开放获取 SuperMamba 小目标检测特征增强框架
摘要
从红外图像中准确、及时地检测包含几十个像素的小目标非常具有挑战性。与低空无人机拍摄的红外图像中的复杂背景相比,本文设计了一个框架来学习将目标与背景分离的强特征表示,但这通常会导致计算量大。在本文中,我们提出了一种用于无人机红外小目标检测的 SuperMamba(SMamba)框架,该框架执行非线性复杂数据的深度学习。我们的 SMamba 框架对多尺度目标执行高分辨率目标检测,同时兼顾检测精度和计算成本。首先,将感受野注意力卷积(RFAConv)用于骨干网络并替换常用的卷积,通过动态感受野调整多尺度特征以优化计算效率。此外,将空间注意力机制(SAM)和挤压激励(SE)添加到状态空间模型(SSM)中,以实现小目标的多尺度和多特征提取。而且,在颈部网络中,将特征增强模块(FEM)引入双向特征金字塔网络(BiFPN),可以增强小目标的局部上下文信息并提高检测效率。实验结果表明,Super Mamba 在 VEDAI 数据集上达到了超过 92% 的准确率(以 mAP@0.5 衡量),比现有的大型模型如 Yolov5、Yolov8 和 Yolov11 高出 20% 以上。PyTorch 代码可在以下网址获取:https://github.com/wolfololo/Super-Mamba-A-Framework-for-Small-Object-Detection-with-Enhanced-Detection。
关键词 小目标检测,深度学习,Super Mamba,特征提取,特征融合
引言
由于中长波段的红外图像在夜间和低光照环境下具有良好的成像性能,无人机红外图像目标检测被广泛应用于安防监控1、军事侦察2、医学成像3、环境监测4等场景。对于具有弱热辐射特性的小型红外目标,在复杂背景干扰、弱红外特征、算法复杂性和实时性方面存在许多挑战。小目标的尺寸通常小于 20 × 20 像素。根据检测目标的运动特性,红外小目标检测有两个研究领域:单帧图像和视频序列图像。本文主要研究单帧红外小目标检测问题。
最近,根据是否生成候选区域,深度学习分为单阶段和两阶段检测方法。单阶段检测方法使用前馈网络来定位和分类小目标。检测的实时效率高。典型的检测方法包括 Yolo 系列(You Only Look Once)5、SSD(Single Shot MultiBox Detector)、RetinaNet 等。两阶段检测方法需要形成候选区域,然后对候选区域进行分类并进行边界框回归。在复杂场景下,候选区域的检测精度高,但计算速度相对较慢。无人机红外图像的目标检测问题需要克服低信噪比、复杂目标运动特性、目标干扰或被云层遮挡等困难。因此,以高效和准确著称的轻量级 Yolo 系列方法在具有高实时性需求的复杂场景中被广泛采用。
Tian 等人11提出了一种融合可见光和红外图像特征的 IV-Yolo 目标检测网络,使用双分支融合结构实现无人机小目标检测。Xiao 等人12引入了新的 C2f-DCNv3 模块以增强特征提取能力,同时在颈部结构中添加 BiFPN 以实现无人机小目标的多尺度特征融合。Xue 等人13提出了一种轻量级的 FECI-RTDETR 无人机红外小目标检测算法,该算法将空间特征选择机制与尺度内特征交互模块相结合,并利用跨尺度特征融合来理解航空红外小目标的上下文语义信息。Zhang 等人14设计了 ESD-Yolov8 模型,识别红外太阳能电池的缺陷特征,并通过将 EMA 注意力机制与 C2f-EMA 模块集成来增强小缺陷的检测。Zhu 等人15结合 Yolov9 和 DeepSORT 设计了多目标跟踪(MOT)模型来跟踪和识别濒危鸟类和无人机目标。
随着深度学习的快速发展,Gu 和 Dao 等人提出了基于状态空间模型(SSM)17的深度学习 Mamba 模型16,通过设计高效的硬件感知算法,实现了线性复杂度的长序列数据处理。在小目标检测中,Yolo 模型可能存在漏检问题,而 Mamba 模型可以通过多帧图像的特征融合来增强小目标的特征,从而提高小目标的检测能力。Wang 等人18提出了 Mamba-YOLO,这是一个新颖的目标检测框架,将状态空间模型主干集成到 YOLO 架构中,为高效和有效的检测建立了新的简单基线。Wang 等人19介绍了 Mamba-YOLO-World,它结合了 YOLO-World 的开放词汇检测能力和基于 Mamba 的主干的高效序列建模,以增强从无限词汇中检测物体的性能。Malekmohammadi 等人20进行了比较分析,采用 YOLO、Vision Transformers 和新兴的 Vision Mamba 架构对前列腺癌组织病理学图像中的 Gleason 分级进行分类,以评估其诊断性能。
基于卷积层的局部特征提取和状态空间模型(SSM)的长距离依赖性,一些学者提出了用于目标检测的双分支结构21,22。将注意力机制集成到 Mamba 模型中可以动态关注关键帧和目标区域,提取全局上下文信息,并减少计算量。对 Mamba 和 Yolo 的改进已应用于医学图像诊断检测25,26和道路损伤检测27,28等领域。Yu 等人29设计了 SFFNet 和 VMamba-GIE 模块来增强红外小目标的特征。Chen 等人30设计了 MiM-ISTD 的嵌套结构,该结构由外部和内部 Mamba 模块组成,以捕获全局和局部红外图像特征,并克服计算成本和内存限制。Li 等人31提出了 HMCNet 模型,该模型采用结合状态空间模型和 CNN 的混合架构。Lu 等人32探索了状态空间模型在单帧 ISTD 任务中的有效性和效率,将视觉 Mamba 模块集成到基于轻量级 CNN 的网络中进行红外小目标分割。Zhang 等人33提出了一种编码器-解码器架构,具有像素差分 Mamba(PDMamba)和层恢复模块(LRM)。近年来,计算机视觉研究呈现出模型效率和跨领域适应性的趋势。通过引入残差通道注意力机制(RCA)34并结合半自动数据集构建技术改进 YOLO 系列架构,该研究显著增强了目标检测的领域适应性。这些技术已成功应用于多尺度场景:在宏观层面支持遥感图像分类和地震损伤评估37,在中间层面实现航空视频中的车辆检测和跟踪38,39,并在微观层面实现实时驾驶员状态监控40,展示了深度学习技术在不同空间尺度上的泛化能力。
在红外小目标检测任务中,Yolo 以其高效的实时性能和多尺度检测能力脱颖而出。同时,基于状态空间模型(SSM)的 Mamba 模型特别适合处理时间序列数据。尽管 Yolo 和 Mamba 模型取得了进展,但缺乏一个有效结合它们优势进行红外小目标检测的框架。受此启发,结合 Yolo 的实时性和 Mamba 的上下文建模能力,本文构建了一个用于复杂场景的高精度红外小目标检测系统。
本研究的贡献总结如下:
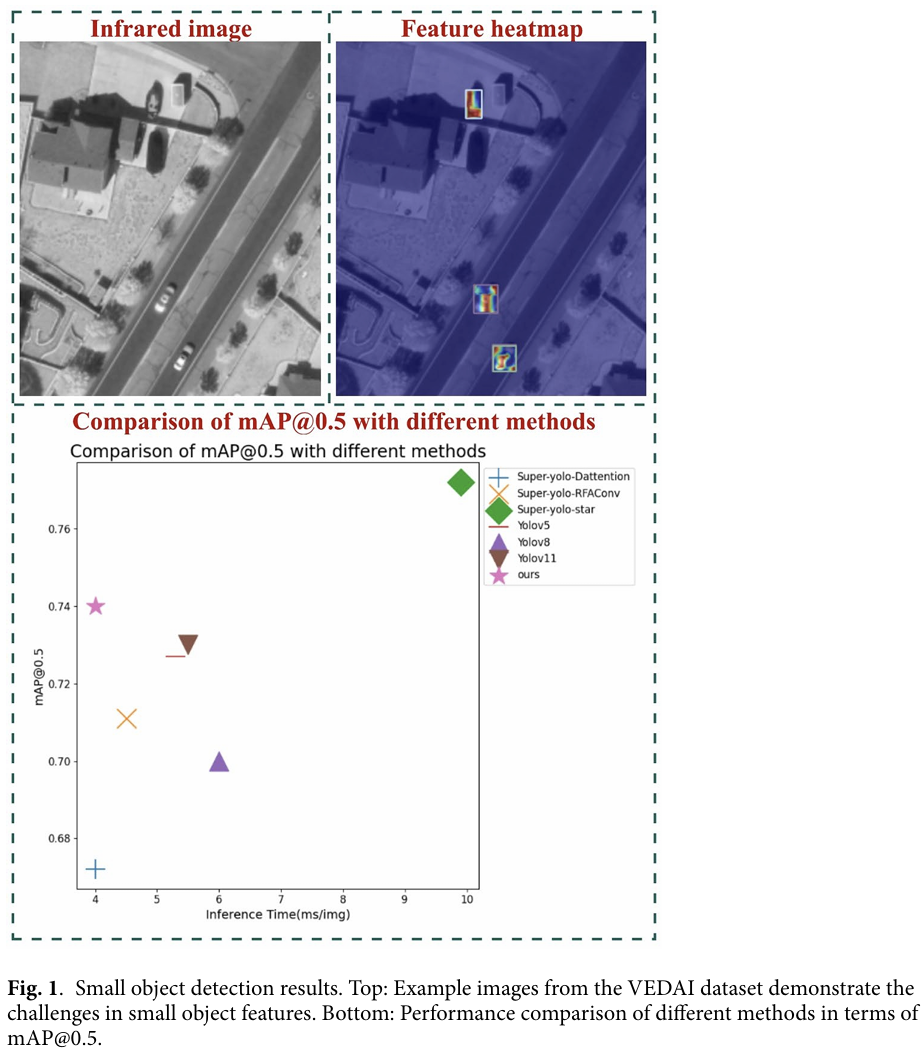
- 我们提出了 Super Mamba 模型,一个基于 SSM 和 Yolov8 的多模态融合目标检测框架。在 VEDAI 上的实验,如图 1 所示,证明我们的 Super Mamba 与现有方法相比取得了显著的性能提升。
- 我们用 RFAConv 替换标准卷积,通过多分支结构捕获多尺度特征。网络可以自适应地调整感受野,并且膨胀卷积可以减少参数数量,使其更适合小目标检测。
- 在网络骨干中,将 SAM 集成到 VSS 模块中,动态计算不同空间位置的权重,并利用 SSM 捕获图像的全局上下文信息,高效实现目标特征的提取和融合。随后,在所有目标的核心区域,SE 和 VSS 的结合形成了"局部-全局"协同特征增强效果。该框架在保持线性时间复杂度的同时,显著提高了红外小目标检测的准确性和鲁棒性。
- 我们引入了多尺度动态特征优化机制,通过 BiFPN 实现多层次特征融合,并结合 FEM 增强小目标的细节特征,有效应对复杂背景下小目标检测的挑战。
本文的其余部分组织如下:"相关工作"讨论了相关工作,包括状态空间模型和感受野注意力卷积操作。"方法"部分描述了我们用于执行此概述分析的方法。"实验结果"部分总结了实验结果和相关讨论。最后,"泛化分析"总结了发现并提出了未来的研究领域。
相关工作
状态空间模型
最近,SSM17由于其在序列长度上的线性扩展性,在深度学习领域受到了广泛关注。SSM 可以被视为一个线性时不变系统,它将输入序列 x(t)∈Rx(t) \in \mathbb{R}x(t)∈R 映射到输出响应 y(t)y(t)y(t),通过隐状态 h(t)∈RNh(t) \in \mathbb{R}^{N}h(t)∈RN,该过程可以用线性常微分方程表示:
h′(t)=Ah(t)+Bx(t)h'(t) = \mathrm{A}h(t) + \mathrm{B}x(t)h′(t)=Ah(t)+Bx(t)
y(t)=Ch(t)+Dx(t)y(t) = \mathrm{C}h(t) + \mathrm{D}x(t)y(t)=Ch(t)+Dx(t)
在公式中,A∈RN×N\mathrm{A} \in \mathbb{R}^{N \times N}A∈RN×N 是状态矩阵,B∈RN×1\mathrm{B} \in \mathbb{R}^{N \times 1}B∈RN×1、C∈R1×N\mathrm{C} \in \mathbb{R}^{1 \times N}C∈R1×N 和 D∈R1\mathrm{D} \in \mathbb{R}^{1}D∈R1 是投影矩阵。
在深度学习中,通过离散化连续常微分方程来实现 SSM 模型的数据离散化。Gu16\mathbf{Gu}^{16}Gu16 提出了 S4 模型作为连续 SSM 的离散化,使用步长参数 Δ\DeltaΔ 将连续参数 A 和 B 转换为离散参数 Aˉ\bar{A}Aˉ 和 Bˉ\bar{B}Bˉ。SSM 中最常用的离散化方法是零阶保持(ZOH),其计算公式为:
Aˉ=exp(ΔA)\bar{A} = \exp(\Delta A)Aˉ=exp(ΔA)
Bˉ=(ΔA)−1(exp(ΔA)−I)ΔB\bar{B} = (\Delta A)^{-1} (\exp(\Delta A) - \mathrm{I}) \Delta BBˉ=(ΔA)−1(exp(ΔA)−I)ΔB
在公式中,I\mathrm{I}I 是单位矩阵。因此,离散化的 SSM 方程为:
ht=Aˉht−1+Bˉxtyt=Cht\begin{aligned} h_t &= \bar{A} h_{t-1} + \bar{B} x_t \\ y_t &= \mathrm{C} h_t \end{aligned}htyt=Aˉht−1+Bˉxt=Cht
其中 hth_tht 是时间步 t 的隐状态,xtx_txt 和 yty_tyt 分别是时间步 t 的输入和输出序列。
感受野注意力卷积操作
在卷积操作期间,标准卷积核通过共享参数提取信息,导致网络对不同位置的差异信息不敏感。RFAConv 通过强调感受野滑动窗口内的不同特征并优先考虑感受野的空间特征来解决卷积中共享参数的问题41。因此,RFAConv 改善了卷积核共享参数导致的网络性能有限的问题。在骨干网络中,用 RFAConv 替换卷积操作可以增强小目标的细节特征,使网络在识别小目标时更加精确,同时计算成本相对较小。
方法
小目标检测的网络框架
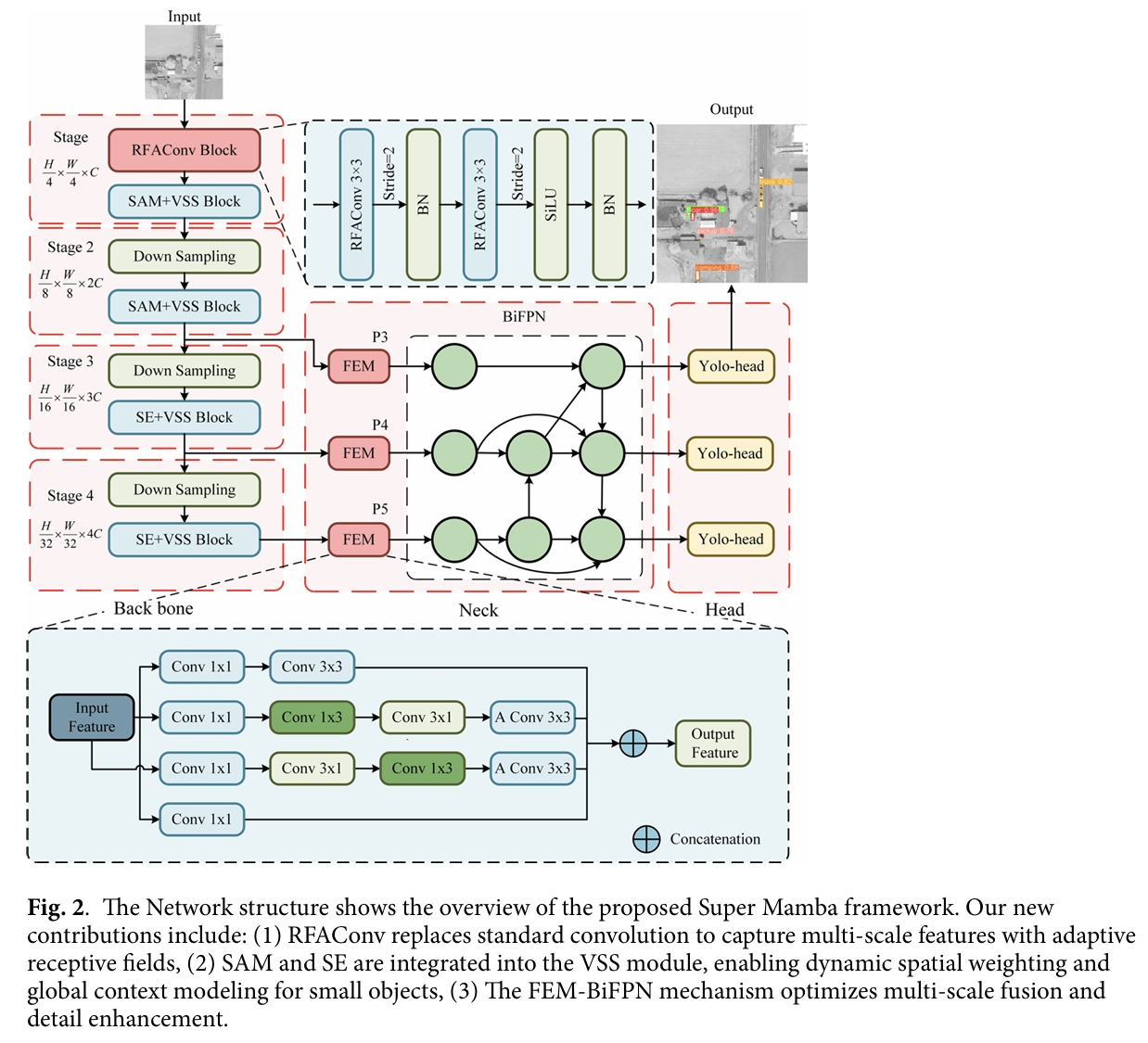
本文提出的红外小目标检测算法是一种基于 Super Mamba 框架的改进单阶段目标检测算法。它利用 Super Mamba 的轻量级结构和多尺度网络进行特征提取,并在颈部使用 FEM 模块改进 BiFPN。采用解耦头的分类和回归子网络进行红外小目标的位置回归和分类。整体网络框架如图 2 所示。Super Mamba 分为三个部分:骨干网络、颈部网络和头部。
在 Super Mamba 模型的骨干网络中,通过四个不同的阶段提取多尺度特征。在第 1 阶段和第 2 阶段,将 SAM 块集成到 VSS 块中,这有利于提取红外小目标的空间位置信息和局部特征。在第 3 阶段和第 4 阶段,将 SE 与 VSS 块结合以增强通道特征,抑制不相关的通道信息,并加强红外小目标的全局特征。在颈部网络中,将 FEM 的多分支卷积集成到自上而下和自下而上的 BiFPN 中,以融合小目标的上下文语义信息。最后,使用 Yolo 模型中的解耦头对输入图像进行分类和预测。
简单的 RFAConv 初始化模块
最近的研究表明,使用分块将图像分割成不重叠的部分作为输入是有效的。因此,我们提出了一个简单的 RFAConv 初始化模块。我们不使用非重叠块,而是使用两个内核大小为 3、步长为 2 的 RFAConv。RFAConv 不仅强调感受野内各种特征的重要性,还关注感受野的空间特征。本文设计的 RFAConv 初始化模块的实现过程如图 2 中的红色模块 RFAConv 所示。
输入图像 X∈RH×W×CX \in \mathbb{R}^{H \times W \times C}X∈RH×W×C,其中 H 是高度;W 是宽度;C 是通道数。简单的初始化模块使用两个 RFAConv 卷积层。
XS=σ(BN(RFAConv(X)))X_S = \sigma(BN(RFAConv(X)))XS=σ(BN(RFAConv(X)))
输出图像 XST=X⊙XSX_{ST} = X \odot X_SXST=X⊙XS,其中 ⊙\odot⊙ 表示逐元素乘法。
集成注意力机制的 VSS 模块
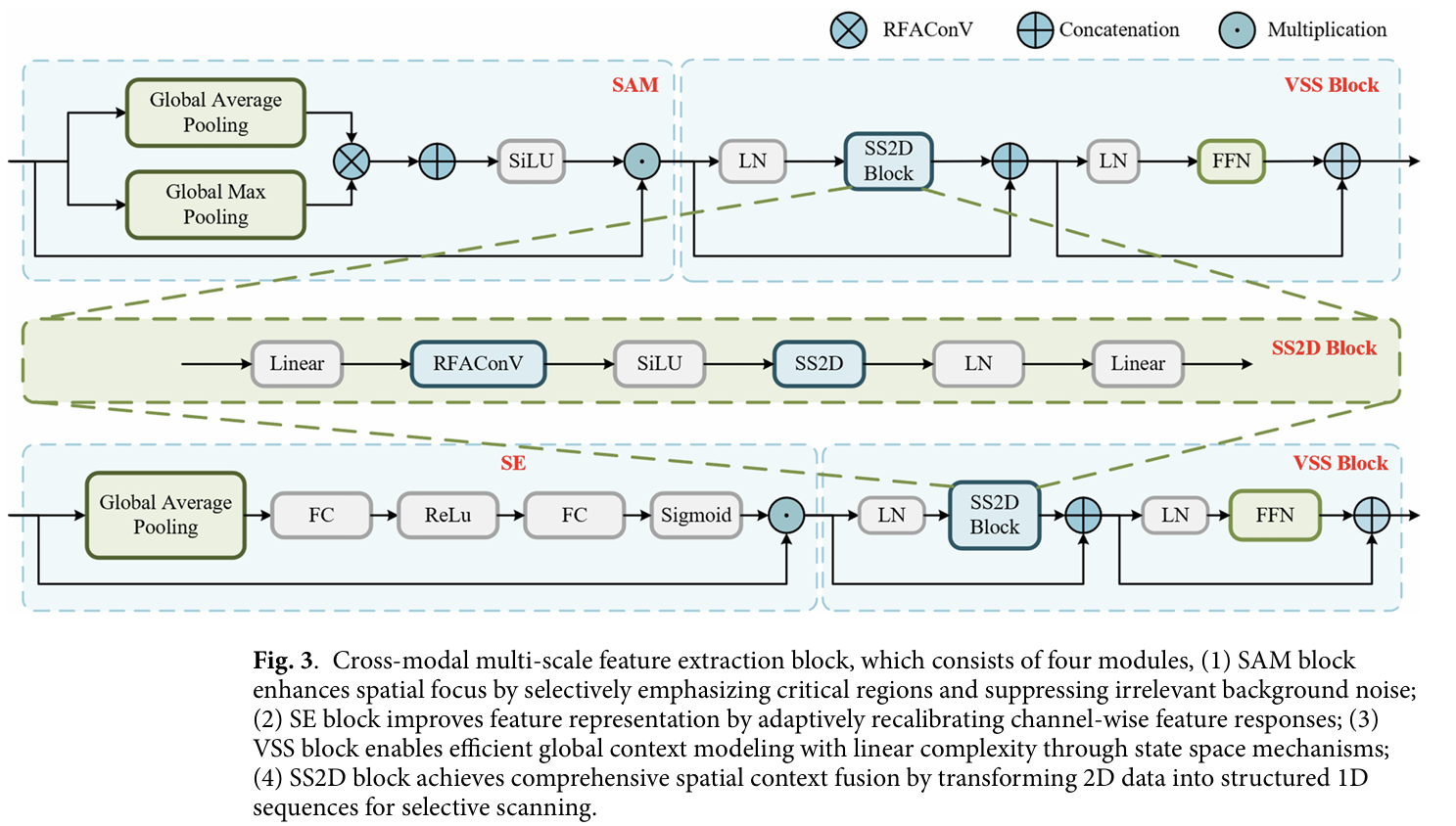
在我们的网络中,SAM 强调包含关键小目标的空间区域,而 SE 则增强通道特征可区分性以细化目标表示,将 SAM 和 SE 集成到 VSS 中可以更加直观。空间注意力机制(SAM)用于搜索全局上下文信息,与 VSS 块结合以高效编码输入图像43。这减少了冗余计算,并使模型能够关注红外图像中的小目标区域(如图 3 所示)。实现过程如下:
将全局平均池化 Xavg∈RH×W×1X_{avg} \in \mathbb{R}^{H \times W \times 1}Xavg∈RH×W×1 和全局最大池化 Xmax∈RH×W×1X_{max} \in \mathbb{R}^{H \times W \times 1}Xmax∈RH×W×1 在通道维度上连接起来,得到 Fcat∈RH×W×2F_{cat} \in \mathbb{R}^{H \times W \times 2}Fcat∈RH×W×2,即
Xavg=AvgPool(XST)X_{avg} = AvgPool(X_{ST})Xavg=AvgPool(XST)
Xmax=MaxPool(XST)X_{max} = MaxPool(X_{ST})Xmax=MaxPool(XST)
Fcat=Concat[Xavg;Xmax]F_{cat} = Concat[X_{avg}; X_{max}]Fcat=Concat[Xavg;Xmax]
对 FcatF_{cat}Fcat 使用 1×11 \times 11×1 卷积核进行卷积,得到空间注意力特征图 MsM_sMs。将 SiLU 函数应用于 MsM_sMs 进行激活,得到归一化的空间注意力权重 Ms^∈(0,1)\widehat{M_s} \in (0,1)Ms∈(0,1)。增强后的空间注意力特征图记为 FoutF_{out}Fout。
Ms=Conv(Fcat)M_s = Conv(F_{cat})Ms=Conv(Fcat)
Ms^=σ(Ms)\widehat{M_s} = \sigma(M_s)Ms=σ(Ms)
Fout=Ms^⊙XSTF_{out} = \widehat{M_s} \odot X_{ST}Fout=Ms⊙XST
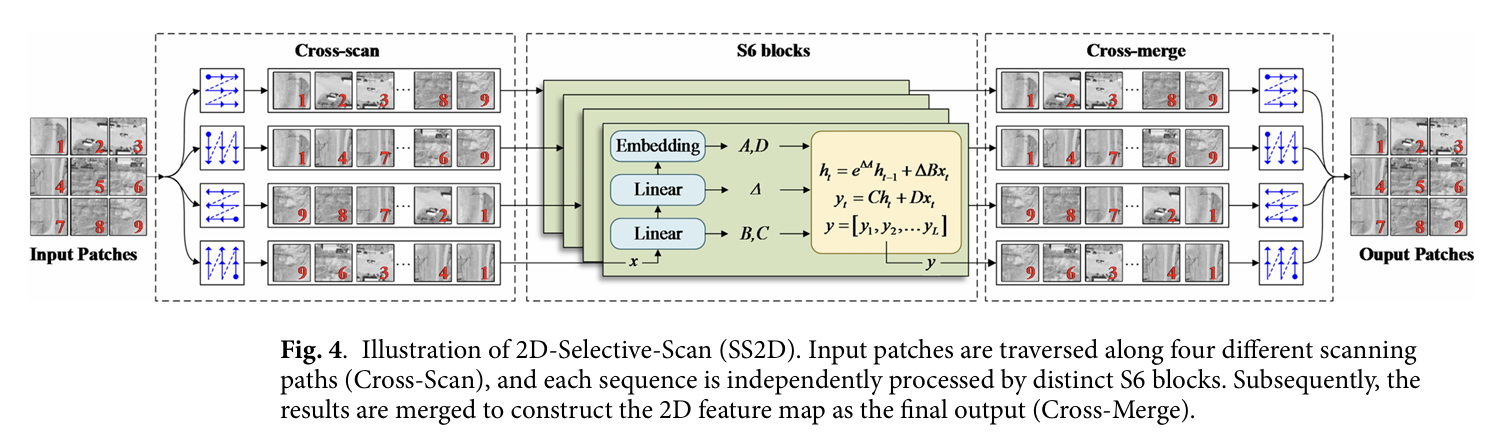
VSS 块通过对特征图执行可变空间采样来增强模型的表达能力,有效处理长图像序列的时空依赖性。在本文中,将空间特征增强图 FoutF_{out}Fout 进行层归一化为 XLNX_{LN}XLN,然后对 XLNX_{LN}XLN 进行二维交叉扫描得到 XSS2DX_{SS2D}XSS2D,将 XSS2DX_{SS2D}XSS2D 和 FoutF_{out}Fout 进行全连接。最后,在对 XcatX_{cat}Xcat 进行层归一化后执行非线性变换。通过动态调整门控权重获得输出特征图 XoutX_{out}Xout,如图 4 所示。
XLN=LN(Fout)X_{LN} = LN(F_{out})XLN=LN(Fout)
XSS2D=SS2D(XLN)X_{SS2D} = SS2D(X_{LN})XSS2D=SS2D(XLN)
Xcat=Concat(XSS2D;Fout)X_{cat} = Concat(X_{SS2D}; F_{out})Xcat=Concat(XSS2D;Fout)
Xout=Xcat⊙FFN(LN(Xcat))X_{out} = X_{cat} \odot FFN(LN(X_{cat}))Xout=Xcat⊙FFN(LN(Xcat))
在本文的深度网络中,引入了 SE 块,通过 Squeeze 和 Excitation 两个步骤自适应地重新校准特征图的通道权重,结合 VSS 块,获得红外图像的多尺度提取特征,如图 3 所示。
对特征图像 Xout∈RH×W×CX_{out} \in \mathbb{R}^{H \times W \times C}Xout∈RH×W×C 执行全局平均池化。每个通道的全局信息表示为 ZZZ,经过两个全连接层变换得到 Z1Z_1Z1,通道权重向量为 Z2Z_2Z2,输出特征图为 ToutT_{out}Tout。
Z=Squeeze(Xout)Z = Squeeze(X_{out})Z=Squeeze(Xout)
Z1=σ(W1Z+b1)Z_1 = \sigma(W_1 Z + b_1)Z1=σ(W1Z+b1)
Z2=Sigmoid(W2Z1+b2)Z_2 = Sigmoid(W_2 Z_1 + b_2)Z2=Sigmoid(W2Z1+b2)
Tout=Xout⊙Z2T_{out} = X_{out} \odot Z_2Tout=Xout⊙Z2
