接口自动化测试SOP标准流程
课程:B站大学
接口自动化测试SOP流程
接口自动化测试-pytest
- 第一章 文档概述
- 1.1 背景
- 1.2 适用范围
- 2.2 技术栈
- 第三章 目录结构与命名规范
- 3.1 目录结构
- 3.2 命名规范
- 3.3 代码风格
- 3.4 Git提交规范
- 第四章 环境与依赖管理
- 4.1 目标
- 4.2 依赖管理
- 4.3 环境隔离
- 4.4 配置管理
- 第五章 框架与用例编写规范
- 5.1 框架分层
- 5.2 用例模板
- 5.3 参数化
- 第六章 数据与环境管理规范
- 6.1 目标
- 6.2 生命周期
- 6.3 数据标识
- 6.4 幂等性
- 6.5 环境切换
- 第七章 报告与日志规范
- 7.1 Allure 报告
- 7.2 日志规范
- 第八章 CI/CD 流水线配置(阿里云效)
- 8.1 步骤概要
- 8.2 执行命令
- 8.3 触发方式
- 8.4 质量门禁
- 第九章 质量度量与持续改进
- 一、核心指标总览
- 二、实施建议(分阶段推进)
- 三、指标采集方法(简易版)
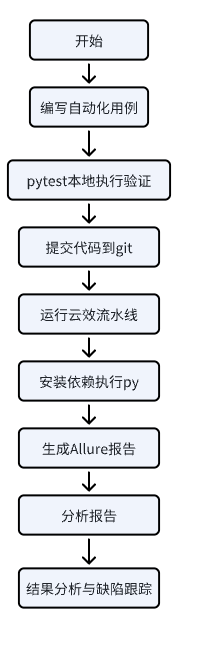
- SOP 执行流程图
- 暂时无法在飞书文档外展示此内容
- 实践是检验真理的唯一标准
第一章 文档概述
1.1 背景
随着业务系统服务化、微服务化,接口(API)已成为各系统的主要交互方式。传统手工接口测试存在:
- 测试周期长、人工成本高;
- 缺乏统一标准与复用机制;
- 接口变更难快速感知;
- 报告形式不统一,结果难追溯。
本 SOP 旨在建立标准化、可复用、可持续集成的接口自动化体系,实现结构统一、执行自动、结果可量化。
1.2 适用范围
| 项目类型 | 测试阶段 | 技术栈 | CI/CD 平台 |
|---|---|---|---|
| RESTful / RPC / GraphQL 后端服务 | 回归、冒烟、前置验证 | Python 3.10 + pytest + httpx/requests + allure + pydantic/jsonschema + docker + git + 云效(Jenkins) | 阿里云效 Yunxiao(流水线 API-Auto-Regression) |
第二章 体系架构与技术栈说明
2.1 分层架构
测试用例层(tests/)↓
业务逻辑层(business/)↓
接口驱动层(api/)↓
基础框架层(common/)↓
CI/CD 平台层(云效 Yunxiao)
各层职责清晰、单向依赖,保证高复用与低耦合。
2.2 技术栈
Python 3.10 + pytest + httpx/requests + allure + pydantic/jsonschema + docker+git +云效(Jenkins)
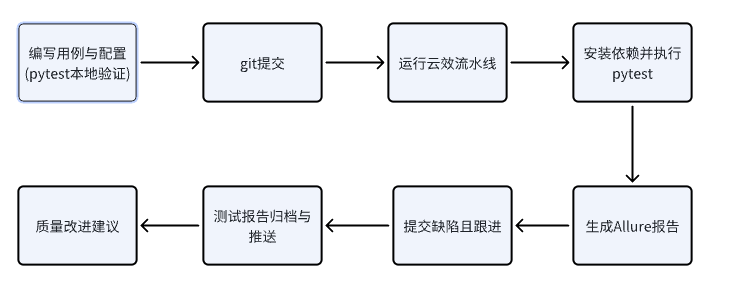
2.3 运行流程
第三章 目录结构与命名规范
3.1 目录结构
(后续补充)
3.2 命名规范
| 类型 | 规则 | 示例 |
|---|---|---|
| 文件 | test_*.py 或 *_test.py | test_order_create.py |
| 类 | Test*(驼峰命名) | TestUserLogin |
| 方法 | test_*(下划线命名) | test_login_success |
| fixture | 简短小写下划线 | auth_client、order_payload |
| 配置文件 | env.<环境>.yaml | env.test.yaml |
3.3 代码风格
使用 Black + Ruff + pre-commit 统一格式。
pip install pre-commit
pre-commit install
3.4 Git提交规范
feat: 新增功能
fix: 修复问题
docs: 文档修改
refactor: 代码重构
chore: 构建调整
test: 测试相关
第四章 环境与依赖管理
4.1 目标
保证环境可复现、依赖一致、安全管理。
4.2 依赖管理
requirements.txt依赖文件
