小杰-大模型(one)——RAG与Agent设计——Langchain部署大模型。
1. Langchain部署本地大模型
1.1 Langchain的安装
pip install langchain==0.3.4
pip install langchain_community==0.3.5
pip install -U langchain-openai==0.2.5这三个库都与构建和使用自然语言处理(NLP)和人工智能(AI)应用有关。下面是每个库的简要介绍:
1. langchain==0.3.4
langchain 是一个用于构建对话系统的框架。它提供了许多工具和模块,帮助开发者快速搭建和训练对话系统。这个库支持多种语言模型和服务,包括但不限于 OpenAI 的模型。
2. langchain_community==0.3.5
langchain_community 是一个社区驱动的扩展库,旨在为 langchain 提供更多的功能和插件。这个库通常包含由社区贡献的模块和工具,可以帮助开发者更快地实现特定功能。
3. langchain-openai==0.2.5
langchain-openai 是专门为 langchain 框架设计的 OpenAI 集成库。它提供了与 OpenAI API 交互的便捷方式,使得在 langchain 中使用 OpenAI 的模型变得更加简单。
1.2 Langchain模型推理
Langchain中包含两种语言模型:LLMs(纯文本补全模型)和ChatModels(专门针对对话进行了调整的模型)。
其中LLMs以字符串作为输入并返回字符串而ChatModels以消息列 表作为输入并返回消息。
LLMs比较好理解输入输出都是字符串。
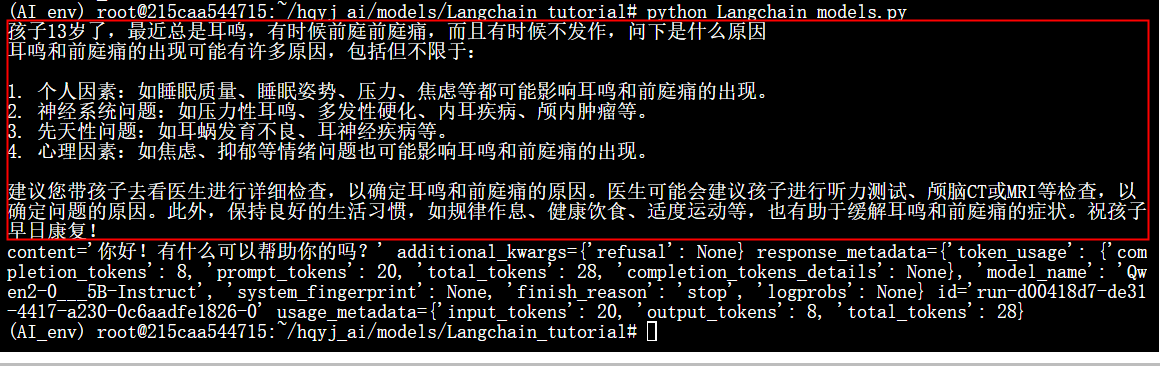
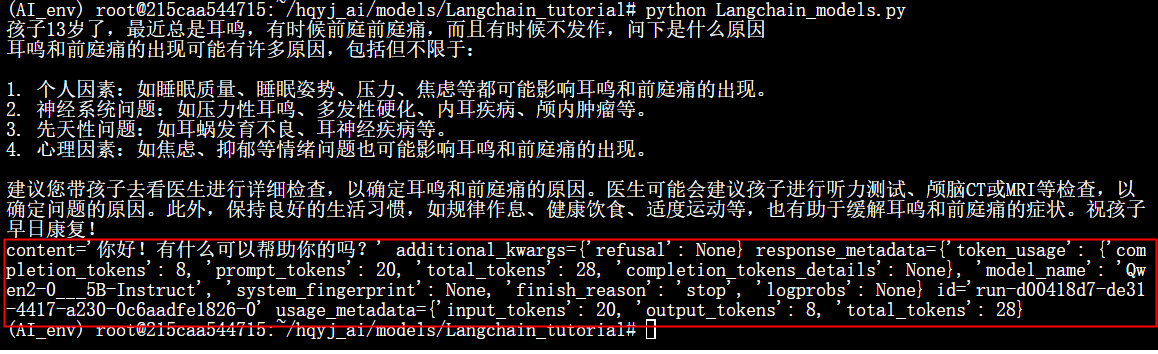
我们来说一下ChatModels。ChatModels输入是一个ChatMessage列表。而输出是一个单独的ChatMessage,一个ChatMessage具有两个必需的组件:
- content: 这是消息的内容。
- role: 这是ChatMessage来自的实体的角色。包括
- HumanMessage来自人类/用户的ChatMessage
- AIMessage(AI消息)来自AI/助手的ChatMessage
- SystemMessage来自系统的ChatMessage(系统预设的提示或规则,定义AI的行为边界、角色设定或对话上下文)
- FunctionMessage来自函数调用的ChatMessage(获得外部工具/函数执行后的返回结果,作用:向AI传递函数调用的执行结果))
Langchain为LLMs和ChatModels都提供了标准接口。
from langchain_openai import OpenAI是纯文本补全模型。它们包装的 API 将字符串提示作为输入并输出字符串完成。
from langchain_openai import ChatOpenAI是聊天模型,通常由LLMs支持,但专门针对对话进行了调整。
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAIllm = OpenAI()
chat_model = ChatOpenAI()但这种方式需要OpenAI的api,下面介绍两种Langchain调用大模型的方法。
.2.1 方法一
直接调用硅基流动上的OpenAI接口
from langchain_openai import ChatOpenAI
from langchain_openai import OpenAI
#续写能力
llm = OpenAI(openai_api_key="sk-bhpqpryfyiszcqwugbmjgvvccultcovcgbfbvauxnbbfkcdo", # 替换为你的实际API密钥base_url="https://api.siliconflow.cn/v1",model="Qwen/Qwen2.5-7B-Instruct"
)print(llm.invoke("你好"))
print("------------------------------------")#聊天能力
chat_model = ChatOpenAI(openai_api_key="sk-bhpqpryfyiszcqwugbmjgvvccultcovcgbfbvauxnbbfkcdo", # 替换为你的实际API密钥base_url="https://api.siliconflow.cn/v1",model="Qwen/Qwen2.5-7B-Instruct"
)print(chat_model.invoke("你好"))1.2.2 方法二
使用手动封装续写模型 替换掉openai(手动封装的效果等于llm.invoke的效果,也就是纯文本补全)。
from langchain.llms.base import LLM
from transformers import AutoModelForCausalLM, AutoTokenizer
import torch
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
#分词
tokenizer = AutoTokenizer.from_pretrained("./models/Qwen/Qwen2.5-0.5B-Instruct")
#加载因果语言模型
