Hadoop 分布式计算MapReduce和资源管理Yarn
目录
一、MapReduce概述
1.1 MapReduce定义
1.2 MapReduce优缺点
1.3 MapReduce工作流程
二、Yarn资源调度器
2.1 Yarn架构剖析
2.2 Yarn工作机制
2.3 YARN RM-HA搭建
2.3.1 文档查看与集群规划
2.3.2 相关文件配置
2.3.3 启动与测试
2.3.4 启动脚本和停止脚本:
三、单词数量统计案例实战
3.1 运行自带的wordcount
3.1.1 运行的命令:
3.1.2 输出目录内容:
3.2 自带的wordcount源码分析
3.3 手写wordcount
3.3.1 环境准备
3.3.2 编写WCMapper类
3.3.3 编写 WCReducer类
3.3.4 编写WCDriver类
3.4.5 运行测试
四、Hadoop序列化与反序列化
4.1 什么是序列化和反序列
一、MapReduce概述

1.1 MapReduce定义
Google发表了两篇论文《Google File System》 《Google MapReduce》
- 《Google File System》简称GFS,是Google公司用于解决海量数据存储的文件系统。
- 《Google MapReduce》简称MapReduce,是Google的计算框架,基于GFS。
MapReduce是一个分布式运算程序的框架重要组成部分,是用户开发“基于Hadoop HDFS的数据分析应用”的核心框架。
MapReduce核心功能是将用户编写的业务逻辑代码和自带默认组件整合成一个完整的分布式运算程序,并行运行在Hadoop集群上。
1.2 MapReduce优缺点
优点
(1)MapReduce易于编程
它简单的实现一些接口(比如Mapper、Reducer等),就可以完成一个分布式程序的开发,分布式程序可以运行在大量廉价的PC机器上。也就是说你写一个分布式程序,跟写一个简单的串行程序是一模一样的。因此使得MapReduce编程变得非常流行。及时对分布式不太了解,也可以开发分布式分析程序。
(2)良好的扩展性
当你的计算资源不够用的时候,你可以通过简单的增加机器来扩展它的计算能力。
(3)高容错性
MapReduce设计的初衷就是使程序能够部署在廉价的PC机器上,这就要求它具有很高的容错性。比如其中一台机器挂了,它可以把上面的计算任务转移到另外一个节点上运行,不至于这个任务运行失败,而且这个过程不需要人工参与,而完全是由Hadoop内部完成的。
(4)适合TB+级别海量数据的离线处理
可以实现数以千计的服务器集群并发工作,提供数据处理能力。
缺点
(1)不擅长实时计算
MapReduce无法像MySQL、Spark、Flink一样,在毫秒或者秒级内返回结果。
(2)不擅长流式计算
流式计算的输入数据是动态的,而MapReduce的输入数据集是静态的,不能动态变化。这是因为MapReduce自身的设计特点决定了数据源必须是静态的。
(3)不擅长DAG(有向无环图)计算
多个应用程序存在依赖关系,后一个应用程序的输入为前一个的输出。在这种情况下,MapReduce并不是不能做,而是使用后,每个MapReduce作业的输出结果都会写入到磁盘,会造成大量的磁盘IO,导致性能非常的低下。
1.3 MapReduce工作流程
官方给的定义:系统执行排序、将map输出作为输入传给reducer的过程称为Shuffle。(看完是不是一脸懵逼)通俗来讲,就是从map产生输出开始到reduce消化输入的整个过程称为Shuffle。如下图用黑线框出的部分:

圆形缓冲区介绍:

每一个map任务都会有一个圆形缓冲区。默认大小100MB(io.sort.mb属性)阈值0.8也就是80MB(mapreduce.map.sort.spill.percent属性指定) ,
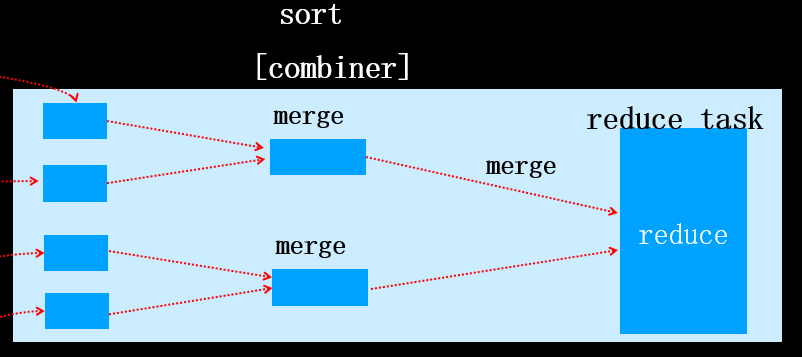
一旦达到阈值一个后台线程开始把内容写到(spill)磁盘的指定目录mapred.local.dir下的新建的一个溢出写文件。写入磁盘前先partition、sort、[combiner]。一个map task任务可能产生N个磁盘文件。map task运算完之后,产生了N个文件,然后将这些文件merge合成一个文件。 如果N=2,合成的新文件写入磁盘前只经过patition(分区)和sort(排序)过程,不会执行combiner合并(无论是否指定combiner类),如下图所示:
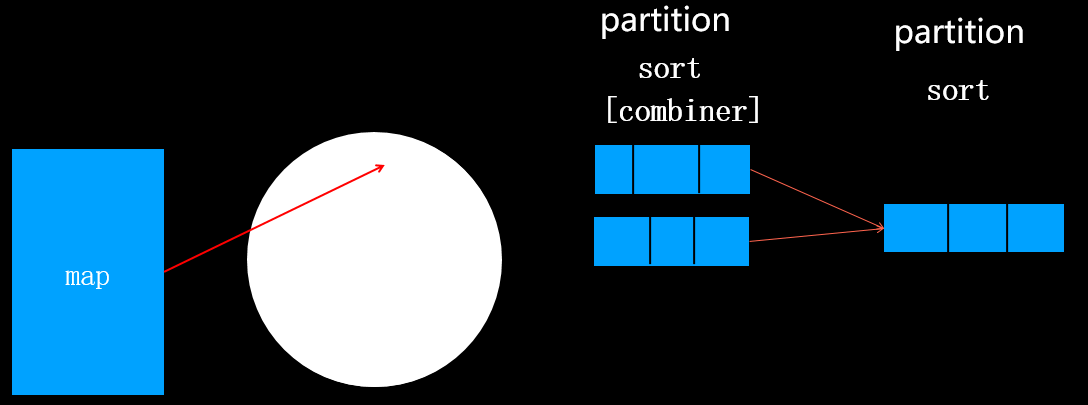
如果N>=3,合成的新文件写入磁盘前经过patition(分区)、sort(排序)过和combiner合并(前提是指定了combiner类),如下图所示:
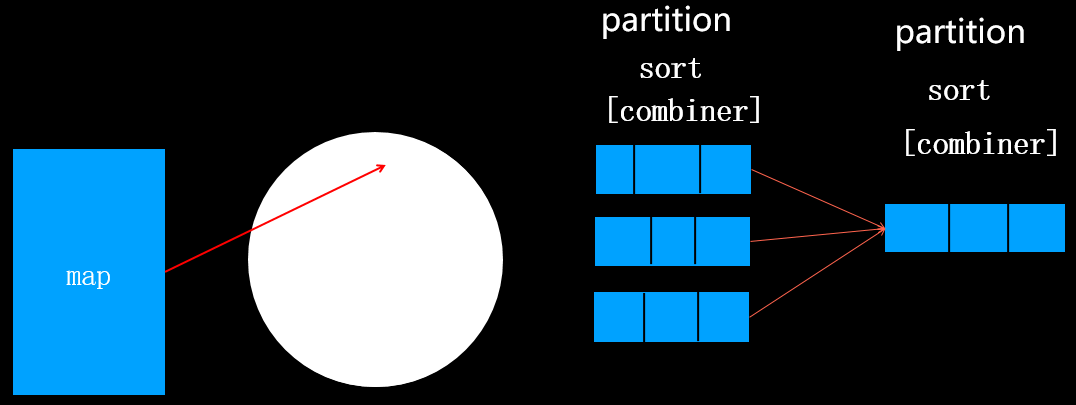
思考:为什么只有当N>=3时,合成文件才会执行combiner呢?
