【multi-model】moco系列SimCLRBEiT
moco和SimCLR都属于对比学习,对比学习是属于无监督学习,不需要手动标注label,通过对原图像进行增强,产生新的图像,和其他图像做对比来计算loss,使同一张图片增强之后的两者之间的loss更近,不同图片之间的loss更远;
一、moco
关键词:内存银行、动量更新、队列
流程结构:

注意:
1、x_q和x_k是x0经过的不同的图像增强
2、Encoder和Momentum encoder的结构是一样的,为了保证编码的维度一致
3、Momentum encoder更新公式:θ_k = m*θ_k + (1-m)*θ_q, m是系数,默认0.99,θ_k是Momentum encoder,θ_q是Encoder
4、quene如果是1024*4096大小的,1024是指每个样本用1024维度的参数表征,4096的样本容量,每次有新的样本进来会更新指针,如果超过4096个,会替换掉最老的一批
5、相似度是余弦相似度
6、infoNCE Loss:
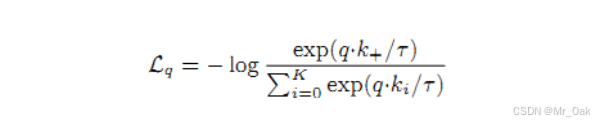
其中k+就是正样本相似度,ki就是所有样本的相似度,所以ki = 正样本相似度和负样本相似度,因此实际操作起来,需要将政府样本相似度cat一下,T是温度系数
7、内存银行目的,增加负样本数量,让效果更好
二、simCLR
关键词:图像增强,MLP、更大的batch
流程结构:

注意:
1、simCLR中用到的图像增强:随机裁剪然后将大小调整回原始大小,随机颜色失真,以及随机高斯模糊
2、中间涉及到的Encoder和MLP都是同一个网络
3、如果batch为N,那么会产生2N个增强后的图片,那么负样本就有2(N-1)个
4、batch越大效果越好,后面加MLP是因为验证之后效果好: 提升特征表达能力、优化对比学习目标、与数据增强的协同作用
5、如果是应对下游任务,那么会用Encoder完之后的hi和hj去做下游任务,而不是MLP完之后的zi和zj
6、Loss:
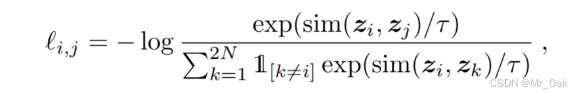
三、mocoV2
mocoV2实际上是moco和simCLR的合体
改动点:
1、参考simCLR的MLP层,mocoV2在encoder后面的fc之前加了一个线性层和一个relu,新增的分类器的训练用全部的 ImageNet label训练,这仅影响无监督训练阶段;线性分类或迁移阶段不使用此MLP头部;
2、在 MoCo v1 的基础上又添加了 blur augmentation
四、mocoV3
关键点:vit、双向对比、取消内存银行
流程结构:

注意:
1、mocoV3取消了内存银行,改为比较大的batchsize,比如4096
2、Encoder部分,用VIT换掉了Resnet50
3、认为x1和x2没有贵贱之分,因此采用双向的相似度计算,两个相似度矩阵相加
4、动量更新部分和loss计算部分之前一样,没有变化
五、BEiT
BEiT是基于掩码重建的自监督学习
关键点:VIT、dVAE、MIM
流程结构:
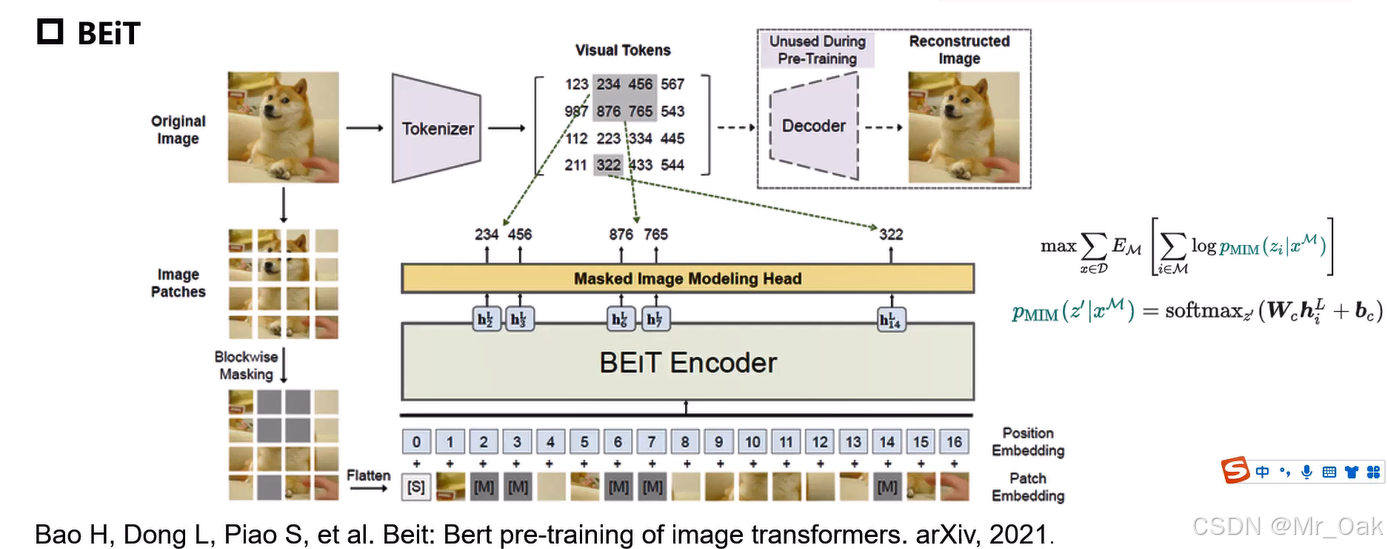
注意:
1、dVAE:离散变分自编码器(discrete Variance Auto-Encoder,dVAE)是一个早在2016年就被提出的无监督模型,它的核心模型是一个自编码器,由编码器(Encoder)和解码器(Decoer)组成。其中编码器的作用是将图像编码成一个特征向量,解码器的作用是使用这个特征向量对图像进行重建。dVAE正是通过这种图像的编码和解码实现模型的预训练的。
2、dVAE是预训练的,tokenizer和decoder部分是训练得来的
3、输入图像,分成很多patches,进入vit进行运算,同时每个patch会经过dVAE的tokenizer,得到编码,将vit的结果和tokenizer的结果进行对比求loss
4、分成不同的patch之后,还需要做MIM,就是随机对patch块进行掩码mask(约40%),掩码之后的patch放入transformer
5、损失函数:
