MyBatis:性能优化实战 - 从 SQL 优化到索引设计
一. 引言
在企业级应用开发中,数据访问层的性能直接决定了系统的整体响应速度。根据权威性能测试报告,数据库操作通常占据应用程序响应时间的 70% 以上,其中不合理的 SQL、缺失的索引和低效的 MyBatis 配置是导致性能问题的三大主因。
MyBatis 作为半自动化 ORM 框架,既保留了 SQL 的灵活性,又提供了对象映射能力,但这种灵活性也带来了性能优化的复杂性。很多开发者虽然掌握了 MyBatis 的基本使用,却在面对大数据量、高并发场景时束手无策:慢查询导致接口超时、连接池耗尽引发系统雪崩、索引失效造成全表扫描等问题屡见不鲜。
本文将从实战角度出发,系统讲解 MyBatis 性能优化的完整方案:从 SQL 编写优化、索引设计原则,到缓存机制配置、执行计划分析,最终通过真实案例展示如何将查询响应时间从秒级优化到毫秒级,帮助开发者构建高性能的数据访问层。
二. SQL 优化:从低效到高效的蜕变
1. 避免全表扫描:精准定位数据
全表扫描(Full Table Scan)是性能杀手之一,当表数据量超过 10 万条时,全表扫描的耗时会呈指数级增长。
反面案例:
<!-- 错误:未加条件的全表查询 -->
<select id="selectAllUsers" resultType="User">SELECT * FROM user
</select>
<!-- 错误:使用函数导致索引失效 -->
<select id="selectByUsername" resultType="User">SELECT * FROM user WHERE SUBSTR(username, 1, 3) = 'adm' <!-- 无法使用username索引 -->
</select>
优化方案:
- 添加必要的查询条件,限制返回数据量
- 避免在 WHERE 子句中对字段进行函数操作
- 使用分页查询处理大量数据
<!-- 优化:带条件的分页查询 -->
<select id="selectUsersByCondition" resultType="User">SELECT id, username, email, create_time FROM user WHERE status = #{status} AND create_time >= #{startTime}LIMIT #{offset}, #{pageSize} <!-- 分页限制 -->
</select>
MyBatis 分页插件优化:
使用 MyBatis-Plus 的分页插件,自动处理分页逻辑并避免全表扫描:
// 配置分页插件
@Bean
public MybatisPlusInterceptor mybatisPlusInterceptor() {MybatisPlusInterceptor interceptor = new MybatisPlusInterceptor();interceptor.addInnerInterceptor(new PaginationInnerInterceptor(DbType.MYSQL));return interceptor;
}
// 分页查询使用
Page<User> page = new Page<>(1, 10); // 第1页,每页10条
QueryWrapper<User> queryWrapper = new QueryWrapper<>();
queryWrapper.eq("status", 1);
Page<User> resultPage = userMapper.selectPage(page, queryWrapper);
2. 优化 JOIN 操作:减少关联层级
多表关联查询是业务开发中常见场景,但过多的 JOIN 操作会显著降低查询性能,尤其是关联大表时。
优化原则:
- 控制 JOIN 表数量,最多不超过 3 张表
- 关联字段必须建立索引
- 避免使用 SELECT *,只查询必要字段
反面案例:
<!-- 错误:多表JOIN且查询所有字段 -->
<select id="selectOrderDetail" resultType="OrderDetailVO">SELECT * FROM order oJOIN order_item oi ON o.id = oi.order_idJOIN product p ON oi.product_id = p.idJOIN user u ON o.user_id = u.idJOIN address a ON o.address_id = a.idWHERE o.id = #{orderId}
</select>
优化方案:
<!-- 优化:减少JOIN表并指定查询字段 -->
<select id="selectOrderDetail" resultType="OrderDetailVO">SELECT o.id, o.order_no, o.total_amount, o.create_time,u.id AS user_id, u.username,a.receiver, a.phone, a.addressFROM order oJOIN user u ON o.user_id = u.idJOIN address a ON o.address_id = a.idWHERE o.id = #{orderId}
</select>
<!-- 子查询获取订单项(按需加载) -->
<select id="selectOrderItems" resultType="OrderItemVO">SELECT oi.id, oi.product_id, oi.quantity, oi.unit_price,p.name AS product_nameFROM order_item oiJOIN product p ON oi.product_id = p.idWHERE oi.order_id = #{orderId}
