设计电子商务网站方式网站备案拍照点
GEM: 迈向通用LLM智能体训练新纪元
本文将介绍开源框架GEM(General Experience Maker),它为大型大语言模型(LLM)智能体提供了标准化的环境模拟平台,支持多任务、多工具集成及灵活的强化学习训练。通过统一接口与多样化环境,GEM解决了现有框架中环境与训练耦合的问题,为通用智能体研究提供了强大工具。
博客标题:💎 GEM: A Gym for Generalist LLMs
来源:https://axon-rl.notion.site/gem
PS: 整理了LLM、量化投资、机器学习方向的学习资料,关注同名公众号 「 亚里随笔」 即刻免费解锁
文章核心
研究背景
我们正进入"era of experience",LLM训练从静态数据集转向智能体在复杂环境中通过经验学习。传统强化学习中,OpenAI Gym通过标准化接口极大推动了算法发展,但现有LLM智能体训练框架存在环境与训练耦合紧密的问题,难以灵活集成不同强化学习框架。
为此,GEM作为专门为LLM设计的环境模拟器,旨在填补这一空白,支持通用智能体的高效训练与 benchmarking。
研究问题
- 现有LLM训练框架将环境与训练逻辑紧密耦合,导致难以适配不同强化学习框架(如Oat、Verl),限制了算法灵活性。
- 多轮交互场景下,传统强化学习算法(如GRPO)因需要从同一状态采样多个 episode 完成,难以兼容多轮基于回合奖励的任务。
- 缺乏标准化的多任务、多工具集成环境,阻碍了通用LLM智能体在推理、规划、工具使用等综合能力上的系统评估。
主要贡献
- 提出 GEM 框架,通过解耦环境与训练框架,实现与主流强化学习框架(Oat、Verl 等)的无缝集成,提供标准化接口(
reset/step)。 - 设计支持多轮交互的 REINFORCE 算法变体,引入批次回报归一化(batch return normalization),解决了多轮回合奖励场景下的学习效率问题,兼容单轮与多轮任务。
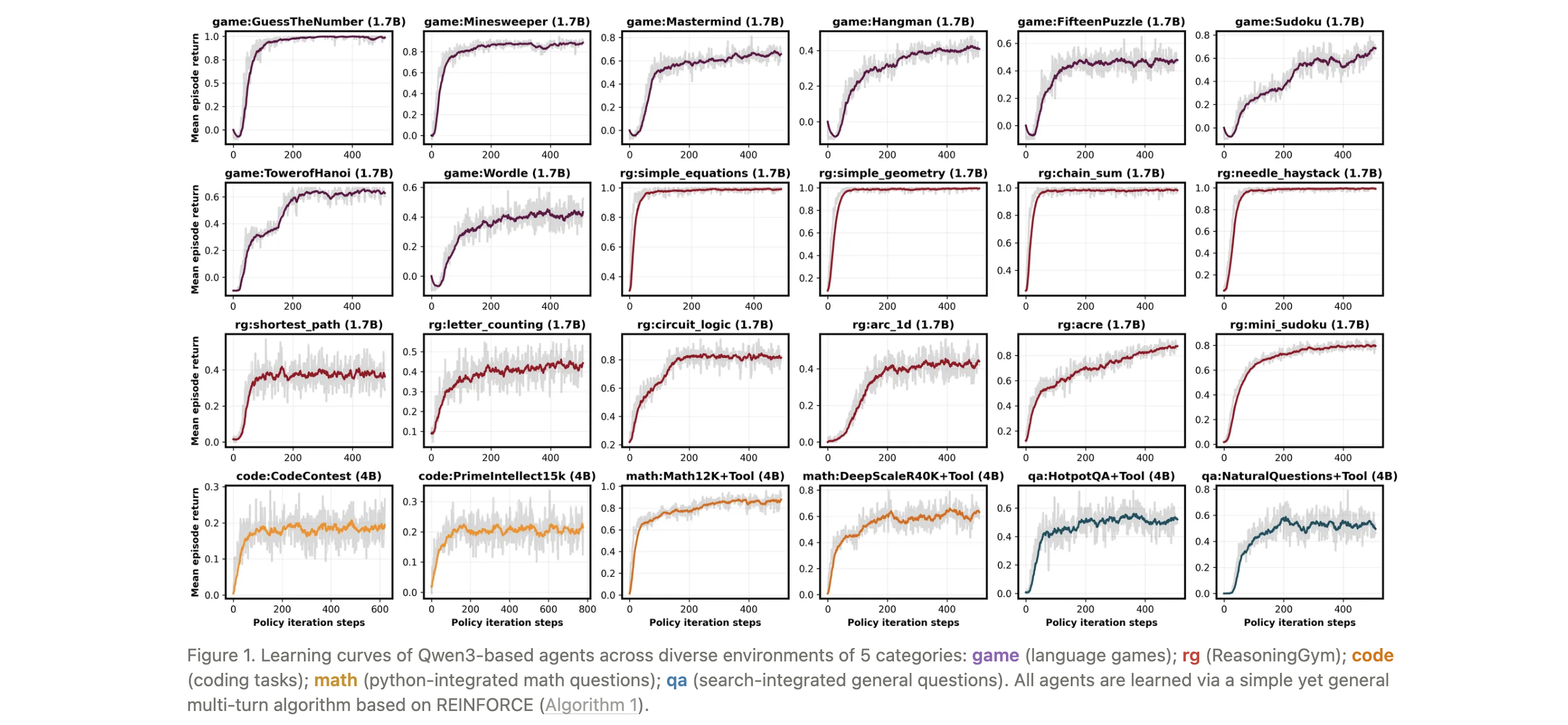
