IB与RoCE:谁是AI智算中心内更好的“桥梁”?
在AI大模型的浪潮下,智算中心的网络架构正经历着前所未有的变革。从ChatGPT到DeepSeek,从训练到推理,背后是无数GPU、CPU与存储设备之间的高速互联与海量数据流转。而支撑这一切的“算力桥梁”,主要有两大阵营:一个是高性能计算领域的老牌劲旅——InfiniBand(简称IB),另一个是站在以太网生态之上的新贵——RDMA over Converged Ethernet(基于RDMA的以太网技术,以下简称为RoCE)。
那么,在AI智算中心的核心网络竞争中,谁更胜一筹?今天我们就来简单了解下这场持续十多年的“算力之争”。
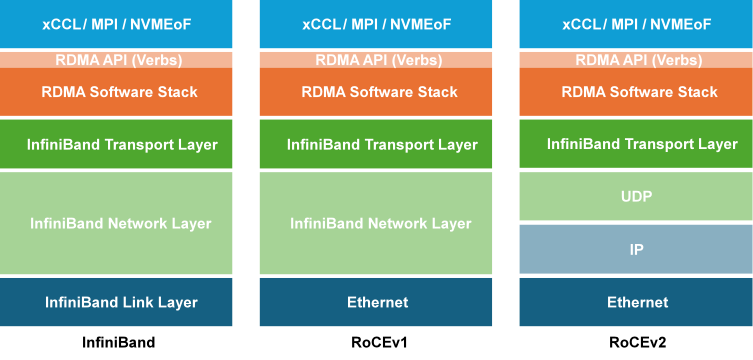 图1 RoCE和IB协议栈对比
图1 RoCE和IB协议栈对比
一、IB:为极致性能而生的“专用高速路”
IB可以说是AI数据中心的“贵族网络”。它不是普通以太网的延伸,而是从底层就为高带宽、低延迟、零丢包而设计的一整套专有体系。 IB网络由多种核心组件构成,包括子网管理器(SM)、IB网卡、IB交换设备以及专用线缆与光模块。
和传统以太网不同,IB网络不运行复杂的路由协议,而是采用集中式管理机制。整个网络的拓扑计算、路由分发、分区策略(Partition)、服务质量(QoS)等,全部由子网管理器负责。这让IB网络的控制与转发体系高度集中、极度可控,也因此更适合大规模GPU集群的统一调度。
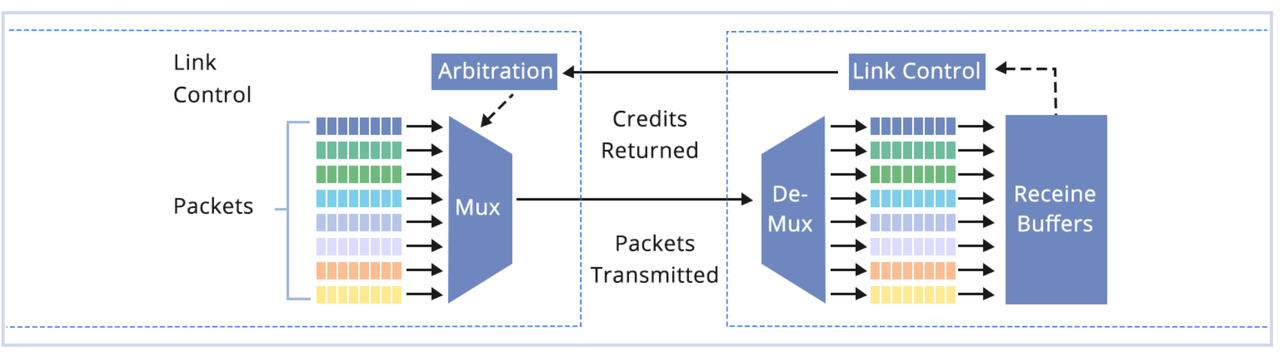
图2 Infiniband的无损数据传输示意图
IB最核心的优势在于其本征无损传输机制。它采用了基于“信用(Credit)”的流量控制方式——在数据发送前,发送端必须确认接收端有足够的缓冲区来接收数据包。如果接收端的缓存已满,发送端会自动等待,从而彻底避免网络拥塞与丢包。这种设计从物理层面保证了数据的完整性与稳定性。
此外,IB还具备自适应路由(Adaptive Routing)能力,能针对每个数据包实时选择最优路径,大幅提升链路利用率。无论是训练数万张GPU卡的大模型,还是进行高密度的参数同步,IB都能保持极低延迟和高吞吐。