</select>
关联查询替代方案:
- 分步查询:先查主表,再根据主表 ID 批量查询子表(利用 MyBatis 的@Batch注解)
- 冗余字段:对高频查询的关联字段进行冗余,减少 JOIN 操作
- 使用中间表:预先计算关联结果,适用于非实时数据场景
3. 动态 SQL 优化:避免拼接陷阱
MyBatis 的动态 SQL 功能(、、等)非常强大,但使用不当会导致性能问题。
常见问题:
- 循环拼接 IN 条件时,元素过多导致 SQL 过长
- 动态条件过多导致 SQL 解析耗时增加
- 重复的条件判断导致 SQL 冗余
优化示例:
批量操作优化:
<!-- 错误:大量元素的foreach导致SQL过长 -->
<delete id="batchDelete">DELETE FROM user WHERE id IN<foreach collection="ids" item="id" open="(" separator="," close=")">#{id}</foreach>
</delete>
<!-- 优化:分批次删除或使用批量删除语句 -->
<delete id="batchDelete">DELETE FROM user WHERE id IN<foreach collection="ids" item="id" open="(" separator="," close=")" size="1000"> <!-- 限制批次大小 -->#{id}</foreach>
</delete>
动态条件复用:
<!-- 定义SQL片段复用条件 -->
<sql id="baseQueryCondition"><where><if test="status != null">AND status = #{status}</if><if test="keyword != null">AND (username LIKE CONCAT('%', #{keyword}, '%') OR email LIKE CONCAT('%', #{keyword}, '%'))</if><if test="startTime != null">AND create_time >= #{startTime}</if><if test="endTime != null">AND create_time <= #{endTime}</if></where>
</sql>
<!-- 复用SQL片段 -->
<select id="selectByCondition" resultType="User">SELECT id, username, email FROM user<include refid="baseQueryCondition"/>ORDER BY create_time DESC
</select><select id="countByCondition" resultType="int">SELECT COUNT(1) FROM user<include refid="baseQueryCondition"/>
</select>
使用 choose 标签减少判断分支:
<select id="selectUser" resultType="User">SELECT * FROM user<where><choose><when test="id != null">AND id = #{id}</when><when test="username != null">AND username = #{username}</when><otherwise>AND status = 1</otherwise></choose></where>
</select>
4. 避免 N+1 查询问题
N+1 查询是 MyBatis 关联查询中常见的性能陷阱:当查询 N 条主表数据后,每条主表数据又触发一次子表查询,导致总共 N+1 次数据库交互。
问题示例:
// 1. 查询所有订单(1次查询)
List<Order> orders = orderMapper.selectAll();// 2. 遍历订单,查询每个订单的明细(N次查询)
for (Order order : orders) {List<OrderItem> items = orderItemMapper.selectByOrderId(order.getId());order.setItems(items);
}
// 总计:1 + N 次查询
解决方案:
关联查询一次性加载:
<resultMap id="orderWithItemsMap" type="Order"><id column="id" property="id"/><result column="order_no" property="orderNo"/><!-- 一对多关联,一次性加载 --><collection property="items" ofType="OrderItem"><id column="item_id" property="id"/><result column="product_id" property="productId"/><result column="quantity" property="quantity"/></collection>
</resultMap><select id="selectOrdersWithItems" resultMap="orderWithItemsMap">SELECT o.id, o.order_no,oi.id AS item_id, oi.product_id, oi.quantityFROM order oLEFT JOIN order_item oi ON o.id = oi.order_idWHERE o.status = #{status}
