唯品会口红数据采集:双请求策略与JSON数据爬取实战
目录
引言
项目目标
效果展示
网站抓包分析过程
抓包分析步骤详解
步骤1:开启开发者工具
步骤2:识别数据接口
步骤3:分析请求详情
步骤4:认证机制分析
步骤5:构建完整请求流程
关键发现
需求分析
主要需求:
技术需求:
实现步骤
步骤1:环境准备和库导入
步骤2:Excel工作表初始化
步骤3:请求头配置和会话初始化
步骤4:Cookies配置
步骤5:API接口配置
步骤6:分页数据采集策略
步骤7:第一次请求参数配置
步骤8:发送第一次请求和获取商品ID列表
步骤9:商品ID分批处理策略
步骤10:第二次请求参数配置
步骤11:发送第二次请求和解析商品详情
步骤12:商品基本信息提取
步骤13:价格信息提取
步骤14:商品属性信息提取
步骤15:详情页链接构建
步骤16:数据保存和输出
步骤17:错误处理和资源清理
完整代码
技术深度解析
抓包分析技术要点
双请求架构优势
JSONP数据处理技术
智能分批策略
健壮的数据提取
详情页链接构建
应用场景与价值
法律和道德声明
技术总结
引言
在时尚美妆电商蓬勃发展的今天,唯品会作为中国领先的品牌特卖电商平台,汇聚了众多国内外知名美妆品牌。其中,口红作为美妆行业的明星品类,具有极高的市场关注度和研究价值。与传统的单次请求数据采集不同,本项目通过分析唯品会独特的双请求API架构,实现了高效、稳定的口红商品数据采集系统。
唯品会平台采用了复杂的数据加载机制,需要先获取商品ID列表,再通过二次请求获取详细商品信息。这种架构设计既保证了数据的安全性,又提升了用户体验。本项目通过深入分析这一机制,构建了完整的数据采集解决方案。
在数据采集过程中,我们严格遵守相关法律法规和平台使用条款,仅将数据用于技术学习和市场研究,尊重平台的数据安全和商家隐私。
项目目标
本项目旨在构建一个高效的唯品会平台口红数据采集系统,能够自动获取平台上的商品详细信息,并按标准化格式保存为可分析的数据文件。
具体目标包括:
-
分析唯品会平台的双请求API接口结构
-
配置完整的请求头和认证参数
-
实现商品ID列表获取与详细数据采集的分离处理
-
处理JSONP格式的数据响应
-
提取商品标题、品牌、价格、属性等多个维度的关键指标
-
处理分页加载和大批量数据获取机制
-
构建完整的商品详情页链接
-
将处理后的数据保存为结构化Excel文件
效果展示

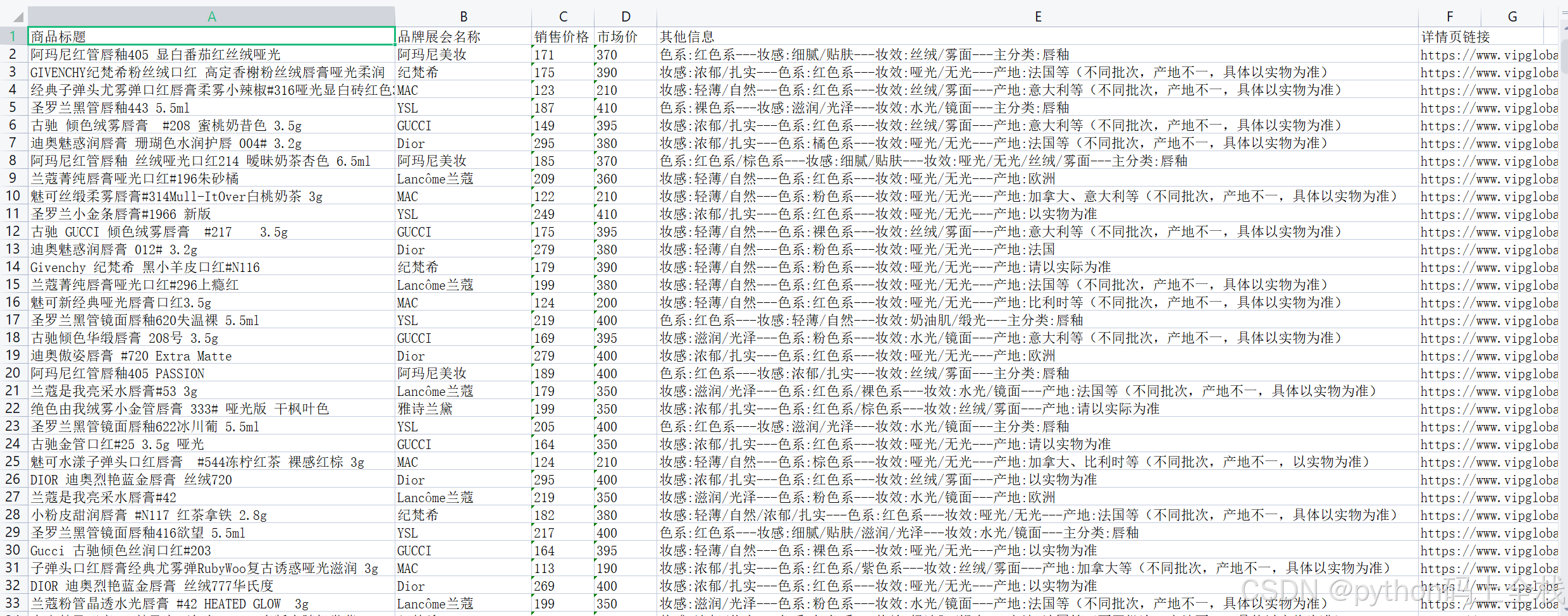
网站抓包分析过程
抓包分析步骤详解
步骤1:开启开发者工具
首先打开唯品会网站,按F12键打开浏览器开发者工具:
-
打开唯品会官网:https://www.vip.com
-
按F12打开开发者工具
-
点击"Network"(网络)选项卡
-
在搜索框中输入"口红"开始搜索
-
刷新页面开始记录网络请求
步骤2:识别数据接口
在网站中浏览商品列表,观察网络请求的变化:
-
筛选XHR/Fetch请求:在筛选器中输入XHR或Fetch,过滤出数据接口
-
观察请求模式:注意观察在翻页或滚动加载时出现的重复请求模式
-
识别关键接口:发现两个关键接口:
-
商品ID列表接口:
/vips-mobile/rest/shopping/pc/search/product/rank -
商品详情接口:
/vips-mobile/rest/shopping/pc/product/module/list/v2
-
步骤3:分析请求详情
点击具体的请求,查看详细信息:
第一次请求(商品ID列表)分析:
请求头分析:
GET /vips-mobile/rest/shopping/pc/search/product/rank?callback=getMerchandiseIds&app_name=shop_pc&... HTTP/1.1
Host: mapi-pc.vip.com
Content-Type: application/x-www-form-urlencoded; charset=UTF-8
User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36
Referer: https://category.vip.com/请求参数分析:
callback: getMerchandiseIds
app_name: shop_pc
app_version: 4.0
keyword: 口红
pageOffset: 0
batchSize: 120响应数据分析:
getMerchandiseIds({"data": {"products": [{"pid": "6920871310745952780","brandId": "1710621388"}]}
})第二次请求(商品详情)分析:
请求参数分析:
callback: getMerchandiseDroplets1
app_name: shop_pc
productIds: 6920871310745952780,6920871310745952781,...
extParams: {"stdSizeVids":"","preheatTipsVer":"3","couponVer":"v2",...}响应数据分析:
getMerchandiseDroplets1({"data": {"products": [{"title": "迪奥烈艳蓝金唇膏","brandShowName": "Dior迪奥","price": {"salePrice": "350.00","marketPrice": "450.00"},"attrs": [{"name": "颜色", "value": "999正红色"},{"name": "质地", "value": "丝绒"}],"productId": "6920871310745952780","brandId": "1710621388"}]}
})步骤4:认证机制分析
通过分析请求参数,发现唯品会平台采用了多种认证机制:
-
