AI小白入门:什么是RAG技术?
图片来源网络,侵权联系删
文章目录
- 一、RAG技术的核心定义与演进
- 二、RAG增强大模型生成能力的核心机制
- 1. 检索(Retrieval):从外部知识库获取精准信息
- 2. 增强(Augment):将检索信息与用户问题融合
- 3. 生成(Generate):基于事实生成准确回答
- 三、RAG增强大模型生成能力的关键价值
- 1. 抑制幻觉,提升准确性
- 2. 动态更新知识,解决时效性问题
- 3. 可控性强,支持个性化配置
- 四、RAG技术的应用场景与案例
- 1. 东航智能客服(传统RAG)
- 2. 一汽丰田智能客服(RAG+多模态)
- 3. B站智能客服(Agentic RAG+GraphRAG)
- 五、总结与展望

一、RAG技术的核心定义与演进
RAG(Retrieval-Augmented Generation,检索增强生成)是一种将外部知识库与大语言模型(LLM)深度融合的人工智能技术,其核心逻辑是通过“检索-增强-生成”的工程化闭环,为大模型注入动态、可控的外部事实库,将模型的生成过程从“无据猜测”转变为“有据可依”的推理。
自2020年由Facebook AI Research提出以来,RAG技术不断演进,2025年已形成四大主流架构,以解决传统RAG的局限性:
- 传统RAG:采用“检索→拼接→生成”的简单流程,适用于企业内部简单知识问答,但知识库更新需重新构建索引,且仅支持单轮检索。
- 多模态RAG:支持文本、图像、视频、音频等多种数据类型的检索与生成,通过OCR(光学字符识别)和多模态Embedding模型(如阿里Qwen3-Embedding)实现跨模态理解。
- Agentic RAG:引入智能体(Agent)实现自主决策,可动态调整检索时机与策略(如多轮检索、迭代优化),适用于复杂任务(如订单管理、营销策略生成)。
- GraphRAG:结合知识图谱(Graph)建模实体间结构化关系,通过图神经网络(GNN)挖掘深层关联,提升推理能力(如法律条文分析、历史事件溯源)。
二、RAG增强大模型生成能力的核心机制
RAG通过三个关键步骤(检索→增强→生成),从“知识获取”到“内容输出”全链路提升大模型的生成能力,具体作用如下:
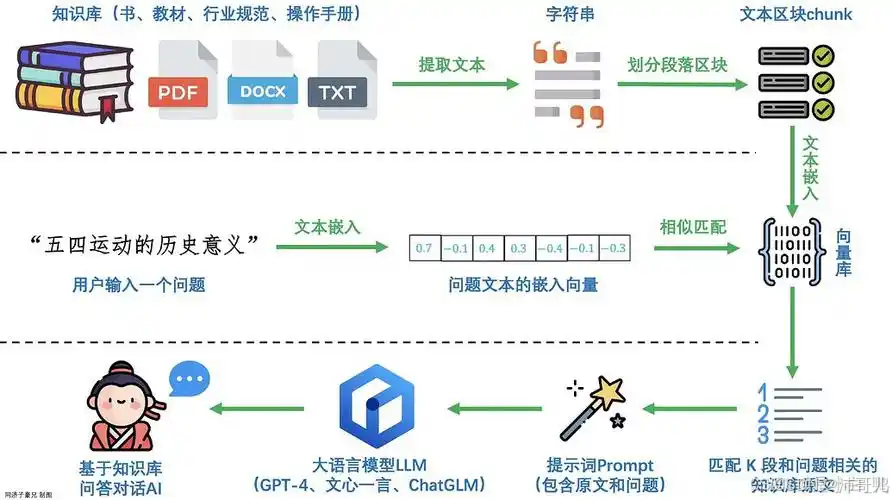
1. 检索(Retrieval):从外部知识库获取精准信息
检索是RAG的“事实输入”环节,其目标是从海量知识库中定位与用户查询最相关的信息片段。这一过程依赖语义检索技术(如向量嵌入、余弦相似度计算),而非传统的关键词匹配,因此能更精准地捕捉查询的语义意图。
-
技术演进:
- 传统RAG采用单一向量检索(如FAISS、Milvus),但2025年已发展为混合检索(向量检索+关键词检索),并通过ReRank机制(如交叉编码器)对候选结果进行精细化排序。
- 多模态RAG通过OCR技术(如百度OCR)将图像/表格转换为文本,再结合多模态Embedding模型(如Qwen3-Embedding)实现跨模态检索。
-
对生成能力的提升:
检索环节为大模型提供了外部事实依据,避免了模型因“内部知识缺失”而编造信息(即“幻觉”)。例如,当用户询问“某款新手机的电池容量”时,RAG会从企业产品手册中检索到准确数据,而非让模型“猜测”。
2. 增强(Augment):将检索信息与用户问题融合
增强是RAG的“上下文构建”环节,其目标是将检索到的知识片段与用户问题整合为一个逻辑连贯的提示(Prompt),引导模型基于事实生成回答。
-
技术演进:
- 传统RAG采用简单拼接(用户问题+检索结果),但2025年已发展为动态增强(如Agentic RAG的“查询优化”:将模糊表述修正为精准查询,如“那个做手机的科技公司最新折叠屏”→“苹果公司2025年发布的折叠屏智能手机型号及技术参数”)。
-
对生成能力的提升:
增强环节将“外部知识”与“用户需求”绑定,使模型的生成过程更聚焦。例如,当用户询问“如何用Python读取Excel文件”时,RAG会将检索到的“Pandas库使用教程”与问题结合,引导模型生成具体的代码示例,而非泛泛而谈。
3. 生成(Generate):基于事实生成准确回答
生成是RAG的“输出”环节,其目标是利用增强后的提示,让LLM生成符合事实、逻辑连贯的回答。此时,LLM的生成过程不再是“纯概率预测”,而是“基于事实的推理”。
-
技术演进:
- 传统RAG采用单轮生成,但2025年已发展为多轮生成(如Agentic RAG的“迭代优化”:若生成结果存在数据过时问题,自动返回检索环节重新获取最新信息)。
- 多模态RAG支持跨模态生成(如根据图像生成描述、根据文本生成视频片段)。
-
对生成能力的提升:
生成环节的“事实约束”显著降低了模型的“幻觉率”。例如,在医疗领域,RAG引导模型基于最新的医学指南生成诊断建议,而非编造未经证实的治疗方法;在法律领域,模型基于最新的法律条文生成法律意见,确保准确性。

