Redis进阶
Redis是一种key-value的数据库,key一般是String类型,value的类型多种多样,redis的数据结构通常指的都是value的类型
什么是缓存?
缓存就是数据交换的缓存区(Cache),是存储数据的临时地方,读写性能较高
缓存的作用:
降低后端的负载(数据库压力)
提高读写效率,降低响应时间
缓存的成本:
数据一致性成本(双写一致问题)
代码维护成本(缓存三兄弟)
运维成本(高可用,集群模式)
一.Spring框架集成Redis的Java客户端
SpringData是Spring中数据操作的模块,包含对各种数据库的集成,其中对Redis的集成模块就叫做SpringDataRedis
1.提供了对不同Redis客户端的整合(Lettuce和Jedis,SpringBoot2.x起默认选择Lettuce)
2.提供了RedisTemplate统一API来操作Redis
3.支持Redis哨兵和Redis集群
4.支持基于JDK,JSON,字符串,String对象的数据序列化及反序列化
SpringDataRedis的序列化方式:
首先介绍什么是序列化?什么是反序列化?
序列化:在数据传输的时候,将内存中的对象转换为可以存储或传输的格式(字节流)的过程
反序列化:将存储或传输的格式转换回内存中的对象的过程
SpringDataRedis默认使用的是JDK中提供的序列化工具,通常我们在使用RedisTemple时都会写一个配置类,将序列化器和反序列化器改为String方式,来对对象进行序列化,反序列化

那么为什么需要我们重新指定序列化器和反序列化器,为什么不使用默认提供的jdk中的序列化器和反序列化器?
首先我们要知道,在网络传输过程中数据都是以字节流的形式传输的,也就是数组保存,传输的数据不可读,看着像乱码,我们要将对象转为JSON的格式存储
尽管JSON的序列化方式可以满足可读需求,但是还存在一些问题
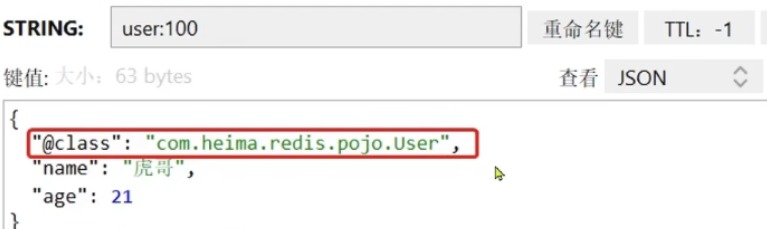
它会将JSON格式存储的对象对象的类地址保存,用于反序列化,存入redis中会带来额外的内存开销
StringRedisTemple是Spring提供的一个类,它的key和value序列化方式默认就是String方式,所以我们在使用的时候,键值都得用String类型,要存储对象时,把对象转为JSON字符串存储,或者将对象中的数据都转为String类型
StringRedisTemplate和RedisTemplate的区别:
StringRedisTemple存储对象时不需要存储类的地址,但需要我们手动将json格式字符串转化为对象
二.使用redis作为缓存中间件
在项目中我们经常会使用缓存来减轻数据库的压力,在高并发的业务场景下,数据库是扛不住大量请求,这时候我们就需要增加一个或多个中间层来减轻数据库压力,而redis就是将数据存储到缓存中,读写速度远远大于从磁盘中读写
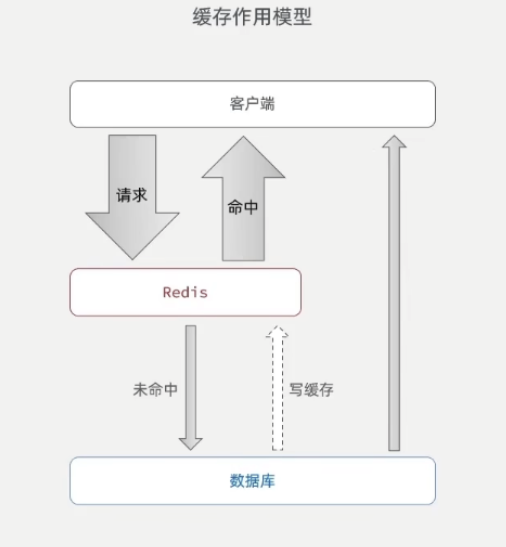
首先我们要明白什么样的数据需要添加到缓存中:需要频繁查询的数据
@Overridepublic List<ShopType> queryTypeList() {//先查询缓存判断是否存在String key = "cache:shopType";String shopTypeJson = stringRedisTemplate.opsForValue().get(key);if(StrUtil.isNotBlank(shopTypeJson)){List<ShopType> shopTypes = JSONUtil.toList(shopTypeJson,ShopType.class);return shopTypes;}List<ShopType> shopTypes = query().orderByAsc("sort").list();if(shopTypes == null){return null;}stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shopTypes));return shopTypes;}缓存更新策略

内存淘汰:在缓存内存不足时,redis会主动淘汰部分数据
超时剔除:给缓存添加数据的时候设置过期时间
主动更新:编写业务逻辑,在数据库更新的时候,主动去更新缓存
操作缓存和数据库时有三个问题需要考虑:
1.删除缓存还是更新缓存?
