(Arxiv-2025)KALEIDO:开源的多主体参考视频生成模型
KALEIDO:开源的多主体参考视频生成模型
paper是合工大发布在arxiv 2025的工作
paper title:KALEIDO: OPEN-SOURCED MULTI-SUBJECT REFERENCE VIDEO GENERATION MODEL
Code:https://github.com/CriliasMiller/Kaleido
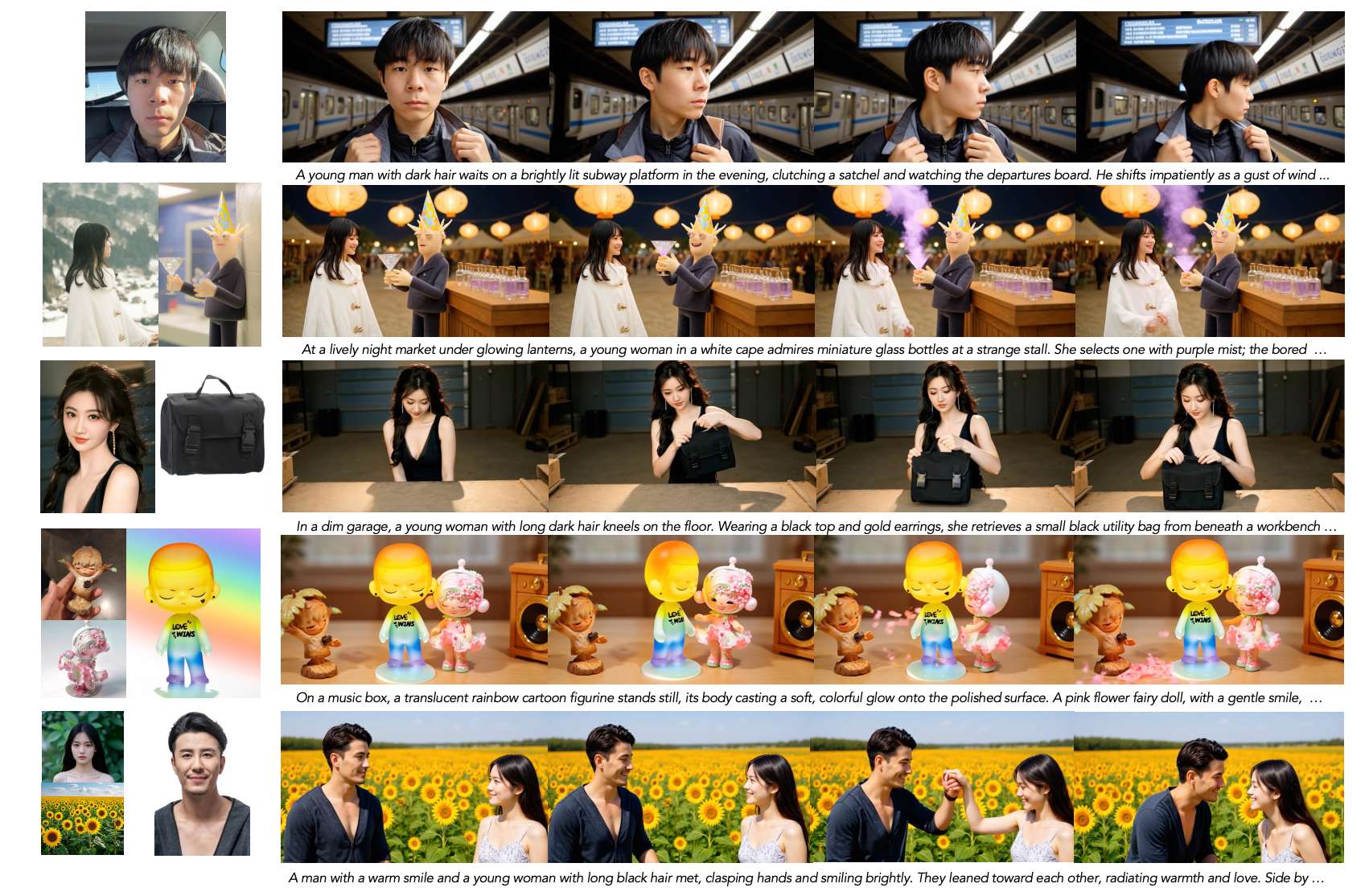
图1:由Kaleido生成的主体到视频的结果,涵盖了人类、物体以及可控背景,既包括单主体情况,也包括多主体情况。
ABSTRACT
我们提出了Kaleido,这是一种主体到视频(S2V)生成框架,旨在基于目标主体的多个参考图像合成主体一致的视频。尽管近年来S2V生成模型取得了一定进展,但现有方法在保持多主体一致性和进行背景解耦方面仍显不足,常常在多图像条件下导致参考保真度降低和语义漂移。这些问题主要源于以下几个因素。首先,训练数据集缺乏多样性和高质量样本,同时存在交叉配对数据,即其组成部分来自不同实例的配对样本。此外,当前用于整合多个参考图像的机制并不理想,容易导致多个主体之间的混淆。为克服这些限制,我们提出了一条专用的数据构建流程,结合低质量样本过滤和多样化数据合成,以生成保持一致性的训练数据。此外,我们引入了参考旋转位置编码(R-RoPE)来处理参考图像,从而实现稳定且精确的多图像融合。在多个基准上的大量实验表明,Kaleido在一致性、保真度和泛化能力方面显著优于以往方法,标志着S2V生成领域的一项重要进展。本研究的源代码和已训练模型检查点将于此处公开。
1 INTRODUCTION
近年来,视频生成领域取得了快速而令人振奋的进展。受Sora成功的部分启发,结合扩散模型与扩散Transformer(DiT)(Peebles & Xie, 2023; Esser et al., 2024)的架构已成为主流范式,并得到了进一步发展。