智源:目标分解和路径提示的奖励学习

📖标题:InfoFlow: Reinforcing Search Agent Via Reward Density Optimization
🌐来源:arXiv, 2510.26575
🌟摘要
信息寻求是人类的基本要求。然而,现有的LLM代理严重依赖开放web搜索,这暴露了两个基本弱点:在线内容嘈杂和不可靠,许多现实世界的任务需要web无法获得的精确、特定领域的知识。模型上下文协议 (MCP) 的出现现在允许代理与数千个专门的工具进行交互,这似乎解决了这一限制。然而,目前尚不清楚代理是否可以有效地利用这些工具,更重要的是,它们是否可以与通用搜索集成以解决复杂的任务。因此,我们引入了InfoMosaic-Bench,这是第一个专门用于工具增强代理中寻找多源信息的基准。涵盖六个代表性领域(医学、金融、地图、视频、网络和多域集成),InfoMosaic-Bench 要求代理将通用搜索与特定领域的工具相结合。任务是使用 InfoMosaic-Flow 合成的,这是一个可扩展的管道,它将任务条件置于经过验证的工具输出中,强制执行跨源依赖关系,并过滤掉可以通过琐碎查找解决的快捷方式案例。这种设计保证了可靠性和非平凡性。使用14个最先进的LLM代理的实验揭示了三个发现:(i)单独的web信息是不够的,GPT-5只实现了38.2%的准确率和67.5%的传递率;(ii)领域工具提供选择性但不一致的好处,提高了一些领域,同时降低了其他领域;(iii) 22.4%的故障来自于不正确的工具使用或选择,强调当前的llm仍然很难处理即使是基本的工具处理。
🛎️文章简介
🔸研究问题:如何提高大语言模型(LLM)在深度搜索任务中的奖励密度,以增强其训练效率和推理能力?
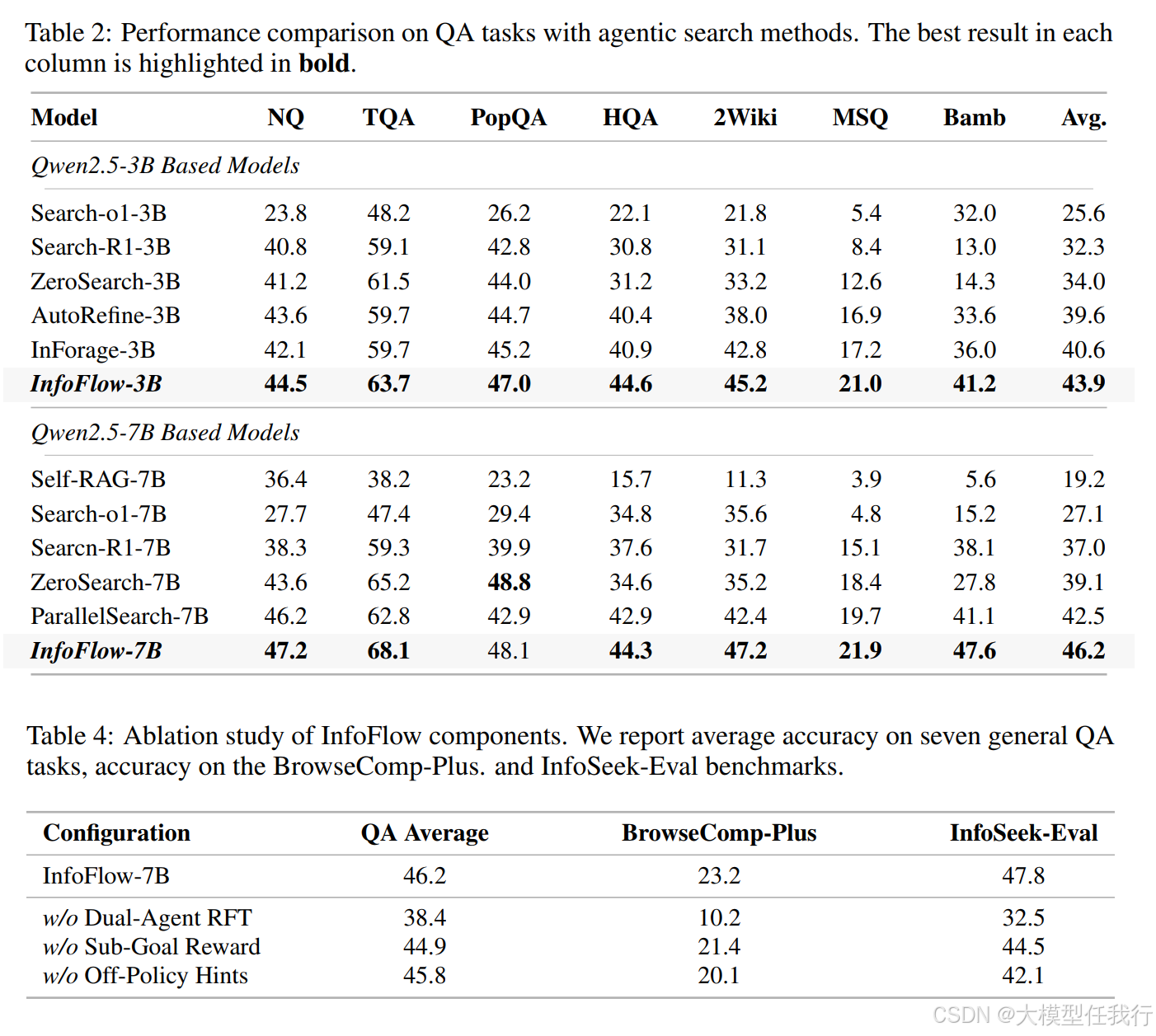
🔸主要贡献:论文提出了InfoFlow,一个双代理框架,通过优化奖励密度,显著提升了LLM在复杂信息检索任务中的性能。
📝重点思路
🔸采用奖励密度优化(Reward Density Optimization)方法,将复杂任务分解为子目标并提供中间奖励,以提高学习信号的密集性。
🔸引入路径提示(Pathfinding Hints),利用专家模型生成引导查询,以帮助代理在困难的推理步骤中更有效地探索。
🔸实施轨迹精炼(Trajectory Refinement),通过两个代理的协作(研究者代理和精炼代理),提高信息处理的效率和准确性。
🔎分析总结
🔸InfoFlow通过子目标奖励塑造,在训练过程中提供密集的反馈,使得代理能够通过解决子目标获得部分奖励,从而增强学习信号。
🔸路径提示有效降低了探索障碍,提高了成功路径的数量,增强了代理的学习效果。
🔸轨迹精炼显著减少了上下文长度,帮助研究者聚焦于高层次推理,从而获得更高的初始奖励和更快的推理速度。
💡个人观点
论文提出了一个结合子目标奖励、路径提示和双代理架构的综合方法,成功地应对了深度搜索领域中奖励稀疏的问题。
🧩附录