nats jetstream 测试和客户端分析
基础分析
当创建stream的时候,最重要的 option 是 retentionPolicy
StreamConfiguration config = StreamConfiguration.builder()
.name(streamName)
.subjects("TestStream.>")
.retentionPolicy(RetentionPolicy.Interest)
.build();
when choose interest policy,must start at least one consumer before create stream
选择interest 策略时,必须在创建流之前至少启动一个消费者,LimitsPolicy 可以和其它policy叠加:
- LimitsPolicy (default) - Retention based on the various limits that are set including: MaxMsgs, MaxBytes, MaxAge, and MaxMsgsPerSubject. If any of these limits are set, whichever limit is hit first will cause the automatic deletion of the respective message(s). See a full code example.
- WorkQueuePolicy - Retention with the typical behavior of a FIFO queue. Each message can be consumed only once. This is enforced by only allowing one consumer to be created per subject for a work-queue stream (i.e. the consumers’ subject filter(s) must not overlap). Once a given message is ack’ed, it will be deleted from the stream. See a full code example.
- InterestPolicy - Retention based on the consumer interest in the stream and messages. The base case is that there are zero consumers defined for a stream. If messages are published to the stream, they will be immediately deleted so there is no interest. This implies that consumers need to be bound to the stream ahead of messages being published to the stream. Once a given message is ack’ed by all consumers filtering on the subject, the message is deleted (same behavior as WorkQueuePolicy). See a full code example.
当一个客户端发送了stream message,processJetStreamMsg 负责处理消息
// processJetStreamMsg is where we try to actually process the stream msg.
func (mset *stream) processJetStreamMsg(subject, reply string, hdr, msg []byte, lseq uint64, ts int64) error {
当一个消息保存到store后,一个全局的seq 被返回并送给客户端,实现了message的可最终和最少一次发送。
// Store actual msg.
if lseq == 0 && ts == 0 {
seq, ts, err = store.StoreMsg(subject, hdr, msg)
} else {
// Make sure to take into account any message assignments that we had to skip (clfs).
seq = lseq + 1 - clfs
// Check for preAcks and the need to skip vs store.
if mset.hasAllPreAcks(seq, subject) {
mset.clearAllPreAcks(seq)
store.SkipMsg()
} else {
err = store.StoreRawMsg(subject, hdr, msg, seq, ts)
}
}
msg先写入缓存,然后再写入磁盘,所以如果不是在集群模式下,可能会丢失
// Ask msg block to store in write through cache.
err = mb.writeMsgRecord(rl, seq, subj, hdr, msg, ts, fs.fip)
最后,写入磁盘的函数是flushPendingMsgsLocked
func (mb *msgBlock) flushPendingMsgsLocked() (*LostStreamData, error) {
send response to client's inbox
// Send response here.
if canRespond {
response = append(pubAck, strconv.FormatUint(seq, 10)...)
response = append(response, '}')
mset.outq.sendMsg(reply, response)
}
最后返回消息给客户端是如下函数
func (mset *stream) internalLoop()
func (c *client) processInboundClientMsg(msg []byte) (bool, bool) {
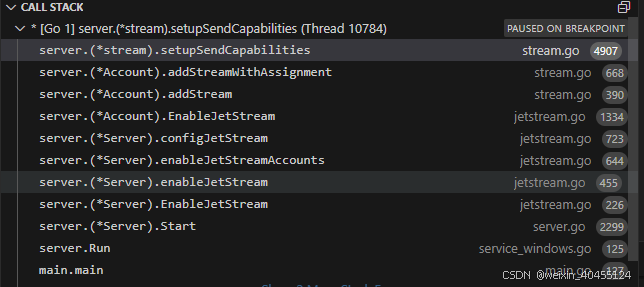
call stacks如下

func (mset *stream) internalLoop() 的关键代码如下:
case <-msgs.ch:
// This can possibly change now so needs to be checked here.
isClustered := mset.IsClustered()
ims := msgs.pop()
for _, im := range ims {
// If we are clustered we need to propose this message to the underlying raft group.
if isClustered {
mset.processClusteredInboundMsg(im.subj, im.rply, im.hdr, im.msg)
} else {
mset.processJetStreamMsg(im.subj, im.rply, im.hdr, im.msg, 0, 0)
}
im.returnToPool()
}
msgs.recycle(&ims)
internalLoop 在 func (mset *stream) setupSendCapabilities() 中被启动:
func (mset *stream) setupSendCapabilities() {
mset.mu.Lock()
defer mset.mu.Unlock()
if mset.outq != nil {
return
}
qname := fmt.Sprintf("[ACC:%s] stream '%s' sendQ", mset.acc.Name, mset.cfg.Name)
mset.outq = &jsOutQ{newIPQueue[*jsPubMsg](mset.srv, qname)}
go mset.internalLoop()
}
setupSendCapabilities 则是ibei stream startup function调用
func (a *Account) addStreamWithAssignment(config *StreamConfig, fsConfig *FileStoreConfig, sa *streamAssignment) (*stream, error) {
关键objects
// SubjectTree is an adaptive radix trie (ART) for storing subject information on literal subjects.
