python-爬虫之beautifulsoup
HTML,全称为 HyperText Markup Language,即超文本标记语言,是用于创建网页和用户界面的标准标记语言。HTML 通过使用标记(即标签)来定义网页的内容和结构。一个典型的 HTML 文档包括元素、属性和内容。每个网站都是由 HTML 代码构成的,并且它能够决定网页的结构和内容。
一、网页的基本结构
HTML文档由4个主要标记组成,包括<html>、<head>、<body>.这3个标记构成了HTML页面最基本的元素。
1.1、网页常见要素
<!DOCTYPE html>- 作用:声明文档类型,告诉浏览器这是一个 HTML5 文档。
- 必须放在文档的最顶部。
<html>标签- 是整个 HTML 文档的根元素,所有的HTML文件都以标记开头,以标记结束,即所有其他内容都包含在
<html>标签中。标记虽然没有实质性的功能,但却是HTML必不可少的部分。 - 属性
lang="zh-CN"表示页面语言为中文(中国大陆),有助于搜索引擎和辅助技术理解页面内容语言。
- 是整个 HTML 文档的根元素,所有的HTML文件都以标记开头,以标记结束,即所有其他内容都包含在
<head>部分- 标记是HTML文件的头标记,用于存放HTML文件的信息。
- 常见内容:
<meta charset="UTF-8">:设置字符编码为 UTF-8,确保中文等特殊字符正常显示。<meta name="viewport" ...>:用于响应式设计,让网页在手机等设备上显示良好。<title>:定义浏览器标签页上显示的标题,也是搜索引擎结果中显示的标题。建议必须设置<link>:引入外部资源,如 CSS 文件。<script>:引入 JavaScript 脚本。<style>:内联 CSS 样式(一般推荐将样式写在独立的 CSS 文件中)。
<body>部分- 是网页的主体内容区域,用户在浏览器中看到的所有内容(文字、图片、链接、表单等)都放在这里。
- 包括标题、段落、图片、链接、列表、表格、表单、视频等元素。
1.2、HTML 常用结构标签
html的标签预定义了一部分,下面一些常用的 HTML 标签,它们用于构建网页的基本结构与内容:
| 标签 | 用途 | 示例 |
|---|---|---|
<h1>到 <h6> | 定义标题,<h1>最重要,<h6>最不重要 | <h1>主标题</h1> |
<p> | 定义段落 | <p>这是一个段落。</p> |
<a> | 定义链接 | <a href="https://www.example.com">访问示例</a> |
<img> | 插入图片 | <img src="image.jpg" alt="描述文字"> |
<ul>, <ol>, <li> | 定义无序和有序列表 | <ul><li>项目1</li><li>项目2</li></ul> |
<div> | 定义一个块级容器,用于布局或分组内容 | <div>这是一个容器</div> |
<span> | 定义行内容器,用于对文本的一部分进行样式化或操作 | <span>高亮文字</span> |
<form> | 创建表单,用于用户输入 | <form action="/submit" method="POST">...</form> |
<input> | 输入框(文本、密码、按钮等) | <input type="text" placeholder="请输入"> |
<button> | 按钮 | <button>点击我</button> |
1.3、HTML 语义化标签(HTML5 新增)
HTML5 引入了一系列语义化标签,它们不仅起到容器的作用,还明确表达了内容的含义,有助于 SEO 和可访问性。
| 标签 | 语义/用途 |
|---|---|
<header> | 页面或区块的页眉,通常包含标题、导航等 |
<nav> | 导航栏,包含链接集合 |
<main> | 页面的主要内容,每个页面应该只有一个 |
<section> | 一个主题性的内容区块 |
<article> | 独立的内容块,如一篇博客文章、新闻 |
<aside> | 侧边栏或与主内容相关但独立的内容(如广告、相关链接) |
<footer> | 页脚,通常包含版权信息、联系方式等 |
<figure>和 <figcaption> | 用于展示媒体(如图片、图表)及其标题说明 |
<!DOCTYPE html>
<html lang="zh-CN">
<head><meta charset="UTF-8" /><meta name="viewport" content="width=device-width, initial-scale=1.0" /><title>我的第一个网页</title><link rel="stylesheet" href="styles.css" />
</head>
<body><header><h1>欢迎来到我的网站</h1><nav><ul><li><a href="#">首页</a></li><li><a href="#">博客</a></li></ul></nav></header><main><section><h2>关于我们</h2><p>这是关于我们的介绍。</p></section><article><h2>最新文章</h2><p>这是一篇新文章的内容。</p></article></main><footer><p>Copyright © 2024 我的公司</p></footer>
</body>
</html>
html打开后的显示效果
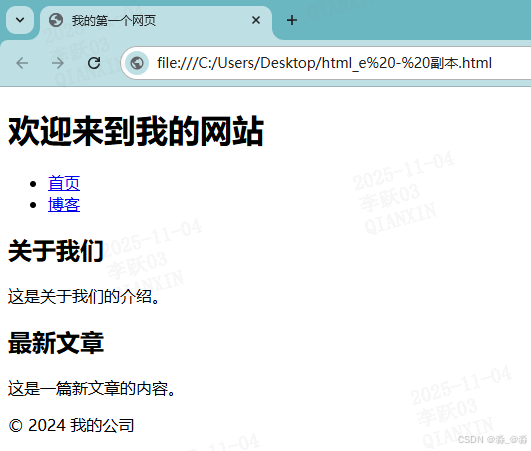
二、python解析html
python解析html可以lxml或者beautifulsoup。下面主要介绍beautifulsoup模块
2.1、Beautiful Soup的简介
Beautiful Soup是python的一个 HTML/XML 解析库,提供了简单易用的 API,适合快速提取和操作网页内容。不是解析器本身,而是一个解析工具,需要搭配解析器使用(如 html.parser、lxml、html5lib),其中只要html.parser是官方内置的标准库,其他库都需要额外安装。下面是不同解析器的对比:
| 解析器 | 使用方法 | 优势 | 劣势 |
|---|---|---|---|
| Python标准库 | BeautifulSoup(markup, “html.parser”) | Python的内置标准库、执行速度适中、文档容错能力强 | Python 2.7.3 or 3.2.2)前 的版本中文档容错能力差 |
| lxml HTML 解析器 | BeautifulSoup(markup, “lxml”) | 速度快、文档容错能力强 | 需要安装C语言库 |
| lxml XML 解析器 | BeautifulSoup(markup, [“lxml”, “xml”])或BeautifulSoup(markup, “xml”) | 速度快、唯一支持XML的解析器 | 需要安装C语言库 |
| html5lib | BeautifulSoup(markup, “html5lib”) | 最好的容错性、以浏览器的方式解析文档、生成HTML5格式的文档、不依赖外部扩展 | 速度慢 |
不同场景下使用建议:
| 场景 | 推荐工具 |
|---|---|
| 快速上手、代码简洁、功能够用 | BeautifulSoup + html.parser 或 lxml |
| 追求解析速度,处理大量数据 | BeautifulSoup + lxml 或直接使用 lxml |
| 处理混乱、不规范的 HTML | BeautifulSoup + html5lib |
| 不想安装第三方库,轻量级使用 | BeautifulSoup + html.parser |
| 需要使用 XPath 进行高级查询 | lxml(推荐) |
| 需要严格按 XML 标准解析 | lxml-xml |
2.2、BeautifulSoup用法
soup = BeautifulSoup(markup, features=None, builder=None, parse_only=None, from_encoding=None, exclude_encodings=None, element_classes=None, **kwargs)
-
功能:原始的 HTML/XML 字符串或文件内容,转换成一个可遍历、可搜索的 DOM 树结构,从而让你能够方便地提取、修改和操作其中的内容
-
常用参数:
-
markup:必选, 要解析的 HTML 或 XML 内容,可以是HTML 字符串、XML 字符串,本地 HTML 文件内容
-
features:可选,指定使用的解析器,强烈建议指定,因为不同环境存在的解析器不同。如果没有显式指定解析器,BeautifulSoup 会使用当前环境下 “可用的、优先级最高的解析器” 作为默认解析器,通常lxml>html.parser>html5lib
-
-
返回值:
bs4.BeautifulSoup类的实例(对象),它是对整个 HTML/XML 文档的封装,表示一个可遍历、可搜索的树状结构。
Beautiful Soup将复杂HTML文档转换成一个复杂的树形结构,每个节点都是Python对象,所有对象可以归纳为4种:
| 对象名 | 描述 |
|---|---|
| BeautifulSoup | 文档自身:表示的是一个文档的全部内容 |
| Tag | 标签对:Tag对象与XML或HTML原生文档中的tag相同,即标签对 |
| NavigableString | 标签值:标签对中的字符串 |
| Comment | 注释:文档的注释部分 |
2.2.1、tag对象
下面是tag对象的一下属性和方法
| 功能类别 | 说明 | 示例方法/属性 |
|---|---|---|
| 访问标签 | 直接通过标签名获取第一个匹配的标签对象 | soup.p, soup.a, soup.div,soup.head, soup.body,soup.title |
| 获取标签名称 | 获取某个标签名 | soup.p.name |
| 获取标签内容 | 获取某个标签的文本(会递归地提取该标签及其所有子孙节点中的文本内容,并将它们拼接成一个完整的字符串) | .text, .get_text() |
| 获取标签内容 | 获取某个标签文本(没有嵌套其他标签返回字符串内容,有嵌套其他标签返回None)Navigable对象(并不好用) | .string |
| 获取标签属性 | 获取标签的属性,返回的是一个字典对象。 | soup.p.attrs |
| 获取标签某个属性 | 获取某个标签的属性值,如 class、href、id,返回的是一个list对象 | soup.a['href'], soup.p['class'] |
| 查找标签 | 查找第一个符合条件的标签(一般不使用) | soup.find('p'), soup.find(class_='intro') |
| 查找所有标签 | 查找所有符合条件的tag,返回一个列表 | soup.find_all('p') |
| 遍历文档结构 | 可以遍历子节点、父节点、兄弟节点等 | .children, .parent, .next_sibling |
| 搜索与过滤 | 支持按标签名、属性、CSS 类名、文本内容等查找 | find_all(), select()(CSS选择器) |
| 修改文档 | 可以修改标签、属性、文本内容(增删改查) | .string = "新文本", .append() |
from bs4 import BeautifulSouphtml_text = """
<html>
<head><title>示例页面</title></head>
<body><h1>欢迎来到我的网站</h1><p class="intro aaa" test=123>这是一个段落。</p><p class="content bbb">这是另一个段落。</p><a href="https://example.com">链接</a>
</body>
