LLMs之Multi-Agent:BettaFish的简介、安装和使用方法、案例应用之详细攻略
LLMs之Multi-Agent:BettaFish的简介、安装和使用方法、案例应用之详细攻略
目录
BettaFish的简介
1、特点
2、系统架构
2.1、 整体架构与核心组件
2.2、 一次完整分析流程
2.3、 项目代码结构树
BettaFish的安装和使用方法
1、安装
步骤 1: 启动项目
步骤 2: 配置说明
数据库配置 (PostgreSQL):
大模型配置 (LLM):
2、使用方法
环境要求:
步骤 1: 创建环境
步骤 2: 安装依赖包
步骤 3: 安装Playwright浏览器驱动
步骤 4: 配置LLM与数据库
步骤 5: 启动系统
启动完整系统 (推荐):
爬虫系统单独使用 (MindSpider):
BettaFish的案例应用
BettaFish的简介
“微舆”(BettaFish)是一个从零开始实现的创新型多智能体(Multi-Agent)舆情分析系统。它的核心目标是帮助用户打破信息茧房,通过深度分析还原舆情事件的全貌,预测未来的发展趋势,并为决策提供辅助支持。
该项目的设计理念是让用户能够像进行聊天对话一样,简单地提出分析需求,系统中的多个智能体便会自动开始执行任务,分析来自国内外超过30个主流社交媒体平台以及数百万条大众评论的数据。
项目的英文名 BettaFish,中文谐音“微鱼”,指的是一种体型虽小但非常好斗和漂亮的鱼(斗鱼),象征着项目“小而强大,不畏挑战”的精神。项目的长远目标是超越舆情分析本身,成为一个能够驱动所有业务场景的、简洁且通用的数据分析引擎。
Github地址:https://github.com/666ghj/BettaFish
1、特点
根据项目文档,“微舆”系统拥有六大核心优势以及独特的协作机制:
| AI驱动的全域监控 | AI驱动的全域监控 (AI-Driven Full-Spectrum Monitoring): 系统内置的AI爬虫集群能够7x24小时不间断地工作。 监控范围广泛,全面覆盖微博、小红书、抖音、快手等10余个国内外关键社交媒体平台。 不仅能实时捕捉热点内容,还能深入挖掘海量的用户评论,从而获取最真实、最广泛的大众声音。 |
| 超越LLM的复合分析引擎 | 超越LLM的复合分析引擎 (Hybrid Analysis Engine Beyond LLM): 系统不单纯依赖大语言模型(LLM),而是融合了5类专业设计的Agent、微调模型(Finetuned Models)和统计模型等多种中间件。 通过多模型协同工作,确保了分析结果的深度、准确性和多维视角。 |
| 强大的多模态能力 | 强大的多模态能力 (Powerful Multimodal Capabilities): 系统能够突破传统的图文限制,深度解析抖音、快手等平台的短视频内容。 它还能精准提取现代搜索引擎中呈现的天气、日历、股票等结构化的多模态信息卡片,从而让用户全面掌握舆情动态。 |
