【算力】AI万卡GPU集群交付确认项与日常运维(算力压测、数据倒腾、日常运维)
【算力】AI万卡GPU服务器交付确认项与日常运维(算力压测、数据倒腾,日常运维)
- 单集群万卡的没整过,不过加起来经手的卡,累计不说万卡,至少也有个5k以上,主流的型号3090/4090/A6000/H20/L20/A100/H100/A800/H200/B200等等。
- 一般是裸机交的比较多,所以这里就不特别加k8s相关的了,毕竟纳管到自建平台进行二次调度的,甚至saas平台本身的开发,感觉是上层的又一大块专题了。
- 单纯记个笔记,整理下个人平常的运维习惯和流程,都是公有领域找得到知识。写完才发现有点长了,下次拆一拆搞成分散的几篇。。。
文章目录
- 1、算力
- 1.1 基础配置
- 硬件:基础检测 & 驱动重装
- 软件:运行环境配置,docker + cuda
- 1.2 单机测试
- P2P单卡通信:p2pBandwidthLatencyTest
- 多卡通信带宽:单机NCCLTest
- 硬件健康诊断:dcgmi
- 全负载压测:gpu-burn
- 1.3 多机压测
- 多机通信:mpirun
- 1.4 NCCL性能调优
- 网络链路优化(核心瓶颈)
- 算法与策略优化
- 拓扑感知与节点调度
- 1.5 业务推理&训练测试
- 2、数据
- 2.1 并行文件存储(PFS)
- PFS介绍
- PFS的价值:支持大量扩容+io性能好
- PFS底层实现:对象存储+并行IO
- 2.2 服务器网络带宽(专线)
- 专线类型,适用范围
- 复用线路 vs 单独施工
- 2.3 内网隧道、专用网卡、并发传输
- 3、日常运维
- 3.1 监控告警(grafana+prometheus+webhook)
- 计算层:GPU监控 DCGM exporter
- 网络层: RDMA/InfiniBand/RoCE, ibstat
- 存储层:一级目录统计 & 容量阈值告警回调
- 集群层:k8s节点健康状态检查
- 3.2 容灾(故障恢复,宕机迁移)
- 机器恢复(需中断,类似冷备)
- 任务恢复(无缝切,类似热备)
- 3.3 安全(网络隔离、入侵检测)
- 网络隔离:安全组限制白名单,禁用密码登录
- 入侵检测:机器内进程监测
文章目录
1、算力
1.1 基础配置
硬件:基础检测 & 驱动重装
软件:运行环境配置,docker + cuda
1.2 单机测试
P2P单卡通信:p2pBandwidthLatencyTest
多卡通信带宽:单机NCCLTest
硬件健康诊断:dcgmi
全负载压测:gpu-burn
1.3 多机压测
多机通信:mpirun
1.4 NCCL性能调优
网络链路优化(核心瓶颈)
算法与策略优化
拓扑感知与节点调度
1.5 业务推理&训练测试
2、数据
2.1 并行文件存储(PFS)
PFS介绍
PFS的价值:支持大量扩容+io性能好
PFS底层实现:对象存储+并行IO
2.2 服务器网络带宽(专线)
专线类型,适用范围
复用线路 vs 单独施工
2.3 内网隧道、专用网卡、并发传输
3、日常运维
3.1 监控告警(grafana+prometheus+webhook)
计算层:GPU监控 DCGM exporter
网络层: RDMA/InfiniBand/RoCE, ibstat
存储层:一级目录统计 & 容量阈值告警回调
集群层:k8s节点健康状态检查
3.2 容灾(故障恢复,宕机迁移)
机器恢复(需中断,类似冷备)
任务恢复(无缝切,类似热备)
3.3 安全(网络隔离、入侵检测)
网络隔离:安全组限制白名单,禁用密码登录
入侵检测:机器内进程监测
1、算力
1.1 基础配置
硬件:基础检测 & 驱动重装
# 查看GPU型号、数量、驱动是否预装
lspci | grep -i nvidia # 若有输出,说明GPU硬件被识别
nvidia-smi # 若报错,说明未装NVIDIA驱动,需先安装# 调用 GPU、CUDA 运行依赖驱动,需匹配 GPU 型号(如 A100 需≥450.80.02 版本)
sudo apt update && sudo apt install -y nvidia-driver-535 # 535为稳定版本,按需替换
sudo reboot # 重启后生效
nvidia-smi # 验证输出GPU信息,确认驱动正常
如果本地网络环境有问题,或者换源很麻烦的话,也可以直接去官网下载,scp上来装
参考驱动重装,版本更新
# 第一步:彻底卸载旧驱动及残留配置
# 1. 用NVIDIA官方卸载工具清理.run安装的驱动(若存在)
sudo /usr/bin/nvidia-uninstall || echo "未检测到.run格式安装的驱动,跳过此步"
# 2. 卸载apt安装的NVIDIA相关包(含驱动、CUDA、依赖库)--purge彻底删除配置
sudo apt purge -y "*nvidia*" "*cuda*" "*libnvidia*"
# 3. 自动清理无用依赖和缓存
sudo apt autoremove -y && sudo apt autoclean
# 4. 删除残留的NVIDIA配置文件(避免冲突)
sudo rm -rf /etc/modprobe.d/nvidia.conf /etc/modules-load.d/nvidia.conf /etc/modprobe.d/blacklist-nvidia.conf
# 5. 更新内核模块配置(使删除生效)
sudo update-initramfs -u# 第二步:安装新版本驱动(.deb包方式)
# 1. 安装本地仓库包(会在系统中添加NVIDIA专属源)
sudo dpkg -i nvidia-driver-local-repo-ubuntu2204-550.163.01_1.0-1_amd64.deb
# 2. 导入GPG密钥(解决 apt update 时的签名验证问题)# 注意:密钥文件名可能随版本变化,需根据实际包内文件名修改
sudo cp /var/nvidia-driver-local-repo-ubuntu2204-550.163.01/nvidia-driver-local-B5A020B0-keyring.gpg /usr/share/keyrings/
# 3. 更新apt源(加载新添加的NVIDIA仓库)
sudo apt update
# 4. 安装指定版本驱动(550系列)
sudo apt install -y nvidia-driver-550# 第三步:重启并验证驱动
# 1. 必须重启使驱动生效(内核模块加载)
sudo reboot
