作业-三层神经网络拟合任意函数、手写数字识别、室内定位
作业1:拟合正弦函数
import tensorflow as tf
import numpy as np
import matplotlib.pyplot as plt
# 设置随机种子以确保结果可复现
tf.random.set_seed(42)
np.random.seed(42)
# 生成数据
x = np.linspace(-10, 10, 1000).reshape(-1, 1) # 输入数据
y = np.sin(x) # 目标函数
# 构建三层神经网络
model = tf.keras.Sequential([
tf.keras.layers.Dense(64, activation='relu', input_shape=(1,)), # 第一层,64个神经元
tf.keras.layers.Dense(64, activation='relu'), # 第二层,64个神经元
tf.keras.layers.Dense(1) # 输出层,1个神经元
])
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error')
# 训练模型
history = model.fit(x, y, epochs=100, batch_size=32, validation_split=0.2, verbose=1)
# 绘制训练过程中的损失曲线
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.legend()
plt.title('Training and Validation Loss')
plt.show()
# 使用训练好的模型进行预测
y_pred = model.predict(x)
# 绘制原始函数和拟合结果
plt.plot(x, y, label='Original Function')
plt.plot(x, y_pred, label='Fitted Function', linestyle='--')
plt.legend()
plt.title('Function Fitting Result')
plt.show()代码说明:
-
数据生成:我们生成了输入数据 x 和目标函数 y=sin(x)。
-
模型构建:使用 TensorFlow 的
Sequential模型构建了一个包含三层的神经网络。第一层和第二层是隐藏层,每层有 64 个神经元,激活函数为 ReLU;最后一层是输出层,输出一个值。 -
编译模型:使用 Adam 优化器和均方误差损失函数。
-
训练模型:训练 100 个 epoch,并将数据分为训练集和验证集。
-
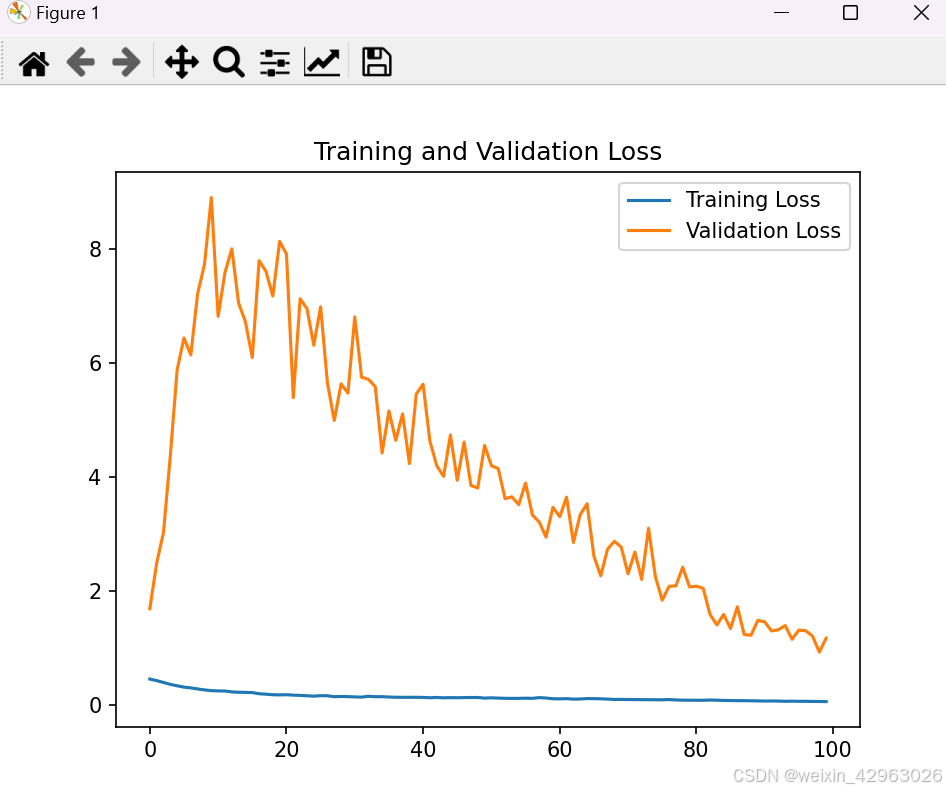
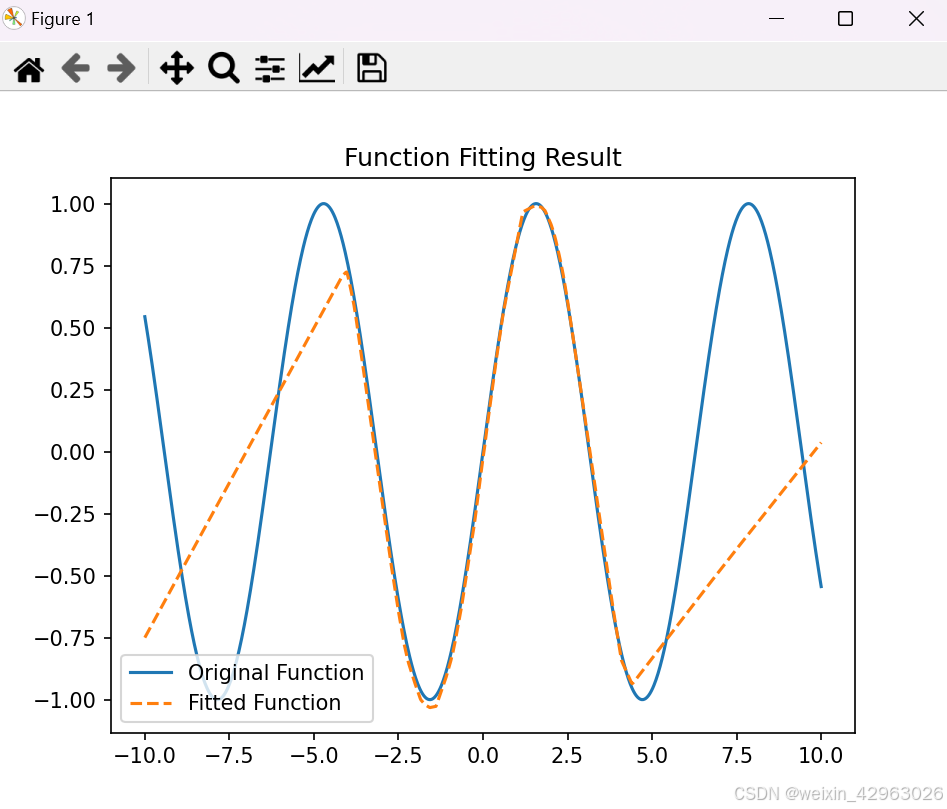
结果可视化:绘制训练和验证损失曲线,以及原始函数和拟合函数的对比图。
运行结果:
运行代码后,你会看到以下两幅图:
-
损失曲线:训练过程中的训练损失和验证损失。
-
拟合结果:原始正弦函数和神经网络拟合的函数。
作业2:识别手写数字
import tensorflow as tf
from tensorflow.keras.datasets import mnist