| Agent“论坛”协作机制 | Agent“论坛”协作机制 (Agent "Forum" Collaboration Mechanism): 为不同的Agent赋予了独特的工具集和思维模式。 引入了一个“辩论主持人模型”(LLM Host),通过“论坛”(ForumEngine)机制让Agent们进行链式思维的碰撞与辩论。 这种机制避免了单一模型思维的局限性以及因交流导致的思想同质化,旨在催生出更高质量的集体智能和决策支持。 |
| 公私域数据无缝融合 | 公私域数据无缝融合 (Seamless Integration of Public and Private Data): 平台不仅能分析公开的舆情数据,还提供了高安全性的接口。 支持用户将企业内部的业务数据库与外部舆情数据进行无缝集成,打通数据壁垒,为垂直业务提供“外部趋势+内部洞察”的强大分析能力。 |
| 轻量化与高扩展性框架 | 轻量化与高扩展性框架 (Lightweight and Highly Extensible Framework): 项目基于纯Python进行模块化设计,不依赖任何重型框架,实现了轻量化和一键式部署。 代码结构清晰,方便开发者轻松集成自定义的模型和业务逻辑,从而实现平台的快速扩展与深度定制。 |
2、系统架构
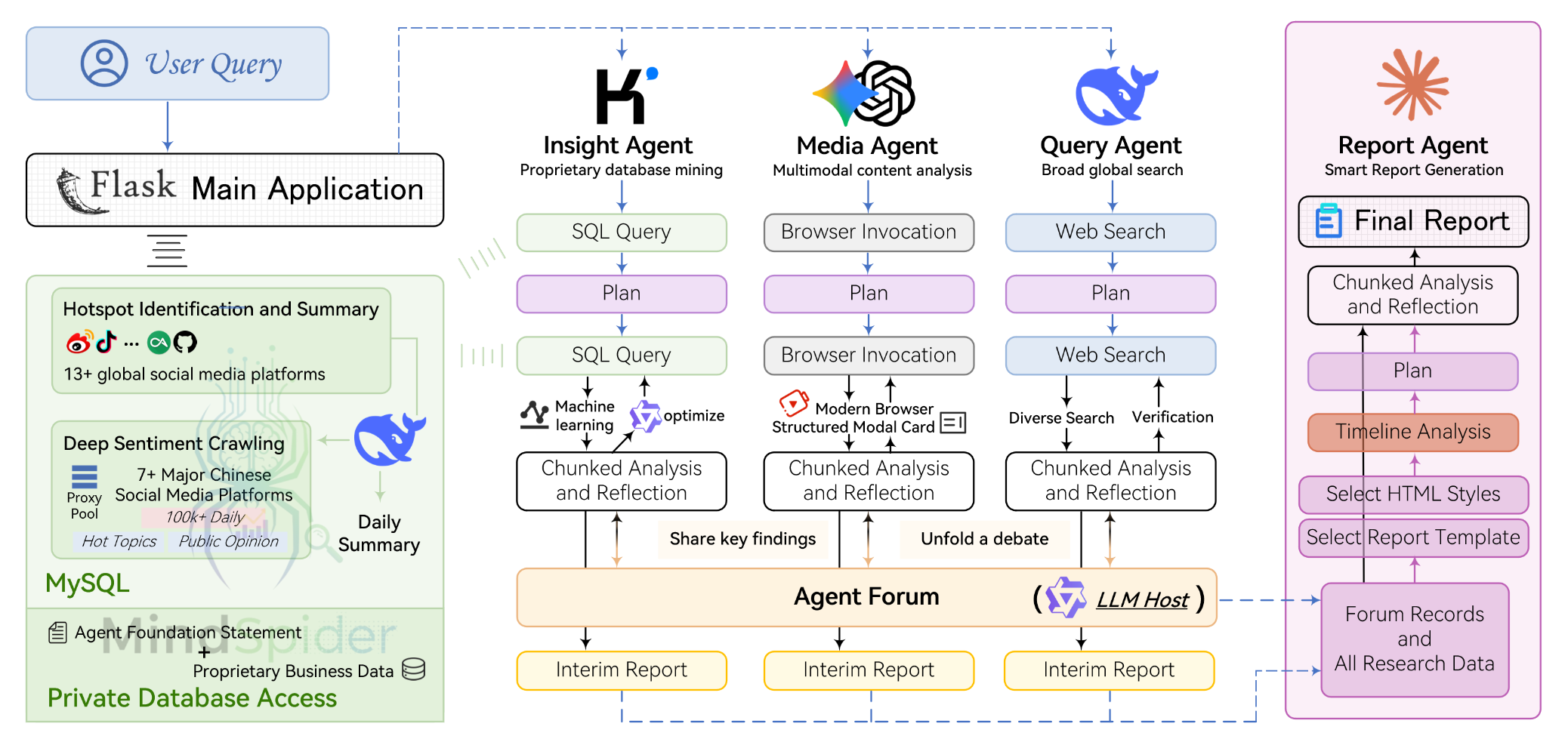
“微舆”项目采用了一个模块化、多智能体(Multi-Agent)协同工作的系统架构。该架构的核心思想是通过多个各司其职的专业Agent并行工作,并通过一个独特的“论坛”机制进行协作和信息融合,最终由一个专门的Agent生成综合性报告。
2.1、 整体架构与核心组件
系统主要由四大核心分析Agent和一个协作引擎构成,它们分别是:
-
Query Agent (精准信息搜索Agent):
- 职责: 负责执行精准的信息搜索任务。
- 能力: 具备强大的国内外网页搜索能力,用于广泛搜集与用户查询相关的公开信息和新闻。
-
Media Agent (多模态内容分析Agent):
- 职责: 负责分析图文之外的多媒体内容。
- 能力: 具备强大的多模态内容理解能力,能够深度解析短视频(如抖音、快手)以及搜索引擎中的结构化信息卡片(如天气、股票),获取更丰富维度的信息。
-
Insight Agent (私有数据库挖掘Agent):
- 职责: 负责深度挖掘私有数据。
- 能力: 专注于分析和挖掘用户内部的私有舆情数据库或业务数据库,实现“外部趋势”与“内部洞察”的结合。
-
Report Agent (智能报告生成Agent):
- 职责: 负责整合所有分析结果并生成最终报告。
- 能力: 内置多种报告模板,能够根据分析主题动态选择模板和样式,通过多轮迭代的方式生成结构化、高质量的分析报告。
-
ForumEngine (论坛协作引擎):
- 职责: 充当Agent之间的协作与辩论平台。
- 机制: 监控各个Agent的分析进展和“发言”(即中间结论),并引入一个由大语言模型(LLM)驱动的“主持人”角色,对讨论进行总结和引导,促进更高质量的集体智能生成。
2.2、 一次完整分析流程
一个完整的分析任务从用户提问到生成报告,遵循以下步骤:
| 步骤 | 阶段名称 | 主要操作 | 参与组件 | 循环特性 |
