监督对齐DPO算法实例讲解
DPO 让AI学会自我纠错
还在用复杂的RLHF?DPO(直接偏好优化)正以更简单、更高效的方式,教会AI如何自我反思和择优学习。
1 告别RLHF
先看DPO的前辈:RLHF(人类反馈强化学习)。
RLHF的痛点:像个复杂的三级火箭。第一级SFT(监督微调)先教会模型说话;第二级训练一个奖励模型(RM)来当裁判;第三级用强化学习(RL)让模型在裁判的打分下刷分。这套流程极其复杂、不稳定、且难以调试。
DPO的革命:DPO(直接偏好优化)的洞察是,根本不需要一个独立的裁判(RM),也不需要复杂的强化学习(RL)。跳过了奖励建模和强化学习,直接将偏好转换为了一个巧妙的损失函数。它只需要好答案(Chosen)和坏答案(Rejected)的对比数据,就能直接微调语言模型本身,让模型学会提高好答案的概率,降低坏答案的概率。
2 DPO训练双雄
DPO的训练过程比RLHF简洁得多,需要两个模型和一种数据。
数据:偏好三元组:DPO的数据格式是 (Prompt, Chosen, Rejected)。
Prompt:用户指令或问题。*Chosen (y_w):更被偏好的、更好的回答。*Rejected (y_r):不被偏好的、较差的回答。
模型:策略与参考:DPO训练时,内存中有两个模型:
-
策略模型:这就是我们正在训练的模型(比如SFT微调后的模型)。它的参数会在训练中不断更新,是我们的学生。
-
参考模型:这是学生在训练开始前的一个快照(初始副本)。它的参数在整个训练过程中保持冻结,像一个锚,用来防止学生在学习新偏好时,忘记了SFT阶段学到的基础知识。
| 核心概念 | 关键特征 | 举例说明 |
|---|---|---|
| 策略模型 | 正在被训练的模型,参数会更新 | 我们的学生模型,比如 Qwen-4B-SFT |
| 参考模型 | 策略模型的初始副本,参数冻结 | SFT的快照,用来衡量学生有没有跑偏 |
| 偏好数据 | (Prompt, Chosen, Rejected) | (问题, 好答案, 坏答案) |
DPO的核心训练循环,损失函数会同时评估两个模型对好坏答案的看法
3 AI自我纠错
背景:假设有一个SFT微调过的小模型(学生,如Qwen-4B-SFT),它在某些任务上准确率不高,思维链(CoT)质量也差。
生成 Rejected (坏答案):把问题(Prompt)喂给我们的学生(Qwen-4B-SFT)。如果它回答错误,太好了!这个错误的结果 + 错误的CoT就是完美的 Rejected 数据。这是模型自己犯的错,是最好的负面教材。
生成 Chosen (好答案):我们知道这个问题的正确结果。调用一个能力极强的大模型(老师,如Qwen-235B)。要求老师:请基于这个‘正确结果’,生成一个逻辑清晰、高质量的CoT。这个正确的结果 + 优质的CoT就是完美的 Chosen 数据。
通过DPO训练,学生模型不仅学会了正确答案,更学会了老师的优质思维方式。
| 角色 | 任务 | 来源 |
|---|---|---|
| Prompt | 用户的提问 | 数据集 |
| Rejected (坏) | 小模型自己生成的错误答案+错误CoT | Qwen-4B-SFT (学生) |
| Chosen (好) | 大模型生成的正确答案+优质CoT | Qwen-235B (老师) |
这幅图展示了如何自动化构建DPO偏好数据,实现小模型犯错,大模型纠正
4 概率计算揭秘
DPO的核心是比较概率。但模型是如何计算一个完整回答(比如北京。)的概率的呢?
