爬虫的基础知识
一、初识爬虫
1.1 百度首页的原始 HTML 源代码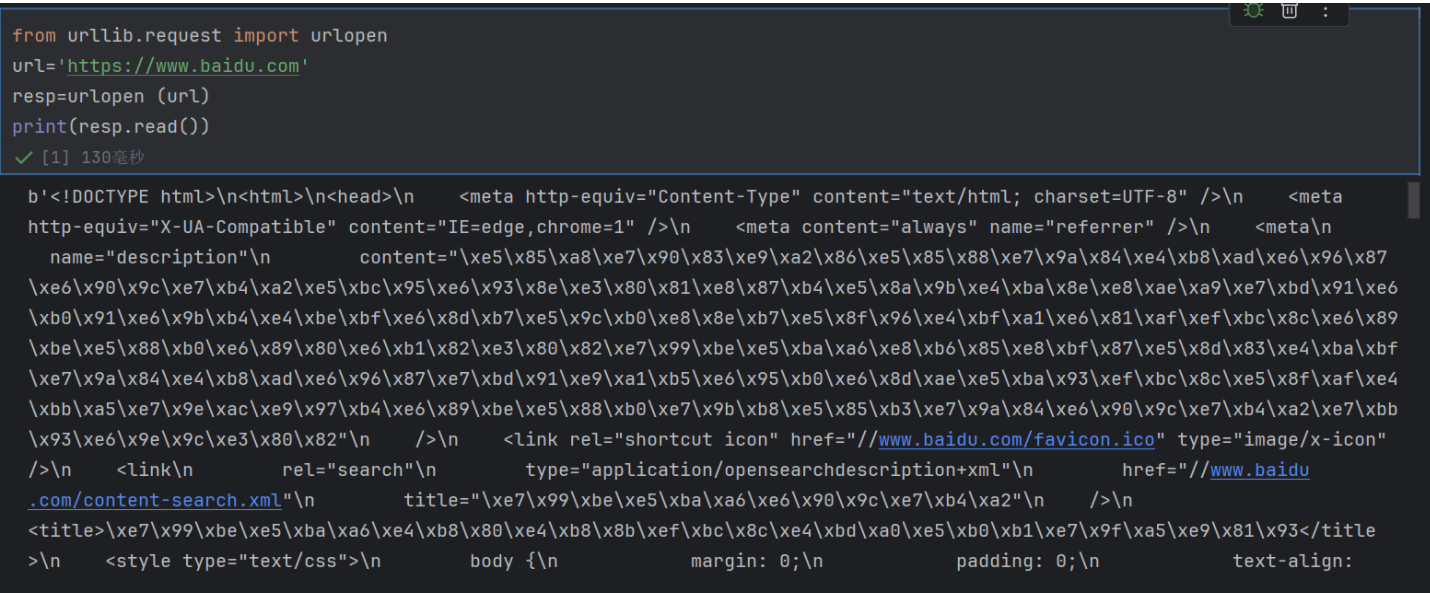
-
先看最外层:
b''的含义
输出开头的 b 表示这是一个 bytes 类型(字节流) 的数据。网络传输中,数据是以字节(bytes)形式传递的,urllib.request.urlopen().read() 返回的就是原始字节流,所以会带 b 前缀。
-
内容本质:百度首页的 HTML 代码
字节流里的内容(去掉 b 和引号后)是百度首页的 HTML 源代码,包含网页的结构和内容,核心元素包括:
-
<!DOCTYPE html>:声明这是 HTML5 文档; -
<html><head>...</head><body>...</body></html>:HTML 的基本结构(头部 + 主体); -
<meta ...>:元数据标签,比如指定字符编码(charset=UTF-8)、网页描述(description)等; -
<link ...>:引入外部资源,比如百度的图标(favicon.ico); -
<title>...</title>:网页标题(这里是 “百度一下,你就知道” 的字节编码形式); -
<style>:内嵌的 CSS 样式,控制网页的布局和外观(比如body { margin: 0; padding: 0; }是清除默认边距)。
-
乱码样的字符:中文的 UTF-8 字节编码
你会看到很多类似 \xe7\x99\xbe\xe5\xba\xa6 的序列,这是 中文被 UTF-8 编码后的字节表示。例如:\xe7\x99\xbe\xe5\xba\xa6 对应的中文是 “百度”,\xe7\x99\xbe\xe5\xba\xa6\xe4\xb8\x80\xe4\xb8\x8b 对应的是 “百度一下”。
百度首页的完整 HTML 源代码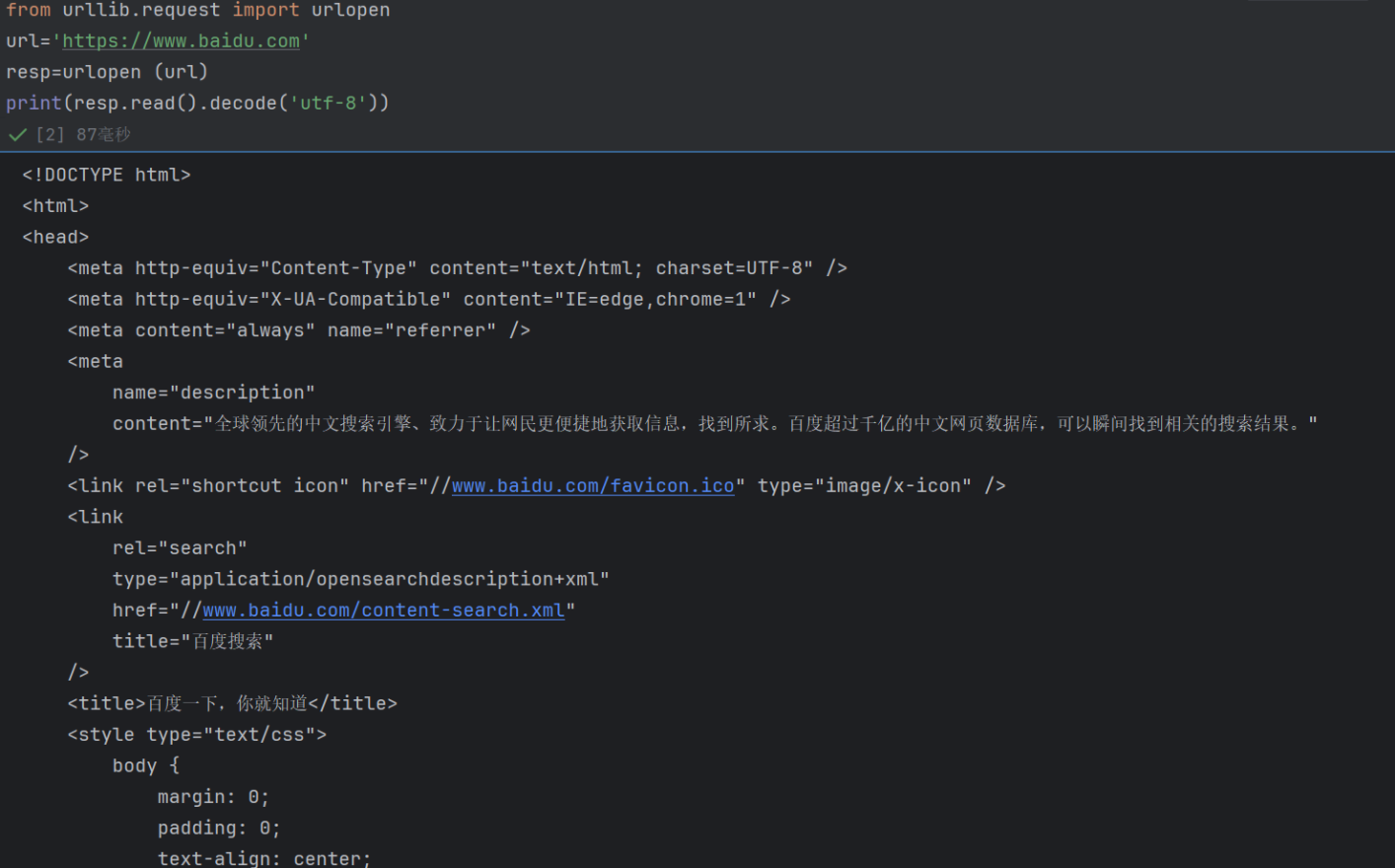
这个结果说明:
-
你的
urllib.request请求完全成功—— 不仅拿到了百度的响应数据,还通过decode('utf-8')正确解码了中文,避免了乱码。 -
现在你已经获取了百度首页的原始 HTML “原材料”,接下来可以用解析库(如BeautifulSoup、lxml)从中提取特定信息,比如:
-
提取
<title>标签内容:“百度一下,你就知道”; -
提取
<meta name="description">的内容,分析网页定位; -
提取页面中的链接、按钮、图片等元素,实现更复杂的爬虫逻辑(如自动点击、跳转)。
-
这个运行结果是爬虫入门的 “里程碑式验证”—— 它证明你已经掌握了 “发送 HTTP 请求→获取响应→解码内容” 的核心流程。接下来的学习方向可以是:
-
学习 HTML 标签的含义,理解网页结构;
-
掌握
BeautifulSoup等解析库,从 HTML 中精准提取数据; -
尝试处理更复杂的网站(如需要登录、动态加载的页面)。
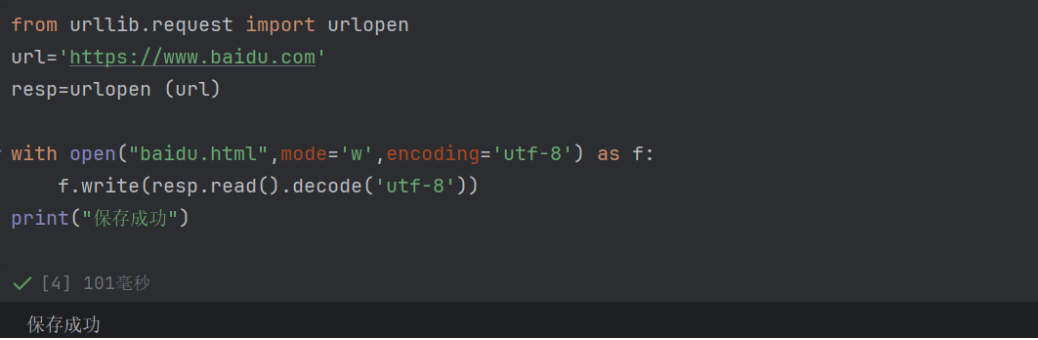
with open("baidu.html", mode='w', encoding='utf-8') as f:f.write(resp.read().decode('utf-8'))
-
with open(...) as f:以 写入模式(mode='w') 打开文件baidu.html,并指定编码为utf-8(确保中文等字符正常保存)。with语句会自动管理文件的打开 / 关闭,避免资源泄漏。 -
resp.read():读取响应对象中的原始字节数据(网页的二进制内容)。 -
.decode('utf-8'):将字节数据解码为 UTF-8 编码的字符串(因为百度网页的编码是 UTF-8)。 -
f.write(...):将解码后的 HTML 字符串写入到baidu.html文件中。

-
关于 “页面前端源代码”
这段代码读取的就是百度首页的前端源代码,包括 HTML 结构、CSS 样式、JavaScript 脚本等浏览器渲染页面所需的 “原始素材”。
换句话说,服务器把这些代码发送给你的浏览器后,浏览器才能把百度首页 “画” 出来 —— 爬虫在这里做的就是直接把这些 “原始素材” 下载到了本地。
-
关于 “交互功能缺失”
本地打开 baidu.html 后,只有静态内容,没有任何交互功能。原因很简单:
-
网页的交互(比如点击搜索、跳转链接、登录等)依赖两部分支撑:
-
一是 JavaScript 脚本的运行(需要浏览器的 JS 引擎和完整的运行环境);
-
二是 与后端服务器的通信(比如搜索时要向百度的服务器发送请求,获取结果)。
-
-
但本地保存的
baidu.html只是一个 “静态文件”,既没有和百度服务器的连接,也无法在本地完整运行所有 JavaScript 逻辑 —— 所以像 “点击搜索出结果”“登录账号” 这些交互操作,在本地文件里是无法实现的。
举个直观的例子:你在本地打开的 baidu.html 里点击搜索框输入内容并提交,不会有任何反应;但在线访问百度官网时,点击搜索就能正常获取结果 —— 这就是 “静态文件” 和 “在线网页” 在交互功能上的核心区别。
遇到的问题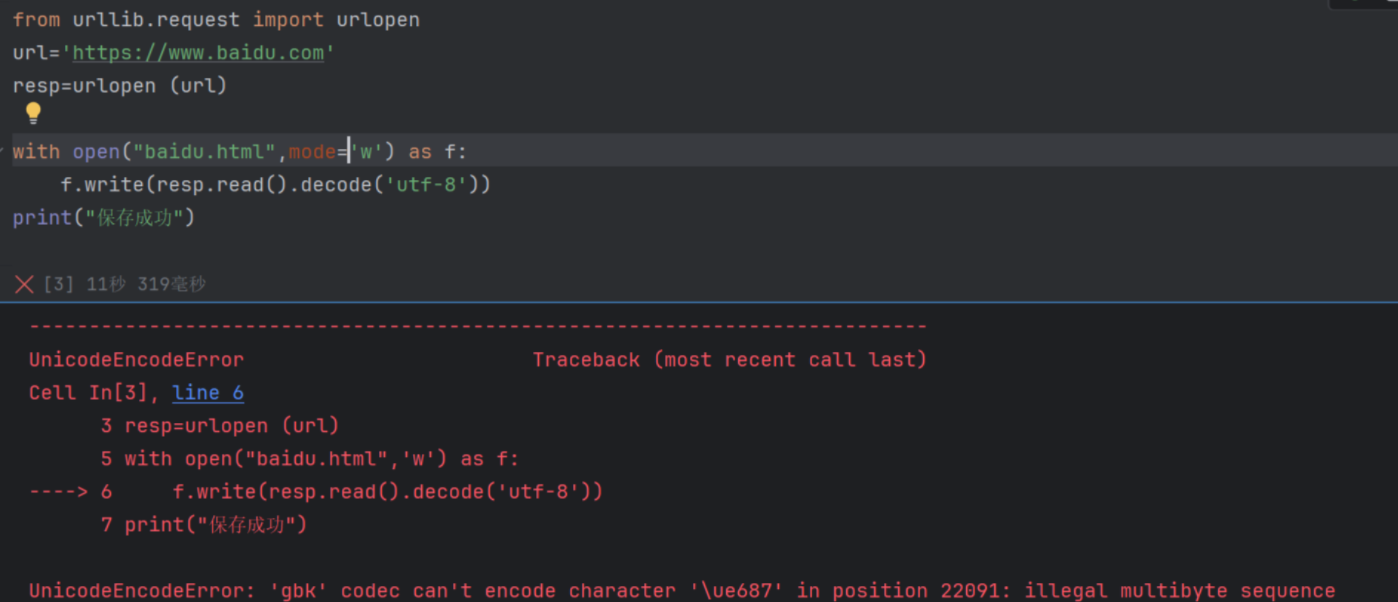
encoding='utf-8'解析:Windows 系统下 Python 默认使用gbk编码来写入字符串,所以需明确指定编码为 utf-8(与 HTML 内容的编码一致),就能避免这个问题
1.2 web请求过程剖析
服务器渲染和客户端渲染
服务器渲染:在服务器那边直接把数据和html整合到一起,同一返回给浏览器。在页面源代码中能看到数据。
定义:服务器在接收到客户端请求后,直接生成包含所有内容的完整 HTML 页面,然后将这个 HTML 发送给客户端。客户端(浏览器)收到后,只需直接展示,无需再做额外的 “渲染” 工作。
请求流程示例
-
你在浏览器输入
https://www.xxx.com并发送请求。 -
服务器接收到请求后,动态拼接数据 + 模板,生成完整的 HTML(比如把用户信息、文章列表等数据嵌入到 HTML 结构中)。
-
服务器把这个完整的 HTML返回给浏览器。
-
浏览器直接解析并展示这个 HTML,用户就能看到完整页面。
你爬取百度首页时,服务器返回的初始 HTML就包含了大量静态内容(如页面结构、文字),这部分属于服务器渲染的结果
客户端渲染:第一次请求看不到只要一个html骨架,第二次请求拿到数据,进行数据展示,在页面源代码中看不到数据
定义:服务器只返回一个 “空壳” HTML 框架 (仅包含页面结构和 JS/CSS 的引用),页面的具体内容由客户端浏览器执行 JS 后动态生成(可能还会通过 AJAX 请求后端数据)。
请求流程示例
-
你在浏览器输入
https://www.xxx.com并发送请求。 -
服务器返回一个 “空壳” HTML(仅包含
<script src="xxx.js">这类 JS 引用)。 -
浏览器下载并执行这些 JS 文件。
-
JS 代码发起AJAX 请求,从后端获取动态数据(如用户信息、商品列表)。
-
JS 将数据动态插入到 HTML 结构中,最终渲染出完整页面。
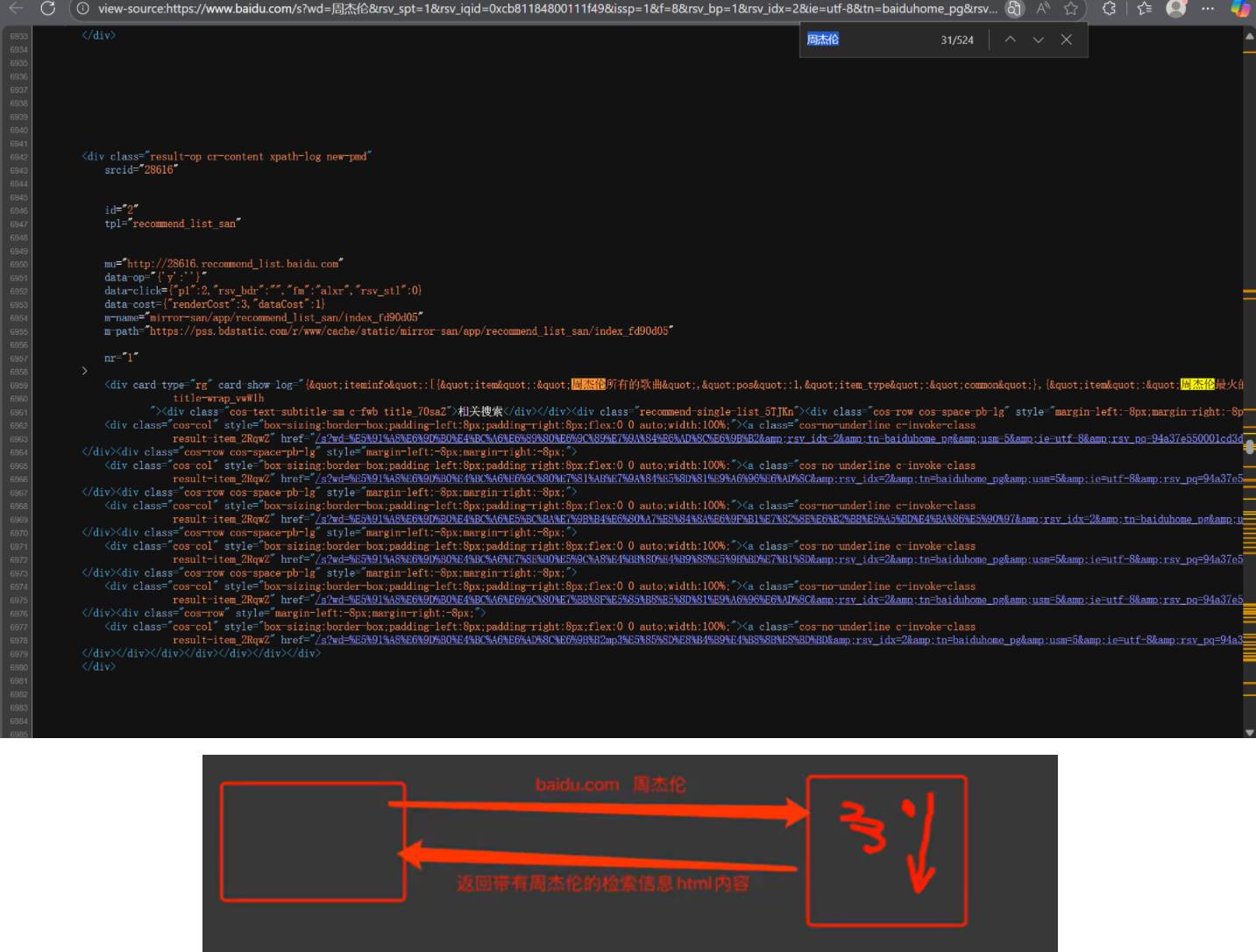
就比如豆瓣这个网站,直接在页面源代码中查找是查找不到数据的,只有一个html的框架。
客户端渲染的整体过程差不多是这样,两次请求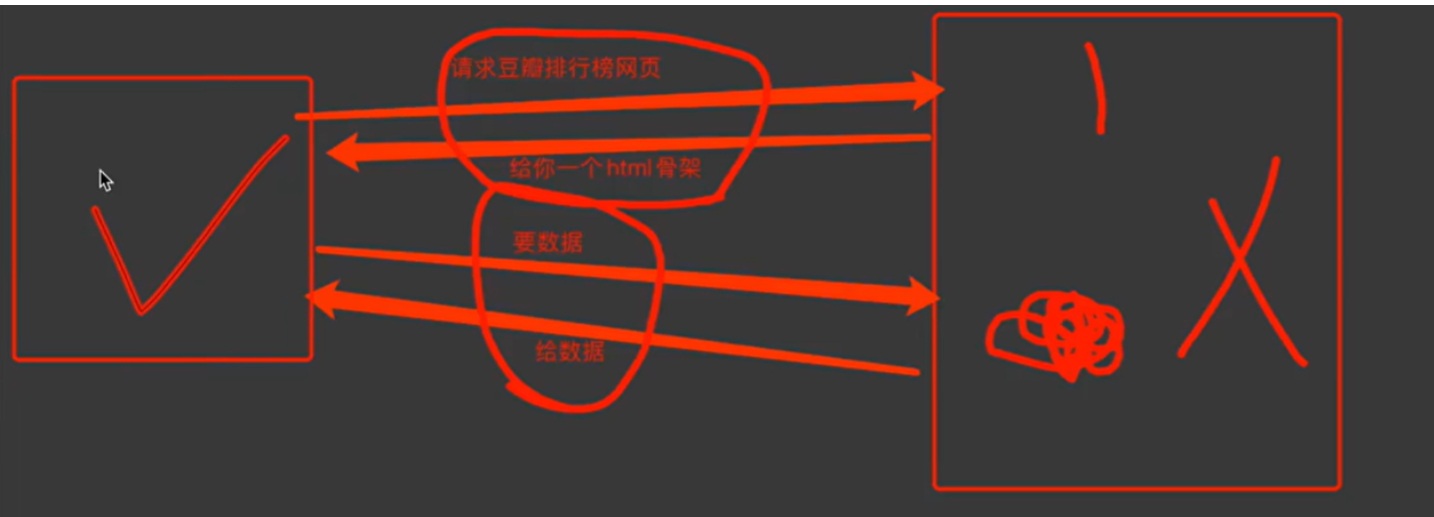
使用浏览器的抓包工具查看,发现这个 URL 是页面加载过程中发起的数据接口请求(属于客户端渲染的动态数据来源),也就是要数据这一步的关键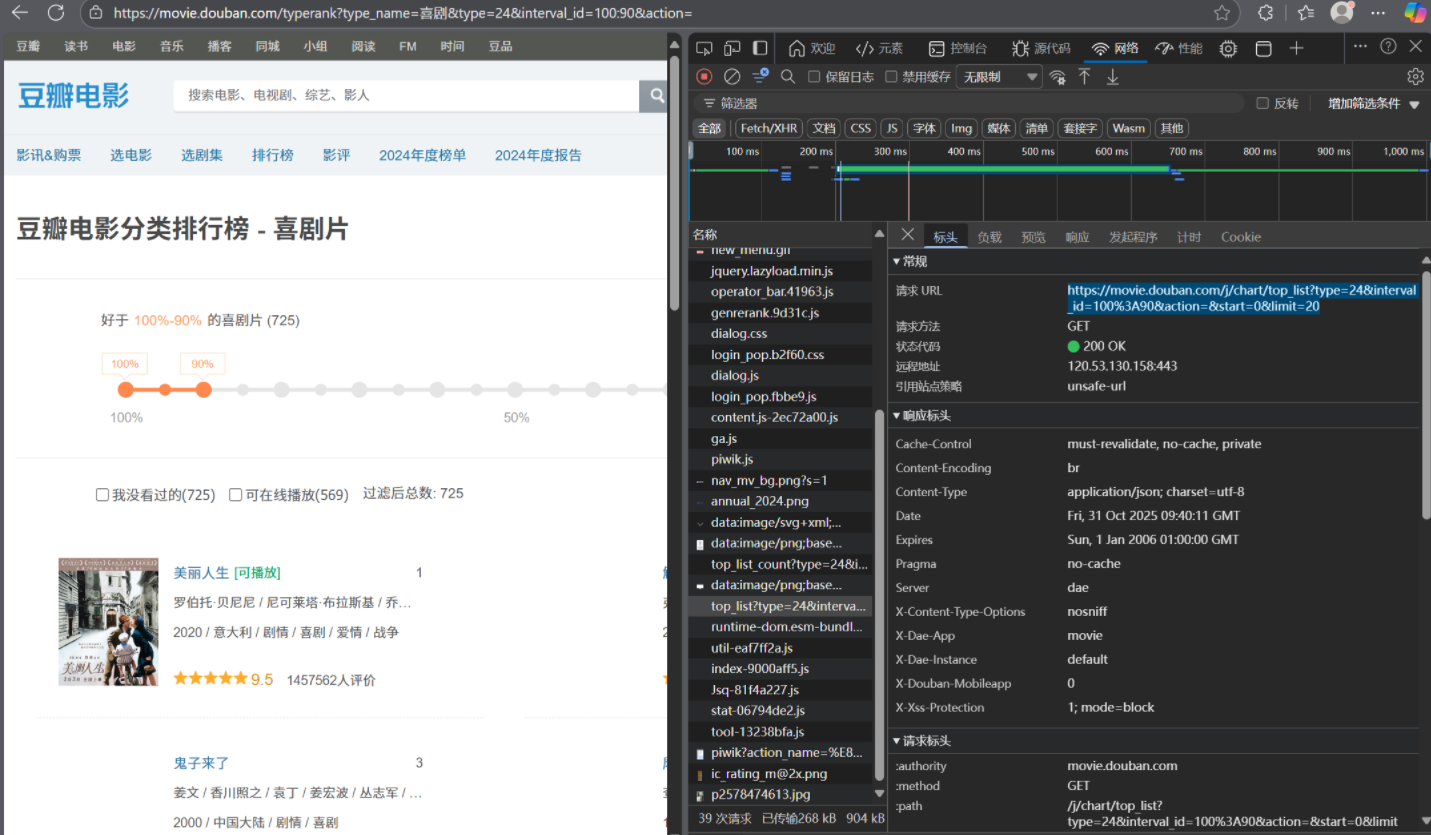
右侧 “预览” 面板中的内容,就是这个数据请求返回的原始数据格式(JSON),它和页面左侧显示的 “喜剧片排行榜” 内容完全对应。