|---|---|---|---|---|
| 1 | 用户提问 | Flask主应用接收用户的分析需求查询。 | Flask主应用 | - |
| 2 | 并行启动 | 系统同时启动 Query Agent、Media Agent 和 Insight Agent。 | Query Agent, Media Agent, Insight Agent | - |
| 3 | 初步分析 | 各个Agent使用其专属的工具集(如网页搜索、数据库查询)进行初步的概览式搜索。 | 各Agent + 专属工具集 | - |
| 4 | 策略制定 | 每个Agent根据初步分析的结果,独立制定后续深度研究的分块研究策略。 | 各Agent内部决策模块 | - |
| 5-N | 循环阶段 | 这是分析的核心环节,通过多轮的“深度研究”与“论坛协作”进行迭代。 | ForumEngine + 所有Agent | 多轮循环 |
| 5.1 | 深度研究 | 在每一轮中,各Agent根据ForumEngine中“主持人”的引导,进行更具针对性的专项搜索和分析。Agent内部还包含反思机制。 | 各Agent + 反思机制 + 论坛引导 | 每轮循环 |
| 5.2 | 论坛协作 | ForumEngine持续监控各个Agent的分析日志(发言),并调用LLM主持人生成阶段性总结,引导下一步的讨论方向。 | ForumEngine + LLM主持人 | 每轮循环 |
| 5.3 | 交流融合 | 各Agent通过forum_reader工具读取论坛中的讨论内容和主持人总结,根据其他Agent的发现和观点来调整自己的研究方向。 | 各Agent + forum_reader工具 | 每轮循环 |
| N+1 | 结果整合 | 循环结束后,Report Agent启动,负责收集所有分析Agent的最终产出以及ForumEngine中的全部讨论内容。 | Report Agent | - |
| N+2 | 报告生成 | Report Agent动态选择最合适的报告模板和样式,通过多轮润色和内容组织,生成最终的HTML格式分析报告。 | Report Agent + 模板引擎 | - |
2.3、 项目代码结构树
项目的代码结构清晰地反映了其模块化的设计思想,每个核心组件都是一个独立的目录:
BettaFish/
├── QueryEngine/ # 国内外新闻广度搜索Agent
│ ├── agent.py # Agent主逻辑
│ ├── tools/ # 搜索工具
│ └── ...
├── MediaEngine/ # 强大的多模态理解Agent
│ ├── agent.py # Agent主逻辑
│ ├── tools/ # 多模态搜索工具
│ └── ...
├── InsightEngine/ # 私有数据库挖掘Agent
│ ├── agent.py # Agent主逻辑
│ ├── tools/ # 数据库查询、关键词优化、情感分析工具
│ ├── nodes/ # 报告结构、搜索、总结等处理节点
│ └── ...