用户身份认证:user_id、mars_cid等用户标识参数
-
API密钥验证:api_key字段,用于接口访问权限控制
-
时间戳防重放:_参数,使用当前时间戳防止请求重放
-
令牌验证:tfs_fp_token,前端生成的指纹令牌
-
区域验证:fdc_area_id、province_id等区域标识参数
步骤5:构建完整请求流程
基于抓包分析,构建完整的Python双请求流程:
# 第一次请求获取商品ID列表
response1 = requests.get(url1, headers=headers, cookies=cookies, params=params1)
product_ids = extract_product_ids(response1.text)
# 第二次请求获取商品详细信息
response2 = requests.get(url2, headers=headers, cookies=cookies, params=params2)
product_details = extract_product_details(response2.text)关键发现
通过抓包分析,我们获得了以下重要信息:
-
双请求架构:唯品会采用先获取ID列表,再获取详情的双请求机制
-
数据接口:
-
ID列表接口:
https://mapi-pc.vip.com/vips-mobile/rest/shopping/pc/search/product/rank -
详情接口:
https://mapi-pc.vip.com/vips-mobile/rest/shopping/pc/product/module/list/v2
-
-
请求方法:GET
-
数据格式:JSONP格式的响应,需要正则提取
-
分页机制:通过pageOffset和batchSize控制分页,每页120个商品
-
数据分批:详情请求需要将商品ID分批,每批最多50个
需求分析
唯品会网站采用了复杂的双请求API架构,需要正确的请求参数和认证信息才能获取数据。
主要需求:
-
配置完整的请求头和认证参数
-
实现双请求策略:先获取商品ID列表,再获取详细信息
-
处理JSONP格式响应,使用正则表达式提取JSON数据
-
解析复杂的嵌套JSON结构提取商品信息
-
处理分页加载和大批量数据获取机制
-
构建商品详情页链接
-
提取多个维度的商品信息
技术需求:
-
使用requests库发送HTTP请求
-
使用re库处理JSONP响应格式
-
使用json库处理数据格式
-
处理复杂的分页和分批逻辑
-
完善的错误处理和数据处理机制
实现步骤
步骤1:环境准备和库导入
首先导入必要的Python库,为项目提供基础技术支持。
import requests
import re
import json
import time
from openpyxl import Workbook详细说明:
-
requests提供HTTP请求功能,能够发送GET请求获取数据 -
re提供正则表达式功能,用于处理JSONP格式响应 -
json提供JSON数据处理功能 -
time提供时间戳生成功能 -
openpyxl用于Excel文件操作和数据存储,支持大规模数据导出
步骤2:Excel工作表初始化
创建Excel工作表并设置专业的表头结构,覆盖商品分析的各个维度。
# 创建excel工作表
wb = Workbook()
# 获取活动工作表
ws = wb.active
# 设置表头
ws.append(['商品标题', '品牌展会名称', '销售价格', '市场价', '其他信息', "详情页链接"])详细说明:
-
使用
Workbook()创建新的Excel工作簿 -
ws.active获取默认的工作表 -
ws.append()设置详细的表头字段,涵盖商品基本信息、价格、品牌等关键指标 -
表头设计考虑了美妆商品的特有属性,如品牌信息和详情页链接
步骤3:请求头配置和会话初始化
基于抓包分析结果,精心配置请求头参数,包含完整的认证信息。
headers = {"Accept": "*/*","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","Connection": "keep-alive","Referer": "https://category.vip.com/","Sec-Fetch-Dest": "script","Sec-Fetch-Mode": "no-cors","Sec-Fetch-Site": "same-site","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0","sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\""
}详细说明:
-
配置完整的请求头信息,模拟真实浏览器行为
-
Sec-Fetch-*系列头信息表明请求的上下文和目的 -
Referer设置为搜索页面的URL,确保请求的合法性 -
User-Agent标识浏览器类型和版本,避免被识别为爬虫
步骤4:Cookies配置
配置必要的cookies信息,维持会话状态和用户身份。
cookies1 = {......}详细说明:
-
配置完整的cookies信息,包含用户身份认证令牌
-
PASSPORT_ACCESS_TOKEN是用户登录凭证,对于访问受限资源至关重要 -
tfs_fp_token是前端生成的指纹令牌,用于反爬虫验证 -
这些cookies对于维持会话状态和通过身份验证至关重要
步骤5:API接口配置
配置数据接口的URL地址。
url = "https://mapi-pc.vip.com/vips-mobile/rest/shopping/pc/search/product/rank"详细说明:
-
通过浏览器开发者工具分析找到数据API接口
-
URL为唯品会搜索数据接口地址
-
这种直接调用API的方式比页面解析更高效