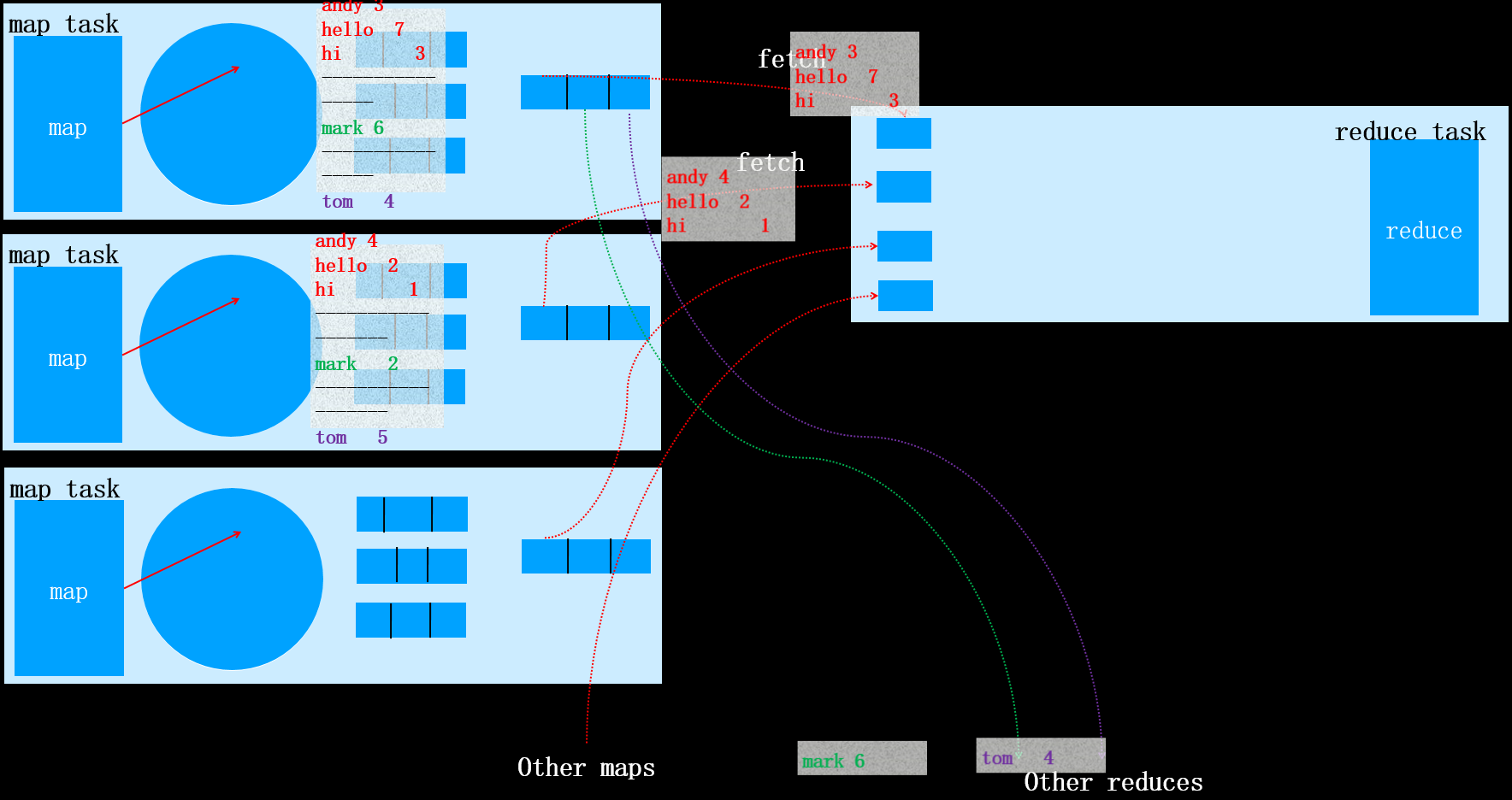
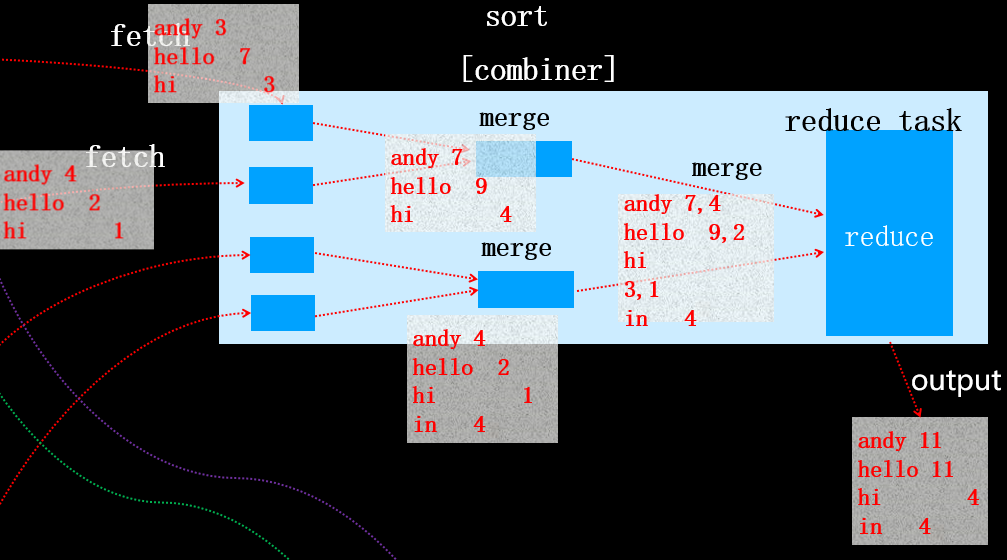
这是因为如果N<3时,执行combiner虽然减少了文件的大小,但是同时产生了一定的系统开销。由于减少的文件大小不大,权衡利弊后,确定N<2时不在执行combiner操作。当该map task全部执行完之后,对应的reduce task将会拷贝对应分区的数据(该过程称为fetch),如下图所示:
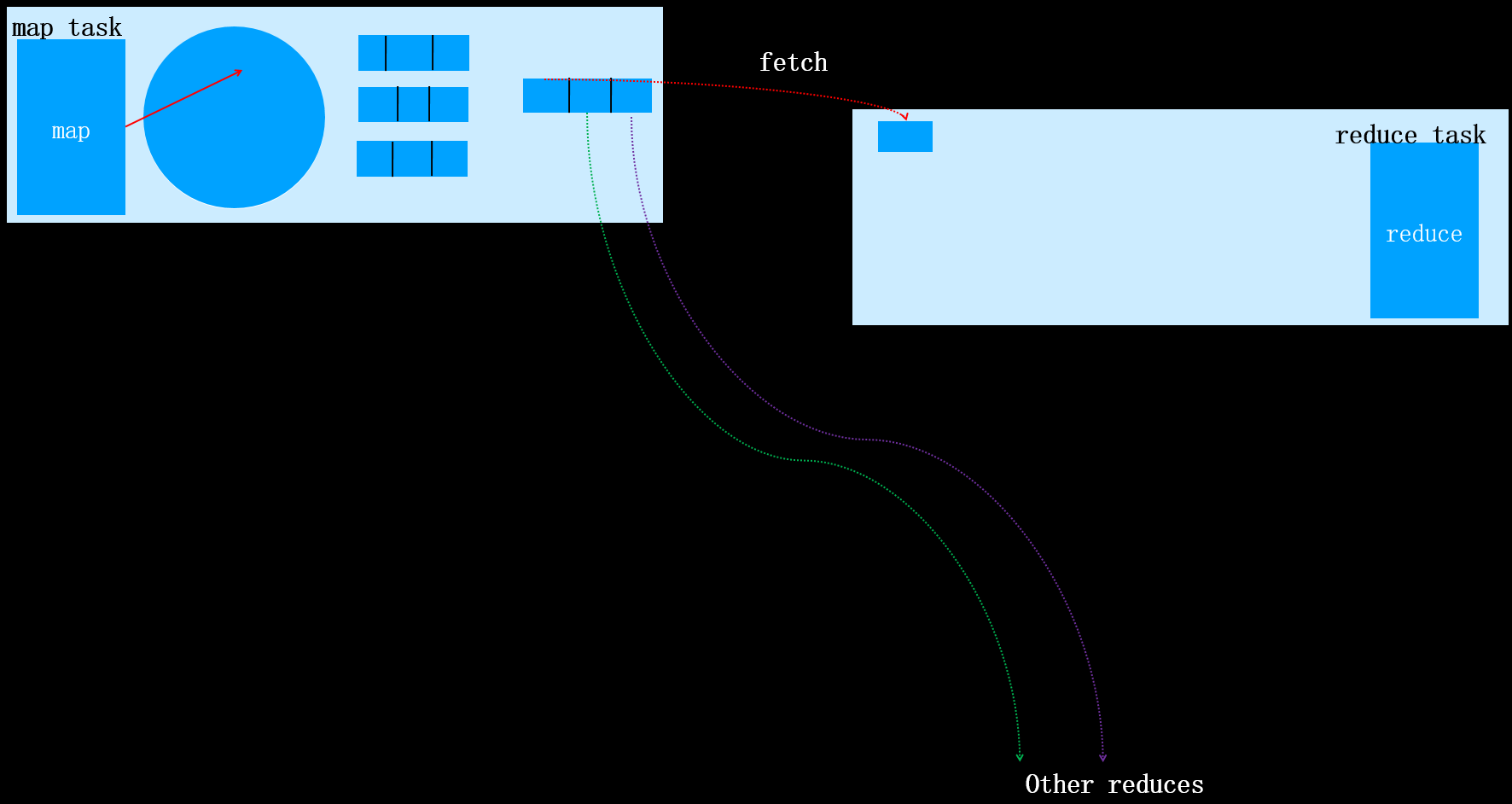
其它的map task任务完成后,对应的reduce task也同样执行fetch操作,如下图所示:
其它的map task任务完成后,对应的reduce task也同样执行fetch操作,如下图所示:
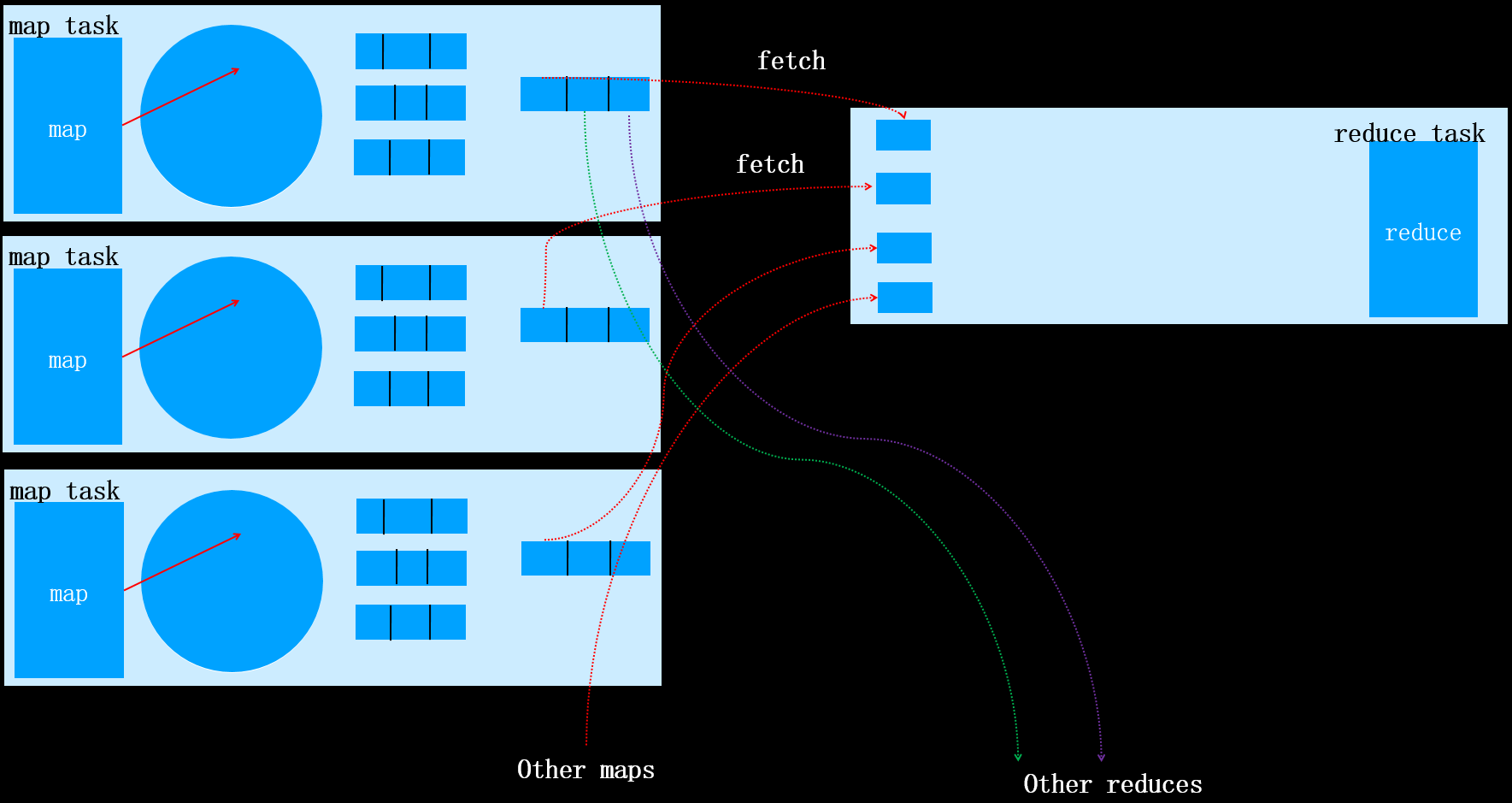
每个map任务的完成时间可能不同,因此只要有一个任务完成,reduce任务就开始复制其输出。该阶段被称为reduce的复制阶段。reduce任务有少量复制线程,因此能够并行取得map输出。默认值是5个线程,但这个默认值可以通过设置mapred.reduce.parallel.copies属性改变。
复制完所有map输出后,reduce任务进入合并阶段,该阶段将合并map输出,并维持其顺序排序(相当于执行了sort),如果指定了combiner,在写入磁盘前还会执行combiner操作。
那么具体是如何合并的呢? 合并因子默认是10,可以通过io.sort.factor属性设置。合并过程是循环进行了,可能叫经过多趟合并。目标是合并最小数量的文件以便满足最后一趟的合并系数。假设有40个文件,我们不会在四趟中每趟合并10个文件从而得到4个文件。相反,第一趟只合并4个文件,随后的三趟分别合并10个文件。再最后一趟中4个已合并的文件和余下的6个(未合并的)文件合计10个文件。具体流程如下图所示:
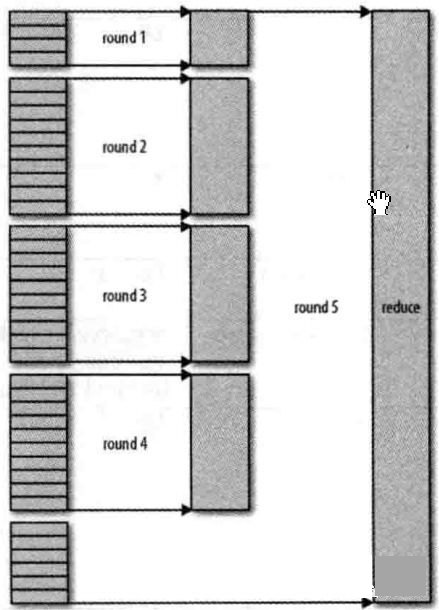
注意:这并没有改变合并次数,它只是一个优化措施,目的是尽量减少写到磁盘的数据量,因为最后一趟总是直接合并到reduce。 看到这里您是否理解了Shuffle的具体原理呢,如果没有,也没有关系,接下来我们通过一个wordcount案例再将整个流程梳理一遍。
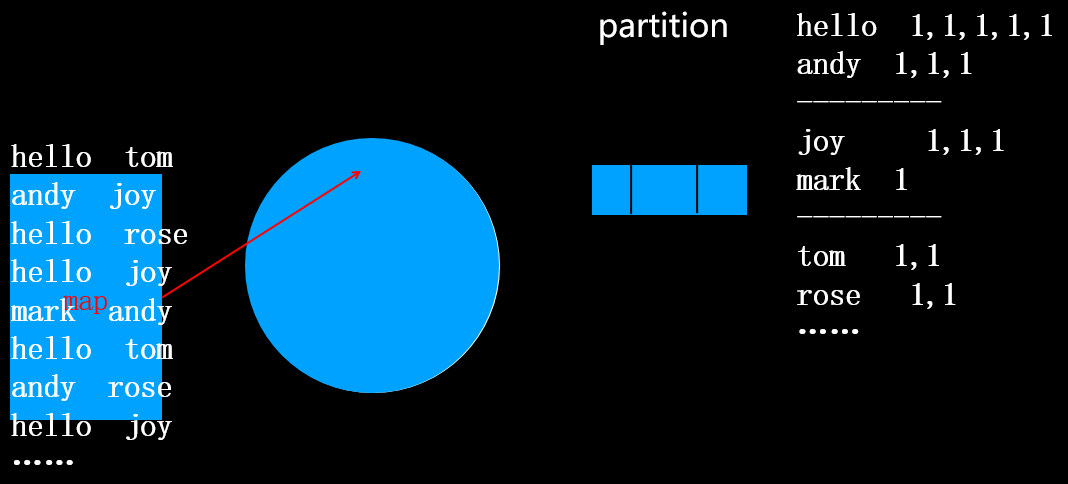
在分区(分区规则:按首字母分四个区,分别为a-i,j-q,r-z,其它)的过程中,会将相同的单词合并到一起,将出现次数用逗号隔开,如上图所示。注意此时还没有排序。
接着执行排序操作,默认排序规则是按照key的字典升序排序,当然你也可以指定排序规则,排序后如下图所示:
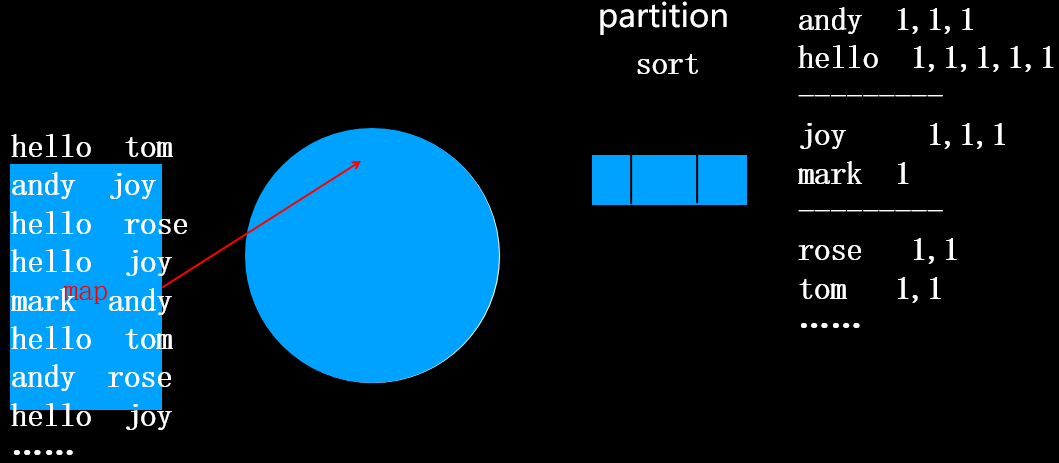
接下来执行combiner操作,将每个单词后续的1求和。
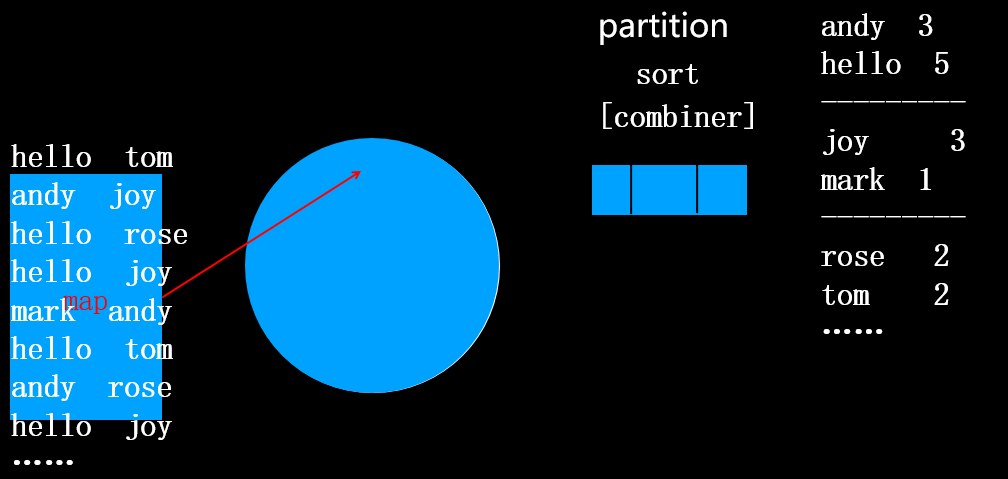