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Flatten
from tensorflow.keras.utils import to_categorical
import matplotlib.pyplot as plt
# 加载 MNIST 数据集
(x_train, y_train), (x_test, y_test) = mnist.load_data()
# 数据预处理
# 将像素值归一化到 [0, 1]
x_train = x_train.astype('float32') / 255.0
x_test = x_test.astype('float32') / 255.0
# 将标签转换为 one-hot 编码
y_train = to_categorical(y_train, 10)
y_test = to_categorical(y_test, 10)
# 构建三层神经网络模型
model = Sequential([
Flatten(input_shape=(28, 28)), # 将 28x28 的图像展平为 784 维向量
Dense(128, activation='relu'), # 第一层隐藏层,128 个神经元
Dense(64, activation='relu'), # 第二层隐藏层,64 个神经元
Dense(10, activation='softmax') # 输出层,10 个类别
])
# 编译模型
model.compile(optimizer='adam',
loss='categorical_crossentropy',
metrics=['accuracy'])
# 训练模型
history = model.fit(x_train, y_train, epochs=10, batch_size=32, validation_split=0.2)
# 评估模型
test_loss, test_acc = model.evaluate(x_test, y_test)
print(f"Test Accuracy: {test_acc:.4f}")
# 绘制训练过程中的损失和准确率曲线
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title('Loss Curves')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['accuracy'], label='Training Accuracy')
plt.plot(history.history['val_accuracy'], label='Validation Accuracy')
plt.title('Accuracy Curves')
plt.legend()
plt.show()
# 测试模型
predictions = model.predict(x_test)
predicted_labels = tf.argmax(predictions, axis=1)
true_labels = tf.argmax(y_test, axis=1)
# 显示一些测试结果
plt.figure(figsize=(10, 5))
for i in range(10):
plt.subplot(2, 5, i + 1)
