构建AI智能体:九十二、智能协作的艺术:大模型上下文与Token优化指南
一、引言
作为开发者,当我们初次接触大模型API时,往往会陷入一个美好的错觉:仿佛面对的是一个能够无限畅聊的智能伙伴,然而,当我们深入实际应用时,一个关键技术概念会立即打破这种幻想,上下文窗口,这就像从自助餐厅模式切换到了按克称重的精品料理。在大模型的世界里,我们每次与AI的对话都在一块固定大小的协作白板上进行,这块白板的容量就是上下文窗口,而衡量其使用量的单位就是Token。
每个Token都在消耗真实的计算资源,而我们的开发习惯直接决定了这笔智力税的金额。不加优化的提示词、冗长的对话历史、模糊的输出要求,都在悄无声息地浪费着宝贵的Token资源。更糟糕的是,这种浪费往往伴随着性能的下降,过长的上下文会导致响应变慢,不精确的指令会产生低质量输出。
理解Token消耗机制也是我们必须掌握的,每个Token不仅是计费的单位,更是模型计算资源的直接体现。无论是我们输入的问题、提供的文档,还是模型生成的回答,都在共同消耗着宝贵的上下文空间。这种限制并非缺陷,而是一种技术设计的必然,它要求我们必须从随心所欲的提问者转变为精打细算的架构师。在这个框架下,优化Token使用不再是可选项,而是构建高效、经济AI应用的必修课。

二、什么是上下文窗口
想象一个场景,可能不是很符合常规,但能解释这个主题,我们正在读一本非常长的书,但手里只有一个固定大小的阅读框。这个框一次只能罩住半页纸,姑且算为500个文字,我们只能基于框里的内容来理解故事和回答问题。如果想理解后面的情节,就必须把框往后移,但这样就忘了前面框里的内容了,这个阅读框的大小,就是大模型的上下文窗口,它决定了模型在生成下一个词时,能够回顾和参考的前面多少个词(Token)。
这就好比大模型是一位学识渊博但短期记忆有限的分析师,在他面前有一块固定大小的黑板,即上下文窗口,我们与他的所有对话,包括我们的问题指令、模型给出的回答,以及我们提供的所有参考材料,如文档、代码、数据等,都必须写在这块黑板上。这块黑板的大小,用专业术语说就是Token数量,在这里可以粗略理解为字数,就是模型的上下文长度。
到这里我们会不会有一个疑问,如果长上下文这么好,它的限制对我们单次输入的内容有何具体益处?事实上,这种限制恰恰塑造了我们与模型高效协作的方式。 它要求我们必须像一位严谨的导演,在有限的舞台上,精准地布置场景和道具。也就是说在有限的范围内,精确的我们的需求从而提炼我们的输入信息,其核心益处在于:
- 它迫使我们进行信息提纯:我们不能将未经整理的原始数据倾倒给模型,而是需要先进行筛选、总结和结构化。这个过程本身就能帮助我们厘清思路,抓住问题的核心矛盾,从而提出更精准的指令。高质量的输入直接决定了高质量的输出。
- 它确保了思维的连贯性与完整性:在一个足够大的窗口内,模型可以同时看到我们的全部要求、相关的背景知识、此前的对话历史以及它自己生成的内容。这使它能在完整的语境下进行推理,保持逻辑的前后一致,避免因信息被截断而出现断片或答非所问的情况。
简单来说,理解并善用上下文窗口的限制,是开发者从简单提问进阶到复杂任务编排的关键第一步,它提醒我们,与AI的有效协作,不在于一次性能扔给它多少信息,而在于如何精巧地为它设定思考的舞台,由此我们可以归纳出:
- 短上下文问题:早期的模型上下文窗口都普遍的偏小,让它读一篇长篇小说或一份长报告并回答问题,是非常困难的。
- 长上下文目标:我们希望把这个阅读框变得非常大,比如10万、100万甚至更长,这样模型就能一口气读完一整本书、所有的项目文档,并基于全部信息进行工作。
三、如何扩展上下文窗口
1. 扩展位置编码
1.1 位置编码是什么
模型需要知道单词的顺序。“猫追老鼠”和“老鼠追猫”的意思完全不同,位置编码就是给每个输入单词一个位置号,告诉模型“你是句子中的第几个词”。
1.2 最初的困境:绝对位置编码
最早的位置编码(如Transformer中的正弦余弦编码)是为固定长度设计的。比如,它只学会了如何给前2048个位置编号,如果你突然让它处理第2049个词,它没见过这个位置号,就会完全混乱,性能急剧下降,这就像我们只背了1-100号的座位表,突然让我们找第101号座位,这时候就懵了。
1.3 解决方案
1.3.1 相对位置编码
前面我们讲词向量的时候说过,模型其实更关心词与词之间的相对距离,而不是绝对位置。比如“它”这个词通常指代它前面不远处的“猫”。
- 思想:不再给每个词一个固定的绝对坐标,而是计算词与词之间的相对距离。
- 代表:RoPE是目前最成功和广泛使用的相对位置编码方法。
- 通俗理解:想象在一个圆桌上,我们不关心每个人绝对坐在几号位,只关心“你在我左边第2个位置”或“他在发言者右边第3个位置”。这样,无论圆桌大小如何变化,相对关系依然成立。RoPE就是通过一种巧妙的数学旋转方式来实现这种相对距离的度量。
1.3.2 扩展RoPE的上下文窗口
即使有了RoPE,直接放大也会出问题。就好比用一把刻度很密的尺子,原设计用于量0-20厘米,突然去量2米长的东西,精度不够了。于是出现了以下几种尺子拉伸技术:
- 位置插值:
- 做法:把原本为短序列设计的位置编号均匀地压缩到新的长窗口中。
- 比喻:尺子原本最大量程是20cm,上面有200个刻度。现在要量40cm的东西,我们把所有刻度之间的间距拉大一倍,这样20cm的尺子就能覆盖40cm的长度了。虽然刻度变稀疏了,但还能用。
- 示例:模型原本在0-2048的位置上训练得很好。现在要扩展到8192,我们就把所有位置索引除以4(position = position / 4),再输入模型。这样,原本2048的位置现在变成了512,依然在模型熟悉的范围内。
- 缺点:刻度变稀疏可能导致精度下降,处理特别长的文本时效果会打折扣。
- 动态NTK插值:
- 做法:一种更聪明的插值方法。它只拉伸高频部分(刻度密集的地方)的维度,而保持低频部分(刻度稀疏的地方)的维度基本不变。
- 比喻:在拉伸尺子时,我们只把测量毫米的精细刻度部分拉松一点,而测量厘米和米的大刻度保持不变。这样既扩展了量程,又最大限度地保留了测量精细距离的能力。
- 优点:可以在不进行全量微调的情况下,仅通过修改推理代码,就实现上下文窗口的有效扩展,非常受欢迎。
- YaRN:
- 做法:这是动态NTK插值的进一步升级和优化。它通过更复杂的数学方法,更好地平衡了不同频率维度的缩放问题。
- 优点:目前被认为是扩展RoPE模型上下文窗口的最佳方法之一,被许多最新模型采用。
2. 调整上下文窗口
调整上下文窗口,一般在代码里把max_seq_len值从2048改成我们需要的长度,但这只是基础操作,实际远不止如此,不只是改一个数字就能解决这个问题。