自回归:语言模型的天性是逐字预测。它不是一次性算出整个句子的概率。
概率链式法则:一个句子的总概率,等于句子中每个词的条件概率的连乘积。
- P(“北京。”) = P(“北” | Prompt) * P(“京” | Prompt, “北”) * P(“。” | Prompt, “北”, “京”)
对数概率:在实际工程中,无数个小于1的概率连乘,会导致浮点数下溢(数字小到计算机无法表示)。因此使用对数概率,将乘法变为加法,计算更稳定高效。
log P("北京。") = log P("北") + log P("京") + log P("。")
DPO的计算:DPO训练时,模型会对 Prompt + Chosen 和 Prompt + Rejected 分别执行一次前向传播,然后只提取回答部分(Chosen/Rejected)所有token的对数概率并求和,得到最终的总分。
| 核心概念 | 关键特征 | 举例说明 |
|---|---|---|
| 自回归 | 逐字(token)生成,后面依赖前面 | 预测京时,模型已经看到了北 |
| 概率连乘 | 整个句子的概率 = 每个词的条件概率相乘 | P(“A B”) = P(“A”) * P(“B” |
| 对数概率 | 将乘法变加法,防止浮点数下溢,计算更稳定 | log P(“A B”) = log P(“A”) + log P(“B” |
5 认知飞跃
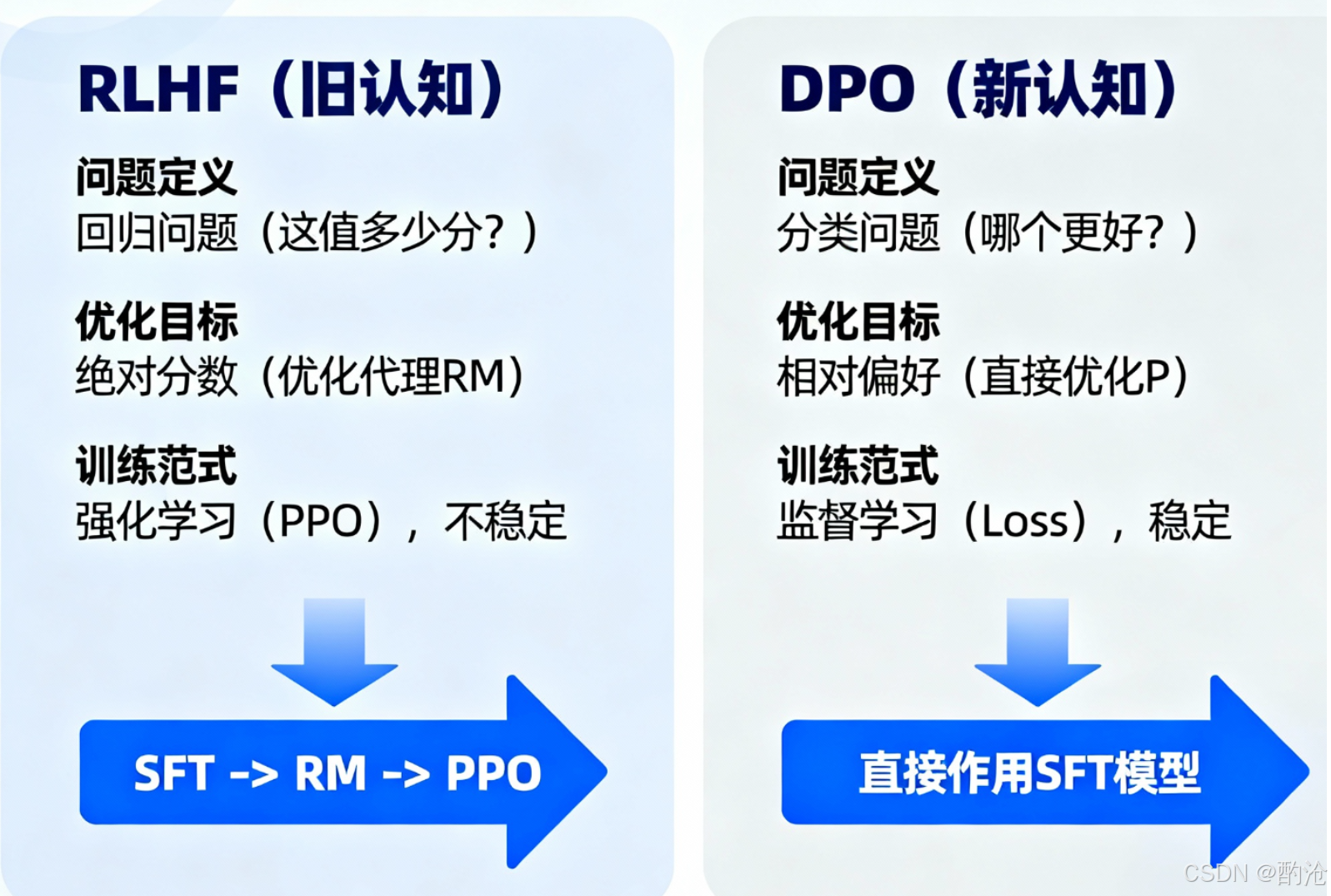
从RLHF到DPO,代表了AI对齐思路上的一次重大认知升级。
1. 从绝对标准到相对偏好
RLHF的困境:先训练一个奖励模型(RM),让这个RM去回答:这个答案在0到100分之间,到底能打多少分? 这是一个回归问题。不仅人类标注者对7分和8分的界限很模糊,训练出来的RM也很可能被模型钻空子。
DPO的智慧:只需要知道‘A比B好’就够了。 把问题从困难的回归问题降维到了简单的分类问题。
2. 从间接优化到直接对齐
RLHF的绕路:它的优化链条太长:SFT -> RM -> PPO。最终的模型(PPO)是在优化一个代理目标(RM的打分)。
DPO的直达:DPO是端到端的。它的损失函数直接将偏好(A>B)这个信号作用在SFT模型上。没有中间商(RM)赚差价,优化目标就是最大化Chosen的概率,最小化Rejected的概率。
2. 从间接优化到直接对齐**
RLHF的绕路:它的优化链条太长:SFT -> RM -> PPO。最终的模型(PPO)是在优化一个代理目标(RM的打分)。
DPO的直达:DPO是端到端的。它的损失函数直接将偏好(A>B)这个信号作用在SFT模型上。没有中间商(RM)赚差价,优化目标就是最大化Chosen的概率,最小化Rejected的概率。