity_prop":candidate_pois["attraction"] = candidate_pois["attraction_activity"]elif model_type == "service_cap":candidate_pois["attraction"] = candidate_pois["attraction_service"]return candidate_pois[["poi_id", "trip_purpose", "distance_to_dropoff", "time_weight", "attraction"]]# -------------------------- 4. 贝叶斯概率推断(文章3.3.2节) --------------------------
def infer_trip_purpose(candidate_pois_with_attraction):"""基于贝叶斯规则推断骑行目的(文章1-85、1-86节):param candidate_pois_with_attraction: 含POI吸引力的候选POI列表:return: 推断的出行目的(概率最高的POI对应的目的)及各目的概率"""if len(candidate_pois_with_attraction) == 0:return "Unknown", {}# 计算各POI的访问概率(文章1-86节公式11:吸引力归一化)total_attraction = candidate_pois_with_attraction["attraction"].sum()candidate_pois_with_attraction["probability"] = candidate_pois_with_attraction["attraction"] / total_attraction# 按目的聚合概率(同一目的的多个POI概率求和)purpose_prob = candidate_pois_with_attraction.groupby("trip_purpose")["probability"].sum().sort_values(ascending=False)# 推断目的:概率最高的目的inferred_purpose = purpose_prob.index[0]return inferred_purpose, purpose_prob.to_dict()# -------------------------- 5. 时空模式可视化(文章4.3节:时间序列+空间热力图) --------------------------
def visualize_spatiotemporal_patterns(bike_with_purpose):"""可视化出行目的的时空模式:- 时间模式:工作日/周末各目的的小时分布(图7风格)- 空间模式:核心目的(Home/Work/Transfer)的核密度热力图(图8风格)"""# 5.1 时间模式可视化(文章图7)plt.figure(figsize=(15, 10))# 筛选核心目的(Home, Work, Transfer, Dining)core_purposes = ["Home", "Work", "Transfer", "Dining"]bike_core = bike_with_purpose[bike_with_purpose["inferred_purpose"].isin(core_purposes)]# 计算工作日/周末各小时各目的的骑行占比weekday_hour_purpose = bike_core[bike_core["is_weekday"]].groupby(["hour", "inferred_purpose"]).size()weekday_hour_total = bike_core[bike_core["is_weekday"]].groupby("hour").size()weekday_hour_ratio = (weekday_hour_purpose / weekday_hour_total).unstack(fill_value=0)weekend_hour_purpose = bike_core[~bike_core["is_weekday"]].groupby(["hour", "inferred_purpose"]).size()weekend_hour_total = bike_core[~bike_core["is_weekday"]].groupby("hour").size()weekend_hour_ratio = (weekend_hour_purpose / weekend_hour_total).unstack(fill_value=0)# 子图1:工作日时间模式plt.subplot(2, 1, 1)for purpose in core_purposes:if purpose in weekday_hour_ratio.columns:plt.plot(weekday_hour_ratio.index, weekday_hour_ratio[purpose], marker="o", label=purpose)plt.title("Temporal Pattern of Core Trip Purposes (Weekdays)", fontsize=12)plt.xlabel("Hour of Day")plt.ylabel("Proportion of Trips")plt.xticks(range(0, 24))plt.legend()plt.grid(alpha=0.3)# 子图2:周末时间模式plt.subplot(2, 1, 2)for purpose in core_purposes:if purpose in weekend_hour_ratio.columns:plt.plot(weekend_hour_ratio.index, weekend_hour_ratio[purpose], marker="s", label=purpose)plt.title("Temporal Pattern of Core Trip Purposes (Weekends)", fontsize=12)plt.xlabel("Hour of Day")plt.ylabel("Proportion of Trips")plt.xticks(range(0, 24))plt.legend()plt.grid(alpha=0.3)plt.tight_layout()plt.savefig("temporal_pattern.png", dpi=300, bbox_inches="tight")plt.close()# 5.2 空间模式可视化(文章图8:核密度热力图)plt.figure(figsize=(18, 6))# 深圳中心城区经纬度范围(简化):lon [113.7, 114.1], lat [22.5, 22.75]shenzhen_extent = [113.7, 114.1, 22.5, 22.75]for i, purpose in enumerate(["Home", "Work", "Transfer"]):purpose_bike = bike_with_purpose[bike_with_purpose["inferred_purpose"] == purpose]if len(purpose_bike) < 100:continue # 样本量不足时跳过# 计算核密度xy = np.vstack([purpose_bike["end_lon"], purpose_bike["end_lat"]])z = gaussian_kde(xy)(xy)# 子图:空间热力图plt.subplot(1, 3, i+1)scatter = plt.scatter(purpose_bike["end_lon"], purpose_bike["end_lat"], c=z, cmap="YlOrRd", alpha=0.6, s=10, edgecolors="none")plt.xlim(shenzhen_extent[0], shenzhen_extent[1])plt.ylim(shenzhen_extent[2], shenzhen_extent[3])plt.title(f"Spatial Pattern of {purpose} Trips", fontsize=12)plt.xlabel("Longitude")plt.ylabel("Latitude")plt.colorbar(scatter, label="Density")plt.grid(alpha=0.3)plt.tight_layout()plt.savefig("spatial_pattern.png", dpi=300, bbox_inches="tight")plt.close()# -------------------------- 6. 主函数:串联全流程 --------------------------
if __name__ == "__main__":# 1. 加载预处理数据bike_data, poi_gdf, aoi_gdf, tud_gdf = load_and_preprocess_data()print(f"加载有效骑行数据:{len(bike_data)} 条")print(f"加载POI数据:{len(poi_gdf)} 个")# 2. 对每条骑行推断出行目的(使用模型III,文章验证最优)inferred_results = []sample_size = min(10000, len(bike_data)) # 采样1万条避免计算过载(全量可删除此限制)bike_sample = bike_data.sample(sample_size, random_state=42)for idx, (_, bike) in enumerate(bike_sample.iterrows()):# 2.1 识别候选POIcandidate_pois = identify_candidate_pois(bike, poi_gdf)# 2.2 计算POI吸引力(模型III:服务容量+活动占比)candidate_with_attr = gravity_model(candidate_pois, bike, model_type="service_cap")# 2.3 贝叶斯推断目的if len(candidate_with_attr) > 0:purpose, prob = infer_trip_purpose(candidate_with_attr)inferred_results.append({"bike_id": bike["bike_id"],"end_time": bike["end_time"],"end_lon": bike["end_lon"],"end_lat": bike["end_lat"],"hour": bike["hour"],"is_weekday": bike["is_weekday"],"inferred_purpose": purpose,"max_prob": max(prob.values()) if prob else 0})# 进度提示if (idx + 1) % 1000 == 0:print(f"已处理 {idx+1}/{sample_size} 条骑行数据")# 3. 整理结果并保存bike_with_purpose = pd.DataFrame(inferred_results)bike_with_purpose.to_csv("bike_trip_purpose_inferred.csv", index=False)print(f"推断完成,保存结果:{len(bike_with_purpose)} 条骑行含目的标签")# 4. 统计各目的占比(对比文章表2)purpose_count = bike_with_purpose["inferred_purpose"].value_counts(normalize=True) * 100print("\n各出行目的占比(模型III):")print(purpose_count.round(2))# 5. 可视化时空模式visualize_spatiotemporal_patterns(bike_with_purpose)print("\n时空模式图已保存:temporal_pattern.png, spatial_pattern.png")