├── ReportEngine/ # 多轮报告生成Agent
│ ├── agent.py # Agent主逻辑
│ ├── nodes/ # 模板选择、HTML生成等节点
│ └── report_template/ # 报告模板库 (如:社会公共热点事件分析.md)
├── ForumEngine/ # 论坛引擎简易实现
│ ├── monitor.py # 日志监控和论坛管理
│ └── llm_host.py # 论坛主持人LLM模块
├── MindSpider/ # 独立的微博爬虫系统
│ ├── BroadTopicExtraction/ # 话题提取模块
│ └── DeepSentimentCrawling/ # 深度舆情爬取模块
├── SentimentAnalysisModel/ # 情感分析模型集合
│ ├── WeiboMultilingualSentiment/# 多语言情感分析(推荐)
│ ├── WeiboSentiment_SmallQwen/ # 小参数Qwen3微调模型
│ └── ... # 其他微调及机器学习模型
├── SingleEngineApp/ # 单独Agent的Streamlit应用,用于独立测试
├── templates/ # Flask网页模板
├── static/ # 静态资源文件
├── logs/ # 运行日志目录
├── final_reports/ # 最终生成的HTML报告存放目录
├── utils/ # 通用工具函数 (如Agent间论坛通信工具)
├── app.py # Flask主应用入口
├── config.py # 全局配置文件
└── requirements.txt # Python依赖包清单
这个结构清晰地展示了每个Agent如何作为一个独立的子系统存在,同时像MindSpider(爬虫系统)和SentimentAnalysisModel(情感分析模型)这样的组件作为底层能力,为上层Agent提供数据和分析工具支持。ForumEngine则作为粘合剂,将各个独立的Agent组织成一个协同工作的有机整体。
BettaFish的安装和使用方法
1、安装
项目提供了两种主要的部署方式:Docker快速部署和源码启动。
Docker 快速开始 (Recommended)
这是最推荐的启动方式,可以一键部署所有服务。
步骤 1: 启动项目
在项目根目录下执行以下命令,即可在后台启动所有服务:
docker compose up -d注意: 如果默认的镜像拉取速度慢,docker-compose.yml 文件中已通过注释提供了备用镜像地址供替换。
步骤 2: 配置说明
启动后,需要进行必要的配置。所有配置项现在都统一在项目根目录的 .env 文件中管理。
数据库配置 (PostgreSQL):
DB_HOST: db (Docker服务名)
DB_PORT: 5432
DB_USER: bettafish
DB_PASSWORD: bettafish
DB_NAME: bettafish大模型配置 (LLM):
系统所有LLM调用均采用与OpenAI API兼容的接口标准。需要在 .env 文件中配置您选择的大模型服务的API_KEY, BASE_URL, 和 MODEL_NAME。
2、使用方法
适合希望深入了解系统搭建或进行二次开发的开发者。
环境要求:
操作系统: Windows, Linux, MacOS
Python版本: 3.9+