可以说,IB是一条“为算力而生的高速专线”。它是英伟达、Meta、微软等超大规模AI集群背后的关键支撑。但它的代价同样昂贵——不仅设备成本高,而且生态几乎被英伟达一家垄断。从交换机到网卡,从光模块到驱动,都是IB专有标准,迁移或维护成本都不低。
二、RoCE:立足以太网的“平民劲旅”
与IB的专有生态不同,**RoCE(RDMA over Converged Ethernet)**走的是“兼容共存”路线。它利用现有以太网基础设施,通过RDMA(远程直接内存访问)技术,实现高效、低延迟的数据传输。
目前,RoCE已经发展到第二代——RoCE v2。这代技术运行在IP网络之上,支持跨子网通信,且采用全分布式架构,不再依赖像IB那样的集中式管理器(SM),部署更加灵活。
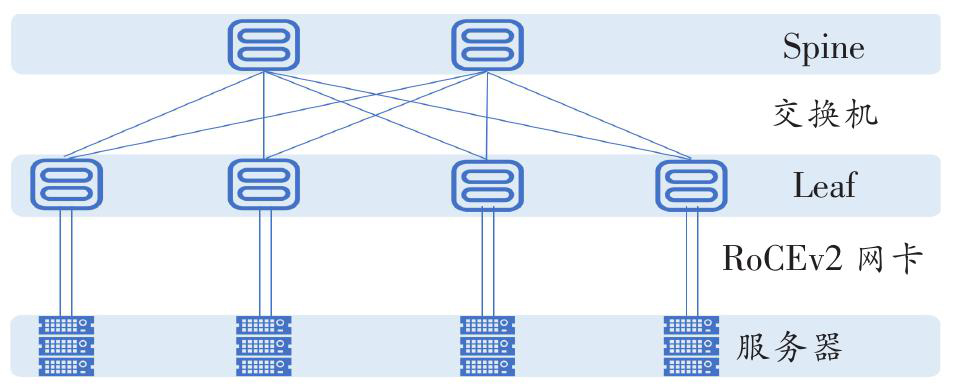
图3 RoCE网络架构
在AI数据中心中,RoCE的最大优势有三点:
-
成本更低: 可以直接复用传统以太网的交换机、光纤和模块资源。 无需更换为IB专用设备,节省大量硬件投入。
-
兼容性更强: 与现有的以太网、TCP/IP架构完美融合,不会破坏原有数据中心的网络设计。
-
部署灵活: RoCE卡通常以PCIe接口形式出现,端口速率可达400Gbps,性能不输IB。 在中大型AI集群中,RoCE完全可以胜任绝大多数训练和推理任务。
不过,RoCE也有短板。它虽然性能接近IB,但要达到“无丢包”效果,必须对交换机进行细致调优——包括开启PFC(优先级流控)、ECN(显式拥塞通知)、流量预留和优先级标记等参数。 如果配置不当,就可能出现丢包、延迟抖动、带宽未达标等问题。尤其在数千张GPU规模的集群中,这种影响会被放大。因此,RoCE更像是“以太网的性能升级版”:在成本、灵活性、兼容性上具备明显优势,但在极端性能和稳定性上,仍然难以全面超越IB。
三、正面对决:IB vs RoCE
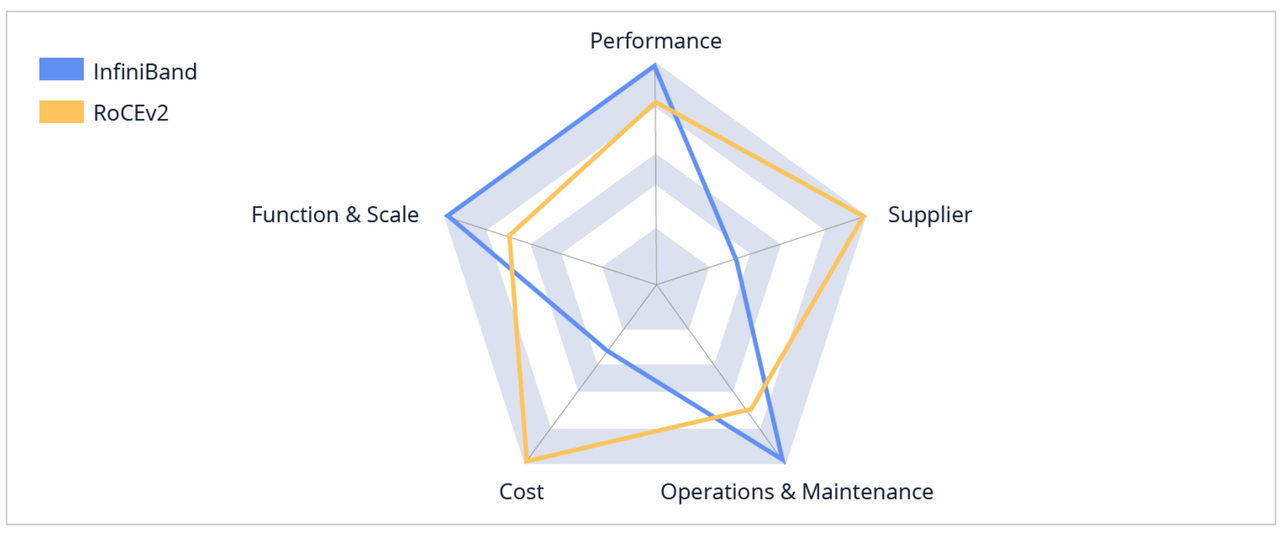
图4 RoCE和IB对比