# 2. 验证驱动是否正常加载
nvidia-smi # 应显示GPU信息及550.163.01版本
lsmod | grep nvidia # 应输出nvidia相关内核模块(如nvidia_modeset、nvidia_uvm)# 第四步:更新GPU互联组件(针对多卡NVLink/PCIe互联)
# 1. 检查Fabric Manager状态(管理NVLink等互联,多卡必装)
systemctl status nvidia-fabricmanager
# 2. 重装Fabric Manager(确保与驱动版本匹配,550驱动对应550版本)
sudo apt install --reinstall -y nvidia-driver-550 nvidia-fabricmanager-550
# 3. 重新加载系统服务配置并启动Fabric Manager
sudo systemctl daemon-reload
sudo systemctl restart nvidia-fabricmanager
sudo systemctl enable nvidia-fabricmanager # 设置开机自启# 第五步:配置RDMA网络(针对IB/RoCE网络)
# 1. 安装RDMA核心组件
sudo apt install -y rdma-core
# 2. 检查RDMA服务状态
systemctl status rdma-agent
# 3. 验证IB/RoCE网卡状态(如mlx5系列)
ibstat # 应显示IB端口状态(LinkUp/Active)
lsmod | grep -e mlx5 -e ib_ # 应加载mlx5_ib、ib_core等模块
# 4. 安装RDMA性能测试工具
sudo apt install -y perftest
# 5. 测试RDMA带宽(替换mlx5_1为实际网卡名)
ib_send_bw -d mlx5_1 -F --report_gbits
# 6. 重启RDMA服务确保配置生效
sudo systemctl restart rdma-agent
万卡集群交付测试步骤, 万卡1, 万卡2
软件:运行环境配置,docker + cuda
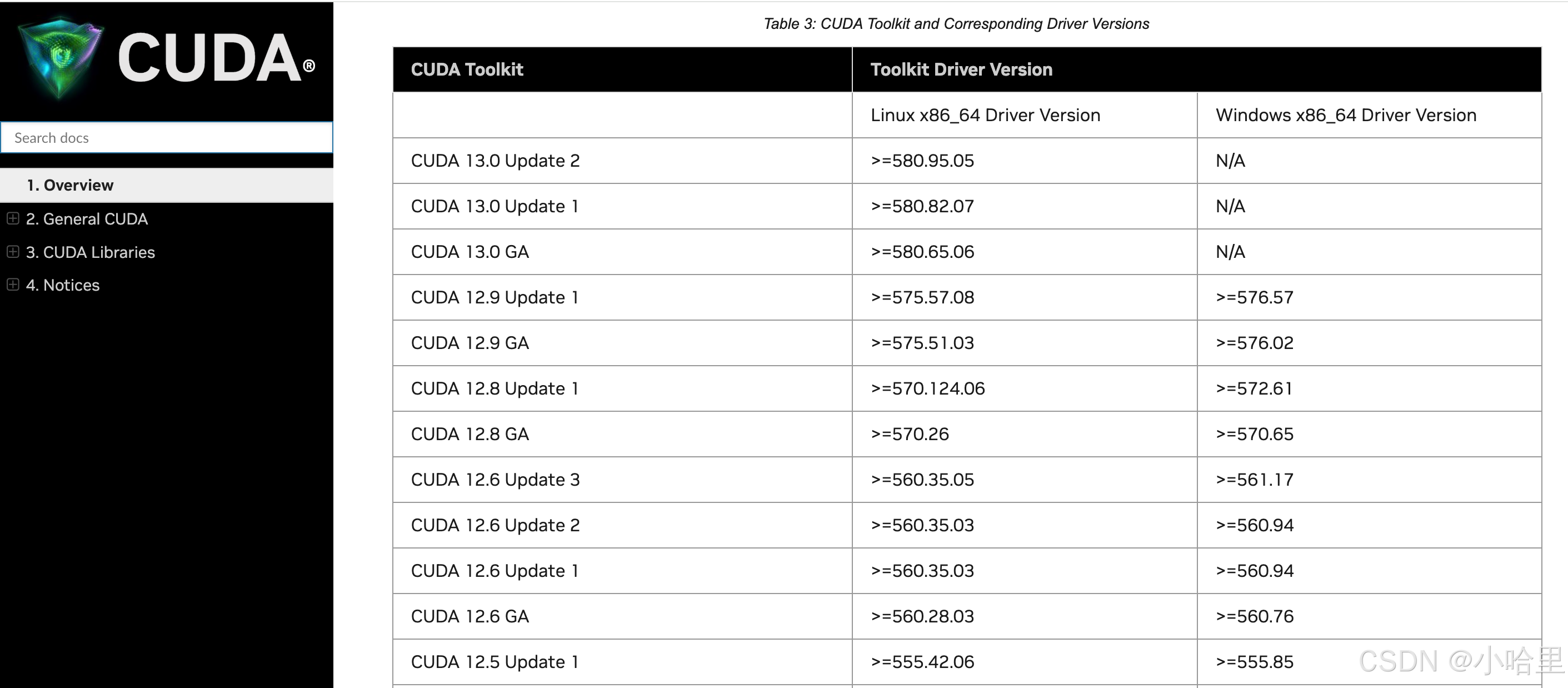
nvidia 驱动版本和cuda对照
官方文档 1 可以通过 apt show cuda-runtime-x-x 找到:
docker安装
# 1. 卸载旧版Docker(若存在)
sudo apt-get remove -y docker docker-engine docker.io containerd runc # 移除旧版组件
sudo apt-get autoremove -y && sudo apt-get autoclean # 清理残留依赖和缓存# 2. 安装Docker Engine(通过官方仓库)
sudo apt-get update # 更新apt包索引
sudo apt-get install -y apt-transport-https ca-certificates curl gnupg-agent software-properties-common # 安装HTTPS依赖包,用于获取远程仓库
curl -fsSL https://download.docker.com/linux/ubuntu/gpg | sudo apt-key add - # 添加Docker官方GPG密钥(验证包完整性)
sudo add-apt-repository "deb [arch=amd64] https://download.docker.com/linux/ubuntu $(lsb_release -cs) stable" # 添加Docker稳定版仓库(适配当前系统版本)
sudo apt-get update # 刷新仓库索引
sudo apt-get install -y docker-ce docker-ce-cli containerd.io # 安装Docker核心组件(默认安装最新版,满足≥27.2.0要求)
sudo usermod -aG docker $USER # 将当前用户加入docker组,避免每次执行docker需sudo# 3.验证Docker安装成功(运行hello-world测试镜像)
docker run --rm hello-world # 输出"Hello from Docker!"即成功
docker -v # 查看Docker版本,确认≥27.2.0
安装NVIDIA容器工具(nvidia-container-toolkit/runtime)
# 获取系统版本(如ubuntu22.04),用于匹配软件源
distribution=$(. /etc/os-release;echo $ID$VERSION_ID)# 添加NVIDIA官方GPG密钥(解密软件源)
curl -fsSL https://nvidia.github.io/libnvidia-container/gpgkey | sudo gpg --dearmor -o /usr/share/keyrings/nvidia-container-toolkit-keyring.gpg# 添加NVIDIA容器工具软件源(配置密钥签名验证)
curl -s -L https://nvidia.github.io/libnvidia-container/$distribution/libnvidia-container.list | \
sed 's#deb https://#deb [signed-by=/usr/share/keyrings/nvidia-container-toolkit-keyring.gpg] https://#g' | \
sudo tee /etc/apt/sources.list.d/nvidia-container-toolkit.list# 安装NVIDIA容器工具(核心组件,支持Docker调用GPU)
sudo apt-get update && sudo apt-get install -y nvidia-container-toolkit nvidia-container-runtime
sudo systemctl restart docker # 重启Docker,加载NVIDIA运行时
配置docker镜像源
# 4. 配置Docker(NVIDIA运行时+国内镜像加速器)
# --------------------------
cd /etc/docker/ # 进入Docker配置目录
