嘉兴中元建设网站有效的引流推广方法
llamacpp 简介
llama.cpp 的主要目标是通过最小的设置,实现 LLM 推理,在各种硬件上(无论是本地还是云端)提供最先进的性能。
- 纯 C/C++实现,无任何依赖
- 苹果 M1/M2 芯片(Apple silicon)优化,支持 Arm NEON、Accelerate 和 Metal 框架
- 支持 x86 架构的 AVX、AVX2、AVX512 和 AMX 指令集
- 支持 1.5-bit、2-bit、3-bit、4-bit、5-bit、6-bit 和 8-bit 整数量化,实现更快速的推理和内存减少
- 支持在 NVIDIA GPU 上运行 LLM 的自定义 CUDA 内核(通过 HIP 支持 AMD GPU,通过 MUSA 支持 Moore Threads MTT GPU)
- 支持 Vulkan 和 SYCL 后端
- 支持 CPU+GPU 混合推理,加速超过总 VRAM 容量的大模型
- llama.cpp 项目是开发 ggml 库新特性的主要平台。
模型准备
由于 Debian 自带的 Python 库版本较旧,需要首先创建一个 python 的虚拟环境,然后安装最新依赖:
python3 -m venv llama_test
source llama_test/bin/activate
pip install -r ./requirements.txt

然后,需要安装 Git LFS 支持,否则克隆的模型数据文件会不完整:
apt-get install git-lfs
git lfs install

在这里,我选择 DeepSeek-R1-Distill-Qwen-14B 模型作为示例,这是 16GB RAM 在 4-bit 量化方法下能够处理的最大模型:
git clone https://huggingface.co/deepseek-ai/DeepSeek-R1-Distill-Qwen-14B

将模型转换为 gguf 格式:
./convert_hf_to_gguf.py ../DeepSeek-R1-Distill-Qwen-14B --outfile ../models/DeepSeek-R1-Distill-Qwen-14B-FP16.gguf
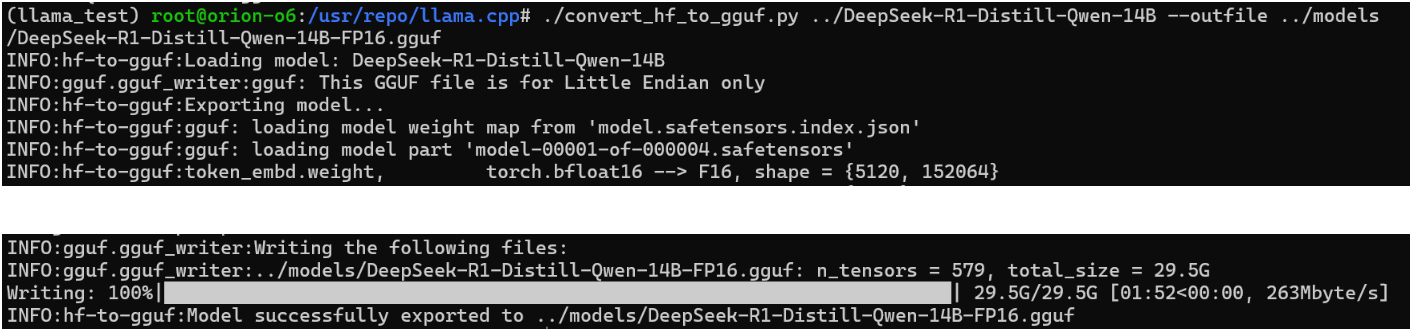
接下来,我们需要将模型从 FP16 量化到更低的精度类型,以获得更好的性能。
我们可以在 KleidiAI 的官网找到支持加速的常见数据类型:
KleidiAI supports matrix multiplication of models across FP32, FP16, INT8, and INT4 formats.
似乎 Q4_K_M 这一更常用的平衡型量化类型在这里有一些问题,所以我们选择 Q4_0 作为量化类型:

将模型量化为 Q4_0:
./llama-quantize ../../../models/DeepSeek-R1-Distill-Qwen-14B-FP16.gguf ../../../models/DeepSeek-R1-Distill-Qwen-14B-Q4_0.gguf Q4_0
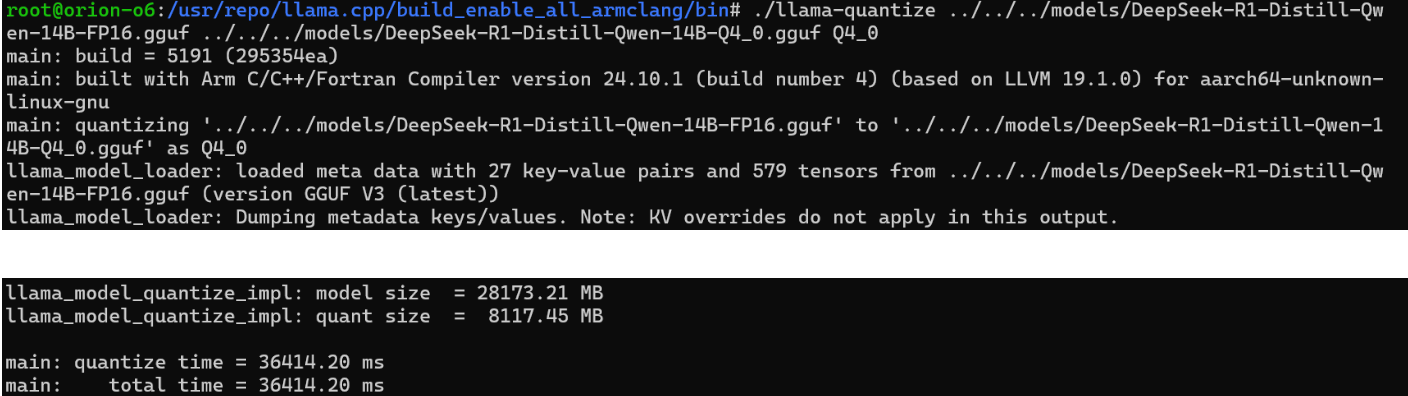
llamacpp-cpu
14B 模型推理速度勉强可用,如果希望获得更流畅的体验,建议选择 1.5B 或 7B 模型。
Armv9.2-a acceleration##
首先,我们需要从 GitHub 克隆 llamacpp 代码库:
git clone https://github.com/ggml-org/llama.cpp.git
请注意,Debian 自带的 gcc/g++版本已过时,建议使用 Arm 官方的 ACfL 编译器。
下载 Arm Compiler for Linux:
curl -L https://developer.Arm.com/-/cdn-downloads/permalink/Arm-Compiler-for-Linux/Package/install.sh -o install.sh
chmod +x ./install.sh
由于 Ubuntu-22.04 基于 Debian 12,我们选择 Ubuntu-22.04:

选择最新版本:

安装脚本会自动下载必要的软件包并进行安装。
安装完成后,需要配置环境以使用 ACfL:
apt-get install environment-modules
source /etc/profile.d/modules.sh
module use /opt/Arm/modulefiles
module load acfl/24.10.1
module load Armpl/24.10.1

生成 Makefile:
cmake -B build_Armv9 -DCMAKE_C_COMPILER=Armclang -DCMAKE_CXX_COMPILER=Armclang++ -DGGML_CPU_Arm_ARCH=Armv9.2-a -DGGML_CPU_AARCH64=ON -DGGML_NATIVE=OFF
从 Makefile 构建:
cmake --build build_Armv9 --config Release --parallel 12

已启用的特性:

进行 Armv9.2-a 下的 llama-bench 性能评估测试:

KLEIDIAI acceleration
KleidiAI 是一个为 AI 工作负载优化的微内核库,专门为 Arm CPU 设计。这些微内核能提升性能,并可以通过 CPU 后端启用。
生成带 KleidiAI 支持的 Makefile:
cmake -B build_enable_all_Armclang -DCMAKE_C_COMPILER=Armclang -DCMAKE_CXX_COMPILER=Armclang++ -DGGML_CPU_Arm_ARCH=Armv9.2-a -DGGML_CPU_KLEIDIAI=ON -DGGML_KLEIDIAI_SME=ON -DGGML_CPU_AARCH64=ON -DGGML_NATIVE=OFF
从 Makefile 构建:
cmake --build build_enable_all_Armclang --config Release --parallel 12
llamacpp 需要手动设置环境变量来启用 SME:
llama.cpp/ggml/src/ggml-cpu/kleidiai/kleidiai.cpp:
const char *env_var = getenv("GGML_KLEIDIAI_SME");
...
if (env_var) {sme_enabled = atoi(env_var);
}
所以我们需要通过设置环境变量 GGML_KLEIDIAI_SME=1 来手动启用 SME 微内核:
export GGML_KLEIDIAI_SME=1
通过 llama_cli 的输出可以看出,KleidiAI 已被启用:

已启用的特性:

进行 KleidiAI 加速的 llama-bench 测试:
./llama-bench -m ../../../models/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf

llamacpp GPU
Vulkan acceleration##
llamacpp 支持通过 Vulkan API 进行 GPU 加速。
安装 Vulkan SDK 支持:
apt-get install libvulkan-dev
apt-get install vulkan-tools
随后确保一下 Vulkan 的环境配置正确:
vulkaninfo | grep deviceName

生成带 Vulkan 支持的 Makefile:
cmake -B build_vulkan -DCMAKE_C_COMPILER=Armclang -DCMAKE_CXX_COMPILER=Armclang++ -DGGML_VULKAN=1 -DGGML_CPU_Arm_ARCH=Armv9.2-a -DGGML_NATIVE=OFF
从 Makefile 构建:
cmake --build build_vulkan --config Release --parallel 12
Tensor load:
Vulkan 后端下的 llama-bench 测试:
./llama-bench -m ../../../models/DeepSeek-R1-Distill-Qwen-14B-Q4_K_M.gguf

实际应用
llama-cli##
llama.cpp 提供了命令行界面来和生成式 AI 交互:
./llama-cli -m ../../../models/DeepSeek-R1-Distill-Qwen-14B-Q4_0.gguf
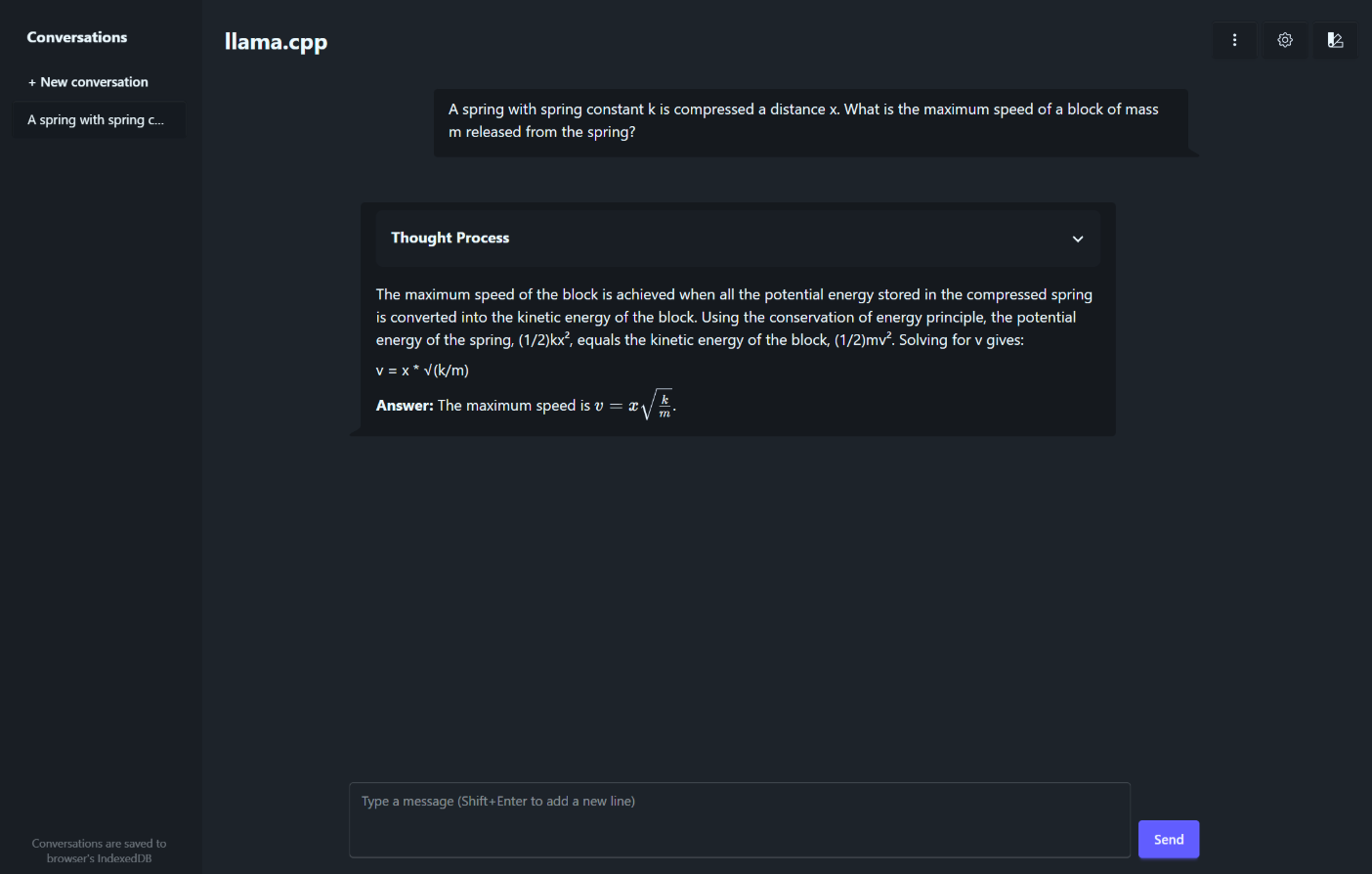
输入一个示例问题:
> A spring with spring constant k is compressed a distance x. What is the maximum speed of a block of mass m released from the spring?
生成得到的回答:
<think>
Okay, so I have this problem here: A spring with spring constant k is compressed a distance x. What is the maximum speed of a block of mass m released from the spring? Hmm, let's try to figure this out step by step.First, I remember that when a spring is compressed or stretched, it stores potential energy. The formula for elastic potential energy is (1/2)kx², right? So, if the spring is compressed by x, the potential energy stored would be (1/2)kx².Now, when the block is released, the spring will push the block, converting that potential energy into kinetic energy. Kinetic energy is given by (1/2)mv², where m is the mass and v is the velocity. Since energy is conserved in the system (assuming no friction or air resistance), the potential energy stored in the spring should equal the kinetic energy of the block when it's moving the fastest.So, setting those two equal: (1/2)kx² = (1/2)mv². Hmm, I can cancel out the (1/2) on both sides, which leaves kx² = mv². Then, solving for v, I get v = sqrt(kx²/m). Wait, that simplifies to v = x*sqrt(k/m). Is that right?Let me double-check. When the spring is compressed, it's storing energy, and when the block is released, all that energy goes into the block's motion. So, yes, the potential energy equals the kinetic energy at maximum speed. That makes sense.But wait, is there any