训练阶段调整:
- 渐进式扩展:先在一个稍长的序列上(比如4096)对模型进行微调,让它适应;稳定后再扩展到更长的序列(如8192),一步步来。这就像健身,不能一下子举起100公斤,要循序渐进。
- 全量预训练:最彻底但成本最高的方法。直接用长文本数据从头开始训练一个模型。这相当于培养一个天生就能看长文章的新模型,但需要巨大的算力和数据。
推理阶段优化:
- 即使模型支持长上下文,处理10万个词的计算量和内存占用也是巨大的。因此需要优化技术,如FlashAttention,它通过巧妙的算法重组,极大地减少了内存访问次数,让长序列计算变得可行和高效。
3. 长文本数据
一个只读过短篇新闻和推特帖子的模型,如果突然给它一本完整的书,它是无法理解的。它需要长文本的阅读训练。模型需要在训练数据中看到长距离的依赖关系。比如,小说的第一章埋下的伏笔,在第二十章才揭示。只有见过这种模式,模型才能学会。
数据来源:
- 书籍、学术论文、长篇文章、法律文书、代码库等。
数据处理的挑战:
- 质量:网络上充斥着低质量的碎片化文本,需要精心筛选。
- 格式:需要保证数据的完整性,不能把一篇文章随意截断。
- 构建长文本:有时需要主动将多个相关的短文档拼接成一个长的训练样本。
4. 长文本和推理关系
- 上下文长度增加 ≠ 推理能力提升:给模型更多信息并不会自动提升其逻辑推理能力
- 推理需要专门训练:需要通过思维链、推理过程监督等专门方法培养
- 长上下文可能引入噪声:如果没有良好的推理能力,更多信息反而可能降低表现
长上下文和推理能力是互补关系,而非替代关系:
- 长上下文:提供丰富的原材料和信息基础
- 推理能力:提供信息加工、分析、综合的认知工具
四、Token介绍与简省
1. 什么是Token
Token 是模型处理文本的基本单位,可以理解为模型的词汇原子。它不仅仅是我们的输入,而是包含了整个对话回合中的所有内容。
Token的组成:
- 用户输入:您的提问、指令、提供的文档内容
- 系统提示:预设的角色设定、行为规则
- 模型回复:AI生成的全部回答内容
- 对话历史:如果配置历史保留,那么之前多轮问答的所有内容也会存在
2. Token的计算
- 不是1次请求 = 1个Token
- 而是1段文本 = N个Tokens(N取决于文本长度和复杂度)
请求阶段(输入Tokens)
- "您的可见输入": "请解释机器学习", # 假设5个tokens
- "隐藏的系统提示": "你是一个专家...", # 假设20个tokens
- "对话格式标记": "<|im_start|>等", # 假设15个tokens
- "历史对话": "之前的所有问答", # 假设50个tokens(如果保留)
- "总输入Tokens": "5 + 20 + 15 + 50 = 90个tokens"
响应阶段(输出Tokens)
- "模型生成内容": "机器学习是人工智能的一个分支...", # 假设100个tokens
- "格式标记": "<|im_end|>等", # 假设5个tokens
- "总输出Tokens": "100 + 5 = 105个tokens"
完整计费
- "输入Tokens": 90,