如果想爬取这个排行榜的数据,不需要解析左侧的 HTML 页面,直接请求这个返回 JSON 的接口(即右侧网络面板中对应的 URL),就能拿到结构化数据,提取效率更高。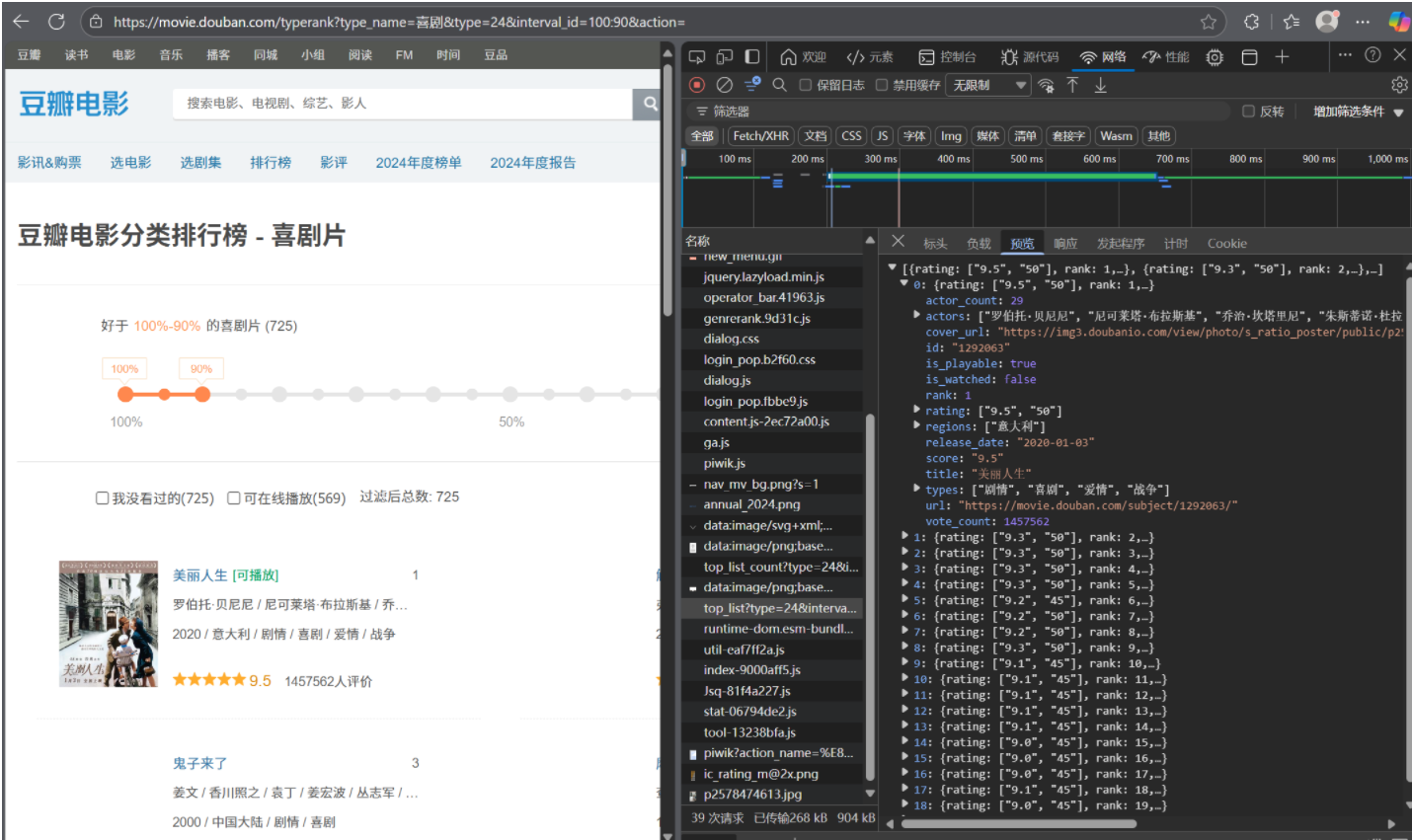
1.3 http协议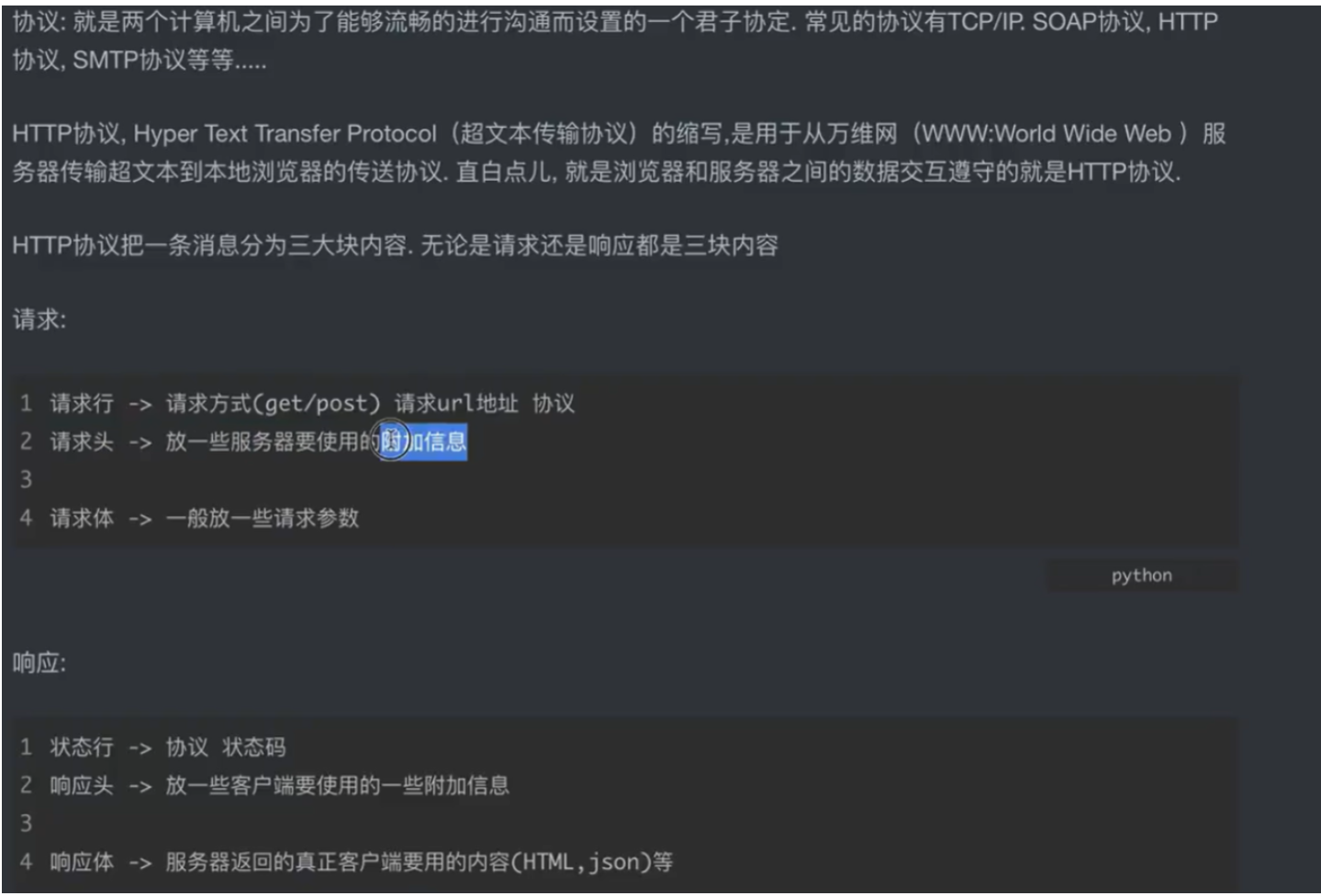
-
先理解 “协议” 的本质
协议就是 “计算机之间的沟通约定”,就像你和餐厅服务员交流得说同一种语言(比如中文),否则彼此听不懂。常见的协议比如:
-
TCP/IP:负责 “数据怎么在网络里传输”(类似餐厅里 “菜怎么从厨房传到你桌上” 的规则);
-
HTTP:负责 “浏览器和服务器怎么交换网页数据”(类似你和服务员 “怎么点菜、怎么上菜” 的规则)。
-
HTTP 协议的定位
HTTP 是 “超文本传输协议”,核心作用是“让浏览器从服务器那里拿到网页内容(超文本)”。直白说,就是浏览器和服务器之间 “聊天的话术”—— 浏览器按这个规则 “要东西”,服务器按这个规则 “给东西”。
-
HTTP 请求:“你向服务器‘点菜’的过程”
把请求拆成 3 部分,类比 “你在餐厅点菜”:
-
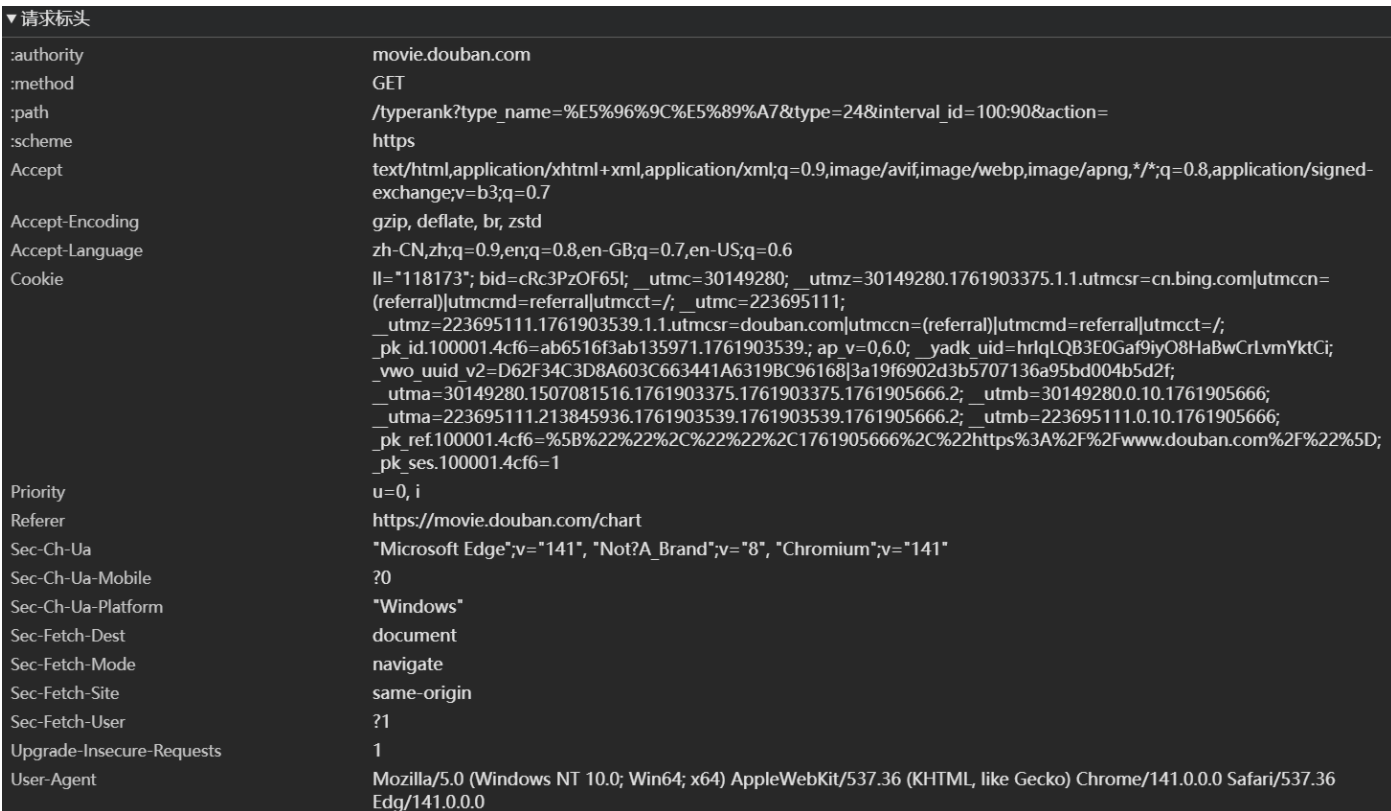
请求行:“我要什么菜” → 对应请求方式(GET/POST)+ 请求URL + 协议版本。比如GET /index.html HTTP/1.1意思是:“我要用 GET 方法,要根路径下的 index.html 页面,用 HTTP/1.1 版本的规则”。
-
请求头:“点菜的附加要求” → 放服务器需要的额外信息。比如User-Agent: Chrome(告诉服务器 “我是 Chrome 浏览器”)、Accept: text/html(告诉服务器 “我要 HTML 格式的内容”)。
-
请求体:“点菜的具体参数” → 一般放 POST 请求的表单数据(比如你点外卖时填的 “地址、手机号”)。
-
HTTP 响应:“服务器给你‘上菜’的过程”
把响应拆成 3 部分,类比 “餐厅给你上菜”:
-
状态行:“这道菜的状态” → 对应协议版本 + 状态码。比如 HTTP/1.1 200 OK意思是:“按 HTTP/1.1 规则,请求成功,马上给你内容”;如果是HTTP/1.1 404 Not Found,就是 “你要的页面不存在”。
-
响应头:“菜的附加说明” → 放客户端(浏览器)需要的额外信息。比如Content-Type: text/html; charset=utf-8(告诉浏览器 “内容是 HTML,编码是 UTF-8”)、Content-Length: 1024(告诉浏览器 “内容有 1024 字节”)。
-
响应体:“真正的菜” → 服务器返回的实际内容(比如网页的 HTML 代码、JSON 数据,就是你之前爬虫拿到的百度首页源代码)。
总结
HTTP 的请求和响应,就像 “点菜→上菜” 的完整流程:
-
你(浏览器)按 “请求结构” 点菜 → 服务器(后厨)按 “响应结构” 上菜 → 整个过程都遵循 HTTP 的 “话术约定”,这样双方才能高效沟通,你最终才能看到网页内容~

1.4 get和post的区别
咱们用 生活场景类比 把 GET 和 POST 的区别讲透,全程不用复杂术语,结合你之前爬取搜索、翻译的场景,一看就懂:先看核心类比:GET 是 “查东西”,POST 是 “交东西”
把 HTTP 请求想象成 “你和服务器的互动”:
-
GET 请求 = 你去「便利店查商品」:想要什么直接说(比如 “我要一瓶可乐”),需求公开,别人可能听到;
-
POST 请求 = 你去「快递站寄包裹」:要寄的东西(比如身份证、文件)装在包裹里(不公开),只给快递员看,别人看不到。
再拆 3 个最直观的区别(带爬虫场景例子)
-
数据 “藏在哪”?(最核心区别)
-
GET 请求:数据直接拼在 URL 里,像 “喊出来” 一样公开可见;
例子:你之前爬搜狗搜索
https://www.sogou.com/web?query=周杰伦
?query=周杰伦 就是 GET 的参数,直接暴露在网址里,任何人看 URL 都知道你查了 “周杰伦”。
-
POST 请求:数据藏在 “请求体” 里(相当于快递包裹),URL 里看不到;
例子:你爬百度翻译时,输入的单词dog是通过form_data={"kw": "dog"}传递的,URL 还是
https://fanyi.baidu.com/sug
看不到dog这个参数,别人只能看到你访问了翻译接口,看不到你翻译的内容。
-
适合做什么?(用途区别)
-
GET 请求:只 “查数据”,不修改、不提交
比如:搜索内容、获取网页、查看列表(像你爬百度首页、搜狗搜索结果),这些操作只是 “拿数据”,不会让服务器的内容变多或变少。
-
POST 请求:“提交数据”,会让服务器有变化(或需要隐私传输)
比如:登录(提交账号密码)、翻译(提交要翻译的单词)、注册(提交个人信息)、支付(提交订单),这些操作需要把 “私密 / 要处理的数据” 传给服务器,服务器会根据数据做处理(返回翻译结果、验证账号)。
-
数据大小和安全性?(实际使用注意)
-
GET 请求:
-
数据大小有限制(URL 长度不能太长,通常几 KB),没法传大文件(比如图片、视频);
-
安全性低(参数在 URL 里),不能传密码、身份证等隐私数据(比如你不会把密码喊出来让别人听)。
-
-
POST 请求:
-
数据大小没限制(能传大文件、长文本);
-
安全性高(参数藏在请求体),适合传隐私数据(比如你寄快递不会把身份证贴在包裹外面)。
-
最后用表格总结(一看就记牢)
| 区别点 | GET 请求(查东西) | POST 请求(交东西) |
|---|---|---|
| 数据位置 | URL 里(公开可见) | 请求体里(隐藏不可见) |
| 核心用途 | 查询数据(不修改服务器内容) | 提交数据(服务器会处理 / 存储数据) |
| 安全性 | 低(参数暴露) | 较高(参数隐藏) |
| 数据大小限制 | 有(URL 长度有限) | 无(可传大文件 / 长文本) |
| 爬虫场景例子 | 搜狗搜索、获取百度首页、豆瓣电影列表 | 百度翻译提交单词、登录账号、提交表单 |
一句话判断:该用 GET 还是 POST?
-
只要是「查数据、不提交隐私信息」,用 GET;
-
只要是「提交数据、传隐私 / 大文件、需要服务器处理」,用 POST。
结合你之前的代码:
-
爬搜狗搜索(查数据)→ GET 请求,参数拼在 URL;
-
百度翻译(提交单词让服务器处理)→ POST 请求,参数藏在请求体。
1.5 request模块入门
user-Agent请求头
这是因为搜狗的反爬机制识别出了 “非浏览器的请求行为”,从而触发了验证码验证。你的代码中用requests.get发起请求时,默认没有携带 “浏览器标识”(User-Agent),搜狗服务器检测到这个 “不像真人浏览器发出的请求”,就会返回验证码页面,要求人工验证。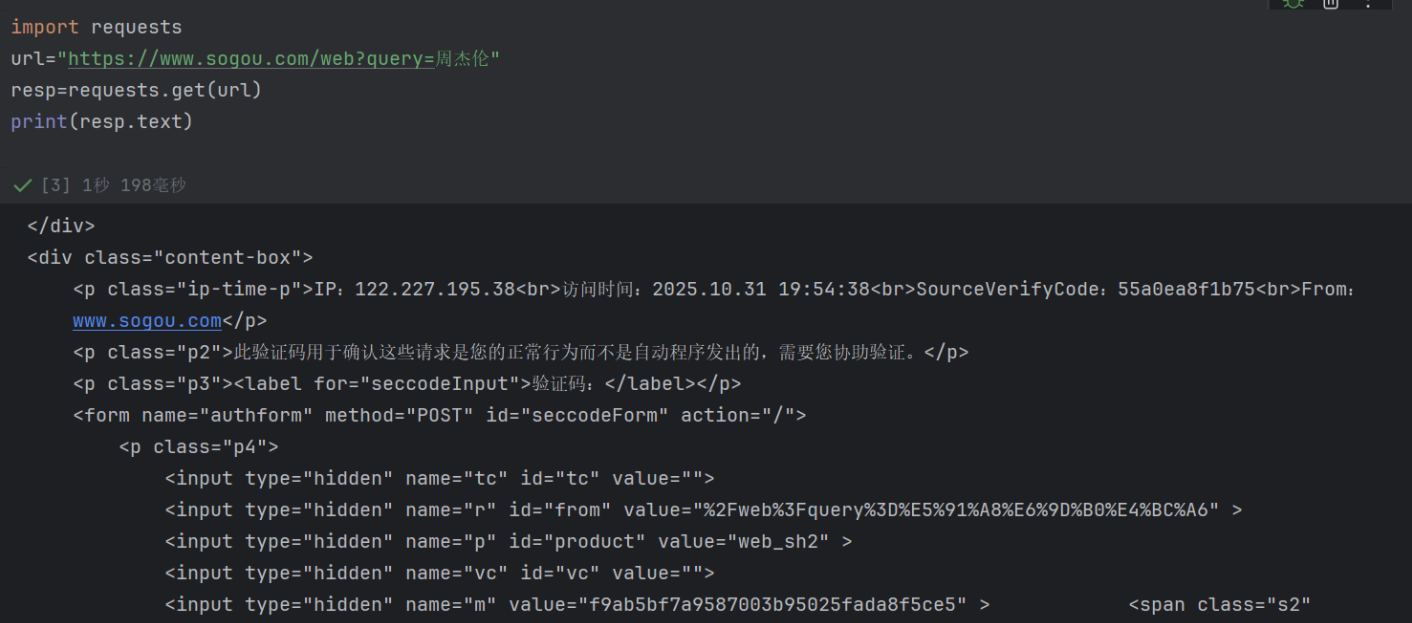
和上一次代码相比,这次新增了headers参数,其中User-Agent字段模拟了真实浏览器的身份标识(这里是 Edge 浏览器的标识)。这段代码成功绕过了搜狗的基础反爬机制,获取到了 “周杰伦” 的搜索结果页面 HTML 源代码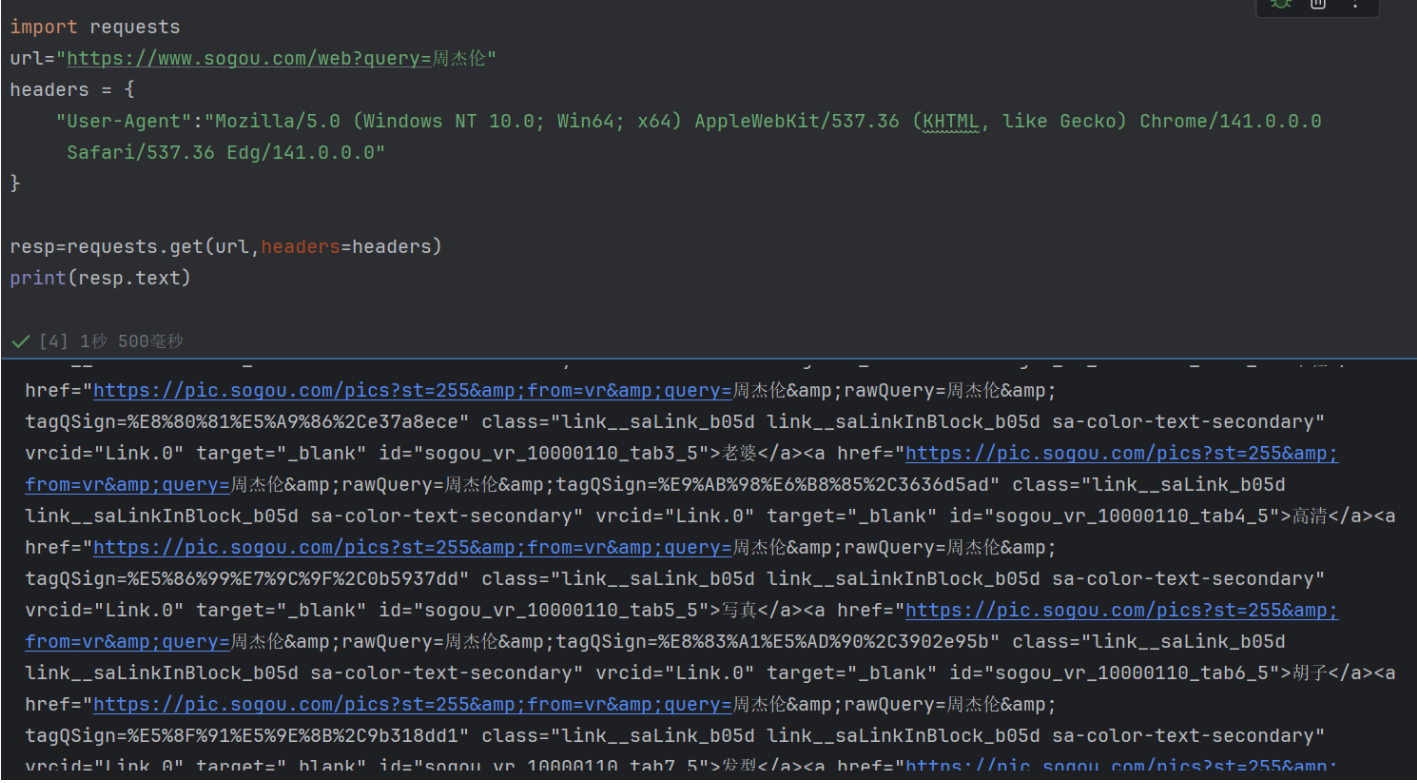
post请求
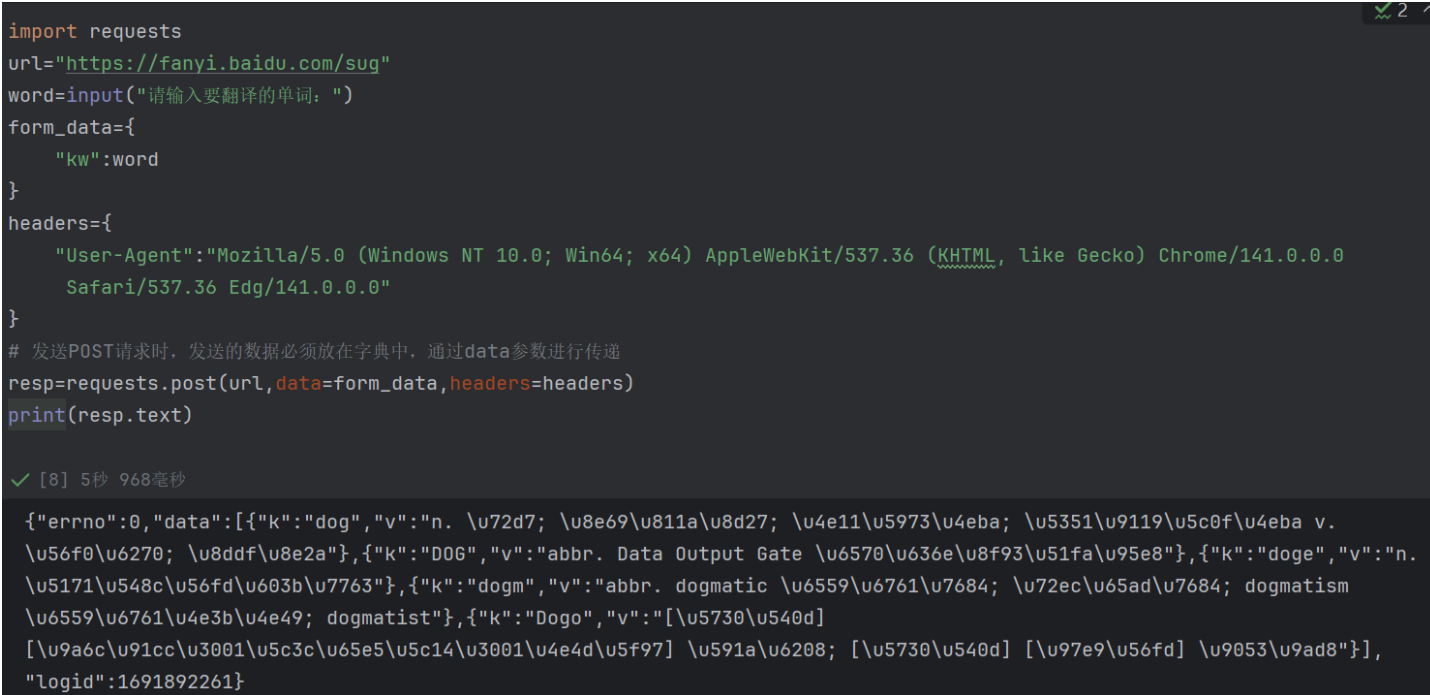
当服务器返回JSON 格式的响应时,resp.json() 会将其自动解析为 Python 的字典 / 列表,方便直接操作数据
1.6 补充:close释放资源
要理解 resp.close(),核心就一句话:手动释放请求占用的 “网络连接资源”,避免资源浪费或后续请求出问题。咱们用生活类比 + 实际场景,讲得明明白白:
1、先看生活类比:用完水龙头要关
把 resp(响应对象)想象成你家的 “水龙头”:
-
发起请求(
requests.get/post)= 打开水龙头接水(获取服务器数据); -
拿到数据(
resp.text/resp.json())= 接完水了; -
resp.close()= 关掉水龙头。
如果接完水不关掉水龙头(不调用close()),水龙头会一直 “滴漏”(占用网络连接和系统资源),时间久了可能导致:
-
家里水被浪费(系统资源被无用连接占用);
-
后续想再开水龙头(发起新请求)时,因为 “水管被占满”(连接数上限),接不到水(请求失败)。
2、再讲技术层面:resp 到底占用了什么?
当你发起请求后,resp 对应的是 “客户端和服务器之间的 TCP 网络连接” + 系统分配的内存资源:
-
这个连接是 “双向通道”,服务器和客户端通过它传输数据;
-
数据传输完成后,这个通道不会自动消失(需要手动或自动关闭);
-
如果不关闭,这个 “空通道” 会一直占用系统的 “连接池”(系统能同时维持的连接数是有限的)。
3、为什么有时候 “不加也能用”?
你可能发现:之前有些代码没写 resp.close(),也能正常运行。这是因为:
-
requests库有 “自动关闭机制”:当你把resp的数据(resp.text/resp.json())读完,或者程序结束时,会自动关闭连接; -
但自动关闭有 “延迟”(不是即时释放),如果短时间内发起大量请求(比如爬 1000 页数据),可能会因为 “未关闭的连接堆积”,导致服务器拒绝新请求(提示 “连接数过多”)。
4、resp.close() 的实际作用场景
-
爬大量数据时:循环请求 100 + 次,手动调用
close()能即时释放连接,避免被服务器限制; -
处理大文件时:比如下载视频、大图片(用
resp.content),数据没读完就想中断,close()能强制关闭连接,节省资源; -
兼容旧版本 / 特殊环境:某些旧 Python 环境或服务器配置下,自动关闭机制可能失效,手动
close()是 “兜底方案”。
更推荐的 “自动关闭” 写法(替代手动close())
虽然 resp.close() 有用,但手动写容易忘。requests 支持用 with 语句自动管理连接,更简洁安全:
import requests
url = "https://movie.douban.com/j/chart/top_list"
param = {"type":24, "interval_id":"100:90", "start":0, "limit":20}
headers = {"User-Agent": "你的UA"}
# with语句会自动在数据处理完后关闭resp,无需手动写close()
with requests.get(url, params=param, headers=headers) as resp:data = resp.json()print(data)
resp.close() 的核心作用是 “及时归还借用的网络 / 系统资源”,就像用完东西要归位一样:
-
简单场景(单次请求):不加也能跑,但加了更规范;
-
复杂场景(多请求、大文件):必须加(或用
with自动关),避免资源泄漏和请求失败。
这也是编程里 “资源管理” 的基本常识 ——“谁申请,谁释放”,不让无用资源一直占用系统~
二、数据解析与提取
-
re 解析(正则表达式解析):用 “文本匹配规则” 来从 HTML 中捞取数据。
-
特点:灵活,能处理各种文本场景;但 HTML 结构复杂时,正则容易写得 “臃肿且易错”,维护成本高。
-
-
bs4 解析(BeautifulSoup4 解析):把 HTML 转换成 “对象树”,通过标签名、类名、id等属性 “按结构找元素”。
-
特点:简单直观,适合 HTML 结构清晰的页面;但如果页面非常庞大,解析速度可能稍慢。
-
-
xpath 解析:用 “路径语言” 定位元素,比如通过
//div[@class="list"]/ul/li这种 “路径”,直接找到嵌套结构中的目标标签。-
特点:定位精准,尤其适合处理嵌套复杂的 HTML/XML;但需要学习 XPath 的语法规则。
-
2.1 正则表达式—re解析
在爬虫数据解析中,正则表达式通过一系列元字符和语法来实现对字符串的精准匹配与提取。以下是核心元字符 / 语法的分类说明(表格形式):
| 元字符 / 语法 | 说明 | 示例 |
|---|---|---|
| 普通字符(字母、数字、下划线等) | 直接匹配自身 | abc 匹配 "abc" |
. | 匹配除换行符外的任意单个字符 | a.c 匹配 "abc" "a1c" 等 |
\d | 匹配任意数字(0-9) | \d+ 匹配 "123" "45" 等连续数字 |
\D | 匹配任意非数字字符 | \D+ 匹配 "abc" "a!" 等 |
\w | 匹配字母、数字、下划线(等价于 [a-zA-Z0-9_]) | \w+ 匹配 "hello123" "_abc" 等 |
\W | 匹配非字母、数字、下划线的字符 | \W+ 匹配 "!@#" "你好" 等 |
\s | 匹配任意空白字符(空格、制表符、换行等) | \s+ 匹配多个空格、换行等 |
\S | 匹配任意非空白字符 | \S+ 匹配 "abc" "123" 等 |
[] | 字符类,匹配括号内任意一个字符 | [abc] 匹配 "a" "b" "c";[0-9] 等价于 \d |
[^] | 否定字符类,匹配不在括号内的任意字符 | [^abc] 匹配 "d" "1" 等非 a、b、c 的字符 |
* | 匹配前面的元素0 次或多次 | a* 匹配 """a" "aa" 等 |
+ | 匹配前面的元素1 次或多次 | a+ 匹配 "a" "aa" 等(至少 1 次) |
? | 匹配前面的元素0 次或 1 次;也可将贪婪匹配改为非贪婪 | ab? 匹配 "a" "ab";.*? 非贪婪匹配任意字符 |
{n} | 匹配前面的元素恰好 n 次 | a{3} 匹配 "aaa" |
{n,} | 匹配前面的元素至少 n 次 | a{2,} 匹配 "aa" "aaa" 等 |
{n,m} | 匹配前面的元素至少 n 次,最多 m 次 | a{1,3} 匹配 "a" "aa" "aaa" |
^ | 匹配字符串开头(多行模式下匹配行开头) | ^abc 匹配 "abcdef" 开头的 "abc" |
$ | 匹配字符串结尾(多行模式下匹配行结尾) | abc$ 匹配 "defabc" 结尾的 "abc" |
\b | 单词边界,匹配单词的开始 / 结束位置 | \bword\b 匹配独立的 "word",不匹配 "word1" 中的 "word" |
\B | 非单词边界,匹配非单词的开始 / 结束位置 | \Bword\B 匹配 "awordb" 中的 "word" |
() | 分组与捕获,将多个元素视为一个整体,也可捕获匹配内容 | (ab)+ 匹配 "ab" "abab" "ababab" 等连续的 "ab" 组合;(a|b) 匹配 "a" 或 "b"; |
| | | 分支结构(逻辑 “或”),匹配符号左边或右边的任意一个表达式,优先级较低,通常结合 () 限制匹配范围 | a|b 匹配 "a" 或 "b";apple|banana 匹配 "apple" 或 "banana";(http|https) 匹配 "http" 或 "https" |
\ | 转义字符,用于匹配元字符本身(如.、* 等) | \. 匹配 ".";\* 匹配 "*" |
这些元字符和语法可组合使用,实现爬虫中复杂的文本提取需求(如提取 URL、邮箱、电话号码等结构化数据)。
re模块使用
findall:匹配字符串中所有符合正则表达式的子串,返回一个列表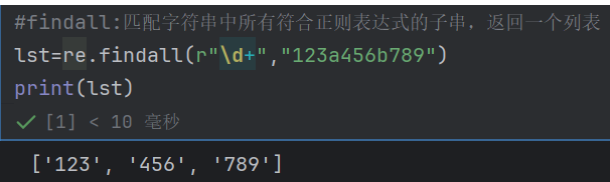
finditer:匹配字符串中所有符合正则表达式的子串,返回一个迭代器。从迭代器中获取匹配的子串时,需要调用group()方法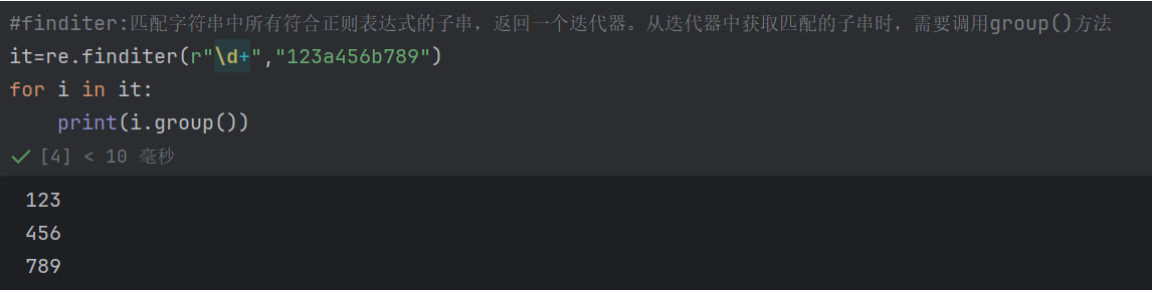
search:匹配字符串中第一个符合正则表达式的子串,返回一个匹配对象。如果没有匹配到,则返回None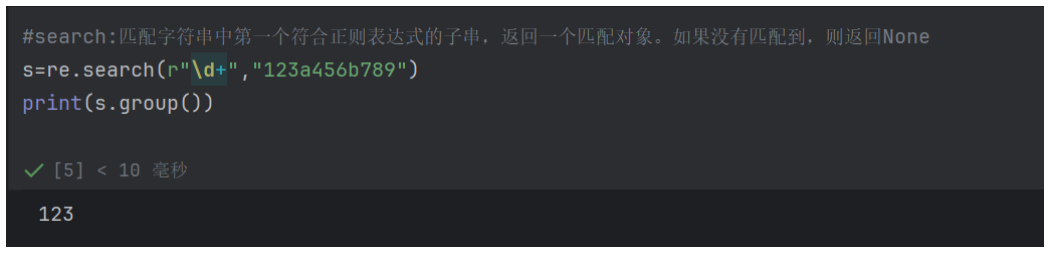