</select>
MyBatis 延迟加载 + 批量查询:
<!-- 配置延迟加载 -->
<settings><setting name="lazyLoadingEnabled" value="true"/><setting name="aggressiveLazyLoading" value="false"/>
</settings><!-- 订单结果映射 -->
<resultMap id="orderMap" type="Order"><id column="id" property="id"/><result column="order_no" property="orderNo"/><!-- 延迟加载订单项 --><collection property="items" select="com.example.mapper.OrderItemMapper.selectByOrderIds"column="id" fetchType="lazy"/>
</resultMap><!-- 订单项Mapper -->
<select id="selectByOrderIds" resultType="OrderItem">SELECT * FROM order_item WHERE order_id IN<foreach collection="list" item="id" open="(" separator="," close=")">#{id}</foreach>
</select>
优化效果:将 N+1 次查询减少为 2 次查询(1 次主表查询 + 1 次批量子表查询)。
三. 索引设计:数据库性能的基石
1. 索引类型与适用场景
MyBatis 的性能优化离不开合理的索引设计,不同类型的索引适用于不同场景:
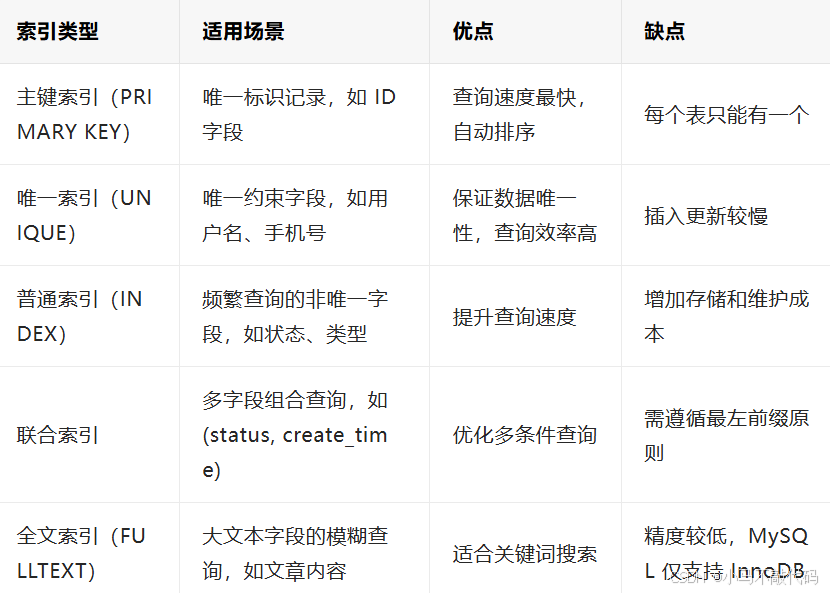
创建示例:
-- 主键索引(通常在建表时指定)
ALTER TABLE `user` ADD PRIMARY KEY (`id`);
-- 唯一索引
ALTER TABLE `user` ADD UNIQUE INDEX `idx_username` (`username`);
-- 普通索引
ALTER TABLE `order` ADD INDEX `idx_status` (`status`);
-- 联合索引(按查询频率排序字段)
ALTER TABLE `order` ADD INDEX `idx_status_create_time` (`status`, `create_time`);
-- 全文索引
ALTER TABLE `article` ADD FULLTEXT INDEX `idx_content` (`content`);
2. 联合索引设计原则
联合索引是优化多条件查询的关键,但设计不当会导致索引失效,需遵循以下原则:
- 最左前缀匹配原则:
联合索引(a, b, c)等效于(a)、(a,b)、(a,b,c)三个索引,where 条件中必须包含最左字段a才能使用该索引。
// 有效使用联合索引(a,b,c)的查询
WHERE a = ? // 使用(a)部分
WHERE a = ? AND b = ? // 使用(a,b)部分
WHERE a = ? AND b = ? AND c = ? // 使用全部索引
// 无法使用联合索引的查询
WHERE b = ? // 缺少最左字段a
WHERE a = ? AND c = ? // 中间字段b缺失,只能使用(a)部分
- 字段顺序原则:
区分度高的字段放前面(如用户 ID 比状态字段区分度高)
频繁查询的字段放前面
范围查询字段放最后(范围查询后的字段无法使用索引)
-- 推荐:区分度高的user_id放前面,范围查询create_time放最后
CREATE INDEX idx_user_status_time ON `order`(user_id, status, create_time);-- 优化查询
SELECT * FROM `order`
WHERE user_id = 100 AND status = 1 AND create_time > '2024-01-01';
- 避免冗余索引:
若已存在联合索引(a,b),则无需单独创建(a)索引,避免维护成本增加。
3. 索引失效的十大陷阱
即使创建了索引,以下情况也会导致索引失效,需特别注意:
- 使用函数或表达式操作索引字段:
WHERE SUBSTR(username, 1, 3) = 'adm' -- username索引失效
WHERE price * 1.2 > 100 -- price索引失效
- 隐式类型转换:
-- 字段类型为varchar,查询用数字,导致全表扫描
WHERE phone = 13800138000 -- phone索引失效
-- 正确写法:WHERE phone = '13800138000'
- 使用 NOT IN、!=、<> 操作符:
WHERE status != 1 -- status索引失效
- 使用 OR 连接非索引字段:
-- name无索引,导致id索引也失效
WHERE id = 100 OR name = 'test'
- LIKE 以 % 开头的模糊查询:
WHERE username LIKE '%admin' -- 索引失效
-- 可以使用:WHERE username LIKE 'admin%'(前缀匹配)
- 联合索引不满足最左前缀:
-- 联合索引(a,b,c),缺少a导致索引失效
WHERE b = 1 AND c = 2
WHERE 子句中使用 IS NULL/IS NOT NULL:
WHERE email IS NULL -- 可能导致索引失效(视数据库版本而定)
-
查询条件包含全表扫描更优的情况:
当查询结果超过表数据量 30% 时,数据库可能选择全表扫描而非索引。 -
