长尾识别BBN方法
1 代码实现



2 原理解析
长尾识别是视觉识别中的一个重要研究方向,BBN(Bilateral-Branch Network)模型就是为了解决数据长尾分布问题而提出的一个有效方法。下面我们来详细了解它的原理、实现方法,并会提供一个简单的代码示例。
BBN 原理详解
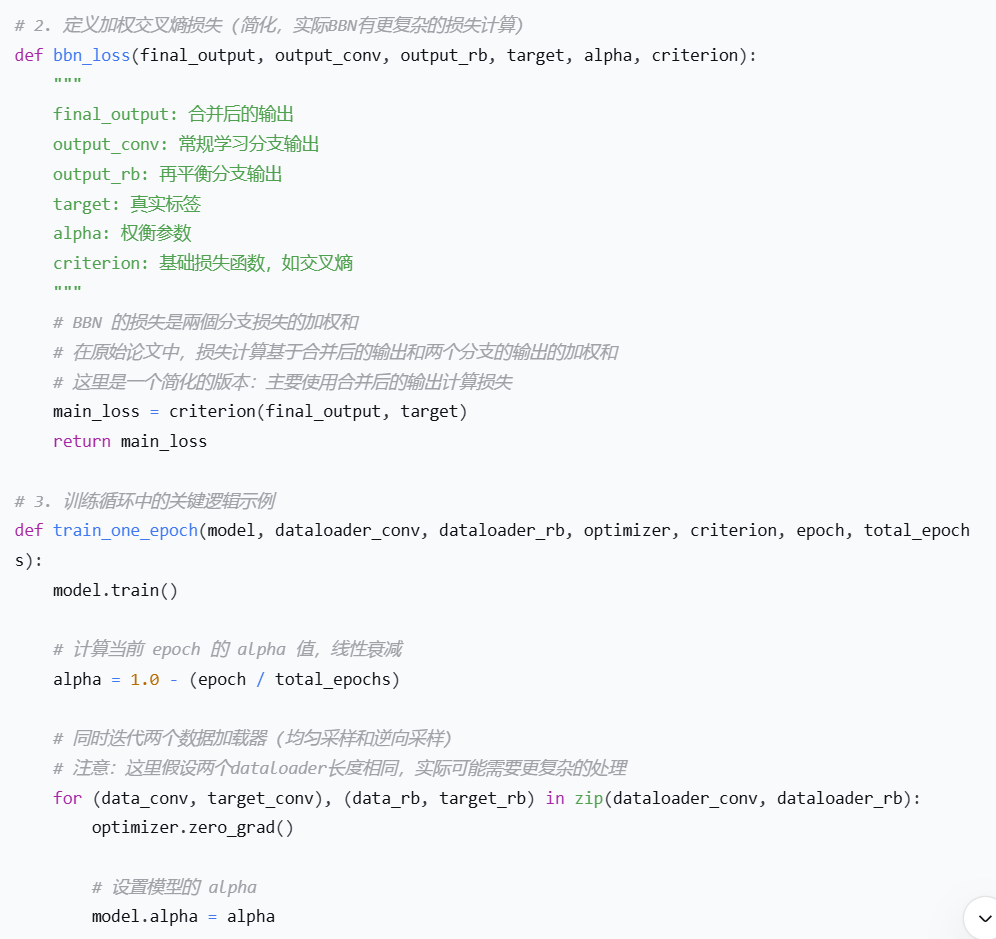
BBN 的核心思想是通过双边分支网络结构和累积学习策略,来平衡表征学习和分类器学习,从而在改善尾类性能的同时,不损害模型的整体表征能力。
背景与动机
现实世界的数据集往往遵循长尾分布,即少数类别(头部类别)拥有大量样本,而多数类别(尾部类别)只有少量样本-6。这种极端的不平衡会导致模型严重偏向头部类别。
传统的类别再平衡方法(如再采样和代价敏感再加权)虽然在一定程度上通过调整分类器来缓解问题,但研究者发现,这些策略在提升分类器学习的同时,可能会损害模型学习到的深度特征的表征能力-1-6。
BBN 的设计正是为了兼顾表征学习和分类器学习-1。
核心组件
BBN 模型主要包含三个关键部分:
-
双边分支结构:
-
常规学习分支(Conventional Learning Branch):使用均匀采样从原始长尾分布中获取数据,专注于学习通用的图像表征。这些表征对所有类别都应具有良好的区分性。
-
再平衡分支(Re-Balancing Branch):使用逆向采样,更关注尾部类别中的数据,目标是为尾部数据学习更好的特征和分类器,从而缓解类别不平衡。
-
-
累积学习(Cumulative Learning)策略:
-
这是 BBN 的"灵魂",通过一个自适应权衡参数 α 来实现。
-
参数 α 随着训练周期(epoch)的增加而逐渐减小。
-
训练初期,α 接近 1,模型主要依赖常规学习分支学习通用表征。
-
训练后期,α 逐渐减小,模型逐渐增加对再平衡分支的关注,更多学习如何区分尾部类别。
-
这种逐渐过渡的方式确保了模型在关注尾部数据的同时,不破坏已学到的通用表征。
-
-
分类器与损失函数:
-
两个分支的特征经过加权(α 和 1-α)后,分别通过它们自己的分类器,然后将输出logits相加,再计算交叉熵损失-6。
-
最终的损失函数是两个分支损失的加权和-6。


-