match:从字符串的开头开始匹配,返回一个匹配对象。如果没有匹配到,则返回None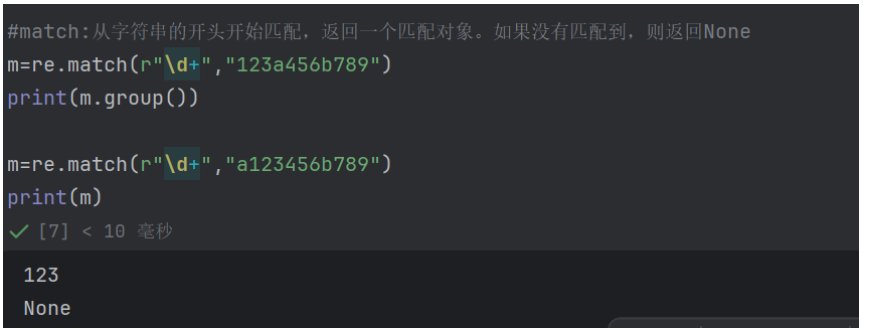
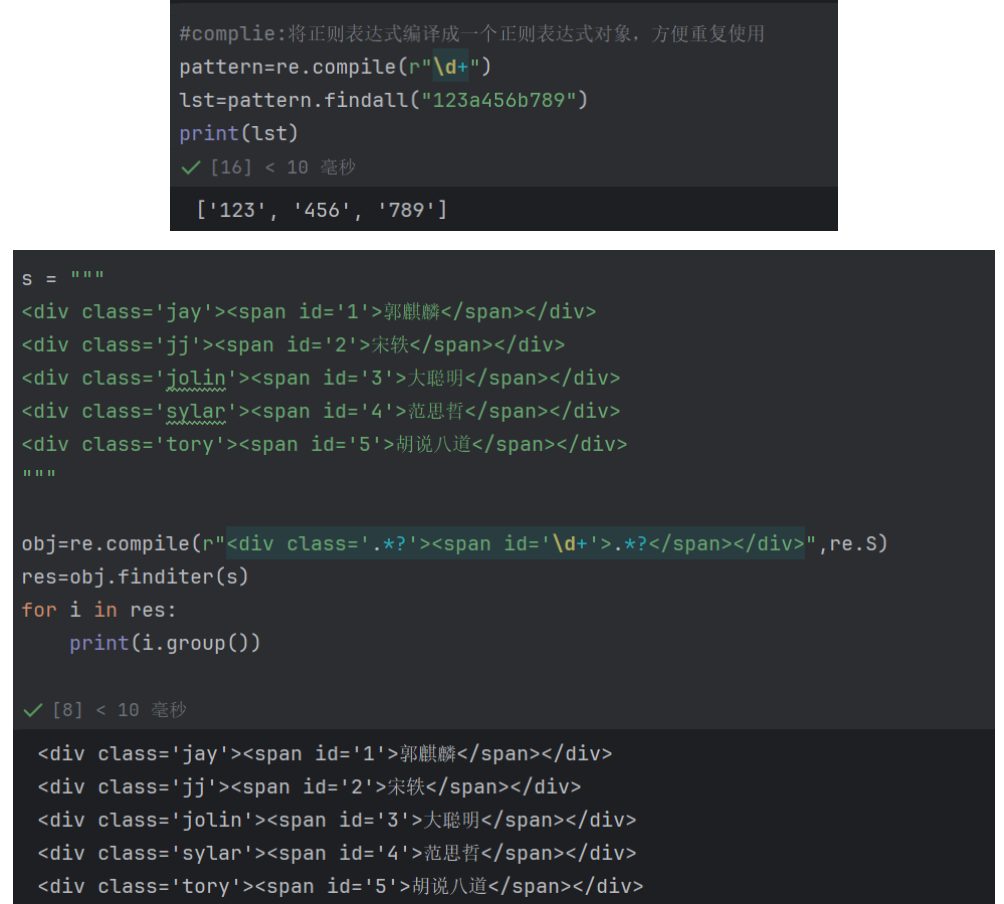
complie:将正则表达式编译成一个正则表达式对象,方便重复使用
-
正则命名捕获组
通过 (?P<组名>正则规则) 的语法,给正则中的分组赋予 “可读性名称”,后续可通过 group('组名') 直接获取对应内容,大幅提升代码可读性。
-
示例:
(?P<name>.*?)定义了名为name的分组,用于匹配class属性值;(?P<id>\d+)定义名为id的分组,匹配数字型id;(?P<wahaha>.*?)定义名为wahaha的分组,匹配<span>内的文本。
-
正则惰性匹配(非贪婪模式)
通过 .*?(在量词*后加?)实现 “尽可能少匹配字符”,避免跨标签 / 跨块的冗余匹配。
-
场景:原文本中每个
<div>是独立块,.*?确保每个<div class='...'>和<span>...</span>只匹配自身块内的内容,不会 “吞噬” 后续的<div>或<span>。
-
正则修饰符
re.S(Dotall 模式)
re.S 是 re.DOTALL 的简写,作用是让正则中的 . 可以匹配换行符。
-
必要性:原文本是多行结构(每个
<div>占一行),若没有re.S,.无法匹配换行,正则会因换行符中断而匹配失败。
-
正则的编译与迭代匹配(
re.compile+finditer)
-
re.compile(pattern, flags):将正则表达式 “编译” 为正则对象,重复使用时效率更高,适合多次匹配的场景。 -
finditer(pattern, string):返回匹配结果的迭代器,逐个生成Match对象,节省内存(相比findall一次性加载所有结果,更适合大量数据场景)。
-
字符串格式化与对齐(
f-string+ljust)
-
f-string:Python 格式化字符串的语法,通过{变量名}直接嵌入变量,简洁高效。 -
ljust(40):字符串左对齐,总长度为 40,使输出格式更整齐(适合批量结果的可视化)。
2.2 Bs4解析
HTML语法规则
演示 HTML 标题标签的层级样式差异
<h1>i love you</h1> <h2>i love you</h2> <h3>i love you</h3> i love you
显示效果: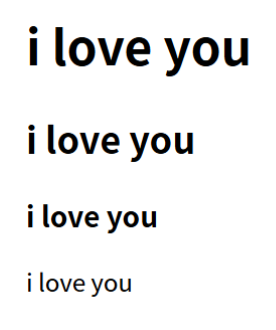
h1是一级标题标签,h2是二级标题标签
<h1 align="center">i love you</h1>
#h1 : 标签 #align : 属性 #center : 属性值<标签 属性=”属性值“>被标记的内容</标签>
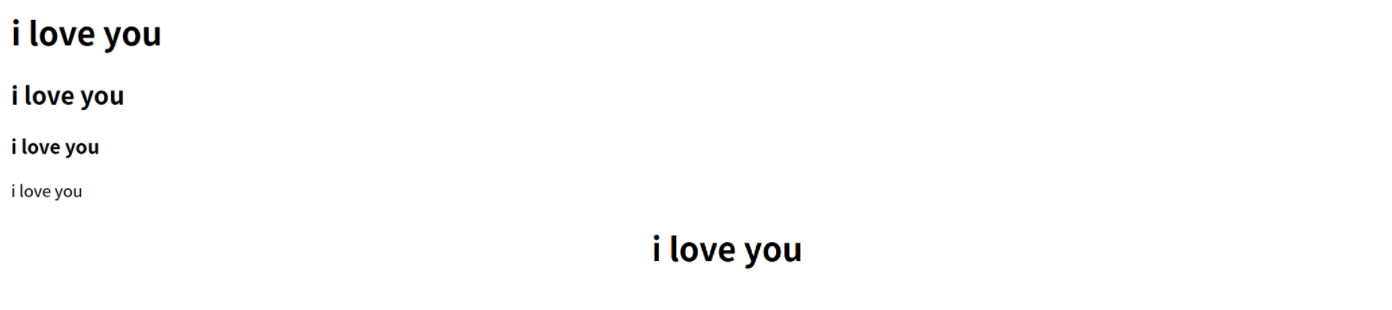
<img src="picture.jpg"/><标签 />

实践:唯美壁纸
一、照旧,获取网址
import requests
from bs4 import BeautifulSoup
url="http://umei.cc/bizhitupian/xiaoqingxinbizhi/"
headers={"user-agent":"Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/142.0.0.0 Safari/537.36 Edg/142.0.0.0"
}
resp=requests.get(url,headers=headers)
二、根据对应结构来找取各种图片对应的链接,所以先找到对应地方的html内容,然后在一堆内容中查找标签a的部分
main_page=BeautifulSoup(resp.content,"html.parser") #"html.parser":解析html文档,返回一个BeautifulSoup对象
alist=main_page.find("div",class_="Clbc_r_cont").find_all("a") #find_all('a'):查找所有的a标签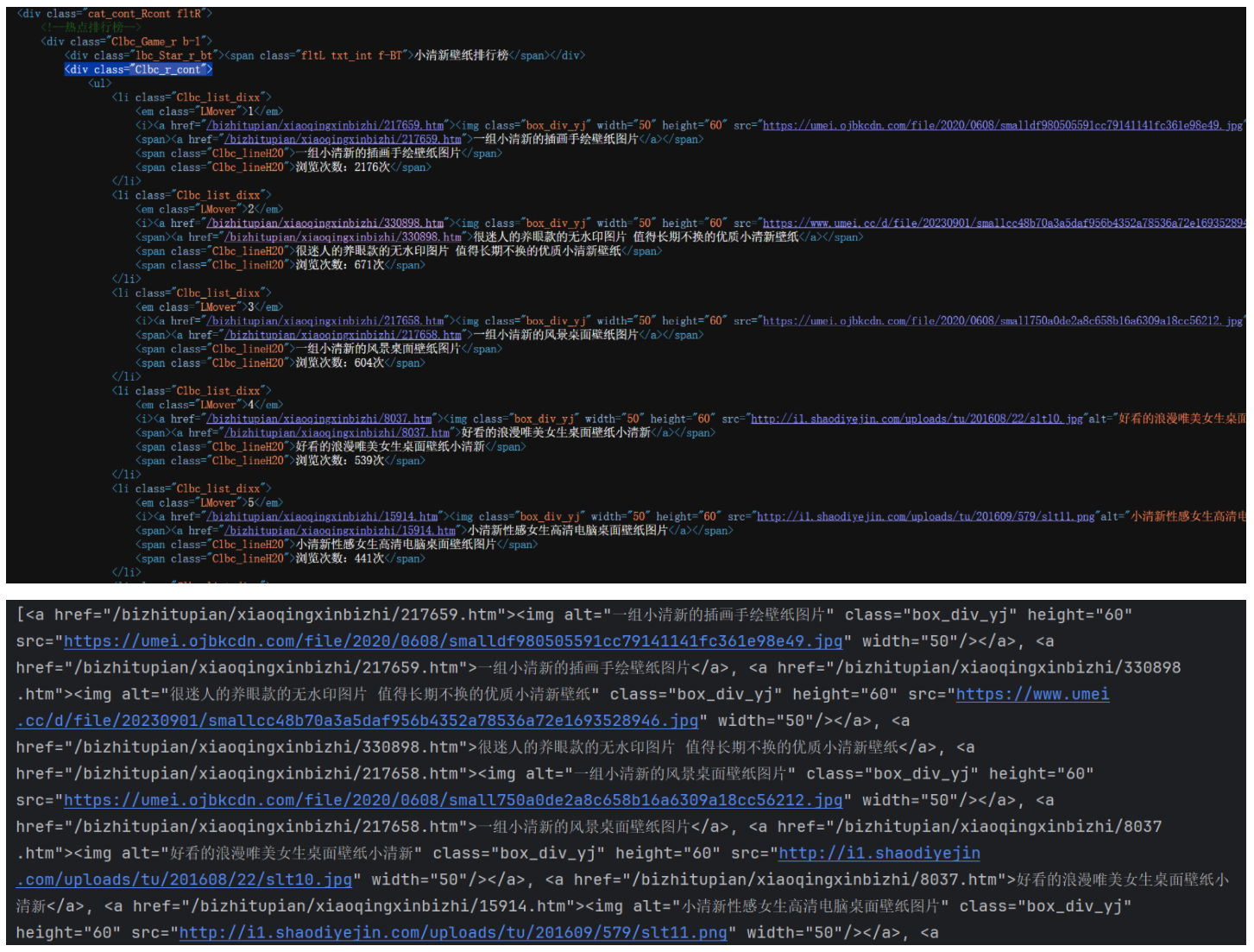
三、由于查找部分是有很多无关内容,我们只需href后的网址部分
for i in alist:#拿到每个子页面的urlhref=("https://www.umei.cc"+i.get("href")) #直接通过get方法获取属性值
四、然后根据每个子页面来提取每个照片的url,最后就是下载照片
for i in alist:#拿到每个子页面的urlhref=("https://www.umei.cc"+i.get("href")) #直接通过get方法获取属性值#请求每个子页面的内容resp=requests.get(href,headers=headers)resp.encoding='utf-8'soup=BeautifulSoup(resp.text,"html.parser")#从每个子页面中提取图片的urlimg=soup.find("div",class_="big-pic").find("img")src=img.get("src")#下载图片resp=requests.get(src,headers=headers)img_name=src.split("/")[-1] #从图片url中提取图片名称with open(img_name,mode='wb') as f: #wb:二进制写入模式,写入字节流f.write(resp.content) #图片内容写入文件print(f"{img_name}下载成功")time.sleep(1) #每个图片下载完成后,休息1秒,避免对服务器 too many requests
例如
2.3 Xpath入门
XML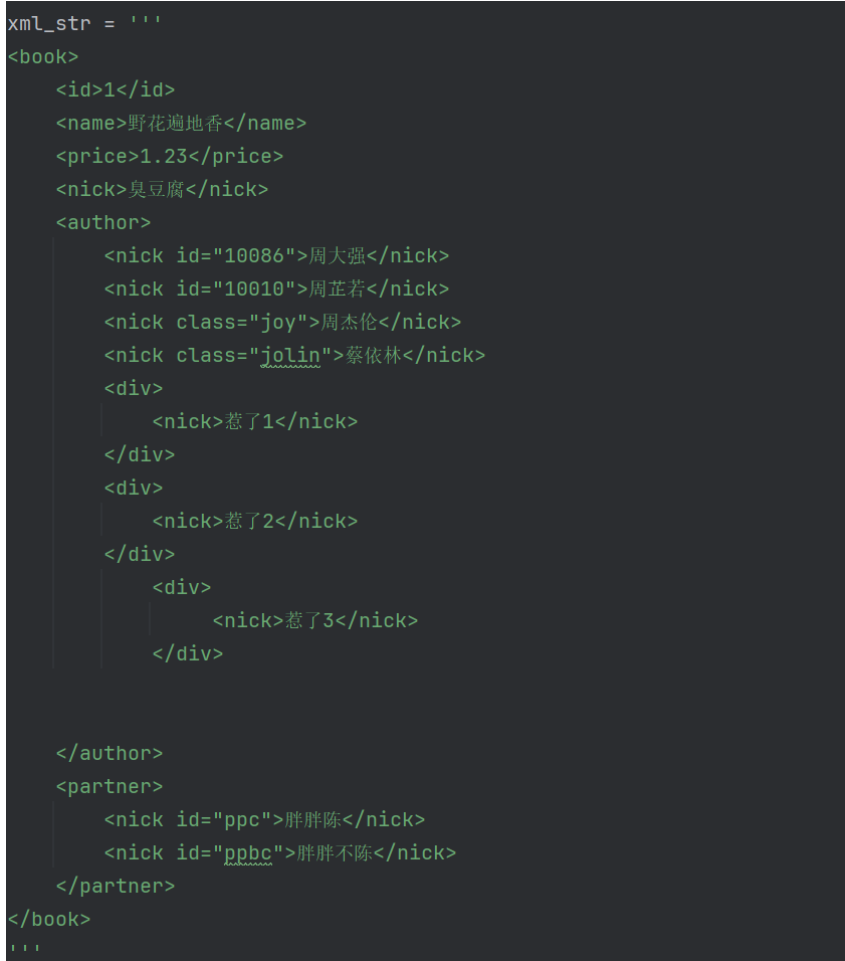
tree=etree.XML(xml_str)
result=tree.xpath("/book/name/text()") #返回name标签的文本内容['野花遍地香']
result=tree.xpath("/book/author/nick[@id='10086']/text()") #返回id为10086的nick标签的文本内容['周大强']
result=tree.xpath("/book/author//nick/text()") #//含义:查找所有子孙节点。代码含义:查找author下所有子孙节点中nick标签的文本内容['周大强', '周芷若', '周杰伦', '蔡依林', '惹了1', '惹了2', '惹了3']
result=tree.xpath("/book/author/*/nick/text()") #*含义:查找所有子节点。代码含义:查找author下所有子节点中nick标签的文本内容['惹了1', '惹了2', '惹了3']
result=tree.xpath("/book//nick/text()") #//含义:查找所有子孙节点。代码含义:查找book下所有子孙节点中nick标签的文本内容['臭豆腐', '周大强', '周芷若', '周杰伦', '蔡依林', '惹了1', '惹了2', '惹了3', '胖胖陈', '胖胖不陈']
HTML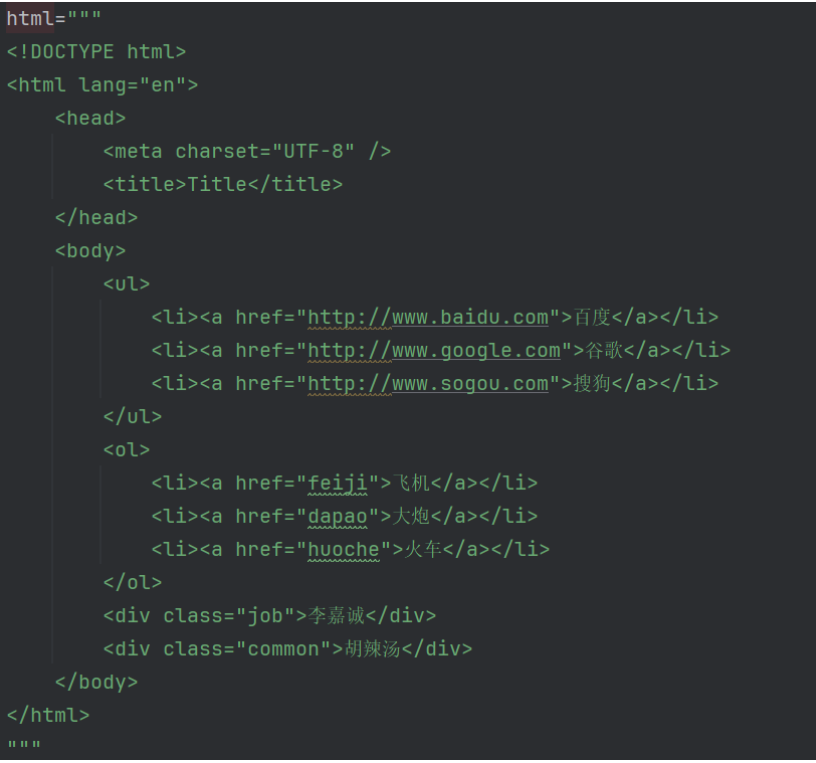
tree=etree.XML(html)
result=tree.xpath("/html/body/ul/li/a/text()") #返回ul标签下所有li标签下a标签的文本内容['百度', '谷歌', '搜狗']
result=tree.xpath("/html/body/ul/li[1]/a/text()") #返回第一个li标签下a标签的文本内容['百度']