步骤6:分页数据采集策略
实现智能的分页数据采集,通过外层循环控制页码。
for page in range(0, 6):pageOffset = page * 120print(f"正在爬取第{page + 1}页的数据内容")详细说明:
-
循环控制页码(0-5页),对应1-6页的实际显示
-
pageOffset计算偏移量,唯品会使用偏移量而非页码进行分页 -
每页获取120个商品,适合大规模数据采集
-
实时打印采集进度,提供操作反馈
步骤7:第一次请求参数配置
基于抓包分析,配置获取商品ID列表的请求参数。
params = {"callback": "getMerchandiseIds","app_name": "shop_pc","app_version": "4.0","warehouse": "VIP_NH","fdc_area_id": "104104101","client": "pc","mobile_platform": "1","province_id": "104104","api_key": "70f71280d5d547b2a7bb370a529aeea1","user_id": "645762488","mars_cid": "1762691744964_5f9e9bc0bae26551c563c283cb2a12bb","wap_consumer": "b","is_default_area": "1","standby_id": "nature","keyword": "口红","lv3CatIds": "","lv2CatIds": "","lv1CatIds": "","brandStoreSns": "","props": "","priceMin": "","priceMax": "","vipService": "ch11","sort": "0","pageOffset": pageOffset,"channelId": "1","gPlatform": "PC","batchSize": "120","tfs_fp_token": "BhIPr/K3uf5k4idKwcFfrUJFayPSF6qauzCjnIy+/5sBJdqdG4knl1kOMMs5UECqq3E7QzU/8nqoF16haA5KDXg==","_": str(int(time.time() * 1000))
}详细说明:
-
callback指定JSONP回调函数名 -
keyword指定搜索关键词为"口红" -
pageOffset和batchSize控制分页,每页120个商品 -
api_key是API访问密钥,通过抓包获取 -
tfs_fp_token是重要的反爬虫令牌 -
_参数使用当前时间戳,防止请求缓存
步骤8:发送第一次请求和获取商品ID列表
发送GET请求获取JSONP格式的商品ID数据,并进行解析。
# 响应商品ID
respond_to_the_product_id = requests.get(url, headers=headers, cookies=cookies1, params=params)
# 初始化结果列表
res_products_id_list = []
# 定义时间戳
time_str = str(int(time.time() * 1000))
if respond_to_the_product_id.status_code == 200:respond_to_the_product_id_text = respond_to_the_product_id.textres = re.search(r'getMerchandiseIds\((.*?)\)', respond_to_the_product_id_text)if res:respond_to_the_product_id_json_data = json.loads(res.group(1))# 提取商品id列表products_id_list = respond_to_the_product_id_json_data["data"]["products"]# 遍历商品idfor num, products_id_item in enumerate(products_id_list):products_id = products_id_item["pid"]res_products_id_list.append(products_id)详细说明:
-
使用
requests.get()发送GET请求获取数据 -
检查响应状态码,确保请求成功
-
使用正则表达式提取JSONP响应中的JSON数据
-
json.loads()解析JSON格式的数据 -
从响应结构中提取商品ID列表
-
遍历商品ID列表,收集所有商品ID
步骤9:商品ID分批处理策略
将获取的商品ID列表进行分批,为第二次请求做准备。
for node in range(1, 4):print(f'正在请求第{page+1}页的第{node}个数据包......')if node == 1:callback = "getMerchandiseDroplets1"products_id_str = ",".join(res_products_id_list[0:50]) + ","print(f"数据包数量:{len(res_products_id_list[0:50])}")elif node == 2:callback = "getMerchandiseDroplets2"products_id_str = ",".join(res_products_id_list[50:100]) + ","print(f"数据包数量:{len(res_products_id_list[50:100])}")else:callback = "getMerchandiseDroplets3"products_id_str = ",".join(res_products_id_list[100:120]) + ","print(f"数据包数量:{len(res_products_id_list[100:120])}")详细说明:
-
将每页120个商品ID分成3个批次进行请求
-
第一批:前50个商品ID
-
第二批:中间50个商品ID
-
第三批:最后20个商品ID
-
使用不同的
callback函数名区分不同批次的响应 -
将商品ID列表转换为逗号分隔的字符串格式
-
实时打印每个批次的数据量,提供进度反馈
步骤10:第二次请求参数配置
配置获取商品详细信息的请求参数。
params2 = {"callback": callback,"app_name": "shop_pc","app_version": "4.0","warehouse": "VIP_NH","fdc_area_id": "104104101","client": "pc","mobile_platform": "1","province_id": "104104","api_key": "70f71280d5d547b2a7bb370a529aeea1","user_id": "645762488","mars_cid": "1762691744964_5f9e9bc0bae26551c563c283cb2a12bb","wap_consumer": "b","is_default_area": "1","productIds": products_id_str,"scene": "search","standby_id": "nature","extParams": "{\"stdSizeVids\":\"\",\"preheatTipsVer\":\"3\",\"couponVer\":\"v2\",\"exclusivePrice\":\"1\",\"iconSpec\":\"2x\",\"ic2label\":1,\"superHot\":1,\"bigBrand\":\"1\"}","context": "","tfs_fp_token": "BicZo59YoUtMcHQ2N7Oc1sob/0fqL22e7a4+g9t3NjweEyw2j8YasJyUJqQYo6G4H6qMfwaurjfuX1MjG3CygDA==","_": time_str
}详细说明:
-
productIds参数包含批次的商品ID字符串 -
extParams包含扩展参数,以JSON字符串格式传递 -
scene参数指定请求场景为搜索 -
使用与第一次请求相同的认证参数,确保会话一致性
-
callback参数根据批次动态设置
步骤11:发送第二次请求和解析商品详情
发送GET请求获取商品详细信息,并进行数据提取。
response2 = requests.get(url2, headers=headers, cookies=cookies2, params=params2)
if response2.status_code == 200:response_json_data = ""
response_text = response2.text# 使用一个正则表达式匹配所有三种情况pattern = r'getMerchandiseDroplets\d+\(\s*(\{.*\})\s*\)'res = re.search(pattern, response_text)
if res:response_json_data = json.loads(res.group(1))else:print('正则匹配失败')continue详细说明:
-
发送第二次请求获取商品详细信息
-
使用动态正则表达式匹配不同批次的JSONP响应
-
json.loads()解析JSON格式的商品数据 -
处理正则匹配失败的情况,确保程序健壮性
步骤12:商品基本信息提取
从JSON响应中提取商品的基本标识信息。
if response_json_data:# 商品列表products_list = response_json_data["data"]["products"]if products_list:print(f"获取到商品数目为:{len(products_list)}")# 遍历商品列表for products_item in products_list:products_item_dict = {}# 商品标题title = products_item["title"]products_item_dict["商品标题"] = title if title else "无"# 品牌展会名称brandShowName = products_item["brandShowName"]products_item_dict["品牌展会名称"] = brandShowName if brandShowName else "无"详细说明:
-
从JSON结构中提取商品信息列表
-
验证数据列表是否为空,避免处理无效数据
-
为每个商品创建字典对象存储信息
-
提取商品标题和品牌名称,这是美妆商品的核心标识
-
设置安全检查,为可能缺失的字段提供默认值
步骤13:价格信息提取
提取商品的销售价格和市场价信息。
# 销售价格salePrice = products_item["price"]["salePrice"]products_item_dict["销售价格"] = salePrice if salePrice else "无"# 市场价marketPrice = products_item["price"]["marketPrice"]products_item_dict["市场价"] = marketPrice if marketPrice else "无"详细说明:
-
从嵌套的价格结构中提取销售价格和市场价
-
销售价格是唯品会的特卖价格
-
市场价是商品的参考原价
-
价格信息对于价格分析和优惠力度计算很重要
步骤14:商品属性信息提取
提取商品的详细属性信息。