combiner的结果如上图所示
map任务执行完,产生N个spill文件,接着对N个文件进行合并,分以下两种情况:1.N<3,无论是否指定combiner类,合并文件时都不会执行combiner
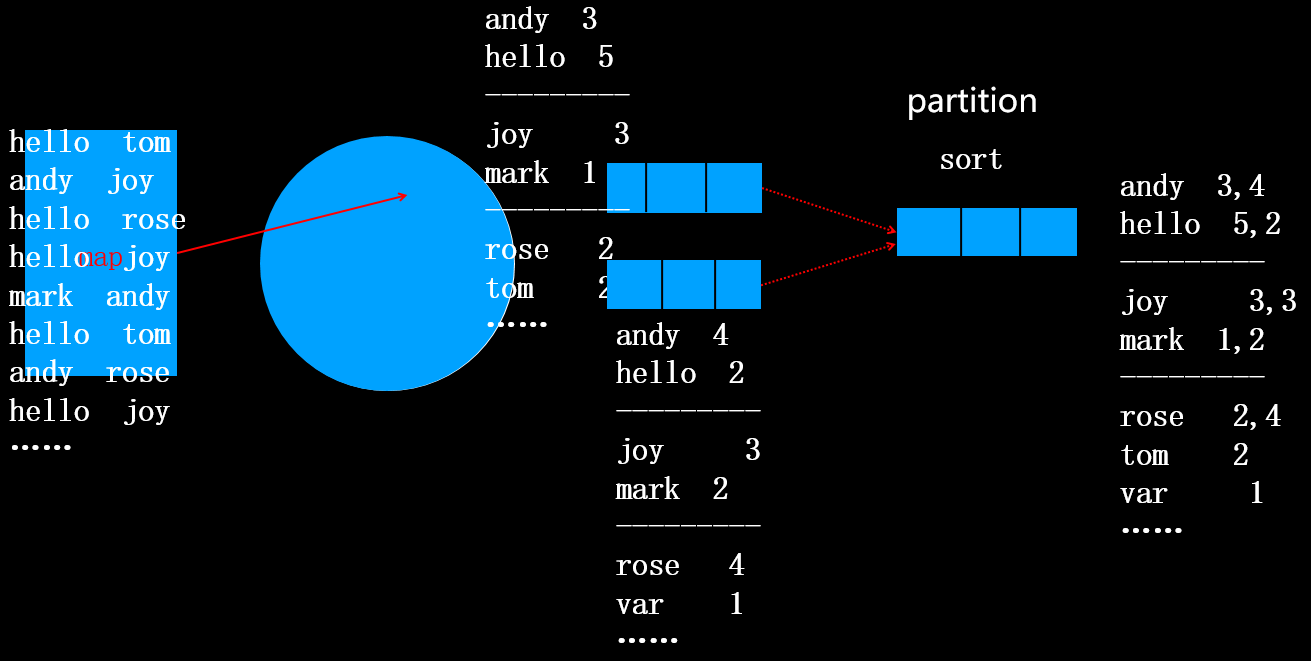
2.N>=3,如果指定了combiner类将执行combiner操作,
接下来进入fetch(或copy)阶段
然后在reduce端进行合并
然后执行最后一趟合并,并将结果直接传给reduce
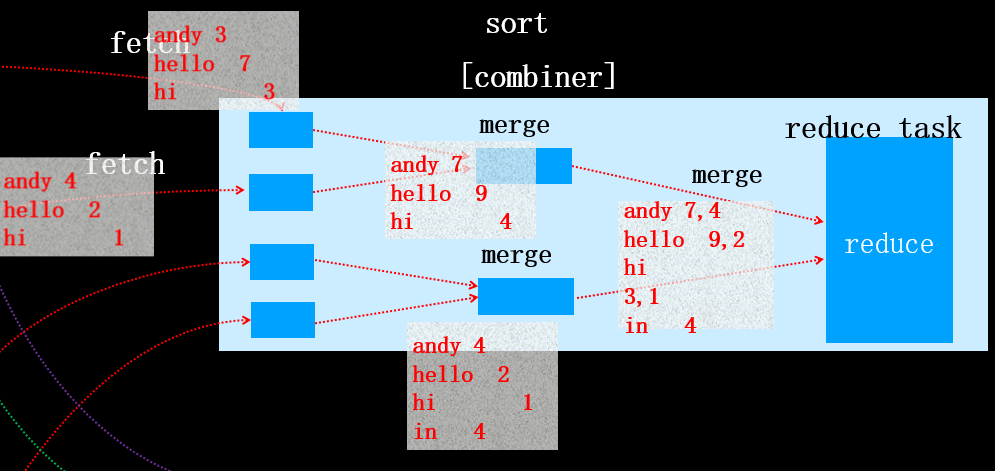
reduce task执行后,输出结果:
二、Yarn资源调度器
2.1 Yarn架构剖析
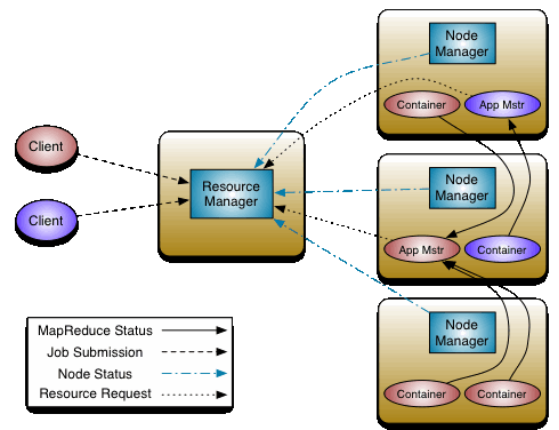
YARN(Yet Another Resource Negotiator): Hadoop 2.0新引入的资源管理系统,直接从MRv1演化而来的;核心思想:将MRv1中JobTracker的资源管理和任务调度两个功能分开,分别由ResourceManager和ApplicationMaster进程实现。YARN的引入,使得多个计算可运行在一个集群中, 每个job对应一个ApplicationMaster。 目前多个计算框架可以运行在YARN上,比如MapReduce、Spark等解耦资源与计算。
Yarn是一个资源调度平台,负责为运行的程序(提交job作业)提供服务器的资源(CPU、Mem..,网络等)。
-
ResourceManager(简称RM)主要作用:
- 处理客户端的请求
- 监控NodeManager
- 启动和监控ApplicationMaster
- 负责整个集群的资源管理和调度
-
NodeManager:
- 与RM汇报资源
- 管理当前服务器上的Container容器
- 处理来自RM的指令
- 处理来之ApplicationMaster指令
-
ApplicationMaster:负责应用程序相关的事务,比如任务调度、任务监控和容错等
- 以作业为单位,负载到不同的节点,避免单点故障。
- 向RM申请创建Task任务(MapTask、ReduceTask)所需要资源(Container)
- 负责任务切分、任务调度、任务监控和容错等
-
Container:【节点NM,CPU,MEM,I/O大小,启动命令】
- 默认NodeManager启动线程监控Container大小
- 超出申请资源额度,被kill掉
-
Client:
- • RM-Client:请求资源创建AM
- • AM-Client:与AM交互
MRAppMaster容错
- 失败后,由YARN重新启动
- 任务失败后,MRAppMaster重新申请资源
2.2 Yarn工作机制
也是一个job的从提交到执行完毕的全流程,除了job本身执行以外,还有Client、RM、NodeManager、MRApplicationMaster.
