请勿直接解析到ip否则我司不能保证您的网站能正常运行!"wordpress 幻灯片代码在哪里
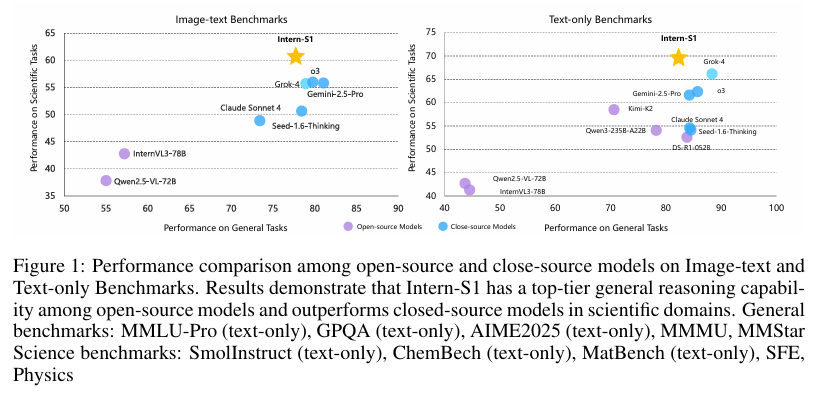
摘要:近年来,大量开源基础模型应运而生,在一些备受关注的领域取得了显著进展,其性能已十分接近闭源模型。然而,在高价值但更具挑战性的科学专业领域,要么这些领域仍依赖专家模型,要么通用基础模型的进展与热门领域相比明显滞后,远不足以推动科学研究变革,并且在这些科学领域中,开源模型与闭源模型之间仍存在巨大差距。为缩小这一差距,并朝着通用人工智能(AGI)更进一步地探索,我们推出了Intern-S1,这是一款具备通用理解和推理能力,且拥有分析多种科学模态数据专业知识的专业通用模型。Intern-S1是一个多模态混合专家(Mixture-of-Experts,MoE)模型,拥有280亿激活参数和2410亿总参数,在包含2.5万亿以上科学领域令牌的5万亿令牌上持续进行预训练。在训练后阶段,Intern-S1在InternBootCamp中先接受离线强化学习(Reinforcement Learning,RL)训练,然后再接受在线强化学习训练。在此过程中,我们提出了混合奖励(Mixture-of-Rewards,MoR)机制,以同时协同完成1000多项任务的强化学习训练。通过在算法、数据和训练系统方面的综合创新,Intern-S1在在线强化学习训练中取得了顶尖性能。在综合评估基准测试中,Intern-S1在开源模型的一般推理任务中展现出具有竞争力的性能,在科学领域显著优于开源模型,并且在分子合成规划、反应条件预测、晶体热力学稳定性预测等专业任务中超越了闭源的先进模型。我们的模型可在Huggingface。Huggingface链接:Paper page,论文链接:2508.15763
研究背景和目的
研究背景:
近年来,开源基础模型在多个广泛关注的领域取得了显著进展,其性能逐渐接近闭源模型。
然而,在高价值但更具挑战性的科学专业领域,现有模型的表现仍然不尽如人意。这些领域不仅要求模型具备对多样化但低资源科学模态(如分子结构、时间序列信号等)的内在规律的理解和捕捉能力,还需要进行长期且严谨的推理过程,如假设验证和实验设计优化。现有的开源模型在科学任务上的进展显著落后于在流行领域(如数学和代码生成)的进展,与闭源模型之间存在较大差距,这限制了开源模型对前沿科学研究的贡献。
研究目的:
为了缩小这一差距并探索迈向人工通用智能(AGI)的进一步路径,研究团队引入了Intern-S1,这是一个具备通用理解和推理能力的专业通用模型,专门用于分析多科学模态数据。Intern-S1旨在成为一个多模态科学推理的基础模型,通过集成创新算法、数据和训练系统,在科学任务上实现顶尖性能,甚至超越闭源模型,从而加速科学发现。
研究方法
1. 模型架构:
Intern-S1采用了多模态混合专家(MoE)模型架构,拥有280亿激活参数和2410亿总参数。模型基于Qwen3-235B MoE模型,并针对科学模态进行了优化。具体来说,研究团队根据科学模态的表示形式将其分为三类,并采用不同策略将其投影到LLM的表示空间中:使用视觉变换器(ViT)编码可视化表示(如气象图像),提出了一种动态标记器处理线性离散表示(如分子结构),并利用特定设计的编码器处理领域特定表示(如时间序列信号)。
2. 数据准备:
在预训练阶段,研究团队通过两条管道准备了大规模的科学领域预训练数据:一是通过回忆和过滤管道从网络数据中挖掘预训练数据,确保知识覆盖,将目标领域的数据纯度从约2%提高到50%以上;二是采用页面级PDF文档解析管道,以中等成本从PDF文档中获取高质量解析文档。这些管道为Intern-S1的持续预训练贡献了超过2.5万亿个科学数据标记。