</html>
"""soup = BeautifulSoup(html_text, "lxml")print("h1标签的tag对象为", soup.h1, type(soup.h1))
# p标签的tag对象为 <h1>欢迎来到我的网站</h1> <class 'bs4.element.Tag'>
print("h1标签的文本为", soup.h1.text, type(soup.h1))print("p标签的tag对象的属性为",soup.p.attrs) # 返回一个字典对象。标签属性的值只有class解析为列表:['intro', 'aaa'],其他的解析为string;lxml将其解析为字符串:'intro aaa'
# p标签的tag对象的属性为 {'class': ['intro', 'aaa'], 'test': '123'}# 获取标签某个属性具体的值有以下四种方式
print("p标签的test属性值为", soup.p.attrs["test"]) # 使用字典的索引
# p标签的test属性值为 123
print("p标签的class属性值为", soup.p.attrs.get("class")) # 使用字典的get方法
# p标签的class属性值为 ['intro', 'aaa']
print("p标签的class属性值为", soup.p.get("class")) # 使用soup对象.标签名.get(属性名)
# p标签的class属性值为 ['intro', 'aaa']
print("p标签的class属性值为", soup.p["class"])
# p标签的class属性值为 ['intro', 'aaa']print("soup的所有p标签的class属性值为", soup.find_all("p"))
# soup的所有p标签的class属性值为 [<p class="intro aaa" test="123">这是一个段落。</p>, <p class="content bbb">这是另一个段落。</p>]
- HTML 规范本身允许
class属性包含多个值,所以除了class属性的值返回为list,其他的属性(id、src等通用属性)返回为string。 - 标签属性的值只有class解析为列表:[‘intro’, ‘aaa’],其他的解析为string;lxml将其解析为字符串:‘intro aaa’
2.2.2、NavigableString对象
在 BeautifulSoup 中,当你访问某个标签(Tag)内部的 纯文本 时(无论是在父子标签之间,还是兄弟标签之间,只要是在tag内部的的存文本),都会被表示为一个 NavigableString类型的对象。格式化的html中换行符也会被当做一个NavigableString类型。
from bs4 import BeautifulSouphtml_text = """
<html>
<head><title>示例页面</title></head>
<body><h1>欢迎来到我的网站</h1><p class="intro aaa" test=123>这是一个段落。<test>这是一个子节点</test>兄弟节点间的文本<test1>test的兄弟节点test1</test1></p><p class="content bbb">这是另一个段落。</p><a href="https://example.com">链接</a>
</body>
</html>
"""soup = BeautifulSoup(html_text, "lxml")for child in soup.p.children:print("-"*30+"\r\n",child,type(child))------------------------------这是一个段落。<class 'bs4.element.NavigableString'>
------------------------------<test>这是一个子节点</test> <class 'bs4.element.Tag'>
------------------------------兄弟节点间的文本<class 'bs4.element.NavigableString'>
------------------------------<test1>test的兄弟节点test1</test1> <class 'bs4.element.Tag'>
------------------------------<class 'bs4.element.NavigableString'>
NavigableString是 BeautifulSoup 提供的一个类,用来表示 HTML 或 XML 标签中包含的 “纯文本” 的对象。它是 str(字符串)的一个子类,可以像操作字符串一样操作它,但它还 “可导航(Navigable)”,即可以访问其父节点、兄弟节点等,这就是 “Navigable” 的含义。通过 soup.p.string获取,.string只有在当前标签下只有一个字符串节点(没有嵌套其它标签)时才有值,且返回的是 NavigableString类型,否则返回None
from bs4 import BeautifulSouphtml_text = """
<html>
<head><title>示例页面</title></head>
<body><h1>欢迎来到我的网站</h1><p class="intro aaa" test=123>这是一个段落。</p><p class="content bbb">这是另一个段落。</p><a href="https://example.com">链接</a>
</body>
</html>
"""soup = BeautifulSoup(html_text, "lxml")print(soup.body.string)
print(soup.body.string.parsend)
print(soup.title.string)
返回结果为:
None
示例页面