model = AutoModelForCausalLM.from_pretrained("./models/Qwen/Qwen2.5-0.5B-Instruct",torch_dtype=torch.float16).to(device)class CustomLLM(LLM):def _call(self, prompt: str, stop: list = None) -> str:#-> str表示返回是字符串# 将输入 prompt 转换为模型的输入格式inputs = tokenizer(prompt, return_tensors="pt").to(device)# 生成模型输出# ** 是解包运算符,专门用于字典。当字典被 ** 解包时,字典的 键(key) 会作为参数名,# 值(value) 会作为参数值传递给函数outputs = model.generate(**inputs)# 解码输出 为文本格式generated_text = tokenizer.decode(outputs[0], skip_special_tokens=True)return generated_text# @property装饰器表示这是一个属性方法,可以通过实例._identifying_params直接访问(无需加括号)@propertydef _identifying_params(self):"""返回模型的标识信息,方便调试"""return {"model_path": model.config.name_or_path}@propertydef _llm_type(self):"""返回模型的类型标识"""return "custom"# 使用封装的模型
local_llm = CustomLLM()# 测试生成结果
result = local_llm("你好")
print(result)手动封装chatmodels模型
from langchain.llms.base import LLM
from transformers import AutoModelForCausalLM, AutoTokenizer
import torchdevice = torch.device("cuda" if torch.cuda.is_available() else "cpu")tokenizer = AutoTokenizer.from_pretrained("./models/Qwen/Qwen2.5-0.5B-Instruct")
model = AutoModelForCausalLM.from_pretrained("./models/Qwen/Qwen2.5-0.5B-Instruct").to(device)## 手动封装chatmodels模型
class CustomChatLLM(LLM):def _call(self, prompt: str, stop: list = None) -> str:messages = [{"role": "system", "content": "You are a helpful assistant."},{"role": "user", "content": prompt}]# 使用分词器将对话历史转换为适用于模型输入的格式,并添加生成提示。text = tokenizer.apply_chat_template(messages,tokenize=False,#设为False返回字符串,True返回token idsadd_generation_prompt=True #True为在末尾添加引导AI回复的提示符如 assistant)print(text)# 将输入 prompt 转换为模型的输入格式model_inputs = tokenizer([text], return_tensors="pt").to(device)# 使用模型生成新的token序列,最大生成新的token数量为512。generated_ids = model.generate(model_inputs.input_ids,max_new_tokens=512,)# 截取生成的token序列,去除原始输入的部分。generated_ids = [output_ids[len(input_ids):] for input_ids, output_ids in zip(model_inputs.input_ids, generated_ids)]# 将生成的token序列解码回文本,并忽略特殊token。response = tokenizer.batch_decode(generated_ids, skip_special_tokens=True)[0]return response@propertydef _identifying_params(self):"""返回模型的标识信息,方便调试"""return {"model_path": model.config.name_or_path}@propertydef _llm_type(self):"""返回模型的类型标识"""return "custom"## 使用封装的模型
local_llm = CustomChatLLM()
# 测试生成结果
result = local_llm("你好")
print(result)方法3调用本地ollama大模型
from langchain_community.chat_models import ChatOllama# 聊天模型(Ollama 本地)
chat_model = ChatOllama(model="qwen2.5:0.5b", # 你本地 ollama pull 下来的模型名字
)print(chat_model.invoke("你好"))