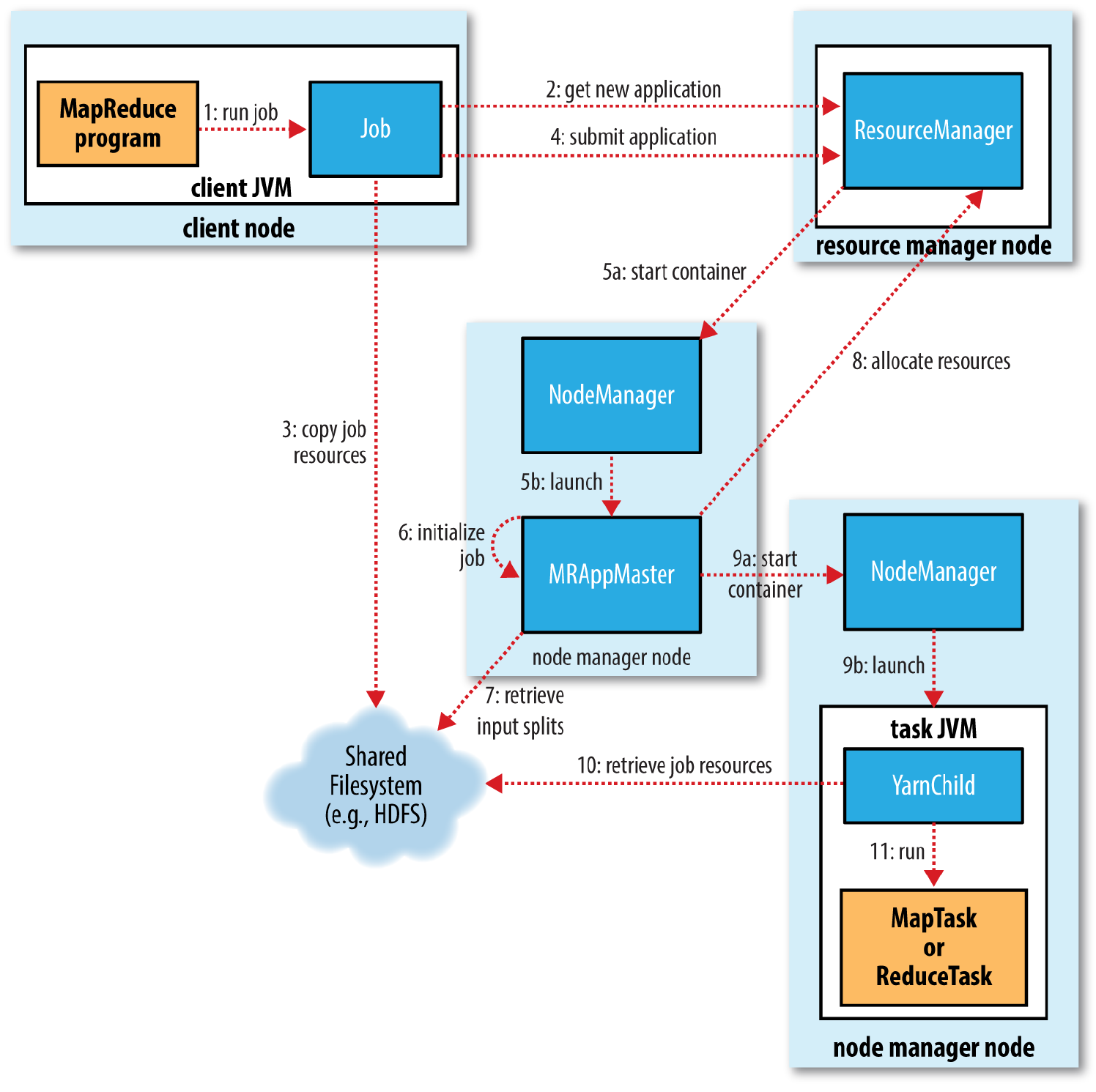
一. 作业提交:
- 提交作业job后,job.waitForCompletion(true)调用monitorAndPrintJob()方法每秒轮询作业进度,如果发现自上次报告后有改变,便把进度报告给控制台。Job的submit()方法创建一个内部的JobSubmitter实例,并调用其submitJobInternal方法(步骤1)。作业完成后,如果成功,就显示计数器;如果失败,这将导致作业失败的错误记录到控制台。
JobSubmitter所实现的作业提交过程如下所述:
- 向资ResourceManager源管理器请求一个新作业的ID,用于MapReduce作业ID。
- 作业客户端检查作业的输出说明,计算输入分片splits并将作业资源(包括作业Jar包、配置文件和分片信息)复制到HDFS
- 通过调用资源管理器上的submitApplication()方法提交作业
二.作业初始化
- 资源管理器ResourceManager收到调用他的submitApplication()消息后,便将请求传递给调度器(scheduler)。调度器分配一个容器(Container),然后资源管理器在节点管理器(NodeManager)的管理下载容器中启动应用程序的master进程(步骤5a和5b)
- MapReduce作业的application master是一个Java应用程序,它的主类是MRAppMaster。它对作业进行初始化:通过创建多个簿记对象以保持对作业进度的跟踪,因为它将接受来自任务的进度和完成报告(步骤6)。
- 接下来,它接受来自共享文件系统的在客户端计算的输入分片(步骤7)。对每一个分片创建一个map任务对象以及由mapreduce. job.reduces属性确定的具体数量的reduce任务对象。
三.任务分配
- AppMaster为该作业中的所有map任务和reduce任务向资源管理器请求容器。
四.任务执行
- 一旦资源管理器的调度器为任务分配了容器,AppMaster就通过与节点管理器NodeManager通讯来启动容器(步骤9a和9b)。
- 该任务由主类为YarnChild的Java应用程序执行。在它允许任务之前,首先将任务需要的资源本地化,包括作业的配置、JAR文件和所有来自分布式缓存的文件.