# 其他信息attrs = products_item.get("attrs", "")# 初始化其他信息列表attrs_list = []if attrs:for attr in attrs:name = attr["name"]value = attr["value"]if name and value:attrs_list.append(name + ":" + value)else:attrs_list.append("无")# 其他信息字符串attrs_str = "---".join(attrs_list)products_item_dict["其他信息"] = attrs_str if attrs_str else "无"详细说明:
-
提取商品的属性列表,包含颜色、质地等美妆商品特有属性
-
遍历属性列表,格式化每个属性信息
-
使用分隔符连接多个属性,便于存储和分析
-
处理属性为空的情况,提供默认值
-
这种处理方式能够有效提取复杂的商品属性信息
步骤15:详情页链接构建
构建商品的详情页链接。
# 获取商品idproductId = products_item["productId"]# 获取品牌idbrandId = products_item["brandId"]# 构建详情页链接https://www.vipglobal.hk/detail-1710621388-6920871310745952780.htmlinfo_link = f"https://www.vipglobal.hk/detail-{brandId}-{productId}.html"products_item_dict["详情页链接"] = info_link if info_link else "无"详细说明:
-
从商品数据中提取商品ID和品牌ID
-
根据唯品会的URL规则构建详情页链接
-
详情页链接提供了查看商品完整信息的入口
-
这种动态构建链接的方式适用于所有商品
步骤16:数据保存和输出
将处理完成的商品数据保存到Excel文件。
print(products_item_dict)ws.append([products_item_dict['商品标题'],products_item_dict['品牌展会名称'],products_item_dict['销售价格'],products_item_dict['市场价'],products_item_dict['其他信息'],products_item_dict["详情页链接"]])详细说明:
-
实时打印采集到的数据,提供进度反馈
-
使用
ws.append()将数据写入Excel行 -
按表头顺序组织字段数据,确保数据结构一致性
-
完整的字段映射确保数据准确存储
步骤17:错误处理和资源清理
处理请求失败的情况,完成数据采集后保存文件。
else:print("请求失败,程序退出......")quit()
else:print("请求失败,程序退出")quit()
wb.save("唯品会口红数据.xlsx")
print("数据保存完毕......")详细说明:
-
处理请求失败的情况,提供错误提示并安全退出
-
使用
wb.save()保存完整的Excel文件 -
文件命名为"唯品会口红数据.xlsx",清晰标识数据来源
-
提供完成提示,确认数据保存成功
完整代码
# 爬取唯品会口红数据
import requests
import re
import json
import time
from openpyxl import Workbook
# 创建excel工作表
wb = Workbook()
# 获取活动工作表
ws = wb.active
# 设置表头
ws.append(['商品标题', '品牌展会名称', '销售价格', '市场价', '其他信息', "详情页链接"])
headers = {"Accept": "*/*","Accept-Language": "zh-CN,zh;q=0.9,en;q=0.8,en-GB;q=0.7,en-US;q=0.6","Connection": "keep-alive","Referer": "https://category.vip.com/","Sec-Fetch-Dest": "script","Sec-Fetch-Mode": "no-cors","Sec-Fetch-Site": "same-site","User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0","sec-ch-ua": "\"Chromium\";v=\"142\", \"Microsoft Edge\";v=\"142\", \"Not_A Brand\";v=\"99\"","sec-ch-ua-mobile": "?0","sec-ch-ua-platform": "\"Windows\""
}
cookies1 = {......}
url = "https://mapi-pc.vip.com/vips-mobile/rest/shopping/pc/search/product/rank"
for page in range(0, 6):pageOffset = page * 120print(f"正在爬取第{page + 1}页的数据内容")params = {"callback": "getMerchandiseIds","app_name": "shop_pc","app_version": "4.0","warehouse": "VIP_NH","fdc_area_id": "104104101","client": "pc","mobile_platform": "1","province_id": "104104","api_key": "70f71280d5d547b2a7bb370a529aeea1","user_id": "645762488","mars_cid": "1762691744964_5f9e9bc0bae26551c563c283cb2a12bb","wap_consumer": "b","is_default_area": "1","standby_id": "nature","keyword": "口红","lv3CatIds": "","lv2CatIds": "","lv1CatIds": "","brandStoreSns": "","props": "","priceMin": "","priceMax": "","vipService": "ch11","sort": "0","pageOffset": pageOffset,"channelId": "1","gPlatform": "PC","batchSize": "120","tfs_fp_token": "BhIPr/K3uf5k4idKwcFfrUJFayPSF6qauzCjnIy+/5sBJdqdG4knl1kOMMs5UECqq3E7QzU/8nqoF16haA5KDXg==","_": str(int(time.time() * 1000))}"""第一次请求:获取商品id列表一次获取120个商品id,由于第二次的参数里面携带了这些"""# 响应商品IDrespond_to_the_product_id = requests.get(url, headers=headers, cookies=cookies1, params=params)# 初始化结果列表res_products_id_list = []# 定义时间戳time_str = str(int(time.time() * 1000))
if respond_to_the_product_id.status_code == 200:respond_to_the_product_id_text = respond_to_the_product_id.textres = re.search(r'getMerchandiseIds\((.*?)\)', respond_to_the_product_id_text)if res:respond_to_the_product_id_json_data = json.loads(res.group(1))# 提取商品id列表products_id_list = respond_to_the_product_id_json_data["data"]["products"]# 遍历商品idfor num, products_id_item in enumerate(products_id_list):products_id = products_id_item["pid"]res_products_id_list.append(products_id)# print(res_products_id_list)for node in range(1, 4):print(f'正在请求第{page+1}页的第{node}个数据包......')if node == 1:callback = "getMerchandiseDroplets1"products_id_str = ",".join(res_products_id_list[0:50]) + ","print(f"数据包数量:{len(res_products_id_list[0:50])}")elif node == 2:callback = "getMerchandiseDroplets2"products_id_str = ",".join(res_products_id_list[50:100]) + ","print(f"数据包数量:{len(res_products_id_list[50:100])}")else:callback = "getMerchandiseDroplets3"products_id_str = ",".join(res_products_id_list[100:120]) + ","print(f"数据包数量:{len(res_products_id_list[100:120])}")# print(products_id_str)"""发送第二次请求:获取商品信息内容一页数据分为3个数据包,第一个50,第二个50,第三个20"""cookies2 = {......}url2 = "https://mapi-pc.vip.com/vips-mobile/rest/shopping/pc/product/module/list/v2"params2 = {"callback": callback,"app_name": "shop_pc","app_version": "4.0","warehouse": "VIP_NH","fdc_area_id": "104104101","client": "pc","mobile_platform": "1","province_id": "104104","api_key": "70f71280d5d547b2a7bb370a529aeea1","user_id": "645762488","mars_cid": "1762691744964_5f9e9bc0bae26551c563c283cb2a12bb","wap_consumer": "b","is_default_area": "1","productIds": products_id_str,"scene": "search","standby_id": "nature","extParams": "{\"stdSizeVids\":\"\",\"preheatTipsVer\":\"3\",\"couponVer\":\"v2\",\"exclusivePrice\":\"1\",\"iconSpec\":\"2x\",\"ic2label\":1,\"superHot\":1,\"bigBrand\":\"1\"}","context": "","tfs_fp_token": "BicZo59YoUtMcHQ2N7Oc1sob/0fqL22e7a4+g9t3NjweEyw2j8YasJyUJqQYo6G4H6qMfwaurjfuX1MjG3CygDA==","_": time_str}response2 = requests.get(url2, headers=headers, cookies=cookies2, params=params2)if response2.status_code == 200:response_json_data = ""