商业模型如Veo3(DeepMind)和Kling(快手)已实现接近专业制作水准的视频质量,为视频内容创作引入了一种全新的工作流范式,在显著提升效率的同时降低了制作成本。在开源领域,Wan(Wang et al., 2025)和CogVideoX(Yang et al., 2025)等模型不仅具备这些优势,还支持针对特定应用场景的自定义微调。
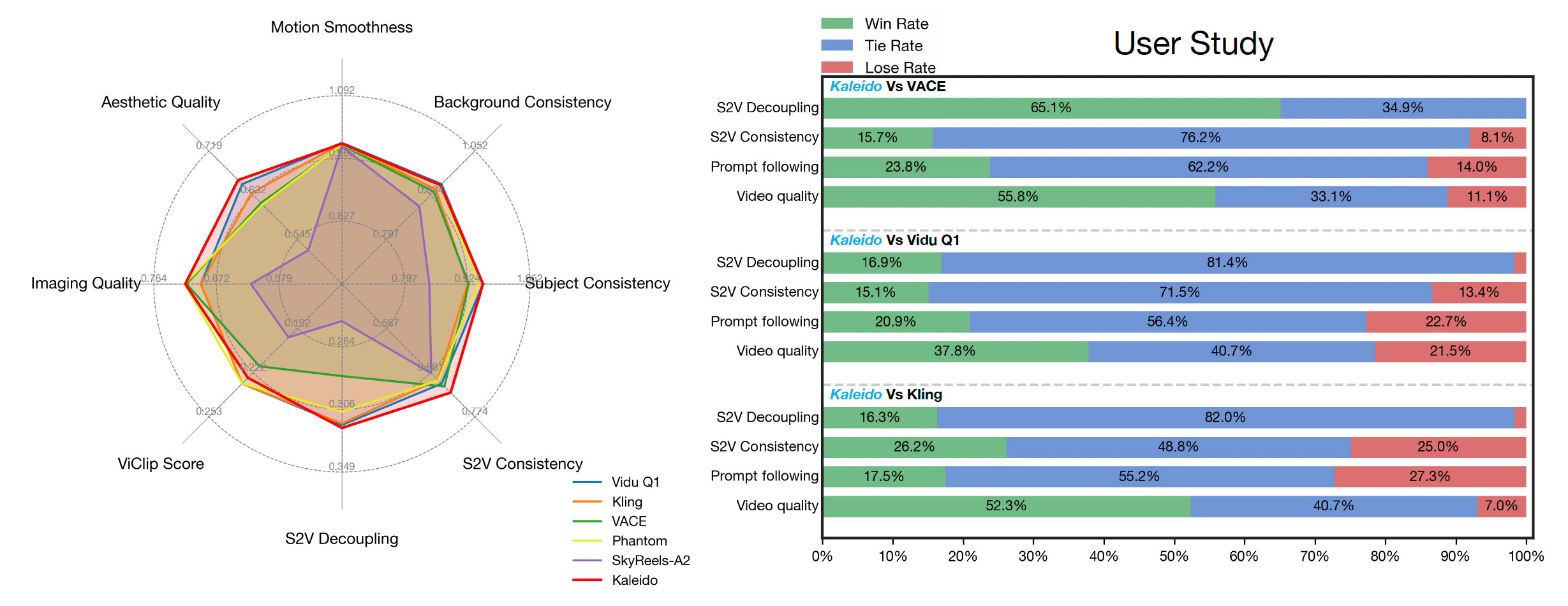
图2:主体到视频的评估结果(左)以及用户研究结果,对比了Kaleido与VACE、Kling和Vidu-Q1(右)。
当前的预训练视频生成研究主要集中在两大任务上:文本到视频(T2V)和图像到视频(I2V)生成。前者直接从文本描述中合成视频,具有较高的创意多样性,但随机性较大;后者则将静态图像转化为动态视频,要求首帧完全一致,这一约束限制了创意灵活性。因此,对视频生成更灵活控制的需求日益增长。主体到视频(S2V)生成任务旨在基于目标主体的多个参考图像,合成保持主体一致性的视频,已引起广泛关注。Vidu(Bao et al., 2024)和Kling(快手)等商业系统体现了这一趋势,展示了其在电商与广告等行业中的巨大潜力。
S2V任务要求从给定的参考图像中解耦出目标主体,并依据文本提示生成视频,同时保持主体外观一致。主体可涵盖广泛的视觉实体,包括人类、物体和背景。它结合了T2V生成的创造性与I2V生成的可控性,从而在视频生成中实现更灵活的控制。
然而,现有开源S2V模型仍落后于闭源系统。差距主要体现在难以在多样化主体组合中保持一致的视觉外观,以及生成高质量视频的能力不足。导致性能差距的根本原因主要有两点:
• 缺乏有效的训练数据。在大多数现有数据构建流程中,参考图像通常直接从视频帧中选取。基于此类数据训练的模型往往倾向于完全复制参考图像中的主体(不改变其视角、姿态或动态属性),而非解耦主体并聚焦其本质特征。因此,生成的视频可能继承多余元素,如参考图像中的背景细节或无关物体,这些在视频中通常是不希望出现的。此外,现有模型在多主体组合或包含动画角色的场景中往往难以保持令人满意的一致性,这主要是由于训练数据的覆盖度和质量不足所致。