- 构建包含 5 类任务(数学、游戏、问答、代码、ReasoningGym)和 2 种工具(Python 执行、搜索)的多样化环境集,并提供异步向量环境、灵活包装器等功能,支持高效训练与扩展。
思维导图
方法论精要
环境设计与接口规范
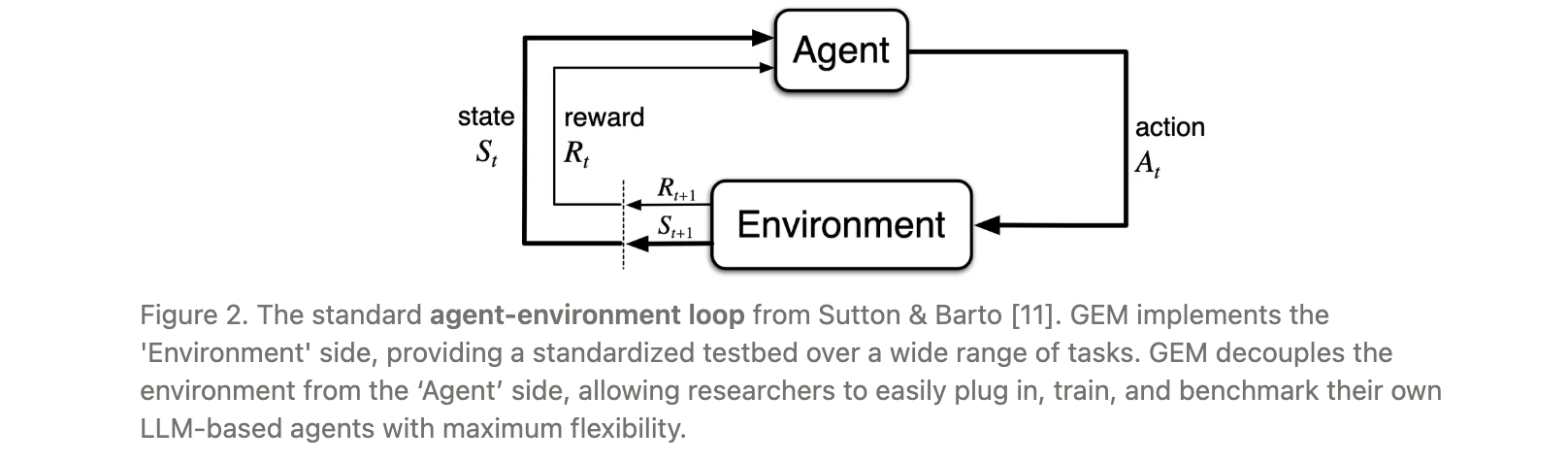
GEM遵循OpenAI Gym的设计理念,为LLM智能体提供标准化环境接口,核心方法包括:
reset(seed):初始化环境状态(如生成数学问题、游戏初始状态),返回初始观测值。step(action):执行智能体动作(如LLM生成的回答或工具调用),返回下一观测、奖励、终止信号(terminated/truncated)及附加信息。

环境由任务与工具组合构成:
- 任务类别:
- 数学(Math):需链式推理解决数学问题;
- 游戏(Game):基于TextArena的多轮文本游戏(如猜数字);
- 问答(QA):知识密集型检索与回答生成;
- 代码(Code):生成并验证Python代码;
- ReasoningGym:轻量级推理任务包装器。

