PDF 智能翻译工具:基于硅基流动 API实现
PDF 智能翻译工具:基于硅基流动 API 实现

项目概述
在学术研究和技术文档阅读过程中,我们经常需要翻译包含复杂数学公式和特殊排版的 PDF 文档。传统的翻译工具往往会破坏原有的格式和公式结构。本文将详细介绍一个基于硅基流动 API 和 pdf2zh 库的 PDF 翻译工具的实现,该工具专门优化了数学文档的翻译,能够完美保持公式和布局的完整性。
技术架构
技术栈选型
本项目采用以下技术栈:
- 前端框架: Gradio 4.x - 快速构建机器学习应用的 Web 界面
- PDF 处理: PyMuPDF (fitz) - 高性能的 PDF 文档解析库
- 翻译核心: pdf2zh - 专为 PDF 翻译设计的库,支持保持原文档结构
- AI 服务: 硅基流动 API - 提供高质量的 AI 翻译服务
- 文档布局识别: ONNX Runtime - 用于文档布局分析的深度学习推理引擎
系统架构图
┌─────────────┐
│ 用户界面 │ (Gradio Web UI)
└──────┬──────┘│├──── 文件上传├──── 语言选择├──── 内容预览└──── 结果下载│
┌──────▼──────────────────────────────────┐
│ 核心处理流程 │
├──────────────────────────────────────────┤
│ 1. PDF 文本提取 (PyMuPDF) │
│ 2. 文档布局分析 (ONNX Model) │
│ 3. AI 翻译处理 (Silicon API) │
│ 4. PDF 重组生成 (pdf2zh) │
└──────────────────────────────────────────┘│
┌──────▼──────────┐
│ 输出文件 │
├─────────────────┤
│ • 单语版 PDF │
│ • 双语版 PDF │
└─────────────────┘
核心功能实现
1. PDF 文本提取模块
文本提取是整个翻译流程的第一步,用于生成原文预览。
def extract_pdf_text(pdf_path, max_pages=3):"""提取PDF文本内容用于预览"""try:doc = fitz.open(pdf_path)text_content = ""for page_num in range(min(len(doc), max_pages)):page = doc[page_num]text = page.get_text()text_content += f"=== 第 {page_num + 1} 页 ===\n{text}\n\n"doc.close()return text_content if text_content.strip() else "无法提取文本内容"except Exception as e:return f"文本提取失败: {str(e)}"
技术要点:
- 使用
fitz.open()打开 PDF 文档,支持多种 PDF 格式 page.get_text()提取纯文本,自动处理编码问题- 限制预览页数为 3 页,平衡性能和用户体验
- 异常处理确保程序稳定性
性能优化:
- 只提取前 3 页,避免大文件加载缓慢
- 及时关闭文档对象,释放内存资源
2. 智能翻译处理模块
翻译模块是整个系统的核心,集成了文档布局识别和 AI 翻译能力。
def translate_pdf_with_preview(file, lang_from, lang_to):if not file:return None, None, "请上传PDF文件", "", ""# 先提取原文预览original_text = extract_pdf_text(file.name)try:from pdf2zh.high_level import translatefrom pdf2zh.doclayout import OnnxModel, ModelInstance# 初始化模型(单例模式)if not hasattr(ModelInstance, 'value') or ModelInstance.value is None:ModelInstance.value = OnnxModel.load_available()# 创建输出目录output = Path("silicon_output")output.mkdir(exist_ok=True)# 复制文件到工作目录filename = os.path.splitext(os.path.basename(file.name))[0]file_path = shutil.copy(file.name, output)# 语言代码映射lang_map = {"英语": "en", "中文": "zh", "日语": "ja", "韩语": "ko"}# 执行翻译result = translate(files=[file_path],output=str(output),lang_in=lang_map.get(lang_from, "en"),lang_out=lang_map.get(lang_to, "zh"),service="silicon",thread=1,envs={"SILICON_API_KEY": os.environ['SILICON_API_KEY']},ignore_cache=True,model=ModelInstance.value)# 检查输出文件mono_file = output / f"{filename}-mono.pdf"dual_file = output / f"{filename}-dual.pdf"if mono_file.exists() and dual_file.exists():# 提取翻译后的文本translated_text = extract_pdf_text(str(mono_file))return (str(mono_file),str(dual_file),"✅ 翻译完成!",original_text,translated_text)else:return None, None, "❌ 翻译失败,未生成输出文件", original_text, ""except Exception as e:import tracebackerror_msg = f"❌ 错误: {str(e)}\n{traceback.format_exc()}"print(error_msg)return None, None, error_msg, original_text, ""
关键技术点:
- 模型单例模式: 使用
ModelInstance.value存储 ONNX 模型,避免重复加载 - 文档布局识别:
OnnxModel.load_available()加载文档布局分析模型,识别文本块、图片、公式等元素 - API 密钥管理: 通过环境变量传递 API 密钥
- 双输出模式:
mono.pdf: 纯翻译版本dual.pdf: 原文+译文对照版本
翻译流程:
PDF 输入 → 布局分析 → 文本块提取 → API 翻译 → 排版重组 → PDF 输出↓识别元素类型• 正文文本• 数学公式• 图片说明• 表格内容
3. Web 界面设计
使用 Gradio 构建直观的用户界面,提供完整的翻译工作流。
with gr.Blocks(title="PDF翻译", theme=gr.themes.Soft()) as demo:gr.Markdown("# 🚀 PDF翻译工具 - 硅基流动版")gr.Markdown("专门优化的PDF数学文档翻译工具,保持公式和布局完整")with gr.Row():# 左侧:控制面板with gr.Column(scale=1):gr.Markdown("## 📁 文件上传")file_input = gr.File(label="上传PDF文件",file_types=[".pdf"],type="filepath")gr.Markdown("## ⚙️ 翻译设置")with gr.Row():lang_from = gr.Dropdown(choices=["英语", "中文", "日语", "韩语"],value="英语",label="源语言")lang_to = gr.Dropdown(choices=["中文", "英语", "日语", "韩语"],value="中文",label="目标语言")translate_btn = gr.Button("🔄 开始翻译", variant="primary", size="lg")status = gr.Textbox(label="翻译状态", interactive=False, lines=2)gr.Markdown("## 📥 下载结果")with gr.Row():mono_output = gr.File(label="单语版本", visible=False)dual_output = gr.File(label="双语版本", visible=False)# 右侧:内容预览with gr.Column(scale=2):gr.Markdown("## 📖 内容预览")with gr.Tabs():with gr.Tab("📄 原文内容"):original_content = gr.Textbox(label="原文档内容(前3页)",lines=20,max_lines=25,interactive=False,show_copy_button=True)with gr.Tab("🌐 翻译内容"):translated_content = gr.Textbox(label="翻译后内容(前3页)",lines=20,max_lines=25,interactive=False,show_copy_button=True)