• 条件控制策略不足。目前的参考图像信息注入策略普遍不够理想,限制了模型高效捕获并表征主体特征的能力。例如,Phantom(Liu et al., 2025)采用沿序列维度的潜特征拼接方式,但这种方法可能导致不同参考对象在空间上重叠,从而产生不良的组合伪影。VACE(Jiang et al., 2025)使用基于适配器的架构,但推理成本较高。
我们提出了一系列方法,使开源模型能够达到与闭源模型相当的性能。主要贡献包括:
• 一个全面的数据构建流程。我们的数据管线采用多类别采样、严格筛选以及交叉配对数据构建,丰富了主体与场景的多样性,提高了数据整体保真度,并确保主体与无关元素的解耦。
• 一种高效的图像条件注入方法,称为R-RoPE(参考旋转位置编码),为主体token引入旋转位置编码,以最大化模型整合多个参考图像信息的能力。该机制在保持计算效率的同时,显著提升了多图像与多主体S2V一致性。
• 一个最先进(SOTA)的开源S2V模型。大量实验表明,我们的方法在主体保真度、背景解耦和总体生成质量方面表现优异,验证了其在构建通用型、主体一致性视频生成模型方面的有效性。
此外,我们将开源数据管线与预训练S2V模型,以支持研究社区并为未来的主体到视频生成研究提供坚实基础。
2 RELATED WORK
参考引导生成在图像与视频领域都得到了广泛研究。在图像领域,DreamBooth(Ruiz et al., 2023)等方法通过在少量参考图像上微调扩散模型,实现了个性化生成,从而能够保留主体特有的特征。其扩展方法如IP-Adapter(Ye et al., 2023)进一步利用多输入图像与上下文信息增强了参考条件控制,尽管这些工作仍局限于静态图像合成。与此同时,视频生成经历了快速演进:基于GAN的方法(Goodfellow et al., 2014)最初在稳定性和时间一致性方面表现不佳,而基于U-Net架构的扩散模型在生成质量上带来了显著提升。近年来,扩散Transformer的引入在可控性、文本对齐以及长时序一致性方面取得了重大进展,推动了视频编辑、视频修复以及文本到视频生成等多种下游任务的发展。