- 工具支持:
- Python工具:解析并执行代码块,返回输出或错误信息;
- 搜索工具:解析查询并调用外部搜索引擎返回结果。

关键功能特性
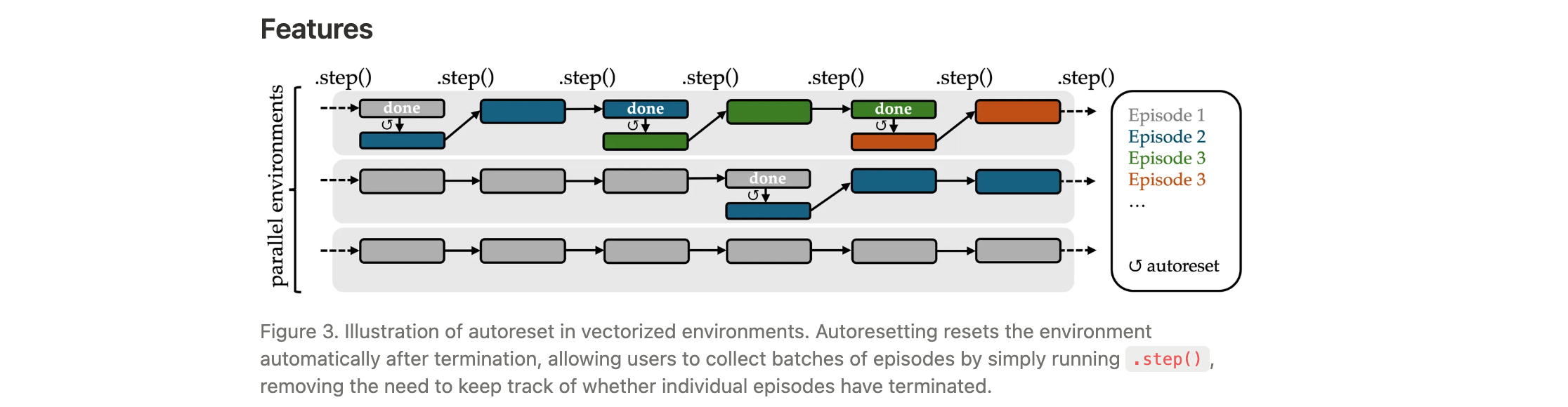
- 异步向量环境:支持并行执行多个环境实例,结合自动重置(autoreset)机制,无需手动跟踪每个episode的终止状态,只需初始化时调用一次
reset,后续通过step持续生成数据,显著提升训练吞吐量。 - 环境包装器:提供灵活的观测、动作、奖励转换机制,例如
FrameStackObservation通过维护观测历史滑动窗口增强马尔可夫性,适用于长程多轮交互场景。 - 自定义环境扩展:通过继承GEM基类,定义状态转换与奖励逻辑即可注册新环境,支持通过数据集扩展数学、代码、问答任务,或通过代码实现新游戏环境。
Baseline算法
GEM采用基于REINFORCE的多轮强化学习算法,核心改进为批次回报归一化。

具体流程如下:
- 数据收集与回报计算:
- 收集一批episodes,每个episode包含多步交互(transition);
- 逆向计算每个时间步的折扣累积回报;
- 对所有transition的回报进行批次归一化。
- 策略更新:
- 基于归一化回报,通过策略梯度更新LLM参数;
- 支持近端更新(proximal update)提升样本效率,优化目标包含完整推理轨迹+动作,避免长度偏差。
- 与现有算法的区别:
- 相比GRPO,无需从同一状态采样多个episode完成,兼容多轮回合奖励场景;
- 通过批次归一化引入负梯度信号,解决0/1奖励下学习效率低下的问题。
训练框架集成
GEM支持与主流强化学习框架集成:
- Oat集成:实现基于GEM向量环境的数据收集actor,将经验发送给learner进行策略更新;
- Verl集成:替换数据集采样为GEM环境交互,作为数据生成器嵌入训练循环。
实验验证两种框架的训练曲线一致性,证明GEM的框架无关性。
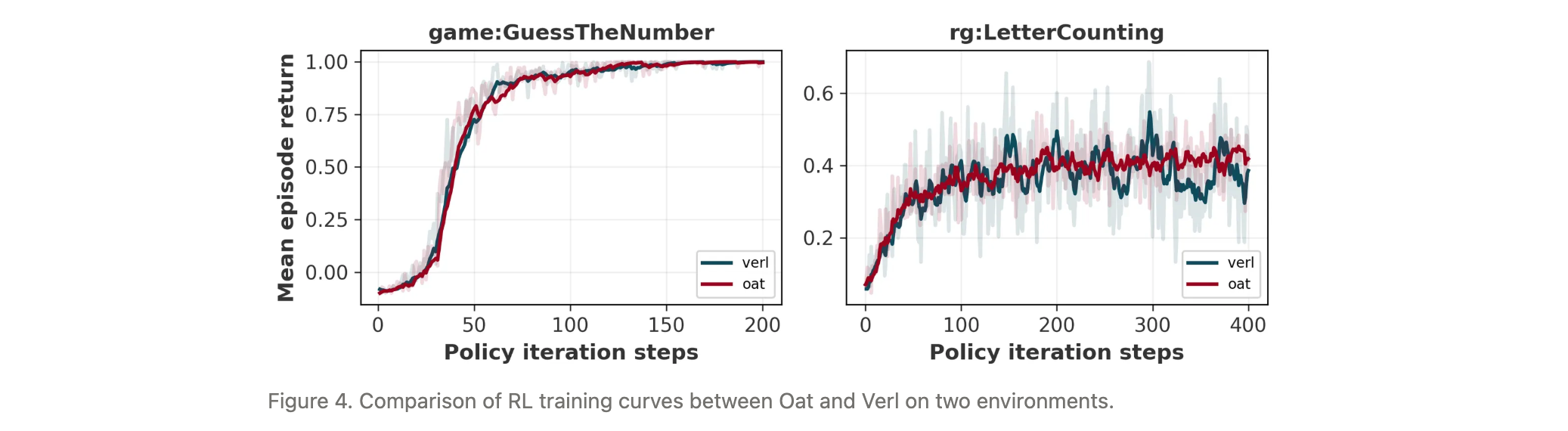
实验洞察