sudo mv daemon.json daemon.json.bak 2>/dev/null # 备份原有配置(无则忽略报错)
# 创建新的daemon.json配置文件:指定NVIDIA运行时、添加国内镜像(加速镜像拉取)
sudo tee /etc/docker/daemon.json << 'EOF'
{"runtimes": {"nvidia": {"args": [],"path": "nvidia-container-runtime" # 指定NVIDIA运行时路径}},"registry-mirrors": [ # 国内镜像加速器,解决海外镜像拉取慢问题"https://docker.m.daocloud.io","https://mirror.ccs.tencentyun.com","https://registry.docker-cn.com"]
}
EOF
# 重新加载Docker配置并重启
sudo systemctl daemon-reload
sudo systemctl restart docker# 5. 验证GPU容器可用性
# 方式1:本地加载已有的CUDA镜像(若有本地tar包,如文档所述)
# docker load -i cuda.tar # 加载本地CUDA镜像# 方式2:从NVIDIA仓库拉取CUDA镜像(无本地包时使用)
docker pull nvidia/cuda:12.4.1-base-ubuntu22.04# 运行容器并执行nvidia-smi,验证GPU是否可调用
docker run --rm --gpus all nvidia/cuda:12.4.1-base-ubuntu22.04 nvidia-smi
| 概念 | 定义与作用 | 与Docker关系 |
|---|---|---|
| CUDA | NVIDIA的并行计算架构,连接GPU硬件与应用,支持调用GPU算力 | 容器通过NVIDIA工具共享宿主机CUDA能力,自身不包含完整CUDA |
| CUDA Toolkit | 开发/运行GPU程序的工具包(编译器、库等),分开发(完整)和运行(精简)版 | 镜像可预装(如nvidia/cuda),开发镜像含完整工具,运行镜像仅含必要库 |
| NVIDIA驱动 | 宿主机硬件驱动,直接控制GPU,是CUDA运行的前提 | 容器不装驱动,通过工具共享宿主机驱动(驱动版本需≥容器CUDA版本) |
| NVIDIA容器工具 | Docker扩展工具,实现容器与GPU的桥接 | 必需组件,无则容器无法识别GPU,无法运行GPU任务 |
附:containerd版本与 NVIDIA 驱动不匹配可能导致容器内 “掉卡”(GPU 识别异常、突然不可用)
- 1, 2 即docker版本不同,对gpu穿透 --gpus all 的支持是不同的
- 确保 containerd(≥1.7)、nvidia-container-toolkit(≥1.13)、NVIDIA 驱动(≥525)三者版本匹配,并正确配置运行时集成。若遇到掉卡问题,优先检查containerd版本和配置,这是社区反馈中最常见的根因。
1.2 单机测试
P2P单卡通信:p2pBandwidthLatencyTest
p2pBandwidthLatencyTest(CUDA Samples的一部分 cuda-samples ):
- 功能:专门测试单机内GPU之间的P2P通信带宽和延迟。
或者说,一个 GPU 直接给另一个 GPU 发数据,不经过 CPU 或内存中转。 - 用法:编译后运行,它会矩阵式地测试每对GPU之间的双向带宽和延迟。健康的系统应显示出高带宽(例如,通过NVLink互连的GPU可达数百GB/s)和低延迟。
- 测两个指标:
带宽:单位时间内两个 GPU 能传多少数据(如 50GB/s,数值越大越好)。
延迟:数据从 GPU0 发出去到 GPU1 收到的时间(如 1 微秒,数值越小越好)。
用 p2pBandwidthLatencyTest 工具测试 8 卡机器,会输出每对 GPU 之间的带宽和延迟(比如 GPU0→GPU1、GPU0→GPU2……),如果某对 GPU 的带宽突然降到 10GB/s(正常应 50GB/s),可能是 NVLink 线没插好或硬件故障。
p2pBandwidthLatencyTest需要本地编译再测
注意github下载的版本和要和cuda版本对上,可以去release下旧的版本,不然会编译不出来
# 查看cpu架构(确定cuda版本,例如12.8)
nviida-smi --query-gpu=compute_cap --format=csv
compute_cap
9.0# 需要对应版本的 https://github.com/NVIDIA/cuda-samples/releases
git clone https://github.com/NVIDIA/cuda-samples
cd cuda-samples/Samples/5_Domain_Specific/p2pBandwidthLatencyTest/# 编译方式1 make
make -j$(nproc) # 快速编译,-j$(nproc)用当前机器所有 CPU 核心同时编译
./p2pBandwidthLatencyTest# 编译方式2 cmake
mkdir -p build && cd build # 创建单独编译目录,避免污染源码
cmake .. -DCMAKE_CUDA_ARCHITECTURES="90" # 90对应A100的计算能力
make -j$(nproc) # 编译生成可执行文件
cd .. # 返回原目录
./build/p2pBandwidthLatencyTest # 执行
结果是一个二维矩阵,表示gpu两两之间的通信带宽
# 参考值
互联方式 单向带宽(典型值) 双向带宽(典型值) 适用 GPU 场景
NVLink 4.0 50~60 GB/s 90~120 GB/s A100、H100
NVLink 3.0 30~40 GB/s 55~75 GB/s V100、A40
PCIe 4.0 x16 25~31 GB/s 45~60 GB/s RTX 4090、RTX A4500 等
多卡通信带宽:单机NCCLTest
NCCLTests(如all_reduce_perf)和p2pBandwidthLatencyTest都是测试GPU通信的工具,但核心目标和场景完全不同
- 前者测“一群人协作搬重物的效率”,后者测“两个人之间传球的速度”。