在这些进展的基础上,主体到视频(S2V)任务作为参考引导生成的自然扩展逐渐兴起。专有系统如Vidu(Bao et al., 2024)和Kling(快手)展示了从参考图像生成视频的可行性,引起了广泛关注,但由于闭源特性限制了社区的使用与研究。随后开源框架如VACE(Jiang et al., 2025)、Phantom(Liu et al., 2025)和SkyReels-A2(Fei et al., 2025)的发布加速了该领域的研究,推动了从数字人生成到虚拟试穿、换脸等多种应用的发展。尽管取得了这些进展,现有的S2V模型(Jiang et al., 2024; Zhou et al., 2024; Wang et al., 2024)仍面临诸多挑战。特别是,许多方法依赖于将参考嵌入直接与视频潜变量拼接,这往往导致背景解耦不足和主体保真度下降。当参考主体位于复杂背景中时,模型常常会将背景伪影带入生成视频中。此外,在多主体或多图像场景中,由于缺乏专门的参考对齐机制,常出现token错乱与时间一致性减弱的问题。
我们的工作建立在上述研究基础之上,同时针对以往S2V方法的局限性进行了改进。通过引入更全面的数据处理流程和改进的训练策略,我们旨在同时提升背景解耦能力与主体保真度,从而迈向一个更加通用且稳健的主体感知视频生成框架。
3 DATASET CONSTRUCTION PIPELINE
3.1 MOTIVATION
主体到视频(S2V)生成致力于在参考图像与文本提示的条件下,合成特定主体的视频。在广泛的开放世界场景中实现高质量的S2V,依赖于内容多样且严格由“解耦图像-视频”对组成的训练数据。在此类配对中,主体的视觉属性必须独立于其周围环境。
以往工作主要使用为主体驱动的图像生成或受限视频任务设计的数据集,难以充分满足上述要求,进而带来三方面的显著局限:主体与场景多样性不足削弱了泛化能力;标注质量不一致降低了可控性;图像-视频对与背景信息纠缠。结果是,当前S2V模型在推理时往往依赖额外的分割或主体提取步骤,无法实现真正的端到端主体条件控制,并限制了组合灵活性。