consideration about the conservation of energy here? I think so. Since the spring is doing work on the block, transferring its potential energy into kinetic energy, and assuming no other forces like friction are acting, which isn't specified here, so I think it's safe to assume that all the potential energy becomes kinetic.Alternatively, could I think about this using forces and acceleration? Well, when the block is released, it will accelerate due to the force from the spring, which is F = -kx, but that's more of a dynamic approach. However, in that case, I would need to solve the differential equation for the motion, which is a bit more complicated.But since energy conservation is straightforward here, I think the first approach is better. It's simpler and gets me to the answer without too much hassle.So, just to recap: The spring's potential energy is (1/2)kx². This is converted into kinetic energy (1/2)mv². Equate them, solve for v, get v = sqrt(kx²/m), which simplifies to v = x*sqrt(k/m). That should be the maximum speed.I think that's the answer. Let me write it in a box as they usually do.**Final Answer**
The maximum speed of the block is \boxed{x\sqrt{\dfrac{k}{m}}}.
</think>To determine the maximum speed of a block of mass \( m \) released from a spring compressed by a distance \( x \), we start by considering the potential energy stored in the spring. The potential energy is given by:\[
\text{Potential Energy} = \frac{1}{2}kx^2
\]When the block is released, this potential energy is converted into kinetic energy. The kinetic energy of the block is given by:\[
\text{Kinetic Energy} = \frac{1}{2}mv^2
\]By conserving energy, we equate the potential energy to the kinetic energy:\[
\frac{1}{2}kx^2 = \frac{1}{2}mv^2
\]We can cancel the \(\frac{1}{2}\) terms on both sides:\[
kx^2 = mv^2
\]Solving for \( v \):\[
v^2 = \frac{kx^2}{m}
\]\[
v = \sqrt{\frac{kx^2}{m}}
\]\[
v = x\sqrt{\frac{k}{m}}
\]Thus, the maximum speed of the block is:\[
\boxed{x\sqrt{\dfrac{k}{m}}}
\]

llama-server
如果你更喜欢图形界面而不是纯命令行界面:
0.0.0.0 这里表示 llama-server 接受来自所有 IP 地址的请求。
./llama-server -m ../../../models/DeepSeek-R1-Distill-Qwen-14B-Q4_0.gguf --port 80 --host 0.0.0.0
这样部署以后, 家庭中的所有设备就都可以直接访问开发板的 IP 地址来和 AI 进行对话和交流:
结语
不同的加速方法适用于不同的数据类型和数据规模,性能很难直接对比,因此这里我就不把它们放在一起做性能比较了。
借助 “星睿 O6”AI PC 开发套件 提供的主流硬件加速方式,可以将“星睿 O6”轻松打造成为家中的家庭 AI 终端。