在正常html数据中是需要将换行符生成的NavigableString类型剔除掉的,可以使用以下几种方式:
2.2.2.1、if child.name
for child in p.children:if child.name: # 如果 child 是一个标签,它会有 name 属性,如 'span'print("找到子标签:", child)else:# child 是字符串(可能是换行/空格/文本)if child.strip(): # 如果文本非空(去掉首尾空格后不为空)print("文本内容:", child.strip())# else: 是纯换行或空格,可忽略
2.2.2.2、isinstance()
for child in p.children:if isinstance(child, Tag):print("子标签:", child)else:# 处理文本节点text = child.strip()if text:print("文本:", text)
2.2.2.3、find_all()–最常用
for child in p.find_all(recursive=False):# 只查找 <p>的直接子标签,不会递归查找子标签的子标签,而且不会返回文本节点,只返回标签print("直接子标签:", child)
2.2.3、BeautifulSoup对象
BeautifulSoup 对象表示的是一个文档的全部内容。大部分时候可以把它当作Tag对象,是一个特殊的Tag,我们可以分别获取它的类型,名称,以及属性。
from bs4 import BeautifulSouphtml_text = """
<html>
<head><title>示例页面</title></head>
<body><h1>欢迎来到我的网站</h1><p class="intro aaa" test=123>这是一个段落。</p><p class="content bbb">这是另一个段落。</p><a href="https://example.com">链接</a>
</body>
</html>
"""soup = BeautifulSoup(html_text, "lxml")print(soup.name,type(soup.name))
print(soup.attrs)返回结果:
[document] <class 'str'>
{}
2.2.4、Comment对象
Comment是 BeautifulSoup 提供的一个对象类型,用于表示 HTML 或 XML 文档中的注释内容,例如 <!-- 这是一个注释 -->。它是 bs4.element.Comment类型,同时也是 字符串(str)的子类,所以你可以像操作字符串一样操作注释内容,但同时它也保留了“可导航”的特性(比如可以访问父节点、兄弟节点等)。
from bs4 import BeautifulSoup, Commenthtml = """
<div>这是正常内容<!-- 这是一个注释 --><p>这是一个段落</p><!-- 另一个注释 -->
</div>
"""soup = BeautifulSoup(html, 'html.parser')# 遍历 div 的所有子节点
for child in soup.div.children:print(child)print(type(child))print("---")
输出结果为:
这是正常内容<class 'bs4.element.NavigableString'>
---
<!-- 这是一个注释 -->
<class 'bs4.element.Comment'>
---
<p>这是一个段落</p>
<class 'bs4.element.Tag'>
---
<!-- 另一个注释 -->
<class 'bs4.element.Comment'>
---
<!-- 这是一个注释 -->被解析成了一个Comment类型 的节点。- 它和
NavigableString(文本)、Tag(标签)一样,都是 BeautifulSoup 文档树的 节点类型之一 - 你可以通过
.children或.contents遍历到它,也可以通过条件判断筛选出注释节点。
2.2.4.1、遍历html中的所有注释
for child in soup.body.children:if isinstance(child, Comment):print("发现注释节点:", child)
2.2.4.2、删除注释
from bs4 import BeautifulSoup, Commenthtml = """
<div>Hello<!-- 注释1 --><p>内容</p><!-- 注释2 -->
</div>
"""
soup = BeautifulSoup(html, 'html.parser')# 找到所有注释节点并删除
for comment in soup.find_all(string=lambda text: isinstance(text, Comment)):comment.extract() # 从文档树中移除该节点print(soup.prettify())
2.2.5、搜索文档树
在BeautifulSoup中最常用的是find()和find_all(),当然还有其他的。比如find_parent() 和 find_parents()、 find_next_sibling() 和 find_next_siblings() 、find_all_next() 和 find_next()、find_all_previous() 和 find_previous() 等等。
find_all( name , attrs , recursive , **string** , **kwargs )
-
功能:搜索当前tag的所有tag子节点,并判断是否符合过滤器的条件。返回值类型是bs4.element.ResultSet
-
参数说明
-
name 参数:可以查找所有名字为 name 的tag。
-
attr 参数:就是tag里的属性。
-
string 参数:搜索文档中字符串的内容。