为解决这些约束并推动可用于非受限场景的真正端到端S2V模型的发展,我们提出了一条新的数据集构建流程。我们的方法结合了稳健的grounding与分割、先进的过滤技术,以及以大规模强化主体-背景解耦为目标的交叉配对(cross-paired)组合策略。该流程产出多样且高质量的数据对,这对于训练能直接从未分割的参考图像与灵活文本提示合成视频的模型至关重要,从而推动S2V研究迈向开放域应用的实际落地。
3.2 PIPELINE DESIGN
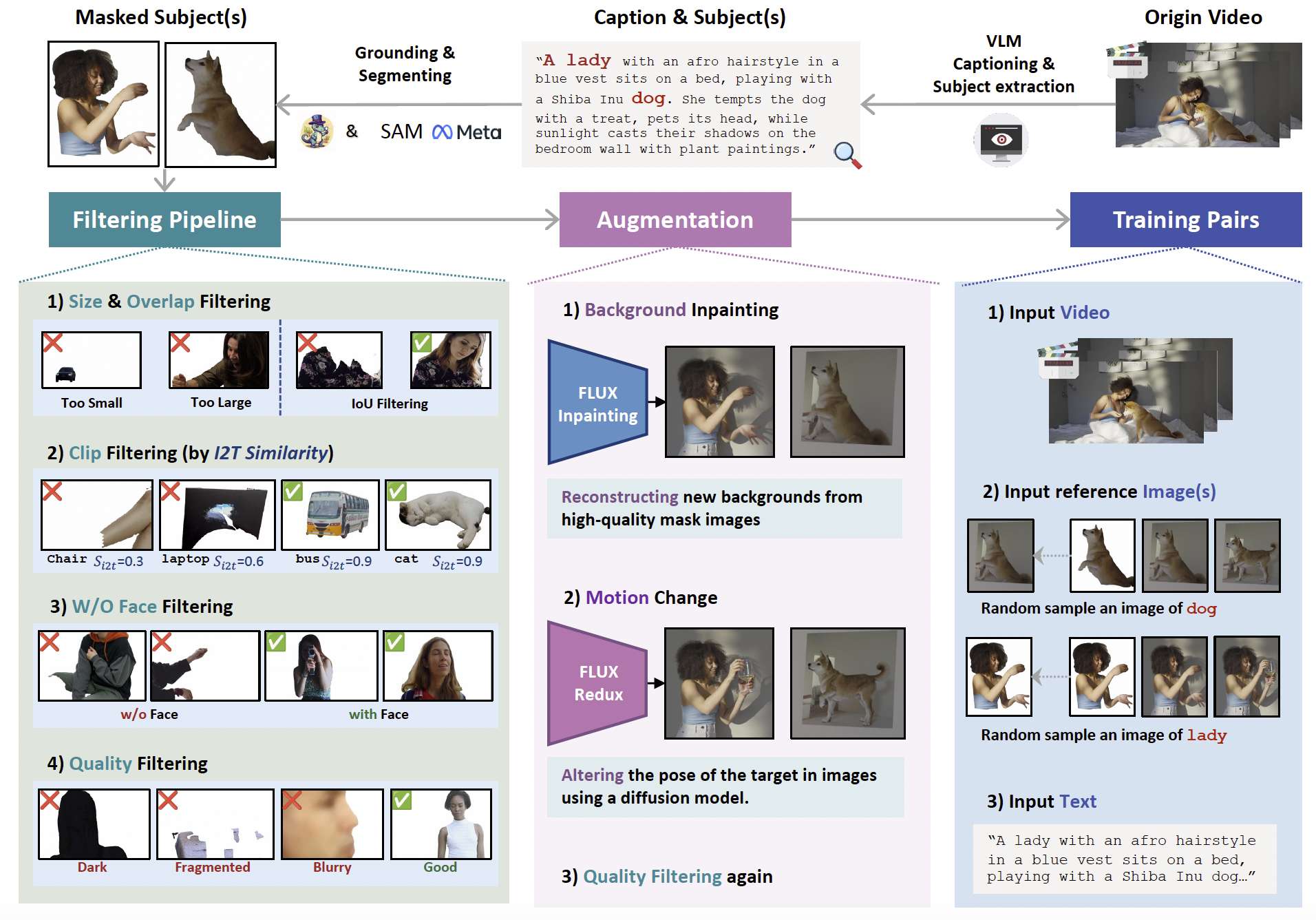
图3:可扩展的多阶段数据管线用于主体到视频(S2V)生成,其中数据增强支持创建交叉配对样本以实现稳健训练。
为实现上述目标,我们提出了一条可扩展的、多阶段的数据集构建流程,专为S2V任务设计。该流程可概括如下:
(1) 视频预处理与字幕生成。首先,我们将大规模原始视频集切分为较短的片段,每个片段包含连贯的动作或事件。随后,自动字幕生成模型为每个片段生成文本描述,以确保视觉模态与文本模态之间的对齐。
(2) 主体类别定义与候选识别。为进一步提升多样性,我们构建了覆盖多个领域(如人类、物体、背景)的广泛主体类别体系。该体系包含100多个不同主体类别及800多个候选同义词与实例,使字幕可通过丰富的词汇库进行匹配,从而识别候选主体(classv)以供后续处理。该方法无需人工标注即可实现可扩展的主体发现,显著增强了数据集的多样性。
(3) 定位与分割。为精确定位主体区域,我们采用Grounding DINO(Liu et al., 2024)实现稳健的目标定位,并使用SAM(Kirillov et al., 2023)进行细粒度分割。该组合确保了语义正确性与边界精度,对实现高质量的主体中心视频生成至关重要。
(4) 过滤与验证。为保证数据质量,我们实施多项过滤策略:
(i) 尺寸过滤:移除过小或过大的样本;
(ii) 基于CLIP的分类:验证类别与文本描述的一致性;
(iii) 基于IoU的过滤:排除重叠区域较大的样本,确保主体独立性;