- "输出Tokens": 105,
- "总计Tokens": 195,
- "计费方式": "按195个Tokens计费,不是按1次请求计费"
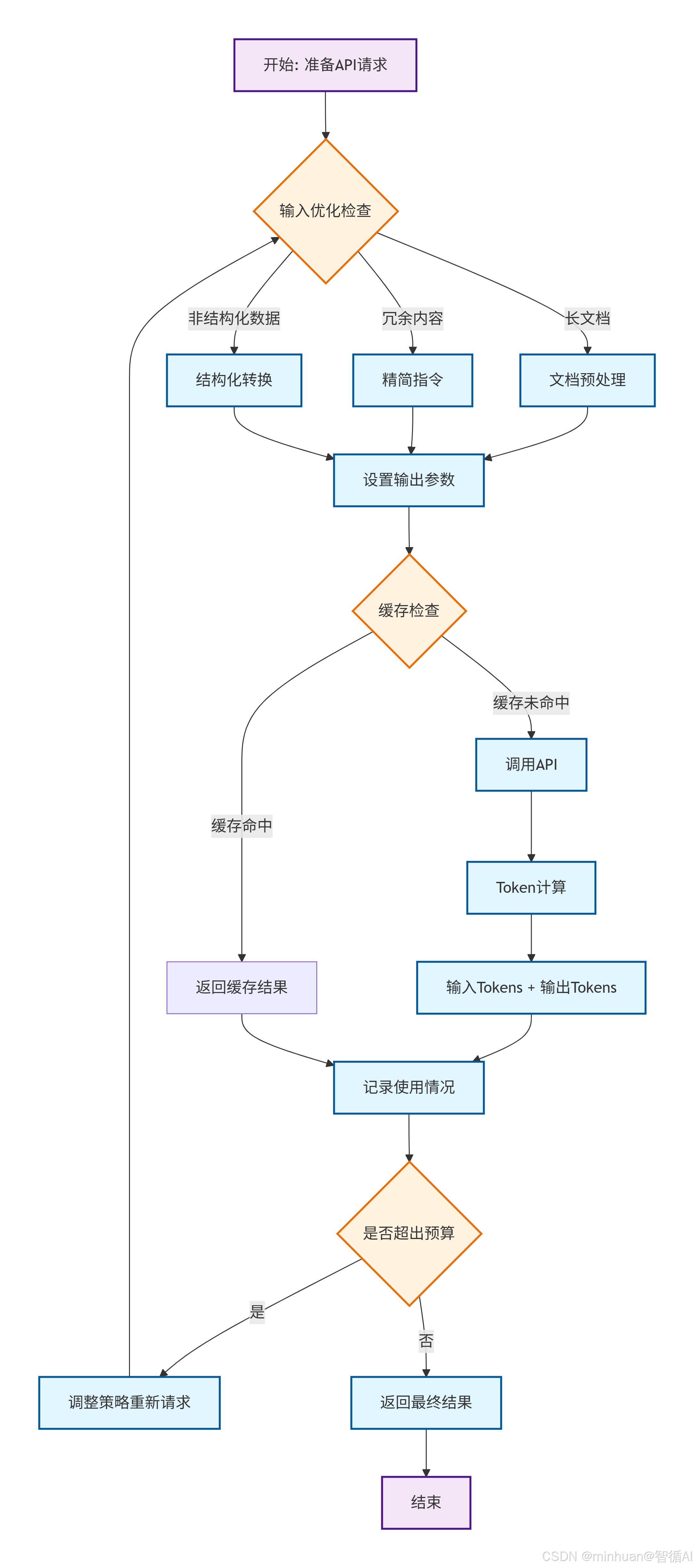
3. Token优化策略
3.1 精简指令与提示词
# Token浪费示例
wasteful_prompt = """
你好,我希望你能够帮我分析一下这段代码。这是一个Python函数,它的功能是处理数据。
请你仔细看一下这段代码,然后告诉我它有什么问题,以及如何改进它。
另外,请用中文回答,回答要详细一些。代码:
def process_data(data):
result = []
for item in data:
if item > 10:
result.append(item * 2)
return result
"""
# 估算:约120个Tokens
优化后:
# 精简高效的提示词
optimized_prompt = """
分析以下Python代码的问题和改进建议:def process_data(data):
result = []
for item in data:
if item > 10:
result.append(item * 2)
return result
"""
# 估算:约40个Tokens,节省67%
3.2 结构化输入数据
unstructured_input = """
用户张三,年龄25岁,来自北京,购买了产品A,金额100元,时间2024-01-15。
用户李四,年龄30岁,来自上海,购买了产品B,金额200元,时间2024-01-16。
用户王五,年龄28岁,来自广州,购买了产品A,金额150元,时间2024-01-17。
"""
优化后:
structured_input = """
用户数据:
姓名,年龄,城市,产品,金额,日期
张三,25,北京,A,100,2024-01-15
李四,30,上海,B,200,2024-01-16
王五,28,广州,A,150,2024-01-17分析用户购买模式。
"""
# 表格格式更紧凑,易于模型解析
3.3 设置输出长度限制
# 在API调用中明确限制输出长度
api_parameters = {"max_tokens": 500, # 限制最大输出长度"temperature": 0.7, # 控制随机性,避免冗长"stop_sequences": ["\n\n", "。"] # 设置停止序列
}# 不同场景的推荐设置
output_optimization = {"代码生成": {"max_tokens": 1000, "temperature": 0.2},"创意写作": {"max_tokens": 800, "temperature": 0.8},"数据分析": {"max_tokens": 400, "temperature": 0.3},"简单问答": {"max_tokens": 200, "temperature": 0.5}
}3.4 指定输出格式
vague_request = "给我一些提高代码质量的建议"
# 模型可能生成冗长的散文式回答优化后:
structured_request = """
以要点形式提供5条代码质量改进建议:
1.