p2p测试:验证“卡0和卡1之间传递某一层的参数”快不快(影响模型并行效率);- NCCL测试:验证“8卡同时同步整个模型的梯度”快不快(影响数据并行效率,更关键)。
- 若要排查“两卡之间通信慢”(如模型并行卡间数据交换卡壳),用
p2pBandwidthLatencyTest; - 若要评估“多卡整体训练速度”(如数据并行时总耗时高),用NCCLTests。
# 1. 克隆并编译工具(前提:已装 CUDA、NCCL)
git clone https://github.com/NVIDIA/nccl-tests.git
cd nccl-tests && make -j$(nproc) # 快速编译# 2. 单机 8 卡测试
./build/all_reduce_perf -b 8 -e 128M -f 2 -g 8
./build/all_reduce_perf -b 1G -e 8G -f 2 -g 8 -c 1 -n 100
# -b 8:起始数据大小 8B(从小数据量开始测)
# -e 128M:结束数据大小 128MB(覆盖训练中常见数据量)
# -f 2:数据量每次翻倍(高效遍历不同规模)
# -g 8:用 8 块 GPU 测试(填实际 GPU 数量)
# -c 1: 每个数据大小测试 1 轮(循环次数),快速测试(若需更稳定结果,可设为-c 5取平均值)
# -n 100: 每个数据大小内部执行 100 次通信操作,通过多次重复减少误差,让带宽 / 延迟结果更稳定# 典型输出(8卡A100示例)size count type redop time algbw busbw error1024M 268435456 float sum 2.69ms 380.6GB/s 3045GB/s 0e+002048M 536870912 float sum 5.42ms 377.8GB/s 3022GB/s 0e+00如何看结果:
- algbw(算法带宽):NCCL 实际计算的通信带宽(越高越好,8 卡 A100 NVLink 应≥4000Gbps)(注意大B小b)。
- busbw(总线带宽):硬件链路的理论总带宽(8 卡 A100 NVLink 约 38400Gbps,接近此值说明链路无瓶颈)。
- busbw反映的是 “算法实际占用的总线带宽”,而非硬件理论上限(如 NVLink 总带宽)
工具计算的 busbw是算法实际利用的带宽(受通信模式限制),8 卡 All-Reduce 用 “树状算法” 时,总线利用率通常只有硬件上限的 30%~50%
硬件健康诊断:dcgmi
sudo dcgmi diag -r 1
# -r 1:指定诊断级别为 “快速诊断”(耗时约 1 分钟),检查 GPU 核心功能
# 基础显存读写测试(检测显存是否有坏块);
# 简单计算核函数执行(检测 CUDA 核心是否正常);
# 温度与功耗传感器检查(确认硬件监控正常)。Diagnostics result: PASS # 所有测试通过,无硬件故障
全负载压测:gpu-burn
全负载烤机:
让 GPU 核心、显存跑满(利用率≈100%),检测硬件稳定性(如过热、虚焊、供电问题)。
常见故障暴露:
- 运行中报错 “CUDA error”→ 核心或显存存在硬件瑕疵;
- 自动重启 / 死机→ 供电不足或散热不良(温度超过 95℃易触发)。
git clone https://github.com/wilicc/gpu-burn.git
cd gpu-burn && make# 运行测试(默认持续10分钟,全GPU负载)
./gpu-burn # 或指定时长:./gpu-burn 60 (测试60秒)
1.3 多机压测
多机通信:mpirun
mpi
双卡测试
# 在主节点执行(假设节点名为 node1、node2,每节点 8 卡)
mpirun -np 16 \ # 总进程数 = 节点数 × 每节点 GPU 数(2×8=16)-H node1:8,node2:8 \ # 指定节点及每节点进程数(node1 跑 8 进程,node2 跑 8 进程)--allow-run-as-root \ # 允许 root 用户运行(集群环境常用)--mca plm_rsh_no_tree_spawn 1 \ # 禁用树状 SSH spawn,避免多节点通信阻塞--bind-to none \ # 不绑定 CPU 核心(让 MPI 自动分配)--map-by slot \ # 按插槽分配进程(对应 GPU 编号)-x NCCL_DEBUG=INFO \ # 输出 NCCL 调试信息(可选,用于排查问题)-x NCCL_IB_HCA=mlx5_0,mlx5_1 \ # 指定 IB 卡(根据实际网卡名修改)-x PATH \ # 同步环境变量(确保所有节点命令路径一致)-x LD_LIBRARY_PATH \/root/nccl-tests/build/all_reduce_perf \ # 测试工具路径(所有节点需一致)-b 1G -e 8G -f 2 -g 1 -c 5 -n 100 # 测试参数(与单机类似,-g 1 表示每进程用 1 卡)
多卡测试
# hostfile格式:每行一个节点,如"node0 slots=8"(共256行,路径示例:/opt/hosts_256.txt)
mpirun -np $((256 * 8)) \ # 总进程数=256节点×8卡=2048进程--hostfile /opt/hosts_256.txt \ # 从hostfile加载节点列表--allow-run-as-root \ # 允许root用户执行(集群环境常用)--bind-to numa \ # 进程绑定到NUMA节点(减少CPU-GPU跨节点调度开销)--map-by ppr:8:node \ # 每节点分配8个进程(严格对应8块GPU)--mca plm_rsh_no_tree_spawn 1 \ # 禁用树状SSH启动,加速256节点进程拉起--mca btl_tcp_if_exclude lo,docker0,virbr0 \ # 排除非业务网卡(避免干扰)-x PATH \ # 同步环境变量(确保所有节点命令路径一致)-x LD_LIBRARY_PATH \-x NCCL_DEBUG=INFO \ # 开启NCCL基础调试日志-x NCCL_DEBUG_SUBSYS=init,net,graph,env,tuning \ # 细化调试子系统(定位初始化/网络问题)-x NCCL_SOCKET_IFNAME=eth0 \ # 绑定TCP通信到eth0(仅用于控制面,数据走IB)-x NCCL_IB_HCA=mlx5_0,mlx5_1 \ # 