- 最后运行map任务或reduce任务。
五.进度和状态更新
在YARN下运行时,任务每3秒钟通过umbilical接口向APPMaster汇报进度和状态。客户端每一秒钟(通过mapreduce.client.Progressmonitor.pollinterval设置)查询一次AppMaster以接收进度更新,通常都会向用户显示。
六.作业完成
除了向AppMaster查询进度外,客户端每5秒还通过调用Job的waitForCompletion()来检测作业是否完成。查询的间隔可以通过mapreduce.client.completion.pollinterval属性进行设置。作业完成后,AppMaster和任务容器清理器工作状态。
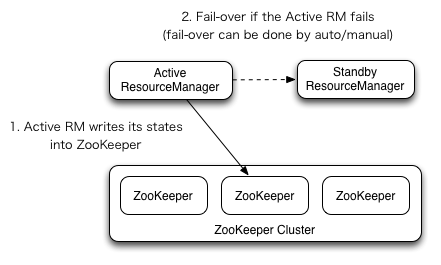
2.3 YARN RM-HA搭建
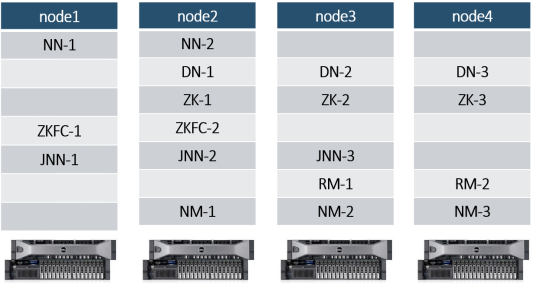
2.3.1 文档查看与集群规划
RM高可用官方网址:
http://hadoop.apache.org/docs/r3.1.3/hadoop-yarn/hadoop-yarn-site/ResourceManagerHA.html
本地进入文档首页:
RM高可用机制:
RM高可用集群规划:
2.3.2 相关文件配置
- mapred-site.xml
local/classic/yarn
指定mr作业运行的框架:要么本地运行(local),要么使用MRv1(classic),要么使用yarn
<property><name>mapreduce.framework.name</name><value>yarn</value>
</property>
- yarn-site.xml
<configuration><!-- 让yarn的容器支持mapreduce的洗牌,开启shuffle服务 --><property><name>yarn.nodemanager.aux-services</name><value>mapreduce_shuffle</value></property><!-- 启用resourcemanager ha --><property><name>yarn.resourcemanager.ha.enabled</name><value>true</value></property><!-- 指定zookeeper集群的各个节点地址和端口号 --> <property><name>yarn.resourcemanager.zk-address</name><value>node2:2181,node3:2181,node4:2181</value></property><!-- 启用自动恢复 --> <property><name>yarn.resourcemanager.recovery.enabled</name><value>true</value></property><!-- 指定RM的状态信息存储在zookeeper集群 --> <property><name>yarn.resourcemanager.store.class</name> <value>org.apache.hadoop.yarn.server.resourcemanager.recovery.ZKRMStateStore</value></property><!-- 声明两台resourcemanager的地址 --><property><name>yarn.resourcemanager.cluster-id</name><value>cluster-yarn1</value></property><!--指定resourcemanager的逻辑列表--><property><name>yarn.resourcemanager.ha.rm-ids</name><value>rm1,rm2</value></property><!-- rm1的配置 --><!-- 指定rm1的主机名 --><property><name>yarn.resourcemanager.hostname.rm1</name><value>node3</value></property><!-- 指定rm1的web端地址 --><property><name>yarn.resourcemanager.webapp.address.rm1</name><value>node3:8088</value></property><!-- 指定rm1的内部通信地址 --><property><name>yarn.resourcemanager.address.rm1</name><value>node3:8032</value></property><!-- 指定AM向rm1申请资源的地址 --><property><name>yarn.resourcemanager.scheduler.address.rm1</name> <value>node3:8030</value></property><!-- 指定供NM连接的地址 --> <property><name>yarn.resourcemanager.resource-tracker.address.rm1</name><value>node3:8031</value></property><!-- rm2的配置 --><!-- 指定rm2的主机名 --><property><name>yarn.resourcemanager.hostname.rm2</name><value>node4</value></property><property><name>yarn.resourcemanager.webapp.address.rm2</name><value>node4:8088</value></property><property><name>yarn.resourcemanager.address.rm2</name><value>node4:8032</value></property><property><name>yarn.resourcemanager.scheduler.address.rm2</name><value>node4:8030</value></property><property><name>yarn.resourcemanager.resource-tracker.address.rm2</name><value>node4:8031</value></property><!-- 环境变量的继承 --><property><name>yarn.nodemanager.env-whitelist</name> <value>JAVA_HOME,HADOOP_COMMON_HOME,HADOOP_HDFS_HOME,HADOOP_CONF_DIR,CLASSPATH_PREPEND_DISTCACHE,HADOOP_MAPRED_HOME,HADOOP_YARN_HOME</value></property><!-- yarn容器允许分配的最大最小内存 --><property><name>yarn.scheduler.minimum-allocation-mb</name><value>512</value></property><property><name>yarn.scheduler.maximum-allocation-mb</name><value>1024</value></property><!-- yarn容器允许管理的物理内存大小 --><property><name>yarn.nodemanager.resource.memory-mb</name><value>1024</value></property><!-- 关闭yarn对物理内存的限制检查 --><property><name>yarn.nodemanager.pmem-check-enabled</name><value>false</value></property><!-- 关闭yarn对虚拟内存的限制检查 --><property><name>yarn.nodemanager.vmem-check-enabled</name><value>false</value></property>
</configuration>
将配置文件在四台服务器同步
[root@node1 hadoop]# pwd
/opt/hadoop-3.1.3/etc/hadoop
[root@node1 hadoop]#scp mapred-site.xml yarn-site.xml node[234]:`pwd`
2.3.3 启动与测试
1. 启动:
node1上首先启动HDFS集群
[root@node1 ~]# starthdfs.sh
在node3和node4上执行命令,启动ResourceManager:
#Node3:(只能启动本机上的ResourceManager和其他节点的NodeManager)
[root@node3 ~]# start-yarn.sh
Starting resourcemanagers on [ node3 node4]
ERROR: Attempting to operate on yarn resourcemanager as root
ERROR: but there is no YARN_RESOURCEMANAGER_USER defined. Aborting operation.
Starting nodemanagers
ERROR: Attempting to operate on yarn nodemanager as root
ERROR: but there is no YARN_NODEMANAGER_USER defined. Aborting operation.
#需要在start-yarn.sh和stop-yarn.sh中配置YARN_RESOURCEMANAGER_USER和YARN_NODEMANAGER_USER
[root@node3 sbin]# vim start-yarn.sh
#添加一下两条配置
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
[root@node3 sbin]# vim stop-yarn.sh
#添加一下两条配置
YARN_RESOURCEMANAGER_USER=root
YARN_NODEMANAGER_USER=root
[root@node3 sbin]# start-yarn.sh
Starting resourcemanagers on [ node3 node4]
上一次登录:一 10月 25 18:00:49 CST 2021pts/1 上
Starting nodemanagers
上一次登录:一 10月 25 18:01:52 CST 2021pts/1 上
#注意:hadoop2.x版本中还需要在Node4启动另外一个RM yarn-daemon.sh start resourcemanager
#可以通过jps查看,也可以调用node1上的allJps.sh脚本查看:发现node3和node4上分别多一个RM进程,node2、node3、node4上分别多出一个NodeManager进程。
#查看服务 arn rmadmin -getServiceState rm1
[root@node3 sbin]# yarn rmadmin -getServiceState rm1
standby
[root@node3 sbin]# yarn rmadmin -getServiceState rm2
active #说明node4上ResourceManager为Active状态。2. 测试:
去zk集群节点上查看:
[root@node4 ~]# zkCli.sh
[zk: localhost:2181(CONNECTED) 0] ls /
