06.LangChain的介绍和入门
1 什么是LangChain
LangChain由 Harrison Chase 创建于2022年10月,它是围绕LLMs(大语言模型)建立的一个应用开发框架。LLMs使用机器学习算法,基于海量数据来训练,通常是对语言模型进行建模,GPT3.5、GPT4,国内百度的文心一言、阿里的通义千问,字节的豆包等等属于LLMs。
LangChain自身并不开发LLMs,它的核心理念是为各种LLMs实现通用的接口,把LLMs相关的组件“链接”在一起,简化LLMs应用的开发难度,方便开发者快速地开发复杂的LLMs应用。LangChain目前有两个语言的实现:python、nodejs。langchain 更像是开发应用的脚手架。
本章节将会从两个方面全面介绍LangChain:一个是LangChain组件的基本概念和应用;另一个是LangChain常见的使用场景。
参考官网介绍:https://python.langchain.com/docs/integrations/text_embedding/huggingfacehub
2 LangChain主要组件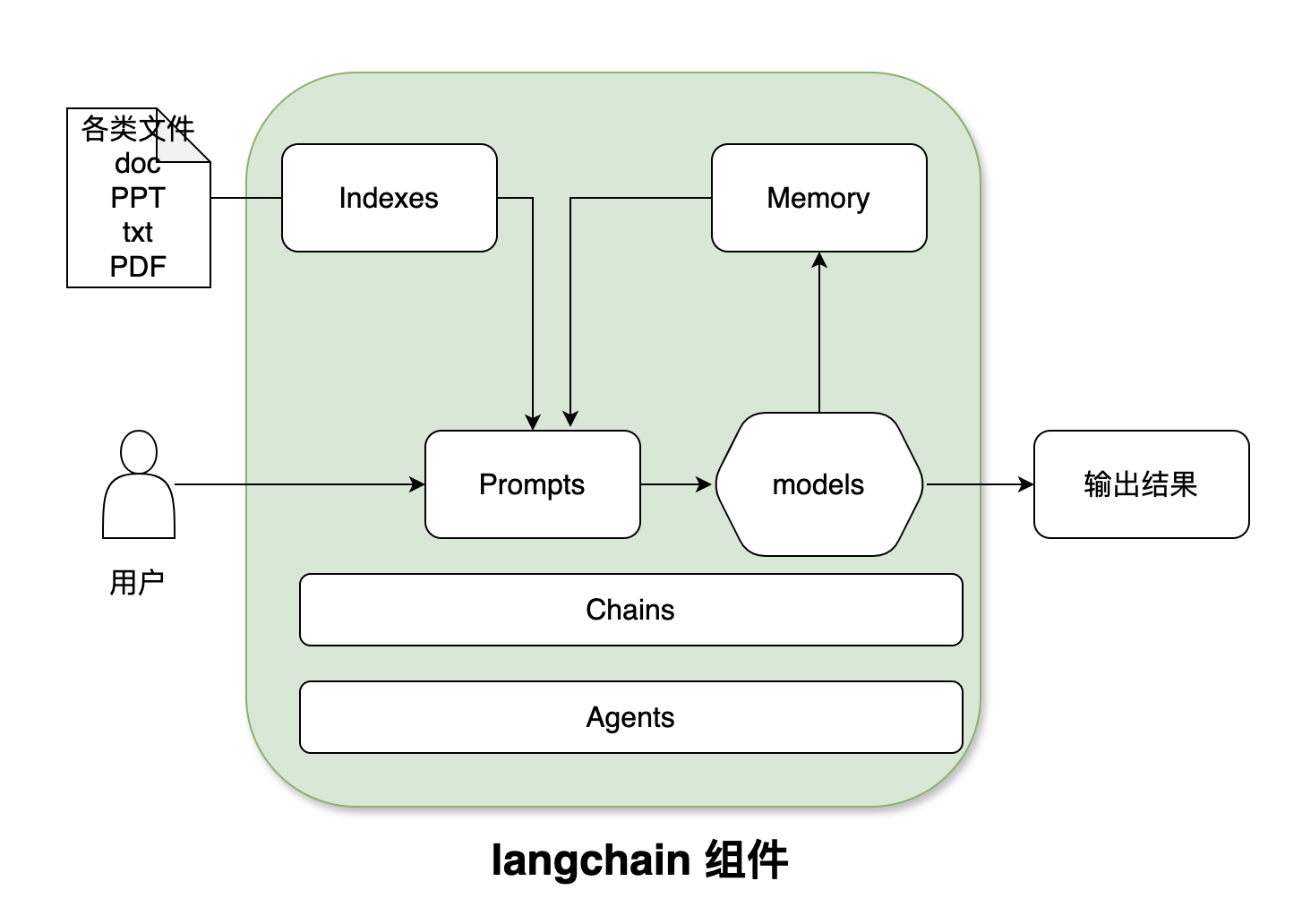
一个LangChain的应用是需要多个组件共同实现的,LangChain主要支持6种组件:
- Models:模型,各种类型的模型和模型集成,比如GPT-4
- Prompts:提示,包括提示管理、提示优化和提示序列化
- Memory:记忆,用来保存和模型交互时的上下文状态
- Indexes:索引,用来结构化文档,以便和模型交互
- Chains:链,一系列对各种组件的调用
- Agents:代理,决定模型采取哪些行动,执行并且观察流程,直到完成为止
2.1 Models
现在市面上的模型多如牛毛,各种各样的模型不断出现,LangChain模型组件提供了与各种模型的集成,并为所有模型提供一个精简的统一接口。
LangChain目前支持三种类型的模型:LLMs、Chat Models(聊天模型)、Embeddings Models(嵌入模型).
-
LLMs: 大语言模型接收文本字符作为输入,返回的也是文本字符.
-
聊天模型: 基于LLMs, 不同的是它接收聊天消(一种特定格式的数据)作为输入,返回的也是聊天消息.
-
文本嵌入模型: 文本嵌入模型接收文本作为输入, 返回的是浮点数列表.
LangChain支持的三类模型,它们的使用场景不同,输入和输出不同,开发者需要根据项目需要选择相应。
2.1.1 LLMs (大语言模型)
LLMs使用场景最多,常用大模型的下载库:https://huggingface.co/models
接下来我们以「通义千问」模型为例, 使用该类模型的组件:
- 第一步:安装必备的工具包:langchain和openai
pip install openai dashscope
pip install langchain langchain_community
注意,在使用openai模型之前,必须开通OpenAI API服务,需要获得API Token。
- 第二步:继续使用千问大模型,没有 API Key 可以自己申请。
- 第三部:代码实现
from langchain_community.llms import Tongyillm = Tongyi(api_key="sk-**",model="qwen-plus")res = llm.invoke("帮我讲个笑话吧")
print(res)
结果输出:
当然可以!给你讲个轻松的冷笑话:有一天,一根火柴走进了森林,结果迷路了。
它突然灵机一动,把自己点着了,想看看路在哪儿……
结果,它被烧死了 😭冷不冷?要不要再给你来一个更暖和的?😄
2.1.2 Chat Models (聊天模型)
聊天消息包含下面几种类型,使用时需要按照约定传入合适的值:
- AIMessage: 就是 AI 输出的消息,可以是针对问题的回答.
- HumanMessage: 人类消息就是用户信息,由人给出的信息发送给LLMs的提示信息,比如“实现一个快速排序方法”.
- SystemMessage: 可以用于指定模型具体所处的环境和背景,如角色扮演等。你可以在这里给出具体的指示,比如“作为一个代码专家”,或者“返回json格式”.
- ChatMessage: Chat 消息可以接受任意角色的参数,但是在大多数时间,我们应该使用上面的三种类型.
LangChain支持的常见聊天模型有:
| 模型 | 描述 |
|---|---|
| ChatOpenAI | OpenAI聊天模型 |
| AzureChatOpenAI | Azure提供的OpenAI聊天模型 |
| PromptLayerChatOpenAI | 基于OpenAI的提示模版平台 |
举例说明:
from langchain_community.chat_models import ChatTongyi
from langchain_core.messages import HumanMessagechat = ChatTongyi(api_key="sk-**",model="qwen-plus")messages = [HumanMessage(content="给我写一首唐诗")
]
res = chat.invoke(messages)
print(res)# 打印结果:
'''
content='当然可以,下面是一首仿唐代风格的五言绝句,意境清幽,希望你喜欢:\n\n---\n\n**山中夜雨** \n\n空山新雨后, \n幽径隐苔青。 \n松月生凉意, \n随风入梦轻。\n\n---\n\n这首诗描绘了夜雨过后山中的静谧与清新,有唐诗常见的自然意境和悠远情怀。如果你想要某种特定主题(如边塞、送别、咏物等)的诗,也可以告诉我,我来为你定制一首。' additional_kwargs={} response_metadata={'model_name': 'qwen-plus', 'finish_reason': 'stop', 'request_id': '4a566dd4-8e52-9c53-b0ab-17157ce8b31e', 'token_usage': {'input_tokens': 17, 'output_tokens': 112, 'total_tokens': 129, 'prompt_tokens_details': {'cached_tokens': 0}}} id='run--7fad69c4-b32f-4421-a252-5ffaed9179bb-0''''
2.1.3 提示模板
在上面的例子中,模型默认是返回纯文本结果的,如果想让模型返回想要的数据格式(比如json格式),可以使用提示模版。
提示模板就是把一些常见的提示整理成模板,用户只需要修改模板中特定的词语,就能快速准确地告诉模型自己的需求。我们看个例子:
from langchain_core.prompts import ChatPromptTemplate
from langchain_community.chat_models import ChatTongyi# 创建原始模板
template_str = """您是一位专业的鲜花店文案撰写员。\n
对于售价为 {price} 元的 {flower_name} ,您能提供一个吸引人的简短描述吗?
注意: 文字不要超过50个字符 """# 根据原始模板创建LangChain提示模板
prompt_template = ChatPromptTemplate.from_template(template_str)
prompt = prompt_template.format_messages(flower_name="玫瑰", price='50')print('prompt-->', prompt)
# 输出指令结果
"""
prompt--> [HumanMessage(content='您是一位专业的鲜花店文案撰写员。\n\n对于售价为 50 元的 玫瑰 ,您能提供一个吸引人的简短描述吗?\n注意: 文字不要超过50个字符 ', additional_kwargs={}, response_metadata={})]"""
# 实例化模型
chat = ChatTongyi(api_key="sk-**",model="qwen-plus")
print(chat.invoke(prompt))
# 打印结果
"""
content='玫瑰50元,浪漫满溢,心动之选。' additional_kwargs={} response_metadata={'model_name': 'qwen-plus', 'finish_reason': 'stop', 'request_id': '6f73fe5d-e4cf-939b-b588-c1ef1dca611f', 'token_usage': {'input_tokens': 57, 'output_tokens': 13, 'total_tokens': 70, 'prompt_tokens_details': {'cached_tokens': 0}}} id='run--40cb54a9-4063-418e-8c84-51cee531c5b3-0'
"""
2.1.4 Embeddings Models(嵌入模型)
Embeddings Models特点:将字符串作为输入,返回一个浮动数的列表。在NLP中,Embedding的作用就是将数据进行文本向量化。
Embeddings Models可以为文本创建向量映射,这样就能在向量空间里去考虑文本,执行诸如语义搜索之类的操作,比如说寻找相似的文本片段。
接下来我们以一个OpenAI文本嵌入模型的例子进行说明:
from langchain_community.embeddings import DashScopeEmbeddings# 实例化模型
embed = DashScopeEmbeddings(dashscope_api_key="sk-**",model="text-embedding-v3")
res1 = embed.embed_query('这是第一个测试文档')
print(res1)
# 打印结果:
'''
[-0.07558029145002365, 0.03589281439781189, -0.06599583476781845,...]
'''
res2 = embed.embed_documents(['这是第一个测试文档', '这是第二个测试文档'])
print(res2)
# 打印结果:
'''
[[-0.07558029145002365, 0.03589281439781189, -0.06599583476781845,...]]
'''
上述代码中,我们分别使用了两种方法来进行文本的向量表示,他们最大不同在于:embed_query()接收一个字符串的输入,而embed_documents可以接收一组字符串。
LangChain集成的文本嵌入模型有:
- AzureOpenAI、Baidu Qianfan、Hugging Face Hub、OpenAI、Llama-cpp、SentenceTransformers
2.2 Prompts
Prompt是指当用户输入信息给模型时加入的提示,这个提示的形式可以是zero-shot或者few-shot等方式,目的是让模型理解更为复杂的业务场景以便更好的解决问题。
提示模板:如果你有了一个起作用的提示,你可能想把它作为一个模板用于解决其他问题,LangChain就提供了PromptTemplates组件,它可以帮助你更方便的构建提示。
zero-shot提示方式:
from langchain_core.prompts import PromptTemplate
from langchain_community.llms import Tongyi# 定义模板
template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字"prompt = PromptTemplate(input_variables=["lastname"],template=template,
)prompt_text = prompt.format(lastname="王")
print(prompt_text)
# result: 我的邻居姓王,他生了个儿子,给他儿子起个名字llm = Tongyi(api_key="sk-**")result = llm.invoke(prompt_text)
print(result)
结果输出:
我的邻居姓王,他生了个儿子,给他儿子起个名字
恭喜你的邻居王先生喜得贵子!给孩子起名是一件非常重要又有趣的事情,名字往往寄托了父母的美好期望。如果你愿意,我可以根据不同的风格和寓意来推荐几个名字供参考:---### 一、传统大气型(寓意聪慧、有为)
1. **王承宇** —— “承”表示继承、担当,“宇”象征气度宽广。
2. **王浩然** —— 出自“浩然正气”,寓意正直、胸怀广阔。
3. **王景行** —— 取自成语“高山景行”,形容品德高尚、前程远大。---### 二、文雅诗意型(富有文化气息)
1. **王清和** —— 出自古诗“清和四月初”,寓意温润、清明。
2. **王知远** —— 寓意有见识、志向远大。
3. **王书尧** —— “书”代表学问,“尧”是中国古代圣王,寓意贤能。---### 三、现代简洁型(朗朗上口,易记易写)
1. **王亦辰** —— 简洁大方,“辰”象征时间、星辰,寓意未来可期。
2. **王子墨** —— 带有文艺气质,“墨”代表文采与智慧。
3. **王言蹊** —— 出自“桃李不言,下自成蹊”,寓意踏实有德。---### 四、结合生辰八字或五行(如需专业取名)
如果知道孩子的出生时间,可以分析五行缺什么,再用名字补足。例如:
- 如果缺木 → 可以用“林、森、楷、楠”等字;
- 如果缺水 → 可用“泽、涵、沐、澜”等字。---你也可以告诉我王先生对名字有什么具体想法,比如希望表达哪种寓意、是否偏好某个字或者某种风格,我可以更有针对性地来起名。需要我帮你拟一个正式的起名建议书吗?😊
few-shot提示方式:
from langchain_core.prompts import PromptTemplate, FewShotPromptTemplate
from langchain_community.llms import Tongyiexamples = [{"word": "开心", "antonym": "难过"},{"word": "高", "antonym": "矮"},
]example_template = """
单词: {word}
反义词: {antonym}
"""example_prompt = PromptTemplate(input_variables=["word", "antonym"],template=example_template,
)few_shot_prompt = FewShotPromptTemplate(examples=examples,example_prompt=example_prompt,prefix="给出每个单词的反义词",suffix="单词: {input}\n反义词:",input_variables=["input"],example_separator="\n",
)prompt_text = few_shot_prompt.format(input="粗")
print(prompt_text)
print('*' * 80)llm = Tongyi(api_key="sk-**")result = llm.invoke(prompt_text)
print(result)# 打印结果:
'''
给出每个单词的反义词单词: 开心
反义词: 难过单词: 高
反义词: 矮单词: 粗
反义词:
********************************************************************************
单词: 粗
反义词: 细
'''
2.3 Chains(链)
在LangChain中,Chains描述了将LLM与其他组件结合起来完成一个应用程序的过程.