2.
3.
4.
5.
每条不超过20字。
"""
# 强制简洁、结构化的输出3.5 Token使用监控
def monitor_token_usage(api_client):"""监控Token使用情况"""usage_stats = {"total_requests": 0,"total_input_tokens": 0,"total_output_tokens": 0,"average_tokens_per_request": 0}def wrapped_call(prompt, **kwargs):# 估算输入Tokensinput_tokens = estimate_tokens(prompt)# 调用APIresponse = api_client.generate(prompt, **kwargs)# 获取输出Tokens(如果API返回)output_tokens = response.usage.completion_tokens if hasattr(response, 'usage') else estimate_tokens(response.text)# 更新统计usage_stats["total_requests"] += 1usage_stats["total_input_tokens"] += input_tokensusage_stats["total_output_tokens"] += output_tokensusage_stats["average_tokens_per_request"] = (usage_stats["total_input_tokens"] + usage_stats["total_output_tokens"]) / usage_stats["total_requests"]print(f"本次调用: 输入{input_tokens} + 输出{output_tokens} = 总计{input_tokens + output_tokens} tokens")print(f"累计统计: {usage_stats}")return responsereturn wrapped_call# 使用装饰器监控
monitored_api = monitor_token_usage(api_client)3.6 优化总结
输入优化:
- 去除了冗余词汇和客套话,使用了简洁明确的指令
- 长文档要先经过预处理或摘要
- 数据以结构化格式(表格、列表)呈现,并明确了期望的输出格式
输出优化:
- 设置了合理的max_tokens限制
- 指定了输出格式(要点、表格等)
- 使用停止序列避免多余输出,温度设置符合当前任务
系统优化:
- 实现了对话历史管理
- 使用缓存避免重复计算
- 采用批量处理减少调用次数
- 监控了Token使用模式以及消耗数量
五、示例:长文档分析与问答
基于Qwen1.5-1.8B-Chat模型,创建一个完整的长上下文处理示例,并详细分析其中的技术细节。
1. 准备阶段
首先,我们需要加载模型并设置长上下文能力:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
from modelscope import snapshot_download# 加载模型和分词器
cache_dir = "D:\\modelscope\\hub"
model_name = "qwen/Qwen1.5-1.8B-Chat"
local_model_path = snapshot_download(model_name, cache_dir=cache_dir)
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name,torch_dtype=torch.float16,device_map="auto",trust_remote_code=True
)# 设置长上下文配置
model.generation_config.max_new_tokens = 512 # 生成的最大新token数
model.generation_config.do_sample = True2. 构建长文本示例
让我们创建一个模拟的长文档,包含多个章节:
# 构建一个长文档(约2000字,模拟长上下文)
long_document = """