指定可用IB卡(根据实际网卡名填写,多卡用逗号分隔)-x NCCL_IB_QPS_PER_CONNECTION=8 \ # 每连接8个QP(队列对),提升IB并行通信能力-x NCCL_IB_GID_INDEX=3 \ # 使用IB的GID索引3(适配RoCEv2网络,需与交换机配置一致)-x NCCL_IB_TIMEOUT=22 \ # IB超时时间(22对应~10ms,避免大规模集群通信超时)-x NCCL_IB_RETRY_CNT=8 \ # IB重试次数(8次,提升弱网环境下的稳定性)-x UCX_TLS=tcp \ # UCX传输层用TCP(兼容部分控制面通信)-x NET_DEVICES=bond1 \ # 应用层绑定bond1网卡(若业务网使用bonding)-x NCCL_TOPO_FILE=/etc/nccl/topo_256node.xml \ # 加载预生成的集群拓扑文件(优化跨节点路径)-x NCCL_IB_PCI_RELAXED_ORDERING=1 \ # 启用IB PCIe松弛排序(提升大消息传输效率)/opt/nccl-tests/build/all_reduce_perf \ # 测试工具路径(所有节点需一致)-b 2G -e 32G -f 2 -g 1 -c 5 -n 100 # 测试参数:2G~32G大消息,每进程1卡,5轮取平均
1.4 NCCL性能调优
nvda, ucloud
分「网络链路」「算法策略」「拓扑感知」三个维度优化,直接关联algbw提升:
网络链路优化(核心瓶颈)
| 配置项 | 作用 | 推荐值(256台集群) |
|---|---|---|
NCCL_IB_HCA | 绑定有效IB卡,避免NCCL扫描无效设备浪费时间。 | mlx5_0,mlx5_1(根据实际IB卡名填写,多卡用逗号分隔) |
NCCL_IB_QPS_PER_CONNECTION | 增加IB队列对数量,提升并行通信能力(2048进程场景必备)。 | 8(默认1,8倍提升并行度) |
NCCL_IB_GID_INDEX | 匹配RoCEv2网络的GID索引(与交换机配置一致,否则IB通信失败)。 | 3(多数集群用索引3,需与网络团队确认) |
NCCL_IB_PCI_RELAXED_ORDERING | 启用IB的PCIe松弛排序,减少大消息传输的CPU干预。 | 1(开启) |
算法与策略优化
| 配置项 | 作用 | 推荐值(256台集群) |
|---|---|---|
NCCL_ALGO | 选择集合通信算法(大规模集群用树状算法更高效)。 | Tree(默认自动选择,强制树状算法减少延迟) |
NCCL_NET_GDR_LEVEL | 启用GPU Direct RDMA,跳过CPU内存直接访问IB卡(减少数据拷贝)。 | 3(最高级别,需IB卡支持) |
NCCL_MIN_NRINGS | 增加通信环数量,提升小消息并行度(大规模集群小消息场景)。 | 8(默认4,256台节点多,需更多并行环) |
拓扑感知与节点调度
PS:特殊注明,如果集群是VM的形式(非裸金属),那么上面跑mpirun的时候就需要指定预加载的集群拓扑文件
| 配置项 | 作用 | 推荐值(256台集群) |
|---|---|---|
NCCL_TOPO_FILE | 加载预生成的集群拓扑文件,让NCCL优先选择近节点通信(如同一机柜内)。 | /etc/nccl/topo_256node.xml(用nccl-topo-generator生成) |
NCCL_SOCKET_IFNAME | 绑定控制面TCP通信到低延迟网卡(避免与数据面IB冲突)。 | eth0(管理网专用网卡) |
NCCL_SHM_DISABLE | 禁用单机共享内存通信(多机场景无用,减少干扰)。 | 0(默认启用,若跨节点通信占比高可设为1) |
每次调整参数后,用相同命令测试并对比,记录调优前后的algbw
优先检查:
- IB网络是否跑满(用
ibstat看链路利用率是否≥90%); - 拓扑文件是否准确(
cat /etc/nccl/topo_256node.xml确认节点间距离参数)
1.5 业务推理&训练测试
模型部署,LLM框架,
开源LLM资料, 推理框架对比, 千卡训练
这里其实没啥好说的,就是上面这些都测完,输出报告。
确定没问题以后,会把机器给到最后用的,做业务算法的同学,交接给他们跑业务模型的实测效果,然后再根据业务测试的结果,决定是否用这个机器。
所以这一章就先过了。
之前好像还欠了一篇ai-infra,下次有机会再整理一波,包括实际模型部署&优化这种的~
2、数据
2.1 并行文件存储(PFS)
PFS介绍
-
PFS 通常指并行文件存储(Parallel File Storage),是一种专为高性能计算(如 AI、HPC)场景设计的并行文件系统。它采用分布式架构,允许大量客户端同时并行访问,提供高 IOPS、高吞吐和低时延的数据存储服务,具有高可靠性和可扩展性。
-
高性能计算 (HPC) 是一门使用一组尖端计算机系统执行复杂模拟、计算和数据分析的艺术和科学。HPC 计算机系统的特点是其高速处理能力、高性能网络和大内存容量,具备执行大量并行处理任务的能力。超级计算机是一种非常先进的 HPC 计算机,提供极强的计算能力和极高的速度,是高性能计算系统的关键组成部分。hpc
-
各家公有云: liantong, baidu, aliyun, huoshan, huawei
嗯,基本都用过,以及其他。
本质上就是支持多机器挂载的文件存储,不过底层做了很多优化,实际底层应该是对象,所以io能高很多。 -
PFS 用 “对象存储的分布式存储能力” 解决 “容量扩展” 问题,用 “并行化 IO 架构” 解决 “性能瓶颈” 问题 —— 两者结合刚好匹配 AI 训练的需求
-
不过实际使用过程中,也需要注意容量扩展(底层物理扩容集群), 以及扩容后并发上去带来的数据不均衡问题。1, 2, 不过一般厂商都会做自动均衡的,有问题可以直接找产品。
PFS的价值:支持大量扩容+io性能好
PFS 的价值:
- 并行写入:多 GPU 节点同时将参数分片写入 PFS,保存时间从分钟级降至秒级(如 8 卡同时写入,总带宽 8×10GB/s=80GB/s,40GB checkpoint 仅需 0.5 秒);
- 并行加载:恢复训练时,多 GPU 节点同时读取对应参数分片,快速启动训练(避免单节点加载导致的小时级延迟)。
PFS底层实现:对象存储+并行IO
PFS 的底层逻辑:
- 数据拆分:把一个大文件(如 100GB 训练集)拆成多个 “数据块”(类似对象,大小如 1GB),分散存到多个存储节点(OSS);
