数据集很大的时候怎么办
首先,为了防止网络原因导致不断重新下载(网络问题暂停下载,然后需要重新下载),可以考虑断点续传机制
curl -C - --retry 100 --retry-delay 30 --retry-max-time 0 --max-time 0 -O "你的完整下载链接"
✅ 命令已启动:curl 正在工作
✅ 断点续传已启用:
-C -参数✅ 无限重试:
--retry 100+--retry-max-time 0✅ 30秒自动重连:
--retry-delay 30
技术原理:
1. HTTP Range 请求(核心机制)
当curl使用
-C -参数时,它会向服务器发送这样的请求:text
GET /video_part_aa Range: bytes=1024000-意思是:"请从 1,024,000 字节开始发送文件剩余部分"
2. 服务器支持断点续传
Google Cloud Storage 支持 Range 请求,会响应:
text
HTTP/1.1 206 Partial Content Content-Range: bytes 1024000-20480000/20480000然后只发送从断点开始的数据
3. 本地文件记录进度
curl 在下载时:
✅ 检查本地文件大小:
ls -l video_part_aa显示已下载多少✅ 计算剩余字节:文件总大小 - 已下载大小
✅ 从正确位置继续:不会重复下载已存在的部分
其次,主包今天遇到的问题是有一个500+GB的数据集,好心人把它分成了4份,让我分别下载然后cat part* > total.tar.gz" and then unzip the file.
但是主包网速max也只有10+MBps,且存储堪忧,打算下载其中一卷。
由于d卷(最后一卷)最小,主包下载了最后一卷。
but
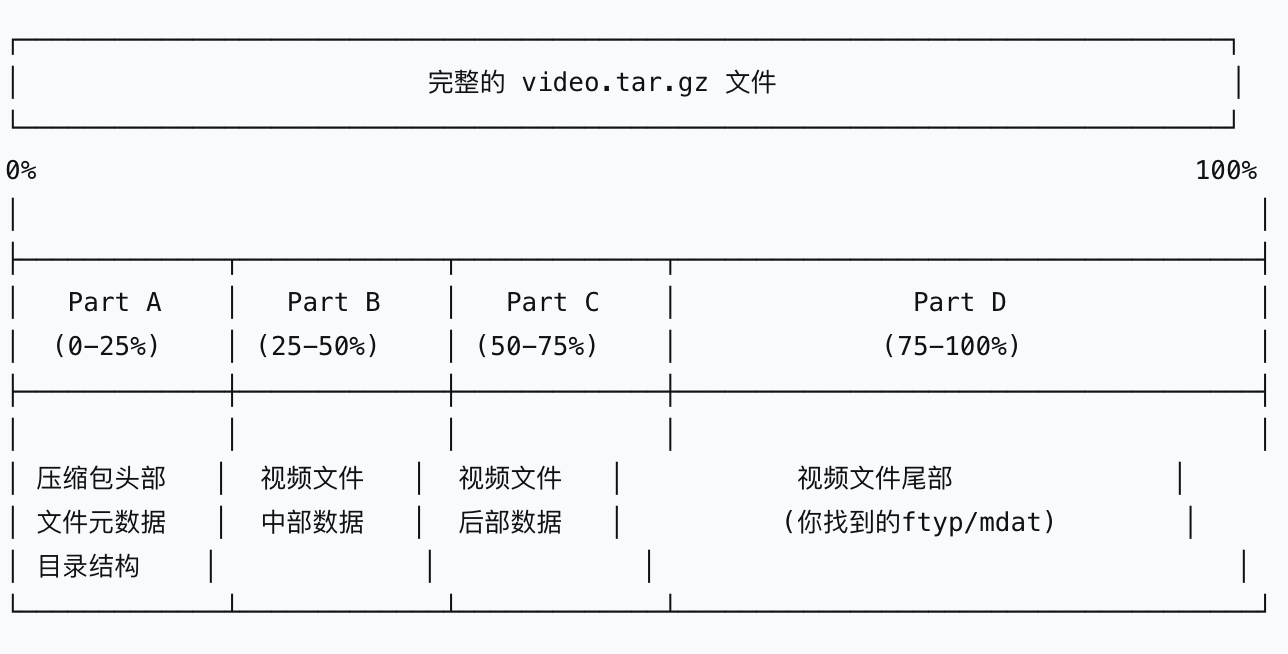

由图可知,整个文件夹其实是包含一些文件元数据等和文件本身的(也可以由操作系统课程所得)
只下载part d,无法获得文件头部信息,
所以在下载2h的d之后,主包不得不重新花费4h下载part a
The end. Have a nice day.