指针深入第四弹--sizeof和strlen的对比、数组和指针笔试题解析、指针运算笔试题解析
目录
sizeof和strlen的对比
sizeof
strlen
sizeof和strlen的对比
数组和指针笔试题解析
数组名的理解
⼀维数组
字符数组
sizeof的运用
代码1:
代码2:
代码3:
strlen的运用
代码1:
代码2:
代码3:
关键表达式解析:
strlen(&p+1) 的行为:
可能的结果:
二维数组
指针运算笔试题解析
题目1:
题目2:
题目3:
题目4:
题目5:
题目6:
题目7:
总结:
sizeof与strlen的本质区别
数组与指针的核心关系
指针运算的关键要点
实践建议
sizeof和strlen的对比
sizeof
在学习操作符的时候,我们学习了 sizeof , sizeof 计算变量所占内存空间⼤⼩的,单位是字节,如果操作数是类型的话,计算的是使⽤类型创建的变量所占内存空间的⼤⼩。
sizeof 只关注占⽤内存空间的⼤⼩,不在乎内存中存放什么数据。
sizeof是单目操作符,绝对不是函数!
#include<stdio.h>
int main()
{int a = 10;printf("%d\n", sizeof(a));return 0;
}strlen
strlen 是C语⾔库函数,功能是求字符串⻓度。函数原型如下:
size_t strlen ( const char * str );size_t是无符号整数
统计的是从 strlen 函数的参数 str 中这个地址开始向后, \0 之前字符串中字符的个数。
strlen 函数会⼀直向后找 \0 字符,直到找到为⽌,所以可能存在越界查找。
#include<stdio.h>
#include<string.h>
int main()
{char arr1[3] = { 'a','b','c' };char arr2[] = "abc";printf("%zd\n", strlen(arr1));printf("%zd\n", strlen(arr2));return 0;
}运行结果为:

arr1中无'\0',造成了数组越界,为随机值
sizeof和strlen的对比
| sizeof | strlen |
| sizeof是操作符 | strlen是库函数,使用需要报告头文件string.h |
| sizeof计算操作数所占内存的⼤⼩,单位是字节 | srtlen是求字符串⻓度的,统计的是 \0 之前字符的隔个数 |
| 不关注内存中存放什么数据 | 关注内存中是否有 \0 ,如果没有 \0 ,就会持续往后找,可能会越界 |
sizeof括号中有表达式的话,表达式是不参与计算的
int main()
{int a = 8;short s = 4;printf("%d\n", sizeof(s = a + 2));printf("%d\n", s);
}运行结果为:

为什么sizeof中的表达式不计算呢?
c语言是编译型语言:test.c
编译-->链接-->test.exe-->运行
数组和指针笔试题解析
数组名的理解
数组名是数组首元素的地址
两个例外
- sizeof(数组名)--数组名表示整个数组,计算的是整个数组的大小,单位是字节
- &数组名--数组名表示整个数组,取出的是整个数组的地址
除此之外,所有的数组名是数组首元素的地址
⼀维数组
int main()
{int a[] = { 1,2,3,4 };printf("%d\n", sizeof(a));//16--sizeof(数组名)的场景printf("%d\n", sizeof(a + 0));//4/8--a是首元素的地址-类型是int*,a+0还是首元素的地址printf("%d\n", sizeof(*a));//4--a是数组首元素的地址,*a是首元素//*a==a[0]==*(a+0)printf("%d\n", sizeof(a + 1));//4/8--a是首元素的地址,类型是int*,a+1跳过1个整型,a+1是第二个元素的地址printf("%d\n", sizeof(a[1]));//4--a[1]是第二个元素,类型是intprintf("%d\n", sizeof(&a));//4/8--&a是数组的地址,类型是int*printf("%d\n", sizeof(*&a));//16--*&互相抵消,sizeof(*&a)==sizeof(a)printf("%d\n", sizeof(&a + 1));//4/8--&a是数组的地址,&a+1跳过一个数组printf("%d\n", sizeof(&a[0]));//4/8--首元素的地址printf("%d\n", sizeof(&a[0] + 1));//4/8--&a[0]首元素的地址,+1跳过一个整型,是第二个元素的地址
}运行结果为:
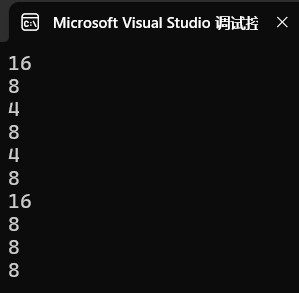
- x64环境:指针大小为8字节 → 所有地址表达式的
sizeof结果为8。 - x86环境:指针大小为4字节 → 所有地址表达式的
sizeof结果为4(你的原始分析)。 - 不变量:数组元素(
int)和整个数组的大小不受平台影响(始终为4字节和16字节)。
字符数组
sizeof的运用
代码1:
int main()
{char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", sizeof(arr));//6--arr在这里是数组名,计算的是数组的大小,为6个字节printf("%d\n", sizeof(arr + 0));//4/8--arr不是单独出现的,所以是首元素的地址,arr+0依旧是首元素的地址printf("%d\n", sizeof(*arr));//1--arr是首元素的地址,*arr就是首元素,为字符:一个字节printf("%d\n", sizeof(arr[1]));//1--arr[1]是第二个元素printf("%d\n", sizeof(&arr));//4/8--arr表示的是数组,&arr是数组地址printf("%d\n", sizeof(&arr + 1));//4/8--arr表示的是数组,&arr是数组的地址,&arr+1是跳过了一个数组//因为sizeof里的表达式不进行计算,所有不存在数组越界的问题printf("%d\n", sizeof(&arr[0] + 1));//4/8--arr[0]是数组首元素,&arr[0]是数组首元素的地址,&arr[0]+1是第二个元素的地址return 0;
}运行结果为:

代码2:
int main()
{char arr[] = { "abcdef"};printf("%d\n", sizeof(arr));//7--arr是数组名,计算的是数组的大小,字符后有'\0'printf("%d\n", sizeof(arr + 0));//4/8--arr是首元素的地址,arr+0是数组首元素的地址printf("%d\n", sizeof(*arr));//1--arr是数组首元素的地址,*arr是数组首元素printf("%d\n", sizeof(arr[1]));//1--arr[1]是数组第二个元素printf("%d\n", sizeof(&arr));//4/8--arr是数组,&arr是数组的地址printf("%d\n", sizeof(&arr + 1));//4/8--arr是数组,&arr是数组的地址,&arr+1跳过1个数组printf("%d\n", sizeof(&arr[0] + 1));//4/8--&arr[0]是数组首元素的地址,&arr[0]+1是第二个元素的地址return 0;
}运行结果为:

代码3:
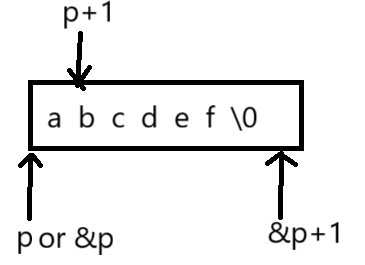
- 把常量字符串想象成数组
- p可以理解为数组名
- p[0]就是首元素
int main()
{char* p = "abcdef";printf("%d\n", sizeof(p));//4/8--p是指针变量,指针变量就是地址printf("%d\n", sizeof(p + 1));//4/8--p+1是第二个元素b的地址printf("%d\n", sizeof(*p));//1--p是首元素的地址,*p是数组首元素aprintf("%d\n", sizeof(p[0]));//1--p[0]是数组首元素//1.p[0]-->*(p+0)-->*p-->'a'//把常量字符串想象成数组,p可以理解为数组名,p[0]就是数组首元素printf("%d\n", sizeof(&p));//4/8--&p是p的地址printf("%d\n", sizeof(&p + 1));//4/8--&p+1是跳过指针变量p的地址printf("%d\n", sizeof(&p[0] + 1));//4/8--&p[0]是a的地址,+1是b的地址return 0;
}运行后的结果:

strlen的运用
代码1:
int main()
{char arr[] = { 'a','b','c','d','e','f' };printf("%d\n", strlen(arr));//随机值--arr是数组首元素的地址,数组中没有'\0',就会导致越界访问printf("%d\n", strlen(arr + 0));//随机值--arr+0是数组首元素的地址,数组中没有'\0',就会导致越界访问//printf("%d\n", strlen(*arr));//系统崩溃--arr是数组首元素的地址,*arr就是数组首元素,就是'a',strlen的返回值是size_t//a的ASCII码值是97,就是把97传递给了strlen,strlen得到的是野指针,代码也是有问题的//printf("%d\n", strlen(arr[1]));//系统崩溃--arr[1]是'b'-98,代码也是有问题的printf("%d\n", strlen(&arr));//随机值1--arr是数组,&arr是数组的地址,数组中没有'\0',就会导致越界访问printf("%d\n", strlen(&arr + 1));// 随机值2==随机值1-6--&arr是数组的地址,&arr+1时跳过一个数组,数组中没有'\0',就会导致越界访问printf("%d\n", strlen(&arr[0] + 1));//随机值3==随机值1-1--arr[0]是数组首元素,&arr[0]是数组首元素的地址,&arr[0] + 1是数组第二个元素的地址return 0;
}运行结果为:
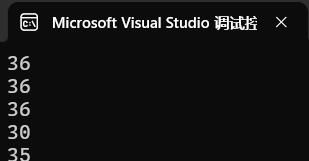
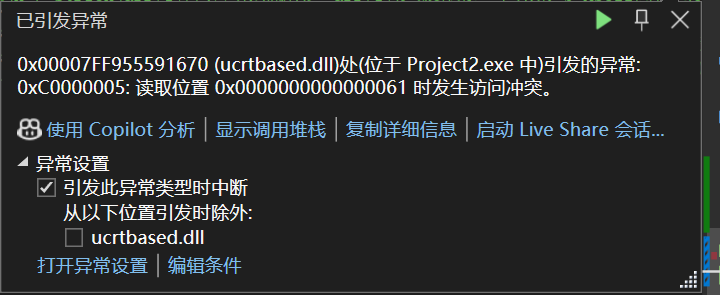
你可能有疑问的地方
-
strlen(arr + 0)可能有输出:- 虽然越界访问是未定义行为,但许多系统允许读取未分配内存
- 如果数组后面内存中恰好有
\0,strlen会"正常"返回一个值 - 这个值可能很大(取决于内存布局),但程序不会立即崩溃
-
strlen(*arr)几乎总是崩溃:- 地址97(0x61)在几乎所有系统中都是无效地址
- 尝试访问这个地址会立即触发硬件异常(段错误)
- 程序在执行
strlen时就终止,printf根本不会执行
代码2:
int main()
{char arr[] = "abcdef";printf("%d\n", strlen(arr));//6--arr是数组首元素的地址,直到遇到'\0'停止printf("%d\n", strlen(arr + 0));//6--arr+0是数组首元素的地址,直到遇到'\0'停止//printf("%zd\n", strlen(*arr));//系统崩溃--arr是数组首元素的地址,*arr是数组首元素-a-ASCII值为97//printf("%zd\n", strlen(arr[1]));//系统崩溃--arr[1]是数组第二个元素-b-ASCII码值为98printf("%d\n", strlen(&arr));//6--&arr是数组的地址,也是从第一个元素向后找'\0'printf("%d\n", strlen(&arr + 1));//随机值--&arr是数组的地址,&arr跳过了整个数组,造成了越界访问printf("%d\n", strlen(&arr[0] + 1));//5--&arr[0]+1是数组第二元素的地址,直到遇到'\0'停止return 0;
}运行结果为:

代码3:
int main()
{char* p = "abcdef";printf("%d\n", strlen(p));//6--p指向的是a的地址,直到找到'\0'printf("%d\n", strlen(p + 1));//5--p+1指向的是b的地址,直到找到'\0'//printf("%d\n", strlen(*p));//系统崩溃--p指向的是a的地址,*p就是a//printf("%d\n", strlen(p[0]));//系统崩溃--p[0]是首元素aprintf("%d\n", strlen(&p));//随机值printf("%d\n", strlen(&p + 1));//随机值printf("%d\n", strlen(&p[0] + 1));//5--&p[0]+1指向的是b的地址,直到找到'\0'return 0;
}运行结果为:

关键表达式解析:
-
&p:&p是取指针变量p本身的地址(不是它指向的内容)- 类型:
char**(指向字符指针的指针) - 假设
p存储在内存地址0x1000,则&p的值就是0x1000
-
&p + 1:- 指针加法会跳过整个指针类型的大小(64位系统上是8字节)
&p + 1=0x1000 + sizeof(char*)=0x1000 + 8=0x1008- 指向
p变量之后的下一个内存位置
strlen(&p+1) 的行为:
-
类型不匹配:
strlen()期望参数是const char*(指向字符的指针)- 但传入的是
char**(指向指针的指针) - 编译器可能产生警告(如你之前看到的 C6328 警告)
-
内存访问:
strlen()会从地址0x1008开始读取内存- 逐字节读取,直到遇到
\0字符 - 问题:
0x1008处存储的是什么?这完全取决于程序内存布局
可能的结果:
-
随机值(最常见):
0x1008处可能存储着其他变量、未初始化数据或栈上的随机值strlen()会读取这些随机字节,直到偶然遇到\0- 输出值不可预测,可能是任意正整数
-
程序崩溃:
- 如果
0x1008指向不可访问的内存区域(如受保护的内核空间) - 会导致段错误(Segmentation Fault)
- 如果
-
特定平台下的"固定"值:
- 在某些特定编译器和内存布局下,可能得到"固定"的随机值
- 例如:如果
p后面紧跟着一个\0,可能输出0 - 但这种情况极不可靠,且依赖具体实现
二维数组
数组名的意义:
- sizeof(数组名),这⾥的数组名表⽰整个数组,计算的是整个数组的⼤⼩。
- &数组名,这⾥的数组名表⽰整个数组,取出的是整个数组的地址。
- 除此之外所有的数组名都表⽰⾸元素的地址。
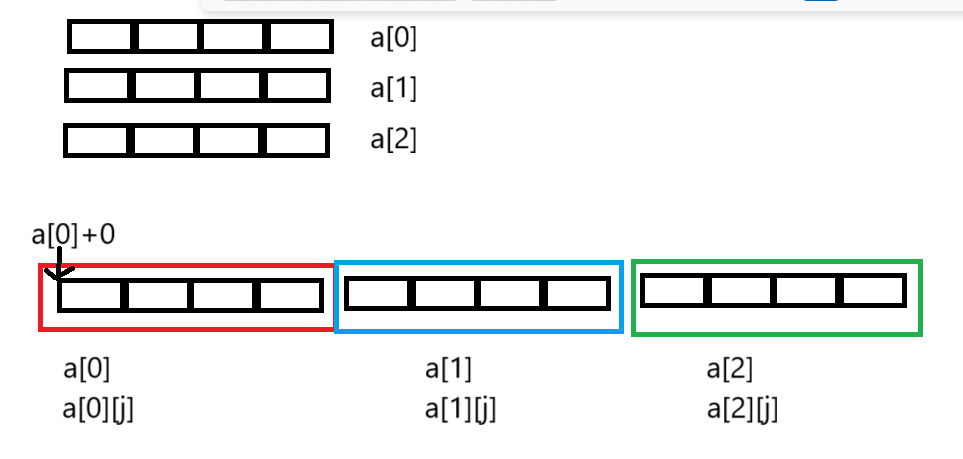
int main()
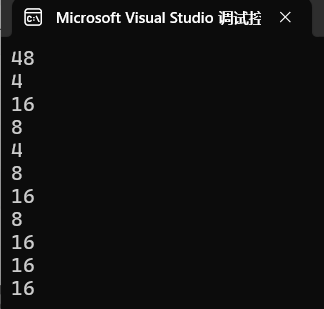
{int a[3][4] = { 0 };printf("%d\n", sizeof(a));//48--a代表着是数组的地址printf("%d\n", sizeof(a[0][0]));//4--a[0][0]是第一行第一列元素printf("%d\n", sizeof(a[0]));//16--a[0]是第一行的地址printf("%d\n", sizeof(a[0] + 1));//8/4--a[0]是第一行的数组名,但是a[0]并没有单独放在sizeof内部,所以这里的数组名a[0]就是//数组首元素的地址,就是&a[0][0],+1后a[0][1]的地址printf("%d\n", sizeof(*(a[0] + 1)));//4--a[0]+1是a[0][1]的地址,*(a[0]+1)是a[0][1]printf("%d\n", sizeof(a + 1));//4/8--a作为数组名并没有单独放在sizeof里,a表示的是数组首元素的地址,是二维数组首元素的地址,也就是//第一行的地址,a+1跳过一行,指向了第二行,是第二行的地址printf("%d\n", sizeof(*(a + 1)));//16--a+1是第二行的地址,*(a+1)就是第二行的大小//*(a+1)==a[1],a[1]是第二行的数组名,sizeof(*(a+1))相当于sizeof(a[1]),意思是把第二行的数组名单独放在sizeof内部,计算的是第二行的大小printf("%d\n", sizeof(&a[0] + 1));//4/8--&a[0]是第一行的地址,&a[0]+1是第二行的地址,相当于sizeof(a[1])printf("%d\n", sizeof(*(&a[0] + 1)));//16--*(&a[0] + 1)意思是对第二行的地址解引用,访问的是第二行printf("%d\n", sizeof(*a));//16--a是数组首元素的地址,是二维数组首元素的地址,也就是第一行的地址,*a就是第一行printf("%d\n", sizeof(a[3]));//16--a[3]是第四行的数组名,计算的是第四行的大小,a[3]无需真实存在,仅仅通过类型的判断就能算出长度return 0;
}运行结果为:
指针运算笔试题解析
题目1:
#include <stdio.h>
int main()
{int a[5] = { 1, 2, 3, 4, 5 };int* ptr = (int*)(&a + 1);printf("%d,%d", *(a + 1), *(ptr - 1));return 0;
}
//程序的结果是什么?题目解释为:
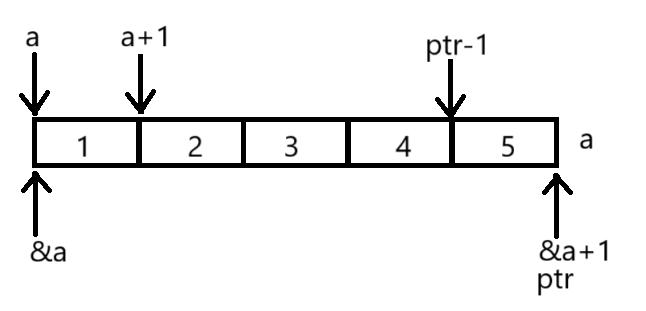
运行结果为:

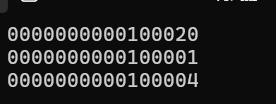
题目2:
// 在X86环境下
//假设结构体的⼤⼩是20个字节
//程序输出的结构是啥?
struct Test
{int Num;char* pcName;short sDate;char cha[2];short sBa[4];
}*p = (struct Test*)0x100000;
int main()
{printf("%p\n", p + 0x1);printf("%p\n", (unsigned long)p + 0x1);printf("%p\n", (unsigned int*)p + 0x1);return 0;
}题目解释为:
0x1再16进制中的结果为1
结构体指针加1,跳过一个结构体,也就是20个字节:0x100000+1-->0x100014
整型加1,就是加1:0x100000+1-->0x100001
int*类型加1,就是加了一个整型,4个字节:0x100000+4-->0x100004
运行结果为:
题目3:
#include <stdio.h>
int main()
{int a[3][2] = { (0, 1), (2, 3), (4, 5) };int *p;p = a[0];printf( "%d", p[0]);return 0;
}
题目解释为:
在二维数组中,每一行是用{}分隔的,而不是()
逗号表达式的结果是最后一个表达式的结果也就是{1,3,5}
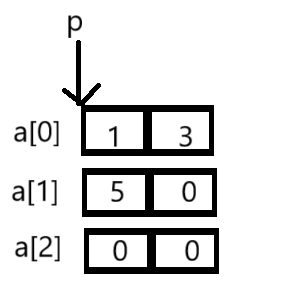
a[0]是第一行的数组名,数组名表示的首元素的地址,其实就是&a[0][0]的地址,p[0]==*(p+0),就是首元素
运行结果为:

题目4:
//假设环境是x86环境,程序输出的结果是啥?
#include <stdio.h>
int main()
{int a[5][5];int(*p)[4];p = a;printf( "%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);return 0;
}
题目解释为:
%d--类型是:int(*)[5]
%p--类型是:int(*)[4]
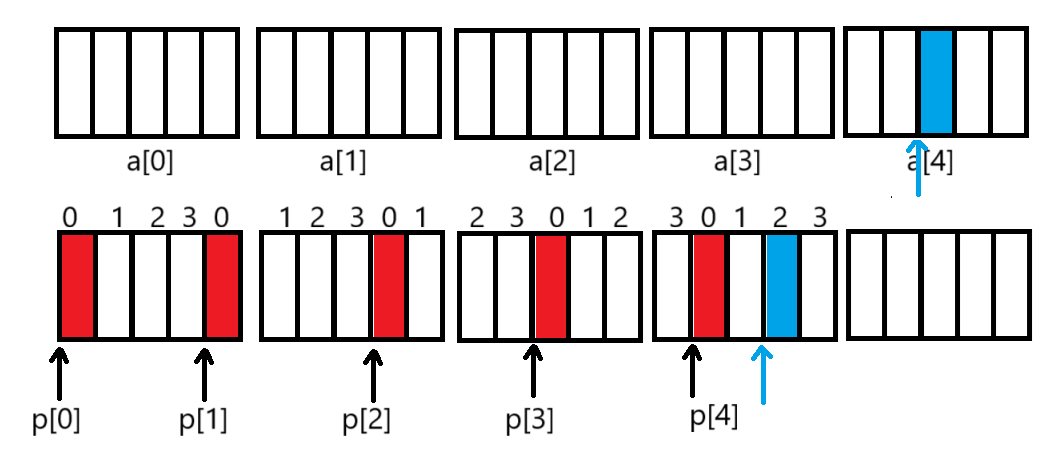
&p[4][2] - &a[4][2]==-4
100000000000000000000100--原码
111111111111111111111011--反码
111111111111111111111100--补码
FFFFFFFFFFFFFFFC运行结果为:
题目5:
#include <stdio.h>
int main()
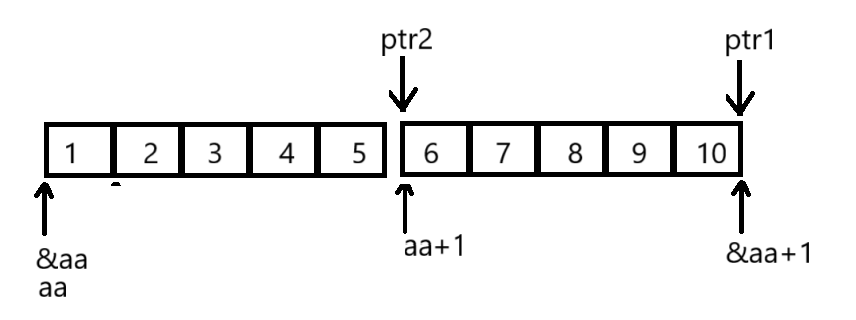
{int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };int* ptr1 = (int*)(&aa + 1);int* ptr2 = (int*)(*(aa + 1));printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));return 0;
}题目解释为:
*(aa+1)-->aa[1]:aa[1]是第二行数组名,数组名表示的是首元素的地址,aa[1]也是&aa[1][0]
运行结果为:
题目6:
#include <stdio.h>
int main()
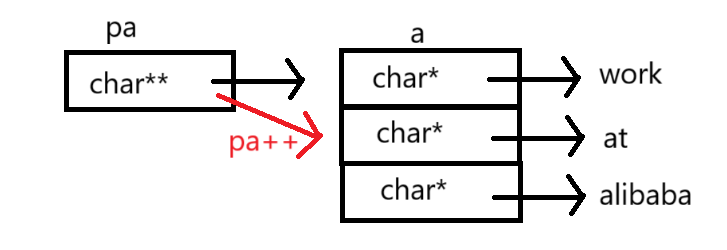
{char* a[] = { "work","at","alibaba" };char** pa = a;pa++;printf("%s\n", *pa);return 0;
}题目解释为:
%s是打印字符串,给一个地址,从这个地址向后打印字符串,直到'\0'
运行结果为:
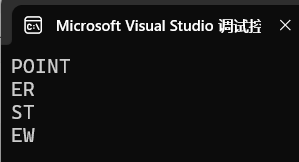
题目7:
#include <stdio.h>