- 元数据管理:单独用元数据服务器(MDS)记录 “文件→数据块→存储节点” 的映射( 比如 “train_001.bin” 的块 1 在 OSS1、块 2 在 OSS2…);
- 并行 IO:GPU 节点读写文件时,MDS 直接返回所有数据块的存储位置,GPU 节点可同时向多个 OSS 发起读写请求(无需等待单个节点)。
2.2 服务器网络带宽(专线)
专线类型,适用范围
服务器网络专线是运营商为服务器提供的专属网络传输通道,不与其他用户共享带宽,能适配 AI 训练、大规模数据传输等对网络稳定性和速度要求高的场景。
| 专线类型 | 带宽范围 | 适用范围(城内/跨城) | 大致距离 | 参考 |
|---|---|---|---|---|
| OTN专线 | 2M - 100G,单纤可达10Tbps以上 | 城内、跨城、跨省均可 | 无明确距离限制,支持全国跨域及跨境 | 10G跨省年30w |
| SDH/MSTP专线 | 2M - 10G | 城内、跨城 | 支持跨地市及跨省传输 | 2M - 10M月数k |
| 裸纤专线 | 带宽随光模块定,支持10G、40G、100G等 | 城内为主,可短距离跨城 | 单段最大约300公里,常见20km左右场景 | 20km年20w,按公里计 |
复用线路 vs 单独施工
专线大多能复用运营商原有线路直接开通,但也有部分特殊场景需单独施工。例如
- 接入点无预置线路资源 (某新建的郊区 AI 训练基地,需开通 100G OTN 专线,因周边无运营商预置光纤)
- 特殊专线类型的需求 (大型数据中心之间互联租用裸纤专线,运营商需单独布设一条专属光纤,避免与其他业务线路干扰,保障带宽和传输稳定性自主可控)
- 跨区域 / 复杂组网的路由需求 这种的(某企业要搭建跨省的两地灾备专线,原有跨城线路时延过高,需重新规划路由,通过直埋或架空方式铺设新的跨城传输链路)
2.3 内网隧道、专用网卡、并发传输
隧道与专用网卡
-
这个不确定会不会被误会成某些技术导致审核,所以也就不细写了
反正就是打通局域网与公有云,方便两个集群数据传输 -
需要注意的点:
在公有云的vpc和内网保持一个网段,这样ip地址就不会冲突了 -
技术方案:
测试用反向代理,小规模IPsec,大规模SD-WAN,或者专线IPIP都可以的。 -
出口访问:
可以局域网内搞台机器专门做转发,export http_proxy="http://10.0.0.xxx:abcd"之类的就可以了 -
其他倒腾数据:
相比起直接scp很慢,可以用rlcone加并发,如何访问源端的话,可以参考下面的技术方案,走ftp,sftp,http,webdav之类的协议都是可以的。
使用rclone+nginx制作FTP镜像站
使用 rclone 连接 WebDAV 并提供 Web Api 给 nginx 1
3、日常运维
3.1 监控告警(grafana+prometheus+webhook)
参考 【监控】使用Prometheus+Grafana搭建服务器运维监控面板(含带BearerToken的Exporter配置)
计算层:GPU监控 DCGM exporter
- DCGM exporter采集单卡算力利用率、显存使用率、温度、功耗,设置阈值告警(如温度≥90℃、显存使用率≥95%)。
# 拉取官方镜像(推荐使用NGC镜像,版本与DCGM匹配)
docker pull nvcr.io/nvidia/k8s/dcgm-exporter:3.3.5# 启动容器(映射metrics端口9400,挂载GPU设备)
docker run -d \--name dcgm-exporter \--restart=always \--gpus all \ # 映射所有GPU设备-p 9400:9400 \ # 暴露metrics端口,供Prometheus抓取-e DCGM_EXPORTER_LISTEN=:9400 \ # 监听地址-e DCGM_EXPORTER_COLLECTORS=./etc/dcgm-exporter/default-collectors.csv \ # 采集指标配置nvcr.io/nvidia/k8s/dcgm-exporter:3.3.5# 验证是否正常运行
curl http://localhost:9400/metrics # 应返回GPU相关metrics(如dcgm_gpu_temp、dcgm_gpu_utilization等)
网络层: RDMA/InfiniBand/RoCE, ibstat
- IB网络:用
ibstat+Prometheus exporter监控链路状态(LinkUp=yes)、带宽利用率(≥90%告警)、错误包数(非零告警)。 - 以太网:监控专线带宽、延迟、丢包率(Zabbix或Node Exporter)。
- ibstat是InfiniBand(IB)网络的状态查询工具,用于查看 IB 网卡(HCA)、端口、链路、子网等硬件和逻辑状态,是 IB 网络运维(如万卡 GPU 集群)的核心工具。
- IB 网卡(InfiniBand 网卡)是支持 InfiniBand 高速网络协议的硬件设备,核心用于超算、AI 集群等场景。 什么是InfiniBand(IB)网络
是RDMA技术协议下的两个重要网络-InfiniBand(IB)网络和RoCE网络
| 维度 | RDMA(Remote Direct Memory Access) | InfiniBand(IB) | RoCE(RDMA over Converged Ethernet) |
|---|---|---|---|
| 定义 | 远程直接内存访问技术(协议无关) | 基于RDMA的专用高速网络协议/架构 | 基于以太网的RDMA协议(复用以太网硬件) |
| 底层网络 | 不依赖特定网络,可运行在IB/RoCE等上 | 专用IB网络(交换机、网卡均为IB设备) | 标准以太网(兼容现有以太网交换机) |
| 典型带宽 | - | 单端口最高400Gb/s(如HDR/HDR100) | 单端口最高400Gb/s(基于以太网800Gbps) |
| 延迟 | - | 微秒级(通常<10μs) | 接近IB(略高,取决于以太网配置) |
| 适用场景 | - | 超算、AI万卡集群(极致性能需求) | 中小型AI集群、混合负载(成本敏感) |
| 成本 | - | 高(专用硬件) | 较低(复用以太网基础设施) |
| 协议栈 | 无内核态干预,零拷贝 | 基于IBTA协议栈 | 基于以太网+RDMA协议(RoCEv1/v2) |
# 1. 查看所有IB网卡及端口状态(默认输出)
ibstat# 2. 列出所有IB网卡名称(如mlx5_0、mlx5_1)
