Soul App AI开源播客语音合成模型SoulX-Podcast
目录
前言
一、从一次成功的虚拟人直播说起
二、AI如何学会“聊天”?SoulX-Podcast的技术秘诀
2.1 一个强大的“大脑”和一个精巧的“声带”
2.2 像“剧本”一样学习,实现超长对话
2.3 让AI拥有“灵魂”:可控的笑声与方言
三、不止于播客:通用场景同样出色
结语:AI语音的下一站,是“情感纽带”

🎬 攻城狮7号:个人主页
🔥 个人专栏:《AI前沿技术要闻》
⛺️ 君子慎独!
🌈 大家好,欢迎来访我的博客!
⛳️ 此篇文章主要介绍 播客语音合成模型SoulX-Podcast
📚 本期文章收录在《AI前沿技术要闻》,大家有兴趣可以自行查看!
⛺️ 欢迎各位 ✔️ 点赞 👍 收藏 ⭐留言 📝!
前言
在过去的几年里,我们见证了AI语音合成(TTS)技术的飞速发展。从最初生硬的“机器人腔”,到如今足以以假乱真的流畅独白,AI已经学会了如何“说话”。但是,“说话”和“聊天”之间,还隔着一道鸿沟。
传统的AI语音,更像一个优秀的播音员在朗读稿件,吐字清晰,语调平稳,但缺少了真实对话中那种你来我往的节奏感、微妙的情绪变化和不经意间的笑声、叹息。当场景从一个人的独白,扩展到两个或多个人七嘴八舌的播客、广播剧或日常闲聊时,大多数AI模型就“露馅”了。
它们很难处理多轮对话中的上下文联系,无法保持长时间的音色稳定,更不用说在不同角色间进行自然流畅的切换。正是这个瓶颈,限制了AI语音在播客、虚拟人直播、情感陪伴等更需要“人情味”的场景中的应用。
近日,社交平台Soul App联合西北工业大学和上海交通大学,开源了一款专为解决上述痛点而生的语音播客生成模型——SoulX-Podcast。它不仅能稳定生成超过60分钟的多人对话,更在多语种、多方言甚至笑声、叹息等“副语言”的控制上,取得了惊人的效果。

一、从一次成功的虚拟人直播说起
SoulX-Podcast的诞生,并非一个纯粹的学术研究项目,而是源于一次真实而成功的商业实践。
2025年9月,Soul App上的两位知名虚拟人——孟知时与屿你——在平台的群聊派对中,进行了一场长达40分钟的AI语音对话直播。在没有任何额外推广的情况下,这场活动迅速引爆社区,房间互动热度刷新了平台纪录。