(iv) 质量检查:通过亮度与模糊度评估去除低质量样本。
对于人类类别,我们使用InsightFace仅保留具备有效正脸的人像,以增强身份一致性。
(5) 基于背景解耦的数据增强。S2V的一大挑战是主体与背景的纠缠。为缓解这一问题,我们对参考图像的分割区域应用修复(inpainting)技术(Labs et al., 2025),有效去除背景信息。在训练过程中,模型被鼓励从参考图像中重建主体外观,同时依赖文本提示生成背景。该策略可防止模型过拟合于偶然背景特征,并提升主体在不同场景中的迁移能力。
(6) 基于姿态与运动的增强。最后,为提高多样性并避免过拟合于帧级相似性,我们利用Flux Redux(Labs et al., 2025)为参考图像添加原视频帧中不存在的新姿态与运动。此增强促使模型学习对运动变化更具鲁棒性的主体身份表征。
最终生成的数据管线不仅产生高质量、与背景无关的主体标注,还提供了一个可广泛应用于多种下游任务的通用框架。更重要的是,它为S2V建立了统一的研究视角,为未来围绕主体个性化与多任务统一的研究奠定了基础。
4 FRAMEWORK
我们探索了一种基于扩散模型的视频生成创新框架。我们的主要关注点是整合多个参考图像以改进视频生成过程。给定一组参考图像I1,I2,…,InI_1, I_2, \ldots, I_nI1,I2,…,In、一个文本输入TTT以及目标视频VVV,我们的目标可表示为:
V=G(I1,I2,…,In,T;z) V = \mathcal{G}(I_1, I_2, \ldots, I_n, T; z) V=G(I1,I2,…,In,T;z)
其中,zzz表示视频生成过程中固有的随机噪声变量。目标是使VVV在视觉上连贯,有效地融合来自参考图像的信息,并遵循文本提示。
4.1 预备知识