这里,权重为 W1∈RCr×CW_1 \in \mathbb{R}^{\frac{C}{r} \times C}W1∈RrC×C 和 W2∈RC×CrW_2 \in \mathbb{R}^{C \times \frac{C}{r}}W2∈RC×rC,偏置为 b1∈RCb_1 \in \mathbb{R}^{C}b1∈RC,b2∈RCb_2 \in \mathbb{R}^{C}b2∈RC。类似地,结合 VSS 块,获得多尺度图像的特征 EoutE_{out}Eout。
Eout=VSS(Tout)E_{out} = VSS(T_{out})Eout=VSS(Tout)
结合 FEM 的 BiFPN 特征融合模块
特征增强模块(FEM)使用多分支卷积结构,通过提取上下文语义信息来增强红外小目标特征的表达能力,从而在复杂背景下的深度学习网络中提高小目标的检测性能。在本文中,基于 SMamba 颈部中的 FEM,提出了一种多尺度双向金字塔特征融合网络(如图 2 所示)。
由于红外小目标通常难以在高层特征图像中被识别,我们在 SMamba 的颈部使用 FEM 和 BiFPN44 改进了特征金字塔网络。BiFPN 通过双向跨尺度连接和加权特征融合,有效缓解了传统 FPN 在信息传递过程中小目标细节特征的稀释和丢失,从而更充分地将包含小目标关键细节的低层特征与包含语义上下文的高层特征相融合。首先,通过多分支结构和扩张卷积增强小目标的局部上下文信息。对每个阶段提取的特征图像 Eout∈RH×W×CE_{out} \in \mathbb{R}^{H \times W \times C}Eout∈RH×W×C 执行多尺度卷积操作。从不同尺度的卷积核 K1˘,K2,⋯,Kn\breve{K_1}, K_2, \cdots, K_nK1˘,K2,⋯,Kn 获得不同尺度的特征图 Y1^,Y2,⋯,Ym\hat{Y_1}, Y_2, \cdots, Y_mY1^,Y2,⋯,Ym,且 Yi=Eout⊙Ki+bi(i=1,2,⋯,n)Y_i = E_{out} \odot K_i + b_i (i=1,2,\cdots,n)Yi=Eout⊙Ki+bi(i=1,2,⋯,n)。然后,通过引入双向特征金字塔网络(BiFPN),在自上而下(Top-Down)和自下而上(Bottom-Up)两个方向上进行特征融合。这意味着每个特征图不仅可以获得来自上层特征的信息,还可以获得来自下层特征的信息,从而增强红外小目标的特征。
实验结果
数据集
我们对提出的 Super Mamba 模型进行了全面的实验。实验使用 VEDAI 数据集,该数据集包含 1,246 张从无人机视角拍摄的具有各种背景的小图像。所有图像尺寸均为 512×512,包括八个不同的类别:汽车、皮卡、卡车、露营车等。此外,还选择了 M3FD 和 LLVIP 数据集来验证我们框架的检测结果。选择 VEDAI、M3FD 和 LLVIP 数据集旨在系统验证模型在不同光照条件和背景复杂性下的鲁棒性。VEDAI 提供多视角复杂背景;M3FD 涵盖一系列极端光照条件;LLVIP 专注于低光照挑战。这种组合确保了评估的全面性和普适性。
实现细节
我们提出的框架在 Python 中实现,并在配备 NVIDIA GeForce GTX 4070TI SUPER (16 GB) 的工作站上运行。在网络训练期间,每个图像被调整为 640 × 640。对于三个波段的输入大小,我们的 Super Mamba 的每秒浮点运算次数和参数计算成本分别为 28.4 GFLOPs 和 17.6 MB。使用 Adam 优化器,批量大小为 16,训练 300 个轮次进行网络优化。
在网络训练之前,VEDAI 数据集按 7:2:1 的比例划分为训练集、测试集和验证集。训练轮数设置为 150,初始学习率为 0.01。考虑到样本图像中存在大量小目标,并考虑检测过程中实时性和准确性之间的平衡,将样本归一化为 640 × 640。为了确保模型结果的公平性,在消融实验中没有使用预训练权重,并且所有训练过程共享一致的超参数设置。
准确性指标
本文的评估指标包括精确率(P)、召回率(R)、平均精度均值(mAP)、峰值信噪比(PSNR)和模型参数量。通常,这些指标的值越高,红外小目标检测任务的检测性能越好。P、R、AP 可以通过以下公式计算:
P=TPTP+FP;R=TPTP+FN;AP=TP+TNTP+TN+FP+FN;\begin{array}{c} {\mathrm{P} = \displaystyle\frac{\mathrm{TP}}{\mathrm{TP} + \mathrm{FP}};} \\ {} \\ {\mathrm{R} = \displaystyle\frac{\mathrm{TP}}{\mathrm{TP} + \mathrm{FN}};} \\ {} \\ {\mathrm{AP} = \displaystyle\frac{\mathrm{TP} + \mathrm{TN}}{\mathrm{TP} + \mathrm{TN} + \mathrm{FP} + \mathrm{FN}};} \end{array}P=TP+FPTP;R=TP+FNTP;AP=TP+TN+FP+FNTP+TN;
其中,真正例(TP)和真负例(TN)表示正确预测,假正例(FP)和假负例(FN)表示错误结果。精确率和召回率分别与误检误差和漏检误差相关。mAP 是通过对所有类别的 AP 值取平均得到的综合指标,它使用积分方法计算所有类别的精确率-召回率曲线与坐标轴围成的面积。因此,mAP 可以计算为:
mAP=∑n=1Num(classes)AP(n)TP+TN+FP+FN.\mathrm{mAP} = \frac{\sum_{n=1}^{Num(classes)} \mathrm{AP}(n)}{\mathrm{TP} + \mathrm{TN} + \mathrm{FP} + \mathrm{FN}}.mAP=TP+TN+FP+FN∑n=1Num(classes)AP(n).
消融研究
如表 1 所示,传统 Mamba 模型的准确率为 71.4%,平均精度值为 70%。在骨干网络中添加 RFAConv 模块后,模型的准确率提高了 2.6 个百分点,平均精度提高了 2.2%。这表明在感受野空间中使用注意力机制只需很小的计算成本即可优化共享卷积参数,从而提高模型性能。当单独引入 SAM 模块时,平均精度提高了 4.7%,这表明添加空间注意力机制可以抑制背景干扰,使网络更关注小目标所在的局部区域。单独添加 SE 通道注意力机制对小目标检测的准确率几乎没有变化,但显著降低了计算成本。当单独激活 FEM 模块时,改进后的模型可以有效整合来自不同感受野的特征,同时保留和增强小目标的细节,平均精度提高了 6.9%,召回率提高了 2.5%。如果仅在 Mamba 模型中添加单个 RFAConv、SAM、SE、FEM 模块进行小目标检测,mAP@0.95 的值仅为 40% 左右,因为更严格的 IoU 阈值会惩罚小目标检测,所以 mAP@0.95 较低。
当所有四个模块同时添加到网络的骨干和颈部时,本文提出的 Super Mamba 模型在准确率上取得了显著提高,mAP@0.5 提高了 22.3%,达到 92.3% 的检测准确率,mAP@0.95 也达到了 77.8%。这些表明我们提出的模型能够准确识别小目标并精确定位,减少了漏检和误检的情况。同时,PSNR 值达到 45.70 表明图像的细节和结构得到了很好的保留,这有助于提高小目标检测的准确性。
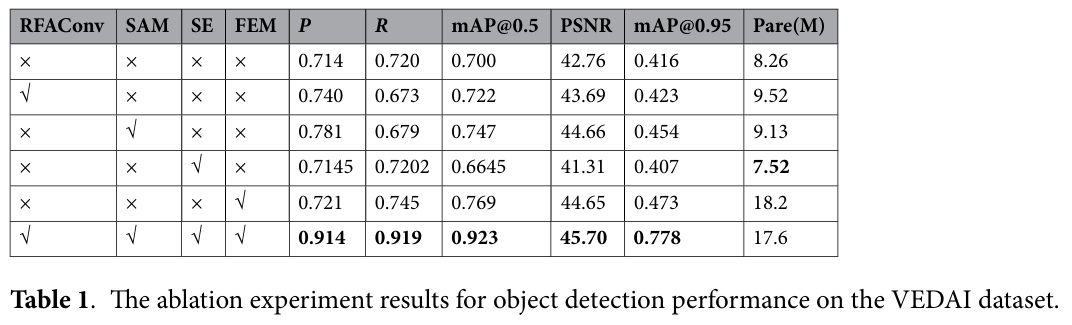
与先前方法的比较
从图 5 可以看出,在 300 轮网络训练中,Super-yolo-star46、Super-yolo-Dattention47、Super-yolo-RFAConv41、Yolov548、Yolov849 的 mAP@0.5 训练曲线均低于所提出的方法。所提出的方法在"高召回率"下仍能保持"高精度",网络性能优异。
为了更直观地表示 Super Mamba 模型在颈部 P3、P4 和 P5 阶段的多尺度特征图像,每个阶段的特征图像显示在图 6 顶部。每个阶段的小目标特征融合图像显示在图 6 顶部的第五列。实验表明,所提出的方法能够准确提取多尺度小目标。经过特征增强和双向金字塔模块后,融合效果非常令人满意。
通过在 VEDAI 数据集上比较七种方法,我们发现除了 Yolov11 和我们提出的方法外,Super-DA 方法出现了红外热特征丢失的现象,而其他四种方法则不同程度地出现了小目标红外热特征范围显著扩大的现象,如图 6 底部所示。
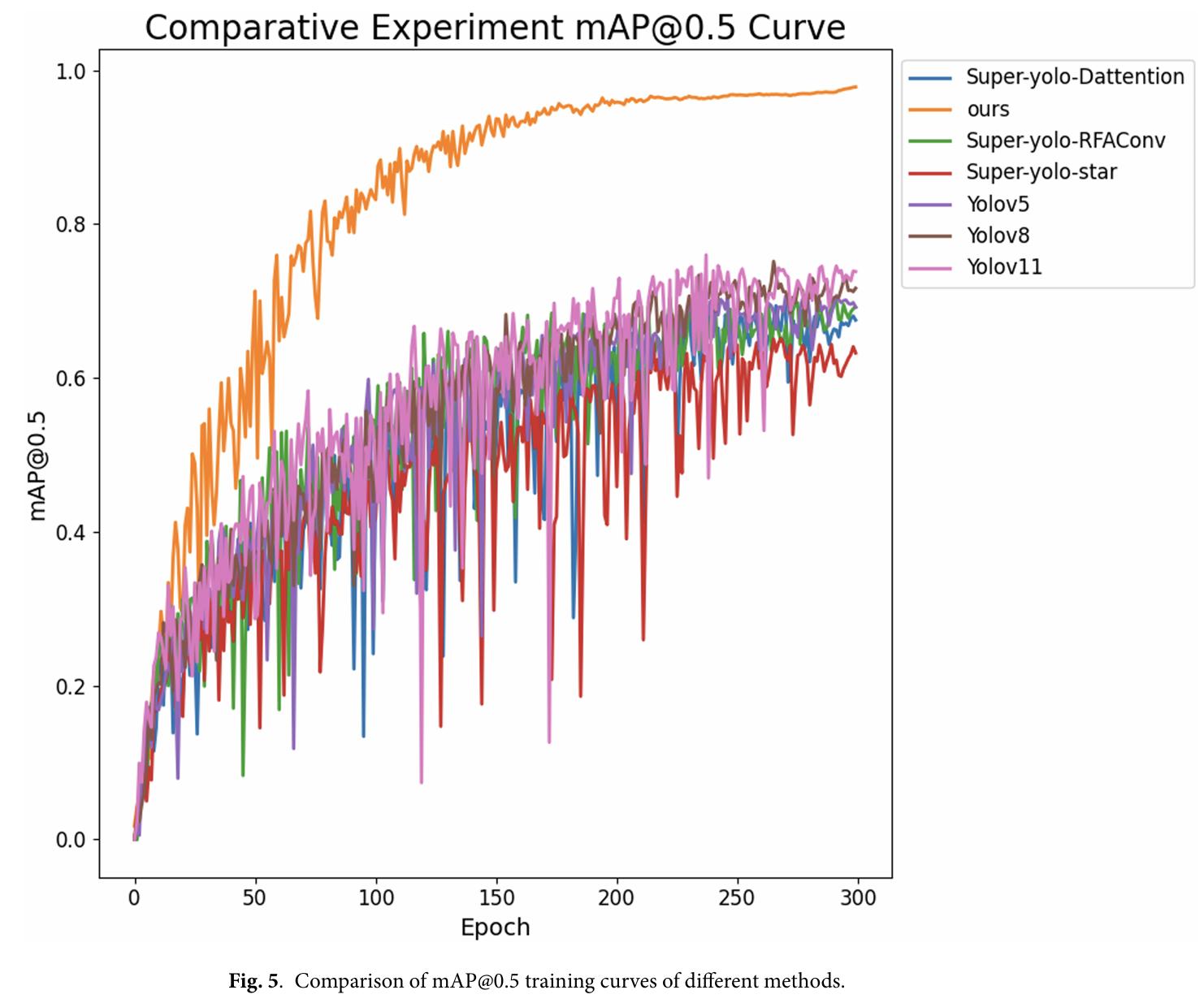
在 VEDAI 数据集中,由于复杂的背景干扰,六种方法——Super-yolo-star、Super-yolo-Dattention、Super-yolo-RFAConv、Yolov5、Yolov8 和 Yolov11——对诸如汽车或船只等小目标表现出不同程度的漏检,如图 7 最后一列蓝色圆圈内的小目标所示。此外,很明显,与其他方法相比,我们提出的方法对小目标的检测精度显著更高。另外,可以注意到,对于训练实例最多的 Car、Pickup、Tractor 和 Camping 类别,取得了优越的性能,如图 7 所示。