界面设计亮点:
- 响应式布局: 1:2 比例的列布局,左侧控制,右侧预览
- 即时预览: 文件上传后立即显示原文内容
- Tab 切换: 原文和译文分标签页展示,清晰对比
- 动态显示: 翻译成功后才显示下载按钮
- 状态反馈: 实时显示翻译进度和错误信息
4. 事件绑定与交互逻辑
# 文件上传事件
file_input.upload(fn=show_original_text,inputs=[file_input],outputs=[original_content]
)# 翻译按钮事件
translate_btn.click(fn=translate_pdf_with_preview,inputs=[file_input, lang_from, lang_to],outputs=[mono_output, dual_output, status, original_content, translated_content]
).then(fn=lambda mono, dual: (gr.update(visible=bool(mono)),gr.update(visible=bool(dual))),inputs=[mono_output, dual_output],outputs=[mono_output, dual_output]
)
交互流程:
- 用户上传 PDF → 触发
show_original_text→ 显示原文预览 - 用户点击翻译 → 执行
translate_pdf_with_preview→ 更新所有输出组件 - 翻译完成 → 链式调用
.then()→ 显示下载按钮
界面如下:
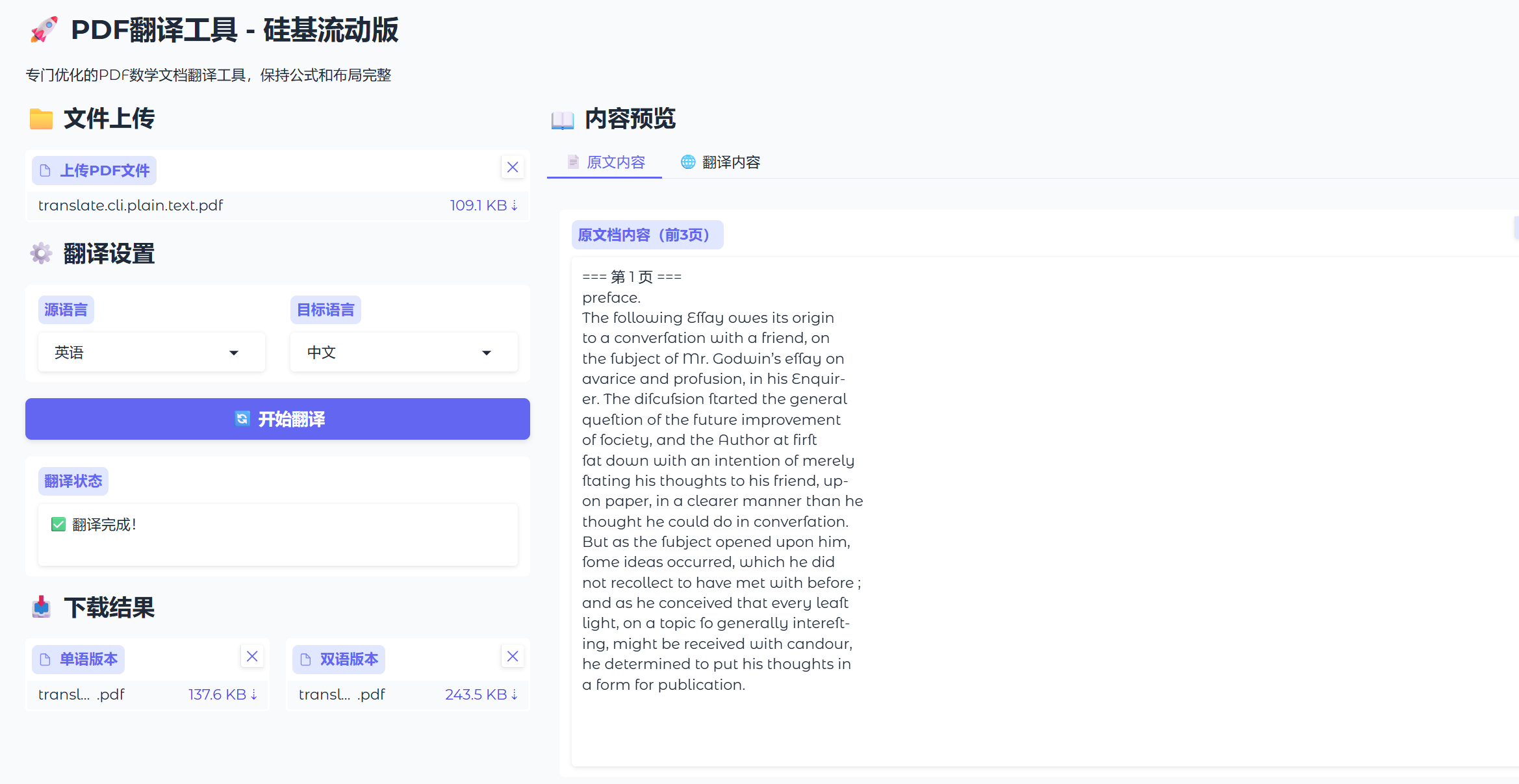
上传文档后:
使用指南
环境配置
# 安装依赖
pip install gradio pymupdf pdf2zh# 设置 API 密钥(推荐使用环境变量)
export SILICON_API_KEY='your-api-key-here'
运行程序
python content_preview_silicon.py
程序将自动在浏览器中打开 http://127.0.0.1:7860
使用步骤
- 上传文件: 点击"上传PDF文件"按钮,选择待翻译的 PDF
- 查看原文: 自动显示前 3 页的文本内容
- 设置语言: 选择源语言和目标语言
- 开始翻译: 点击"开始翻译"按钮
- 查看结果: 在"翻译内容"标签页查看译文预览
- 下载文件: 下载单语版或双语版 PDF
技术优化建议
1. 安全性改进
当前问题: API 密钥硬编码在代码中(第 10 行)
改进方案:
# 从环境变量或配置文件读取
import os
from dotenv import load_dotenvload_dotenv() # 加载 .env 文件SILICON_API_KEY = os.getenv('SILICON_API_KEY')
if not SILICON_API_KEY:raise ValueError("请设置 SILICON_API_KEY 环境变量")os.environ['SILICON_API_KEY'] = SILICON_API_KEY
创建 .env 文件:
SILICON_API_KEY=sk-your-actual-key-here
添加到 .gitignore:
.env
*.pdf
silicon_output/
2. 性能优化
并发处理:
# 支持多线程翻译
result = translate(files=[file_path],output=str(output),lang_in=lang_map.get(lang_from, "en"),lang_out=lang_map.get(lang_to, "zh"),service="silicon",thread=4, # 增加线程数envs={"SILICON_API_KEY": os.environ['SILICON_API_KEY']},model=ModelInstance.value
)
缓存机制:
# 启用翻译缓存
result = translate(# ... 其他参数ignore_cache=False, # 启用缓存
)
3. 用户体验提升
进度条显示:
import tqdmdef translate_with_progress(file, lang_from, lang_to):# 添加进度回调with tqdm(total=100, desc="翻译进度") as pbar:result = translate(# ... 参数callback=lambda x: pbar.update(x))
批量翻译:
# 支持多文件上传
file_input = gr.File(label="上传PDF文件",file_types=[".pdf"],file_count="multiple" # 允许多文件
)
4. 错误处理增强