plt.imshow(x_test[i], cmap='gray')
plt.title(f"True: {true_labels[i]}\nPred: {predicted_labels[i]}")
plt.axis('off')
plt.show()代码说明
-
数据加载与预处理:
-
使用
mnist.load_data()加载 MNIST 数据集。 -
将像素值归一化到
[0, 1]。 -
将标签转换为 one-hot 编码。
-
-
模型构建:
-
使用
Sequential模型构建三层神经网络。 -
第一层为
Flatten,将 28×28 的图像展平为 784 维向量。 -
第二层和第三层为隐藏层,分别有 128 和 64 个神经元,激活函数为 ReLU。
-
输出层有 10 个神经元,激活函数为 softmax,用于分类。
-
-
训练与评估:
-
使用 Adam 优化器和交叉熵损失函数。
-
训练 10 个 epoch,使用 32 的 batch size。
-
在测试集上评估模型的准确率。
-
-
结果可视化:
-
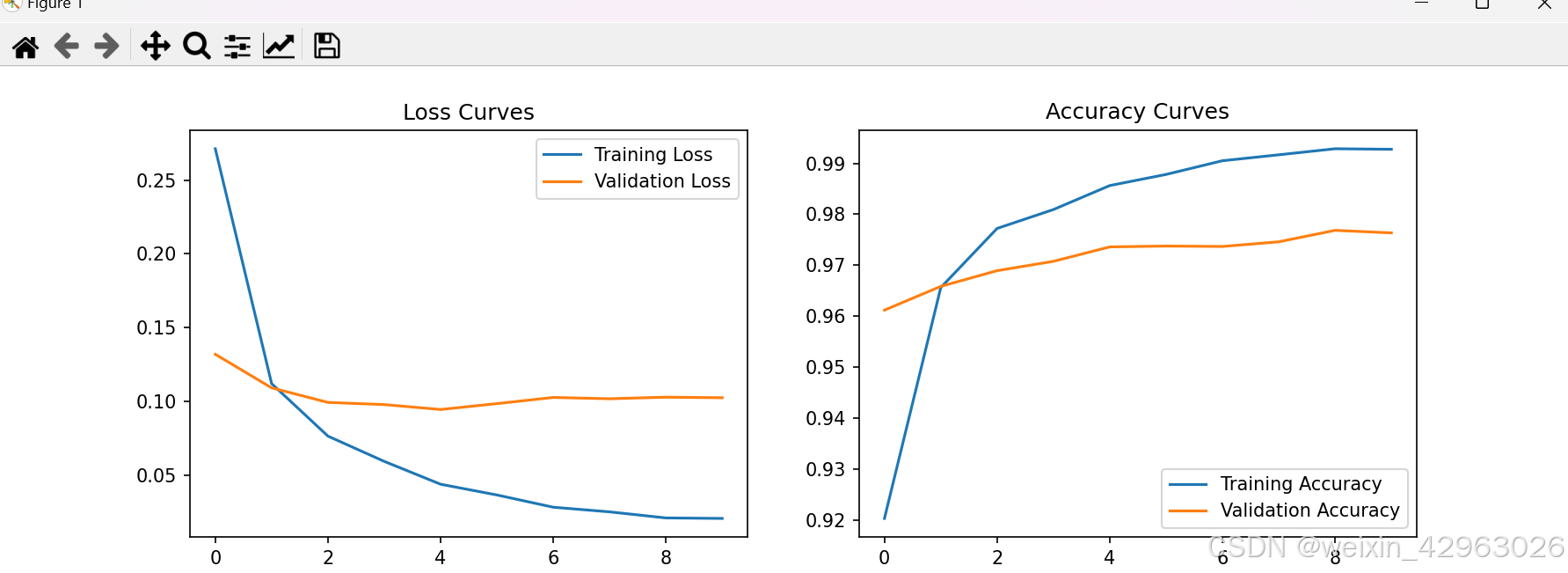
绘制训练过程中的损失和准确率曲线。
-
显示部分测试图像及其预测结果。
-
运行结果
运行代码后,你将看到以下内容:
-
训练过程的损失和准确率曲线:展示模型在训练和验证集上的表现。
-
测试集的准确率:通常可以达到 95% 左右。
-
测试图像及其预测结果:展示模型对部分测试图像的预测情况。
-
Epoch 1/10
1500/1500 [==============================] - 3s 2ms/step - loss: 0.2712 - accuracy: 0.9203 - val_loss: 0.1319 - val_accuracy: 0.9612
Epoch 2/10
1500/1500 [==============================] - 3s 2ms/step - loss: 0.1121 - accuracy: 0.9656 - val_loss: 0.1092 - val_accuracy: 0.9658
Epoch 3/10
1500/1500 [==============================] - 3s 2ms/step - loss: 0.0765 - accuracy: 0.9772 - val_loss: 0.0993 - val_accuracy: 0.9689
Epoch 4/10
1500/1500 [==============================] - 3s 2ms/step - loss: 0.0594 - accuracy: 0.9809 - val_loss: 0.0979 - val_accuracy: 0.9707
Epoch 5/10
1500/1500 [==============================] - 3s 2ms/step - loss: 0.0439 - accuracy: 0.9856 - val_loss: 0.0945 - val_accuracy: 0.9736
Epoch 6/10
1500/1500 [==============================] - 3s 2ms/step - loss: 0.0366 - accuracy: 0.9878 - val_loss: 0.0985 - val_accuracy: 0.9737