Conda: Anaconda 或 Miniconda
数据库: PostgreSQL (推荐) 或 MySQL
内存: 建议 2GB 以上
步骤 1: 创建环境
使用 Conda:
conda create -n your_conda_name python=3.11
conda activate your_conda_name或者使用 uv:
uv venv --python 3.11步骤 2: 安装依赖包
pip install -r requirements.txt或使用更快的 uv:
uv pip install -r requirements.txt提示: 如果不想使用本地情感分析模型,可以先注释掉 requirements.txt 文件中“机器学习”相关的部分再安装。
步骤 3: 安装Playwright浏览器驱动
此驱动用于爬虫功能。
playwright install chromium步骤 4: 配置LLM与数据库
复制项目根目录下的 .env.example 文件,并重命名为 .env。
编辑 .env 文件,填入您的数据库连接信息(主机、端口、用户、密码、库名等)和LLM的API密钥、Base URL以及模型名称。
步骤 5: 启动系统
启动完整系统 (推荐):
激活环境后,在项目根目录运行:
python app.py
启动后,访问 http://localhost:5000 即可使用完整系统。单独启动某个Agent:
如果只想测试或使用单个Agent,可以运行独立的Streamlit应用:
# 启动QueryEngine
streamlit run SingleEngineApp/query_engine_streamlit_app.py --server.port 8503# 启动MediaEngine
streamlit run SingleEngineApp/media_engine_streamlit_app.py --server.port 8502# 启动InsightEngine
streamlit run SingleEngineApp/insight_engine_streamlit_app.py --server.port 8501爬虫系统单独使用 (MindSpider):
爬虫系统需要单独操作。
# 进入爬虫目录
cd MindSpider# 项目初始化
python main.py --setup# 运行话题提取(获取热点新闻)
python main.py --broad-topic# 运行完整爬虫流程
python main.py --complete --date 2024-01-20BettaFish的案例应用
项目文档中明确提供了一个完整的应用案例来展示系统的分析能力。
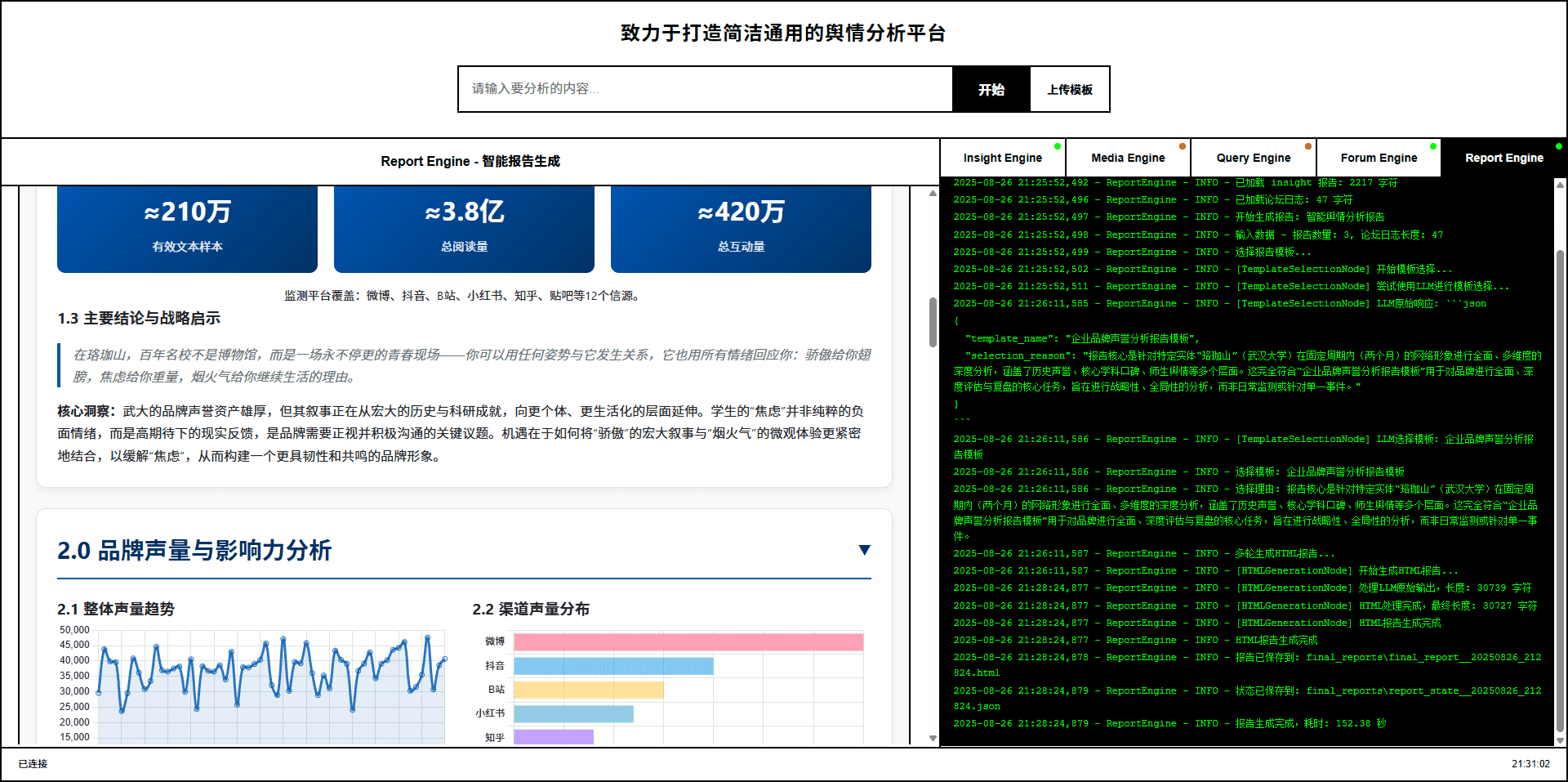
核心案例:武汉大学舆情分析
系统以“武汉大学舆情”为例,生成了一份详细的**《武汉大学品牌声誉深度分析报告》**。文档中提供了该报告的链接供用户查看。
同时,还提供了一个完整的运行视频,展示了从提出需求到生成报告的全过程,视频标题为**《视频-武汉大学品牌声誉深度分析报告》**。
应用扩展性
文档强调了该项目的通用性,指出“始于舆情,而不止于舆情”。它举例说明,用户只需简单修改Agent的工具集API参数和Prompt(提示词),就可以将这个系统转变为其他领域的分析工具,例如金融领域的市场分析系统。这展示了其作为通用数据分析引擎的巨大潜力。