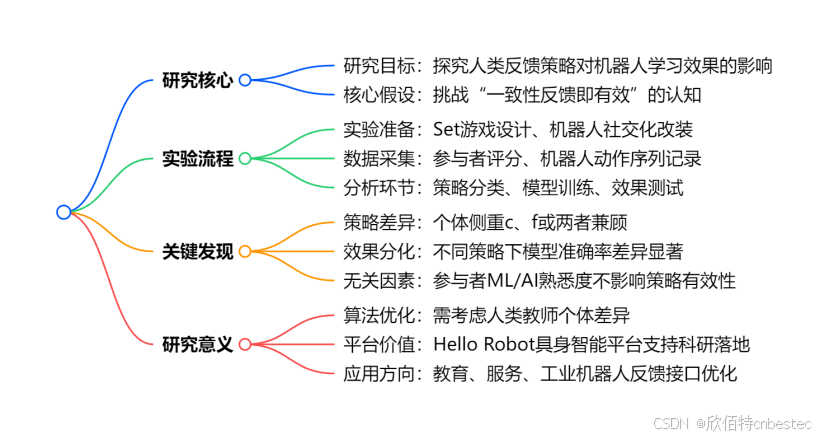
耶鲁大学Hello Robot研究解读:人类反馈策略的多样性与有效性
在人工智能蓬勃发展的2025年,耶鲁大学团队的一项突破性研究揭示了人类教学行为的奥秘。这项发表于认知科学大会的研究发现,人类在教导机器人时采用的反馈策略存在显著差异,而这些差异直接影响机器人的学习效果。下面让我们深入了解这一有趣实验。

研究背景:为什么关注人类反馈策略?
传统观点认为,一致的反馈就是有效的反馈。但这一假设在真实人机交互场景中是否成立?耶鲁大学研究团队通过精心设计的实验,对这一假设发起了挑战。
研究团队选择Set卡牌游戏作为实验任务,参与者需要教导Hello Robot移动操作机器人如何正确选择符合规则的三张牌。这一设置模拟了真实世界中人类教导机器人完成复杂任务的场景。
实验设计:Hello Robot如何成为“好学生”?
实验共有36名参与者面对Hello Robot移动操作机器人,对机器人在Set游戏中的表现提供1-10分的数字反馈。
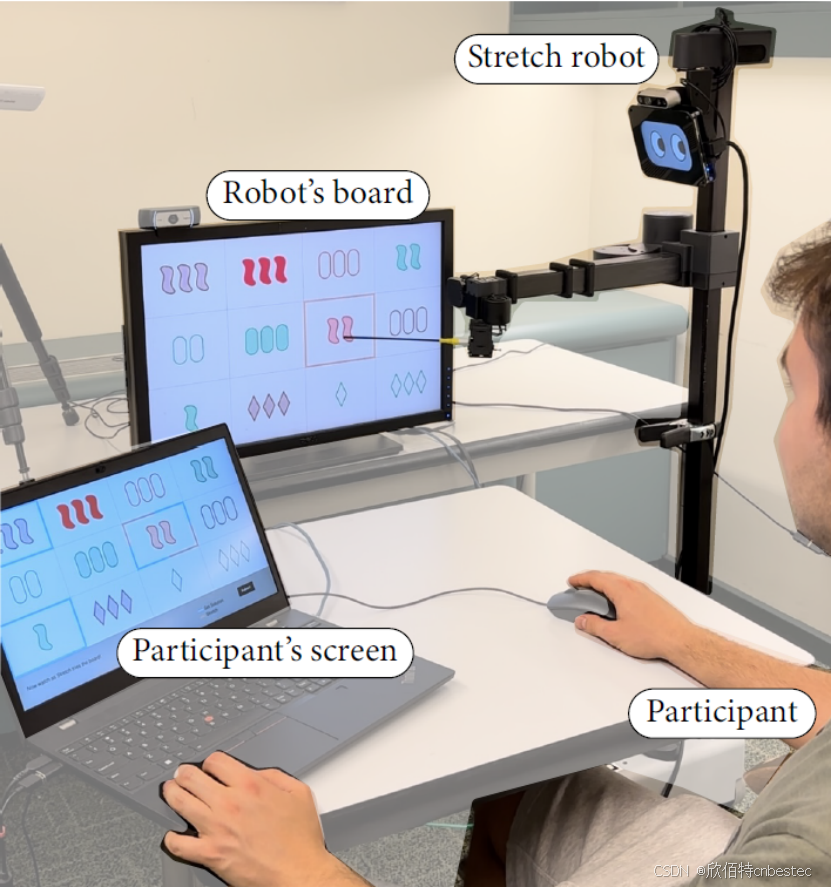
图1: Hello Robot Stretch 2在Set任务中的互动环境
研究团队为Hello Robot赋予了社交元素,如添加眼睛显示器以模拟眨眼、点头等行为,大大增强了人机互动的自然性。这一设计体现了Hello Robot作为具身智能平台的灵活性和可定制性。
Set游戏规则要求从12张卡牌中选出符合规则的三张牌,研究者通过控制机器人动作序列(参数c表示所选牌与解决方案的接近度,f表示符合规则维度数)来模拟不同失败情况。