Epoch 7/10
1500/1500 [==============================] - 3s 2ms/step - loss: 0.0283 - accuracy: 0.9905 - val_loss: 0.1027 - val_accuracy: 0.9737
Epoch 8/10
1500/1500 [==============================] - 3s 2ms/step - loss: 0.0252 - accuracy: 0.9917 - val_loss: 0.1018 - val_accuracy: 0.9746
Epoch 9/10
1500/1500 [==============================] - 3s 2ms/step - loss: 0.0211 - accuracy: 0.9929 - val_loss: 0.1029 - val_accuracy: 0.9768
Epoch 10/10
1500/1500 [==============================] - 3s 2ms/step - loss: 0.0207 - accuracy: 0.9927 - val_loss: 0.1025 - val_accuracy: 0.9763
313/313 [==============================] - 0s 824us/step - loss: 0.0954 - accuracy: 0.9778
Test Accuracy: 0.9778
作业3:室内定位
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
# 加载数据集
train_data = pd.read_csv('D:/data/dataset/trainingData2.csv')
val_data = pd.read_csv("D:/data/dataset/validationData2.csv")
# 数据预处理
# 提取 RSSI 特征和目标位置(经度和纬度)
X_train = train_data.iloc[:, :520] # RSSI 特征
y_train = train_data[['LONGITUDE', 'LATITUDE']] # 目标位置
X_val = val_data.iloc[:, :520]
y_val = val_data[['LONGITUDE', 'LATITUDE']]
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
# 构建三层神经网络模型
model = Sequential([
Dense(128, activation='relu', input_shape=(520,)), # 第一层隐藏层
Dense(64, activation='relu'), # 第二层隐藏层
Dense(2) # 输出层,预测经度和纬度
])
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error', metrics=['mae'])