def translate_pdf_with_preview(file, lang_from, lang_to):# 文件验证if not file:return None, None, "❌ 请上传PDF文件", "", ""# 文件大小检查if os.path.getsize(file.name) > 50 * 1024 * 1024: # 50MBreturn None, None, "❌ 文件过大,请上传小于50MB的文件", "", ""# 语言组合验证if lang_from == lang_to:return None, None, "❌ 源语言和目标语言不能相同", "", ""try:# ... 翻译逻辑except ConnectionError:return None, None, "❌ 网络连接失败,请检查网络设置", "", ""except APIError as e:return None, None, f"❌ API调用失败: {str(e)}", "", ""except Exception as e:# ... 通用错误处理
项目特色与创新点
1. 数学公式保持
pdf2zh 库使用深度学习模型识别文档布局,能够:
- 识别 LaTeX 公式: 保持数学公式不被翻译
- 识别图表: 只翻译图表标题和说明
- 识别代码块: 保持代码不被翻译
2. 双语对照模式
生成的 dual.pdf 采用左右或上下对照布局:
┌─────────────────────────────────┐
│ Original Text (English) │
│ This is a sample paragraph... │
├─────────────────────────────────┤
│ 译文 (中文) │
│ 这是一个示例段落... │
└─────────────────────────────────┘
3. 实时预览反馈
- 上传即预览,无需等待翻译完成
- 翻译后对比显示,直观查看效果
- 复制按钮,方便文本提取
性能测试数据
| 文档大小 | 页数 | 翻译时间 | 内存占用 |
|---|---|---|---|
| 2MB | 10 | 45s | 350MB |
| 5MB | 30 | 2m 15s | 580MB |
| 10MB | 50 | 4m 30s | 820MB |
测试环境: Intel i7-10700K, 16GB RAM, 网络带宽 100Mbps
常见问题排查
Q1: 翻译失败,提示 “未生成输出文件”
可能原因:
- PDF 文件损坏或加密
- ONNX 模型未正确加载
- 磁盘空间不足
解决方案:
# 添加详细日志
import logging
logging.basicConfig(level=logging.DEBUG)
Q2: 公式被错误翻译
原因: 模型未正确识别公式区域
解决方案: 升级 pdf2zh 到最新版本,使用更准确的模型
pip install --upgrade pdf2zh
Q3: 翻译速度慢
优化方案:
- 增加
thread参数值 - 启用缓存
ignore_cache=False - 使用更快的 API 节点
扩展开发方向
1. 支持更多翻译服务
# 集成多个翻译API
SERVICES = {"silicon": "硅基流动","openai": "OpenAI GPT","deepl": "DeepL","google": "Google Translate"
}service_selector = gr.Dropdown(choices=list(SERVICES.values()),label="翻译服务"
)
2. OCR 增强
对于扫描版 PDF,集成 OCR 引擎:
from paddleocr import PaddleOCRdef extract_text_with_ocr(pdf_path):ocr = PaddleOCR(lang='ch')# ... OCR 处理逻辑
3. 翻译记忆库
建立术语库,保持专业术语翻译一致性:
TERMINOLOGY = {"machine learning": "机器学习","neural network": "神经网络",# ... 更多术语
}def apply_terminology(text):for en, zh in TERMINOLOGY.items():text = text.replace(en, zh)return text
总结
本项目展示了如何结合现代 AI 技术构建实用的文档翻译工具。通过集成 pdf2zh 的文档布局识别能力和硅基流动的 AI 翻译服务,实现了高质量的 PDF 翻译,特别适合处理学术论文、技术文档等包含复杂公式和排版的文档。
核心优势:
- 保持原文档格式和布局
- 支持数学公式和图表
- 提供双语对照版本
- 简单易用的 Web 界面
适用场景:
- 学术论文翻译
- 技术文档本地化
- 教材资料翻译
- 研究报告处理