int main()
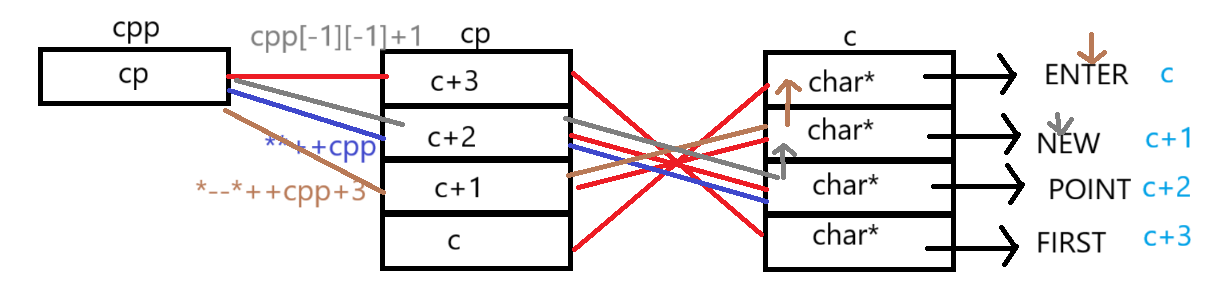
{char *c[] = {"ENTER","NEW","POINT","FIRST"};char**cp[] = {c+3,c+2,c+1,c};char***cpp = cp;printf("%s\n", **++cpp);printf("%s\n", *--*++cpp+3);printf("%s\n", *cpp[-2]+3);printf("%s\n", cpp[-1][-1]+1);return 0;
}
题目解释为:
加法的优先级最低
++cpp和--cpp时cpp才会移动,表达式不动
*{--*(++cpp)}+3==*{--(c+1)}+3==*c+3==ER
运行结果为:
总结:
通过本文对sizeof和strlen的对比以及数组和指针笔试题的详细解析,我们可以得出以下几点关键认识:
sizeof与strlen的本质区别
- sizeof是运算符,用于计算数据类型或变量所占内存空间大小,在编译时确定结果
- strlen是函数,用于计算字符串长度,遇到'\0'停止,在运行时确定结果
- 对于数组,sizeof计算整个数组大小;strlen仅适用于字符串,计算到第一个'\0'前的字符数
数组与指针的核心关系
- 数组名在大多数情况下代表首元素地址,但sizeof(数组名)和&数组名时例外
- 指针可以进行加减运算,但要注意步长由指针类型决定
- 数组作为函数参数会退化为指针,丢失长度信息
指针运算的关键要点
- 指针加减n,实际地址变化为n*sizeof(指针类型)
- 指针间减法得到的是元素个数,而非字节数
- 指针比较操作需确保指向同一数组或有合理关联
- 指针与整数运算时要注意边界条件,避免越界
实践建议
- 在处理字符串时,明确使用场景:需要内存大小用sizeof,需要字符串长度用strlen
- 理解内存布局对指针运算至关重要,建议画图辅助理解
- 注意数组与指针的微妙差异,特别是在参数传递和sizeof操作时
- 多做指针运算练习,培养对内存地址和数据的直观理解
掌握这些知识点不仅能帮助你应对各种笔试面试,更能提升你在C语言编程中对内存管理的精准把控能力,为后续学习更复杂的系统编程打下坚实基础。