[hadoop-ha, itbaizhan, registry, rmstore, wzyy, yarn-leader-election, zk001, zookeeper]
[zk: localhost:2181(CONNECTED) 2] ls /rmstore
[ZKRMStateRoot]
[zk: localhost:2181(CONNECTED) 3] ls /yarn-leader-election
[cluster-yarn1]
[zk: localhost:2181(CONNECTED) 4] get -s /rmstore/ZKRMStateRoot
null
cZxid = 0x900000014
ctime = Mon Oct 25 18:00:34 CST 2021
mZxid = 0x900000014
mtime = Mon Oct 25 18:00:34 CST 2021
pZxid = 0x90000003e
cversion = 22
dataVersion = 0
aclVersion = 2
ephemeralOwner = 0x0
dataLength = 0
numChildren = 6
[zk: localhost:2181(CONNECTED) 5] ls /yarn-leader-election/cluster-yarn1
[ActiveBreadCrumb, ActiveStandbyElectorLock]
[zk: localhost:2181(CONNECTED) 6] get -s /yarn-leader-election/cluster-yarn1/Active
ActiveBreadCrumb ActiveStandbyElectorLock
[zk: localhost:2181(CONNECTED) 6] get -s /yarn-leader-election/cluster-yarn1/ActiveBreadCrumbcluster-yarn1rm2
cZxid = 0x90000003a
ctime = Mon Oct 25 18:02:07 CST 2021
mZxid = 0x90000003a
mtime = Mon Oct 25 18:02:07 CST 2021
pZxid = 0x90000003a
cversion = 0
dataVersion = 0
aclVersion = 0
ephemeralOwner = 0x0
dataLength = 20
numChildren = 0
通过浏览器测试:
http://node3:8088 或者 http://node4:8088 都会被重定向到状态为Active节点的信息页面上,目前我的node4上的RM是Active:
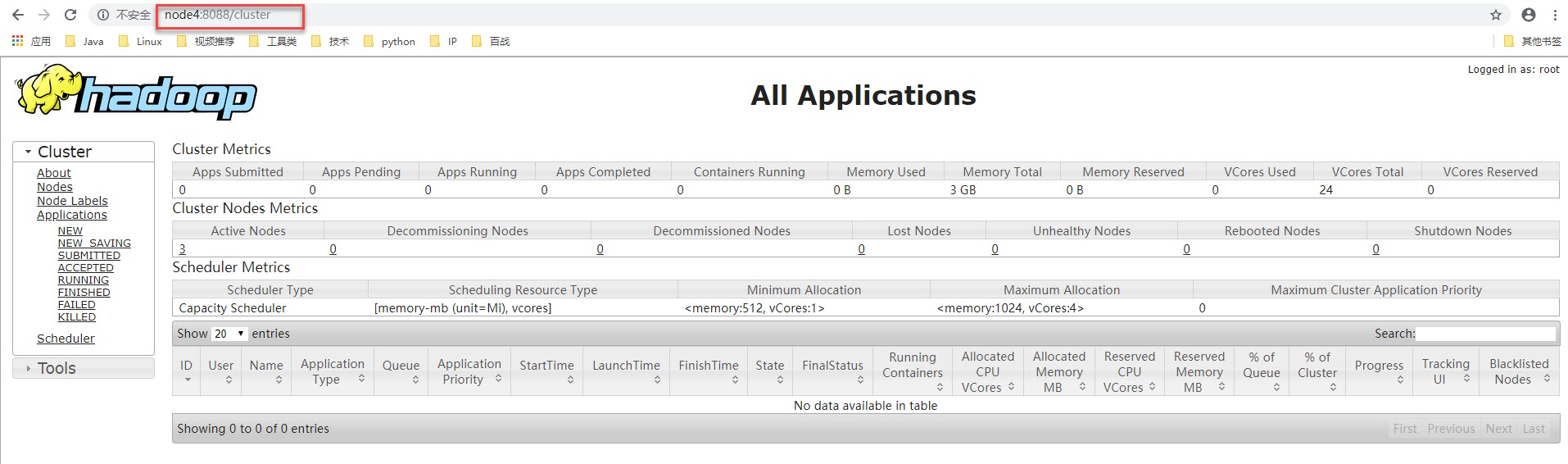
查看node3上的RM的状态信息:
http://node3:8088/cluster/cluster
查看node4上的RM的状态信息:
http://node4:8088/cluster/cluster
高可用演示:
Active对应的节点node3或node4上执行:
#hadoop2.x版本中的关闭或启动resourcemanager进程的命令
yarn-deamon.sh stop resourcemanager
yarn-deamon.sh start resourcemanager
#hadoop3.x版本中关闭或启动resourcemanager进程的命令
[root@node3 ~]# yarn --daemon stop resourcemanager
[root@node3 ~]# yarn --daemon start resourcemanager
http://node3:8088/cluster/cluster
http://node4:8088/cluster/cluster
2.3.4 启动脚本和停止脚本:
Hadoop集群的启动脚本:startha.sh (3.x版本)
[root@node1 bin]# vim startha.sh
#!/bin/bash
#启动zk集群
for node in node2 node3 node4
dossh $node "source /etc/profile;zkServer.sh start"
done
#休眠1s
sleep 1
#启动hdfs集群
start-dfs.sh
#启动yarn
ssh node3 "source /etc/profile;start-yarn.sh"
#查看四个节点上的java进程
allJps.sh[root@node1 bin]# chmod +x startha.sh #添加执行权限
Hadoop集群的关闭脚本stopha.sh (3.x)
[root@node1 bin]# vim stopha.sh
#!/bin/bash
#关闭yarn
ssh node3 "source /etc/profile;stop-yarn.sh"
#关闭hdfs
stop-dfs.sh
#关闭zk集群
for node in node2 node3 node4
dossh $node "source /etc/profile;zkServer.sh stop"
done
#查看java进程
allJps.sh
[root@node1 bin]# ll
总用量 20
-rwxr-xr-x 1 root root 220 10月 15 14:50 allJps.sh
-rwxr-xr-x 1 root root 272 10月 25 19:10 startha.sh
-rwxr-xr-x 1 root root 194 10月 15 14:56 starthdfs.sh
-rw-r--r-- 1 root root 227 10月 25 19:17 stopha.sh
-rwxr-xr-x 1 root root 210 10月 15 14:47 stophdfs.sh
[root@node1 bin]# chmod 755 stopha.sh #添加执行权限
Hadoop集群的启动脚本:startha.sh (2.x版本)
#!/bin/bash
for node in node2 node3 node4
dossh $node "source /etc/profile;zkServer.sh start"
done
sleep 1
start-dfs.sh
ssh node3 "source /etc/profile;start-yarn.sh"
ssh node4 "source /etc/profile;yarn-daemon.sh start resourcemanager"
allJps.sh
Hadoop集群的关闭脚本stopha.sh (2.x)
#!/bin/bash
ssh node4 "source /etc/profile;yarn-daemon.sh stop resourcemanager"
ssh node3 "source /etc/profile;stop-yarn.sh"
stop-dfs.sh
for node in node2 node3 node4
dossh $node "source /etc/profile;zkServer.sh stop"
done
allJps.sh
##2.4 资源调度器
目前,Hadoop作业调度器没有好坏之分,只有适合与否之分,所以Hadoop提供三种调度器让使用者进行选择,这三种:FIFO、Capacity Scheduler和Fair Scheduler。Hadoop3.1.3默认的资源调度器是Capacity Scheduler。具体设置详见:yarn-default.xml文件
| Property | yarn.resourcemanager.scheduler.class |
|---|---|
| Value | org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler |
<!-- 修改自己搭建集群的调度器,修改yarn-site.xml文件 -->
<property><description>The class to use as the resource scheduler.</description><name>yarn.resourcemanager.scheduler.class</name><value>org.apache.hadoop.yarn.server.resourcemanager.scheduler.capacity.CapacityScheduler</value>
</property>
- 先进先出调度器(FIFO)
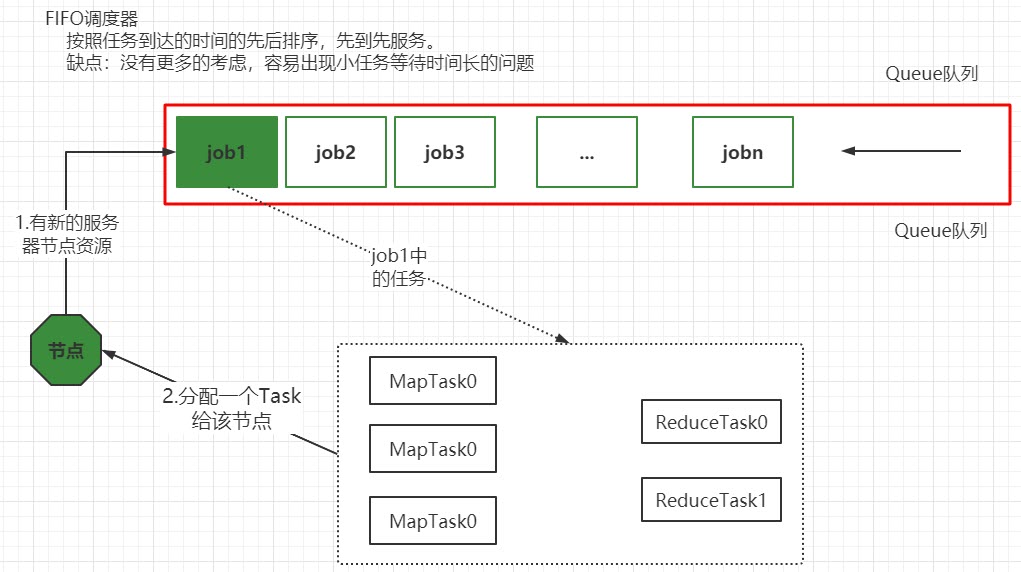
Hadoop最初设计目的是支持大数据批处理作业,如日志挖掘、Web索引等作业,为此,Hadoop仅提供了一个非常简单的调度机制:FIFO,即先来先服务,在该调度机制下,所有作业被统一提交到一个队列中,Hadoop按照提交顺序依次运行这些作业。
但随着Hadoop的普及,单个Hadoop集群的任务处理量越来越多,不同用户提交的应用程序往往具有不同的服务质量要求,典型的应用有以下几种:
- 批处理作业:这种作业往往耗时较长,对时间完成一般没有严格要求,如数据挖掘、机器学习等方面的应用程序。
- 交互式作业:这种作业期望能及时返回结果,如HQL查询(Hive)等。
- 实时统计作业:这种作业要求有一定量的资源保证,如淘宝交易量大屏等。
此外,这些应用程序对硬件资源需求量也是不同的,因此,简单的FIFO调度策略不仅不能满足多样化需求,也不能充分利用硬件资源。
- 容量调度器(Capacity Scheduler)
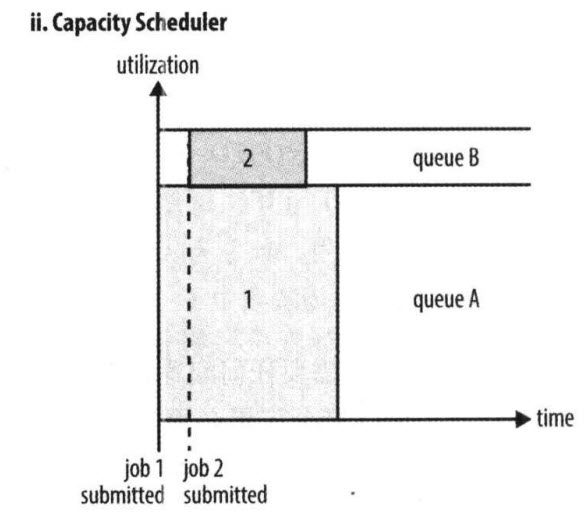
Capacity Scheduler 是Yahoo开发的多用户调度器。
- 它以队列为单位划分资源,支持多个队列,每个队列可设定一定比例的资源最低保证和使用上限。
- 每个队列采用是FIFO调度策略。
- 为了防止同一个用户的作业独占队列中的资源,调度器会对同一个用户提交的作业所占的资源量进行限定。
- 当有任务被提交时,计算每个队列中正在运行的任务数/该对应应分得的计算资源 的比值,任务分给比值最小(最闲)的队列。
- 每个队列最前端的作业可以并行运行。
总之,Capacity Scheduler 主要有以下几个特点:
- 容量保证。管理员可为每个队列设置资源最低保证和资源使用上限,而所有提交到该队列的应用程序共享这些资源。
- 灵活性,如果一个队列中的资源有剩余,可以暂时共享给那些需要资源的队列,而一旦该队列有新的应用程序提交,则其他队列借调的资源会归还给该队列。这种资源灵活分配的方式可明显提高资源利用率。
- 多重租赁。支持多用户共享集群和多应用程序同时运行。为防止单个应用程序、用户或者队列独占集群中的资源,管理员可为之增加多重约束(比如单个应用程序同时运行的任务数等)。
- 安全保证。每个队列有严格的ACL列表规定它的访问用户,每个用户可指定哪些用户允许查看自己应用程序的运行状态或者控制应用程序(比如杀死应用程序)。此外,管理员可指定队列管理员和集群系统管理员。
- 动态更新配置文件。管理员可根据需要动态修改各种配置参数,以实现在线集群管理。
- 公平调度器(Fair Scheduler)(了解)
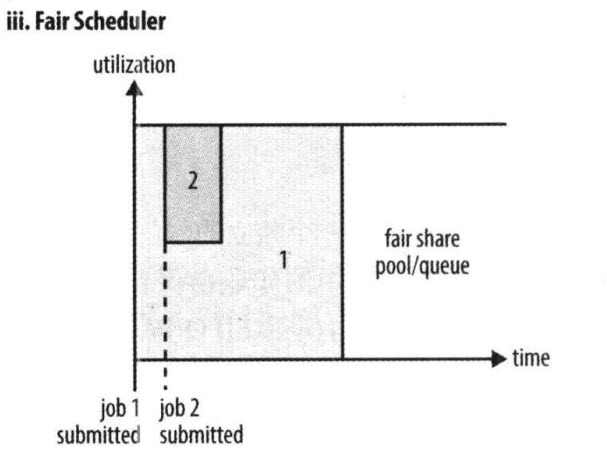
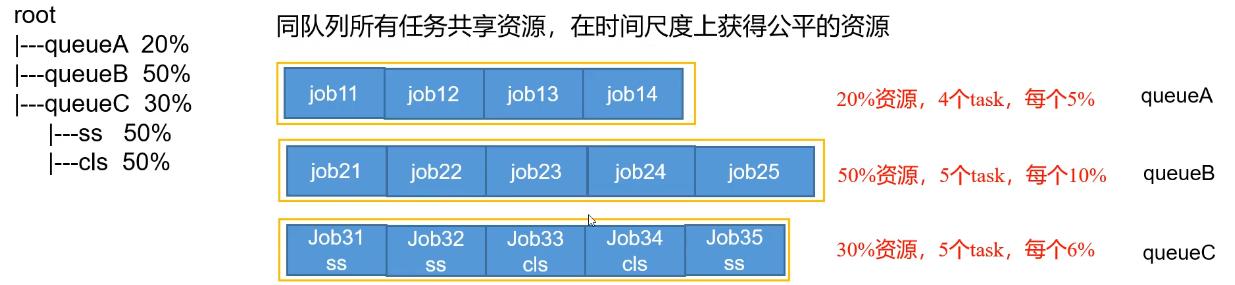
Fair Scheduler 是Facebook开发的多用户调度器。
公平调度器的目的是让所有的作业随着时间的推移,都能平均地获取等同的共享资源。当有作业提交上来,系统会将空闲的资源分配给新的作业,每个任务大致上会获取平等数量的资源。和传统的调度策略不同的是它会让小的任务在合理的时间完成,同时不会让需要长时间运行的耗费大量资源的任务挨饿!