使用 ORDER BY 时字段顺序与索引不一致:
-- 索引为(status, create_time),排序字段顺序不一致
WHERE status = 1 ORDER BY create_time DESC, id ASC -- 部分失效
- 更新频繁的字段创建过多索引:
每个索引都会增加写入操作的开销,写入频繁的表应控制索引数量。
4. MyBatis 与索引协同优化
MyBatis 的配置需与索引设计协同,才能发挥最大性能:
- ResultMap 优化:
只映射必要字段,避免 SELECT * 导致的额外 I/O:
<!-- 优化:只映射需要的字段 -->
<resultMap id="userBaseMap" type="User"><id column="id" property="id"/><result column="username" property="username"/><result column="status" property="status"/>
</resultMap>
<select id="selectUserList" resultMap="userBaseMap">SELECT id, username, status FROM user WHERE status = #{status}
</select>
- 避免使用useGeneratedKeys影响索引:
对于非自增主键(如雪花算法 ID),关闭useGeneratedKeys减少不必要的查询:
<insert id="insertUser" parameterType="User" useGeneratedKeys="false">INSERT INTO user(id, username, email) VALUES(#{id}, #{username}, #{email})
</insert>
- 分页查询与索引结合:
分页查询的 ORDER BY 字段应包含在索引中,避免文件排序:
<!-- 索引:(status, create_time) -->
<select id="selectUserPage" resultType="User">SELECT id, username, create_time FROM user WHERE status = #{status}ORDER BY create_time DESC <!-- 排序字段在索引中 -->LIMIT #{offset}, #{pageSize}
</select>
四. 缓存机制:减少数据库访问的关键
1. 一级缓存优化(SqlSession 级别)
MyBatis 一级缓存默认开启,作用范围为 SqlSession(会话),在同一个会话中多次执行相同查询会命中缓存。
工作原理:
缓存 key:由 SQL 语句、参数、RowBounds、环境等组成
缓存失效:执行 INSERT/UPDATE/DELETE 操作或调用clearCache()时
优化实践:
// 优化:同一事务中复用查询结果
@Service
public class OrderService {@Autowiredprivate OrderMapper orderMapper;@Transactionalpublic OrderDTO getOrderDetail(Long orderId) {// 第一次查询:从数据库获取Order order = orderMapper.selectById(orderId);// 业务处理...// 第二次查询:命中一级缓存,无需访问数据库Order orderAgain = orderMapper.selectById(orderId);return convertToDTO(order);}
}
注意事项:
- 一级缓存不能跨 SqlSession 共享,分布式环境下无效
- 长事务中一级缓存会占用大量内存,需及时清理
- 避免在循环中执行相同查询,应批量查询后在内存中处理
2. 二级缓存配置(Mapper 级别)
二级缓存作用范围为 Mapper 接口,可跨 SqlSession 共享,适合查询频繁、更新较少的数据(如字典表、商品分类)。
配置步骤:
开启全局二级缓存:
<settings><!-- 开启二级缓存 --><setting name="cacheEnabled" value="true"/>
</settings>
在 Mapper.xml 中配置缓存:
<!-- UserMapper.xml -->
<mapper namespace="com.example.mapper.UserMapper"><!-- 配置二级缓存 --><cache eviction="LRU" <!-- 淘汰策略:LRU(最近最少使用) -->flushInterval="60000" <!-- 自动刷新时间(毫秒) -->size="1024" <!-- 最大缓存对象数 -->readOnly="false"/> <!-- 是否只读 --><!-- 配置statement是否使用缓存 --><select id="selectById" resultType="User" useCache="true">SELECT * FROM user WHERE id = #{id}</select><!-- 写操作需刷新缓存 --><update id="updateById" flushCache="true">UPDATE user SET username = #{username} WHERE id = #{id}</update>
</mapper>
实体类实现序列化:
public class User implements Serializable { // 二级缓存要求实体可序列化private Long id;private String username;// ...