result=tree.xpath("/html/body/ul/li/text()") #为什么没结果:因为li标签下没有文本内容,只有a标签下有文本内容[]
# result=tree.xpath("/html/body/ol/li[2]/a/text()") #返回第二个li标签下a标签的文本内容
result=tree.xpath("/html/body/ol/li/a[@href='dapao']/text()") #返回href属性为dapao的a标签的文本内容['大炮']
ol_oi_list=tree.xpath("/html/body/ol/li") #
for li in ol_oi_list:result=li.xpath("./a/text()") #返回li标签下a标签的文本内容result2=li.xpath("./a/@href") #返回a标签下href属性的值print(result,result2)['飞机'] ['feiji']
['大炮'] ['dapao']
['火车'] ['huoche']
三、requests进阶概述
3.3 代理
代理(代理服务器,Proxy Server) 是位于客户端和目标服务器之间的 “中间节点”,所有客户端的网络请求会先发送到代理服务器,再由代理转发给目标服务器;服务器的响应也会先返回给代理,再由代理转发给客户端。
可以把它理解成 “网络请求的‘中转站’或‘中间人’”,核心作用是转发请求、隐藏真实身份、控制访问规则等
-
隐私保护:隐藏真实 IP
当你通过代理访问目标网站时,网站看到的是代理服务器的 IP,而不是你自己的真实 IP。
-
比如你不想让某网站记录你的真实位置,就可以通过代理访问,从而保护隐私。
-
突破访问限制:绕过地域 / 权限封锁
-
地域限制:某些网站(如视频、新闻)仅对特定地区开放(比如 “仅限国内访问” 或 “仅限美国访问”),通过对应地区的代理服务器,就能 “伪装” 成该地区的用户访问。
-
权限限制:企业、学校内网可能限制访问某些外部网站,通过代理(如果被允许)可以绕过这些限制。
-
爬虫 / 数据采集:避免 IP 被封
爬虫程序如果频繁用同一个 IP 请求目标服务器,很容易被识别为 “恶意爬虫” 并封禁 IP。通过代理池(多个不同的代理 IP 轮换使用),可以分散请求来源,让服务器误以为是 “不同用户” 在访问,从而避免 IP 被封。
-
访问控制与过滤
-
企业 / 学校可以通过代理服务器,统一管理员工 / 学生的网络访问(比如禁止访问游戏、赌博网站)。
-
代理还能过滤恶意请求、广告内容,提升网络环境的安全性和整洁度。
-
缓存加速
代理服务器会缓存一些 “高频访问的资源”(如热门图片、视频)。当你再次请求同一资源时,代理可以直接从缓存中返回,不用再去目标服务器获取,从而加快访问速度。
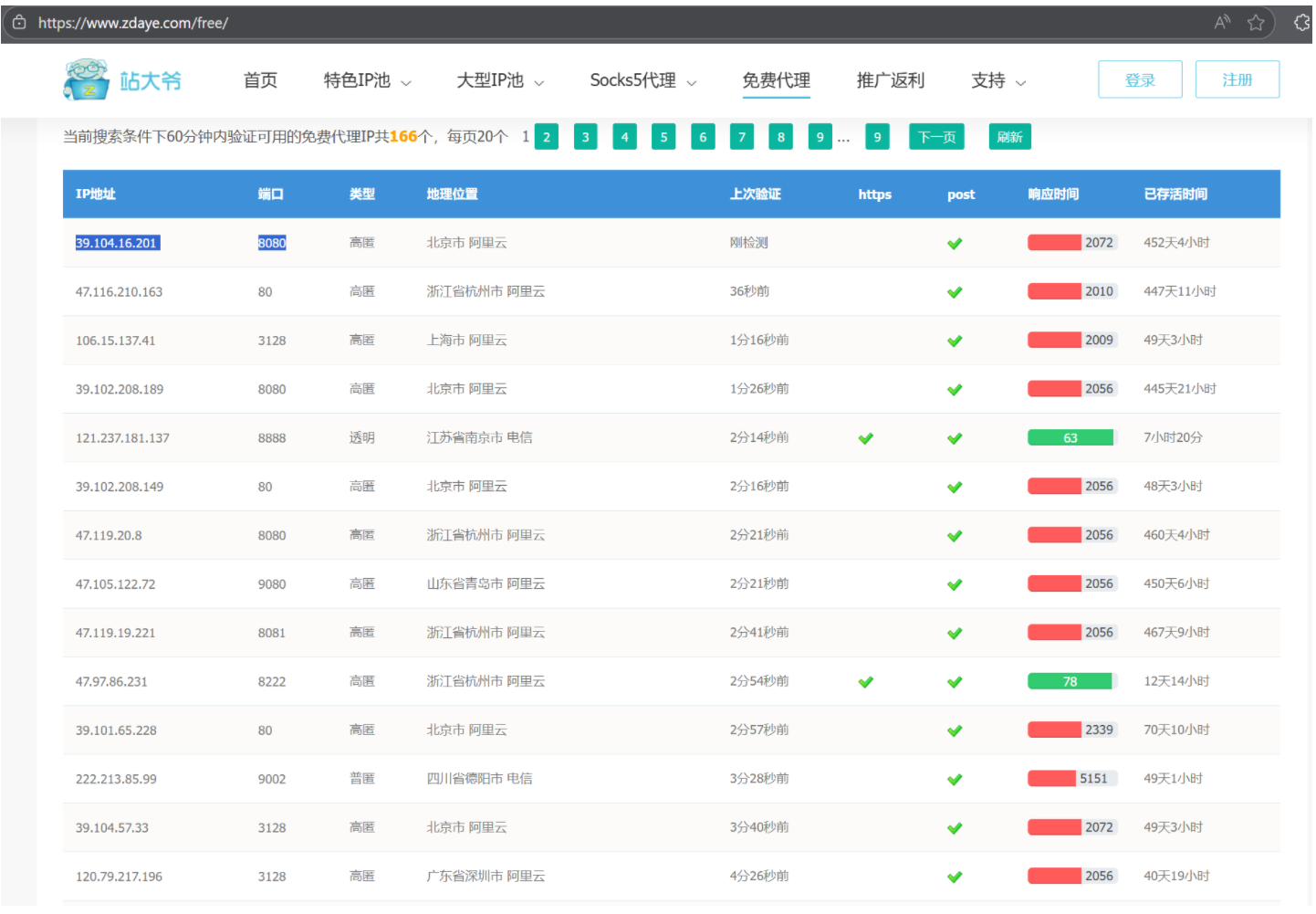
代理 IP 的匿名性分类,不同类型的核心区别在于 “是否隐藏真实 IP” 和 “是否暴露代理痕迹”,具体含义如下:
-
高匿代理
-
含义:匿名性最高的代理类型。它会完全隐藏你的真实 IP,且目标服务器无法察觉你使用了代理(请求头中无任何代理标识字段,如
X-Forwarded-For、Proxy-Connection等)。 -
效果:目标网站只能看到代理服务器的 IP,且认为是 “真实用户直接访问”,常用于隐私保护、爬虫防封、多账号运营等场景。
-
普匿代理(普通匿名代理)
-
含义:能隐藏你的真实 IP,但会在请求头中留下 “代理标识”(如
Proxy-Connection: keep-alive),目标服务器能识别出 “你使用了代理”,但无法获取你的真实 IP。 -
效果:适合反爬较弱的网站数据采集或普通浏览,但部分严格平台可能因 “代理标识” 限制访问频率。
-
透明代理
-
含义:匿名性最差的代理类型。它不仅不隐藏你的真实 IP,还会在请求头的
X-Forwarded-For字段中明文暴露你的真实 IP,同时留下代理标识。 -
风险:目标网站能直接追踪到你的真实 IP,若用于违规操作,可能导致真实 IP 被封禁,个人场景几乎无实用价值,仅适用于企业内部网络管控(如限制员工访问特定网站)。
-
未知类型
-
通常是指代理的匿名性未明确分类,或检测工具无法准确识别其类型,实际使用中需进一步验证(可通过在线 IP 检测工具查看请求头字段来判断)。
例如: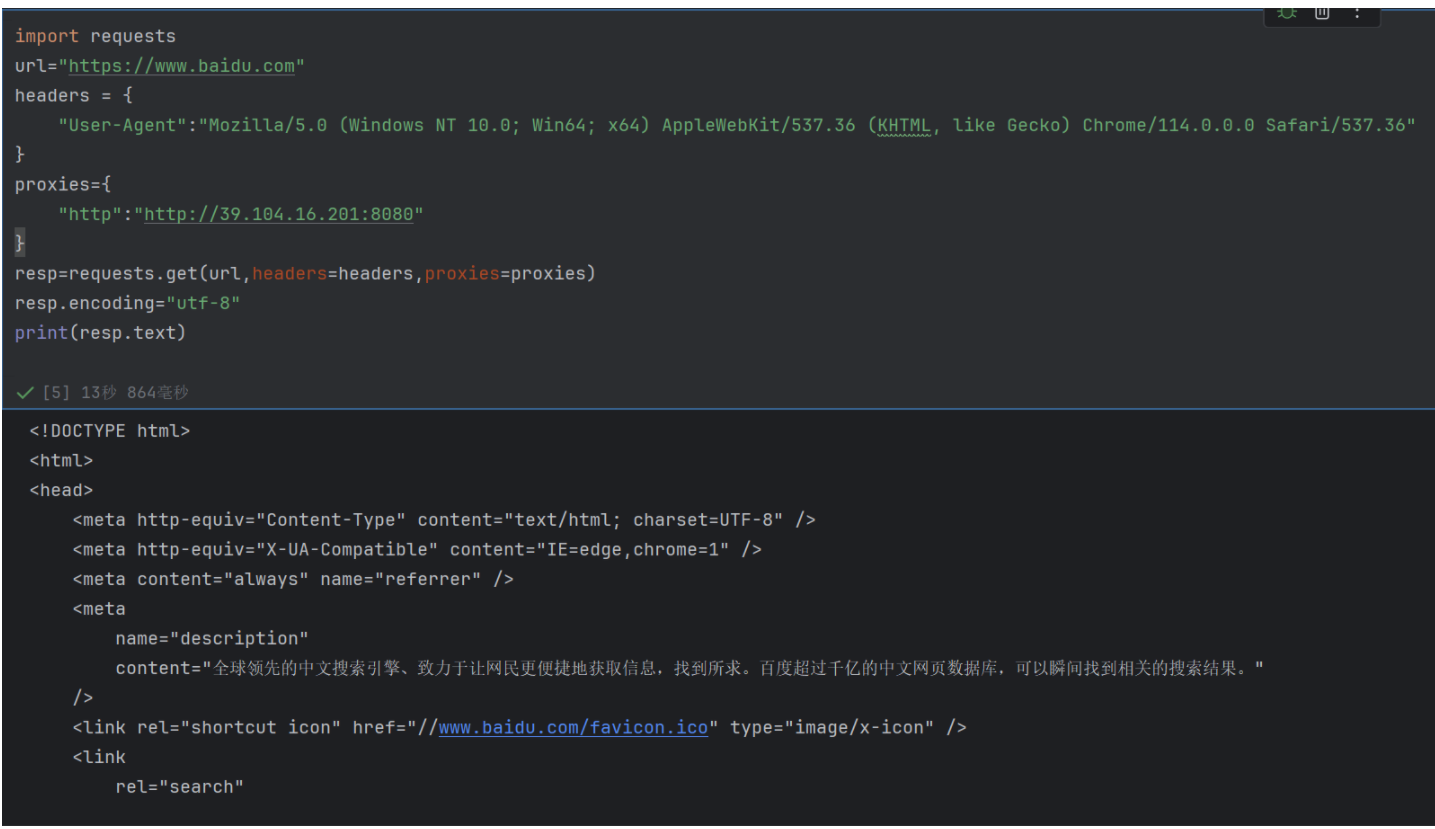
你可能注意到:目标 URL 是HTTPS,但代理配置的是http协议(proxies={"http": "http://...")。这是合理的,因为:
-
代理的 “协议类型” 和目标 URL 的 “协议类型”可以不一致;
-
requests会自动通过HTTP 代理建立 “隧道”(使用CONNECT方法)来转发 HTTPS 请求,只要代理服务器支持即可。
四、给爬虫提速
多线程、多进程、协程是 Python 中实现并发 / 并行的三种核心方案
| 方案 | 通俗比喻 | 核心本质 |
|---|---|---|
| 多进程 | 多个独立的 “工人”,每人一间办公室 | 操作系统层面的独立执行单元,有自己的内存空间、CPU 资源,完全隔离 |
| 多线程 | 一个 “工人” 有多个 “手”,共用一间办公室 | 进程内的执行单元,共享进程的内存空间(变量、文件句柄等),由操作系统调度 |
| 协程 | 一个 “工人” 高效切换干活,同一时间只动一只手 | 用户态的轻量级 “线程”,由程序(而非操作系统)调度,共享线程资源,切换无内核开销 |
二、核心区别(关键维度对比)
| 对比维度 | 多进程(multiprocessing) | 多线程(threading) | 协程(asyncio) |
|---|---|---|---|
| 执行单位 | 进程(操作系统分配资源的最小单位) | 线程(操作系统调度的最小单位) | 协程(用户态调度的最小单位,非 OS 原生) |
| 资源占用 | 极高(每个进程有独立内存、文件描述符) | 中等(共享进程内存,仅占用少量线程栈空间) | 极低(共享线程资源,仅占用少量栈帧) |
| 切换成本 | 高(内核态切换,需保存进程上下文) | 中(内核态切换,需保存线程上下文) | 极低(用户态切换,无需操作系统介入) |
| 并发 / 并行 | 支持并行(多个 CPU 同时执行多个进程) | 伪并行(GIL 限制下,同一时间 1 个线程执行) | 伪并行(单线程内切换,同一时间 1 个协程执行) |
| GIL 影响 | 不受影响(每个进程有独立 GIL) | 受影响(同一进程内所有线程竞争 1 个 GIL) | 不受影响(单线程内调度,GIL 不切换) |
| 数据共享 | 困难(需通过管道、队列、共享内存等 IPC 机制) | 简单(直接共享进程内存,需加锁防冲突) | 极简单(共享线程内存,无锁竞争,单线程执行) |
| 调度方式 | 操作系统调度(抢占式,优先级决定执行顺序) | 操作系统调度(抢占式,时间片轮转) | 程序自主调度(协作式,需手动 yield/await) |
| 崩溃影响 | 进程崩溃不影响其他进程(隔离性强) | 线程崩溃会导致整个进程崩溃(共享资源) | 协程崩溃会导致所在线程崩溃(共享线程资源) |
| 适用场景 | CPU 密集型任务(数据计算、图像处理) | IO 密集型任务(爬虫、文件读写、接口调用) | 高并发 IO 密集型任务(高并发爬虫、API 服务) |
-
关于 “并发” 和 “并行”
-
并发:多个任务 “交替执行”,看起来像同时进行(比如一个人先做 A 再做 B,交替推进);
-
并行
:多个任务 “同时执行”,真正的同时进行(比如两个人同时做 A 和 B)。
-
多进程:支持并行(多个 CPU 同时跑多个进程);
-
多线程 / 协程:仅支持并发(单 CPU 下交替执行,IO 阻塞时切换)。
-
-
GIL 的影响(Python 特有)
GIL(全局解释器锁)是 CPython 解释器的限制,导致同一进程内所有线程只能轮流使用 CPU:
-