# 训练模型
history = model.fit(X_train, y_train, epochs=50, batch_size=32, validation_data=(X_val, y_val))
# 评估模型
val_loss, val_mae = model.evaluate(X_val, y_val)
print(f"Validation Loss: {val_loss:.4f}")
print(f"Validation Mean Absolute Error: {val_mae:.4f}")
# 可视化训练过程
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title("Loss Curves")
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['mae'], label='Training MAE')
plt.plot(history.history['val_mae'], label='Validation MAE')
plt.title("MAE Curves")
plt.legend()
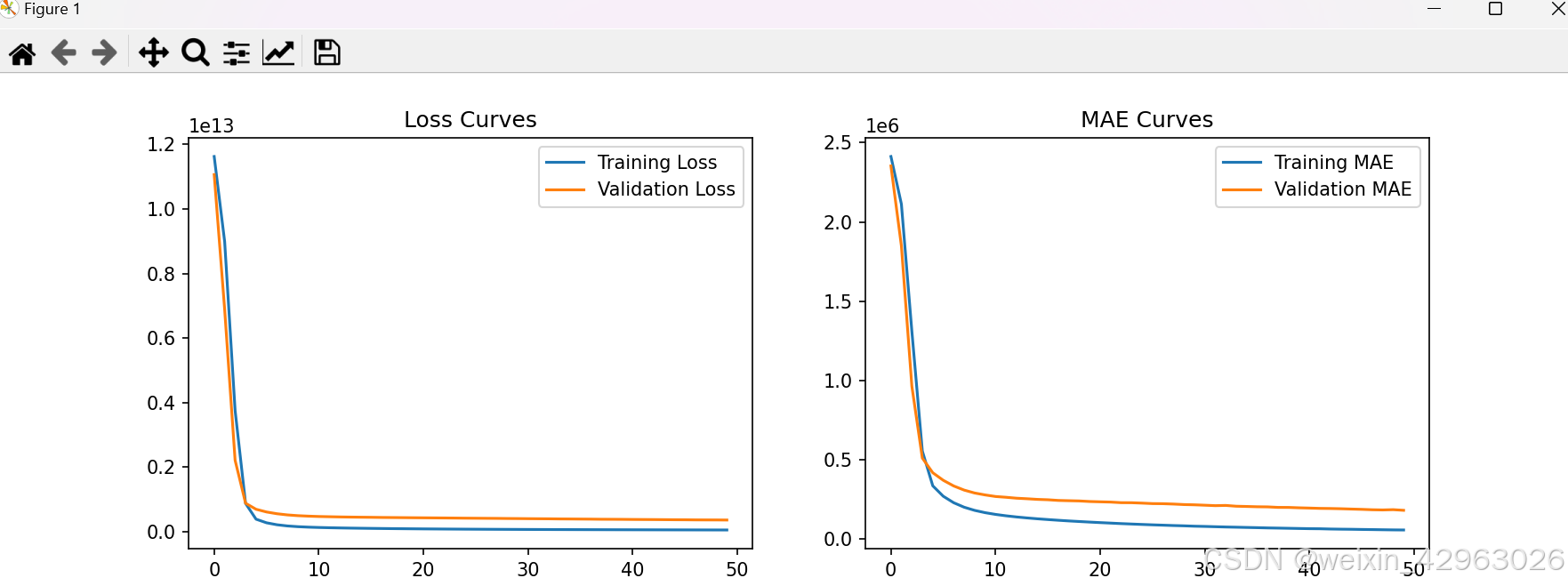
plt.show()Epoch 50/50
624/624 [==============================] - 1s 1ms/step - loss: 56005586944.0000 - mae: 55697.7969 - val_loss: 364364529664.0000 - val_mae: 179818.4844
35/35 [==============================] - 0s 882us/step - loss: 364364529664.0000 - mae: 179818.4844
Validation Loss: 364364529664.0000
Validation Mean Absolute Error: 179818.4844
训练结果分析
-
损失和误差的量级:
-
训练集和验证集的损失(
loss和val_loss)以及平均绝对误差(mae和val_mae)的量级都非常大。例如,最终的验证损失为 353,107,738,624.00,验证 MAE 为 181,511.67。 -
这表明模型的预测值与真实值之间存在很大的偏差。
-
-
损失下降趋势:
-
从日志来看,训练和验证的损失在训练过程中逐渐下降,但下降速度较慢,且最终的损失仍然很高。
-
这可能是因为模型的复杂度不足以捕捉数据的特征,或者数据中存在异常值或噪声。
-
-
过拟合或欠拟合:
-
虽然训练集的损失略低于验证集的损失,但两者的差距并不明显,因此不能明确判断是否存在过拟合。
-
由于损失和误差仍然很高,更可能是模型欠拟合,即模型未能很好地学习到数据的规律。
-
可能的原因
-
数据问题:
-
数据集中可能存在异常值或噪声,导致模型难以学习。
-
数据的分布可能不均匀,或者特征与目标之间的关系较为复杂。
-
-
模型复杂度不足:
-
当前的三层神经网络可能过于简单,无法捕捉数据中的复杂模式。
-
隐藏层的神经元数量可能不足,或者需要更多隐藏层。
-
-
训练不足:
-
50 个训练周期可能不足以让模型收敛到一个较好的状态。
-
学习率可能过高或过低,导致模型训练不充分。
-
-
目标值的量级问题:
-
如果目标值(经度和纬度)的量级很大,可能会导致损失函数的值也很大。可以尝试对目标值进行归一化或标准化。
-
改进建议
1. 数据预处理
-
检查数据:检查数据集中是否存在异常值或噪声,并进行清理。
-
归一化目标值:对目标值(经度和纬度)进行归一化或标准化,使其量级更小。
-
2. 调整模型结构
-
增加隐藏层或神经元数量:尝试增加隐藏层的数量或每层的神经元数量。
-
添加 Dropout:在隐藏层后添加 Dropout 层,以防止过拟合。
-
3. 调整训练参数
-
增加训练周期:将训练周期从 50 增加到 100 或更多,观察模型是否能进一步收敛。
-
调整学习率:尝试使用不同的学习率
-
4. 使用早停机制
-
如果验证集的损失在一定数量的周期后不再下降,可以提前停止训练
-
5. 特征工程
-
检查特征:确认输入特征(RSSI)是否合理,是否需要进一步处理(如去除无关特征)。
-
特征选择:尝试使用特征选择方法(如基于重要性的特征选择)来减少特征数量,提高模型性能。
-
作业3:室内定位改进
""""改进要点"""
# 目标值归一化:对目标值(经度和纬度)进行归一化处理,使其量级更小,有助于加速模型收敛。
# 批量归一化(Batch Normalization):在隐藏层之间添加批量归一化层,加速训练过程并提高模型稳定性。
# Dropout:添加 Dropout 层,防止模型过拟合。
# 早停机制(Early Stopping):监控验证集的损失,当连续多个周期性能未提升时提前停止训练。
# 学习率衰减(ReduceLROnPlateau):当验证集损失不再下降时,动态调整学习率。
# 增加模型复杂度:增加隐藏层的神经元数量,提升模型的拟合能力。
import pandas as pd
import numpy as np
import tensorflow as tf
from tensorflow.keras.models import Sequential
from tensorflow.keras.layers import Dense, Dropout, BatchNormalization
from tensorflow.keras.callbacks import EarlyStopping, ReduceLROnPlateau
from sklearn.preprocessing import StandardScaler
from sklearn.model_selection import train_test_split
import matplotlib.pyplot as plt
# 加载数据集
train_data = pd.read_csv('D:/data/dataset/trainingData2.csv')
val_data = pd.read_csv("D:/data/dataset/validationData2.csv")
# 数据预处理
# 提取 RSSI 特征和目标位置(经度和纬度)
X_train = train_data.iloc[:, :520] # RSSI 特征
y_train = train_data[['LONGITUDE', 'LATITUDE']] # 目标位置
X_val = val_data.iloc[:, :520]
y_val = val_data[['LONGITUDE', 'LATITUDE']]