}
缓存淘汰策略:
- LRU(Least Recently Used):移除最近最少使用的对象(默认)
- FIFO(First In First Out):按插入顺序移除对象
- SOFT:基于软引用,内存不足时移除
- WEAK:基于弱引用,随时可能被垃圾回收
3. 第三方缓存集成(Redis)
MyBatis 默认二级缓存基于内存,不适合分布式环境,推荐集成 Redis 作为分布式缓存。
集成步骤:
引入依赖:
<dependency><groupId>org.mybatis.caches</groupId><artifactId>mybatis-redis</artifactId><version>1.0.0-beta2</version>
</dependency>
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
配置 Redis 缓存:
# redis.properties
redis.host=localhost
redis.port=6379
redis.timeout=2000
redis.password=
redis.database=0
redis.keyPrefix=mybatis:cache:
redis.expire=3600 # 缓存过期时间(秒)
在 Mapper 中使用 Redis 缓存:
<mapper namespace="com.example.mapper.DictMapper"><!-- 使用Redis缓存 --><cache type="org.mybatis.caches.redis.RedisCache"/><select id="selectByType" resultType="Dict" useCache="true">SELECT * FROM dict WHERE type = #{type}</select>
</mapper>
分布式缓存最佳实践:
- 缓存热点数据(访问频率高、更新频率低)
- 设置合理的过期时间,避免缓存雪崩
- 对缓存 key 进行统一命名规范,便于管理
- 实现缓存预热机制,避免缓存穿透
4. 缓存失效问题与解决方案
缓存失效是导致性能下降的常见原因,需针对性解决:
缓存穿透:
问题:查询不存在的数据,导致缓存失效,每次都访问数据库。
解决方案:缓存空结果,设置短期过期时间(或者使用布隆过滤器)。
public User selectById(Long id) {User user = cache.get(id);if (user != null) {return user; // 命中缓存}user = userMapper.selectById(id);if (user == null) {// 缓存空结果,设置5分钟过期cache.set(id, NULL_VALUE, 300);} else {cache.set(id, user, 3600);}return user;
}
缓存击穿:
问题:热点 key 过期瞬间,大量请求穿透到数据库。
解决方案:互斥锁或热点数据永不过期。
public User getHotUser(Long id) {User user = cache.get(id);if (user != null) {return user;}// 获取互斥锁String lockKey = "lock:user:" + id;if (redisTemplate.opsForValue().setIfAbsent(lockKey, "1", 10, TimeUnit.SECONDS)) {try {// 再次检查缓存user = cache.get(id);if (user == null) {user = userMapper.selectById(id);cache.set(id, user, 86400); // 热点数据缓存1天}} finally {// 释放锁redisTemplate.delete(lockKey);}} else {// 未获取到锁,重试Thread.sleep(100);return getHotUser(id);}return user;
}
缓存雪崩:
问题:大量缓存同时过期,导致数据库压力骤增。
解决方案:过期时间加随机值,避免同时过期。
// 设置随机过期时间(1小时±10分钟)
int baseExpire = 3600;
int random = new Random().nextInt(1200) - 600; // -600到600秒
cache.set(key, value, baseExpire + random);
五. 执行计划分析:定位性能瓶颈
1. 解读 EXPLAIN 执行计划
EXPLAIN 命令是分析 SQL 性能的利器,通过它可以查看 SQL 的执行计划,识别全表扫描、索引失效等问题。
使用方法:在 SQL 前加上 EXPLAIN 关键字:
EXPLAIN
SELECT id, username FROM user
WHERE status = 1 AND create_time >= '2024-01-01'
ORDER BY create_time DESC;
关键字段解读:
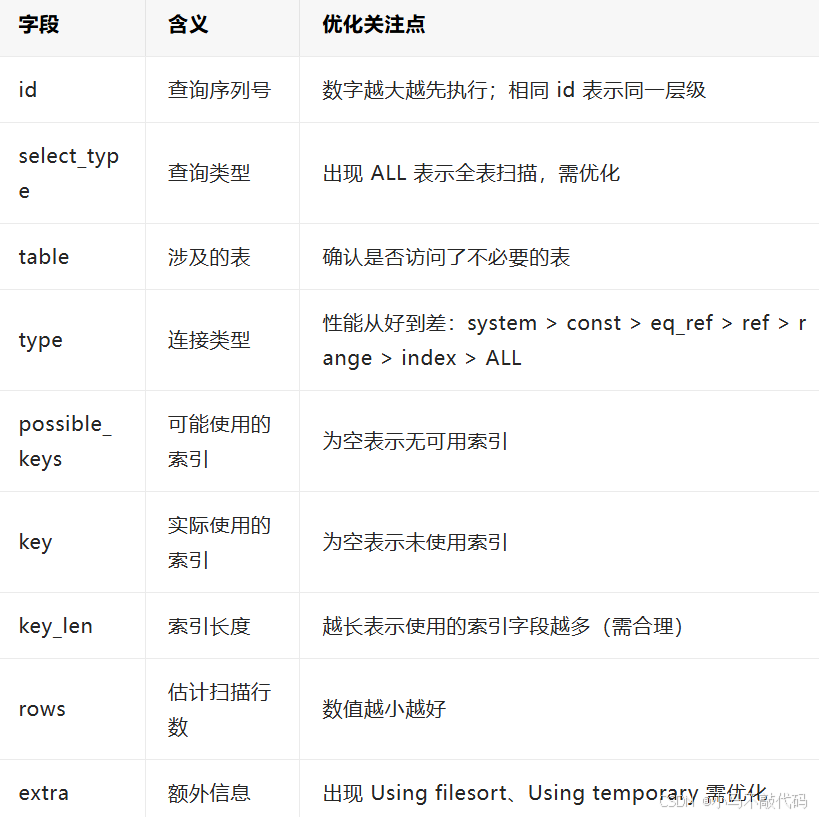
常见 Extra 优化点:
- Using filesort:需要额外排序,优化:使排序字段包含在索引中
- Using temporary:使用临时表,优化:避免 GROUP BY 或 DISTINCT 操作,或添加合适索引
- Using where; Using index:覆盖索引,最佳状态
- Using index condition:索引下推,良好状态
2. MyBatis 日志配置:查看真实执行 SQL