// Will use dynamic nodes, path compression and lazy expansion.
// The reason this exists is to not only save some memory in our filestore but to greatly optimize matching
// a wildcard subject to certain members, e.g. consumer NumPending calculations.
type SubjectTree[T any] struct {
root node
size int
}
type fileStore struct {
srv *Server
mu sync.RWMutex
state StreamState
tombs []uint64
ld *LostStreamData
scb StorageUpdateHandler
ageChk *time.Timer
syncTmr *time.Timer
cfg FileStreamInfo
fcfg FileStoreConfig
prf keyGen
oldprf keyGen
aek cipher.AEAD
lmb *msgBlock
blks []*msgBlock
bim map[uint32]*msgBlock
psim *stree.SubjectTree[psi]
tsl int
adml int
hh hash.Hash64
qch chan struct{}
fsld chan struct{}
cmu sync.RWMutex
cfs []ConsumerStore
sips int
dirty int
closing bool
closed bool
fip bool
receivedAny bool
firstMoved bool
}
consumer
创建函数
ConsumerConfiguration cc = ConsumerConfiguration.builder()
.durable(durationName)
.deliverPolicy(DeliverPolicy.All)
.deliverSubject("TestStream")
// if both set,otherwise where receive ErrorListenerLoggerImpl error but can work
.filterSubjects("TestStream.mouse_move.>")
// .filterSubjects("TestStream.mouse_move.>","TestStream.mouse_move")
// .filterSubject("TestStream.mouse_mve")
.build();
重要options
-
Persistence - Durable / Ephemeral
In addition to the choice of being push or pull, a consumer can also be ephemeral or durable. A consumer is considered durable when an explicit name is set on the Durable field when creating the consumer, or when InactiveThreshold is set.
Durables and ephemeral have the same message delivery semantics but an ephemeral consumer will not have persisted state or fault tolerance (server memory only) and will be automatically cleaned up (deleted) after a period of inactivity, when no subscriptions are bound to the consumer.
By default, consumers will have the same replication factor as the stream they consume, and will remain even when there are periods of inactivity (unless InactiveThreshold is set explicitly). Consumers can recover from server and client failure. -
DeliverPolicy
The policy choices include:- DeliverAll: Default policy. Start receiving from the earliest available message in the stream.
- DeliverLast: Start with the last message added to the stream, or the last message matching the consumer’s filter subject if defined.
- DeliverLastPerSubject: Start with the latest message for each filtered subject currently in the stream.
- DeliverNew: Start receiving messages created after the consumer was created.
- DeliverByStartSequence: Start at the first message with the specified sequence number. The consumer must specify OptStartSeq defining the sequence number.
- DeliverByStartTime: Start with messages on or after the specified time. The consumer must specify OptStartTime defining the start time.
-
DeliverSubject (both worked in push and pull model )
The subject to deliver messages to. Setting this field decides whether the consumer is push or pull-based. With a deliver subject, the server will push messages to clients subscribed to this subject.
FilterSubjects
A filter subject provides server-side filtering of messages before delivery to clients.
For example, a stream factory-events with subject factory-events.. can have a consumer factory-A with a filter factory-events.A.* to deliver only events for factory A.
A consumer can have a singular FilterSubject or plural FilterSubjects. Multiple filters can be applied, such as [factory-events.A., factory-events.B.] or specific event types [factory-events..item_produced, factory-events..item_packaged].
work queue type
When the stream is work queue type, all consumers must be in the same queue, otherwise the following errors may occur:
io.nats.client.JetStreamApiException: filtered consumer not unique on workqueue stream [10100]
at io.nats.client.api.ApiResponse.throwOnHasError(ApiResponse.java:88)
at io.nats.client.impl.NatsJetStreamImpl._createConsumer(NatsJetStreamImpl.java:132)
at io.nats.client.impl.NatsJetStreamManagement.addOrUpdateConsumer(NatsJetStreamManagement.java:131)
at io.nats.client.impl.NatsStreamContext.createOrUpdateConsumer(NatsStreamContext.java:91)
at io.nats.jetstreamtest.PullStreamConsumer.main(PullStreamConsumer.java:45)
When the stream is LimitsPolicy type not plus workqueue, push and pull consomer can both get message from stream.
- deliverGroup Option only work under WorkQueuePolicy stream
timeout 相关
可以使用如下模式设置timeout
timeout = jsOptions == null || jsOptions.getRequestTimeout() == null ? conn.getOptions().getConnectionTimeout() : jsOptions.getRequestTimeout();
JetStreamOptions jtOptions = JetStreamOptions.builder().requestTimeout(Duration.ofMinutes(10)).build();
JetStream js = nc.jetStream(jtOptions);