这次成功的试水,让Soul团队深刻意识到:“虚拟IP + AI语音对话”正在成为虚拟内容生态的一个重要增长点。它不仅能极大地丰富虚拟人的人格魅力,更揭示了AI在内容创作和社交互动中的巨大潜能。然而,当时业界能够稳定支持这种多轮自然对话的开源模型还非常匮乏。于是,Soul团队决定将自己的研发成果开源,与整个AIGC社区一同探索AI语音的未来。
二、AI如何学会“聊天”?SoulX-Podcast的技术秘诀
相比传统的语音合成,生成一段多人播客的难度是指数级增长的。它不仅要求声音好听,更要求AI具备“情商”——理解对话的上下文,并用恰当的韵律、节奏和情绪来回应。SoulX-Podcast通过一套精巧的系统设计,攻克了这些难题。
2.1 一个强大的“大脑”和一个精巧的“声带”
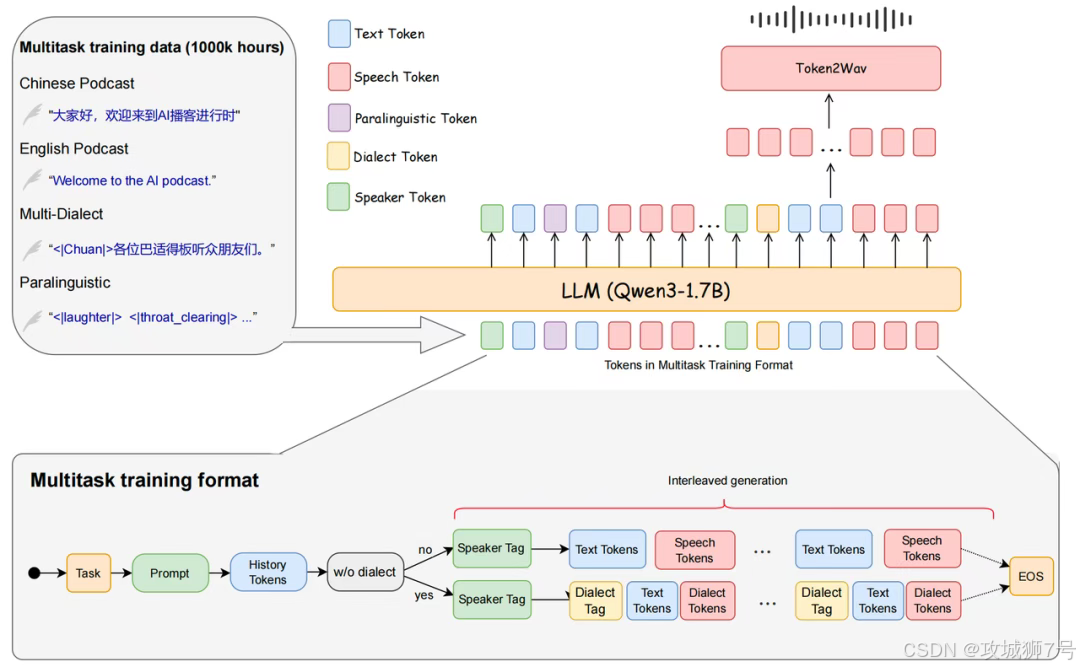
SoulX-Podcast的底层架构,可以通俗地理解为“一个大脑 + 一个声带”。
(1)大脑:它使用了一个强大的大语言模型(Qwen3-1.7B)作为语义理解的核心。这使得模型从一开始就继承了强大的语言理解能力,能读懂对话文本的深层含义和上下文关系。
(2)声带:在理解了文本之后,它通过一种名为Flow Matching的先进声学建模技术,将语义信息转化为真实、自然的声波。
2.2 像“剧本”一样学习,实现超长对话
为了让模型能处理长达一小时甚至更久的多人对话,并始终保持每个角色的音色稳定、切换自然,SoulX-Podcast采用了一种巧妙的“交替排布”策略。
在训练时,数据被整理得像一个剧本:<发言人1><文本><音频><发言人2><文本><音频>...。通过学习这种格式,模型不仅知道了每句话是谁说的、说了什么,还学会了不同发言人之间的语气衔接和对话节奏。
此外,为了让模型能“记住”更长的对话历史,团队还使用了一个聪明的技巧:在处理早期对话时,有策略地丢弃一些音频信息,只保留文本。这就像我们回忆一段久远的对话,可能记不清当时确切的语调,但还记得聊了什么内容。这种方式极大地提升了模型的“记忆”效率,使其在生成90分钟的长篇播客时,依然能保持出色的连贯性和一致性。
2.3 让AI拥有“灵魂”:可控的笑声与方言
SoulX-Podcast最令人惊艳的两个特性,是它对“副语言”和“方言”的驾驭能力。
(1)副语言(Paralinguistic Cues):在真实交流中,笑声、叹息、呼吸、清嗓子等声音是传递情绪、增强临场感的重要元素。团队通过AI工具,从海量语料中精准地标注了这些副语言事件,并教会了模型如何在对话中恰当地使用它们。这使得生成的语音不再是冰冷的文字复读,而是充满了“人味儿”。
(2)多种方言与跨方言克隆:模型目前已经支持粤语、四川话、河南话等主流方言。更神奇的是,它实现了“跨方言音色克隆”。这意味着,你只需要提供一段某人的普通话语音样本,模型就能用这个人的音色,说出地道流利的四川话或粤语。这一功能极大地拓宽了内容创作的可能性,为方言内容的AIGC生成打开了全新的大门。
三、不止于播客:通用场景同样出色
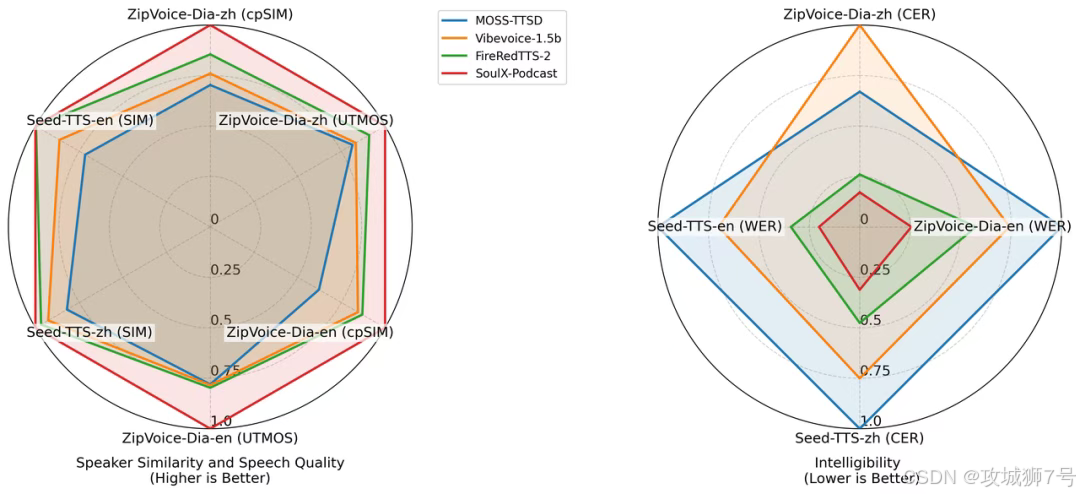
尽管SoulX-Podcast是为复杂的播客场景而设计,但“杀鸡用牛刀”,它在传统的单人语音合成和零样本语音克隆(只用一小段音频就复制某个声音)任务中,同样表现优异。
在多个客观评测基准上,无论是在语音的可懂度(字词听得清不清)还是音色的相似度(声音像不像)方面,SoulX-Podcast都取得了当前最佳(SOTA)的成绩,超越了许多专为单人TTS设计的模型。
结语:AI语音的下一站,是“情感纽带”
SoulX-Podcast的开源,其意义远不止于一个更强大的语音合成工具。它代表了AI语音技术发展的一个重要方向:从追求“清晰度”和“流畅度”,转向追求“真实感”、“表现力”和“情感温度”。
正如Soul团队所观察到的,声音是传递情感、建立陪伴感最直接的媒介。当AI能够像真人一样参与到多姿多彩的对话中时,它就不再仅仅是一个工具,而有潜力成为我们的“虚拟伴侣”、内容创作的“AI搭档”,或是在虚拟世界中富有魅力的“社交达人”。
通过将这项核心能力开源,Soul不仅展示了其在“AI+社交”领域的深厚积累,也为全球的开发者和创作者提供了一块坚实的基石。未来,基于SoulX-Podcast,我们有理由期待一个更加生动、更加充满人情味的AI语音新时代的到来。
Demo Page: https://soul-ailab.github.io/soulx-podcast
Technical Report: https://arxiv.org/pdf/2510.23541
Source Code: https://github.com/Soul-AILab/SoulX-Podcast
HuggingFace: https://huggingface.co/collections/Soul-AILab/soulx-podcast
看到这里了还不给博主点一个:
⛳️ 点赞☀️收藏 ⭐️ 关注!
💛 💙 💜 ❤️ 💚💓 💗 💕 💞 💘 💖
再次感谢大家的支持!
你们的点赞就是博主更新最大的动力!