如表 2 所示,所提出方法的参数量均低于 Yolo 系列模型,然而其平均精度显著超过 Yolo 系列模型,达到 92.3%。Super-yolo-star 模型的准确率最低,仅为 58.1%;而 Super-yolo-RFAConv 模型的召回率最低,为 59.47%。尽管 Super-yolo-star、Super-yolo-RFAConv 和 Super-yolo-Dattention 模型的参数较少,计算速度较快,但其平均检测精度不高,未能达到 75%。本文提出的方法对小目标检测的精确率、召回率和平均精度分别为 91.4%、91.9% 和 92.3%。特别是 mAP@0.75 也达到了 89.1%,mAP@0.95 达到了 77.89%。
该深度学习网络不仅解决了复杂场景下的小目标检测问题,而且具有高鲁棒性和强泛化性能,可以有效地应用于各种小目标检测场景。

泛化分析
为了验证我们框架的泛化能力,我们使用开源数据集进行了小目标检测实验,包括用于水下目标检测的 RGBT 无人机行人数据集和 VTAUV-det 数据集。我们选择了六种常用方法进行比较:Super-yolo-star、Super-yolo-Dattention、Super-yolo-RFAConv、Yolov5、Yolov8 和 Yolov11。
(1) M3FD(多光谱、多模态和多尺度融合检测):该数据集于 2022 年发布,包括 4200 对经过校准和对齐的红外和 RGB 图像。该数据集涵盖了具有各种环境、光照、季节和天气的四种主要场景,像素变化范围广泛。大多数图像的分辨率为 1024 × 768 像素,并为六个类别提供了标注:行人、汽车、公共汽车、摩托车、路灯和卡车。数据集总大小超过 15GB。
(2) LLVIP(大规模纵向视觉-惯性行人):该数据集于 2021 年发布,专注于行人检测和跟踪,特别是在动态和复杂环境中。它涵盖了各种现实世界场景,包括城市街道、室内环境和公共交通,具有不同的光照和天气条件。LLVIP 数据集提供了丰富的数据,具有超过 100,000 张 RGB 图像和深度图像,每张图像的分辨率为 1920 × 1080 像素,总计超过 100GB。
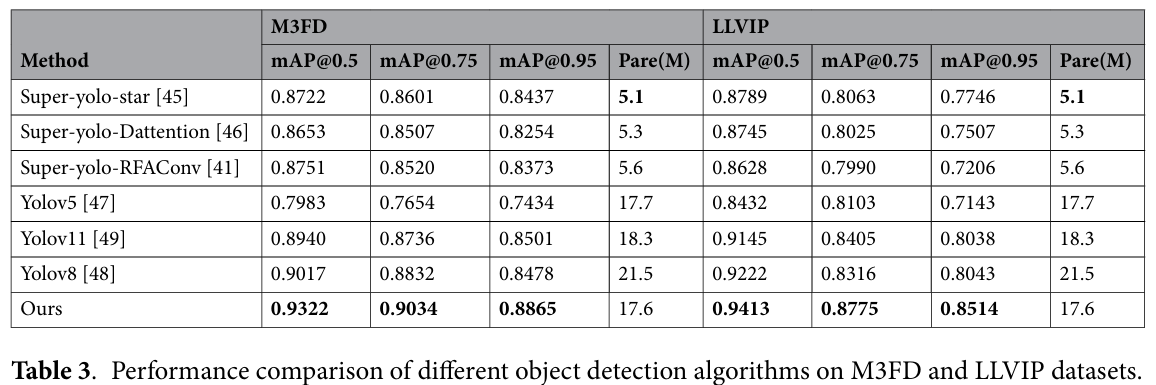
如表 3 所示,我们的 Super Mamba 取得了最佳的检测结果,在 M3FD 数据集上,mAP@0.5、mAP@0.75 和 mAP@0.95 的值分别为 93.22%、90.34%、88.65%。Super Mamba 方法高于其他检测方法。同样,实验结果表明,所提出的方法在 LLVIP 数据集上达到了 94.13%、87.75%、85.14% 的准确率。这些发现表明,尽管数据集特征不同,但模型表现出出色的泛化能力,能够适应不同的场景和任务。这一发现为进一步优化模型提供了重要证据,并为未来的研究指明了方向。
| PSNR 44.38 | 44.18 | 43.67 | 41.60 43.76 | 43.78 45.7 | ||
| 参数量(M) 5 | 5.3 50 | 17.7 18.3 | 21.5 17.6 | mAP@0.95 0.3974 | 0.4122 0.4626 | 0.4359 |
| mAP@0.75 0.4498 | 0.4349 0.4841 | 0.5082 0.5116 | 0.5012 0.891 | mAP@0.5 0.6427 | ||
| 0.6956 | 0.7002 0.7089 | 0.7451 | 0.7518 0.923 | 0.6821 R% | 0.6290 0.5947 0.5929 | 0.7257 0.6262 0.919 |
| 0.5810 P% | 0.6294 0.7199 | 0.8096 0.6437 | 0.7860 0.914 | 其他 0.4277 | 0.6244 0.5344 0.6060 | 0.6650 0.7518 0.9284 |
| 0.5788 厢式货车 | 0.6739 0.6238 | 0.7178 | 0.7229 0.9125 | 0.6517 | 0.5585 船只 | 0.4704 0.6112 0.5211 |
| 拖拉机 0.6219 | 0.7009 | 0.7973 0.6836 0.7597 | 0.7663 0.9155 | 卡车 0.6553 | ||
