谷歌:LLM监督强化学习框架SRL

📖标题:Supervised Reinforcement Learning: From Expert Trajectories to Step-wise Reasoning
🌐来源:arXiv, 2510.25992
🌟摘要
大型语言模型 (LLM) 经常会遇到需要多步推理的问题。对于小规模的开源模型,即使在多次尝试之后很少采样正确解决方案时,具有可验证奖励 (RLVR) 的强化学习也会失败,而监督微调 (SFT) 倾向于通过严格的逐个令牌模仿过度拟合长演示。为了解决这一差距,我们提出了监督强化学习 (SRL),这是一个框架,它将问题解决重新表述为生成一系列逻辑“动作”。SRL 训练模型在提交每个动作之前生成内部推理独白。它以循序渐进的方式基于从SFT数据集中提取的模型动作和专家动作之间的相似性,提供了更平滑的奖励。即使所有推出不正确,这种监督也能提供更丰富的学习信号,同时鼓励专家演示指导的灵活推理。因此,SRL 使小型模型能够学习 SFT 或 RLVR 以前无法学习的挑战性问题。此外,在使用 RLVR 进行细化之前,使用 SRL 初始化训练会产生最强的整体性能。除了推理基准之外,SRL 可以有效地推广到代理软件工程任务,将其确立为面向推理的 LLM 的稳健且通用的训练框架。
🛎️文章简介
🔸研究问题:如何有效训练语言模型在复杂推理任务中学习,从专家的演示中获取知识?
🔸主要贡献:论文提出了监督强化学习(SRL)框架,以解决标准强化学习和监督微调在困难推理任务中的不足,通过细粒度的相似度奖励实现有效学习。
📝重点思路
🔸通过将复杂问题分解为逐步决策过程,SRL框架使模型能够逐步模拟专家的推理过程。
🔸使用动态采样策略过滤掉低有效更新的样本,以保持模型学习信号的强度。
🔸在每一步中,模型生成内部独白以指导其决策,最终根据与专家行动的相似度计算奖励。
🔸SRL结合了专家的演示,使模型能够从中学得合适的动作而不是单一的最终答案,从而灵活地产生多种推理模式。
🔎分析总结
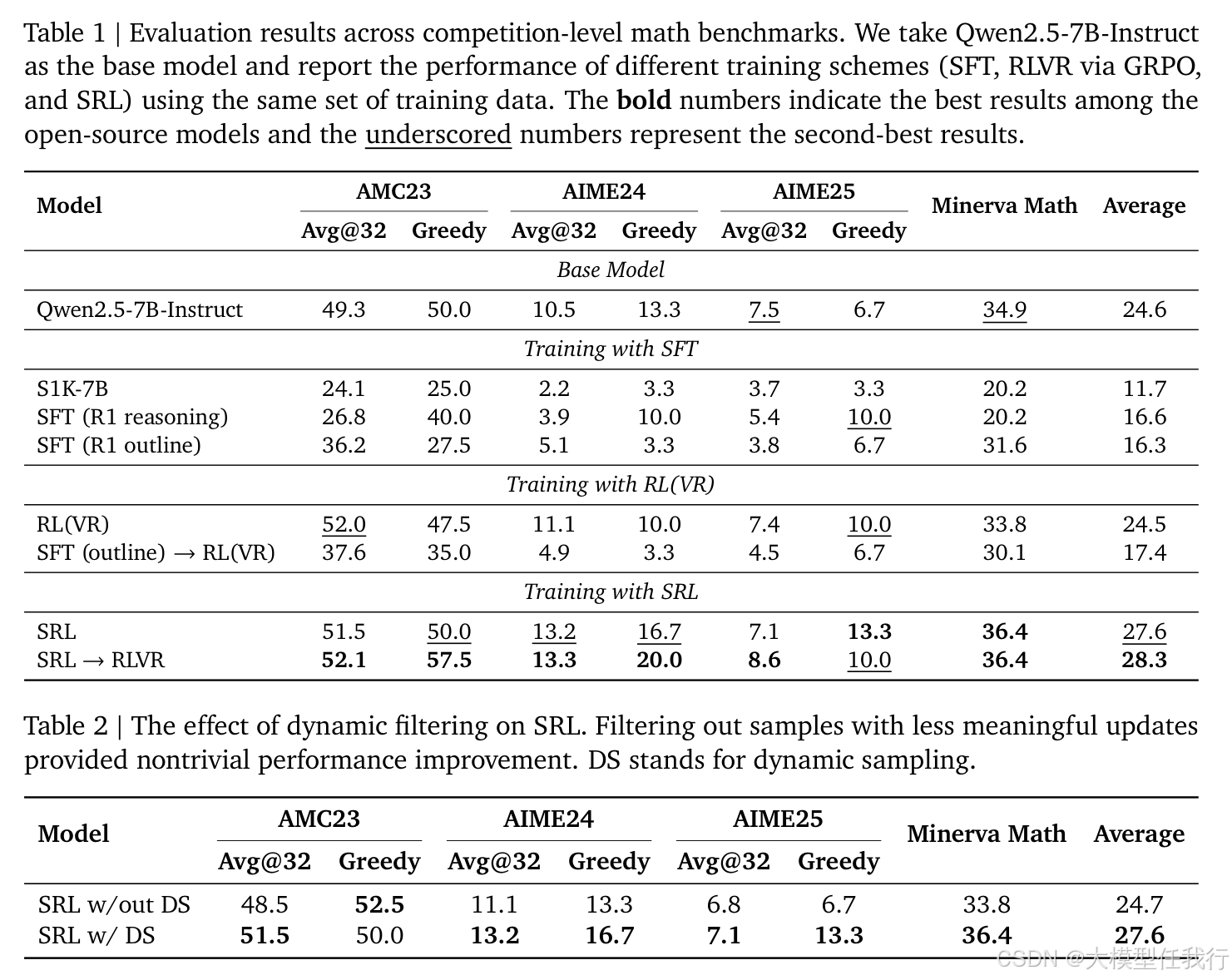
🔸实验结果表明,SRL在数学推理和软件工程任务上显著优于基线方法,提高了模型的解决率和推理能力。
🔸SRL框架提供的密集奖励信号有效地增强了模型的推理表现,使其能够更好地处理困难的推理问题。
🔸细粒度的指导(即逐步提示)极大提升了模型的推理质量,促进了交错的规划与验证行为。
🔸SRL的动态采样策略显示,移除那些提供零学习信号的样本对于强化学习训练的有效性至关重要。
💡个人观点
论文首先选择高效样本,并在推理时通过自我反馈和专家行动相似性学习到推理动作。
🧩附录