针对上一小节的提示模版例子,zero-shot里面,我们可以用链来连接提示模版组件和模型,进而可以实现代码的更改:
from langchain_core.prompts import PromptTemplate
from langchain_community.llms import Tongyi
# from langchain.chains.llm import LLMChainllm = Tongyi(api_key="sk-**")
# 定义模板
template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字"
prompt = PromptTemplate(template=template, input_variables=["lastname"])chain = prompt | llm # 创建链
result = chain.invoke(input="王")
print(result)# 打印结果:
'''
恭喜你的邻居王姓人家喜得贵子!给孩子起名是一件既重要又有趣的事情,名字往往寄托了父母的美好期望。以下是一些适合姓“王”的男孩名字建议,供你和你的邻居参考:### 一、寓意美好、经典大气的名字:
1. **王宇轩**(yǔ xuān):宇,意为广大空间;轩,高大气派,寓意气度不凡。
2. **王子涵**(zǐ hán):子,古代对男性的尊称;涵,有内涵、包容。
3. **王浩然**(hào rán):浩然正气,出自《孟子》,寓意胸怀宽广、正义凛然。
4. **王泽楷**(zé kǎi):泽,恩泽、善良;楷,楷模,寓意品德高尚。
5. **王俊熙**(jùn xī):俊,英俊、才智出众;熙,光明、兴盛。### 二、文雅诗意型:
1. **王清和**(qīng hé):取自“清和平允”,形容人温和公正。
2. **王景行**(jǐng xíng):源自《诗经》“高山仰止,景行行止”,寓意品德高尚、前程远大。
3. **王书尧**(shū yáo):书,代表文化修养;尧,古代圣王,寓意聪慧仁德。
4. **王云舟**(yún zhōu):如云似舟,意境悠远,富有诗意。### 三、现代简约风:
1. **王晨阳**(chén yáng):清晨阳光,象征希望与活力。
2. **王启航**(qǐ háng):寓意人生刚刚启程,充满可能。
3. **王乐言**(lè yán):快乐表达,寓意开朗乐观。
4. **王睿辰**(ruì chén):睿,聪明智慧;辰,星辰,象征光辉未来。如果你愿意,也可以告诉我孩子的出生时间(生辰八字)、属相或者父母的期望方向(比如希望孩子聪明、有担当、文采好等),我可以帮你量身定制一个更有讲究的名字。也别忘了,送一份祝福给这位新晋爸爸哦 😊
'''
如果你想将第一个模型输出的结果,直接作为第二个模型的输入,还可以使用LangChain的SimpleSequentialChain, 代码如下:
from langchain_core.prompts import PromptTemplate
from langchain_community.llms import Tongyi
from langchain.chains.sequential import SimpleSequentialChain
from langchain.chains import LLMChainllm = Tongyi(api_key="sk-**")
# 定义模板
template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字"
prompt = PromptTemplate(template=template, input_variables=["lastname"])first_chain = LLMChain(prompt=prompt, llm=llm) # 创建链second_template = "我的邻居家儿子叫{child_name},给他起一个小名"
second_prompt = PromptTemplate(template=second_template, input_variables=["child_name"])
second_chain = LLMChain(prompt=second_prompt, llm=llm)all_chain = SimpleSequentialChain(chains=[first_chain, second_chain], verbose=True)
print(all_chain.run("王"))# 结果输出
'''
太好了!既然已经为王先生的宝宝准备了正式名字的参考,我们再来起一个小名吧~小名通常更亲切、可爱,也更容易被家人和邻居们记住。以下是几种不同风格的小名供您参考:---### 🌸 温馨可爱型
1. **乐乐** — 寓意快乐成长,简单好记
2. **安安** — 平平安安,温柔贴心
3. **团团** — 圆滚滚、讨人喜欢
4. **果果** — 果断聪慧,也有“开花结果”的吉祥意味 ---### 🌟 创意洋气型
1. **小宇** — 源自大名中的“宇”,也寓意胸怀广阔
2. **辰辰** — 若大名叫“昱辰”或“晨希”,可以呼应
3. **墨墨** — 适合文艺气质的家庭,也适合叫“王墨言”
4. **元宝** — 可爱又有福气,寓意招财进宝 ---### 🐾 生肖/季节相关(假设宝宝属兔/春季出生)
1. **小禾** — 春天万物生长,寓意生机勃勃
2. **沐沐** — 如春风拂面,清新自然
3. **米豆** — 软萌又健康,像春天的小豆芽
4. **跳跳糖** — 如果是活泼可爱的男孩,这个小名很有个性 ---### 🧸 动物/食物系小名(适合邻里间逗趣称呼)
1. **奶糖** — 听起来软糯可爱
2. **布丁** — Q弹有趣,适合乖巧宝宝
3. **毛豆** — 有生命力,也很接地气
4. **小熊** — 萌萌哒,适合邻居家小朋友互动时称呼 ---如果您希望小名与孩子的**生辰八字、生肖、家庭文化**等更紧密结合,我也可以为您定制化设计一个专属小名哦!比如:
- 如果孩子是**清明节前后出生**,可以叫 **清清 / 明明 / 小禾**
- 如果属**兔**,可以叫 **蹦蹦 / 米团 / 小葵**(象征温顺与好运)欢迎告诉我更多信息,我可以继续优化推荐!🎉'''
使用管道符**|**来改写上面的程序
from langchain_core.prompts import PromptTemplate
from langchain_community.llms import Tongyi
from langchain_core.runnables import RunnableSequencellm = Tongyi(api_key="sk-**")
# 定义模板
template = "我的邻居姓{lastname},他生了个儿子,给他儿子起个名字"
prompt = PromptTemplate(template=template, input_variables=["lastname"])second_template = "我的邻居家儿子叫{child_name},给他起一个小名"
second_prompt = PromptTemplate(template=second_template, input_variables=["child_name"])# 创建链
first_chain = prompt | llm # 创建链
second_chain = second_prompt | llm # 创建链
all_chain = RunnableSequence(first=first_chain, last=second_chain)print(all_chain.invoke({"lastname": "王"}))
# 输出结果
"""
恭喜你的邻居王姓喜得贵子!真是可喜可贺🎉!既然大名是「恭喜」,听起来就充满了欢乐和祝福的意味~那我们可以为宝宝起一个可爱又贴切的小名,让名字更有层次感、也更适合家人日常亲昵地呼唤。以下是一些适合男孩、且契合“恭喜”这个大名的小名建议:"""
2.4 Agents (代理)
Agents 也就是代理,它的核心思想是利用一个语言模型来选择一系列要执行的动作。
在 LangChain 中 Agents 的作用就是根据用户的需求,来访问一些第三方工具(比如:搜索引擎或者数据库),进而来解决相关需求问题。
为什么要借助第三方库?