response_text = response2.text# 使用一个正则表达式匹配所有三种情况pattern = r'getMerchandiseDroplets\d+\(\s*(\{.*\})\s*\)'res = re.search(pattern, response_text)
if res:# print('正则匹配结果',res.group(1))response_json_data = json.loads(res.group(1))# print('json字符串转python的字典结果',response_json_data)else:print('正则匹配失败')continueif response_json_data:
# 商品列表products_list = response_json_data["data"]["products"]if products_list:print(f"获取到商品数目为:{len(products_list)}")# 遍历商品列表for products_item in products_list:products_item_dict = {}# 商品标题title = products_item["title"]products_item_dict["商品标题"] = title if title else "无"# 品牌展会名称brandShowName = products_item["brandShowName"]products_item_dict["品牌展会名称"] = brandShowName if brandShowName else "无"# 销售价格salePrice = products_item["price"]["salePrice"]products_item_dict["销售价格"] = salePrice if salePrice else "无"# 市场价marketPrice = products_item["price"]["marketPrice"]products_item_dict["市场价"] = marketPrice if marketPrice else "无"# 其他信息attrs = products_item.get("attrs", "")# 初始化其他信息列表attrs_list = []if attrs:for attr in attrs:name = attr["name"]value = attr["value"]if name and value:attrs_list.append(name + ":" + value)else:attrs_list.append("无")# 其他信息字符串attrs_str = "---".join(attrs_list)products_item_dict["其他信息"] = attrs_str if attrs_str else "无"# 获取商品idproductId = products_item["productId"]# 获取品牌idbrandId = products_item["brandId"]# 构建详情页链接https://www.vipglobal.hk/detail-1710621388-6920871310745952780.htmlinfo_link = f"https://www.vipglobal.hk/detail-{brandId}-{productId}.html"products_item_dict["详情页链接"] = info_link if info_link else "无"print(products_item_dict)ws.append([products_item_dict['商品标题'],products_item_dict['品牌展会名称'],products_item_dict['销售价格'],products_item_dict['市场价'],products_item_dict['其他信息'],products_item_dict["详情页链接"]])
else:print("请求失败,程序退出......")quit()else:print("正则无法匹配")else:print("请求失败,程序退出")quit()
wb.save("唯品会口红数据.xlsx")
print("数据保存完毕......")技术深度解析
抓包分析技术要点
通过抓包分析,我们掌握了以下关键技术点:
-
双请求架构识别:通过观察网络请求顺序,识别出唯品会独特的先ID后详情的双请求机制
-
JSONP响应处理:分析JSONP格式的响应,使用正则表达式提取有效JSON数据
-
认证机制分析:分析复杂的认证参数,包括API密钥、用户标识、指纹令牌等
-
分页机制理解:识别基于偏移量的分页机制,而非传统的页码分页
-
数据分批策略:理解商品ID分批请求的设计原理和实现方式
双请求架构优势
与传统的单次请求相比,唯品会的双请求架构具有显著优势:
# 第一次请求:获取商品ID列表
response1 = requests.get(url1, params=params1)
product_ids = extract_ids(response1.text)
# 第二次请求:获取商品详细信息
response2 = requests.get(url2, params=params2)
product_details = extract_details(response2.text)-