3. 训练策略:
Intern-S1的训练分为四个阶段:单模态预训练、多模态持续预训练、离线强化学习(RL)和在线强化学习。在RL阶段,研究团队提出了混合奖励框架(Mixture-of-Rewards, MoR),以协同处理超过1000个任务的RL训练。MoR通过统一奖励标量来协调不同形式反馈的任务,采用POLAR算法为创造性写作和聊天等难以验证的任务提供奖励标量,对于各种易于验证的任务,则采用不同的验证模型组合、规则和环境反馈来生成精确的奖励标量。
4. 基础设施优化:
研究团队在XTuner工具包中发布了Intern-S1的训练基础设施,该工具包包括预训练和监督微调的并行计算策略,以及RL训练的并行计算策略。
具体优化措施包括使用完全分片数据并行(FSDP)进行模型参数分布,采用FP8精度进行矩阵乘法运算,以及开发特定的内核来减少MoE计算中的内存和计算开销。
研究结果
1. 性能表现:
在综合评估基准上,Intern-S1在开源模型中表现出顶尖的通用推理能力,并在科学领域显著优于开源模型,甚至在某些专业任务上超越了闭源的顶尖模型,如分子合成规划、反应条件预测和晶体热力学稳定性预测。具体来说,在科学相关文本基准测试中,Intern-S1在SmolInstruct、ChemBench和MatBench三个数据集上取得了最佳整体成绩;在多模态科学基准测试中,Intern-S1在四个数据集(SFE、MicroVQA、MSEarthMCQ和XLRS-Bench)上取得了最佳整体成绩。
2. 强化学习效率:
通过集成MoR框架和其他优化措施,Intern-S1在RL训练中的效率显著提高,训练时间减少了10倍,同时保持了高性能表现。这表明MoR框架在处理多样化任务时的有效性和可扩展性。
研究局限
1. 数据覆盖和纯度:
尽管研究团队通过多种策略提高了科学领域数据的纯度和覆盖度,但某些特定领域的数据仍然有限,这可能影响模型在这些领域的表现。此外,网络数据的固有噪声和偏差也可能对模型训练产生一定影响。
2. 模型规模和效率:
尽管Intern-S1在参数规模和性能上取得了显著进展,但庞大的模型规模也带来了计算资源和能效方面的挑战。如何在保持高性能的同时降低模型规模和计算成本,是未来研究需要解决的问题。
3. 任务多样性和复杂性:
尽管MoR框架在处理多样化任务时表现出色,但随着任务数量和复杂性的增加,如何有效协调和优化不同任务的奖励信号,仍然是一个待解决的问题。
未来研究方向
1. 扩大数据覆盖和纯度:
未来研究应继续探索更有效的数据挖掘和过滤技术,以进一步提高科学领域数据的纯度和覆盖度。同时,考虑利用无监督或自监督学习方法,从海量未标注数据中提取有用信息。
2. 优化模型架构和效率:
研究更高效的模型架构和压缩技术,以降低模型规模和计算成本。例如,探索模型剪枝、量化和知识蒸馏等方法,以在保持高性能的同时减少模型参数量和计算量。
3. 增强任务多样性和复杂性处理:
进一步优化MoR框架,以更好地处理任务多样性和复杂性增加的情况。例如,引入更复杂的奖励信号协调机制,或者开发新的RL算法,以更好地适应多样化任务的需求。
4. 跨领域迁移学习:
探索跨领域迁移学习的方法,使模型能够从一个领域学到的知识迁移到其他相关领域。这将有助于进一步提高模型的泛化能力和应用范围,推动科学研究的全面发展。
5. 开放合作和社区参与:
鼓励开放合作和社区参与,共同推动科学领域基础模型的研究和发展。通过共享数据、模型和工具,促进科学研究的透明度和可重复性,加速科学发现的进程。