同Capacity Scheduler类似,它以队列为单位划分资源,每个队列可设定一定比例的资源最低保证和使用上限,同时,每个用户也可设定一定的资源使用上限以防止资源滥用;当一个队列的资源有剩余时,可暂时将剩余资源共享给其他队列。
当然,Fair Scheduler也存在很多与Capacity Scheduler不同之处,这主要体现在以下几个方面:
① 资源公平共享。在每个队列中,Fair Scheduler 可选择按照FIFO、Fair或DRF策略为应用程序分配资源。其中:
FIFO策略
公平调度器每个队列资源分配策略如果选择FIFO的话,就是禁用掉每个队列中的Task共享队列资源,此时公平调度器相当于上面讲过的容量调度器。
Fair策略
Fair 策略(默认)是一种基于最大最小公平算法实现的资源多路复用方式,默认情况下,每个队列内部采用该方式分配资源。这意味着,如果一个队列中有两个应用程序同时运行,则每个应用程序可得到1/2的资源;如果三个应用程序同时运行,则每个应用程序可得到1/3的资源。
【扩展:】最大最小公平算法举例:
1.不加权(关注点是job的个数):
有一条队列总资源12个, 有4个job,对资源的需求分别是:
job1->1, job2->2 , job3->6, job4->5第一次算: 12 / 4 = 3 job1: 分3 --> 多2个 job2: 分3 --> 多1个job3: 分3 --> 差3个job4: 分3 --> 差2个第二次算: 3 / 2 = 1.5 job1: 分1job2: 分2job3: 分3 --> 差3个 --> 分1.5 --> 最终: 4.5 job4: 分3 --> 差2个 --> 分1.5 --> 最终: 4.5 第n次算: 一直算到没有空闲资源
2.加权(关注点是job的权重):
有一条队列总资源16,有4个job
对资源的需求分别是: job1->4 job2->2 job3->10 job4->4
每个job的权重为: job1->5 job2->8 job3->1 job4->2 第一次算: 16 / (5+8+1+2) = 1job1: 分5 --> 多1job2: 分8 --> 多6job3: 分1 --> 少9job4: 分2 --> 少2 第二次算: 7 / (1+2) = 7/3job1: 分4job2: 分2job3: 分1 --> 分7/3 --> 少job4: 分2 --> 分14/3(4.66) -->多2.66第三次算: job1: 分4job2: 分2job3: 分1 --> 分7/3 --> 分2.66job4: 分4第n次算: 一直算到没有空闲资源
DRF策略
DRF(Dominant Resource Fairness),我们之前说的资源,都是单一标准,例如只考虑内存(也是yarn默认的情况)。但是很多时候我们资源有很多种,例如内存,CPU,网络带宽等,这样我们很难衡量两个应用应该分配的资源比例。
那么在YARN中,我们用DRF来决定如何调度:假设集群一共有100 CPU和10T 内存,而应用A需要(2 CPU, 300GB),应用B需要(6 CPU, 100GB)。则两个应用分别需要A(2%CPU, 3%内存)和B(6%CPU, 1%内存)的资源,这就意味着A是内存主导的, B是CPU主导的,针对这种情况,我们可以选择DRF策略对不同应用进行不同资源(CPU和内存)的一个不同比例的限制。
②支持资源抢占。当某个队列中有剩余资源时,调度器会将这些资源共享给其他队列,而当该队列中有新的应用程序提交时,调度器要为它回收资源。为了尽可能降低不必要的计算浪费,调度器采用了先等待再强制回收的策略,即如果等待一段时间后尚有未归还的资源,则会进行资源抢占:从那些超额使用资源的队列中杀死一部分任务,进而释放资源。
yarn.scheduler.fair.preemption=true 通过该配置开启资源抢占。
③提高小应用程序响应时间。由于采用了最大最小公平算法,小作业可以快速获取资源并运行完成
三、单词数量统计案例实战
3.1 运行自带的wordcount
3.1.1 运行的命令:
[root@node1 ~]# cd /opt/hadoop-3.1.3/share/hadoop/mapreduce/
[root@node1 mapreduce]# pwd
/opt/hadoop-3.1.3/share/hadoop/mapreduce
[root@node1 mapreduce]# ll *examples-3.1.3.jar
-rw-r--r-- 1 itbaizhan itbaizhan 316382 9月 12 2019 hadoop-mapreduce-examples-3.1.3.jar
[root@node1 ~]# cd
[root@node1 ~]# vim wc.txt
hello tom
andy joy
hello rose
hello joy
mark andy
hello tom
andy rose
hello joy
[root@node1 ~]# hdfs dfs -mkdir -p /wordcount/input
[root@node1 ~]# hdfs dfs -put wc.txt /wordcount/input
[root@node1 ~]# hdfs dfs -ls /wordcount/input
Found 1 items
-rw-r--r-- 3 root supergroup 80 2021-10-28 09:53 /wordcount/input/wc.txt
[root@node1 ~]# ll
-rw-r--r-- 1 root root 80 10月 28 09:52 wc.txt
[root@node1 ~]# cd -
/opt/hadoop-3.1.3/share/hadoop/mapreduce
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /wordcount/input /wordcount/output
#出现如下bug:Requested resource=<memory:1536, vCores:1>, maximum allowed allocation=<memory:1024, vCores:4>
默认情况下AM的请求1.5G的内存,降低am的资源请求配置项到分配的物理内存限制以内。
修改配置mapred-site.xml (四台上都要修改),修改后重启hadoop集群,重启在执行
<property><name>yarn.app.mapreduce.am.resource.mb</name><value>256</value>
</property><!-- 默认对mapred的内存请求都是1G,也降低和合适的值。--><property><name>mapreduce.map.memory.mb</name><value>256</value>
</property>
<property><name>mapreduce.reduce.memory.mb</name><value>256</value>
</property>
但如果太低也会出现OOM的问题。ERROR [main] org.apache.hadoop.mapred.YarnChild: Error running child : java.lang.OutOfMemoryError: Java heap space
[root@node1 mapreduce]# hadoop jar hadoop-mapreduce-examples-3.1.3.jar wordcount /wordcount/input /wordcount/output
2021-10-28 10:33:10,194 INFO client.ConfiguredRMFailoverProxyProvider: Failing over to rm2
2021-10-28 10:33:10,635 INFO mapreduce.JobResourceUploader: Disabling Erasure Coding for path: /tmp/hadoop-yarn/staging/root/.staging/job_1635388346175_0001
2021-10-28 10:33:10,837 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-10-28 10:33:11,853 INFO input.FileInputFormat: Total input files to process : 1
2021-10-28 10:33:11,927 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-10-28 10:33:12,042 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-10-28 10:33:12,092 INFO mapreduce.JobSubmitter: number of splits:1
2021-10-28 10:33:12,299 INFO sasl.SaslDataTransferClient: SASL encryption trust check: localHostTrusted = false, remoteHostTrusted = false
2021-10-28 10:33:12,364 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1635388346175_0001
2021-10-28 10:33:12,364 INFO mapreduce.JobSubmitter: Executing with tokens: []
2021-10-28 10:33:12,662 INFO conf.Configuration: resource-types.xml not found
2021-10-28 10:33:12,663 INFO resource.ResourceUtils: Unable to find 'resource-types.xml'.
2021-10-28 10:33:13,177 INFO impl.YarnClientImpl: Submitted application application_1635388346175_0001
2021-10-28 10:33:13,235 INFO mapreduce.Job: The url to track the job: http://node4:8088/proxy/application_1635388346175_0001/
2021-10-28 10:33:13,235 INFO mapreduce.Job: Running job: job_1635388346175_0001
2021-10-28 10:33:22,435 INFO mapreduce.Job: Job job_1635388346175_0001 running in uber mode : false
2021-10-28 10:33:22,438 INFO mapreduce.Job: map 0% reduce 0%
2021-10-28 10:33:30,575 INFO mapreduce.Job: map 100% reduce 0%
2021-10-28 10:33:36,661 INFO mapreduce.Job: map 100% reduce 100%
2021-10-28 10:33:37,685 INFO mapreduce.Job: Job job_1635388346175_0001 completed successfully
2021-10-28 10:33:37,827 INFO mapreduce.Job: Counters: 53File System CountersFILE: Number of bytes read=71FILE: Number of bytes written=442495FILE: Number of read operations=0FILE: Number of large read operations=0FILE: Number of write operations=0HDFS: Number of bytes read=184HDFS: Number of bytes written=41HDFS: Number of read operations=8HDFS: Number of large read operations=0HDFS: Number of write operations=2Job Counters Launched map tasks=1Launched reduce tasks=1Data-local map tasks=1Total time spent by all maps in occupied slots (ms)=5238Total time spent by all reduces in occupied slots (ms)=3935Total time spent by all map tasks (ms)=5238Total time spent by all reduce tasks (ms)=3935Total vcore-milliseconds taken by all map tasks=5238Total vcore-milliseconds taken by all reduce tasks=3935Total megabyte-milliseconds taken by all map tasks=2681856Total megabyte-milliseconds taken by all reduce tasks=2014720Map-Reduce FrameworkMap input records=8Map output records=16Map output bytes=144Map output materialized bytes=71Input split bytes=104Combine input records=16Combine output records=6Reduce input groups=6Reduce shuffle bytes=71Reduce input records=6Reduce output records=6Spilled Records=12Shuffled Maps =1Failed Shuffles=0Merged Map outputs=1GC time elapsed (ms)=411CPU time spent (ms)=1930Physical memory (bytes) snapshot=375353344Virtual memory (bytes) snapshot=3779186688Total committed heap usage (bytes)=210911232Peak Map Physical memory (bytes)=203862016Peak Map Virtual memory (bytes)=1874542592Peak Reduce Physical memory (bytes)=171491328Peak Reduce Virtual memory (bytes)=1904644096Shuffle ErrorsBAD_ID=0CONNECTION=0IO_ERROR=0WRONG_LENGTH=0WRONG_MAP=0WRONG_REDUCE=0File Input Format Counters Bytes Read=80File Output Format Counters Bytes Written=41*input:是hdfs文件系统中数据所在的目录
*ouput:是hdfs中不存在的目录,mr程序运行的结果会输出到该目录
3.1.2 输出目录内容:
[root@node1 mapreduce]# hdfs dfs -ls /wordcount/output
Found 2 items
-rw-r--r-- 3 root supergroup 0 2021-10-28 10:33 /wordcount/output/_SUCCESS
-rw-r--r-- 3 root supergroup 41 2021-10-28 10:33 /wordcount/output/part-r-00000
[root@node1 mapreduce]# hdfs dfs -cat /wordcount/output/part-r-00000
andy 3
hello 5
joy 3
mark 1
rose 2
tom 2/_SUCCESS:是信号/标志文件
/part-r-00000:是reduce输出的数据文件
r:reduce的意思,00000是对应的reduce编号,多个reduce会有多个数据文件
3.2 自带的wordcount源码分析
首先将hadoop-mapreduce-examples-3.1.3.jar下载到桌面上,解压,使用反编译软件jd-gui打开C:\Users\Administrator\Desktop\hadoop-mapreduce-examples-3.1.3\org\apache\hadoop\examples目录下WordCount.class
package org.apache.hadoop.examples;import java.io.IOException;
import java.io.PrintStream;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Mapper.Context;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.Reducer.Context;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.GenericOptionsParser;public class WordCount