数据分离:ID列表和详细信息分离,降低单次请求的数据量
-
灵活性:可以根据需要选择获取哪些商品的详细信息
-
性能优化:减少不必要的数据传输,提升响应速度
-
错误恢复:单个商品详情获取失败不影响其他商品
JSONP数据处理技术
唯品会采用JSONP格式返回数据,需要特殊处理:
pattern = r'getMerchandiseDroplets\d+\(\s*(\{.*\})\s*\)'
res = re.search(pattern, response_text)
if res:response_json_data = json.loads(res.group(1))-
正则表达式匹配:使用动态正则匹配不同回调函数的JSONP响应
-
JSON提取:从JSONP包装中提取纯JSON数据
-
错误处理:处理正则匹配失败的情况,确保程序稳定性
智能分批策略
针对唯品会的限制,实现了智能的商品ID分批:
for node in range(1, 4):if node == 1:products_id_str = ",".join(res_products_id_list[0:50]) + ","elif node == 2:products_id_str = ",".join(res_products_id_list[50:100]) + ","else:products_id_str = ",".join(res_products_id_list[100:120]) + ","-
批量限制:每批次最多50个商品ID
-
灵活分割:根据实际商品数量动态分割
-
进度跟踪:实时显示每个批次的处理进度
-
容错处理:处理商品数量不足的情况
健壮的数据提取
安全的数据提取策略确保程序稳定性:
title = products_item["title"]
products_item_dict["商品标题"] = title if title else "无"-
直接访问JSON字段,效率高
-
使用条件判断处理可能为空的字段
-
为所有字段提供合理的默认值
-
确保程序在数据不完整时仍能正常运行
详情页链接构建
动态构建商品详情页链接:
info_link = f"https://www.vipglobal.hk/detail-{brandId}-{productId}.html"-
基于品牌ID和商品ID构建标准URL
-
适用于所有商品的通用链接格式
-
提供查看商品完整信息的入口
应用场景与价值
这个唯品会口红数据采集系统可以应用于多个重要场景:
-
美妆市场分析:分析口红市场的品牌分布、价格区间和产品趋势
-
竞品监控:跟踪竞争对手的产品策略和价格变动
-
价格策略研究:研究唯品会的特卖价格策略和折扣力度
-
品牌影响力分析:分析各品牌在唯品会平台的展示和销售情况
-
产品选品参考:为美妆零售商提供产品选品的数据支持
-
消费者偏好研究:通过商品属性分析消费者对口红色号、质地的偏好
-
学术研究:为美妆电商和消费者行为研究提供真实的数据支持
法律和道德声明
在使用本数据采集程序时,请务必严格遵守以下原则:
-
遵守法律法规:严格遵循《网络安全法》、《电子商务法》及相关互联网监管规定
-
尊重平台规则:严格遵守唯品会平台的使用条款和robots.txt协议
-
控制访问频率:合理设置请求间隔,不对平台服务器造成压力
-
合法使用数据:仅将数据用于技术学习和市场研究,不用于商业竞争
-
尊重知识产权:承认数据来源,不将爬取数据用于商业用途
-
隐私保护:不采集、使用或传播涉及用户隐私的信息
-
商业道德:不利用获取的数据进行不正当竞争或损害平台利益的行为
技术总结
本文详细介绍了通过双请求API接口爬取唯品会平台口红数据的完整技术方案,特别强调了抓包分析和JSONP数据处理的重要性。通过这个项目,我们掌握了以下核心技术:
-
复杂架构分析:分析并理解唯品会的双请求API架构
-
JSONP处理技术:使用正则表达式处理JSONP格式的响应数据
-
分批请求策略:实现智能的商品ID分批和详情获取
-
认证机制处理:配置复杂的用户认证和API访问参数
-
分页采集机制:实现基于偏移量的分页数据采集
-
数据标准化:将复杂的商品数据保存为可分析的标准格式
与传统的单次请求采集相比,这种基于双请求调用的方案具有独特优势:
-
适应现代电商平台的复杂数据加载机制
-
更高的数据获取效率和稳定性
-
更好的错误恢复能力
-
适用于采用先进前端技术的电商平台
关于认证参数的重要说明:
虽然在当前实现中我们直接使用了抓包获取的认证参数,但在实际生产环境中,需要理解这些参数的生成机制:
# 认证参数生成伪代码(示例)
def generate_auth_params(user_id, api_key):timestamp = int(time.time() * 1000)fingerprint = generate_fingerprint()return {"user_id": user_id,"api_key": api_key,"tfs_fp_token": fingerprint,"_": timestamp}在实际应用中,应该分析认证参数的生成逻辑,实现自动化的参数生成,而不是硬编码固定的参数值。
抓包分析是现代网络数据采集的关键技能,通过深入分析网络请求,我们可以:
-
理解网站的数据传输架构
-
识别必要的认证和反爬虫机制
-
找到最高效的数据获取方式
-
优化数据采集的性能和稳定性
掌握这种基于抓包分析和API调用的数据采集技术,在电子商务和美妆市场分析领域具有重要价值。无论是美妆品牌商、市场研究人员还是电商分析师,都能够通过这种技术获取宝贵的市场洞察。
在网络数据采集技术的学习道路上,我们既要追求技术精进,更要坚守法律和道德底线。特别是在商业数据采集领域,必须确保技术的合法合规使用,尊重数据知识产权和市场秩序。
注意:本文仅供技术学习交流,实际应用中请严格遵守相关法律法规和平台使用条款。所有数据采集行为应仅限于个人学习研究,不得用于任何商业用途或竞争行为。商业决策请以官方渠道信息为准。