文本到视频(T2V)合成将基于扩散的建模扩展到时空域,旨在将高斯噪声变量ϵ∼N(0,I)\epsilon \sim \mathcal{N}(0, I)ϵ∼N(0,I)转换为与文本描述相对应的连贯视频x0x_0x0。现代方法采用潜空间扩散建模,其中时空自编码器E(⋅)E(\cdot)E(⋅)将视频压缩为紧凑的潜张量Z∈RC×H×W×TZ \in \mathbb{R}^{C \times H \times W \times T}Z∈RC×H×W×T,其中TTT表示时间维度,H×WH \times WH×W为空间分辨率,CCC为通道维度。
在该潜空间中,基于Transformer的去噪网络对噪声进行建模,利用时空自注意力和相对位置编码(例如3D旋转位置编码)捕获长距离依赖关系。文本条件通过预训练编码器τθ(y)\tau_{\theta}(y)τθ(y)对提示进行编码,并通过交叉注意力层将视频潜特征与文本特征融合。在训练过程中,我们采用Flow Matching(Esser等,2024),其中噪声注入方式为xt=(1−t)x0+tϵx_t = (1 - t)x_0 + t\epsilonxt=(1−t)x0+tϵ,模型通过以下损失进行优化:
L=Ex0,t,y,v[∥v−vθ(E(x0),t,τθ(y))∥22], \mathcal{L} = \mathbb{E}_{x_0, t, y, v} \left[ \| v - v_{\theta}(E(x_0), t, \tau_{\theta}(y)) \|_2^2 \right], L=Ex0,t,y,v[∥v−vθ(E(x0),t,τθ(y))∥22],
其中ttt为扩散时间步,且v=dxdt=ϵ−x0v = \frac{dx}{dt} = \epsilon - x_0v=dtdx=ϵ−x0。
4.2 METHOD
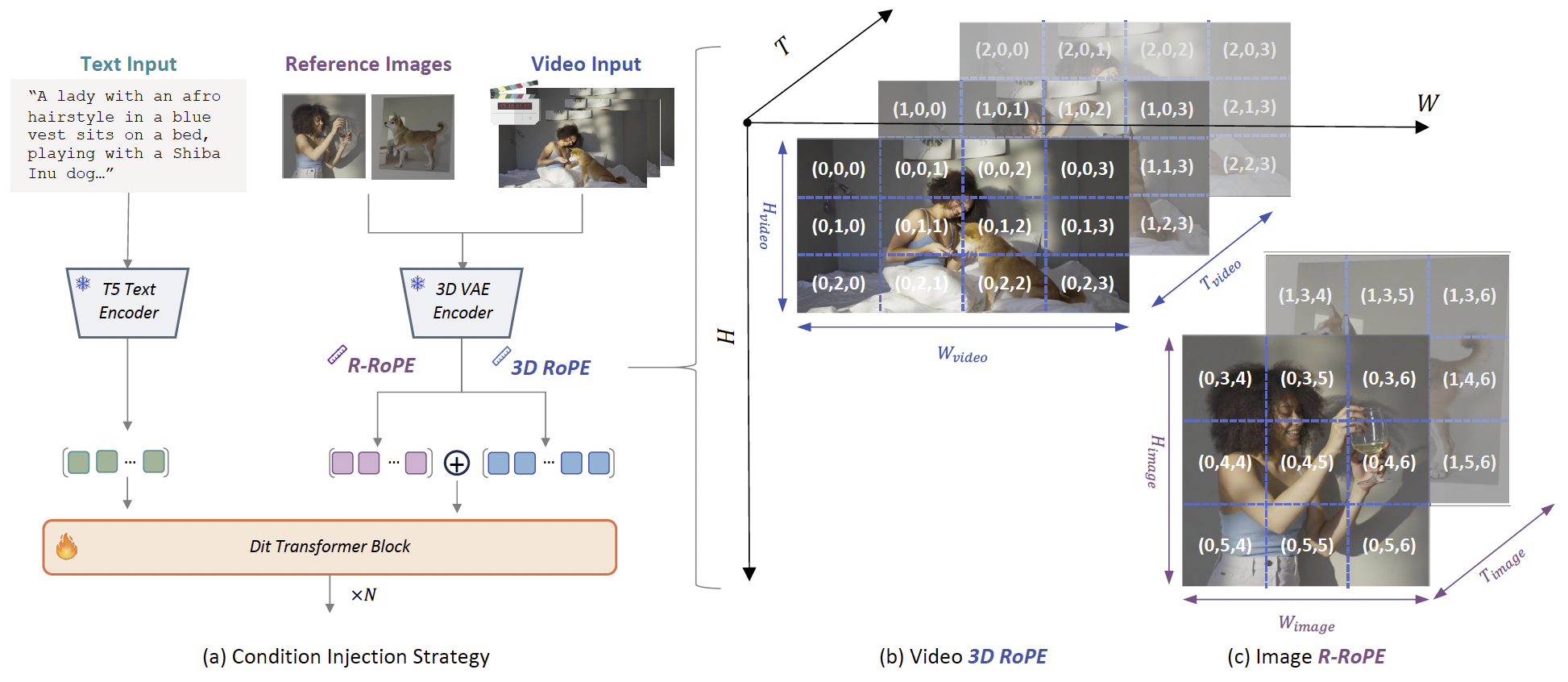
图4:我们的主体到视频框架示意图。(a) 通过注入多个参考图像实现引导式视频生成。(b) 视频token使用3D RoPE位置编码,而©参考图像使用R-RoPE以实现独特的时空定位。
在本研究中,我们采用了一种直接的条件注入策略,将图像条件与视频序列结合用于S2V任务。与采用复杂的基于适配器模块的方法不同,我们使用一种简单的拼接方案,将编码后的图像条件与视频噪声表示在序列维度上合并。具体来说,输入序列可表示为:
X=[I1,I2,⋯ ,In,z] X = [I_1, I_2, \cdots, I_n, z] X=[I1,I2,⋯,In,z]
这种方法保留了原始基础模型的固有结构,并通过最小化架构修改实现高效、稳定的学习。然而,与相邻位置ID的直接拼接引入了新的挑战:模型可能将图像条件误解为视频序列中的连续帧,从而破坏时间连续性并降低生成视频的质量。为了解决这一问题,关键在于模型能够区分图像token与视频token,并充分理解它们各自的作用。
为实现这种区分,我们引入了参考旋转位置编码(Reference Rotary Positional Encoding, R-RoPE)机制。如图4所示,传统的3D RoPE通过位置向量(t,h,w)(t, h, w)(t,h,w)对视频token进行编码,其中ttt为时间帧索引,h,wh, wh,w为空间维度,均从零开始。对于图像条件,我们修改了位置向量,使其空间维度从视频序列的最大观测维度(Hmax,Wmax)(H_{max}, W_{max})(Hmax,Wmax)开始,从而确保图像token在模型的时空嵌入空间中占据独立位置,易于与视频token区分。此外,每张参考图像的时间位置单独分配,从t=0t=0t=0开始。形式化定义如下:
Posi=[i−1,Hmax:shiftH,Wmax:shiftW] Pos_i = [i - 1, H_{max} : shiftH, W_{max} : shiftW] Posi=[i−1,Hmax:shiftH,Wmax:shiftW]
其中,iii表示图像条件的索引,shiftHshiftHshiftH和shiftWshiftWshiftW分别表示HmaxH_{max}Hmax与参考图像高度之和,以及WmaxW_{max}Wmax与参考图像宽度之和。通过这种显式的位置信息分离,可防止视频序列与注入的图像条件之间的空间关系混淆。利用该基于拼接的条件注入和位置编码机制,我们的模型能够有效区分视频与图像信息,并在扩散Transformer架构中生成一致且高质量的视频输出。