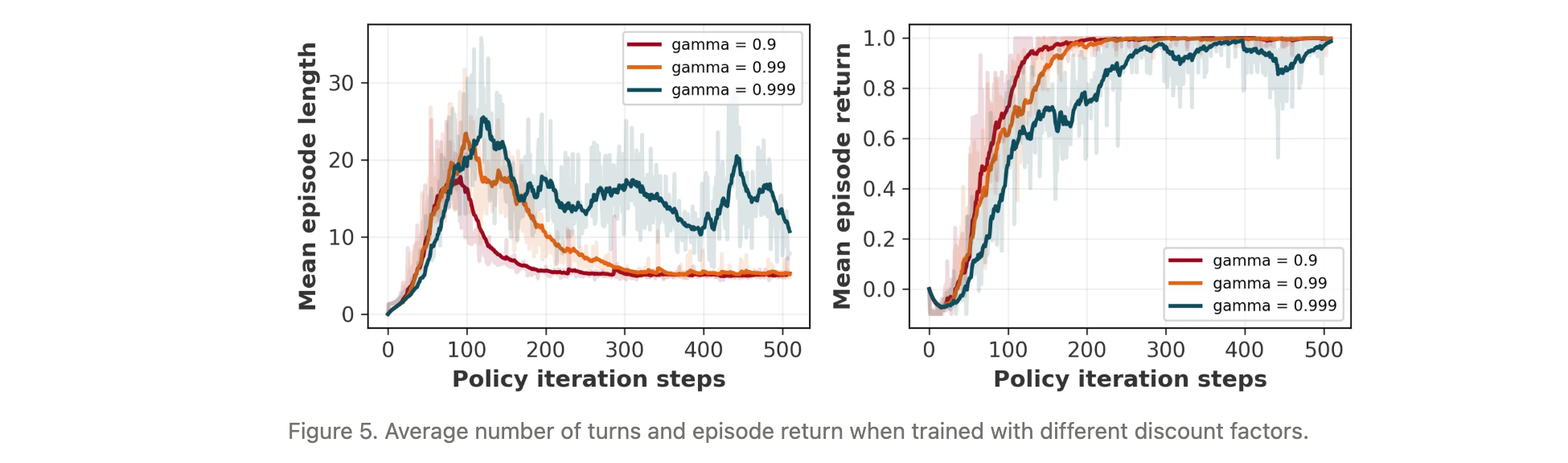
折扣因子对多轮策略的影响
在GuessTheNumber游戏(目标是通过最小步数猜中1-50之间的数字,最优策略为二分查找)中,分析折扣因子$ \gamma $的影响:
结果显示,较小的γ\gammaγ(如0.5)鼓励短视决策,推动智能体学习更优策略(平均步数接近log2(50)≈5.6\log_2(50) \approx 5.6log2(50)≈5.6);
较大的γ\gammaγ(如0.9)导致智能体接受更长路径,平均步数更高;
示例表明,γ=0.9\gamma=0.9γ=0.9时智能体明确采用二分查找策略,验证了折扣因子对策略优化方向的引导作用。
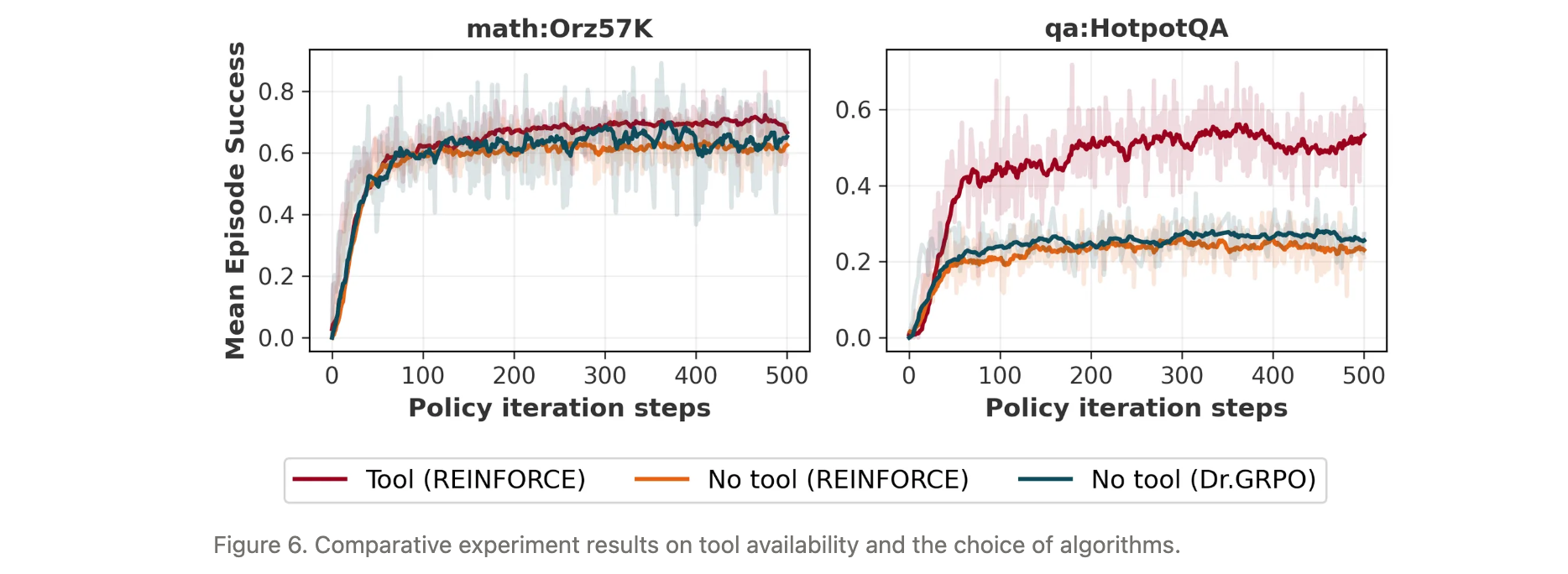
工具使用对性能的提升
在math:Orz57K(数学任务,配Python工具)和qa:HotpotQA(问答任务,配搜索工具)中对比工具使用效果:
- 基准算法:REINFORCE(无工具)、Dr.GRPO(无工具);