- 因为大模型虽然非常强大,但是也具备一定的局限性,比如不能回答实时信息、处理数学逻辑问题仍然非常的初级等等。因此,可以借助第三方工具来辅助大模型的应用。
几个重要的概念:
- Agent代理:
- 制定计划和思考下一步需要采取的行动。
- 负责控制整段代码的逻辑和执行,代理暴露了一个接口,用来接收用户输入。
- LangChain 提供了不同类型的代理(主要罗列一下三种):
- zero-shot-react-description: 代理使用ReAct框架,仅基于工具的描述来确定要使用的工具.此代理使用 ReAct 框架确定使用哪个工具 仅基于工具的描述。缺乏 会话式记忆。
- structured-chat-zero-shot-react-description:能够使用多输入工具,结构化的参数输入。
- conversational-react-description:这个代理程序旨在用于对话环境中。提示设计旨在使代理程序有助于对话。 它使用ReAct框架来决定使用哪个工具,并使用内存来记忆先前的对话交互。
-
Tool工具:
-
解决问题的工具
- 第三方服务的集成,例如计算、网络(谷歌、bing)、代码执行等等
-
Toolkit工具包:
-
用于完成特定目标所需要的工具组,比如
create_csv_agent可以使用模型解读csv文件。 -
AgentExecutor代理执行器:
-
它将代理和工具列表包装在一起, 负责迭代运行代理的循环,直到满足停止的标准。
- 这是实际调用agent并执行其选择的动作部分。
现在我们实现一个使用代理的例子:假设我们想查询一下中国目前有多少人口?我们可以使用多个代理工具,让Agents选择执行。代码如下:
from langchain.agents import load_tools
# from langchain_community.agent_toolkits.load_tools import load_tools
from langchain.agents import initialize_agent
from langchain.agents import AgentType
from langchain_community.chat_models import ChatTongyi
from langchain import PromptTemplate# 1 pip install duckduckgo-search numexpr# 2 实例化大模型
llm = ChatTongyi(api_key="sk-**")# 3 设置工具
# "serpapi"实时联网搜素工具、"math": 数学计算的工具
# tools = load_tools(["serpapi", "llm-math"], llm=llm)
tools = load_tools(["ddg-search", "llm-math"], llm=llm)# 4 实例化代理Agent:返回 AgentExecutor 类型的实例
agent = initialize_agent(tools, llm, agent=AgentType.ZERO_SHOT_REACT_DESCRIPTION, verbose=True)print('agent', agent)
# 5 准备提示词prompt_template = "中国目前有多少人口"
prompt = PromptTemplate.from_template(prompt_template)
print('prompt-->', prompt)# 6 代理Agent工作
agent.run(prompt)# 结果输出
"""
> Entering new AgentExecutor chain...
The question is asking about the current population of China. This is a factual question that requires up-to-date data.Action: duckduckgo_search
Action Input: China current population 2023/Users/chan/project/czbk/.venv/lib/python3.10/site-packages/langchain_community/utilities/duckduckgo_search.py:63: RuntimeWarning: This package (`duckduckgo_search`) has been renamed to `ddgs`! Use `pip install ddgs` instead.with DDGS() as ddgs:Observation: Jul 11, 2024 · In 2023., the world reached a total population of 8,091,734,930 and 🇮🇳 India was the most populous country that year, with a total of 1,438,069,596 people. Followed by 🇨🇳 China, with … Jan 17, 2025 · China ceded its position as the most populated country to India in 2023, after the population began to fall in 2022. Women are having fewer babies despite the easing of China’s … Jan 17, 2025 · India overtook China in 2023 as the world’s most populous country. China’s declining population, which fell in 2022 for the first time in six decades, stems from a 1980s policy — … Feb 7, 2025 · According to estimates by the United Nations, India surpassed China as the country with the largest population in the world in 2023. Find the most relevant and recent facts on the... Jan 17, 2025 · The National Bureau of Statistics said the total number of people in China dropped by 1.39 million to 1.408 billion in 2024, compared to 1.409 billion in 2023. The total number of births …
Thought:The search results indicate that China's population was approximately 1.409 billion in 2023, but it declined to 1.408 billion in 2024. However, the exact current population (as of 2025) is not clearly stated. For the most up-to-date figure, further verification may be needed.Final Answer: As of 2023, China's population was approximately 1.409 billion, and it slightly declined to 1.408 billion in 2024. Exact current figures may require more recent data.> Finished chain."""