更新缓存:每次更新数据库都更新缓存,无效写操作较多,浪费内存资源
删除缓存:更新数据库时让缓存失效,查询时再更新缓存,这样即使无效的写操作,我们也不会主动去同步的更新缓存
2.如何保证缓存与数据库的操作同时成功或失败?
单体系统:将缓存与数据库操作放在一个事务中,也就是将操作缓存和操作数据库写在一个方法内,给Service层添加Transational注解,让spring帮我们统一管理事务
分布式系统:利用TCC等分布式事务方案
3.先操作缓存还是先操作数据库?
并发产生的双写一致性问题
数据库中数据被修改,我们需要同步的去删除缓存
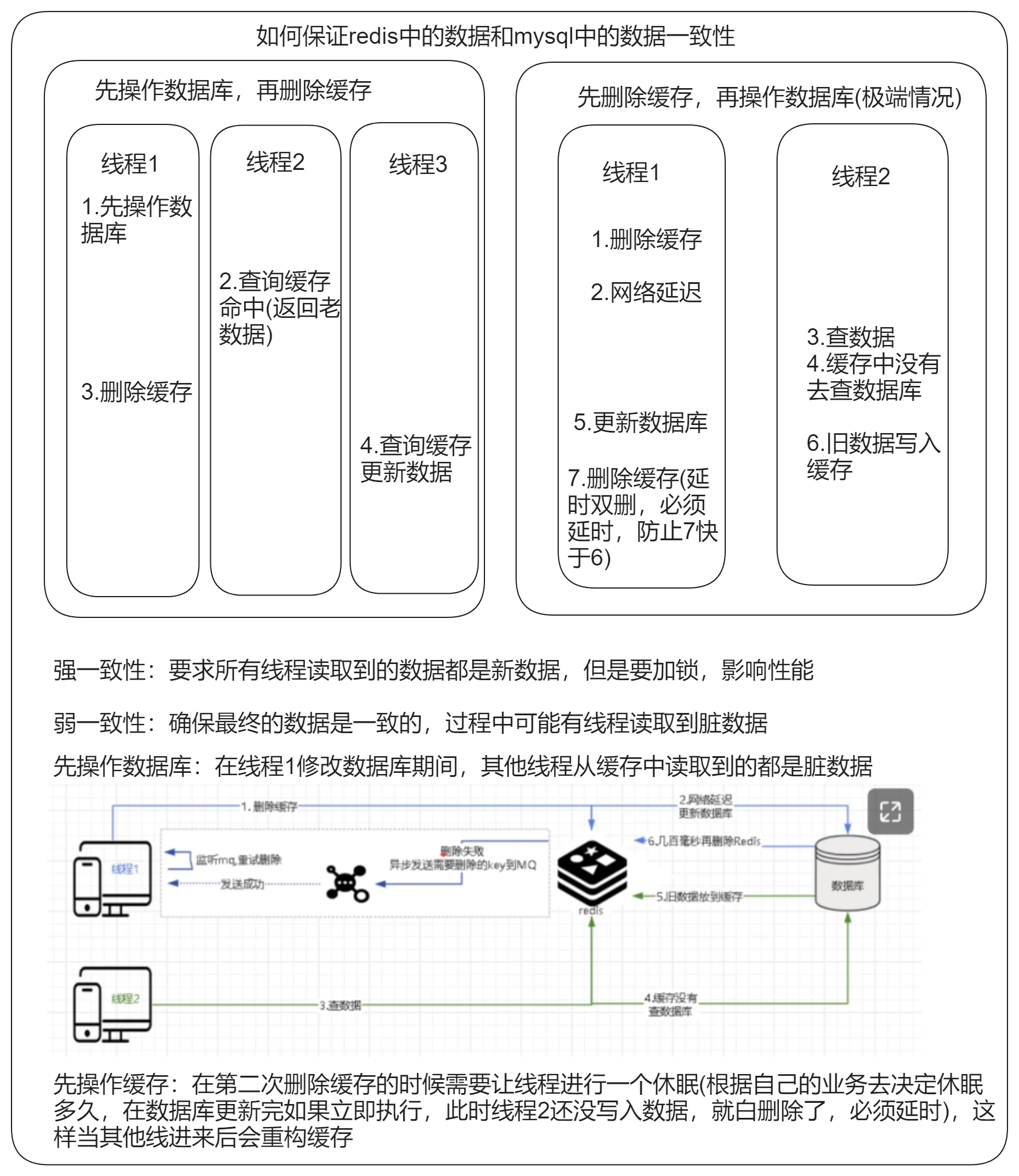
无论是先操作数据库还是先删除缓存,都会出现有线程读取到脏数据的情况,推荐使用先操作数据库的方式,而且两种方式如果没有上锁的话都是弱一致,都是最终确保数据的一致性
三.缓存击穿,缓存穿透,缓存雪崩及解决方案
缓存击穿