# 数据标准化
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train)
X_val = scaler.transform(X_val)
# 目标值归一化
y_scaler = StandardScaler()
y_train = y_scaler.fit_transform(y_train)
y_val = y_scaler.transform(y_val)
# 构建改进后的神经网络模型
model = Sequential([
Dense(256, activation='relu', input_shape=(520,)), # 第一层隐藏层
BatchNormalization(), # 批量归一化
Dropout(0.5), # Dropout 层
Dense(128, activation='relu'), # 第二层隐藏层
BatchNormalization(), # 批量归一化
Dropout(0.5), # Dropout 层
Dense(64, activation='relu'), # 第三层隐藏层
Dense(2) # 输出层,预测经度和纬度
])
# 编译模型
model.compile(optimizer='adam', loss='mean_squared_error', metrics=['mae'])
# 设置早停机制和学习率衰减
early_stopping = EarlyStopping(monitor='val_loss', patience=10, restore_best_weights=True)
reduce_lr = ReduceLROnPlateau(monitor='val_loss', factor=0.5, patience=5, min_lr=1e-6)
# 训练模型
history = model.fit(
X_train, y_train,
epochs=100,
batch_size=32,
validation_data=(X_val, y_val),
callbacks=[early_stopping, reduce_lr]
)
# 评估模型
val_loss, val_mae = model.evaluate(X_val, y_val)
print(f"Validation Loss: {val_loss:.4f}")
print(f"Validation Mean Absolute Error: {val_mae:.4f}")
# 可视化训练过程
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(history.history['loss'], label='Training Loss')
plt.plot(history.history['val_loss'], label='Validation Loss')
plt.title("Loss Curves")
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(history.history['mae'], label='Training MAE')
plt.plot(history.history['val_mae'], label='Validation MAE')