多线程:IO 密集型任务中,线程等待网络 / 文件响应时会释放 GIL,其他线程可执行,所以效率提升明显;但 CPU 密集型任务中,线程切换会消耗资源,反而比单线程慢;
-
多进程:每个进程有独立的 GIL,不受限制,所以 CPU 密集型任务必须用多进程;
-
协程:单线程内调度,GIL 全程不切换,无竞争,效率最高。
-
切换机制的差异
-
多进程 / 多线程:内核态切换—— 由操作系统负责,需要保存进程 / 线程的上下文(寄存器、内存地址等),开销大;
-
协程:用户态切换—— 由程序(如 asyncio 库)自己控制,只需保存协程的局部状态(如函数执行到哪一行),开销几乎可以忽略。
-
数据共享的问题
-
多进程:数据完全隔离,共享数据需用
multiprocessing.Queue、Pipe等 IPC 机制,麻烦但安全(无竞争); -
多线程:共享进程内存,直接操作全局变量,但多个线程同时写数据会导致 “数据错乱”(race condition),必须用
threading.Lock加锁保护; -
协程:单线程内执行,同一时间只有一个协程操作数据,无需加锁,既简单又安全。
进程和线程是相互依存、层级分明的关系 —— 进程是线程的 “容器”,线程是进程的 “执行单元”,二者协同实现程序的并发 / 并行执行,核心关系可概括为:线程不能脱离进程独立存在,进程的资源由线程共享,进程的执行依赖线程完成。
用更通俗的比喻理解:
-
进程 = 一家独立的公司(有自己的办公场地、设备、资金等资源,完全独立于其他公司);
-
线程 = 公司里的员工(共享公司的资源,协同完成公司的业务,不能脱离公司单独工作);
-
一个公司(进程)至少有一个 “核心员工”(主线程),也可以招聘多个员工(子线程),所有员工一起推进工作(程序执行)。
-
包含关系:进程是线程的 “母体”
-
每个进程在创建时,会自动创建一个主线程(比如 Python 程序的
main线程),主线程是进程执行的起点; -
进程可以根据需求创建多个子线程(比如多线程爬虫中的工作线程),所有线程都属于同一个进程,受进程管理;
-
线程不能脱离进程存在:线程的创建、运行、销毁都依赖进程提供的资源,一旦进程终止,其内部所有线程会被强制销毁(无论是否执行完毕)。
-
资源关系:线程共享进程的 “资产”,进程隔离资源
-
进程是操作系统分配资源的最小单位:系统会给每个进程分配独立的内存空间(代码段、数据段、堆)、文件描述符、网络端口等资源,不同进程的资源完全隔离(比如 A 进程不能直接访问 B 进程的内存);
-
线程是操作系统调度的最小单位:线程不单独占有资源,而是共享所属进程的全部资源(比如全局变量、文件句柄、网络连接等),多个线程可以直接读写进程的内存数据(无需额外 IPC 机制)。
4.1 多线程
爬虫的核心耗时不在 “处理数据”(CPU 密集),而在 “网络请求”(IO 密集)—— 比如发起 HTTP 请求后,需要等待服务器响应、数据传输,这个过程中程序会处于 “阻塞状态”。
-
单线程爬虫:同一时间只能发起一个请求,必须等前一个请求完成,才能发起下一个,效率极低(比如爬 100 个网页,每个请求耗时 1 秒,单线程需要 100 秒)。
-
多线程爬虫:同时开启多个线程,每个线程负责一个请求,多个请求并行等待响应(比如开启 10 个线程,爬 100 个网页仅需 10 秒左右)。
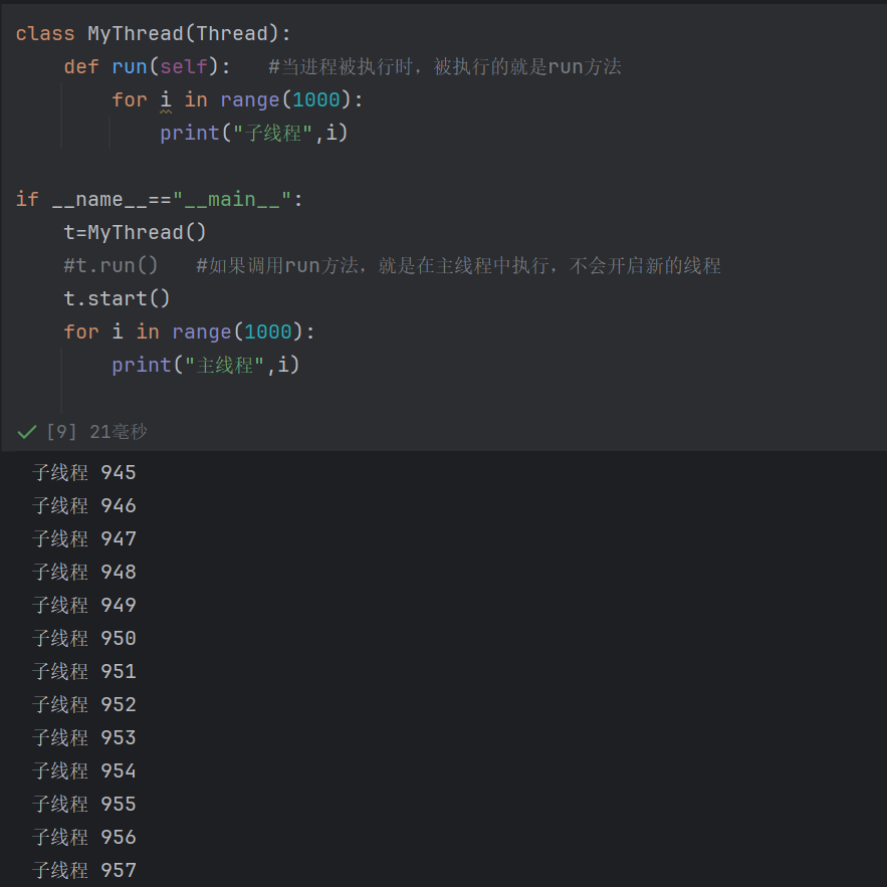
-
两种方式的底层执行机制完全一致(都是通过
Thread类创建线程,start()启动,CPU 调度执行),最终效果(并发执行)相同; -
核心区别是「逻辑组织方式」:封装成类(强扩展、高复用)vs 独立函数(简代码、低门槛);
-
选型口诀:简单任务用
target函数,复杂任务用Thread子类。
4.2 多进程
在爬虫开发中,多进程是应对CPU 密集型任务(如爬取后的数据清洗、复杂解析、机器学习推理等)的关键技术,它能绕过 Python 的 GIL 限制,实现真正的并行计算。
Python 的 GIL(全局解释器锁)会限制多线程在 CPU 密集型任务中的效率(同一时间仅一个线程执行 Python 字节码)。而多进程是操作系统级的独立执行单元,每个进程有自己的 GIL,因此在数据计算、图像处理、复杂解析等 CPU 密集型场景中,多进程能让多个 CPU 核心同时工作,效率远高于多线程。
用多线程 / 协程负责 “网络请求”(IO 密集),用多进程负责 “数据清洗、模型推理”(CPU 密集)。
注意事项
-
资源消耗高:每个进程有独立内存空间,大量进程会导致内存、CPU 过载,需控制进程数(建议与 CPU 核心数一致);
-
进程间通信复杂:数据共享需通过
Queue、Pipe等,不如多线程直接共享内存方便; -
启动开销大:进程创建、销毁的开销远大于线程,适合长时运行的 CPU 密集任务。
三、选型建议
-
选多进程:爬取后有大量 CPU 密集型操作(如数据清洗、复杂正则、机器学习模型推理),且数据量较大;
-
选多线程:以网络请求、文件读写为主(如普通网页爬取、接口调用),数据处理简单;
-
混合方案:爬取用多线程 / 协程(IO 密集),数据处理用多进程(CPU 密集),充分发挥各自优势。
from multiprocessing import Processdef func():for i in range(1000):print("子进程",i,flush=True)if __name__=="__main__":p=Process(target=func) #创建进程,target是要执行的函数p.start() #多进程为可以开始工作状态,但是不一定会立即执行,具体执行时间由CPU调度决定for i in range(1000):print("主进程",i)
Jupyter Notebook(或类似交互式环境)与多进程(multiprocessing)的兼容性冲突,而终端是 Python 多进程的 “原生友好环境”。Jupyter 等交互式环境因模块导入机制,会导致子进程异常退出;
4.3 进程池和线程池
在爬虫开发中,线程池和进程池是管理并发任务的 “高效容器”—— 它们通过预先创建一批线程 / 进程并复用,避免了频繁创建 / 销毁线程 / 进程的开销,同时能精准控制并发数量,平衡效率与资源消耗。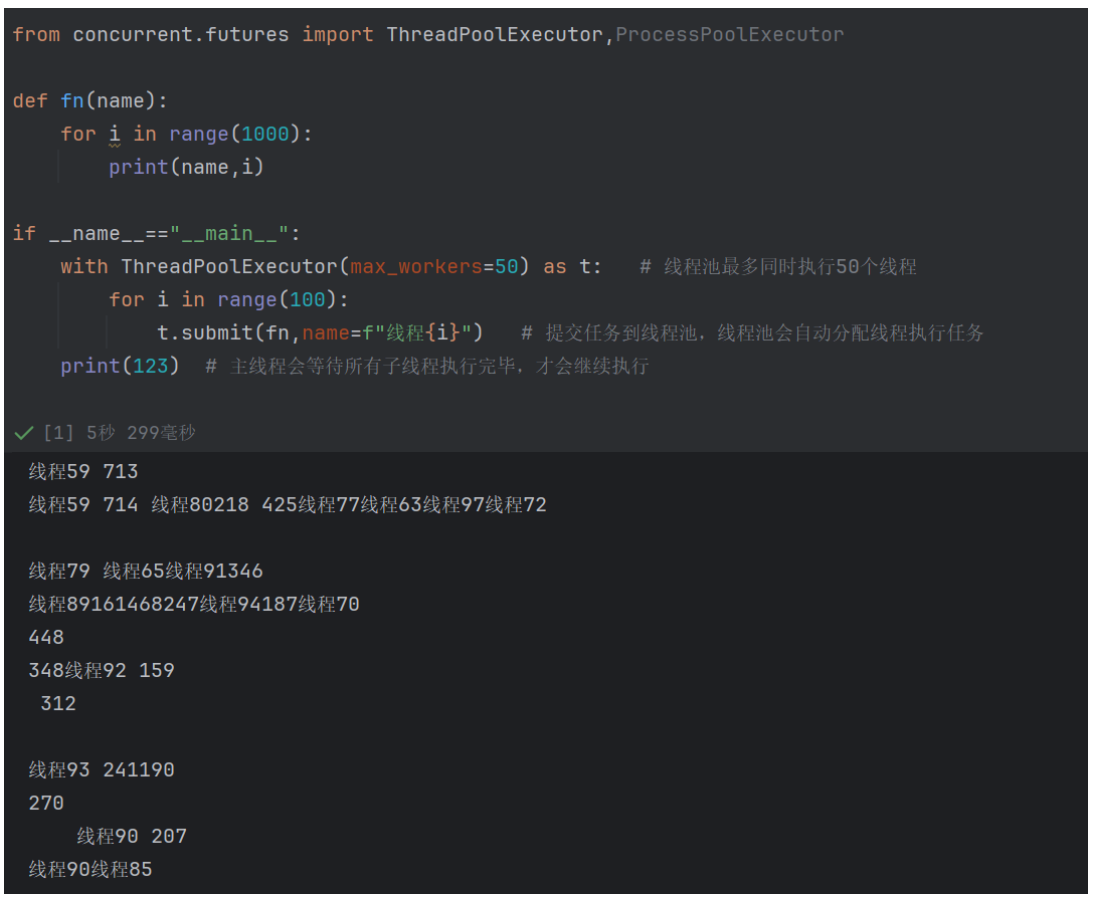
4.4 协程
在爬虫开发中,协程(Coroutine) 是比多线程更高效的「高并发 IO 密集型解决方案」—— 它基于「单线程异步调度」,避免了线程切换的内核开销,能以极少的资源支撑上千个并发请求(比如同时爬 1000 个网页,协程资源占用仅为线程池的几十分之一)。
通俗比喻:
-
多线程 = 10 个工人同时干活(每人一间小办公室,切换要开门关门,开销大);
-
协程 = 1 个超级工人,同时处理 1000 个任务(不用切换办公室,只是手里的活交替干,IO 等待时绝不闲着,开销极小)。
核心优势:并发量极高、资源占用极低、无线程安全问题
| 对比维度 | 协程爬虫(asyncio+aiohttp) | 线程池爬虫(ThreadPoolExecutor) |
|---|---|---|
| 并发量 | 极高(支持 1000 + 并发请求) | 中等(支持 10-20 并发,多了资源耗尽) |
| 资源占用 | 极低(单线程,仅占用少量内存) | 中等(每个线程占用独立栈空间) |
| 切换成本 | 极低(用户态切换,无内核开销) | 中等(内核态切换,需保存线程上下文) |
| 线程安全 | 天然安全(单线程执行,无竞争) | 需加锁(多线程共享资源,易冲突) |
| 依赖库 | 需用异步库(aiohttp、aiomysql) | 可用同步库(requests、pymysql) |
| 适用场景 | 高并发 IO(上千个请求、批量接口) | 中等并发 IO(几十到上百个请求) |
协程的切换核心原则是:只有遇到「可挂起的异步操作」时,才会主动交出 CPU 控制权,让事件循环切换到其他就绪的协程。协程 “不等待不切换,一等待就切换”,所有切换都是为了避免 “空等”,最大化利用 CPU。