| 0.7518 | 0.6781 0.7637 0.7654 | 0.7908 0.9231 | 露营车 0.6569 0.7346 | 0.7803 | 0.7680 0.7572 | 0.9126 |
| 皮卡 0.7719 | 0.7750 0.7220 0.7977 | 0.8533 | 0.8281 0.9245 | 0.8703 汽车 | 0.9250 | |
| 0.8673 | 0.8899 0.8671 | 0.9105 | 0.8844 | 方法 | Super-yolo-Dattention Super-yolo-RFAConv | Super-yolo-star |
| 方法 | M3FD | LLVIP | ||||||
| mAP@0.5 | mAP@0.75 | mAP@0.95 | 参数量(M) | mAP@0.5 | mAP@0.75 | mAP@0.95 | 参数量(M) | |
| Super-yolo-star[45] | 0.8722 | 0.8601 | 0.8437 | 5.1 | 0.8789 | 0.8063 | 0.7746 | 5.1 |
| Super-yolo-Dattention [46] | 0.8653 | 0.8507 | 0.8254 | 5.3 | 0.8745 | 0.8025 | 0.7507 | 5.3 |
| Super-yolo-RFAConv [41] | 0.8751 | 0.8520 | 0.8373 | 5.6 | 0.8628 | 0.7990 | 0.7206 | 5.6 |
| Yolov5 [47] | 0.7983 | 0.7654 | 0.7434 | 17.7 | 0.8432 | 0.8103 | 0.7143 | 17.7 |
| Yolov11 [49] | 0.8940 | 0.8736 | 0.8501 | 18.3 | 0.9145 | 0.8405 | 0.8038 | 18.3 |
| Yolov8 [48] | 0.9017 | 0.8832 | 0.8478 | 21.5 | 0.9222 | 0.8316 | 0.8043 | 21.5 |
| Ours | 0.9322 | 0.9034 | 0.8865 | 17.6 | 0.9413 | 0.8775 | 0.8514 | 17.6 |
结论
本文改进了 Mamba 算法,提出了一种多尺度融合的 Super Mamba 小目标检测算法。首先,将感受野注意力卷积 RFAConv 集成到骨干网络中,替代常用的 Conv,有效提取感受野的空间特征,缓解共享卷积参数的问题,增强网络性能;其次,在特征增强的 Mamba 模型中添加空间注意力机制和通道注意力机制,实现小目标的多尺度和多特征提取;在颈部使用 BiFPN 进行多层次特征融合时,引入 FEM 块可以增强小目标的局部上下文信息。在三个数据集上的实验结果表明,与其他主流算法相比,改进后的模型在 mAP@0.5 上达到了 92.3%、93.2%、94.1%,满足小目标实时检测的要求。
本文当前检测的小目标像素大约在 20×20 左右。如何将该方法扩展到涉及 10×10 以下的超小目标像素的任务是一个需要进一步研究的课题。在未来的工作中,我们计划系统评估在可见光和红外光谱的多模态复杂场景中的性能,使用图神经网络优化深度学习网络,并在训练期间利用更少的标记数据来进一步增强模型的泛化能力,旨在在地面或水下等挑战性环境中成功应用。
所提出模型的 PyTorch 代码实现已在 GitHub 上公开可用:https://github.com/wolfololo/Super-Mamba-A-Framework-for-Small-Object-Detection-with-Enhanced-Detection。本研究期间分析的数据集可从以下来源公开获取:(1) VEDAI:航空图像中的车辆检测数据集可在以下网址获取:https://pan.baidu.com/s/19ktRRUcYXYcvdvc3sk3ygQ?pwd=j227。(2) M3FD:多光谱多模态目标检测基准可在 OpenDataLab 上获取:https://pan.baidu.com/s/1xUZsXzgjp0Q2GcLLcDDOKw?pwd=j227。(3) LLVIP:低光可见光-红外配对数据集可在 GitHub 上获取:https://github.com/bupt-ai-cz/LLVIP。这些数据集包含用于小目标检测的各种图像集,涵盖不同场景中的车辆和行人,并用于模型训练、验证和评估。所有相关数据和代码均无限制提供,以确保本研究的完全可重复性。