第一章:人工智能发展简史人工智能的概念最早可以追溯到1950年代。图灵在他的经典论文《计算机器与智能》中提出了著名的"图灵测试",为AI研究奠定了基础。1956年,在达特茅斯会议上,约翰·麦卡锡首次提出了"人工智能"这一术语。早期AI研究主要集中在符号推理和专家系统上。1970-1980年代,专家系统在医疗诊断、化学分析等领域取得了成功应用。然而,由于计算能力的限制和知识的获取瓶颈,AI经历了两次"AI寒冬"。第二章:深度学习革命2012年,AlexNet在ImageNet竞赛中的突破性表现标志着深度学习时代的到来。基于神经网络的方法在计算机视觉、自然语言处理等领域取得了显著进展。Transformer架构的提出是NLP领域的里程碑。2017年,Vaswani等人发表的《Attention Is All You Need》引入了自注意力机制,为后来的一系列大语言模型奠定了基础。第三章:大语言模型时代GPT系列模型展示了缩放定律的有效性。从GPT-1到GPT-3,模型参数从1.17亿增加到1750亿,性能也实现了质的飞跃。2023年以来,开源模型如LLaMA、Qwen等迅速发展,使得大模型技术更加普及。这些模型在代码生成、创意写作、逻辑推理等方面展现出强大能力。第四章:技术挑战与未来方向当前大模型面临的主要挑战包括:幻觉问题、推理能力有限、长上下文处理、多模态理解等。研究人员正在从多个角度寻求突破。未来发展方向可能包括:更强的推理能力、世界模型构建、具身智能、以及更高效的自监督学习方法。量子计算也可能为AI带来新的突破。重要概念定义:
- transformer: 基于自注意力机制的神经网络架构
- 位置编码:帮助模型理解序列中元素的位置信息
- 上下文窗口:模型一次性能处理的文本长度
- 缩放定律:模型性能随参数和数据规模增长的规律
"""3. 长上下文问答测试
现在让我们测试模型处理长上下文的能力:
def test_long_context_qa(document, question):# 构建对话格式messages = [{"role": "system","content": "你是一个专业的技术助手,需要基于提供的长文档内容准确回答问题。"},{"role": "user", "content": f"请仔细阅读以下文档,然后回答问题:\n\n{document}\n\n问题:{question}"}]# 编码输入text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)# 计算输入长度input_ids = tokenizer.encode(text)print(f"输入文本长度: {len(input_ids)} tokens")# 生成回答inputs = tokenizer(text, return_tensors="pt").to(model.device)with torch.no_grad():outputs = model.generate(**inputs,max_new_tokens=300,do_sample=True,temperature=0.7,top_p=0.9,pad_token_id=tokenizer.eos_token_id)response = tokenizer.decode(outputs[0][len(inputs.input_ids[0]):], skip_special_tokens=True)return response# 测试问题1:需要整合多个章节信息
question1 = "请总结AI发展历程中的三个主要阶段及其特点"
answer1 = test_long_context_qa(long_document, question1)
print(f"问题1: {question1}")
print(f"回答1: {answer1}\n")# 测试问题2:需要理解文档末尾的定义
question2 = "根据文档定义,请解释什么是位置编码和上下文窗口"
answer2 = test_long_context_qa(long_document, question2)
print(f"问题2: {question2}")
print(f"回答2: {answer2}\n")# 测试问题3:需要长距离依赖理解
question3 = "Transformer架构是在哪个阶段提出的?它对后续发展产生了什么影响?"