一、库的区别:同步库(正常编程)vs 协程异步库
协程不能直接使用同步库(如requests、time),否则会阻塞事件循环(协程失效),必须用专门的「异步库」—— 这些库的核心是支持「await 挂起」,不会阻塞线程。
| 功能场景 | 正常同步库(常用) | 协程异步库(对应替代) | 核心差异说明 |
|---|---|---|---|
| 网络请求(爬虫核心) | requests(requests.get()) | aiohttp(session.get()) | 同步requests:发起请求后阻塞线程,直到拿到响应;异步aiohttp:await后协程挂起,事件循环切换其他任务 |
| 延迟等待(反爬) | time.sleep(n) | asyncio.sleep(n) | 同步time.sleep:阻塞整个线程,所有任务停等;异步asyncio.sleep:仅挂起当前协程,其他协程正常执行 |
| 文件读写 | open()(f.write()) | aiofiles(await f.write()) | 同步文件操作:阻塞线程直到 IO 完成;异步文件操作:await后挂起,切换其他协程 |
| 数据库操作 | pymysql(MySQL)、psycopg2(PostgreSQL) | aiomysql、asyncpg | 同步数据库操作:阻塞线程等待 SQL 执行结果;异步库:await后挂起,不浪费 CPU |
| 任务调度 | 无(直接调用函数) | asyncio(事件循环、任务管理) | 协程需要asyncio提供的事件循环来调度,同步代码无需额外调度(串行执行) |
二、语法的区别:同步语法 vs 协程语法
协程在语法上有专属关键字和规则,核心是「标记异步函数」和「挂起异步操作」,而同步语法更直接(直接调用、无额外关键字)。以下是最常用的语法对比,结合你之前的爬虫代码举例:
| 语法场景 | 正常同步语法(示例) | 协程异步语法(示例) | 核心差异说明 |
|---|---|---|---|
| 函数定义 | def download_one_day(url, param): | async def async_download_one_day(session, date_str): | 协程函数用async def定义,返回「协程对象(Coroutine)」;同步函数用def,返回普通值 |
| 执行函数 | download_one_day(url, param)(直接调用) | asyncio.create_task(async_download_one_day(session, date_str)) | 同步函数直接调用执行;协程函数不能直接调用(调用后仅创建协程对象),必须提交到事件循环 |
| 等待操作 | resp = requests.get(url)(阻塞等待) | resp = await session.get(url)(挂起等待) | 同步操作「阻塞线程」,直到完成;协程用await挂起当前协程,事件循环切换其他任务 |
| 上下文管理器 | with open("file.csv", "w") as f: | async with aiohttp.ClientSession() as session: | 协程的异步上下文用async with(如aiohttp会话、aiofiles文件);同步用with |
| 启动执行 | 直接调用函数(if __name__ == "__main__": download_one_day(...)) | asyncio.run(main())(启动事件循环) | 同步代码自上而下串行执行;协程必须通过asyncio.run()启动事件循环,由事件循环调度任务 |
| 批量任务执行 | ThreadPoolExecutor(多线程并行) | asyncio.gather(*tasks)(协程并发) |
aiohttp模块
import aiohttp
#requests.get()同步代码-> aiohttp异步操作
import asyncio
urls=["https://pcsource.upupoo.com/theme/2000539939/listCover.jpg","https://pcsource.upupoo.com/theme/2000745644/listCover.jpg","https://pcsource.upupoo.com/theme/2000765051/listCover.jpg"]
async def download(url):name=url.rsplit("/",2)[1]+".jpg" #rsplit从右分割async with aiohttp.ClientSession() as session: #使用async with语法确保会话会被正确关闭async with session.get(url) as resp:#使用async with语法确保响应对象会被正确处理with open(name, 'wb') as f: # 以二进制写入模式打开文件f.write(await resp.read()) #读取内容是异步的,需要awaitprint(name,"搞定")async def main():tasks=[]for url in urls:tasks.append(asyncio.create_task(download(url)))# 使用asyncio.create_task()创建异步任务,并添加到任务列表中await asyncio.gather(*tasks)
if __name__ == '__main__':await main()
-
异步函数定义:
async def
-
语法:用
async def声明函数(如async def download(url)、async def main()),这类函数称为「协程函数」。 -
核心作用:标记函数内部包含异步操作(需配合
await),调用后不会立即执行,而是返回「协程对象」,需通过await或asyncio.create_task()触发。
-
异步上下文管理器:
async with
-
语法:
async with aiohttp.ClientSession() as session、async with session.get(url) as resp。 -
核心作用:专门用于管理「异步资源」(如异步会话、异步网络响应),替代同步的
with。 -
原理:自动处理资源的创建与释放(如会话建立 / 关闭、响应接收 / 释放),避免手动管理资源泄漏,且不会阻塞事件循环。
-
异步等待关键字:
await
-
语法:
await resp.read(),仅能在async def函数内使用。 -
核心作用:等待「异步操作完成」(此处是等待网络响应数据读取),同时释放事件循环—— 在等待期间,事件循环会切换到其他就绪的异步任务(如同时下载其他图片),不浪费等待时间(非阻塞)。
-
异步任务创建与聚合:
asyncio.create_task()+asyncio.gather(*tasks)
-
任务创建:
asyncio.create_task(download(url))将协程函数包装为「可并发执行的任务」,添加到事件循环中等待调度(不会立即阻塞)。 -
任务聚合:
await asyncio.gather(*tasks)等待所有任务完成,按任务创建顺序返回结果(有序),是异步并发的核心控制方式。await asyncio.gather(*tasks) 和 await asyncio.wait(tasks)区别:
简单场景、需要有序结果用
gather;需要超时、部分完成、灵活异常处理用wait。
-
异步网络请求库:
aiohttp的使用
-
核心组件:
aiohttp.ClientSession()是异步网络请求的「会话对象」,用于复用连接池(比同步requests更节省资源)。 -
异步请求:
session.get(url)是异步网络请求,需配合async with和await才能获取响应,不会像同步requests.get(url)那样阻塞线程。