概述:缓存击穿是指一个热点key过期或这个缓存业务重建复杂,恰好再这个时间点有大量请求到来,查询缓存没有,请求全部打到数据库中,给数据库带来巨大压力
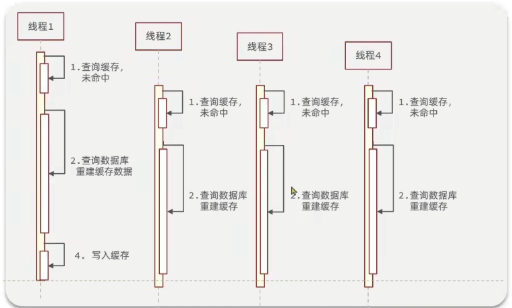
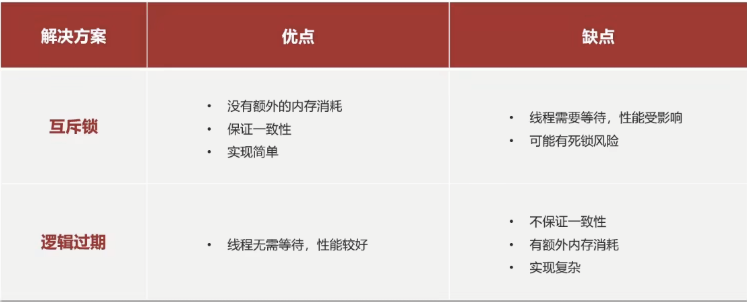
解决方案:互斥锁,逻辑过期
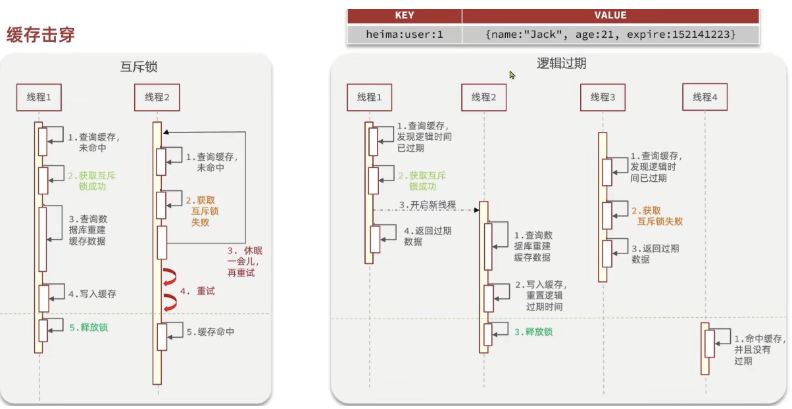
互斥锁:互相等待,只有一个线程在重建缓存,其他线程都在等待,性能差
在使用互斥锁方案中,如果是多集群模式,需要使用分布式锁,因为在每一个Tomact服务器中都有一把锁,多个服务器就会有多把锁
逻辑过期:再添加缓存数据时,不设置过期时间,只增加一个过期字段,对数据一致性需求高的业务不可用,因为在重建缓存之前,如果数据库中的数据更改了,没有获得锁的线程直接返回了旧数据
为什么需要开辟一个线程单独重构缓存,在加入双写一致性问题中不是解决了双写一致问题吗?