- 结果显示,工具使用显著提升性能:数学任务中REINFORCE+工具略优于基准,问答任务中性能接近翻倍;
- Dr.GRPO在无工具时略优于REINFORCE,可能得益于组内对比学习信号,但工具带来的增益更为显著。
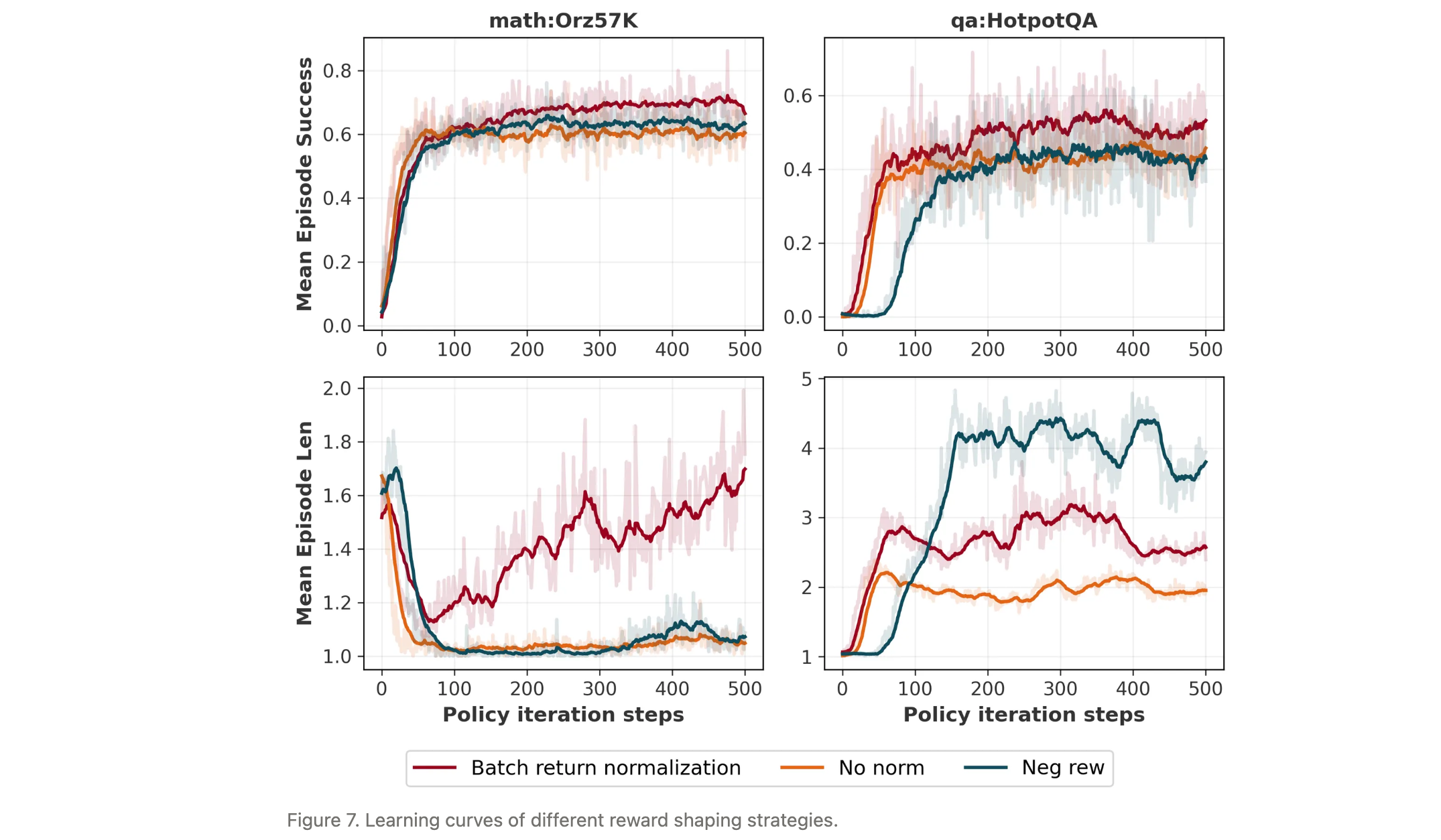
批次回报归一化的有效性
对比不同奖励塑造策略在多轮工具使用场景的效果:
- 无归一化(No norm):0/1奖励下,模型无法学习工具使用,性能停滞;
- 负奖励(Neg rew):1(正确)/-1(错误)奖励,在数学任务中无明显提升,在问答任务中导致工具滥用;
- 批次回报归一化:0/1奖励经归一化后,在数学、问答及游戏环境中均表现优异,有效解决了负梯度缺失问题,且对奖励塑造不敏感。
基准性能与泛化能力
数学任务泛化:
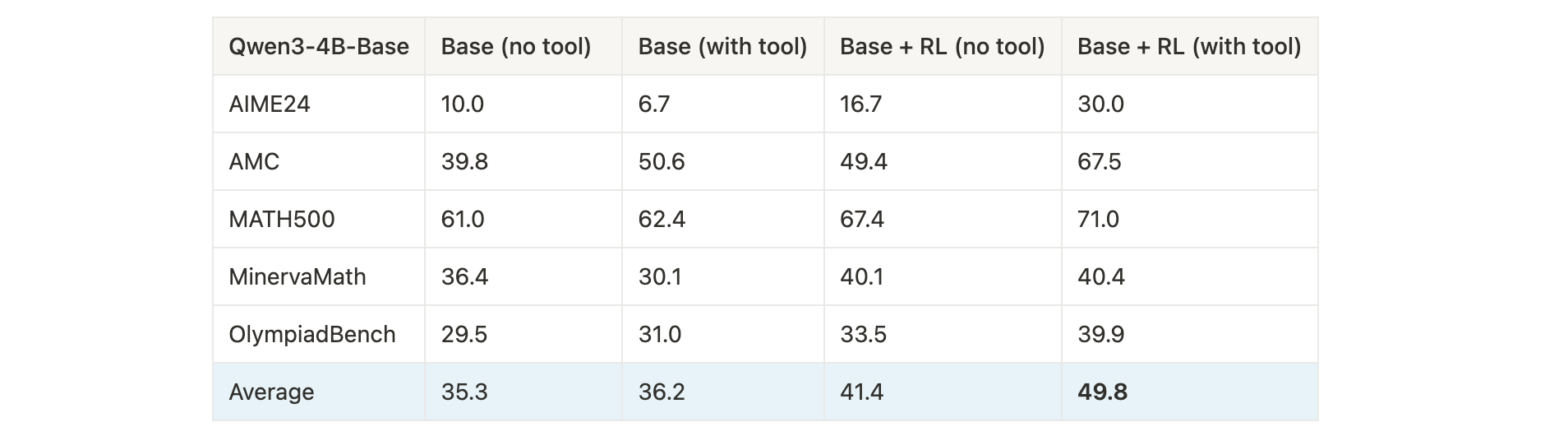
- 训练模型:Qwen3-4B-Base,在