ibstat -l# 3. 查看指定网卡(如mlx5_0)的详细信息(固件、型号等)
ibstat -d mlx5_0# 4. 查看指定端口(如mlx5_0的1号端口)的链路状态
ibstat mlx5_0/1 | grep -E "State|Physical State|Rate"# 5. 列出所有端口的GUID(用于网络拓扑识别)
ibstat -p
存储层:一级目录统计 & 容量阈值告警回调
- PFS监控(公有云API回调):OST使用率(≥80%告警)、IOPS、读写延迟(≥100ms告警)。
- 监控 PFS 挂载点的一级目录大小,过滤超阈值(如≥10TB)的目录,并通过 Webhook(如企业微信、钉钉)发送通知。
#!/bin/bash
# 简化版PFS一级目录大小统计(含超阈值Webhook告警)# 仅需修改这3个参数
PFS_DIR="/mnt/pfs" # PFS挂载点
THRESHOLD="10T" # 阈值(支持T/G/M,如5G、20T)
WEBHOOK="https://qyapi.weixin.qq.com/cgi-bin/webhook/send?key=你的密钥" # 告警Webhook# 统计一级目录大小并排序
echo "正在统计${PFS_DIR}下一级目录大小..."
size_list=$(du -sh ${PFS_DIR}/*/ 2>/dev/null | sort -hr)# 筛选超阈值目录
over_list=$(echo "$size_list" | awk -v thresh="$THRESHOLD" '$1 >= thresh')if [ -n "$over_list" ]; then# 构造告警消息msg="⚠️ PFS目录超阈值(${THRESHOLD})\n挂载点:${PFS_DIR}\n\n超标目录:\n$over_list"# 发送Webhook(企业微信示例,钉钉可改格式)curl -s -X POST $WEBHOOK -H "Content-Type: application/json" -d "{\"msgtype\":\"text\",\"text\":{\"content\":\"$msg\"}}"echo -e "\n已发送告警:\n$msg"
elseecho -e "\n所有目录均未超阈值(${THRESHOLD})"
fi
告警方式:
- 邮件+企微/钉钉机器人,基于webhook自己实现服务部署。类似, 1
- 分级告警(P0级故障<5分钟响应,如集群宕机;P1级<30分钟,如单卡故障)
告警阈值如存储80%以上,告警时间可以5分钟,10分钟,20分钟,40分钟,80分钟,指数递增。
集群层:k8s节点健康状态检查
- Slurm/K8s监控:任务排队时长(≥1小时告警)、节点健康状态(离线节点即时告警)。
prometheusRule:groups:- name: node-healthrules:- alert: NodeNotReadyexpr: kube_node_status_condition{condition="Ready",status="true"} == 0for: 30s # 持续30秒NotReady才告警(避免瞬时抖动)labels:severity: criticalannotations:summary: "节点 {{ $labels.node }} 状态异常"description: "节点 {{ $labels.node }} 已处于NotReady状态超过30秒,请检查kubelet、网络或硬件故障。"
3.2 容灾(故障恢复,宕机迁移)
- 很多GPU机器默认是带一些不低的故障率的。毕竟常年高功耗负载的运转。
- 无损迁移/恢复的核心:依赖共享存储(保存状态)+框架级Checkpoint(记录进度)+自动调度系统(重分配资源)
- 实际实践过程中,考虑到产品化没那么完善,一般来说,裸金属只支持集群里放备份机器手动切换,VM可以换底层Host但是至少1小时起,Pod可以自动调度但是故障拉起任务实际实现也比较复杂。
机器恢复(需中断,类似冷备)
| 维度 | 裸金属(物理机) | 虚拟机(VM) | 容器(K8s Pod) |
|---|---|---|---|
| 底层载体 | 物理服务器(无虚拟化层) | 虚拟化层(KVM/VMware)上的虚拟服务器 | 容器引擎(Docker/containerd)封装的应用单元 |
| 宕机迁移方式 | 任务级重调度(依赖业务断点续跑) | 整机迁移(冷迁移/热迁移,依赖虚拟化层) | 容器重建(K8s自动重启,依赖镜像和存储卷) |
| 数据依赖 | 强依赖共享存储(PFS/Lustre),本地数据易丢失 | 依赖VM镜像+共享存储,内存数据可同步(热迁移) | 依赖镜像(只读)+持久卷(PVC),数据存在共享存储 |
| 迁移耗时 | 分钟级(取决于任务启动和数据加载时间) | 热迁移:秒级(<1s);冷迁移:分钟级 | 秒级(容器启动快,依赖镜像拉取速度) |
| 自动剔除机制 | 需外部工具(如Slurm/Metal³)检测并标记故障节点 | 虚拟化平台(如OpenStack Nova)自动标记down节点 | K8s kube-controller-manager标记NotReady,调度器避开 |
| 典型适用场景 | AI训练集群、超算(追求极致性能) | 通用业务、数据库(需稳定和隔离) | 微服务、在线推理(追求弹性和快速迭代) |
任务恢复(无缝切,类似热备)
-
分布式训练框架
- PyTorch(DDP):支持通过
torch.save()定期保存Checkpoint到共享存储,节点故障后,在新节点加载Checkpoint续训,仅丢失最后一次Checkpoint后的训练进度(通常≤5分钟)。 - TensorFlow(MultiWorkerMirroredStrategy):通过
tf.train.Checkpoint保存模型和优化器状态,配合分布式文件系统(如GCS/HDFS),支持任务自动重调度续跑。
- PyTorch(DDP):支持通过
-
容器编排平台
- Kubernetes:
- 对于无状态服务(Deployment):Pod故障后自动在健康节点重建,依赖镜像和外部存储(如Ceph)实现“无损”(业务无感知,数据存在外部存储)。
- 对于有状态服务(StatefulSet):通过Headless Service和PVC模板,保证Pod重建后身份和数据不变,配合Raft等协议(如etcd集群)实现数据一致性。
- Kubernetes:
-
集群调度系统
- Slurm:通过
--requeue参数标记任务为“可重排队”,节点故障后任务自动进入队列,在健康节点重新启动(需任务支持断点续跑)。 - Apache Mesos:结合Marathon框架,任务故障时自动在其他Agent节点重启,依赖共享存储确保数据不丢失。
- Slurm:通过
3.3 安全(网络隔离、入侵检测)
网络隔离:安全组限制白名单,禁用密码登录
安全组限制白名单
- 对进出特定设备/实例的流量进行“白名单式”管控(默认拒绝所有,仅放行明确允许的规则),精准限制通信范围。
- 办公内网出口IP白名单清单,公有云机器访问控制限制到仅内网可访问。
安全组策略:
- 计算节点:仅开放SSH(22端口)、NCCL通信端口(自定义范围,如29500-29600),禁用公网直接访问。
- 管理节点:启用VPN访问,限制IP白名单,禁止密码登录(仅SSH密钥)。
禁用密码
#!/bin/bash
# 禁用SSH密码登录,仅允许密钥认证# 备份sshd配置文件
cp /etc/ssh/sshd_config /etc/ssh/sshd_config.bak# 修改配置(禁用密码登录、ChallengeResponse、root直接登录)
sed -i 's/^#PasswordAuthentication yes/PasswordAuthentication no/' /etc/ssh/sshd_config
sed -i 's/^PasswordAuthentication yes/PasswordAuthentication no/' /etc/ssh/sshd_config
sed -i 's/^#ChallengeResponseAuthentication yes/ChallengeResponseAuthentication no/' /etc/ssh/sshd_config
sed -i 's/^ChallengeResponseAuthentication yes/ChallengeResponseAuthentication no/' /etc/ssh/sshd_config
sed -i 's/^PermitRootLogin yes/PermitRootLogin no/' /etc/ssh/sshd_config # 禁止root直接登录# 重启sshd服务
systemctl restart sshd# 验证配置是否生效
grep -E "PasswordAuthentication|ChallengeResponseAuthentication|PermitRootLogin" /etc/ssh/sshd_config
echo "SSH密码登录已禁用,仅允许密钥认证"
# disable_ssh_password.yml
- hosts: all # 目标主机组(在inventory中定义)become: yes # 提权执行tasks:- name: 备份sshd配置copy:src: /etc/ssh/sshd_configdest: /etc/ssh/sshd_config.bak_{{ ansible_date_time.date }}remote_src: yesmode: '0600'- name: 禁用密码登录和root直接登录lineinfile:path: /etc/ssh/sshd_configregexp: '{{ item.regexp }}'line: '{{ item.line }}'state: presentwith_items:- { regexp: '^PasswordAuthentication', line: 'PasswordAuthentication no' }- { regexp: '^ChallengeResponseAuthentication', line: 'ChallengeResponseAuthentication no' }- { regexp: '^PermitRootLogin', line: 'PermitRootLogin no' }- name: 重启sshd服务service:name: sshdstate: restarted- name: 验证配置command: grep -E "PasswordAuthentication|PermitRootLogin" /etc/ssh/sshd_configregister: sshd_check- debug:var: sshd_check.stdout_lines
入侵检测:机器内进程监测
入侵检测:
- 部署IDS(如Suricata)监控异常流量(如大量SSH暴力破解、异常端口扫描)。
- 定期漏洞扫描(OpenVAS):检查GPU驱动、容器镜像、操作系统的高危漏洞(每月至少1次)。
- 数据安全:PFS启用访问控制列表(ACL),按用户组限制数据集读写权限,敏感数据加密存储(如LUKS加密)。
入侵检测工具(如Suricata)
#!/bin/bash
# 安装Suricata(开源网络入侵检测系统)# 安装依赖
apt update && apt install -y libpcre3 libpcre3-dbg libpcre3-dev \build-essential autoconf automake libtool libpcap-dev libnet1-dev \libyaml-0-2 libyaml-dev zlib1g zlib1g-dev libcap-ng-dev libcap-ng0 \make libmagic-dev libjansson-dev libjansson4# 下载并编译Suricata(最新稳定版)
VERSION="6.0.13"
wget https://www.openinfosecfoundation.org/download/suricata-${VERSION}.tar.gz
tar -zxf suricata-${VERSION}.tar.gz
cd suricata-${VERSION}
./configure --prefix=/usr --sysconfdir=/etc --localstatedir=/var
make && make install# 配置规则库(使用Emerging Threats规则)
suricata-update
systemctl enable --now suricata# 验证安装
suricata --version
echo "Suricata安装完成,规则库路径:/var/lib/suricata/rules/"