MyBatis 默认不会输出完整 SQL,需配置日志查看实际执行的 SQL 语句和参数,便于分析优化。
配置方式(application.yml):
logging:level:# 配置Mapper接口所在包的日志级别为DEBUGcom.example.mapper: DEBUG
日志输出示例:
DEBUG [main] com.example.mapper.UserMapper.selectById - ==> Preparing: SELECT id, username, email FROM user WHERE id = ?
DEBUG [main] com.example.mapper.UserMapper.selectById - ==> Parameters: 1001(Long)
DEBUG [main] com.example.mapper.UserMapper.selectById - <== Total: 1
进阶:集成 p6spy 查看完整 SQL:
对于需要查看带参数的完整 SQL(如调试动态 SQL),可集成 p6spy:
引入依赖:
<dependency><groupId>p6spy</groupId><artifactId>p6spy</artifactId><version>3.9.1</version>
</dependency>
配置数据源:
spring:datasource:driver-class-name: com.p6spy.engine.spy.P6SpyDriverurl: jdbc:p6spy:mysql://localhost:3306/mybatis_demo?useSSL=falseusername: rootpassword: 123456
配置 spy.properties:
appender=com.p6spy.engine.spy.appender.Slf4JLogger
logMessageFormat=com.p6spy.engine.spy.appender.MultiLineFormat
databaseDialectDateFormat=yyyy-MM-dd HH:mm:ss
配置后可直接查看带参数的完整 SQL,便于复制到数据库客户端执行 EXPLAIN 分析。
3. 慢查询日志分析
启用 MySQL 慢查询日志,记录执行时间超过阈值的 SQL,针对性优化:
开启慢查询日志:
# my.cnf 配置
slow_query_log = 1
slow_query_log_file = /var/log/mysql/slow.log
long_query_time = 1 # 执行时间超过1秒的SQL视为慢查询
log_queries_not_using_indexes = 1 # 记录未使用索引的查询
分析慢查询日志:
使用 mysqldumpslow 工具分析:
# 查看最耗时的10条慢查询
mysqldumpslow -s t -t 10 /var/log/mysql/slow.log
# 查看访问次数最多的10条慢查询
mysqldumpslow -s c -t 10 /var/log/mysql/slow.log
- 结合 MyBatis 定位问题:
根据慢查询日志中的 SQL,在 MyBatis 的 Mapper 中找到对应方法,检查:
- 是否使用了合适的索引
- 是否存在 N+1 查询
- 动态 SQL 是否生成了冗余条
- 是否查询了不必要的字段或表
六. 实战案例:订单查询性能优化
1. 问题场景
某电商平台订单查询接口响应缓慢,高峰期耗时超过 3 秒,数据库 CPU 使用率经常达到 90% 以上。该接口主要功能是根据用户 ID、订单状态、时间范围等条件查询订单列表,并返回订单明细和商品信息。
原始实现:
<!-- OrderMapper.xml -->
<select id="selectOrders" resultType="OrderVO">SELECT o.*, oi.*, p.name AS product_name, p.price AS product_priceFROM order oLEFT JOIN order_item oi ON o.id = oi.order_idLEFT JOIN product p ON oi.product_id = p.idWHERE 1=1<if test="userId != null">AND o.user_id = #{userId}</if><if test="status != null">AND o.status = #{status}</if><if test="startTime != null">AND o.create_time >= #{startTime}</if><if test="endTime != null">AND o.create_time <= #{endTime}</if>ORDER BY o.create_time DESC
</select>
问题分析:
- 使用SELECT *查询所有字段,包括大量不必要字段
- 多表 JOIN 导致查询复杂,无法有效使用索引
- 未分页,当订单数量大时返回数据过多
- 动态条件未优化,可能导致索引失效
2. 优化步骤
步骤 1:SQL 重构与索引优化
精简查询字段,只返回必要信息
添加分页限制,避免大量数据返回
创建合适的索引:
-- 订单表索引:优化查询条件和排序
CREATE INDEX idx_user_status_time ON `order`(user_id, status, create_time);
-- 订单项索引:优化关联查询
CREATE INDEX idx_order_id ON order_item(order_id);
优化后的 SQL:
<select id="selectOrders" resultType="OrderVO">SELECT o.id, o.order_no, o.total_amount, o.create_time, o.status,oi.id AS item_id, oi.product_id, oi.quantity, oi.unit_price,p.name AS product_nameFROM order oLEFT JOIN order_item oi ON o.id = oi.order_idLEFT JOIN product p ON oi.product_id = p.id<where><if test="userId != null">AND o.user_id = #{userId}</if><if test="status != null">AND o.status = #{status}</if><if test="startTime != null">AND o.create_time >= #{startTime}</if><if test="endTime != null">AND o.create_time <= #{endTime}</if></where>ORDER BY o.create_time DESCLIMIT #{offset}, #{pageSize}
</select>
步骤 2:解决 N+1 查询问题
将订单主表和订单项查询分离,先查询主表,再批量查询订单项:
@Service
public class OrderServiceImpl implements OrderService {@Autowiredprivate OrderMapper orderMapper;@Autowiredprivate OrderItemMapper itemMapper;@Overridepublic PageResult<OrderVO> queryOrders(OrderQuery query) {// 1. 查询订单主表(分页)int total = orderMapper.countOrders(query);if (total == 0) {return PageResult.empty();}List<OrderVO> orderVOs = orderMapper.selectOrderMains(query);List<Long> orderIds = orderVOs.stream().map(OrderVO::getId).collect(Collectors.toList());// 2. 批量查询订单项(1次查询)List<OrderItemVO> items = itemMapper.selectByOrderIds(orderIds);// 3. 内存中组装数据Map<Long, List<OrderItemVO>> itemMap = items.stream().collect(Collectors.groupingBy(OrderItemVO::getOrderId));orderVOs.forEach(vo -> vo.setItems(itemMap.getOrDefault(vo.getId(), Collections.emptyList())));return new PageResult<>(total, orderVOs);}
}
步骤 3:添加二级缓存
对于用户查询自己的订单历史,添加二级缓存减少数据库访问:
<!-- OrderMapper.xml -->
<mapper namespace="com.example.mapper.OrderMapper"><!-- 配置二级缓存,过期时间30分钟 --><cache type="org.mybatis.caches.redis.RedisCache"eviction="LRU"flushInterval="1800000"size="5000"/><!-- 查询订单主表,使用缓存 --><select id="selectOrderMains" resultType="OrderVO" useCache="true">SELECT id, order_no, total_amount, create_time, statusFROM order<where><if test="userId != null">AND user_id = #{userId}</if><!-- 其他条件 --></where>ORDER BY create_time DESCLIMIT #{offset}, #{pageSize}</select><!-- 写操作刷新缓存 --><update id="updateOrderStatus" flushCache="true">UPDATE order SET status = #{status} WHERE id = #{id}</update>
</mapper>
步骤 4:执行计划验证
使用 EXPLAIN 分析优化后的 SQL:
EXPLAIN
SELECT id, order_no, total_amount, create_time, status
FROM order
WHERE user_id = 1001 AND status = 2
ORDER BY create_time DESC
LIMIT 0, 10;
优化后执行计划关键指标:
type: ref(使用了索引)
key: idx_user_status_time(使用了预期的联合索引)
rows: 10(扫描行数少)
Extra: Using where; Using index; Using filesort(无全表扫描)
3. 优化效果对比