pytest==8.3.3
httpx==0.27.2
allure-pytest==2.13.5
pydantic==2.9.2
jsonschema==4.23.0
pytest-xdist==3.6.1
loguru==0.7.2
PyYAML==6.0.2
安装:
pip install -r requirements.txt
4.3 环境隔离
conda 开发、Docker 部署。
conda create -n api-auto python=3.10
conda activate api-auto
pip install -r requirements.txt
Dockerfile 示例:
FROM python:3.10-slim
WORKDIR /app
COPY requirements.txt .
RUN pip install -r requirements.txt -i https://pypi.tuna.tsinghua.edu.cn/simple
COPY . .
ENTRYPOINT ["pytest","-m","smoke or regression","--alluredir=reports/allure-results"]
4.4 配置管理
项目结构落地优化后更新为最新版本
config/
├─ env.dev.yaml
├─ env.test.yaml
├─ env.stage.yaml
└─ settings.yaml
通过 RUN_ENV 环境变量切换。
第五章 框架与用例编写规范
5.1 框架分层
- common/client.py → BaseApiClient 封装HTTP请求与鉴权。
- api/ → 接口层封装具体业务API。
- tests/ → 用例层。
- common/assertions.py → 统一断言模块。
5.2 用例模板
import pytest, allure
from api.order_api import OrderApi
from common.assertions import assert_status_json
@allure.epic(“订单系统”)
@allure.story(“创建订单接口”)
@pytest.mark.regression
def test_order_create_success(auth_client, order_payload):
resp = auth_client.create_order(**order_payload)
assert_status_json(resp, 201)
5.3 参数化
@pytest.mark.parametrize(“user,pwd,code”,
[(“tester”,“123456”,200),(“tester”,“wrong”,401)])
def test_login(user,pwd,code):
…
第六章 数据与环境管理规范
6.1 目标
保证测试数据独立、可追踪、可清理、可重复。
6.2 生命周期
[测试前] 数据准备 → [执行中] 用例执行 → [测试后] 数据清理
6.3 数据标识
@pytest.fixture(scope=“session”)
def test_run_tag():import uuidreturn f"X-Test-Run-{uuid.uuid4()}"
6.4 幂等性
使用 idempotency_key 确保多次执行返回一致结果。
6.5 环境切换
通过 RUN_ENV 控制环境加载,YAML 配置 + 云效机密变量注入。
第七章 报告与日志规范
7.1 Allure 报告
pytest --alluredir=reports/allure-results
allure generate reports/allure-results -o reports/allure-report --clean
使用 @allure.title、@allure.story 增强报告信息。
7.2 日志规范
使用 loguru 统一输出:
{time} | {level} | {module} | {message}
失败用例自动将日志附加到 Allure 报告。
第八章 CI/CD 流水线配置(阿里云效)