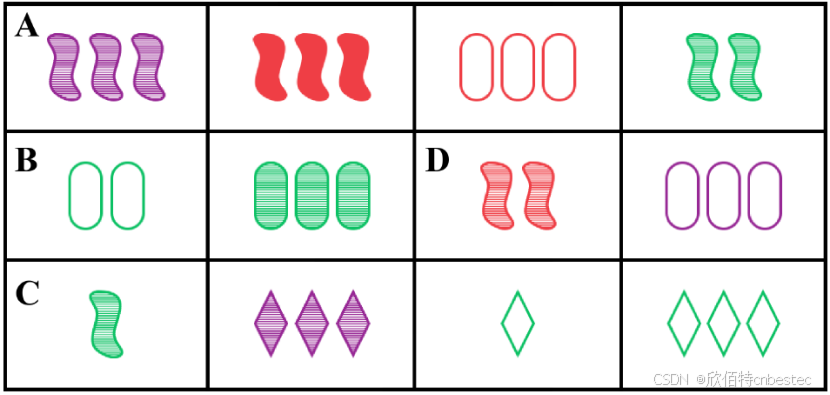
图2: Set游戏示例
我们用机器人动作序列预定义,以展示c和f的渐进变化。例如,在部分序列中,机器人逐步接近解决方案,但规则符合度波动,这帮助观察参与者的反馈策略差异。
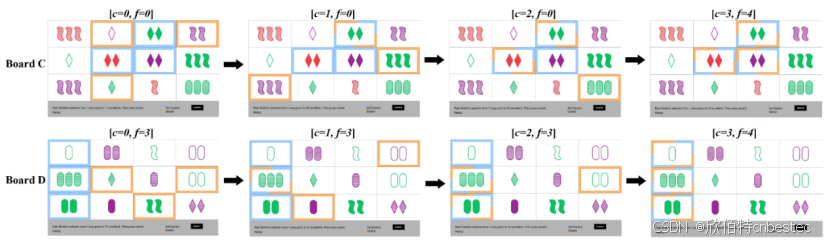
图3: 机器人动作序列示例
惊人发现:反馈策略差异巨大,效果天壤之别
数据分析揭示了令人惊讶的结果:参与者平均评分5.53,但深入分析发现,每个人的反馈策略截然不同。
- 有人侧重c参数(解决方案接近度)
- 有人侧重f参数(规则符合度)
- 有人尝试平衡两者
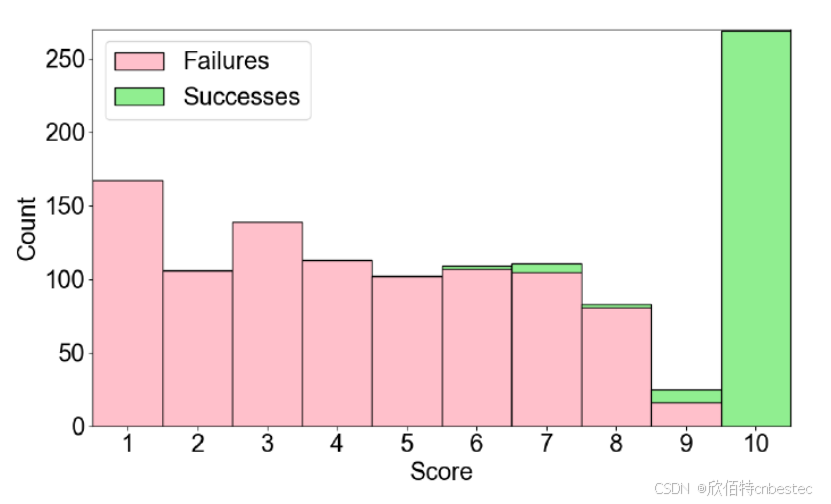
图4: 参与者反馈分数分布,显示成功和失败动作的评分差异
通过模拟训练MLP模型测试不同策略效果,结果显示:不同策略下的模型准确率差异巨大(平均62.9%,标准差41%),部分策略导致模型几乎无法学习,而某些策略(如高权重c和f)则带来快速学习。
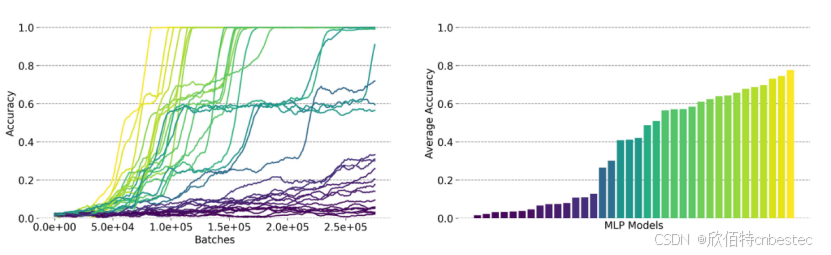
图5: 模拟训练准确率随时间变化,显示不同策略下的学习效果
最令人意外的是,参与者的机器学习或AI熟悉度并未带来教学优势,这挑战了“专业知识决定教学效果”的常规认知。
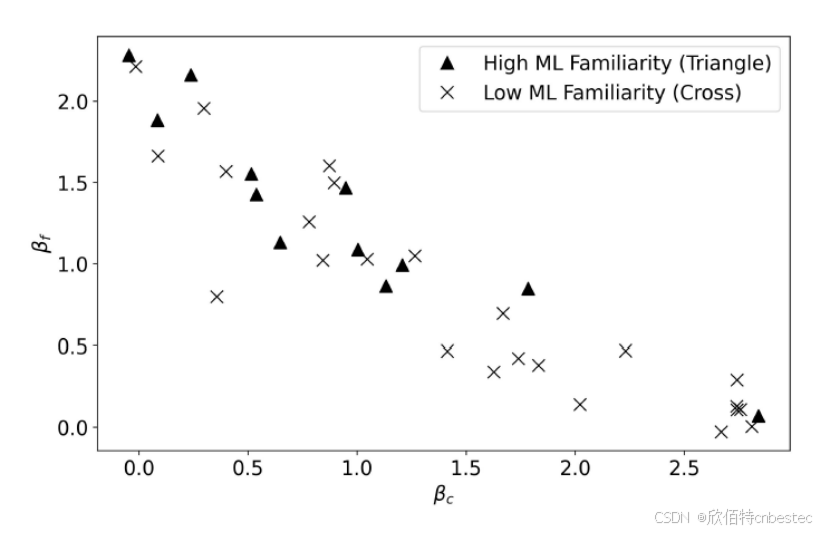
图6: 参与者线性回归系数图,标注ML熟悉度,展示策略多样性
潜在应用场景:改变未来人机协作模式
这项研究为多个领域带来启示:
- 教育领域:开发个性化教学机器人,适应不同学生的反馈风格
- 服务场景:优化客服机器人学习机制,提升用户体验
- 工业环境:改进工业机器人技能传递效率,降低培训成本
- 家庭应用:让家庭服务机器人更快适应不同家庭成员的教学风格
结语:技术服务于人的新篇章
这项研究不仅揭示了人类反馈策略的重要性,也展示了Hello Robot作为研究平台的价值。

随着Stretch3移动操作机器人的不断发展,我们有理由相信,智能机器人将更自然地融入人类生活,真正实现“技术服务于人”的愿景。
论文价值一览图(点击保存)
【版权声明】
本文部分技术内容及数据援引自论文《When Teaching A Robot, People Employ Different Feedback Strategies: Some Are More Effective Than Others》(Proceedings of the Cognitive Science Society, 47th Annual Meeting, 2025)。
论文链接:https://escholarship.org/uc/item/4t00267n
如需转载,请完整保留本声明并注明原始出处。
✅ 感谢论文的核心贡献者:
Nicholas C. Georgiou(尼古拉斯·C·乔治乌)
Shuangge Wang(王双歌)
Joel Banks(乔尔·班克斯)
Kate Candon(凯特·坎登)
Dražen Brščić(德拉任·布尔什奇奇)
Brian Scassellati(布赖恩·斯卡塞拉蒂)
美国耶鲁大学计算机科学系
日本京都大学社会信息学系