math:Orz57K上训练; - 结果:RL训练+工具使用显著提升多数据集平均性能(从36.2%提升至49.8%),尤其在AIME24(+20%)和AMC(+16.9%)任务上增益明显。
问答任务泛化:
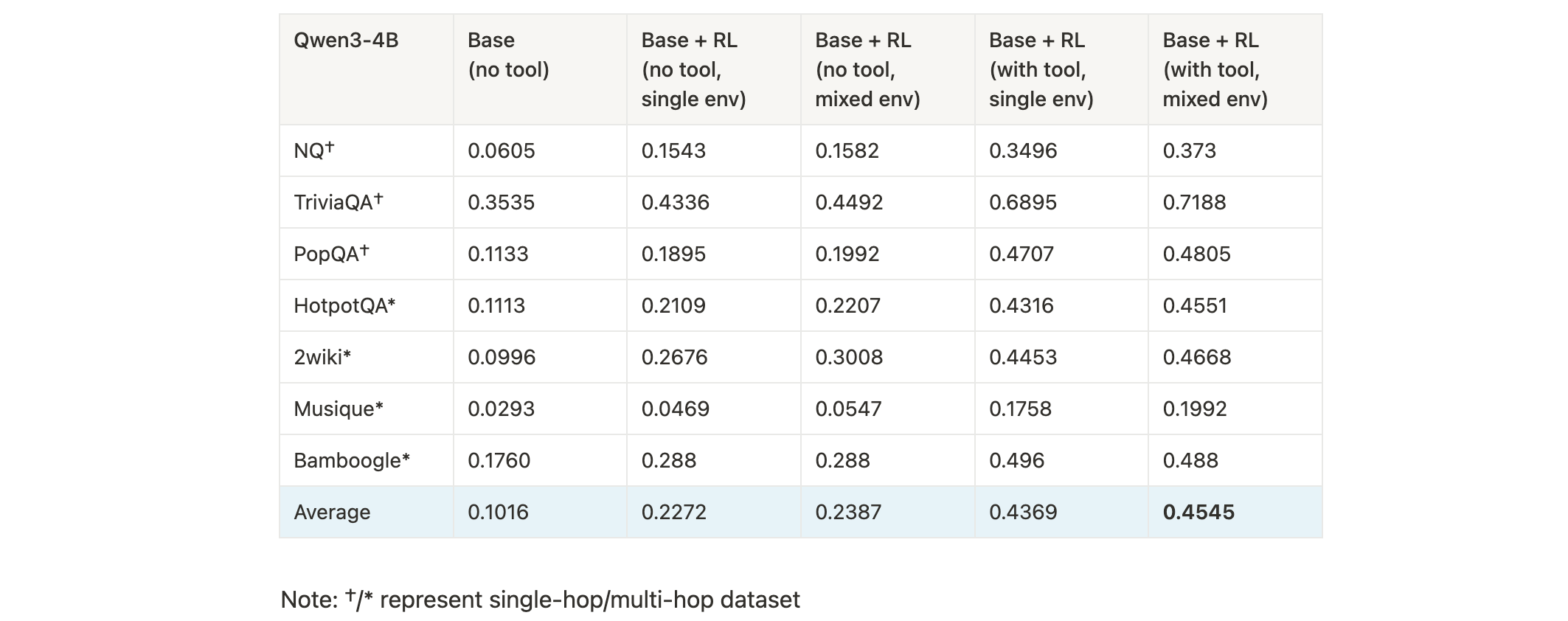
- 训练设置:单环境(
qa:HotpotQA) vs 混合环境(qa:HotpotQA+qa:NaturalQuestions),有无搜索工具; - 结果:RL+工具+混合环境训练效果最优,多数据集平均准确率达45.45%,较基线(10.16%)提升35个百分点,单跳与多跳任务均有显著增益。
跨框架一致性:
- Oat与Verl在相同环境上的训练曲线几乎重合,验证了GEM与不同训练框架集成的一致性。
关键发现
- 折扣因子是多轮任务中策略优化的关键参数,较小值更利于学习短路径最优策略;
- 工具集成(Python/搜索)能大幅提升LLM在知识密集型和计算密集型任务上的性能;
- 批次回报归一化是解决多轮场景下0/1奖励学习效率问题的简单有效方法,优于负奖励塑造;
- 混合环境训练能增强模型的泛化能力,尤其在问答任务中表现突出。