-
recursive 参数: 调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点。如果只想搜索tag的直接子节点,可以使用参数 recursive=False 。
-
find( name , attrs , recursive , string , **kwargs )
- 功能:与find_all()类似,只不过只返回找到的第一个值。返回值类型是bs4.element.Tag。
- 参数说明
- name 参数:可以查找所有名字为 name 的tag。
- attr 参数:就是tag里的属性。
- string 参数:搜索文档中字符串的内容。
- recursive 参数: 调用tag的 find_all() 方法时,Beautiful Soup会检索当前tag的所有子孙节点。如果只想搜索tag的直接子节点,可以使用参数 recursive=False 。
三、爬虫脚本
3.1、爬取图片
import requests
from bs4 import BeautifulSoup
import os
import timeclass BeautifulPicture():def __init__(self, web_url, path): # 类的初始化操作self.headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1'} # 给请求指定一个请求头来模拟chrome浏览器self.web_url = web_url # 要访问的网页地址self.folder_path = path # 设置图片要存放的文件目录def get_pic(self,pic_url_data):print('开始网页get请求')r = self.request(self.web_url)print('开始获取所有a标签')all_a = BeautifulSoup(r.text, 'lxml').find_all('img') # 获取网页中的所有a标签,一般图片都存放在img标签下print('开始创建文件夹')self.mkdir(self.folder_path) # 创建文件夹print('开始切换文件夹')os.chdir(self.folder_path) # 切换路径至上面创建的文件夹i = 0print(all_a)for a in all_a: # 循环每个标签,获取标签中图片的url并且进行网络请求,最后保存图片try:img_str = a[pic_url_data] # 获取a标签中图片的url地址,需要先查看网站中url的属性值print('-'*40+'\r\n'+f"a标签中第{i+1}个style内容是:", img_str)# first_pos = img_str.find('"') + 1# print(first_pos)# second_pos = img_str.find('"', first_pos)# print(second_pos)# img_url = img_str[first_pos: second_pos] # 使用Python的切片功能截取双引号之间的内容img_name = str(i+1)if not img_str.startswith(('http:', 'https:')):img_url = 'https:' + img_strself.save_img(img_url, img_name) # 调用save_img方法来保存图片i = int(i) + 1except KeyError as e:print("标签不存在:", e)def save_img(self, url, name): # 保存图片print('开始请求图片地址,过程会有点长...')if url.find('https') != -1:print(url)img = self.request(url)time.sleep(1)file_name = name + '.jpg'if img is not None:print('开始保存图片')with open(file_name, 'wb') as f:f.write(img.content)print(file_name, '图片保存成功!')def request(self, url): # 返回网页的responsetry:r = requests.get(url, headers=self.headers) # 像目标url地址发送get请求,返回一个response对象。有没有headers参数都可以。print(r.status_code)if r.status_code == 200:return r # return的结果需要判断请求是否成功,成功就返回,未成功就返回Noneelse:return Noneexcept Exception as e:print("http请求报错", e)return Nonedef mkdir(self, path): # 这个函数创建文件夹path = path.strip()isExists = os.path.exists(path)if not isExists:print('创建名字叫做', path, '的文件夹')os.makedirs(path)print('创建成功!')else:print(path, '文件夹已经存在了,不再创建')if __name__ == "__main__":beauty = BeautifulPicture("https://www.51miz.com/so-sucai/3581313.html", r'E:\pic\mizi') # 创建类的实例beauty.get_pic("data-layzeload") # 执行类中的方法
参考:
https://blog.csdn.net/huaweichenai/article/details/136480489
https://gitcode.csdn.net/65e83f7d1a836825ed78b70b.html