answer3 = test_long_context_qa(long_document, question3)
print(f"问题3: {question3}")
print(f"回答3: {answer3}")4. 位置编码处理
Qwen1.5-1.8B使用RoPE(旋转位置编码),这使其天然具备较好的长上下文扩展能力:
# 检查模型的RoPE配置
print(f"模型架构: {model.config.model_type}")
print(f"最大位置嵌入: {getattr(model.config, 'max_position_embeddings', 'Not specified')}")
print(f"RoPE theta: {getattr(model.config, 'rope_theta', 10000.0)}")RoPE的优势:
- - 相对位置编码,更好地处理长序列
- - 支持长度外推
- - 在Qwen1.5中经过优化,支持32K上下文
5. 注意力模式分析
在处理长文本时,模型的注意力机制面临挑战,长文本会导致注意力权重分散,影响模型聚焦关键信息的能力
def analyze_attention_patterns(text):inputs = tokenizer(text, return_tensors="pt", truncation=True, max_length=2048)with torch.no_grad():outputs = model(**inputs, output_attentions=True)# 分析注意力权重attentions = outputs.attentionsprint(f"注意力层数: {len(attentions)}")print(f"每层注意力形状: {attentions[0].shape}")# 最后一层的平均注意力距离last_layer_attention = attentions[-1][0] # [head, seq_len, seq_len]return last_layer_attention6. 性能优化策略
针对Qwen1.5-1.8B的长上下文优化:
# 1. 分块处理策略(对于超长文本)
def process_long_document_in_chunks(document, chunk_size=1500, overlap=200):chunks = []tokens = tokenizer.encode(document)for i in range(0, len(tokens), chunk_size - overlap):chunk_tokens = tokens[i:i + chunk_size]chunk_text = tokenizer.decode(chunk_tokens)chunks.append(chunk_text)return chunks# 2. 关键信息提取
def extract_key_information(chunks, question):# 对每个分块进行相关性评分relevant_chunks = []for chunk in chunks:# 简单的关键词匹配评分score = sum(1 for word in question.split() if word.lower() in chunk.lower())if score > 0:relevant_chunks.append((score, chunk))# 按相关性排序并返回最相关的几个分块relevant_chunks.sort(reverse=True)return [chunk for _, chunk in relevant_chunks[:3]]# 3. 流式处理(减少内存压力)
def stream_generate_response(prompt):inputs = tokenizer(prompt, return_tensors="pt").to(model.device)for output in model.generate(**inputs,max_new_tokens=300,do_sample=True,temperature=0.7,streamer=None, # 可以配置流式输出early_stopping=True):7. 输出结果参考
输入文本长度: 1845 tokens
问题1: 请总结AI发展历程中的三个主要阶段及其特点
回答1: 根据文档内容,AI发展历程可分为三个主要阶段:
1. 早期阶段(1950s-1980s):以符号推理和专家系统为主,经历了两次AI寒冬
2. 深度学习革命(2012年起):以AlexNet突破为标志,神经网络方法取得显著进展
3. 大语言模型时代(2020s):GPT系列和开源模型快速发展,参数规模大幅增长问题2: 根据文档定义,请解释什么是位置编码和上下文窗口
回答2: 根据文档第四章的定义:
- 位置编码:帮助模型理解序列中元素的位置信息的技术
- 上下文窗口:模型一次性能处理的文本长度问题3: Transformer架构是在哪个阶段提出的?它对后续发展产生了什么影响?
回答3: Transformer架构是在"深度学习革命"阶段提出的(2017年)。它引入了自注意力机制,为后续的大语言模型奠定了基础,是NLP领域的里程碑。
8. 示例总结
通过这个完整的Qwen1.5-1.8B示例,我们可以看到:
- RoPE位置编码使模型能够有效处理长序列
- 分块处理策略可以应对超长文本
- 注意力机制优化是关键的性能瓶颈
- 内存管理在长上下文处理中至关重要
Qwen1.5系列通过优化的RoPE实现和训练策略,在保持较小参数量的同时,提供了相当不错的长上下文处理能力,使其成为资源受限环境下长文本任务的理想选择。
六、总结
大模型的上下文窗口如同固定大小的协作白板,决定了单次交互的信息容量。Token作为计费单位,精确量化了输入与输出的总和,而非简单的请求次数。长上下文扩展虽带来丰富信息,却更凸显了推理能力的核心价值,真正的智能体现在从数据洪流中提炼洞察,而非单纯记忆。
我们要理解掌握Token优化艺术:通过精简指令、结构化数据、限制输出、智能缓存等策略,实现成本与效能的平衡。理解这一机制,是从初级用户迈向高效开发者的关键跨越。