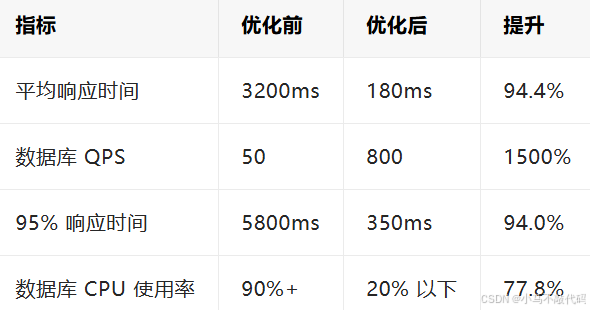
七. 监控与持续优化
1. 集成 SpringBoot Actuator 监控
通过 SpringBoot Actuator 监控 MyBatis 关键指标,及时发现性能问题:
添加依赖:
<dependency><groupId>org.springframework.boot</groupId><artifactId>spring-boot-starter-actuator</artifactId>
</dependency>
配置监控端点:
management:endpoints:web:exposure:include: health,info,metrics,mybatismetrics:tags:application: order-serviceendpoint:health:show-details: always
自定义 MyBatis 监控指标:
@Component
public class MyBatisMetricsMonitor {private final MeterRegistry meterRegistry;public MyBatisMetricsMonitor(MeterRegistry meterRegistry) {this.meterRegistry = meterRegistry;// 注册MyBatis执行时间指标Timer.builder("mybatis.execution.time").description("MyBatis SQL execution time").register(meterRegistry);}// 记录SQL执行时间public <T> T recordExecutionTime(Supplier<T> supplier, String mapper, String method) {Timer.Sample sample = Timer.start(meterRegistry);try {return supplier.get();} finally {sample.stop(Timer.builder("mybatis.execution.time").tag("mapper", mapper).tag("method", method).register(meterRegistry));}}
}
2. 性能测试与基准对比
定期进行性能测试,建立基准线,确保优化效果持续:
使用 JMH 进行微基准测试:
@BenchmarkMode(Mode.AverageTime)
@OutputTimeUnit(TimeUnit.MILLISECONDS)
@State(Scope.Thread)
public class OrderMapperBenchmark {private SqlSession sqlSession;private OrderMapper orderMapper;private OrderQuery query;@Setup(Level.Trial)public void setup() {// 初始化MyBatis环境SqlSessionFactory factory = new SqlSessionFactoryBuilder().build(Resources.getResourceAsStream("mybatis-config.xml"));sqlSession = factory.openSession();orderMapper = sqlSession.getMapper(OrderMapper.class);// 准备测试数据query = new OrderQuery();query.setUserId(1001L);query.setStatus(2);query.setPageSize(10);}@Benchmarkpublic List<OrderVO> testSelectOrders() {return orderMapper.selectOrders(query);}@TearDown(Level.Trial)public void teardown() {sqlSession.close();}
}
关键测试指标:
- 平均响应时间(Average Time)
- 吞吐量(Throughput)
- 内存分配(Allocation Rate)
- 垃圾回收次数(GC Count)
3. 持续优化策略
性能优化是一个持续过程,需建立长效机制:
1、代码审查制度:
新增 SQL 必须附带 EXPLAIN 执行计划分析
禁止使用 SELECT * 和全表扫描
关联表数量不超过 3 张
2、定期索引优化:
每周分析慢查询日志,优化低效索引
使用 pt-index-usage 工具分析索引使用情况
移除长期未使用的冗余索引
3、缓存策略调整:
根据业务变化调整缓存过期时间
监控缓存命中率,低于 80% 需优化
定期清理缓存碎片
4、数据库扩容准备:
当单表数据量接近 1000 万时,准备分库分表
提前规划读写分离架构
建立数据归档机制,迁移历史数据
总结
MyBatis 性能优化是一项系统工程,需要从 SQL 编写、索引设计、缓存配置到执行计划分析全方位入手。本文通过实战案例展示了如何将一个响应缓慢的接口优化到毫秒级,核心在于:
1、减少数据库访问:通过合理的缓存策略和批量操作,降低数据库压力
2、提高查询效率:优化 SQL 结构,设计高效索引,避免全表扫描
3、避免性能陷阱:警惕 N+1 查询、索引失效、缓存穿透等常见问题
4、建立监控体系:通过监控指标和性能测试,持续发现并解决问题
性能优化没有银弹,需要结合具体业务场景,平衡开发效率和运行性能。我们应养成 “性能意识”,在代码编写阶段就考虑性能影响,而非等到系统出现问题后再补救。