注意,如果运行这个示例你要使用serpapi, 需要申请
serpapitoken,并且设置到环境变量SERPAPI_API_KEY,然后安装依赖包google-search-results
查询所有工具的名称
from langchain.agents import get_all_tool_names
results = get_all_tool_names()
print(results)
# ['python_repl', 'requests', 'requests_get', 'requests_post', 'requests_patch', 'requests_put', 'requests_delete', 'terminal', 'sleep', 'wolfram-alpha', 'google-search', 'google-search-results-json', 'searx-search-results-json', 'bing-search', 'metaphor-search', 'ddg-search', 'google-serper', 'google-scholar', 'google-serper-results-json', 'searchapi', 'searchapi-results-json', 'serpapi', 'dalle-image-generator', 'twilio', 'searx-search', 'wikipedia', 'arxiv', 'golden-query', 'pubmed', 'human', 'awslambda', 'sceneXplain', 'graphql', 'openweathermap-api', 'dataforseo-api-search', 'dataforseo-api-search-json', 'eleven_labs_text2speech', 'google_cloud_texttospeech', 'news-api', 'tmdb-api', 'podcast-api', 'memorize', 'llm-math', 'open-meteo-api']
LangChain支持的工具如下:
| 工具 | 描述 |
|---|---|
| Bing Search | Bing搜索 |
| Google Search | Google搜索 |
| Google Serper API | 一个从google搜索提取数据的API |
| Python REPL | 执行python代码 |
| Requests | 执行python代码 |
2.5 Memory
大模型本身不具备上下文的概念,它并不保存上次交互的内容,ChatGPT之所以能够和人正常沟通对话,因为它进行了一层封装,将历史记录回传给了模型。
因此 LangChain 也提供了Memory组件, Memory分为两种类型:短期记忆和长期记忆。短期记忆一般指单一会话时传递数据,长期记忆则是处理多个会话时获取和更新信息。
目前的Memory组件只需要考虑ChatMessageHistory。举例分析:
from langchain.memory import ChatMessageHistoryhistory = ChatMessageHistory()
history.add_user_message("在吗?")
history.add_ai_message("有什么事?")print(history.messages)
#打印结果:
'''
[HumanMessage(content='在吗?', additional_kwargs={}, response_metadata={}), AIMessage(content='有什么事?', additional_kwargs={}, response_metadata={})]
'''
和 Qwen大模型结合,直接使用ConversationChain:
from langchain.chains import ConversationChain
from langchain_community.chat_models import ChatTongyillm = ChatTongyi(api_key="sk-**")conversation = ConversationChain(llm=llm)
resut1 = conversation.predict(input="小明有1只猫")
print(resut1)
print('*' * 80)
resut2 = conversation.predict(input="小刚有2只狗")
print(resut2)
print('*' * 80)
resut3 = conversation.predict(input="小明和小刚一共有几只宠物?")
print(resut3)
print('*' * 80)
# 打印结果:
'''
小明有一只猫,听起来是一个很温馨的宠物家庭。这只猫可能有着独特的性格和习惯,比如喜欢在阳光下打盹、对玩具老鼠充满兴趣,或者总是准时在晚饭时间跑到主人身边。如果你愿意分享更多关于小明或他的猫的故事,我可以和你一起探讨更多有趣的细节!
********************************************************************************
小刚有两只狗,这一定让他的生活充满了活力和乐趣。两只狗可能有不同的性格,比如一只活泼好动,喜欢跑来跑去,另一只则比较温顺安静,喜欢静静地陪伴在主人身边。他们可能会一起玩耍、散步,甚至在家中制造一些小小的“混乱”,但这些都让家庭氛围更加温暖和有趣。如果你愿意,可以分享更多关于小刚和他狗狗们的故事,我很乐意听你讲述!
********************************************************************************
小明和小刚一共有3只宠物。小明有1只猫,小刚有2只狗,所以加起来是1 + 2 = 3只宠物。
********************************************************************************
'''
如果要像chatGPT一样,长期保存历史消息,,可以使用messages_to_dict 方法
from langchain.memory import ChatMessageHistory
from langchain.schema import messages_from_dict, messages_to_dicthistory = ChatMessageHistory()
history.add_user_message("hi!")