{public static void main(String[] args)throws Exception{Configuration conf = new Configuration();String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();if (otherArgs.length < 2) {System.err.println("Usage: wordcount <in> [<in>...] <out>");System.exit(2);}Job job = Job.getInstance(conf, "word count");job.setJarByClass(WordCount.class);job.setMapperClass(TokenizerMapper.class);job.setCombinerClass(IntSumReducer.class);job.setReducerClass(IntSumReducer.class);job.setOutputKeyClass(Text.class);job.setOutputValueClass(IntWritable.class);for (int i = 0; i < otherArgs.length - 1; i++) {FileInputFormat.addInputPath(job, new Path(otherArgs[i]));}FileOutputFormat.setOutputPath(job, new Path(otherArgs[(otherArgs.length - 1)]));System.exit(job.waitForCompletion(true) ? 0 : 1);}public static class IntSumReducer extends Reducer<Text, IntWritable, Text, IntWritable>{private IntWritable result = new IntWritable();public void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context)throws IOException, InterruptedException{int sum = 0;for (IntWritable val : values) {sum += val.get();}this.result.set(sum);context.write(key, this.result);}}public static class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable>{//hello tom helloprivate static final IntWritable one = new IntWritable(1);private Text word = new Text();public void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException{StringTokenizer itr = new StringTokenizer(value.toString());while (itr.hasMoreTokens()) {this.word.set(itr.nextToken());context.write(this.word, one);}}}
}
3.3 手写wordcount
对给定的文件,统计每一个单词出现的总次数。
3.3.1 环境准备
- 创建maven项目:wordcount
- 修改pom.xml文件,添加如下依赖:
<properties><project.build.sourceEncoding>UTF-8</project.build.sourceEncoding><maven.compiler.source>1.8</maven.compiler.source><maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies><dependency><groupId>junit</groupId><artifactId>junit</artifactId><version>4.13</version></dependency><dependency><groupId>org.apache.hadoop</groupId><artifactId>hadoop-client</artifactId><version>3.1.3</version></dependency><dependency><groupId>org.apache.logging.log4j</groupId><artifactId>log4j-slf4j-impl</artifactId><version>2.12.0</version></dependency>
</dependencies>
在项目的src/main/resources目录下,新建一个文件,名为“log4j2.xml”,在文件中填入一下内容
<?xml version="1.0" encoding="UTF-8"?>
<Configuration status="error" strict="true" name="XMLConfig"><Appenders><!-- 类型名为Console,名称为必须属性,在Logger配置中会使用到 --><Appender type="Console" name="STDOUT"><!-- 布局为PatternLayout的方式,输出样式为[INFO] [2021-10-18 11:29:12][org.test.Console]hadoop api code show --><Layout type="PatternLayout"pattern="[%p] [%d{yyyy-MM-dd HH:mm:ss}][%c{10}]%m%n" /></Appender></Appenders><Loggers><!-- 可加性为false --><Logger name="test" level="info" additivity="false"><AppenderRef ref="STDOUT" /></Logger><!-- root logger Config设置 --><Root level="info"><AppenderRef ref="STDOUT" /></Root></Loggers>
</Configuration>
-
从集群拷贝这四个文件到当前项目的src/main/resources目录下
core-site.xml
hdfs-site.xml
mapred-site.xml
yarn-site.xml
3.3.2 编写WCMapper类
package com.itbaizhan;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**一、输入数据:* KEYIN:输入数据的key的类型,默认的key是文本的偏移量* VALUEIN:输入数据的value的类型, 这行文本的内容 hello tom* 二、输出数据* KEYOUT:处理后输出的key的类型* VALUEOUT:处理后输出的value的类型 1*/
public class WCMapper extends Mapper<LongWritable, Text, Text, IntWritable> {//定义输出的value的对象private static final IntWritable valueOut = new IntWritable(1);//定义输出的key的对象private Text keyOut = new Text();//文本中的每一行内容调用一次map方法@Overrideprotected void map(LongWritable key, Text value, Mapper<LongWritable, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {if(value!=null) {//value就是读取到的当前行中的内容,并将之转换为字符串String lineContenct = value.toString();//将字符串进行处理:先去掉两端的空格,然后在按照空格进行切分String[] words = lineContenct.trim().split(" ");//遍历数组,逐一进行输出for(String word:words){//将word内容封装到keyOut中keyOut.set(word);//将kv对输出context.write(keyOut, valueOut);}}}
}
3.3.3 编写 WCReducer类
package com.itbaizhan;import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;import java.io.IOException;/**输入的kv对的类型:KEYIN, VALUEIN, (分别和Mapper输出的kv对的类型保持一致)* 输出的kv对的类型:KEYOUT, VALUEOUT*/
public class WCReducer extends Reducer<Text, IntWritable,Text,IntWritable> {private int sum;private IntWritable valOut = new IntWritable();//相同的key为一组,调用一次reduce方法@Overrideprotected void reduce(Text key, Iterable<IntWritable> values, Reducer<Text, IntWritable, Text, IntWritable>.Context context) throws IOException, InterruptedException {//hello 1//hello 1//hello 1//key:hello values: 1,1,1//首先将sum重置为0,避免上一组数据计算参数干扰sum = 0;//遍历values,累加求和for(IntWritable value:values){sum += value.get();}//将计算后的结果sum封装到valOut中valOut.set(sum);//输出context.write(key,valOut);}
}
3.3.4 编写WCDriver类
package com.itbaizhan;import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;import java.io.IOException;/**WordCount程序的入口类:* 在该类中配置job作业的相关参数、创建job对象、设置输入输出路径、提交作业*/
public class WCDriver {public static void main(String[] args) throws IOException, InterruptedException, ClassNotFoundException {//0.教研输入参数if(args==null||args.length<2){System.out.println("Usage:hadoop jar xxx.jar com.itbaizhan.WCDriver <inpath> <outpath>");System.exit(0);}//1.创建配置文件对象Configuration conf = new Configuration();//2.设置本地运行conf.set("mapreduce.framework.name","local");//3.创建job对象Job job = Job.getInstance(conf);//6.设置关联Driver类job.setJarByClass(WCDriver.class);//7.设置Mapper相关信息:Mapper类,kv的类型job.setMapperClass(WCMapper.class);job.setMapOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//8.设置reducer相关信息:Reducer类和kv的类型job.setReducerClass(WCReducer.class);job.setOutputKeyClass(Text.class);job.setMapOutputValueClass(IntWritable.class);//9.设置输入路径FileInputFormat.addInputPath(job, new Path(args[0]));//10.设置输出路径FileOutputFormat.setOutputPath(job,new Path(args[1]));//4.提交作业boolean result = job.waitForCompletion(true);//5.根据返回结果结束程序System.exit(result?0:1);}
}
3.4.5 运行测试
一. 本地测试:
-
直接在WCDriver类中右键->Run,出现如下错误提示:
Usage:hadoop jar xxx.jar com.itbaizhan.WCDriver <inpath> <outpath>
-
原因是我们在运行前没有设置输入和输出路径。
-
检查输出路径是否存在,如果存在,则删除
[root@node1 ~]# hdfs dfs -ls /wordcount
Found 2 items
drwxr-xr-x - root supergroup 0 2021-10-28 09:53 /wordcount/input
drwxr-xr-x - root supergroup 0 2021-10-28 10:33 /wordcount/output
[root@node1 ~]# hdfs dfs -rm /wordcount/output
rm: `/wordcount/output': Is a directory
[root@node1 ~]# hdfs dfs -rm -r /wordcount/output
Deleted /wordcount/output-
设置输入输出路径
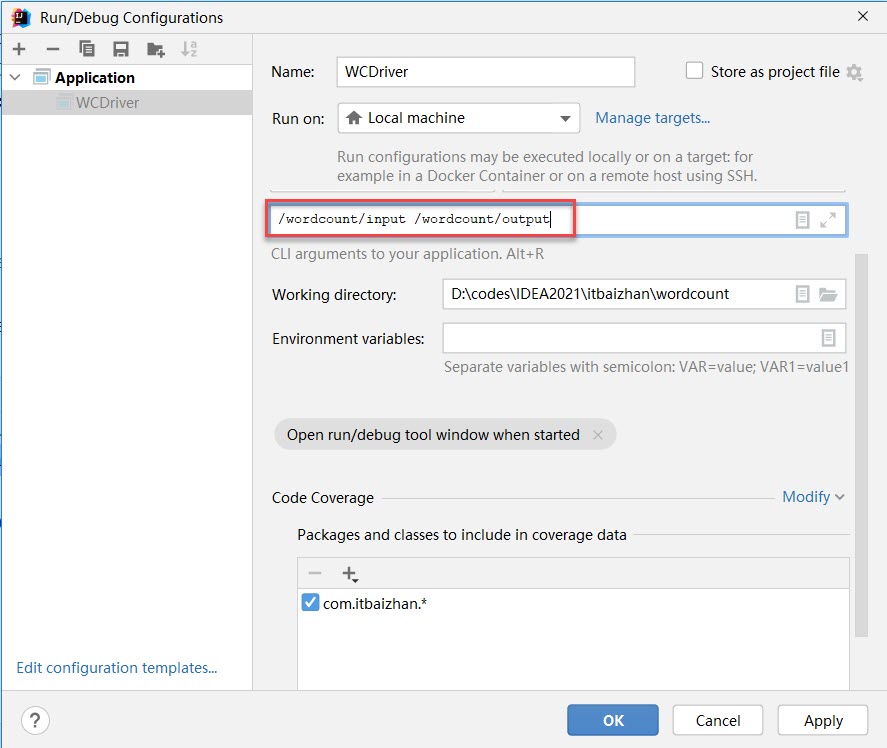
填写完输入输出路径后,点击 Apply 然后再点击OK。
-
IDEA中运行WCDriver:直接在WCDriver类中右键->Run
-
查看运行结果:
[root@node1 ~]# hdfs dfs -ls /wordcount/output
Found 2 items
-rw-r--r-- 3 root supergroup 0 2021-10-29 01:53 /wordcount/output/_SUCCESS
-rw-r--r-- 3 root supergroup 41 2021-10-29 01:53 /wordcount/output/part-r-00000
[root@node1 ~]# hdfs dfs -cat /wordcount/output/part-r-00000
andy 3
hello 5
joy 3
mark 1
rose 2
tom 2二. 集群中测试:
- 先注释掉WCDriver类中://conf.set("mapreduce.framework.name","local");
- 用maven打jar包,需要在pom.xml文件中添加的打包插件依赖:
<build><pluginManagement><plugins><plugin><artifactId>maven-clean-plugin</artifactId><version>3.1.0</version></plugin><plugin><artifactId>maven-resources-plugin</artifactId><version>3.0.2</version></plugin><plugin><artifactId>maven-compiler-plugin</artifactId><version>3.8.0</version></plugin><plugin><artifactId>maven-surefire-plugin</artifactId><version>2.22.1</version></plugin><plugin><artifactId>maven-jar-plugin</artifactId><version>3.0.2</version></plugin><plugin><artifactId>maven-install-plugin</artifactId><version>2.5.2</version></plugin><plugin><artifactId>maven-deploy-plugin</artifactId><version>2.8.2</version></plugin><plugin><artifactId>maven-site-plugin</artifactId><version>3.7.1</version></plugin><plugin><artifactId>maven-project-info-reports-plugin</artifactId><version>3.0.0</version></plugin></plugins></pluginManagement>
</build>
注意:如果工程上显示红叉。在项目上右键->maven->Reload Project即可。
-
将程序打成jar包,然后拷贝到Hadoop集群中node1的/root目录下。
步骤详情:maven->clean-> install。等待编译完成就会在项目的target文件夹中生成jar包。如果看不到。在项目上右键->Refresh,即可看到。修改不带依赖的jar包名称为wc.jar,并拷贝该jar包到Hadoop集群。
-
执行WordCount程序
[root@node1 ~]#yarn jar wc.jar com.itbaizhan.WCDriver /wordcount/input /wordcount/output23.查看结果
[root@node1 ~]# hdfs dfs -cat /wordcount/output2/part-r-00000
andy 3
hello 5
joy 3
mark 1
rose 2
tom 2四、Hadoop序列化与反序列化
4.1 什么是序列化和反序列
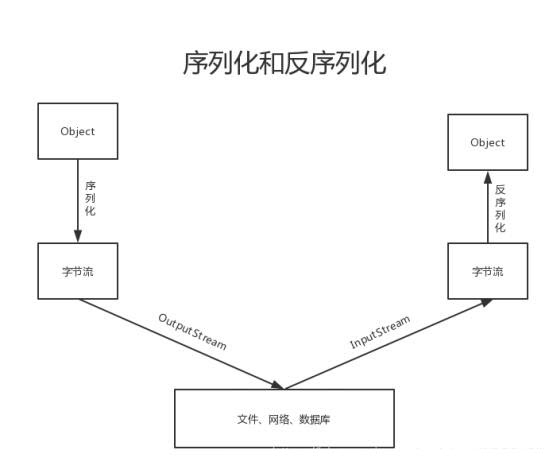
序列化定义:就是把内存中的对象,转换为字节序列,以便于存储到磁盘或网络传输,此过程被称为序列化。
反序列化定义:将字节序列或磁盘中的持久化字节数据,转换为内存中的对象的过程。
##4.2 hadoop为什么需要序列化和反序列化
数据经过mapper 任务的处理后,会产生溢出文件,这些文件会被保存到磁盘上。mapper任务完成后,reducer会通过http get的方式从mapper端拷贝对应分区的数据,中间需要经过网络传输。需要做持久化(存盘)或网络传输,这中间就需要做数据的序列化和反序列操作。
期待下一期吧!