首先,需要明确的是在逻辑过期方案中写缓存业务的时候,操作数据库时不会删除缓存,因为逻辑过期就是为了这个缓存key一直存在,所以在逻辑过期解决方案中是需要在缓存逻辑过期后去更新缓存的,确保缓存中的是新数据
缓存穿透
概述:缓存穿透是指客户端请求的数据在缓存和数据库中都不存在,这样缓存永远都不不会生效,请求全部打到数据库,这种情况一般是遭到了恶意攻击
解决方案:缓存空对象,布隆过滤
缓存空对象:当数据库中也查询不到这个数据,将这个数据的值存为null存到缓存中
优点:实现简单,维护方便
缺点:额外的内存消耗,可能造成短期的数据不一致(在构建缓存后,数据库有了数据)
布隆过滤:
概述:布隆过滤是一种算法,底层使用BitMap来实现,也就是一个bit数组,用于快速判断一个元素是否在一个集合中
优点:内存空间占用少,没有多余的key
缺点:实现复杂,存在误差(数组越长,误判率越低)
缓存雪崩
概述:在同一时间点内,大量的缓存同时过期或redis服务宕机,导致请求全部到达数据库,带来巨大压力
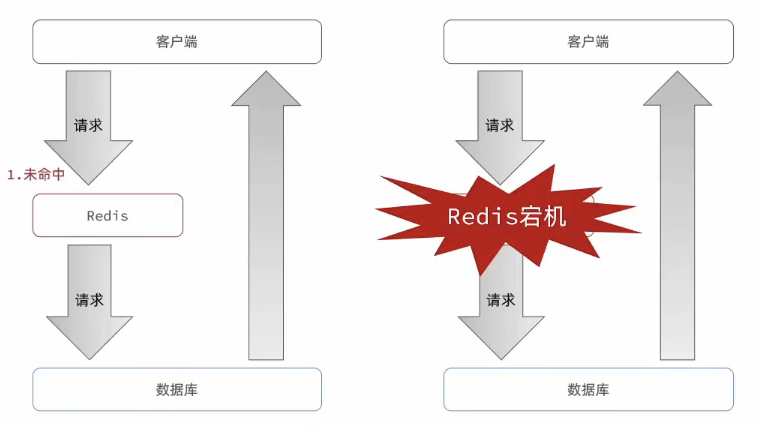
大量缓存失效:给缓存失效时间添加随机值
redis服务宕机:
利用redis集群提高服务的可用性
给业务添加多级缓存
给缓存业务添加降级限流策略
示例代码:
private Shop queryWithMutex(Long id){String key = RedisConstants.CACHE_SHOP_KEY +id;String shopJson = stringRedisTemplate.opsForValue().get(key);if(StrUtil.isNotBlank(shopJson)){Shop shop = JSONUtil.toBean(shopJson,Shop.class);return shop;}if(shopJson != null){return null;}// TODO 实现缓存重建,获取互斥锁String lockKey = "lock:shop"+id;Shop shop = null;// TODO 判断是否获取成功try {boolean isLock = tryLock(lockKey);if(!isLock){// TODO 失败,则休眠重试Thread.sleep(50);return queryWithMutex(id);//递归重试}// TODO 成功,查询数据库shop = getById(id);//Mybatis-Plus提供的单表查询//模拟重建延时Thread.sleep(200);if(shop == null){stringRedisTemplate.opsForValue().set(key,"",RedisConstants.CACHE_NULL_TTL, TimeUnit.MINUTES);return null;}stringRedisTemplate.opsForValue().set(key,JSONUtil.toJsonStr(shop),RedisConstants.CACHE_SHOP_TTL, TimeUnit.MINUTES);}catch(InterruptedException e){throw new RuntimeException(e);}finally{unlock(lockKey);}//TODO 写入缓存,释放互斥锁return shop;}