history.add_ai_message("whats up?")dicts = messages_to_dict(history.messages)print(dicts)'''
[{'type': 'human', 'data': {'content': 'hi!', 'additional_kwargs': {}, 'response_metadata': {}, 'type': 'human', 'name': None, 'id': None, 'example': False}}, {'type': 'ai', 'data': {'content': 'whats up?', 'additional_kwargs': {}, 'response_metadata': {}, 'type': 'ai', 'name': None, 'id': None, 'example': False, 'tool_calls': [], 'invalid_tool_calls': [], 'usage_metadata': None}}]
'''# 读取历史消息
new_messages = messages_from_dict(dicts)print(new_messages)
"""
[HumanMessage(content='hi!', additional_kwargs={}, response_metadata={}), AIMessage(content='whats up?', additional_kwargs={}, response_metadata={})]
"""
2.6 Indexes (索引)
Indexes组件的目的是让LangChain具备处理文档处理的能力,包括:文档加载、检索等。注意,这里的文档不局限于txt、pdf等文本类内容,还涵盖email、区块链、视频等内容。
Indexes组件主要包含类型:
- 文档加载器
- 文本分割器
- VectorStores
- 检索器
2.6.1 文档加载器
文档加载器主要基于Unstructured 包,Unstructured 是一个python包,可以把各种类型的文件转换成文本。
对于文档分隔,会使用到nltk库,下载数据集。
移动到主目录的*nltk_data/taggers*
文档加载器使用起来很简单,只需要引入相应的loader工具:
from langchain_community.document_loaders import UnstructuredFileLoaderloader = UnstructuredFileLoader('衣服属性.txt', encoding='utf8')
docs = loader.load()
print(docs)
print(len(docs))
first_01 = docs[0].page_content[:4]
print(first_01)
print('*' * 80)from langchain_community.document_loaders import TextLoaderloader = TextLoader('衣服属性.txt', encoding='utf8')
docs = loader.load()
print(docs)
print(len(docs))
first_01 = docs[0].page_content[:4]
print(first_01)# 打印结果:
'''
[Document(metadata={'source': '衣服属性.txt'}, page_content='身高:160-170cm, 体重:90-115斤,建议尺码M。\n\n身高:165-175cm, 体重:115-135斤,建议尺码L。\n\n身高:170-178cm, 体重:130-150斤,建议尺码XL。\n\n身高:175-182cm, 体重:145-165斤,建议尺码2XL。\n\n身高:178-185cm, 体重:160-180斤,建议尺码3XL。\n\n身高:180-190cm, 体重:180-210斤,建议尺码4XL。\n\n面料分类:其他\n\n图案:纯色\n\n领型:翻领\n\n衣门襟:单排扣\n\n颜色:黑色 卡其色 粉色 杏色\n\n袖型:收口袖\n\n适用季节:冬季\n\n袖长:长袖\n\n厚薄:厚款\n\n适用场景:其他休闲\n\n衣长:常规款\n\n版型:宽松型\n\n款式细节:假两件\n\n工艺处理:免烫处理\n\n适用对象:青年\n\n面料功能:保暖\n\n穿搭方式:外穿\n\n销售渠道类型:纯电商(只在线上销售)\n\n材质成分:棉100%')]
1
身高:1
********************************************************************************
[Document(metadata={'source': '衣服属性.txt'}, page_content='身高:160-170cm, 体重:90-115斤,建议尺码M。\n身高:165-175cm, 体重:115-135斤,建议尺码L。\n身高:170-178cm, 体重:130-150斤,建议尺码XL。\n身高:175-182cm, 体重:145-165斤,建议尺码2XL。\n身高:178-185cm, 体重:160-180斤,建议尺码3XL。\n身高:180-190cm, 体重:180-210斤,建议尺码4XL。\n面料分类:其他\n图案:纯色\n领型:翻领\n衣门襟:单排扣\n颜色:黑色 卡其色 粉色 杏色\n袖型:收口袖\n适用季节:冬季\n袖长:长袖\n厚薄:厚款\n适用场景:其他休闲\n衣长:常规款\n版型:宽松型\n款式细节:假两件\n工艺处理:免烫处理\n适用对象:青年\n面料功能:保暖\n穿搭方式:外穿\n销售渠道类型:纯电商(只在线上销售)\n材质成分:棉100%')]
1
身高:1
'''
LangChain支持的文档加载器 (部分):
| 文档加载器 | 描述 |
|---|---|
| CSV | CSV问价 |
| JSON Files | 加载JSON文件 |
| Jupyter Notebook | 加载notebook文件 |
| Markdown | 加载markdown文件 |
| Microsoft PowerPoint | 加载ppt文件 |
| 加载pdf文件 | |
| Images | 加载图片 |
| File Directory | 加载目录下所有文件 |
| HTML | 网页 |
2.6.2 文档分割器
由于模型对输入的字符长度有限制,我们在碰到很长的文本时,需要把文本分割成多个小的文本片段。
文本分割最简单的方式是按照字符长度进行分割,但是这会带来很多问题,比如说如果文本是一段代码,一个函数被分割到两段之后就成了没有意义的字符,所以整体的原则是把语义相关的文本片段放在一起。
LangChain中最基本的文本分割器是CharacterTextSplitter ,它按照指定的分隔符(默认“\n\n”)进行分割,并且考虑文本片段的最大长度。我们看个例子:
from langchain.text_splitter import CharacterTextSplittertext_splitter = CharacterTextSplitter(separator = " ", # 空格分割,但是空格也属于字符chunk_size = 5,chunk_overlap = 0,
)# 一句分割
a = text_splitter.split_text("a b c d e f")
print(a)
# ['a b c', 'd e f']# 多句话分割(文档分割)
texts = text_splitter.create_documents(["a b c d e f", "e f g h"], )
print(texts)
# [Document(page_content='a b c'), Document(page_content='d e f'), Document(page_content='e f g'), Document(page_content='h')]
除了CharacterTextSplitter分割器,LangChain还支持其他文档分割器 (部分):
| 文档加载器 | 描述 |
|---|---|
| LatexTextSplitter | 沿着Latex标题、标题、枚举等分割文本。 |
| MarkdownTextSplitter | 沿着Markdown的标题、代码块或水平规则来分割文本。 |
| TokenTextSplitter | 根据openAI的token数进行分割 |
| PythonCodeTextSplitter | 沿着Python类和方法的定义分割文本。 |
2.6.3 VectorStores
VectorStores是一种特殊类型的数据库,它的作用是存储由嵌入创建的向量,提供相似查询等功能。我们使用其中一个Chroma 组件pip install chromadb作为例子:
from langchain_community.embeddings import DashScopeEmbeddings
from langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import Chroma# pku.txt内容:<https://www.pku.edu.cn/about.html>
with open('./pku.txt') as f:state_of_the_union = f.read()text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_text(state_of_the_union)
print(texts)embeddings = DashScopeEmbeddings(dashscope_api_key="sk-**")docsearch = Chroma.from_texts(texts, embeddings)query = "1937年北京大学发生了什么?"
docs = docsearch.similarity_search(query)
print(docs)
'''
[Document(metadata={}, page_content='1937年卢沟桥事变后,北京大学与清华大学、南开大学南迁长沙,共同组成国立长沙临时大学。1938年,临时大学又西迁昆明,更名为国立西南联合大学。抗日战争胜利后,北京大学于1946年10月在北平复员。\n中华人民共和国成立后,全国高校于1952年进行院系调整,北京大学成为一所以文理基础教学和研究为主、兼有前沿应用学科的综合性大学,为社会主义建设事业培养了大批杰出人才,在23位“两弹一星”元勋中有12位北大校友。'),
Document(metadata={}, page_content='1917年,著名教育家蔡元培就任北京大学校长,他“循思想自由原则,取兼容并包主义”,对北京大学进行了卓有成效的改革,促进了思想解放和学术繁荣。陈独秀、李大钊、毛泽东以及鲁迅、胡适、李四光等一批杰出人士都曾在北京大学任教或任职。'), Document(metadata={}, page_content='北京大学创办于1898年,是戊戌变法的产物,也是中华民族救亡图存、兴学图强的结果,初名京师大学堂,是中国近现代第一所国立综合性大学,辛亥革命后,于1912年改为现名。'),
Document(metadata={}, page_content='改革开放以来,北京大学进入了稳步快速发展的新时期,于1994年成为国家“211工程”首批重点建设大学。1998年5月4日,在庆祝北京大学建校一百周年大会上,党中央发出了“为了实现现代化,我国要有若干所具有世界先进水平的一流大学”的号召,之后启动了建设世界一流大学的“985工程”。在这一国家战略的支持和推动下,北京大学的发展翻开了新的一页。\n2000年4月3日,北京大学与原北京医科大学合并,组建了新的北京大学。原北京医科大学的前身是创建于1912年10月26日的国立北京医学专门学校, 1903年京师大学堂设立的医学实业馆为这所国立西医学校的诞生奠定了基础。20世纪三、四十年代,学校一度名为北平大学医学院,并于1946年7月并入北京大学。1952年在全国高校院系调整中,北京大学医学院脱离北京大学,独立为北京医学院。1985年更名为北京医科大学,1996年成为国家首批“211工程”重点支持的医科大学。两校合并进一步拓宽了北京大学的学科结构,为促进医学与理科、工科以及人文社会科学的交叉融合,改革创新医学教育奠定了基础。')]
'''
LangChain支持的VectorStore如下:
| VectorStore | 描述 |
|---|---|
| Chroma | 一个开源嵌入式数据库 |
| ElasticSearch | ElasticSearch |
| Milvus | 用于存储、索引和管理由深度神经网络和其他机器学习(ML)模型产生的大量嵌入向量的数据库 |
| Redis | 基于redis的检索器 |
| FAISS | Facebook AI相似性搜索服务 |
| Pinecone | 一个具有广泛功能的向量数据库 |
2.6.4 检索器
检索器是一种便于模型查询的存储数据的方式,LangChain约定检索器组件至少有一个方法get_relevant_texts,这个方法接收查询字符串,返回一组文档。
# pip install faiss-cpu 报错使用 conda 环境
# conda install -c conda-forge faiss-cpufrom langchain.text_splitter import CharacterTextSplitter
from langchain_community.vectorstores import FAISS
from langchain_community.document_loaders import TextLoader
from langchain_community.embeddings import DashScopeEmbeddingsloader = TextLoader('./pku.txt')
documents = loader.load()
text_splitter = CharacterTextSplitter(chunk_size=100, chunk_overlap=0)
texts = text_splitter.split_documents(documents)embeddings = DashScopeEmbeddings(dashscope_api_key="sk-**")db = FAISS.from_documents(texts, embeddings)
retriever = db.as_retriever(search_kwargs={'k': 1})
docs = retriever.get_relevant_documents("北京大学什么时候成立的")
print(docs)# 打印结果:
'''
[Document(id='79cf7a12-6e64-4d45-8eff-156e7a6ac0d4', metadata={'source': './pku.txt'}, page_content='北京大学创办于1898年,是戊戌变法的产物,也是中华民族救亡图存、兴学图强的结果,初名京师大学堂,是中国近现代第一所国立综合性大学,辛亥革命后,于1912年改为现名。')]
'''
LangChain支持的检索器组件如下:
| 检索器 | 介绍 |
|---|---|
| Azure Cognitive Search Retriever | Amazon ACS检索服务 |
| ChatGPT Plugin Retriever | ChatGPT检索插件 |
| Databerry | Databerry检索 |
| ElasticSearch BM25 | ElasticSearch检索器 |
| Metal | Metal检索器 |
| Pinecone Hybrid Search | Pinecone检索服务 |
| SVM Retriever | SVM检索器 |
| TF-IDF Retriever | TF-IDF检索器 |
| VectorStore Retriever | VectorStore检索器 |
| Vespa retriever | 一个支持结构化文本和向量搜索的平台 |
| Weaviate Hybrid Search | 一个开源的向量搜索引擎 |
| Wikipedia | 支持wikipedia内容检索 |
3 LangChain使用场景
- 个人助手
- 基于文档的问答系统
- 聊天机器人
- Tabular数据查询
- API交互
- 信息提取
- 文档总结