8.1 步骤概要
1️⃣ 安装依赖 2️⃣ 执行测试 3️⃣ 生成 Allure 报告 4️⃣ 上传制品 5️⃣ 发布报告。
8.2 执行命令
pip install -r requirements.txt
pytest -m "regression or smoke" --alluredir=reports/allure-results
allure generate reports/allure-results -o reports/allure-report --clean
8.3 触发方式
- 手动执行
- 定时任务 (每日 20:00)
- 代码 push/MR 触发
8.4 质量门禁
失败率 > 5% 或关键 smoke 用例失败 → 阻断发布。
第九章 质量度量与持续改进
一、核心指标总览
| 序号 | 指标名称 | 定义/计算公式 | 数据来源 | 目标值(建议) | 说明 |
|---|---|---|---|---|---|
| 1 | 用例通过率 (Pass Rate) | 通过用例数 ÷ 总执行用例数 × 100% | Allure 报告 / pytest 结果 | ≥95% | 衡量脚本与环境稳定性,是最直观的质量指标。 |
| 2 | 不稳定用例比例 (Flaky Rate) | 重试成功用例 ÷ 总用例数 × 100% | Allure retries.json | ≤5% | 反映测试脚本或环境波动情况。 |
| 3 | 平均执行时长 (Avg Duration) | 总执行时间 ÷ 用例数量 | Allure summary / pytest 执行日志 | ≤5 秒/用例 | 衡量执行效率与测试反馈速度。 |
| 4 | 接口自动化覆盖率 | 已自动化接口数 ÷ 系统接口总数 × 100% | Swagger / 用例统计 | ≥50% | 衡量自动化覆盖深度与建设进展。 |
| 5 | 缺陷发现效率 (Defect Efficiency) | 自动化发现缺陷数 ÷ 执行次数 | 缺陷管理系统 / 执行日志 | ≥0.1(每 10 次执行至少发现 1 个缺陷) | 衡量自动化对质量的实际贡献。 |
二、实施建议(分阶段推进)
| 阶段 | 目标 | 建议操作 | 工具与方法 |
|---|---|---|---|
| 阶段一:建立执行体系 | 能稳定运行并产出报告 | 使用 pytest + allure,记录每次执行结果 | allure summary.json |
| 阶段二:提升稳定性 | 用例失败率低于 5% | 启用 pytest-rerunfailures 插件,统计 flaky 用例 | pytest + allure retries |
| 阶段三:优化效率 | 平均执行时长 ≤ 5 秒 | 开启 pytest-xdist 并行执行 | pytest -n auto |
| 阶段四:扩大覆盖率 | 自动化覆盖率 ≥ 50% | 新增接口时同步编写自动化用例 | 对比 Swagger 与 api 目录 |
| 阶段五:衡量产出价值 | 缺陷发现效率 ≥ 0.1 | 在缺陷系统标注"来源=自动化" | Jira / Tapd 统计报表 |
三、指标采集方法(简易版)
- 用例通过率
- 查看 Allure 报告首页 “Passed / Failed / Broken” 数据;
- 公式:通过率 = Passed ÷ (Passed + Failed + Broken)。
- 不稳定用例比例
- 查看 Allure 报告 “Retries” 模块;
- 计算 flaky ÷ total × 100%。
- 平均执行时长
- 查看 Allure “Duration” 图表;
- 计算 duration ÷ total。
- 自动化覆盖率
- 对比 Swagger API 总数与项目 api/ 文件夹中的自动化接口数量。
- 后续统计接口总数
- 缺陷发现效率
- 从 Jira/Tapd 缺陷系统中筛选字段 “来源=自动化”,
统计发现缺陷 ÷ 执行次数。
“三看两算”:
看通过率(质量)、看覆盖率(进展)、看缺陷发现率(价值)
算平均时长(效率)、算不稳定率(健康度)
指标周期性统计(周 / 月 / 季度),形成自动化质量报告。