-
异步执行入口:
await main()
-
场景:因代码运行在交互式环境(如 Jupyter),环境已启动事件循环,直接用
await main()触发协程执行。 -
普通脚本场景:需用
asyncio.run(main())启动事件循环(自动创建→运行→关闭循环),是独立脚本的标准异步入口。
交互式环境(如 Jupyter Notebook、IPython 终端),因为这些环境会自动启动一个事件循环来支持异步代码的交互执行。而 asyncio.run() 的设计是用于在 “无事件循环” 的环境中(如普通 Python 脚本)启动并管理一个全新的事件循环,因此在已有事件循环的场景中调用它会冲突。
| 对比维度 | 本代码的异步操作 | 对应的同步操作(以 requests+open 为例) |
|---|---|---|
| 函数定义 | async def 声明协程函数 | def 声明普通函数(如 def sync_download(url)) |
| 资源管理 | async with 管理异步资源(会话 / 响应) | with 管理同步资源(如 with requests.Session()) |
| 等待逻辑 | await 非阻塞等待(等待时切换其他任务) | 直接执行阻塞操作(如 resp = requests.get(url),等待时程序卡死) |
| 并发实现 | asyncio.create_task() 创建多个任务,事件循环调度(单线程并发) | 要么顺序执行(总耗时 = 所有任务耗时之和),要么用 threading 多线程(系统级切换,开销大) |
| 网络请求库 | aiohttp(异步非阻塞) | requests(同步阻塞) |
| 数据读取 | await resp.read()(异步读取响应体) | resp.content(同步读取,阻塞线程) |
| 执行效率(IO 密集) | 多任务并行等待(总耗时≈最长单个任务耗时) | 任务排队等待(总耗时 = 所有任务耗时之和) |
| 执行依赖 | 必须依赖事件循环(asyncio 管理) | 无需事件循环,直接顺序执行 |
实践:异步实战—爬取小说
一、找取内容加载的js异步接口,然后会发现这是其中一章的内容,id=1569782244,所以需要去找齐所有章节的id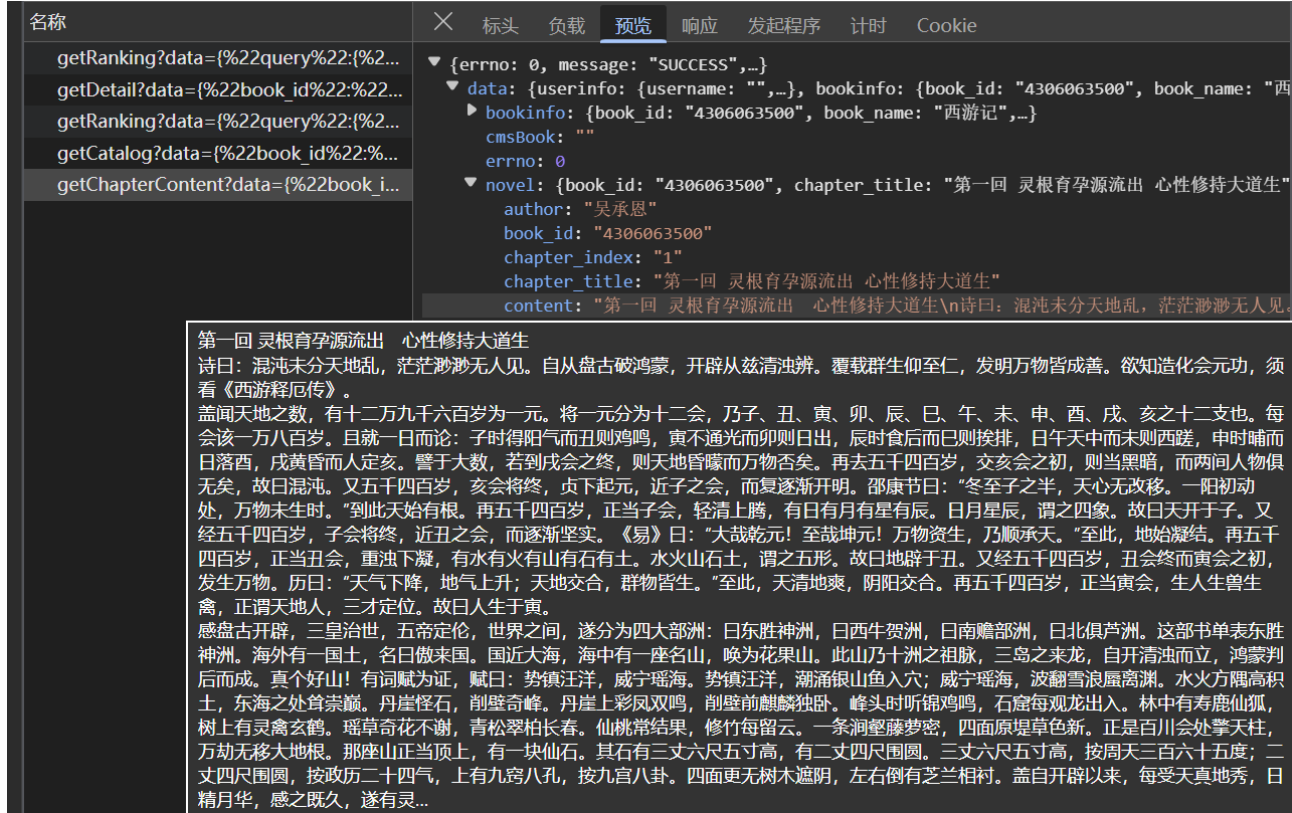
二、找齐所有章节的id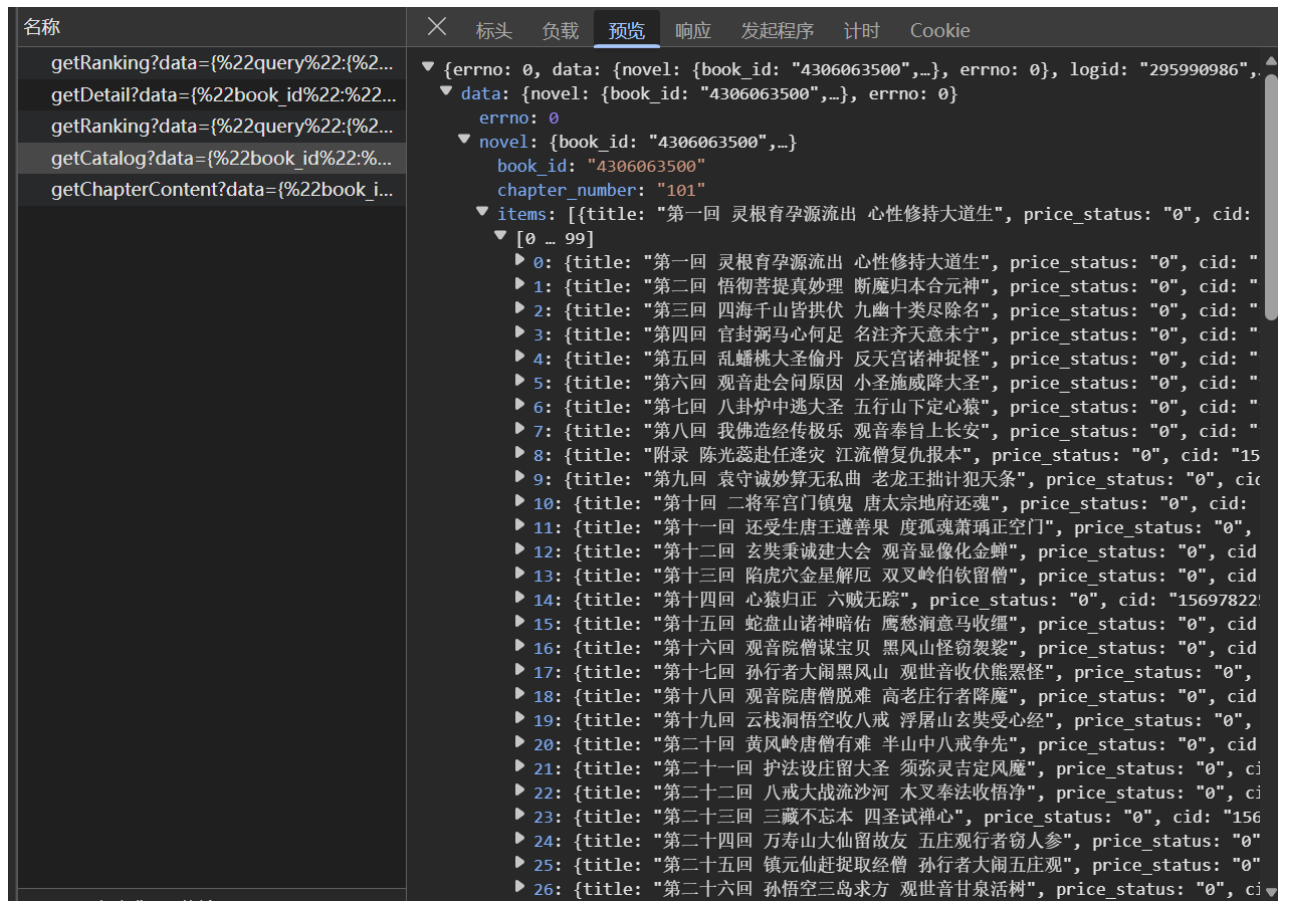
所以就可以通过该网址来爬取所有章节的id,并提取出来每一章的题目以及id值
async def getbook_id(url):resp=requests.get(url)dic=resp.json()tasks=[]for a in dic["data"]["novel"]["items"]:title=a["title"]+".txt"cid=a["cid"]
三、找齐id后,拼接小说每一章对应的网址url
data = {"book_id":book_id,"cid":f"{book_id}|{cid}","need_bookinfo":1
}
data=json.dumps(data)
url=f"https://dushu.baidu.com/api/pc/getChapterContent?data={data}"
四、将爬取每一个章节任务都划入到tasks中
async def getbook_id(url):resp=requests.get(url)dic=resp.json()tasks=[]for a in dic["data"]["novel"]["items"]:title=a["title"]+".txt"cid=a["cid"]#准备异步任务tasks.append(asyncio.create_task(getcontent(book_id,cid,title))) #将每个章节的爬取任务添加到任务列表中await asyncio.gather(*tasks)
五、将章节写入保存到novels文件夹
async with aiohttp.ClientSession() as session: #创建异步HTTP客户端会话async with session.get(url,data=data) as resp:dic=await resp.json()# 异步解析响应内容为JSON格式的字典content=dic["data"]["novel"]["content"] #从响应数据中提取小说章节内容async with aiofiles.open(f"novels/{title}",mode='w',encoding="utf-8") as f: # 使用异步文件操作库aiofiles,以写入模式打开文件await f.write(content)
六、完整代码以及运行结果
import asyncio
import aiohttp
import aiofiles
import requests
import jsonasync def getcontent(book_id,cid,title):data = {"book_id":book_id,"cid":f"{book_id}|{cid}","need_bookinfo":1}data=json.dumps(data)url=f"https://dushu.baidu.com/api/pc/getChapterContent?data={data}"async with aiohttp.ClientSession() as session: #创建异步HTTP客户端会话async with session.get(url,data=data) as resp:dic=await resp.json()# 异步解析响应内容为JSON格式的字典content=dic["data"]["novel"]["content"] #从响应数据中提取小说章节内容async with aiofiles.open(f"novels/{title}",mode='w',encoding="utf-8") as f: # 使用异步文件操作库aiofiles,以写入模式打开文件await f.write(content)async def getbook_id(url):resp=requests.get(url)dic=resp.json()tasks=[]for a in dic["data"]["novel"]["items"]:title=a["title"]+".txt"cid=a["cid"]#准备异步任务tasks.append(asyncio.create_task(getcontent(book_id,cid,title))) #将每个章节的爬取任务添加到任务列表中await asyncio.gather(*tasks)if __name__=="__main__":book_id="4306063500"url='https://dushu.baidu.com/api/pc/getCatalog?data={%22book_id%22:%22'+book_id+'%22}'await getbook_id(url)
综合训练—视频网站的工作原理
使用专业工具(如 FFmpeg)将原始视频编码为多分辨率版本(如 360p、720p、1080p),并按固定时长(通常 2-10 秒)切割成独立片段。
生成索引文件(如 HLS 的.m3u8或 DASH 的.mpd),记录每个切片的 URL、时长及码率信息,例如:
#EXTM3U #EXT-X-VERSION:3 #EXT-X-TARGETDURATION:10 #EXTINF:10.0, part1.ts #EXTINF:10.0, part2.ts
想要抓取一个视频
1、找到视频的 m3u8 链接
2、通过 m3u8 下载所有 ts 切片文件
3、将 ts 文件合并为 mp4 文件