plt.title("MAE Curves")
plt.legend()
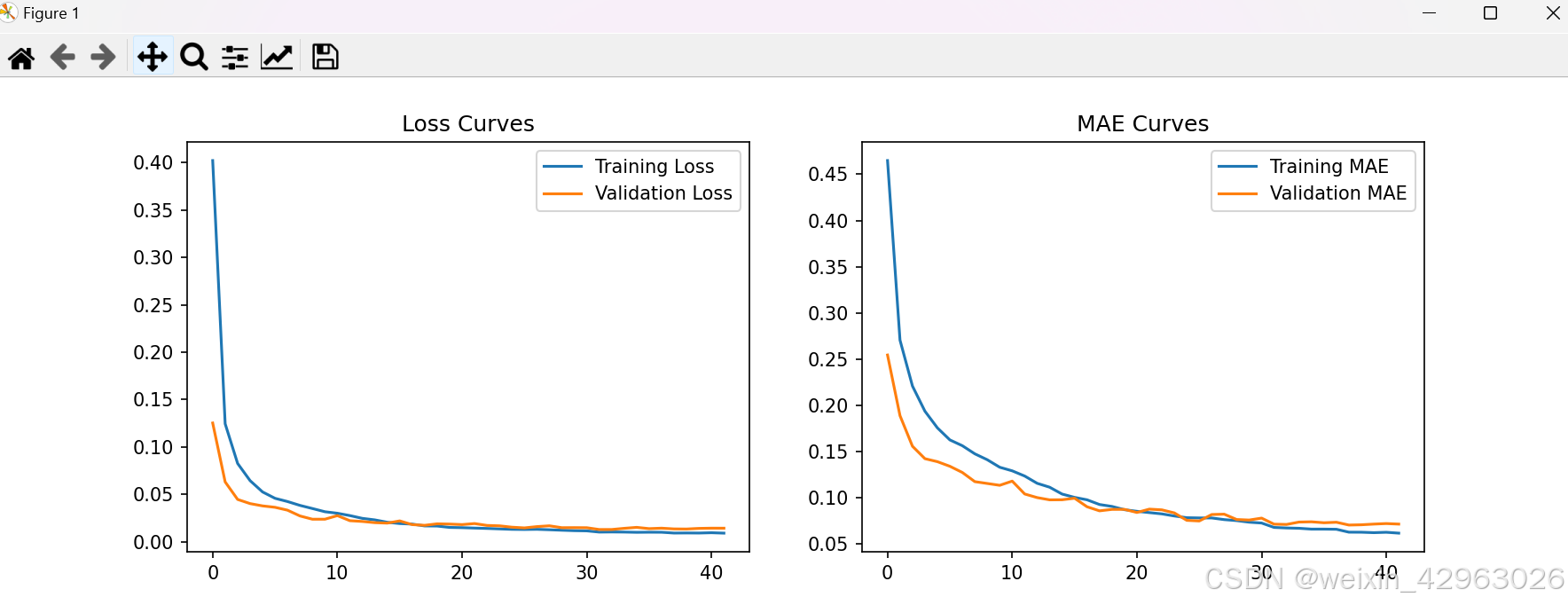
plt.show() 624/624 [==============================] - 2s 3ms/step - loss: 0.0086 - mae: 0.0582 - val_loss: 0.0164 - val_mae: 0.0723 - lr: 1.2500e-04
35/35 [==============================] - 0s 1ms/step - loss: 0.0157 - mae: 0.0733
Validation Loss: 0.0157
Validation Mean Absolute Error: 0.0733
神经网络的层数分析
-
输入层:
-
输入层由
input_shape=(520,)定义,表示输入特征的维度为 520。输入层本身不算作隐藏层。
-
-
隐藏层:
-
第一层隐藏层:
Dense(256, activation='relu'),包含 256 个神经元。 -
第二层隐藏层:
Dense(128, activation='relu'),包含 128 个神经元。 -
第三层隐藏层:
Dense(64, activation='relu'),包含 64 个神经元。
-
-
输出层:
-
输出层:
Dense(2),包含 2 个神经元,用于预测经度和纬度。
-
总结
-
隐藏层数量:3 层(256 → 128 → 64)
-
总层数(包括输入层和输出层):5 层(输入层 + 3 个隐藏层 + 输出层)
从训练日志来看,改进后的模型性能有了显著提升,验证集的损失(val_loss)和平均绝对误差(val_mae)已经降低到了一个相对合理的范围(val_loss 约为 0.0130,val_mae 约为 0.0713)。这表明模型已经能够更好地学习数据的特征,并且训练过程更加稳定。
进一步分析和优化方向
尽管模型性能已经有所提升,但仍然有一些潜在的优化空间,可以根据具体需求进一步改进:
1. 调整学习率和优化器
-
当前的学习率调整策略已经起到了一定的作用,但可以尝试更精细的调整。例如,使用更小的初始学习率(如 1e-4)并结合更激进的学习率衰减策略。
-
尝试使用其他优化器,如
RMSprop或SGD,并调整其参数。
2. 调整模型结构
-
如果验证集的损失和 MAE 仍然有进一步下降的空间,可以尝试增加更多的隐藏层或神经元,以增强模型的拟合能力。
-
添加更多的 Dropout 层或调整 Dropout 的比例(如从 0.5 调整到 0.3 或 0.7),以更好地平衡拟合能力和泛化能力。
3. 数据增强和特征工程
-
如果数据量仍然有限,可以尝试对训练数据进行增强,例如通过添加噪声或随机扰动来增加数据多样性。
-
检查输入特征的分布,尝试对特征进行进一步的处理(如对数变换、归一化等)。
4. 超参数调整
-
调整批量大小(
batch_size),例如尝试 64 或 128,观察对训练速度和模型性能的影响。 -
增加训练周期(
epochs),例如设置为 200 或更多,以确保模型有足够的时间收敛。
5. 模型集成
-
如果单个模型的性能已经达到瓶颈,可以尝试训练多个模型并进行集成。例如,训练多个不同初始化的模型,然后取平均值作为最终预测结果。