三、RAG增强大模型生成能力的关键价值
RAG通过上述机制,从准确性、时效性、可控性三个维度彻底提升了大模型的生成能力:
1. 抑制幻觉,提升准确性
RAG的“事实锚点”设计让模型生成的内容有据可查,有效缓解了LLM“一本正经胡说八道”的问题。例如,某智能客服系统采用RAG后,回答的“事实错误率”从15%降至2%。
2. 动态更新知识,解决时效性问题
RAG的外部知识库可实时更新(如每日同步企业产品手册、每周更新行业报告),解决了LLM“知识固化”的局限。例如,金融领域的RAG系统可实时同步监管文件,确保模型生成的“投资建议”符合最新政策。
3. 可控性强,支持个性化配置
RAG的知识库可按需定制(如企业私有数据、特定领域知识),无需重新训练LLM即可注入新信息。例如,某电商企业通过RAG接入“产品库存数据”,让模型实时回答“某款商品的库存情况”,无需修改模型参数。
四、RAG技术的应用场景与案例
RAG技术已广泛应用于智能客服、医疗诊断、法律咨询、金融分析等场景,以下是2025年的典型案例:
1. 东航智能客服(传统RAG)
东航推出基于RAG的AI业务助手,融合大模型与224本业务手册(包括81个公司级文件和143个部门/岗位级文件),实现“检索-生成-溯源”三阶段机制。客服人员处理行李规定、航班改签等问题时,AI可从业务手册中检索相关内容,生成简明易懂的解答,并自动标注答案来源章节。该应用上线一个月以来,覆盖9100多名一线业务骨干,效率提升了数十倍。
2. 一汽丰田智能客服(RAG+多模态)
一汽丰田借助腾讯云大模型知识引擎RAG能力,让DeepSeek大模型更好地理解和处理企业专属知识(如车型参数、售后服务政策)。通过OCR技术将纸质手册转换为文本,结合多模态Embedding模型实现跨模态检索,智能在线客服机器人独立解决率从37%提升至84%,月均自动解决客户咨询问题1.7万次。
3. B站智能客服(Agentic RAG+GraphRAG)
B站将RAG与Agentic RAG、GraphRAG结合,构建覆盖UP主规则、番剧版权、稿件审核等场景的智能客服系统。通过Agentic RAG的“查询优化”(如将“UP主违规处罚流程”修正为“B站2025年UP主违规行为分类及处罚标准”),结合GraphRAG的知识图谱(建模UP主、违规行为、处罚标准间的关系),智能客服拦截率(无需人工介入的成功回答比例)显著提升,某些业务场景达到20%以上的提升。

五、总结与展望
RAG技术的核心价值在于为大模型提供了“动态、可控的事实引擎”,通过“检索→增强→生成”的闭环,将模型的生成过程从“无据猜测”转变为“有据可依”的推理。随着技术的演进(如Agentic RAG、GraphRAG的出现),RAG正朝着更智能、更精准、更可控的方向发展,未来将进一步拓展至多模态交互、自主决策、复杂推理等场景,成为大模型商业化落地的关键技术之一。
对于企业而言,选择RAG技术时需结合业务需求(如是否需要实时更新、是否需要多模态支持)、数据特征(如是否为结构化数据、是否需要知识图谱)和技术条件(如是否有足够的算力支持),选择合适的RAG架构(如传统RAG、多模态RAG、Agentic RAG),以实现技术与业务的最佳匹配。