| 对比维度 | InfiniBand (IB) | RoCE以太网 |
| 传输机制 | 信用流控,天然无损 | 基于PFC/ECN,依赖配置 |
| 管理架构 | 集中式(SM子网管理器) | 分布式,以太网兼容 |
| 延迟表现 | 极低延迟(微秒级) | 稍高(接近IB) |
| 扩展规模 | 可支撑数万GPU节点 | 适合数千GPU节点 |
| 生态开放性 | 英伟达主导,封闭 | 多厂商参与,开放 |
| 部署与维护 | 稳定但昂贵 | 灵活但需精调 |
| 成本 | 高昂(专用硬件) | 中低(复用以太网) |
总体来看:
-
IB 是“性能优先”的方案,代表极致计算力;
-
RoCE 是“成本与灵活并重”的方案,更贴合企业级AI部署的现实需求。
四、趋势:融合是最终答案
过去十年,IB在高性能计算和AI训练领域一直占据统治地位。从NVIDIA DGX SuperPOD,到Meta AI集群,几乎都采用IB网络。然而,随着AI算力需求下沉、边缘计算与多数据中心协同兴起,越来越多的企业倾向于采用“RoCE + 以太网优化”方案。
业界正在出现一种趋势:IB负责超大规模训练集群的核心算力互联,RoCE负责云化部署与多中心互通。这意味着未来AI数据中心的网络将不再是二选一,而是异构共生、智能协同。英伟达依然深耕IB生态,不断推出更高带宽、更智能路由的交换设备;而以太网厂商(如Broadcom、Mellanox、Intel等)也在持续优化RoCE性能,通过AI自适应流控、软件定义网络(SDN)等手段,逐步缩小差距。
五、结语:算力时代的“桥梁之争”,没有绝对赢家
总的来说,RoCE和InfiniBand都由IBTA定义,没有本质的不同。RoCE实际上是将成熟的IB传输层和RDMA移植到了同样成熟的以太网和IP网络上,是一种强强联合,在保持高性能的同时,降低了RDMA网络的成本,能够适应更大规模的网络。
在AI智算中心的世界里,IB像是高速专列,稳定、高效、但造价昂贵;RoCE则更像灵活地铁,性价比高、兼容性强,但需要精细运营。真正的未来,并非一方彻底取代另一方,而是两者共同构建起新一代智能算力互联底座。